При построении и обслуживании инфраструктуры такого масштаба требуется учитывать массу параметров, среди которых даже самый незначительный на первый взгляд может кардинально повлиять на совокупную стоимость владения (Total Cost of Ownership, TCO), к минимизации которой стремятся все гиперскейлеры. Как происходит процесс выбора оборудования и почему решили попробовать систему жидкостного охлаждения (СЖО) в серверах, нам рассказал Станислав Закиров, директор по развитию инфраструктуры VK.
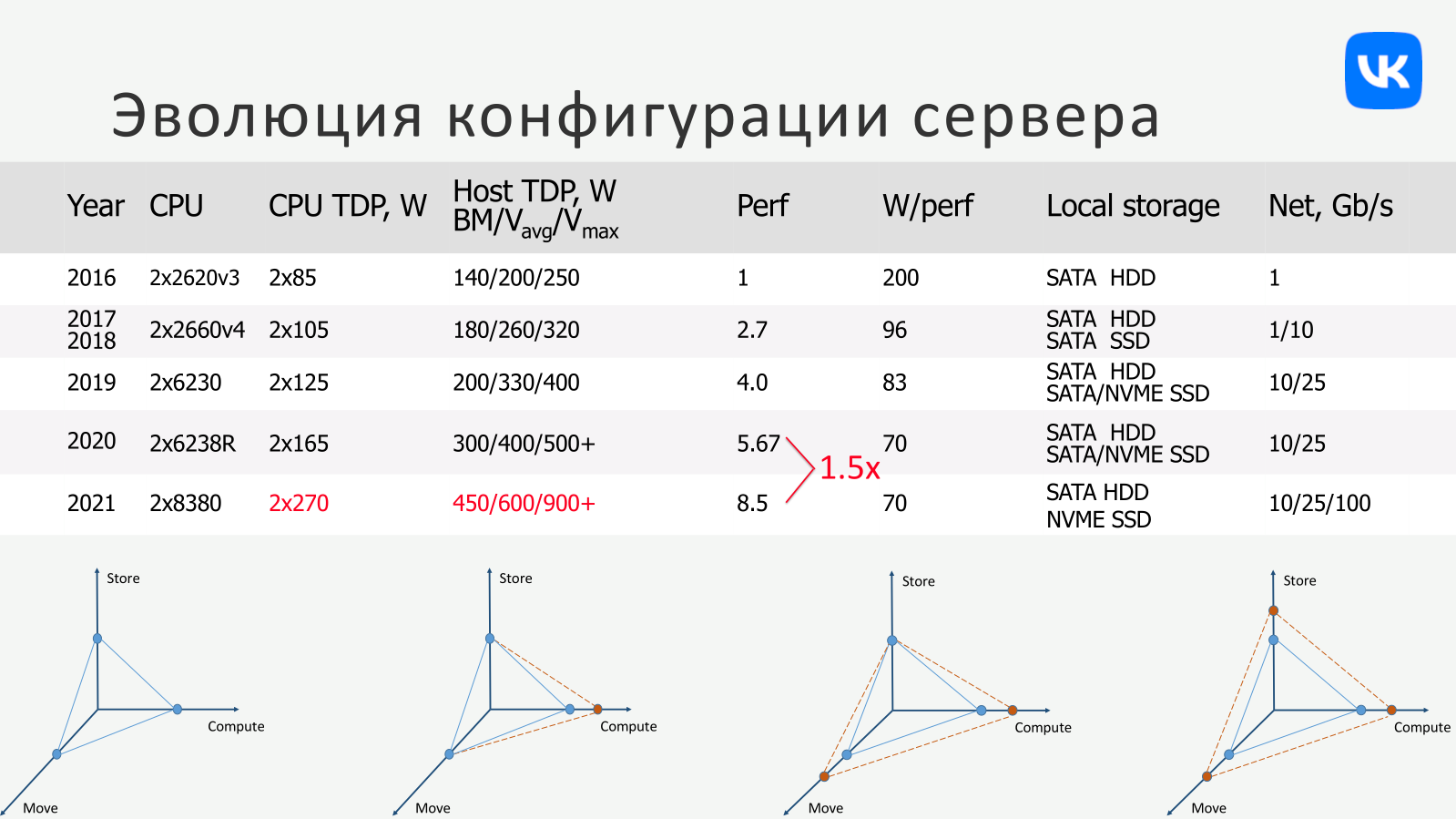
В случае VK — а это не только ВКонтакте, но и масса других сервисов, включая Одноклассники, Mail.RU, Ситимобил, Delivery Club и т. д. — подход к построению инфраструктуры значительно изменился за последние несколько лет. За выбор аппаратной платформы отвечает отдельная тестовая лаборатория, которая изучает массу «железа», в том числе ещё не вышедшего. Одним из важнейших параметров при выборе является производительность на ватт, поскольку этот параметр оказывает драматичное влияние на будущие операционные затраты и, следовательно, на оценку TCO.

Первичный отбор идёт с опорой на синтетические тесты, но затем кандидаты попадают в руки инженеров, которые смотрят как они справляются с реальными нагрузкой, данными и в реальном же окружении. С CPU снимается масса метрик, включая, например, уровень загрузки, время отклика, промахи кеша и т. д. Основное требование — чтобы новая система справлялась с задачами наиболее требовательных и крупных внутренних заказчиков максимально эффективно с точки зрения затрат на единицу полезной производительности.
Излишние для менее требовательных задач мощности всё равно до определённой степени утилизируются, в чём помогает переход к облачной модели (в частности, контейнеризации и виртуализации) и программно определяемым решениям вкупе с грамотной оркестрацией. Собственно говоря, на данном этапе развития VK подошла к логическому концу — все новые машины имеют унифицированную платформу с единственным вариантом процессора, на которой строятся и CPU-узлы, и GPU-узлы, и СХД.
Изображение: VK
Текущее поколение серверов базируется на двухсокетных платформах с Intel Xeon Platinum 8380 (40C/80T, 2,3/3,40 ГГц, L3-кеш 60 Мбайт, TDP 270 Вт). Проще говоря, используется самый старший процессор Intel на текущий момент. CPU теперь только один и платформа тоже одна. Закупаются они всё в больших объёмах, что значительно удобнее и выгоднее с точки зрения обслуживания и позволяет получить существенный выигрыш в цене. Настолько существенный, что даже использование двух-трёх платформ с отличающимися CPU и периферией в нынешних условиях и с текущими запросами VK оказывается в среднем дороже.
И это даже без учёта дополнительных факторов вроде дозакупки CPU и прочих компонентов в будущем, ведь чем больше используемый ассортимент, тем труднее это будет сделать. Но у каждого гиперскейлера своя, очень интересная математика. Можно посмотреть, к примеру, на дизайн OCP-серверов Meta✴ (Facebook✴), а ещё лучше — на новые платформы AWS, которая «достигла вершин». AWS использует преимущественно собственные ЦОД и активно переходит на платформу с собственными же CPU Graviton3. Что и приводит нас к вопросу об операционных расходах, а точнее о балансе между CAPEX и OPEX.

Изображение: VK
У VK сейчас всего два собственных дата-центра — в Москве и Санкт-Петербурге, а всё остальное приходится на арендованные площадки в других ЦОД, причём далеко не всегда самых новых. Это имеет свои последствия. Повышение плотности размещения вычислительных мощностей в рамках одного узла приводит к необходимости более сложных калькуляций для питания и охлаждения в рамках стойки и, далее, ЦОД. Так, для новой платформы было выбрано 2U-шасси просто потому, что в него можно поставить более крупные вентиляторы, снизив их скорость вращения и энергопотребление, которое быстро растет по мере увеличения нагрузки на «железо».
Собственно говоря, в современных платформах c парой CPU, у которых TDP приближается к 300 Вт (в пике ещё выше), и прочими компонентами (ещё до 200 Вт) на питание только вентиляторов может уходить ещё треть от уровня потребления самого «железа». При этом масштабировать питание с типовых для коммерческих ЦОД (с их фактической средней нагрузкой по мощности, грубо говоря, на уровне двух третей) 5-7 кВт на стойку можно ещё относительно просто. А вот охлаждение — далеко не всегда. И это мы ещё не говорили про системы с ускорителями, где только «кремний» съедает от 3 кВт.
Выход? Первый путь — резко снижать плотность размещения оборудования в стойках, что чаще всего невыгодно с точки зрения TCO и в своём ЦОД, и владельцам арендованных, особенно когда таковые расположены там, где стоимость земли является значительной статьёй расходов при построении дата-центра. Кроме того, это усложняет поддержание связности и повышает расходы на сетевую инфраструктуру. Второй — создавать собственные оптимизированные узлы и дата-центры, где уже можно экономить просто на масштабах развёртывания, как и делают крупные гиперскейлеры. Третий — повышать эффективность охлаждения. А вот как именно, вопрос отдельный.
Повышать выработку холода для традиционного воздушного охлаждения может быть накладно, да и склонить оператора ЦОД (своего или чужого, нового или старого) к установке, скажем, ещё пары-тройки чиллеров (а это не только лишнее место, но и электричество) не всегда возможно, а часто не реализуемо даже технически. Компромиссный вариант — это СЖО, у которых эффективность выше, но которые, если это не иммерсионные системы, можно относительно просто внедрить даже в уже имеющуюся инфраструктуру. Да, не всегда и не везде. Да, капитальные расходы будут несколько выше, чем у классического «воздуха», зато в перспективе потенциально можно значительно сэкономить на операционных.

Вообще говоря, для каждого отдельного случая надо делать отдельные расчёты, но если имеется возможность протестировать СЖО на существующих мощностях, а в планах есть дальнейшее расширение инфраструктуры, где без мощных систем с ускорителями уже никак не обойтись, то упускать такой шанс не стоит. Ровно такая ситуация сейчас у VK, которая, в частности, готовится к строительству третьего по счёту собственного ЦОД, который разместится в подмосковном Домодедово. Для изучения возможностей практического применения СЖО VK обратилась к компании РСК, которая создала систему «под ключ», компоненты собственной разработки: насосные блоки, систему распределения жидкости в стойке и водоблоки для CPU с TDP 270+ Вт.
В начале лета 2020 года тестовая система была развёрнута в московском дата-центре VK (далеко не самом новом) — две стойки с различными типами узлов на 30 кВт суммарно, на каждую из которых приходилось по 5 кВт на «воздух» и по 10 кВт на «воду». На коммутацию систем ушло полдня, причём СЖО была в минимальном варианте, т. е. без резервирования. Затем эти машины были включены в общий пул, и на них запущены (и до сих пор работают) обычные продуктовые нагрузки. Изучив особенности поведения и эксплуатации машин и СЖО, найдя и устранив все проблемные места, а также отладив весь программно-аппаратный стек, компания приняла решение расширить тестовый полигон — всего сейчас 60 машин в Москве и ещё 40 в Санкт-Петербурге.

Летом 2021 года в Москве появилось ещё несколько стоек с СЖО в серверах. В том числе два десятка GPU-узлов: те же два топовых CPU + восемь PCIe-ускорителей по 300 Вт каждый. При этом все горячие компоненты в таких узлах охлаждаются жидкостью. Сам контур пятикратно нарастил мощность и получил резервирование: для охлаждения жидкости установлены две градирни, а для создания циркуляции холодоносителя — два насосных блока. Причём насосные блоки РСК уникальны — это единственное решение, объединяющее насосы внутреннего и внешнего контуров в одном блоке вкупе с энергоэффективной схемой управления. Вся система охлаждения, включая градирни и насосы обоих контуров, потребляет пропорционально количеству установленных серверов с СЖО и реальной тепловой нагрузке.
После обновления инженерам тестовой лаборатории снова пришлось помучиться с отладкой всей этой системы на разных уровнях. Начиная с того, что перевод GPU на СЖО намного сложнее, чем CPU, и заканчивая созданием развитой системы мониторинга, которая позволила понять, почему в синтетических тестах всё было хорошо, а под реальными нагрузками возникали проблемы. Это важно, поскольку ускорители участвуют в распределённом машинном обучении, и потеря даже одного из них неприятна.

Заодно было подтверждено, что с ростом масштаба внедрения СЖО становятся всё более и более выгодным решением — каждый киловатт в новой тестовой 100-кВт системе с резервированием обходится значительно дешевле, чем в старой 20-кВт без него. И узел с исключительно воздушным охлаждением, согласно тестам, по факту потребляет не меньше, чем с СЖО (включая и внутренние, и внешние компоненты), а масштабировать только «воздух» значительно дороже.
Такой гибридный подход с отбором тепла с помощью СЖО от удельно наиболее горячих компонентов (на них в среднем приходится 85% по питанию и, соответственно, охлаждению в конкретной системе) позволяет, например, намного проще перейти уже на фрикулинг (в том числе с адиабатикой). Итоговый коэффициент PUE составляет примерно 1,1 против традиционных 1,35–1,5. Поэтому даже если CAPEX для СЖО выше, CAPEX для дата-центра целиком (особенно с учётом IT-компонентов) может быть ниже, а экономия на OPEX на периоде от 3–5 лет и вовсе позволяет полностью окупить повышенные капитальные затраты.

А само по себе снижение удельного пикового энергопотребления позволяет меньше потратить на закупку гарантированных мощностей, ИБП и генераторов. Кроме того, есть и целый ряд дополнительных факторов в капитальных затратах. Например, для «воды» — это как минимум вся «сантехника», дооборудование узлов и стоек и т. д. В случае только «воздуха» это весьма дорогие радиаторы и вентиляторы для высоких уровней TDP и более низкая плотность размещения оборудования в стойках.
В случае VK расчёты показывают, что внедрение СЖО оказывается эффективным по ключевым параметрам решением. Это не значит, что у всех остальных будет точно так же. Даже нынешнюю платформу можно достаточно комфортно использовать в старых ЦОД. Но у VK уже есть планы на следующее поколение «железа», у которого TDP растёт (CPU 300+ Вт, GPU 500+ Вт), а вот критическая температура падает. И к его появлению надо готовиться уже сейчас, причем переход на СЖО для них будет ещё более эффективным, чем в нынешнем поколении.

А возможность использования именно нужного (и топового) оборудования важна для развития бизнеса в целом. Как оно получится на самом деле, сейчас никто не готов сказать. Пока что в планах оснастить СЖО часть будущего ЦОД, получив опыт действительно массового развёртывания и эксплуатации узлов с «водой», а также остальной инфраструктуры — например, про СХД и сеть тоже нельзя забывать. Главное, что страха перед использованием СЖО в ЦОД уже нет. Есть понимание слабых мест и единых точек отказа, есть понимание, как решать проблемы.

