Итак, SC21 завершилась, шум вокруг «неофициально» появившихся экзафлопсных суперкомпьютеров поутих, а работа китайских учёных, выполненная на одном из них, получила премию Гордона Белла за развенчание мифа о квантовом превосходстве Google Sycamore (в которое, впрочем, еще в момент анонса пару лет назад поверили не все). Заявку на включение в TOP500 Китай в этот раз подавать не стал, а потому и подробностей о новых системах почти нет. Хотя это в целом не такая уж необычная практика — можно вспомнить многострадальный проект Blue Waters.
OceanLight
Кое-что о суперкомпьютере SunWay (ShenWei) OceanLight узнать все-таки можно, так как было опубликовано сразу несколько научных статей, в которых даны отдельные кусочки информации. За их достоверность, впрочем, поручиться нельзя. Кроме того, кое-какие материалы были выложены ещё весной, когда начался ввод этой машины в эксплуатацию. В некоторых аспектах она повторяет TaihuLight, самую мощную систему предыдущего поколения, некогда лидера TOP500.
OceanLight состоит из отдельных блоков (суперузлов), которые содержат по 256 узлов, объединённых между собой быстрой pan-tree-фабрикой. Сетевой адаптер (NIC) каждого узла имеет два интерфейса PCIe 4.0 x16 и предоставляет четыре 56-Гбит/с линии. Агрегированная пропускная способность фабрики превышает 1000 Тбайт/с в дуплексе при задержке менее 1,5 мкс, а число переходов от одного узла к другому внутри сети не превышает шести. СХД, о которой, увы, нет практически никакой информации, тоже включена в сетевую фабрику системы.
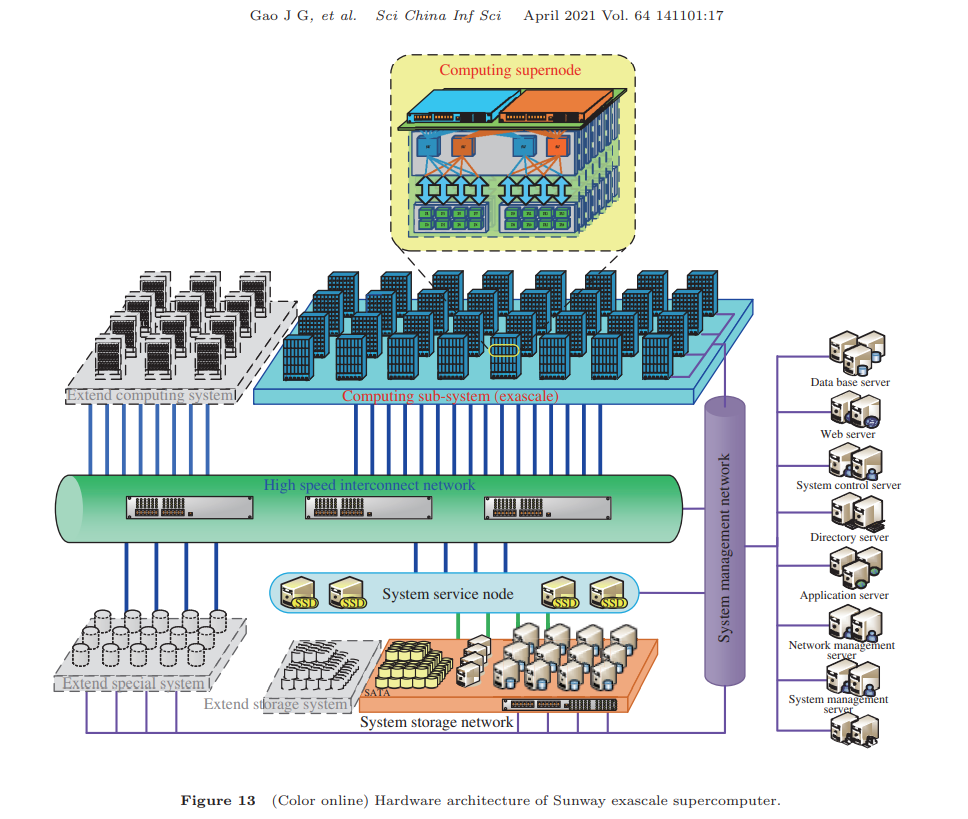
Каждый узел содержит локальные SSD, 96 Гбайт DDR4 и один CPU ShenWei SW26010-Pro (SW26010P). Это 64-бит RISC-процессор, который развивает идеи модели SW26010 и поддерживает тот же фирменный набор инструкций SW64. Сам процессор состоит из шести групп ядер, объединённых mesh-сетью (тор), к которой подключаются и NIC. Каждая группа ядер включает собственный контроллер памяти (по 16 Гбайт на группу), одно управляющее ядро (MPE) и кластер из 64 вычислительных ядер (CPE).
CPE организованы в виде mesh-кластера из 8 × 8 ядер (внутри они объединены в группы 4 × 4) и работают на частоте 2,25 ГГц. Каждое ядро имеет 32 Кбайт L1i-кеша и 256 Кбайт общей LDM-памяти, из которой опционально можно выделить блок 32 или 128 Кбайт для использования в качестве L1d-кеша. CPE сам определяет, какая конфигурация будет оптимальной. Для обмена данными между ядрами CPE-кластера используется RMA-интерфейс с пропускной способностью до 460 Гбайт/с.
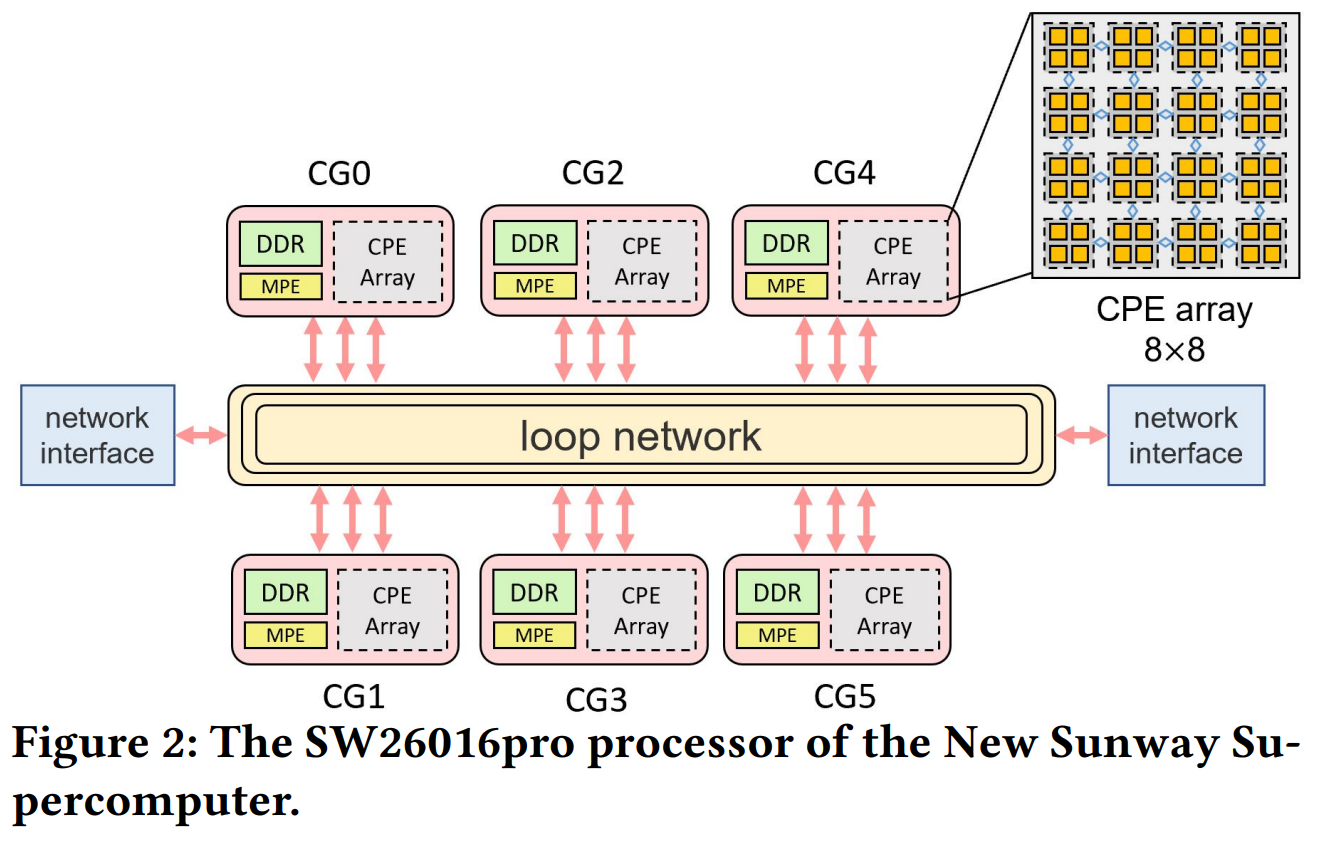
Между основной DRAM и LDM организован DMA-обмен с пиковой скоростью 307,2 Гбайт/с. Заявленный уровень задержки доступа CPE к основной памяти составляет менее 0,2 мкс. Ядро MPE, в отличие от CPE, имеет чуть более расширенный набор инструкций, работает на частоте 2,1 ГГц и доступно не только из пользовательского пространства. Впрочем, оба типа ядер имеют 256- и 512-бит SIMD-блоки. Есть поддержка FP64/FP32/FP16, а также целочисленных вычислений.
Пиковая теоретическая FP64-производительность SW26010P составляет 14,026 Тфлопс, а FP16 — 55,296 Тфлопс. Для CPU разработан собственный компилятор с поддержкой C/C++ и Fortran, а также OpenMP, MPI 3.1, OpenCL, OpenACC 2.0 и ряд адаптированных библиотек. Впрочем, разработчики утверждают, что для портирования ПО достаточно изменить порядка 1% кода. И при правильном подходе производительность с увеличением числа ядер (упомянуто до 42 млн) может расти практически линейно. Но тут всё нет так однозначно.
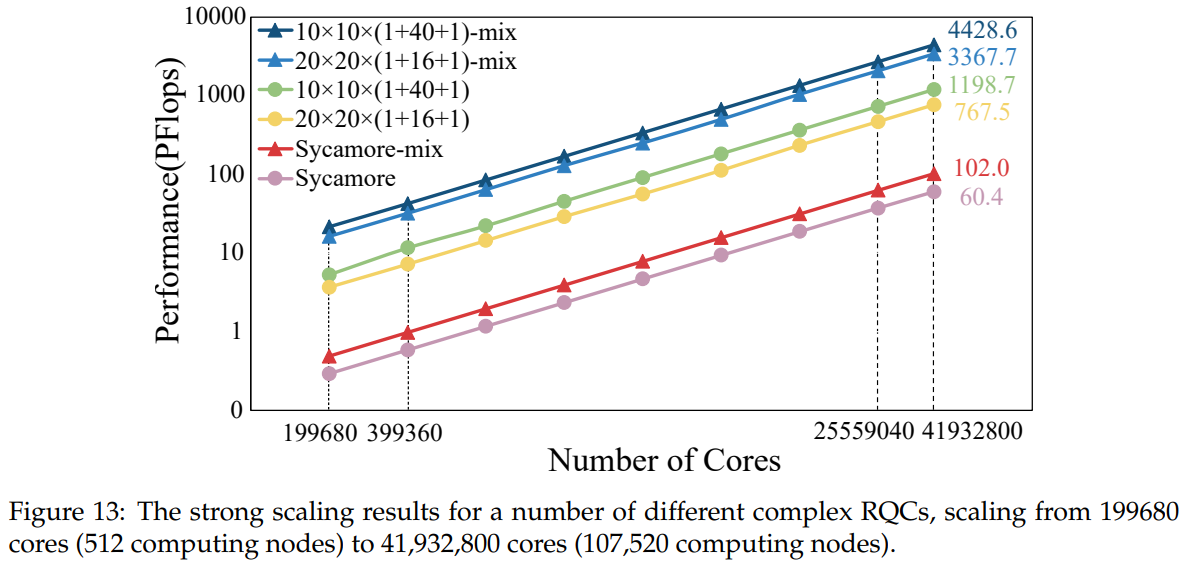
ATIP со ссылкой на свои (неофициальные) источники говорит, что на системе был запущен HPL, который показал 1,05 Эфлопс (по умолчанию в случае Linpack речь идёт о FP64). Пиковая заявленная производительность без конкретизации точности вычислений составляет 1,3 Эфлопс. В научных работах также приводятся такие цифры для конфигурации из 107 520 узлов и 41 932 800 ядер: 1,2 Эфлопс (FP32), 4,4 Эфлопс (смешанная точность, FP16) и 468,5 Пфлопс (FP64). Но! Это всё показатели для конкретных задач, исследуемых в рамках работ, и сравнивать их с результатами HPL других систем смысла нет.
Однако есть и ещё одна цифра — для более комплексного бенчмарка HPCG учёным удалось добиться устоявшейся производительности в 5,91 Пфлопс при соблюдении всех правил. Если же добавить некоторые оптимизации, то можно добиться уже 27,6 Пфлопс. Для сравнения: Fugaku, лидер TOP500, сейчас набирает в HPCG 14 Пфлопс, а в HPL 442 Пфлопс. Японская система потребляет 29,9 МВт, а для OceanLight приводится цифра в 35 МВт ±10%. Так что о высокой энергоэффективности обеих систем речи нет.
Tianhe-3
Постройка второй экзафлопсной системы, условно называемой Tianhe-3, по данным ATIP, практически завершилась в октябре, и у неё есть перспективы дальнейшего расширения. Опять-таки неофициально сообщается о полном предварительном прогоне HPL, который показал устоявшуюся FP64-производительность на уровне более 1,3 Эфлопс (вот тут ATIP говорит уже о FP64), а пиковую — более 1,7 Эфлопс. И тут нам снова помогут публикации китайских учёных, в которых рассказывается о тестовом варианте системы.
Первый прототип включал 512 узлов, 96 608 ядер, 98,3 Тбайт RAM и хранилище на 1,4 Пбайт. Пиковая теоретическая производительность составляла 3,15 Пфлопс, но в HPL удалось получить 2,47 Пфлопс (по умолчанию считается, что это FP64). Суперкомпьютер полагается в первую очередь на ускорители Matrix2000+, которые сами разработчики всё же называют CPU. Каждый узел содержит три таких ускорителя, работающих на частоте 2 ГГц.
Matrix2000+ содержит 128 ядер, которые собраны в четыре независимых суперузла, объединённых быстрым внутренним интерконнектом. Суперузел, в свою очередь, включает четыре блока, каждый из которых состоит из восьми ядер, имеющих общий кеш с поддержкой когерентности. За обмен данными между ядрами отвечает отдельный движок. Ядра имеют конвейер переменной длины (от 8 до 12 стадий) и способны выполнить восемь FP64-операций за такт. Таким образом, пиковая производительность одного CPU составляет 2,048 Тфлопс.
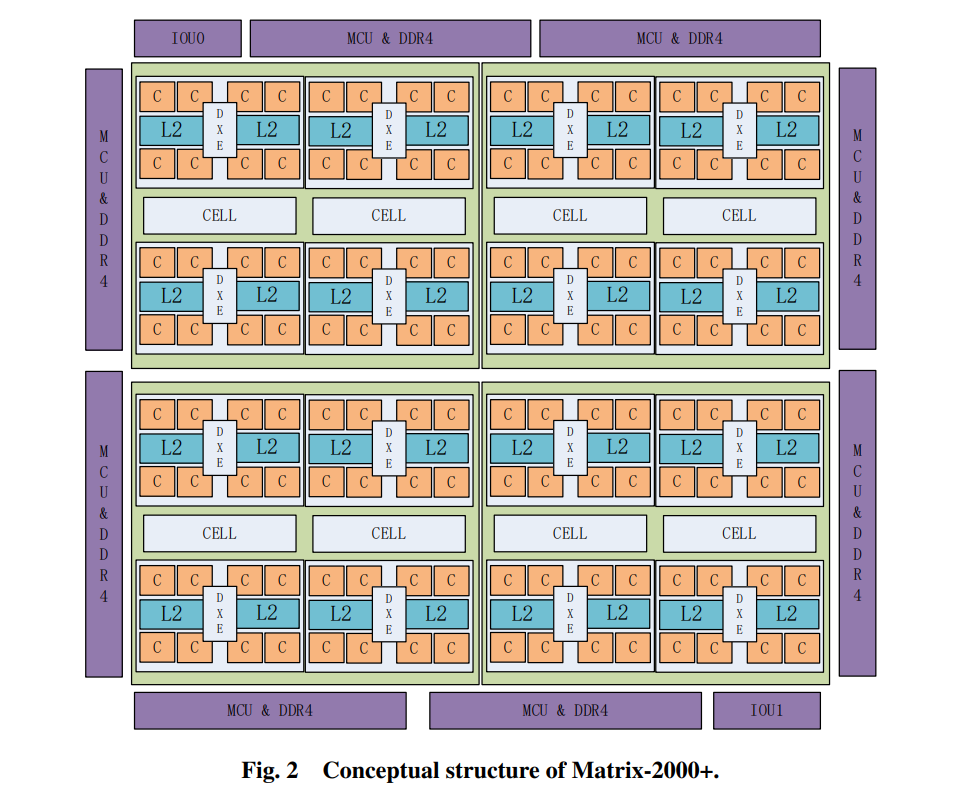
Архитектура ядер — RISC (без уточнения семейства) с дополнительными векторными инструкциями и отсутствием поддержки внеочередного исполнения. Интересной особенностью является поддержка векторов переменной длины, от 128 до 1024 бит, на уровне суперузла (возможно, и ядра), что напоминает Arm SVE (Fujitsu A64FX в Fugaku, к примеру, поддерживают SVE-512). Сам CPU имеет восемь контроллеров памяти DDR4-2400, что даёт каждому узлу до 768 Гбайт DRAM с суммарной пропускной способностью 614,4 Гбайт/с. Также имеется контроллер PCIe 3.0, который нужен, в частности, для сети.
Интерконнект здесь тоже интересный и тоже собственной разработки. Он использует два вида ASIC — для подключения (HFI-E) и для маршрутизации (HFR-I) — и реализует механизм MP/RDMA (Mini Packet/Remote Direct Memory Access), а также аппаратную разгрузку. HFI-E используют подключения PCIe 3.0 x16 и предоставляют 200-Гбит/c порты (восемь SerDes-блоков 25 Гбит/с). HFR-I имеет 24 200-Гбит/с порта и суммарную пропускную способность 9,6 Тбит/с, а для передачи MPI заявлена задержка 1,1 мкс.

Плата с тремя чипами Matrix-2000+ (Фото: NUDT)
Сетевая фабрика (двумерное дерево) использует активные оптические соединения и способна масштабироваться до 150 тыс. узлов. Более того, разработчики утверждают, что они добились и самой высокой в мире плотности размещения — 864 оптических порта в одном шасси. Фабрика поддерживает автономное управление ресурсами и планирование, функции изоляции и самовосстановления, да и в целом является программно определяемой.
Для разработки ПО предлагается использовать компилятор MOCL для C/C++/Fortran с поддержкой OpenMP 4.5 и OpenCL 1.2. Ожидается, что система Tianhe-3 со временем будет доступна зарубежным пользователям — в отличие от OceanLight, которая в большей степени ориентирована на внутренние нужды Китая. В нынешний TOP500 Tianhe-3 вряд ли бы успела попасть в силу затянувшихся из-за пандемии сроков постройки, но есть шанс, что летом 2022 года она всё же будет включена в рейтинг.

Описываемая архитектура отличается от той, что предполагалась ранее. На данный момент ничего не говорится об «обычных» CPU. Это должны быть наследники FT-2000+/64: ARMv8, 7 нм, 64 ядра, PCIe 4.0, DDR4, 2+ Тфлопс и поддержка FP16. Вероятно, именно их TSMC перестала производить весной этого года под давлением США. Ускоритель тоже должен быть другой, Matrix-3000: 96+ ядер, 10+ Тфлопс, HBM2 и PCIe 4.0. Текущее состояние этих чипов, а также наличие их в Tianhe-3 неизвестно.
Планы Китая
Третья экзафлопсная система, ранее известная как Shuguang, должна была бы иметь «честную» производительность уже в 2 Эфлопс. Однако её запуск пока что перенесён на 2022 год, и проект находится в подвешенном состоянии. Дело в том, что изначальный подрядчик — компания Sugon — уже неоднократно попадал под санкции США, а имеющиеся у него технологии не позволяют самостоятельно создать эффективную машину такого класса. В активе Sugon остались процессоры Hygon Dhyana, клоны первого поколения EPYC, с которыми она без поддержки AMD вряд ли что-либо сможет сделать.

Ранее компания грозилась каким-то образом перевести их на 7-нм техпроцесс Samsung или TSMC. Так что либо Sugon удастся каким-то чудом построить систему нужного класса, либо компания будет заменена другим подрядчиком, менее «токсичным» и способным получить современные западные компоненты. Есть и третий вариант — поскольку Sugon разрабатывала собственные ускорители DCU с обещанной производительностью до 15 Тфлопс, возможно, хватит и имеющихся Hygon для постройки машины.

Однако всё это лишь часть общей картины. По данным ATIP, сейчас у Китая есть восемь крупных национальных суперкомпьютерных центров, два из которых появились в 2020 году. Ещё два появятся в ближайшее время. И уже введено в строй или готовится к этому несколько суперкомпьютеров производительностью от 100 до 500 Пфлопс (тут как раз лидер Sugon), которые могли бы изрядно поменять расклад сил в первой десятке TOP500. Более того, к 2025 году Китай планирует получить сразу две 10-Эфлопс системы.
Мировой ландшафт
Согласно данным Hyperion Research, в следующем году заработает первая — во всяком случае, первая публичная — экзафлопсная система Frontier с ожидаемой пиковой производительностью 1,5 Эфлопс и потреблением порядка 29 МВт. Полностью доступна она будет в III квартале 2022 года. Примерно тогда же должна начать работу Aurora с устоявшейся производительностью более 1 Эфлопс. У площадки неожиданно высокий уровень энергопотребления — 60 МВт. Если вся эта мощь уйдёт только на машину, то энергоэффективность её вызовет большие вопросы.
И тогда же должен появиться суперкомпьютер El Capitan с ожидаемой производительностью 2 Эфлопс. Но фактически две последние системы будут окончательно введены в эксплуатацию только в 2023 году. В планах на ближайшие пару лет есть ещё несколько систем средних размеров. А в 2026-м систем экзафлопсного класса должно быть уже около десятка. Примерно столько же, как ожидается, будет и у Китая.
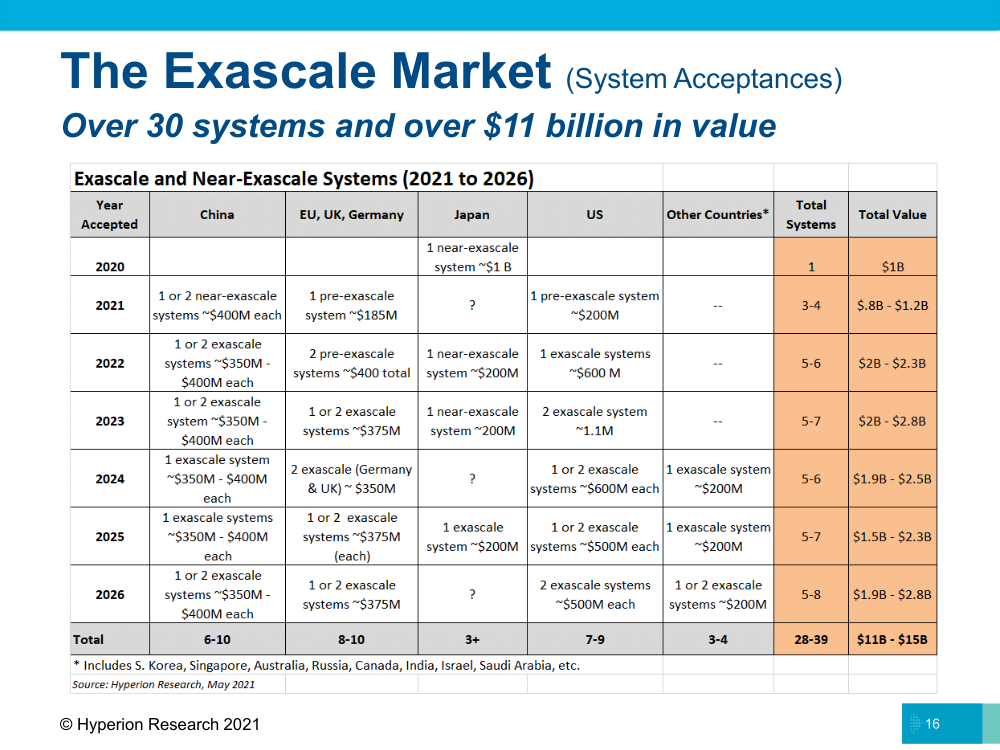
Япония пока что полностью удовлетворена работой Fugaku и следующую большую систему хочет получить только в 2025 году, а до этого введёт в строй ещё пару машин поменьше. Великобритания после выхода из Евросоюза и последовавшего «отлучения» от ряда проектов оказалась в несколько затруднительном положении и готовится запустить только одну экзафлопсную машину в начале 2024 года. Подробностей о ней пока не известно.
Проект Евросоюза EuroHPC в очередной раз натолкнулся на разногласия между участниками, так что первая крупная система, MareNostrum 5, несколько задержится. Всего же планируется построить три суперкомпьютера мощностью 150-200 Пфлопс в Испании, Италии и Финляндии. Также в скором времени должна заработать 550-Пфлопс система LUMI. В остальном мире первые экзафлопсные машины должны появиться после 2023 года, но их будет совсем немного.
Заключение
Некоторое удивление вызвал даже не сам факт появления у Китая столь мощных систем, а то, что обе машины базируются на чипах собственной разработки, которые оказались, если верить результатам китайских учёных, не так уж и плохи в сравнении с американскими решениями и способны показать возможности не только исключительно экстенсивного наращивания производительности. По крайней мере, на текущий момент это так. Впрочем, в любом случае это системы нового поколения, как и Fugaku. При этом надо понимать, что возникли они не из ниоткуда — о планах было заявлено почти 10 лет назад, а ранние прототипы появились в 2018-2019 гг.
В этом отличие, например, от Европы, где только в последние годы громко заговорили о необходимости технологической независимости — насколько такая независимость вообще возможна при нынешнем уровне глобализации. Европейские производители разрабатывают собственные HPC-чипы (Arm, RISC-V и Tachyum), но готовы комбинировать их и с другими решениями. Аналогичные проекты есть у Индии и Южной Кореи. А у Японии (помимо A64FX) есть и всякая экзотика вроде PEZY-SC или MN. В России же из заметных проектов можно, наверное, выделить «Эльбрус-16С»/«Эльбрус-32С» и будущие Baikal.


{kind=link}