|
Опрос
|
реклама
Быстрый переход
Билли Айлиш и сотни музыкантов попросили защиты от неправомерного применения ИИ в музыке
03.04.2024 [17:08],
Дмитрий Федоров
Более 200 известных музыкантов и владельцев авторских прав подписали открытое письмо, которое было опубликовано правозащитной группой Artist Rights Alliance. В нём они выразили серьёзную обеспокоенность неправомерным использованием искусственного интеллекта в музыке, призывая к немедленному регулированию этой области с целью предотвращения потенциального ущерба их творчеству и культурному наследию. 
Источник изображения: artistrightsnow.medium.com В числе подписавшихся — звёзды мировой музыки и наследники прав на творения легендарных исполнителей: Стиви Уандер (Stevie Wonder), Смоки Робинсон (Smokey Robinson), Билли Айлиш (Billie Eilish), Джон Бон Джови (Jon Bon Jovi), Кэти Перри (Katy Perry), группы REM и Pearl Jam, а также представители наследия Боба Марли (Bob Marley) и Фрэнка Синатры (Frank Sinatra). Такое многообразие жанров и поколений иллюстрирует общую обеспокоенность влиянием ИИ на музыкальное искусство. Открытое письмо поднимает вопрос о двойственной природе ИИ: с одной стороны, его потенциал для расширения границ творчества в музыкальной индустрии неоспорим, с другой — существует риск его неправомерного использования, когда технологии подрывают уникальность и ценность авторского труда. Проблема касается инструментов, разработанных технологическими гигантами. Эти инновации вызывают волну споров о нарушении авторских прав и риски судебных разбирательств. Письмо акцентирует внимание на том, что неконтролируемое применение ИИ ставит под угрозу не только авторское право, но и личную идентичность артистов, их творческую уникальность и финансовую независимость. Авторы призывают к ответственному использованию технологий, подчёркивая безразличие крупных компаний к их правам. Губернатор штата Теннесси Билл Ли (Bill Lee) выступил в поддержку музыкантов, приняв законопроект, направленный на защиту авторов от неправомерного использования их творчества компаниями, занимающимися разработкой ИИ. Закон, получивший название «Закон Элвиса» (Elvis Act), призван защитить уникальность и интеллектуальную собственность артистов. Особое внимание уделяется инструментам, способным генерировать тексты песен, имитируя стили различных авторов. Примером служит реакция австралийского исполнителя Ника Кейва (Nick Cave) на сборник его собственных текстов, созданных с помощью ChatGPT, который назвал «гротескной карикатурой на человечность». Не все воспринимают подобные инновации негативно. Люсиан Грейндж (Lucian Grainge), глава Universal Music Group, высказал мнение о необходимости поиска компромиссов, совместной работы ИИ и музыкантов над созданием будущего, где технологии и творчество будут дополнять друг друга. В исках NeMo: писатели обвинили Nvidia в незаконном использовании произведений для обучения нейросети
11.03.2024 [11:30],
Алексей Разин
В минувшую пятницу Федеральный суд Сан-Франциско принял к рассмотрению групповой иск к Nvidia от троих авторов литературных произведений, которые обвиняют компанию в неправомерном использовании своих трудов для обучения системы искусственного интеллекта NeMo созданию текстов на английском языке. 
Источник изображения: Nvidia Представители истцов сообщают, что Nvidia использовала выборку из 196 640 литературных произведений для обучения своей платформы NeMo с целью дальнейшей генерации текстов на английском языке силами системы искусственного интеллекта. Авторы книг упрекают компанию в использовании их произведений без разрешения. Иск подан от имени трёх авторов: Брайана Кина (Brian Keene), Абди Наземяна (Abdi Nazemian) и Стюарта О’Нэна (Stewart O’Nan), которые уличили Nvidia в использовании текстов их романов и новелл различных лет публикации без согласования с правообладателями. Сумма ущерба, которую пытаются взыскать истцы, не уточняется, но групповой характер иска подразумевает, что к претензиям могут присоединиться и прочие авторы из упоминаемой выборки, которую Nvidia использовала для обучения своей большой языковой модели. Это уже не первый иск такого рода, с которым приходится сталкиваться Nvidia, ранее компанию обвинило в неправомерном использовании своих материалов издание The New York Times. Аналогичные мотивы уже заставили некоторые организации обратиться в суд с иском не только на создавшую ChatGPT компанию OpenAI, но и финансирующую её Microsoft. Все ведущие большие языковые модели ИИ нарушают авторские права, а GPT-4 — больше всех
06.03.2024 [18:36],
Сергей Сурабекянц
Компания по изучению ИИ Patronus AI, основанная бывшими сотрудниками Meta✴, исследовала, как часто ведущие большие языковые модели (LLM) создают контент, нарушающий авторские права. Компания протестировала GPT-4 от OpenAI, Claude 2 от Anthropic, Llama 2 от Meta✴ и Mixtral от Mistral AI, сравнивая ответы моделей с текстами из популярных книг. «Лидером» стала модель GPT-4, которая в среднем на 44 % запросов выдавала текст, защищённый авторским правом. 
Источник изображений: Pixabay Одновременно с выпуском своего нового инструмента CopyrightCatcher компания Patronus AI опубликовала результаты теста, призванного продемонстрировать, как часто четыре ведущие модели ИИ отвечают на запросы пользователей, используя текст, защищённый авторским правом. Согласно исследованию, опубликованному Patronus AI, ни одна из популярных книг не застрахована от нарушения авторских прав со стороны ведущих моделей ИИ. «Мы обнаружили контент, защищённый авторским правом, во всех моделях, которые оценивали, как с открытым, так и закрытым исходным кодом», — сообщила Ребекка Цянь (Rebecca Qian), соучредитель и технический директор Patronus AI. Она отметила, что GPT-4 от OpenAI, возможно самая мощная и популярная модель, создаёт контент, защищённый авторским правом, в ответ на 44 % запросов. Patronus тестировала модели ИИ с использованием книг, защищённых авторскими правами в США, выбирая популярные названия из каталога Goodreads. Исследователи разработали 100 различных подсказок, которые можно счесть провокационными. В частности, они спрашивали модели о содержании первого абзаца книги и просили продолжить текст после цитаты из романа. Также модели должны были дополнять текст книг по их названию. Модель GPT-4 показала худшие результаты с точки зрения воспроизведения контента, защищённого авторским правом, и оказалась «менее осторожной», чем другие. На просьбу продолжить текст она в 60 % случаев выдавала целиком отрывки из книги, а первый абзац книги выводила в ответ на каждый четвёртый запрос. Claude 2 от Anthropic оказалось труднее обмануть — когда её просили продолжить текст, она выдавала контент, защищённый авторским правом, лишь в 16 % случаев, и ни разу не вернула в качестве ответа отрывок из начала книги. При этом Claude 2 сообщала исследователям, что является ИИ-помощником, не имеющим доступа к книгам, защищённым авторским правом, но в некоторых случаях всё же предоставила начальные строки романа или краткое изложение начала книги. Модель Mixtral от Mistral продолжала первый абзац книги в 38 % случаев, но только в 6 % случаев она продолжила фразу запроса отрывком из книги. Llama 2 от Meta✴ ответила контентом, защищённым авторским правом, на 10 % запросов первого абзаца и на 10 % запросов на завершение фразы. 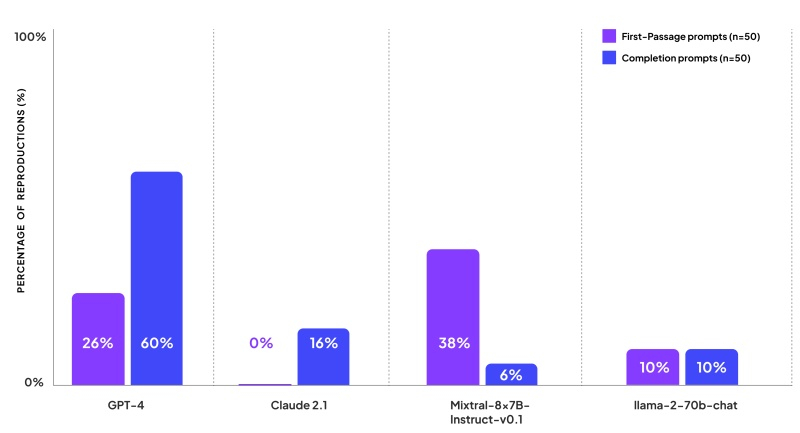
Источник изображения: Patronus AI «В целом, тот факт, что все языковые модели дословно создают контент, защищённый авторским правом, был действительно удивительным, — заявил Ананд Каннаппан (Anand Kannappan), соучредитель и генеральный директор Patronus AI, раньше работавший в Meta✴ Reality Labs. — Я думаю, когда мы впервые начали собирать это вместе, мы не осознавали, что будет относительно просто создать такой дословный контент». Результаты исследования наиболее актуальны на фоне обострения отношений между создателями моделей ИИ и издателями, авторами и художниками из-за использования материалов, защищённых авторским правом, для обучения LLM. Достаточно вспомнить громкий судебный процесс между The New York Times и OpenAI, который некоторые аналитики считают переломным моментом для отрасли. Многомиллиардный иск новостного агентства, поданный в декабре, требует привлечь Microsoft и OpenAI к ответственности за систематическое нарушение авторских прав издания при обучении моделей ИИ.  Позиция OpenAI заключается в том, что «поскольку авторское право сегодня распространяется практически на все виды человеческого выражения, включая сообщения в блогах, фотографии, сообщения на форумах, фрагменты программного кода и правительственные документы, было бы невозможно обучать сегодняшние ведущие модели ИИ без использования материалов, защищённых авторским правом». По мнению OpenAI, ограничение обучающих данных созданными более века назад книгами и рисунками, являющимися общественным достоянием, может стать интересным экспериментом, но не обеспечит системы ИИ, отвечающие потребностям настоящего и будущего. В ответ на обвинения в воровстве контента OpenAI обвинила New York Times во взломе ChatGPT
28.02.2024 [21:13],
Сергей Сурабекянц
OpenAI заявила в суде, что New York Times (NYT) «заплатила кому-то за взлом продуктов OpenAI», таких как ChatGPT, чтобы получить доказательства для подачи иска против OpenAI о нарушении авторских прав. OpenAI считает, что более ста примеров, в которых модель GPT-4 генерирует контент Times в качестве выходных данных не отражают обычного использования ChatGPT, а представляют собой «надуманные атаки наёмника», который добивался от чат-бота генерации фальшивого контента NYT. 
Источник изображения: pexels.com OpenAI обвинила NYT в «десятках тысяч попыток» получить эти «крайне аномальные результаты», «выявив и воспользовавшись ошибкой», которую сама OpenAI «стремится устранить». NYT якобы организовала эти атаки, чтобы собрать доказательства в поддержку утверждения, что продукты OpenAI ставят под угрозу журналистику, копируя авторские материалы и репортажи и тем самым отбирая аудиторию у NYT. «Вопреки утверждениям [содержащимся в жалобе NYT], ChatGPT никоим образом не заменяет подписку на The New York Times, — заявила OpenAI в ходатайстве, направленном на отклонение большинства претензий NYT. — В реальном мире люди не используют ChatGPT или любой другой продукт OpenAI для этой цели. И не могут. В обычном мире невозможно использовать ChatGPT для предоставления статей Times по своему желанию». 
Источник изображений: unsplash.com OpenAI отметила, что примеры в иске NYT цитируют не текущие материалы, которые подписчики Times могут прочитать на сайте Times, а гораздо более старые статьи, опубликованные до 2022 года. Это дополнительно ослабляет заявление NYT о том, что ChatGPT можно рассматривать как замену изданию. «То, что OpenAI ошибочно называет "хакерством", — это просто использование продуктов OpenAI для поиска доказательств воровства и воспроизведения материалов NYT, защищённых авторским правом. И это именно то, что мы нашли. На самом деле масштаб копирования OpenAI гораздо больше, чем сто примеров, изложенных в жалобе», — парировали адвокаты NYT. Юристы NYT сделали акцент на том, что OpenAI «не оспаривает и не может оспорить того, что они скопировали миллионы работ для создания и поддержки своих коммерческих продуктов без нашего разрешения». Позиция издания заключается в том, что создание новых продуктов не является оправданием для нарушения закона об авторском праве, и это именно то, что OpenAI сделала в беспрецедентных масштабах.  OpenAI заявила, что NYT в течение многих лет с энтузиазмом разрабатывала собственных чат-ботов, не опасаясь нарушения ими авторских прав. OpenAI сообщала об использовании статей NYT для обучения своих моделей ИИ ещё в 2020 году, но NYT обеспокоилась только после резко возросшей популярности ChatGPT в 2023 году. После этого NYT обвинила OpenAI в нарушении авторских прав и потребовала «коммерческих условий», а после нескольких месяцев обсуждений подала многомиллиардный иск. OpenAI убеждает суд, что ему следует отклонить иски, направленные на защиту прямого авторского права в цифровую эпоху и игнорировать обвинения в незаконном присвоении, которые компания называет «юридически недействительными». У некоторых жалоб истёк срок давности, другие, по утверждению OpenAI, неправильно трактуют добросовестное использование или искажают требования федеральных законов. Если это ходатайство OpenAI будет удовлетворено, в иске NYT останутся только претензии о косвенном нарушении авторских прав и размывании товарного знака. Но если NYT победит в суде (а вероятность этого не так уж мала), OpenAI, возможно, придётся буквально «стереть» ChatGPT и заново начать обучение моделей.  OpenAI утверждает, что NYT использовала вводящие в заблуждение подсказки, чтобы вынудить ChatGPT раскрыть обучающие данные. The Times якобы просила у чат-бота предоставить вступительный абзац конкретной статьи, а затем запрашивала «следующее предложение». Но даже эта тактика не поможет воссоздать статью целиком, а скорее выведет набор «разрозненных и неупорядоченных цитат». OpenAI считает, что NYT намеренно вводит суд в заблуждение, используя купюры и многоточие, чтобы скрыть порядок, в котором ChatGPT выдавал фрагменты репортажей, что создаёт ложное впечатление, что ChatGPT выводит последовательные и непрерывные копии статей.  OpenAI также отвергла примеры галлюцинаций ИИ предоставленных NYT, где модели ИИ изобретали на первый взгляд реалистичные статьи, которые содержали неверные факты и никогда не публиковались изданием. Поскольку ни одна из ссылок в этих фиктивных статьях не работала, OpenAI считает, что «любой пользователь, получивший такие выходные данные, сразу же распознает в них галлюцинацию». OpenAI планирует исправить ошибки ИИ, но это будет возможно сделать только в случае победы в суде. OpenAI необходимо убедить суды во многих юрисдикциях в своей теории добросовестного использования текстов, защищённых авторским правом, что имеет решающее значение для развития её моделей ИИ. «Постоянная задача разработки ИИ — свести к минимуму и в конечном итоге устранить галлюцинации, в том числе за счёт использования более полных наборов обучающих данных для улучшения точности моделей», — заявили в OpenAI. Адвокаты NYT полагают, что для OpenAI «незаконное копирование и дезинформация являются основными особенностями их продуктов, а не результатом маргинального поведения». По их словам, OpenAI «отслеживает запросы и результаты пользователей, что особенно удивительно, учитывая, что они утверждали, что не делают этого. Мы с нетерпением ждём возможности изучить эту проблему».  Разработчики больших языковых моделей всё чаще прибегают к лицензированию вместо обучения на общедоступных данных, чтобы избежать возможных обвинений в нарушении авторских прав. «Разработка технологий в соответствии с установленными законами об авторском праве является общеотраслевым приоритетом, — считает ведущий советник NYT Ян Кросби (Ian Crosby). — Решение OpenAI и других разработчиков генеративного ИИ заключать сделки с издателями новостей только подтверждает, что они знают, что их несанкционированное использование работ, защищённых авторским правом, далеко не справедливо». Гильдия актёров США заключила соглашение, по которому для озвучки игр можно использовать синтезированные ИИ голоса
11.01.2024 [07:52],
Алексей Разин
Одна из возможностей, которую открыли человечеству системы искусственного интеллекта — это исполнение любой песни или озвучание любого персонажа голосом известного артиста без его ведома и участия. Само собой, подобная практика быстро насторожила профессиональные объединения актёров и музыкальных исполнителей, которые привыкли получать доходы от использования своего голоса. На днях в этой сфере была заключена необычная сделка. 
Источник изображения: Unsplash, Jacek Dylag По данным CNet, на выставке CES 2024 в Лас-Вегасе крупнейший мировой профсоюз в данной сфере SAG-AFTRA (Гильдия киноактеров и Американская федерация артистов телевидения и радио) объявил о достижении соглашения с компанией Replica Studios, которая использует технологии искусственного интеллекта для имитации голоса актёров и музыкальных исполнителей. По условиям сделки, члены SAG-AFTRA смогут работать с Replica Studios, чтобы лицензировать свой голос для игровых студий. Таким образом, впервые в этой сфере подобная практика закрепляется официальным соглашением юридически. В прошлом году в США проходила длительная забастовка представителей кино- и телевизионной индустрии, которые протестовали против использования искусственного интеллекта для написания сценариев и использования цифровых двойников актёров в этой сфере. В результате этих протестов было принято положение, согласно которому студии должны спрашивать разрешение у актёров на использование «цифровых дубликатов» их внешности и платить им за это. SAG-AFTRA объединяет более 160 000 актёров, музыкантов и певцов, поэтому интересы многих представителей отрасли будут учитываться в рамках соглашения с Replica Studios. Дункан Крэбтри-Иреланд (Duncan Crabtree-Ireland), главный переговорщик от профсоюза, заявил, что соглашение «открывает путь для профессиональных артистов озвучивания к новым возможностям трудоустройства их цифровых голосовых реплик». В соглашении есть положения о минимальных расценках, безопасном хранении и требованиях к обозначению сгенерированного контента, а также «ограничения по количеству времени, в течение которого реплика может быть использована без дополнительной оплаты и согласия». При этом представитель профсоюза отметил, что соглашение не распространяется на использование голосов артистов для обучения больших языковых моделей Однако полностью проблему незаконного использования голосов артистов новое соглашение не решит. Оно никак не запрещает частным создателям контента использовать имитацию голоса известного артиста в своих произведениях. Что характерно, ещё в январе прошлого года звукозаписывающие студии были убеждены, что им не нужно разрешение артистов на использование цифровых реплик их голосов. За прошедший год настроение представителей отрасли изменилось, о чём свидетельствует заключённое на CES 2024 соглашение. Хотя это соглашение касается именно видеоигр, Крэбтри-Иреланд говорит, что могут быть достигнуты и другие соглашения по другим видам деятельности, например, в музыке и телевизионной рекламе. Также в подобном соглашении могут быть заинтересованы правообладатели, которым достались права на произведения покойных артистов, и они хотели бы претендовать на выплаты со стороны студий, использующих копии голоса покойных исполнителей в своих произведениях. OpenAI признала использование авторских материалов без разрешения владельцев, но есть нюанс
10.01.2024 [11:13],
Дмитрий Федоров
В своём недавнем обращении к Комитету Палаты лордов парламента Великобритании по вопросам коммуникаций и цифровых технологий (Communications and Digital Committee) компания OpenAI, разработчик чат-бота ChatGPT, подчеркнула неизбежность использования защищённых авторским правом материалов в процессе создания эффективных ИИ-моделей. На первый взгляд, кажется, что использование материалов без разрешения владельца противоречит основам защиты интеллектуальной собственности, но позиция OpenAI основана на сложных юридических и технических нюансах. 
Источник изображения: sergeitokmakov / Pixabay По мнению OpenAI, ограничение исходных данных для обучения ИИ-моделей исключительно произведениями, являющимися общественным достоянием и созданными более ста лет назад, значительно сокращает возможности интеллектуальных систем. Современный ИИ наподобие ChatGPT требует доступа к широкому спектру человеческих выражений — от блогов и фотографий до форумных сообщений и фрагментов программного кода. Такой подход не только способствует обучению ИИ пониманию разнообразных форм коммуникации, но и обеспечивает его актуальность в условиях стремительно меняющегося цифрового мира. В центре защиты OpenAI лежит принцип добросовестного использования, который, согласно заявлениям компании, допускает ограниченное использование авторских материалов без согласия владельцев. Этот юридический принцип, имеющий глубокие корни в американском законодательстве, предоставляет определённый простор для инноваций и исследований. OpenAI уверяет, что её методы обучения ИИ соответствуют этому принципу, подчёркивая, что такой подход не только справедлив по отношению к авторам, но и критически важен для поддержания конкурентоспособности США в области высоких технологий. Причиной этого заявления OpenAI послужил иск, поданный The New York Times. В нём газета обвинила OpenAI и Microsoft, одного из ключевых инвесторов OpenAI, в незаконном использовании своих новостных материалов для обучения ИИ-моделей. В ответ на эти обвинения OpenAI заявила, что иск не имеет под собой оснований. Компания также выразила свою поддержку журналистике и стремление к сотрудничеству с новостными ресурсами, подчеркнув свою приверженность этическим принципам в разработке ИИ. Это не первый случай, когда OpenAI сталкивается с подобными обвинениями. Ранее компания уже защищала своё право на использование общедоступных материалов в рамках принципа добросовестного использования в ответ на судебный иск, связанный с мемуарами Сары Сильверман (Sarah Silverman). В то время OpenAI заявляла, что критики ошибочно трактуют сферу действия авторских прав, не учитывая законных исключений и ограничений, которые допускают инновации вроде разработки передовых ИИ-моделей. Писатели обвинили OpenAI и Microsoft в краже интеллектуальной собственности для обучения ИИ
07.01.2024 [10:46],
Дмитрий Федоров
Писатели Николас Басбейнс (Nicholas Basbanes) и Николас Гейдж (Nicholas Gage) подали иск в Манхэттенский федеральный суд против Microsoft и OpenAI. Они обвиняют компании в использовании их литературных произведений без согласия авторов для обучения ИИ-моделей, включая семейство GPT. 
Источник изображения: Daniel_B_photos / Pixabay В новом коллективном иске, поданном в пятницу, упоминаются Microsoft и OpenAI — компании, стоящие за разработкой передовых ИИ-моделей. Писатели заявляют, что их произведения были незаконно использованы для обучения ИИ-моделей, ставших основой бизнес-империи, оцениваемой в миллиарды долларов. Также писатели утверждают, что Microsoft и OpenAI занимались массовым и преднамеренным воровством произведений, защищённых авторским правом. Это новый этап в ряде судебных исков, поданных в ноябре прошлого года. Тогда писатель Джулиан Сэнктон (Julian Sancton) стал первым, кто подал иск сразу против обеих компаний. В нём указывалось, что Microsoft является крупным инвестором OpenAI и использует технологии последней для своего продукта Copilot, что подчёркивает взаимосвязанность обеих технологических компаний. Газета The New York Times также недавно подала судебный иск против Microsoft и OpenAI, утверждая, что её новостные материалы использовались для обучения ИИ-моделей без разрешения или какой-либо компенсации. По словам издания, ИИ-инструменты могут генерировать тексты, которые дословно повторяют, тщательно обобщают и даже имитируют выразительный стиль её материалов. Несмотря на возрастающую волну исков, не все новостные издания выступают против того, чтобы их материалы использовались для обучения ИИ. Например, Associated Press предоставила OpenAI доступ к своим новостным материалам на ближайшие два года для обучения ИИ-моделей, а Politico и Business Insider также заключили с компанией сделки на использование контента с их сайтов для обучения ИИ. Эти судебные иски отражают глубокую проблематику баланса между инновациями и уважением к авторским правам. Они выявляют необходимость чётких правил и этических стандартов в использовании интеллектуальной собственности для развития передовых технологий. OpenAI запустила программу защиты бизнес-клиентов от исков по авторскому праву
07.11.2023 [05:55],
Дмитрий Федоров
Компания OpenAI объявила о запуске программы Copyright Shield. Эта инициатива направлена на защиту бизнес-клиентов от возможных исков, связанных с нарушением авторских прав при использовании продуктов OpenAI. В рамках этой программы OpenAI возьмёт на себя оплату юридических издержек клиентов, использующих общедоступные инструменты её платформы для разработчиков, а также коммерческую версию чат-бота ChatGPT Enterprise. 
Источник изображения: Tumisu / Pixabay Программа Copyright Shield охватывает клиентов, использующих платформу разработчиков OpenAI и ChatGPT Enterprise — коммерческую версию их ИИ-чатбота. Однако, стоит отметить, что защита не распространяется на бесплатные и Plus-версии ChatGPT, а также пока неясно, предусматривает ли эта программа защиту от претензий, связанных с данными для обучения, использованными в генеративных ИИ-моделях компании. Генеративные модели ИИ, такие как ChatGPT, GPT-4 и DALL-E 3, обучаются на огромных массивах данных, включая книги, произведения искусства, электронные письма, песни и аудиозаписи. Большая часть этих данных поступает с публичных ресурсов, и, хотя некоторые из них относятся к общественному достоянию, другие защищены авторским правом или имеют ограничительные лицензии. Вопросы законности обучения ИИ на таких данных в настоящее время активно обсуждаются в судебных инстанциях. Проблемы могут возникнуть, когда модель ИИ воспроизводит точные фрагменты данных, на которых она была обучена, что потенциально может привести к нарушению авторских прав. Опросы, проведённые среди крупных компаний и разработчиков, показывают, что вопросы интеллектуальной собственности являются ключевой проблемой при использовании технологий генеративного ИИ. Крупные игроки в сфере технологий, такие как IBM, Microsoft, Amazon, а также фотостоки Getty Images, Shutterstock и Adobe, уже заявили о готовности защищать своих клиентов от исков, связанных с интеллектуальной собственностью. Теперь к их числу присоединилась и OpenAI, что может стать сигналом для всей отрасли о необходимости разработки подобных механизмов защиты пользователей. Google пообещала защитить пользователей генеративного ИИ от исков за нарушение авторских прав
13.10.2023 [13:08],
Дмитрий Федоров
Google объявила о готовности взять на себя юридическую защиту пользователей своих продуктов, использующих генеративный ИИ, в случае судебных исков, связанных с нарушением авторских прав. Такой шаг компании направлен на снижение опасений пользователей в части возможных юридических последствий от использования данной технологии. 
Источник изображения: sergeitokmakov / Pixabay Было отмечено 7 продуктов, попадающих под защиту: Duet AI в Workspace (включая текст, созданный в Google Docs и Gmail, а также изображения в Google Slides и Google Meet), Duet AI в Google Cloud, Vertex AI Search, Vertex AI Conversation, Vertex AI Text Embedding API, Visual Captioning на Vertex AI и Codey APIs. Вместе с тем, инструмент Bard Search не был включён в этот список. «Если вам будут предъявлены претензии по поводу авторских прав, мы возьмём на себя связанные с этим потенциальные юридические риски», — говорится в заявлении компании. Google подчеркнула, что подобная практика не является чем-то новым. Тем не менее, компания признала, что её пользователи хотели получить чёткое уточнение, что защита распространяется на возможное включение данных, защищённых авторским правом, в обучающие данные для ИИ-моделей Google. Также Google предоставит защиту пользователям в случае исков, связанных с результатами, полученными в результате использования её базовых ИИ-моделей. Например, если пользователь сгенерирует предложение, схожее с ранее опубликованным. Однако, компания подчеркнула, что такая защита будет действовать только в том случае, если пользователь не пытался намеренно создать или использовать сгенерированный контент для нарушения прав других лиц. Не только Google, но и другие крупные технологические компании, такие как Microsoft и Adobe, сделали похожие заявления о юридической защите своих пользователей. Microsoft обещает защиту корпоративным пользователям своих продуктов Copilot, в то время как Adobe заявляет о защите клиентов, использующих Firefly, от исков по вопросам авторских прав. Вопросы авторского права продолжают активно обсуждаться в сфере генеративного ИИ, и на сегодняшний день подано большое количество исков против различных компаний за нарушение ими авторских прав. Более того, Google уже столкнулась с коллективным иском за использование личной информации пользователей и данных, защищённых авторскими правами, для обучения своих ИИ-моделей. На постере второго сезона «Локи» нашли следы ИИ — это всполошило дизайнеров и выявило проблему у Shutterstock
09.10.2023 [19:53],
Сергей Сурабекянц
Рекламный постер второго сезона сериала «Локи» на Disney Plus вызвал у профессиональных дизайнеров подозрения, что его создали с помощью генеративного ИИ. Творческое сообщество обеспокоено тем, что ИИ-генераторы изображений обучаются без согласия авторов и могут быть использованы для замены людей-художников. Ранее Disney обвиняли в использовании ИИ в сериале «Секретное вторжение», хотя студия утверждала, что это не уменьшило роли реальных дизайнеров. 
Источник изображений: Disney / Marvel В X появились сообщения, утверждающие, что фон на постере сериала был взят из стокового изображения на Shutterstock под названием «Сюрреалистическая бесконечность, спираль времени, космический антиквариат». Иллюстратор Катрия Раден (Katria Raden) считает, что изображение спиралевидных часов на заднем плане имеет «явные признаки ИИ, как будто вещи случайно превращаются в бессмысленные закорючки», похожие на артефакты, присущие ИИ-изображениям. Эксперты предполагают, что миниатюрные персонажи, окружающие Локи, тоже сгенерированы с помощью ИИ. Стоковые изображения, сгенерированные ИИ, становятся настоящей проблемой для многих творческих профессионалов. Как отмечает Раден: «Лицензирование фотографий и иллюстраций на стоковых сайтах было способом, которым многие трудолюбивые художники зарабатывали на жизнь. Я не думаю, что замена их изображениями, созданными с помощью технологий, основанных на массовой эксплуатации и воровстве заработной платы, более этична, чем замена собственных сотрудников Disney». Исходное изображение, использованное в постере, было опубликовано на Shutterstock в этом году, что исключает возможность, что оно создано до наступления бума ИИ. К тому же файл не содержит встроенных метаданных о процессе создания и авторе. Несколько программ проверки изображений также пометили его как созданное ИИ. Сама Shutterstock не пометила изображение, как созданное ИИ, но продвигает его как «лучший выбор», пользующийся большим спросом. 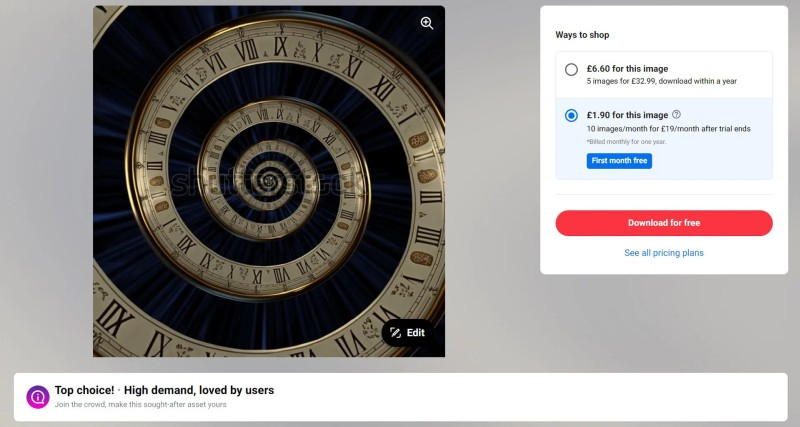
Источник изображения: Shutterstcok / Svarun На изображении видны визуальные ошибки, такие как размытые буквы и «бессмысленные закорючки», что позволяет предположить, что фон был создан с использованием ИИ. 
Источник изображения: Disney / Marvel / The Verge Многие другие изображения, загруженные на Shutterstock тем же автором, также кажутся сгенерированными искусственным интеллектом, хотя и не помечены как таковые. 
Источник изображения: Shutterstcok / Svarun Shutterstock лицензирует только те ИИ-изображения, которые созданы с использованием собственного генеративного ИИ-инструмента платформы, получая интеллектуальные права на весь представленный контент. Shutterstock гарантирует, что стоковые изображения, сгенерированные ИИ явно и чётко обозначены на платформе и безопасны для коммерческого использования, поскольку они обучены на собственной библиотеке Shutterstock. Поскольку данное изображение не было отмечено, как созданное ИИ, Shutterstock, видимо, посчитала его плодом творчества живого художника. Сама компания пока не прокомментировала создавшуюся ситуацию. Другие компании, например, Adobe и Getty Image, также в настоящее время активно пытаются коммерциализировать контент, созданный ИИ, но пока неясно, насколько хорошо эти платформы модерируют материалы, не соблюдающие их правила для создателей. Disney не ответила на вопрос журналистов, использовался ли ИИ в рекламном постере сериала «Локи» и не предоставила данных о лицензировании изображения. Возможно, поскольку оно не было помечено Shutterstock как созданное ИИ, Disney могла и не знать о его происхождении. Тем не менее, большинство специалистов легко замечают артефакты, присущие сгенерированным ИИ изображениям, и вряд ли использование такого контента является хорошим решением для процесса дизайна Disney. 
Источник изображения: Apple / Disney / Marvel За последний год творческая индустрия насытилась инструментами на базе ИИ, такими как Adobe Firefly и Canva Magic Studio. Они призваны облегчить работу неопытным дизайнерам и обычно используются для быстрого и дешёвого производства контента в больших масштабах. Медиа-компании всё чаще используют сгенерированные ИИ изображения из-за их доступности и быстроты создания. Легко понять, почему творческие профессионалы обеспокоены будущим своей отрасли. Джордж Мартин и другие писатели подали в суд на создателя ChatGPT за нарушение авторских прав
20.09.2023 [19:53],
Сергей Сурабекянц
Все больше авторов присоединяются к иску против OpenAI за нарушение авторских прав путём использования их книг для обучения больших языковых моделей искусственного интеллекта. Гильдия авторов и 17 известных писателей, среди которых Джонатан Франзен (Jonathan Franzen), Джон Гришэм (John Grisham), Джордж Р. Р. Мартин (George R.R. Martin) и Джоди Пиколт (Jodi Picoult), подали в суд Южного округа Нью-Йорка жалобу, которая, как они надеются, будет классифицирована как групповой иск. 
Источник изображений: Pixabay Согласно жалобе, OpenAI «копировала работы истцов оптом, без разрешения и рассмотрения» и использовала защищённые авторским правом материалы для обучения больших языковых моделей. «Заработок авторов зависит от произведений, которые они создают. Но большие языковые модели Ответчика ставят под угрозу способность писателей-фантастов зарабатывать на жизнь, поскольку позволяют любому создавать — автоматически и бесплатно (или очень дёшево) — текст, за создание которого в противном случае он заплатил бы писателям», — говорится в иске. Авторы добавили, что использование ИИ OpenAI для написания книг может привести к созданию производных работ, «которые основаны на их книгах, имитируют, обобщают или перефразируют». OpenAI, говорится в жалобе, могла бы обучить свою большую языковую модель на произведениях, находящихся в общественном достоянии, вместо того, чтобы использовать материалы, защищённые авторским правом, без уплаты лицензионного сбора.  Это уже не первый иск против OpenAI от популярных авторов о нарушении авторских прав. Писатель Майкл Чабон (Michael Chabon) совместно с несколькими другими авторами подали в суд на компанию за использование их книг для обучения ИИ в начале сентября. Комик Сара Сильверман (Sarah Silverman) и авторы Кристофер Голден (Christopher Golden) и Ричард Кадри (Richard Kadrey) подали иск сразу против OpenAI и Meta✴, а Пол Трембле (Paul Tremblay) и Мона Авад (Mona Awad) подали аналогичную жалобу ещё в июне. Компаниям, занимающимся генеративным ИИ, пришлось столкнуться с сопротивлением со стороны владельцев авторских прав, при этом иски также были поданы против платформ генерации изображений при помощи ИИ. Microsoft, финансирующая OpenAI, объявила, что берёт на себя юридическую защиту коммерческих пользователей её сервиса Copilot AI, если на них подадут в суд за нарушение авторских прав. YouTube будет оплачивать правообладателям использование музыки для обучения ИИ
21.08.2023 [18:32],
Сергей Сурабекянц
YouTube оптимистично оценивает потенциал ИИ для «расширения уникального творческого самовыражения», но приложит все усилия, чтобы обеспечить защиту авторских прав. С этой целью компания запускает «инкубатор музыкального ИИ YouTube», для сотрудничества с артистами, авторами песен и продюсерами. Для запуска этой программы YouTube заручилась поддержкой Universal Music Group (UMG), обладающей правами на множество музыкальных произведений. 
Источник изображения: Pixabay UMG не спешит использовать ИИ. Ранее в этом году компания попросила потоковые сервисы, такие как Spotify, запретить использовать её музыку для обучения моделей ИИ. UMG также предупреждала о нарушении авторских прав в видеороликах YouTube, созданных ИИ, в которых использовались работы её артистов. Когда песня, созданная ИИ на основе вокала Дрейка и The Weeknd, стала вирусной, UMG потребовала удалить её из Spotify и Apple Music. Претензии UMG заключаются в том, что музыкальные произведения, созданные людьми и защищённые авторскими правами, используются для обучения моделей ИИ, которые затем генерируют новые произведения без надлежащего разрешения или компенсации. Поэтому UMG объединилась с YouTube, чтобы разработать некую структуру, обеспечивающую выплату вознаграждения правообладателям. YouTube подчеркнула своё историческое понимание ситуации, ведь на протяжении многих лет компания, по её утверждению, «делала огромные инвестиции в системы, которые помогают сбалансировать интересы правообладателей с интересами творческого сообщества на YouTube». Компания привела в пример свою систему Content ID, которая обеспечивает оплату правообладателям за использование их контента на платформе и предположила, что подобная система сможет применяться для ИИ-музыки, по крайней мере, для тех «музыкальных партнёров, которые решат участвовать». Приоритетом для полноценной работы такой системы являются доверие и безопасность. Компания уже разработала политики в отношении манипуляций с контентом, вводящим зрителей в заблуждение. Необходимо гарантировать, что генеративный ИИ не будет использоваться для нарушения авторских прав, дезинформации и спама. Наоборот, YouTube планирует использовать технологии ИИ для идентификации такого рода контента. «Я невероятно взволнован возможностью ИИ стимулировать творчество во всём мире, но признаю, что YouTube и перспективы ИИ будут успешными только в том случае, если наши партнёры будут успешными, — заявил генеральный директор YouTube Нил Мохан (Neal Mohan). — Вместе мы можем использовать эту новую технологию, чтобы она поддерживала артистов, авторов песен, продюсеров и индустрию в целом, повышая ценность для фанатов и расширяя границы творческих возможностей». YouTube пообещала в ближайшем будущем подробно рассказать о том, как будет работать новая система для ИИ-музыки с точки зрения конкретных технологий, возможностей монетизации и политики защиты авторских прав. Фильм «Тетрис» оказался в центре скандала: писатель обвинил компании Apple и Tetris в нарушении его авторских прав
10.08.2023 [08:39],
Дмитрий Федоров
Главный редактор технологического новостного портала Gizmodo, Дэн Акерман (Dan Ackerman), подал иск в федеральный суд Манхэттена, утверждая, что Apple и компания Tetris использовали материалы из его книги о культовой игре «Тетрис» (Tetris) для создания фильма без его разрешения. 
Источник изображения: Apple Дэн Акерман в 2016 году отправил свою книгу «Эффект „Тетриса“: Игра, которая загипнотизировала мир» компании Tetris. Он утверждает, что компания не только скопировала материалы из книги для создания фильма, но и угрожала ему судебным иском, если он решит создать свои киноверсии или телевизионные проекты на основе собственной книги. Фильм «Тетрис» был представлен на платформе Apple TV в марте. Акерман требует компенсацию в размере не менее 6 % бюджета фильма, составляющего $80 млн. Адвокат Акермана, Кевин Ландо (Kevin Landau), заявил, что целью иска является восстановление справедливости и уважения к труду и правам автора. Представители Apple и компании Tetris пока не дали комментариев по этому поводу. Книга Акермана «Эффект „Тетриса“: Игра, которая загипнотизировала мир» была опубликована в 2016 году. В ней рассказывается об истории этой популярной головоломки и борьбе за её мировые лицензионные права, которую автор описывает как «триллер времён Холодной войны с политическим интриганством». По словам Акермана, ещё до публикации книги он отправил её предварительный экземпляр компании Tetris. Однако компания отказалась предоставить лицензию на свою интеллектуальную собственность для проектов, связанных с книгой, и даже отправила автору решительное письмо с требованием всё прекратить. В жалобе указано, что с 2017 года генеральный директор компании Майя Роджерс (Maya Rogers) и сценарист Ноа Пинк (Noah Pink) начали использовать материалы книги для сценария фильма. Акерман утверждает, что фильм заимствовал множество конкретных разделов и событий из его книги. Акерман обвиняет Apple и компанию Tetris в нарушении авторских прав, недобросовестной конкуренции и незаконном вмешательстве в его деловые отношения. Этот случай ставит под сомнение вопросы о защите интеллектуальной собственности в эпоху цифровых технологий и подчёркивает важность уважения к авторским правам в индустрии развлечений. Крупные издательства объединятся для противодействия ИИ
30.06.2023 [11:09],
Владимир Мироненко
В настоящее время ряд крупных издательств новостных ресурсов и журналов обсуждают создание коалиции для решения проблемы влияния искусственного интеллекта на отрасль, сообщила газета The Wall Street Journal со ссылкой на свои источники. Переговоры находятся на ранней стадии, и задачи будущей коалиции пока не определены. Источники допускают, что из-за различия в приоритетах стороны так и не смогут договориться о совместной защите своих интересов. 
Источник изображения: Pixabay В числе участников обсуждения создания группы источники называют New York Times, News Corp, владеющую The Wall Street Journal, а также Barron's, MarketWatch и новостными агентствами в Великобритании и Австралии, Vox Media, Advance, владеющую Condé Nast, владельца Politico и Insider Акселя Спрингера (Axel Springer) и IAC, родительскую компанию Dotdash Meredith. Сотрудничество между конкурирующими крупными издателями случается крайне редко, и их переговоры свидетельствуют о том, что генеративный ИИ представляет собой значительную угрозу как для отрасли, так и для общества, отметила The Wall Street Journal. Впрочем, различие в приоритетах может стать препятствием при формировании повестки дня и объединении издательств в единую группу. Особую озабоченность у издательств вызывает то, что генеративный ИИ, способный создавать различные типы контента, включая тексты, изображения и аудио, предоставляют информацию непосредственно пользователям, устраняя необходимость переходить по ссылкам на источники информации. Поэтому у издательств возникли вопросы, каким образом они смогут получать компенсацию за использование их контента при обучении больших языковых моделей (LLM) и каковы их юридические возможности в защите своих авторских прав. Председатель IAC Барри Диллер (Barry Diller) на недавнем отраслевом мероприятии заявил, что в некоторых случаях использования текста и изображений, доступных онлайн, для обучения инструментов искусственного интеллекта издатели должны «немедленно начать действовать и обязательно инициировать судебный процесс». Гендиректор News Corp Роберт Томсон (Robert Thomson) предупредил, что интеллектуальная собственность находится под угрозой из-за распространения ИИ. Он отметил, что контент, публикуемый издательствами, собирается, накапливается и используется для обучения ИИ. Он может появляться в отдельных поисках, а также «будет синтезирован и представлен как уникальный, тогда как на самом деле представляет собой выжимку из редакционной статьи». Следует отметить, что ещё до того, как ИИ набрал популярность, издатели пытались получить компенсацию за использование их контента технологическими платформами, но делали это порознь. Например, News Corp и Times заключили крупные сделки по этому поводу с Google, входящей в холдинг Alphabet. В ответ на критику Сэм Альтман (Sam Altman), гендиректор OpenAI, создавшей ИИ-чат-бот ChatGPT, ранее заявил, что компания придерживается практики добросовестного использования контента, что не требует разрешения объекта авторского права. Adobe пообещала компенсацию, если её ИИ для генерации картинок Firefly нарушит чьи-то авторские права
08.06.2023 [18:55],
Сергей Сурабекянц
Компания Adobe представила расширение Firefly на основе генеративного ИИ для корпоративных пользователей. «Предложение включает полную компенсацию за контент, созданный с помощью этого инструмента», — утверждает Клод Александр (Claude Alexandre), вице-президент по цифровым медиа Adobe. Компания уверена в способности своего ИИ уважать защищённые авторским правом изображения и выплатит компенсацию своим клиентам, если им будет предъявлен иск за нарушение авторских прав в отношении любых изображений, созданных при помощи Firefly. 
Источник изображения: Adobe «Все, что создано с помощью инструмента Firefly для преобразования текста в изображение будет полностью возмещено компанией как доказательство того, что мы поддерживаем коммерческую безопасность и готовность ИИ-функций», — добавил Александр. Стандарты генеративного ИИ и авторского права ещё не урегулированы юридически, что заставляет компании воздерживаться от использования ИИ в своих бизнес-операциях. Александр надеется, что решение Adobe внесёт ясность. Модель Firefly обучается на стоковых изображениях, права на которые принадлежат Adobe, а также на контенте с открытой лицензией (например, изображения Creative Commons) и контенте, являющемся общественным достоянием. «Adobe уже довольно давно предлагает компенсацию за использование собственных продуктов, в частности за стоковые изображения», — отметил Александр. Предложение будет доступно только для корпоративных клиентов, и Adobe отказалась сообщить, сколько она выделила средств для возможных судебных разбирательств. Также компания не разъяснила, означает ли возмещение убытков при использовании Firefly, что иск в случае нарушения авторских прав нужно подавать напрямую к Adobe, а не к пользователю Firefly. Исследователь прав интеллектуальной собственности Андрес Гуадамуз (Andres Guadamuz) уверен, что обещание Adobe не следует воспринимать легкомысленно: «У них должны быть очень серьёзные гарантии от их юристов. Adobe утверждает, что Firefly была обучена на полностью законных исходных данных. Они провели тщательное исследование своих источников обучения и уверены, что на них не подадут в суд». Adobe надеется, что гарантия возмещения убытков придаст компаниям уверенности в развёртывании генеративных инструментов ИИ в их бизнесе. Пока неясно, как создатели стоковых изображений, используемых для обучения Firefly, получат компенсацию за свою работу. Adobe сообщила, что разрабатывает модель вознаграждения для участников Adobe Stock на основе «этичного и ответственного» подхода и поделится подробностями, когда Firefly выйдет из статуса бета-версии. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться