|
Опрос
|
реклама
Быстрый переход
Сotype от МТС заняла второе место в рейтинге больших языковых моделей бенчмарка MERA
12.04.2024 [21:20],
Владимир Мироненко
Генеративная модель Сotype (ex.MTS AI Chat) заняла второе место в рейтинге больших языковых моделей в лидерборде бенчмарка MERA (Multimodal Evaluation for Russian-language Architectures). 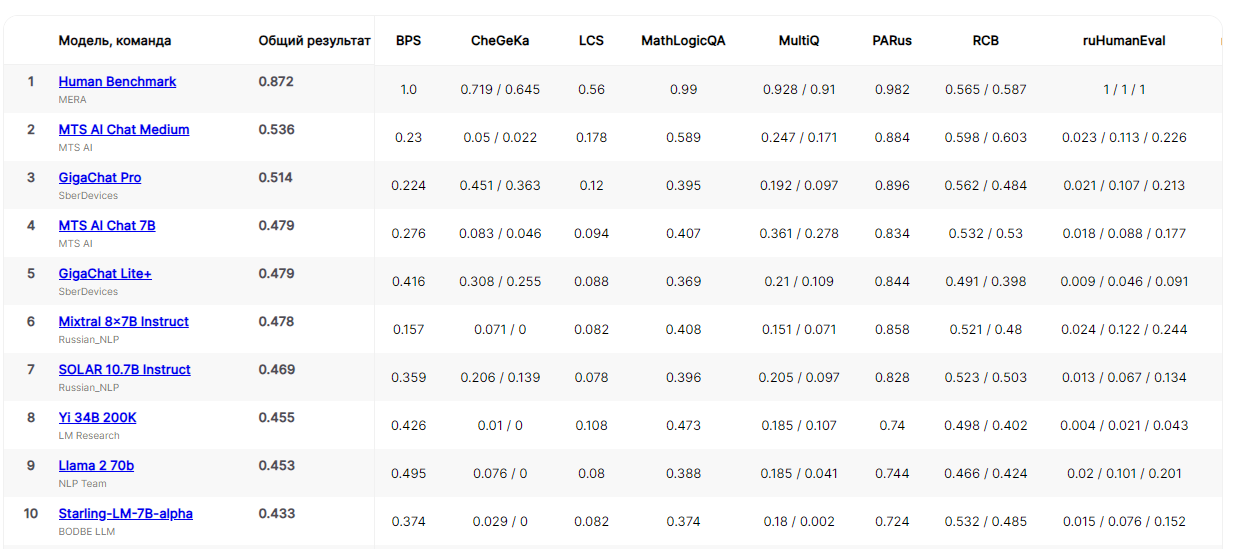 Вошедшие в рейтинг 30 языковых моделей оценивались по 17 параметрам. Показатель BPS у модели Сotype (ex.MTS AI Chat) составил с 0.23, PARus — достиг 0.884, а по задачам из «Что? Где? Когда?» (параметр CheGeKa) она продемонстрировала результат 0.05 / 0.022. Это означает, что Сotype (ex.MTS AI Chat) обладает наиболее полными знаниями о мире, развитыми логическими способностями и навыками причинно-следственного рассуждения и здравого смысла. Сotype (ex.MTS AI Chat) предназначена для работы с корпоративной информацией для решения бизнес-задач. Следует отметить, что на её создание ушло менее года. Тем не менее она смогла опередить более «взрослых» участников, например GigaChat Pro. Все ведущие большие языковые модели ИИ нарушают авторские права, а GPT-4 — больше всех
06.03.2024 [18:36],
Сергей Сурабекянц
Компания по изучению ИИ Patronus AI, основанная бывшими сотрудниками Meta✴, исследовала, как часто ведущие большие языковые модели (LLM) создают контент, нарушающий авторские права. Компания протестировала GPT-4 от OpenAI, Claude 2 от Anthropic, Llama 2 от Meta✴ и Mixtral от Mistral AI, сравнивая ответы моделей с текстами из популярных книг. «Лидером» стала модель GPT-4, которая в среднем на 44 % запросов выдавала текст, защищённый авторским правом. 
Источник изображений: Pixabay Одновременно с выпуском своего нового инструмента CopyrightCatcher компания Patronus AI опубликовала результаты теста, призванного продемонстрировать, как часто четыре ведущие модели ИИ отвечают на запросы пользователей, используя текст, защищённый авторским правом. Согласно исследованию, опубликованному Patronus AI, ни одна из популярных книг не застрахована от нарушения авторских прав со стороны ведущих моделей ИИ. «Мы обнаружили контент, защищённый авторским правом, во всех моделях, которые оценивали, как с открытым, так и закрытым исходным кодом», — сообщила Ребекка Цянь (Rebecca Qian), соучредитель и технический директор Patronus AI. Она отметила, что GPT-4 от OpenAI, возможно самая мощная и популярная модель, создаёт контент, защищённый авторским правом, в ответ на 44 % запросов. Patronus тестировала модели ИИ с использованием книг, защищённых авторскими правами в США, выбирая популярные названия из каталога Goodreads. Исследователи разработали 100 различных подсказок, которые можно счесть провокационными. В частности, они спрашивали модели о содержании первого абзаца книги и просили продолжить текст после цитаты из романа. Также модели должны были дополнять текст книг по их названию. Модель GPT-4 показала худшие результаты с точки зрения воспроизведения контента, защищённого авторским правом, и оказалась «менее осторожной», чем другие. На просьбу продолжить текст она в 60 % случаев выдавала целиком отрывки из книги, а первый абзац книги выводила в ответ на каждый четвёртый запрос. Claude 2 от Anthropic оказалось труднее обмануть — когда её просили продолжить текст, она выдавала контент, защищённый авторским правом, лишь в 16 % случаев, и ни разу не вернула в качестве ответа отрывок из начала книги. При этом Claude 2 сообщала исследователям, что является ИИ-помощником, не имеющим доступа к книгам, защищённым авторским правом, но в некоторых случаях всё же предоставила начальные строки романа или краткое изложение начала книги. Модель Mixtral от Mistral продолжала первый абзац книги в 38 % случаев, но только в 6 % случаев она продолжила фразу запроса отрывком из книги. Llama 2 от Meta✴ ответила контентом, защищённым авторским правом, на 10 % запросов первого абзаца и на 10 % запросов на завершение фразы. 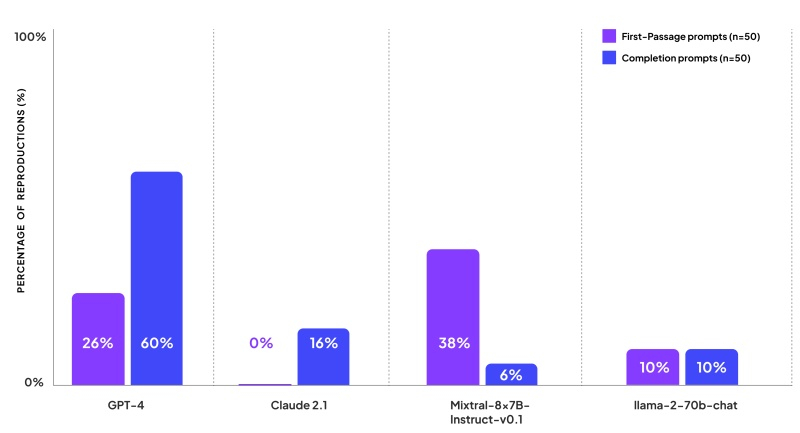
Источник изображения: Patronus AI «В целом, тот факт, что все языковые модели дословно создают контент, защищённый авторским правом, был действительно удивительным, — заявил Ананд Каннаппан (Anand Kannappan), соучредитель и генеральный директор Patronus AI, раньше работавший в Meta✴ Reality Labs. — Я думаю, когда мы впервые начали собирать это вместе, мы не осознавали, что будет относительно просто создать такой дословный контент». Результаты исследования наиболее актуальны на фоне обострения отношений между создателями моделей ИИ и издателями, авторами и художниками из-за использования материалов, защищённых авторским правом, для обучения LLM. Достаточно вспомнить громкий судебный процесс между The New York Times и OpenAI, который некоторые аналитики считают переломным моментом для отрасли. Многомиллиардный иск новостного агентства, поданный в декабре, требует привлечь Microsoft и OpenAI к ответственности за систематическое нарушение авторских прав издания при обучении моделей ИИ.  Позиция OpenAI заключается в том, что «поскольку авторское право сегодня распространяется практически на все виды человеческого выражения, включая сообщения в блогах, фотографии, сообщения на форумах, фрагменты программного кода и правительственные документы, было бы невозможно обучать сегодняшние ведущие модели ИИ без использования материалов, защищённых авторским правом». По мнению OpenAI, ограничение обучающих данных созданными более века назад книгами и рисунками, являющимися общественным достоянием, может стать интересным экспериментом, но не обеспечит системы ИИ, отвечающие потребностям настоящего и будущего. В центре Млечного Пути найдены скрытые следы появления тысяч молодых звёзд
20.02.2024 [20:09],
Геннадий Детинич
Центр нашей галактики интересен не только сверхмассивной чёрной дырой Стрелец А*. Там есть области обильного образования звёзд. Астрономы получили снимок одной из таких областей — Стрельца С. Несмотря на всё своё великолепие, этот снимок не отображает всей полноты находящихся там звёзд. Пыль и газ застилают обзор и скрывают множество новорожденных. Об их появлении говорят только спектры. Но это служит и подсказкой для поиска других похожих очагов. 
Нажмите для увеличения. Источник изображения: ESO Снимок области Стрелец С на удалении 300 световых лет от центра Млечного Пути получен на Очень большом телескопе (VLT) Европейской Южной обсерватории (ESO) в пустыне Атакама в Чили. Заглянуть чуть глубже сквозь пыль и газ помог инфракрасный прибор HAWK-I, установленный на телескопе. Без него изучаемая область показала бы ещё меньше звёзд, чем мы видим на снимке выше. В скоплении Стрелец С сотни тысяч звёзд, большинство из которых есть на снимке. «Центр Млечного Пути — самая плодовитая область звездообразования во всей галактике, — заявили представители ESO в заявлении. — Однако астрономы обнаружили здесь лишь часть молодых звёзд, которые они ожидали [увидеть]». «Есть "ископаемые" свидетельства того, что в недавнем прошлом родилось гораздо больше звёзд, чем те, которые мы видим на самом деле, — поясняют учёные. — Это потому, что смотреть в сторону центра галактики — непростая задача». Тем не менее, инфракрасный прибор на телескопе позволил заглянуть сквозь эти облака и увидеть плотно упакованную звездную популяцию Стрельца С. Приборы также позволили выявить химический состав межзвёздного газа, что дало основание ожидать в этой области появления множества новых звёзд. Это наблюдение поможет астрономам определить новые регионы, в которых можно искать другие затемнённые молодые звезды и скопления. Млечный Путь — это наш звёздный дом и о нём лучше знать больше, чем меньше. Microsoft обвинила хакеров из Китая, России и Ирана в использовании её ИИ
14.02.2024 [20:13],
Владимир Мироненко
Microsoft опубликовала отчёт, в котором обвинила хакерские группы, якобы связанные с российской военной разведкой, Ираном, Китаем и Северной Кореей в использовании её больших языковых моделей (LLM) для совершенствования атак. Компания объявила об этом, когда ввела полный запрет на использование поддерживаемыми государством хакерскими группами её ИИ-технологий. 
Источник изображения: Pixabay «Независимо от того, имеет ли место какое-либо нарушение закона или какие-либо условия обслуживания, мы просто не хотим, чтобы те субъекты, которых мы определили, которых мы отслеживаем и знаем как субъектов угроз различного рода, чтобы они имели доступ к этой технологии», — сообщил агентству Reuters вице-президент Microsoft по безопасности клиентов Том Берт (Tom Burt) перед публикацией отчёта. «Это один из первых, если не первый случай, когда компания, занимающаяся ИИ, публично обсуждает, как субъекты угроз кибербезопасности используют технологии ИИ», — отметил Боб Ротстед (Bob Rotsted), руководитель отдела анализа угроз кибербезопасности в OpenAI. OpenAI и Microsoft сообщили, что использование хакерами их ИИ-инструментов находится на ранней стадии и никаких прорывов не наблюдается. «Они просто используют эту технологию, как и любой другой пользователь», — сказал Берт. В отчёте Microsoft отмечено, что цели использования LLM разными хакерскими группами всё же отличаются. Например, хакерские группы, которым приписывают связь с ГРУ, использовали LLM для исследования «различных спутниковых и радиолокационных технологий, которые могут иметь отношение к обычным военным операциям на Украине». Северокорейские хакеры использовали LLM для создания контента, «который, вероятно, будет применяться в целевых фишинговых кампаниях» против региональных экспертов. Иранским хакерам эти модели потребовались для написания более убедительных электронных писем потенциальным жертвам, а китайские хакеры экспериментировали с LLM, например, чтобы задавать вопросы о конкурирующих спецслужбах, проблемах кибербезопасности и «известных личностях». ASML показала первый рекламный фильм, который никто не снимал — почти всё в нём сделал ИИ
01.02.2024 [22:49],
Геннадий Детинич
Нидерландская компания ASML — безусловный лидер рынка литографических сканеров для производства полупроводников — представила «первый рекламный фильм», созданный искусственным интеллектом. Видео создано с использованием моделей Midjourney и алгоритмов RunwayAI с минимальным вмешательством людей в процесс монтажа и редактирования, и оно поражает воображение. Это будущее, которое наступило, и которое скоро многое изменит в жизни каждого человека. 
Кадр из созданного ИИ фильма ASML «Стоя на плечах гигантов». Источник изображения: ASML Ролик ASML под названием «Стоя на плечах гигантов» отсылает к известному высказыванию Исаака Ньютона: «Если я видел дальше других, то потому, что стоял на плечах гигантов». В представлении ASML, сотрудники которой составляли текстовые подсказки, микропроцессорная индустрия и все современные достижения в области вычислений также стоят на плечах гигантов, включая самого сэра Ньютона. Кстати, с Ньютоном и яблоком в его руке пришлось особенно помучиться, признаются в ASML. Это оказалась самая сложная сцена. Команде операторов потребовалось более 20 попыток, чтобы правильно её воспроизвести. Для этого было сгенерировано более 9800 кадров, после чего можно было удовлетвориться результатом. В целом фильм был создан с использованием 1963 подсказок, которые дали 7852 изображения. Цифровые картинки были отредактированы, а затем отрисованы на более чем 900 компьютерах. Наконец, полученные рендеры были обработаны алгоритмами RunwayAI, и общий объём кадров составил 25 957 штук по 1000 Мбайт на каждый из них. RagaAI выпустит лекарство от галлюцинаций для ИИ
23.01.2024 [14:23],
Алексей Разин
Cтартапу RagaAI удалось привлечь финансирование в размере $4,7 млн на разработку программных средств, упрощающих выявление дефектов в нейросетях, пишет Bloomberg. Речь о таких проблемах современных ИИ систем, как так называемые «галлюцинации» или неспособность предоставить критически важную информацию в конкретный момент времени. 
Источник изображения: RagaAI Подобные решения, по словам источника, позволят повысить надёжность работы и безопасность систем искусственного интеллекта. У истоков стартапа стоит выходец из NVIDIA и Texas Instruments — сорокачетырёхлетний Гаурав Агарвал (Gaurav Agarwal), который о необходимости создания подобных инструментов задумался после неприятного инцидента с тестированием системы автономного вождения на дорогах Калифорнии. Автоматика не смогла своевременно распознать возникшее на пути следования препятствия, в результате чего Агарвал был вынужден применить экстренное торможение и избежал тем самым столкновения. Как основатель RagaAI признался в интервью Bloomberg, ему доводилось сталкиваться с проблемами в работе нейросетей во время работы в NVIDIA и Ola. Устранять ошибки в работе систем искусственного интеллекта, по его словам, важно в ряде сценариев, подразумевающих высокую степень ответственности — например, при диагностике онкологических заболеваний, обслуживании авиационной техники и использовании искусственного интеллекта для подбора персонала. Стартап RagaAI был основан в Калифорнии ещё до выхода на рынок нашумевшего чат-бота ChatGPT компании OpenAI. Разработанная им платформа позволяет корпоративным клиентам провести более 300 тестов, выявляющих узкие места в работе их систем искусственного интеллекта. Она позволяет выявлять проблемы с распознаванием объектов и появлением «мусора», а также ложных данных, выдаваемых за истину. Более того, разработка RagaAI позволяет блокировать атаки на языковые модели, призванные заставить их работать с ошибками. Основной штат специалистов стартапа разместится в индийском Бенгалуру, на его расширение как раз будут потрачены привлечённые в ходе недавнего раунда финансирования средства. По словам главы компании, она уже сотрудничает с несколькими крупными клиентам в сфере электронной торговли, аэронавтики и обработки медицинских изображений. Платформа RagaAI уже позволила им снизить количество ошибок в работе систем искусственного интеллекта на 90 %. ByteDance заподозрили в использовании технологий OpenAI для создания конкурирующей ИИ-модели
18.12.2023 [16:52],
Владимир Мироненко
ByteDance (родительская компания TikTok) тайно использует технологию OpenAI для разработки собственной конкурирующей большой языковой модели (LLM), сообщил ресурс The Verge, подчеркнувший, что это является прямым нарушением условий использования технологий ИИ OpenAI, согласно которым они не могут применяться для разработки каких-либо моделей ИИ, которые конкурируют с продуктами и сервисами» компании. 
Источник изображений: ByteDance Согласно внутренним документам ByteDance, с которыми ознакомились в The Verge, OpenAI API использовался в проекте под кодовым названием Project Seed почти на каждом этапе разработки LLM, в том числе для обучения и оценки модели. После публикации The Verge китайская компания сочла необходимым выступить с разъяснением по этому поводу. ByteDance признала в заявлении, направленном ресурсу South China Morning Post, что, когда в начале этого года занялась изучением LLM, её небольшая группа разработчиков действительно использовала API-сервис OpenAI в экспериментальной модели, которая не предназначалась для публичного запуска. Работа над проектом была прекращена в апреле после введения регламентации использования OpenAI, условиями которой запрещается применение продуктов GPT для разработки моделей, конкурирующих с продуктами OpenAI. ByteDance сообщила, что по-прежнему использует API OpenAI вместе с некоторыми другими сторонними моделями «в очень ограниченной степени в процессе оценки/тестирования, например, при сравнительном анализе результатов». «ByteDance имеет лицензию на использование API OpenAI и уделяет большое внимание соблюдению условий использования OpenAI», — указано в заявлении компании. Тем не менее OpenAI приостановила доступ ByteDance к своему сервису. «Хотя использование ByteDance нашего API было минимальным, мы заблокировали её учётную запись на время расследования»,— указано в заявлении OpenAI, направленном ресурсу Verge. OpenAI предупредила, что, если выяснится, что использование API OpenAI китайской компанией не соответствует её условиям, ей будет предложено внести необходимые изменения или закрыть свою учётную запись. В настоящее время в Китае наблюдается бум в разработке LLM. К июлю этого года местными фирмами и исследовательскими институтами было выпущено не менее 130 LLM. В связи с этим основатель и гендиректор Baidu Робин Ли (Robin Li) заявил, что в стране слишком много базовых моделей искусственного интеллекта, что является «громадным растранжириванием ресурсов». Amazon представила мощные ускорители Trainium2 для обучения больших ИИ-моделей, а также Arm-процессоры Graviton4
28.11.2023 [22:26],
Николай Фрей
Рост спроса на генеративный искусственный интеллект, который зачастую обучается и запускается на специализированных ускорителях на графических процессорах (GPU), во всём мире наблюдается дефицит таких ускорителей. На этом фоне облачные гиганты создают свои чипы. И Amazon сегодня на ежегодной конференции re:Invent продемонстрировала новейшие собственные ускорители для обучения нейросетей — Trainium2. А ещё были представлены серверные процессоры Graviton4. 
Источник изображения: Unsplash Первый из двух представленных чипов, AWS Trainium2, способен обеспечить в четыре раза более высокую производительность и в два раза более высокую энергоэффективность по сравнению с первым поколением Trainium, представленным в декабре 2020 года. Trainium2 будет доступен клиентам Amazon Web Services в инстансах EC Trn2 в кластерах из 16-ти чипов. В решении AWS EC2 UltraCluster клиенты смогут получить в своё распоряжении до 100 000 чипов Trainium2 для обучения больших языковых моделей. К сожалению, Amazon не уточнила, когда Trainium2 станут доступны клиентам AWS, предположив лишь, что это произойдёт «где-то в следующем году». По заявлению Amazon, 100 000 чипов Trainium2 обеспечат теоретическую вычислительную мощность в 65 Эфлопс (квинтиллионов операций в секунду), что в пересчёте на одно ядро составляет 650 Тфлопс (триллионов операций). Конечно, это лишь теоретические показатели, и стоит брать во внимание факторы, усложняющие расчёты. Однако, если предположить, что одно ядро Trainium2 сможет обеспечивать реальную производительность около 200 Тфлопс, то это значительно превысит возможности чипов того же Google для обучения моделей ИИ. В Amazon также подчеркнули, что кластер из 100 000 чипов Trainium2 способен обучить большую языковую модель ИИ (LLM – large language model) с 300 миллиардами параметров всего за несколько недель. Раньше на такие задачи уходили месяцы обучения. Отметим, что параметры в парадигме LLM — это элементы модели, полученные на обучающих датасетах и, по сути, определяющие мастерство модели в решении той или иной задачи, к примеру, генерации текста или кода. 300 миллиардов параметров — это примерно в 1,75 раза больше, чем у GPT-3 от OpenAI. «Чипы лежат в основе всех рабочих нагрузок клиентов, что делает их критически важной областью инноваций для AWS, — отметил в пресс-релизе вице-президент AWS по вычислениям и сетям Дэвид Браун (David Brown). — Учитывая всплеск интереса к генеративному ИИ, Trainium2 поможет клиентам обучать их ML-модели быстрее, по более приемлемой цене и с большей энергоэффективностью». 
Слева — процессор Graviton4, справа — ускоритель Trainium2. Источник изображения: Amazon Второй чип, анонсированный Amazon сегодня — Arm-процессор Graviton4. Amazon утверждает, что он обеспечивает на 30 % более высокую производительность, на 50 % больше ядер и на 75 % более высокую пропускную способность памяти, чем процессор предыдущего поколения Graviton3 (но не более современный Graviton3E), применяемый в облаке Amazon EC2. Таким образом Graviton4 предложат до 96 ядер (но будут и другие конфигурации) и поддержку до 12 каналов оперативной памяти DDR5-5600. Ещё один апгрейд по сравнению с Graviton3 состоит в том, что все физические аппаратные интерфейсы Graviton4 зашифрованы. По заявлению Amazon, это должно надёжнее защищать рабочие нагрузки клиентов по обучению ИИ и клиентские данные с повышенными требованиями к конфиденциальности. «Graviton4 — это четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, когда-либо созданный нами для широкого спектра рабочих нагрузок, — говорится в заявлении Дэвида Брауна. — Затачивая наши чипы на реальные рабочие нагрузки, которые очень важны для клиентов, мы можем предоставить им самую передовую облачную инфраструктуру». Graviton4 будет доступен в массивах Amazon EC2 R8g, которые уже сегодня открыты для пользователей в предварительной версии. «Тинькофф» объявил о разработке антипода ChatGPT
24.11.2023 [15:52],
Владимир Мироненко
Компания «Тинькофф» в настоящее время занимается разработкой собственных специализированных больших языковых моделей (LLM). Об этом сообщил директор «Тинькофф» по ИИ Виктор Тарнавский на международной конференции по искусственному интеллекту AI Journey, которая сейчас проходит в Москве. 
Источник изображения: Pixabay Тарнавский уточнил, что разрабатываемый продукт является в каком-то смысле «антиподом» чат-бота ChatGPT компании OpenAI. По его словам, основное отличие LLM «Тинькофф» от ChatGPT заключается в том, что решение будет не единой универсальной моделью, а несколькими инструментами, заточенными под разные продукты. Кроме того, «Тинькофф» пока не планирует коммерциализацию создаваемых языковых моделей. Предполагается, что они будут использоваться исключительно внутри экосистемы «Тинькофф» для создания и улучшения продуктов и процессов. «Наш основной фокус — делать лучшие продукты для наших пользователей, и мы создаём для этих продуктов заточенные под наши сценарии модели», — заявил Тарнавский. «Мы сами строим большие языковые модели. Строим их с нуля. Мы создаём базовые модели, а потом сверху надстраиваем те, что решают конкретные задачи», — рассказал топ-менеджер «Тинькофф». Он отметил, что у компании «сильная команда, достаточно данных и вычислительных мощностей». «Мы понимаем, как сделать наши модели по качеству лучше, чем у любого конкурента на рынке», — подчеркнул Тарнавский. Благодаря фокусировке можно будет создать инструмент более высокого качества, чем «общее» решение. «Стоит ожидать больших значимых запусков продуктов в экосистеме "Тинькофф", базирующихся на больших языковых моделях. Через продукты и через продуктовую ценность для конечного потребителя мы будем реализовывать потенциал, который заложен в больших языковых моделях», — заявил Тарнавский. Alibaba выпустила одну из самых мощных ИИ-моделей в мире с сотнями миллиардов параметров
31.10.2023 [18:24],
Владимир Мироненко
Крупнейшая в Китае компания в области облачных вычислений и электронной коммерции Alibaba на ежегодной конференции в Ханчжоу представила большую языковую модель следующего поколения Tongyi Qianwen 2.0. Данная разработка компании должна помочь ей в стремлении выйти на равные с глобальными технологическими гигантами, такими как Amazon и Microsoft. 
Источник изображения: Pixabay Alibaba охарактеризовала Tongyi Qianwen 2.0 как «существенное обновление своего предшественника» Tongyi Qianwen, представленного в апреле. «Новая ИИ-платформа демонстрирует замечательные способности в понимании сложных языковых инструкций, копирайтинге, рассуждениях, запоминании и предотвращении галлюцинаций (выдумывания фактов)», — говорится в пресс-релизе компании. Сообщается, что Tongyi Qianwen 2.0 имеет сотни миллиардов параметров, что делает её одной из самых мощных ИИ-моделей в мире по этому показателю. Alibaba также выпустила восемь ИИ-моделей для индустрии развлечений, финансов, здравоохранения и юридической сферы. Китайская компания также анонсировала сервисную платформу генеративного ИИ, которая позволяет клиентам создавать собственные генеративные приложения ИИ, обученные на их собственных массивах данных. Одним из рисков использования общедоступных продуктов генерирующего ИИ, таких как ChatGPT, компании Alibaba считают возможность доступа к их данным третьих лиц и организаций. Alibaba наряду с другими облачными провайдерами предлагает компаниям инструменты для создания собственных продуктов генеративного ИИ с использованием собственных данных, которые будут защищены от постороннего вмешательства в рамках пакета услуг. Напомним, что месяцем ранее конкурент Alibaba, китайский IT-холдинг Tencent, представил собственную большую языковую модель Hunyuan с более 100 млрд параметров, которая, по словам разработчика, превосходит модель OpenAI GPT-4 при обработке китайского языка. «Большая семёрка» договорилась о руководящих принципах и кодексе поведения для ИИ
30.10.2023 [19:35],
Сергей Сурабекянц
Лидеры G7 сегодня подписали «Соглашение о международных руководящих принципах ИИ» и «Добровольный кодекс поведения разработчиков ИИ» в рамках «Хиросимского процесса ИИ» — форума, посвящённого перспективам и проблемам развития искусственного интеллекта. Эти документы дополнят на международном уровне юридически обязательные правила, которые в настоящее время дорабатываются законодателями ЕС в соответствии с «Законом об ИИ». 
Источник изображения: Pixabay Одиннадцать руководящих принципов, принятых лидерами «Большой семёрки», служат руководством по обеспечению безопасности и надёжности технологий для организаций, разрабатывающих, внедряющих и использующих передовые системы ИИ. Они включают в себя обязательства по снижению рисков и злоупотреблений, выявлению уязвимостей, поощрению ответственного обмена информацией, отчётности об инцидентах и инвестициям в кибербезопасность, а также систему маркировки, позволяющую пользователям идентифицировать контент, созданный ИИ. Эти принципы, основанные на результатах опроса заинтересованных сторон, были разработаны ЕС совместно с другими членами «Большой семёрки» в рамках инициативы, известной как «Хиросимский процесс ИИ». Они послужили основой для составления кодекса, который предоставит подробное и практическое руководство для организаций, разрабатывающих ИИ и будет способствовать ответственному управлению ИИ во всём мире. Оба документа будут пересматриваться и обновляться по мере необходимости, в том числе посредством консультаций с участием многих заинтересованных сторон, чтобы гарантировать, что они остаются пригодными для использования и отвечают требованиям этой быстро развивающейся технологии. Лидеры G7 призвали организации, разрабатывающие передовые системы ИИ, взять на себя обязательство использовать в своей деятельности провозглашённые в принятых документах принципы. «Хиросимский процесс ИИ» был учреждён на саммите G7 19 мая 2023 года с целью содействия развитию передовых систем ИИ на глобальном уровне. Эта инициатива является частью более широкого спектра международных дискуссий по вопросам сдерживания развития ИИ. 
Источник изображения: Japan Pool / Bloomberg «Потенциальные преимущества ИИ для граждан и экономики огромны. Однако ускорение развития возможностей ИИ также порождает новые проблемы. Уже будучи лидером в сфере регулирования благодаря "Закону об ИИ", ЕС вносит свой вклад в создание барьеров и управление ИИ на глобальном уровне. Я рада приветствовать международные руководящие принципы и добровольный кодекс поведения, отражающие ценности ЕС. Я призываю разработчиков ИИ подписать и внедрить этот Кодекс поведения как можно скорее», — прокомментировала принятые решения президент Еврокомиссии Урсула фон дер Ляйен. Ниже приведён текст официального заявления лидеров G7 на «Хиросимском процессе ИИ» от 30 октября 2023 года: «Мы, лидеры "Большой семёрки" (G7), подчёркиваем инновационные возможности и преобразующий потенциал передовых систем искусственного интеллекта (ИИ), в частности, базовых моделей и генеративного ИИ. Мы также признаем необходимость управления рисками и защиты отдельных лиц, общества и наших общих принципов, включая верховенство закона и демократические ценности, сохраняя человечество в центре внимания. Мы подтверждаем, что решение этих проблем требует формирования инклюзивного управления искусственным интеллектом. Опираясь на прогресс, достигнутый соответствующими министрами в рамках Хиросимского процесса искусственного интеллекта, включая Заявление министров цифровых технологий и технологий "Большой семёрки", опубликованное 7 сентября 2023 года, мы приветствуем Международные руководящие принципы Хиросимского процесса для организаций, разрабатывающих передовые системы искусственного интеллекта, и Международный кодекс Хиросимского процесса. поведения организаций, разрабатывающих передовые системы искусственного интеллекта. Чтобы гарантировать, что оба документа сохранят свою пригодность и соответствие этой быстро развивающейся технологии, они будут пересматриваться и обновляться по мере необходимости, в том числе посредством постоянных инклюзивных консультаций с участием многих заинтересованных сторон. Мы призываем организации, разрабатывающие передовые системы искусственного интеллекта, соблюдать Международный кодекс поведения. Мы поручаем соответствующим министрам ускорить процесс разработки Комплексной политики Хиросимского процесса ИИ, которая включает сотрудничество на основе проектов, к концу этого года в сотрудничестве с Глобальным партнёрством по искусственному интеллекту (GPAI) и Организацией экономического сотрудничества. операции и развития (ОЭСР), а также проводить информационно-разъяснительную работу и консультации с участием многих заинтересованных сторон, в том числе с правительствами, научными кругами, гражданским обществом и частным сектором, не только входящим в "Большую семёрку", но и в странах за её пределами, включая развивающиеся и развивающиеся экономики. Мы также просим соответствующих министров разработать к концу года план работы по дальнейшему развитию Хиросимского процесса искусственного интеллекта. Мы считаем, что наши совместные усилия в рамках Хиросимского процесса искусственного интеллекта будут способствовать созданию открытой и благоприятной среды, в которой безопасные, надёжные и заслуживающие доверия системы ИИ проектируются, разрабатываются, внедряются и используются для максимизации преимуществ технологии при одновременном снижении её рисков, для общего блага во всем мире, в том числе в развивающихся странах и странах с формирующейся рыночной экономикой, с целью преодоления цифрового неравенства и достижения охвата цифровыми технологиями. Мы также с нетерпением ждём британского саммита по безопасности искусственного интеллекта, который пройдёт 1 и 2 ноября». Сотрудничество NVIDIA и ИИ-стартапа Hugging Face поможет упростить облачное обучение ИИ-моделей
09.08.2023 [04:25],
Владимир Мироненко
Чипмейкер NVIDIA объявил на ежегодной конференции SIGGRAPH 2023 о партнёрстве со стартапом в области ИИ Hugging Face. В рамках партнёрства NVIDIA обеспечит поддержку новой услуги Hugging Face под названием Training Cluster as a Service (Кластер обучения как услуга), которая упростит создание и настройку новых пользовательских генеративных моделей ИИ для корпоративных клиентов, использующих собственную платформу и NVIDIA DGX Cloud для инфраструктуры, делая это одним щелчком мыши. 
Источник изображения: Hugging Face Запуск сервиса Training Cluster as a Service намечен на ближайшие месяцы. Он будет базироваться на DGX Cloud, облачном ИИ-суперкомпьютере NVIDIA, предлагающем выделенные ИИ-кластеры NVIDIA DGX с ПО NVIDIA. DGX Cloud предоставляет доступ к инстансу с восемью ускорителями NVIDIA H100 или A100 и 640 Гбайт памяти, а также ПО NVIDIA AI Enterprise для разработки приложений ИИ и больших языковых моделей (LLM). Также предоставляется возможность консультирования у экспертов NVIDIA. Разработчики также получат доступ к новой рабочей среде NVIDIA AI Workbench, которая позволит им быстро создавать, тестировать и настраивать предварительно обученные модели генеративного ИИ и LLM. Компании могут подписаться на сервис DGX Cloud самостоятельно — стоимость инстансов DGX Cloud начинается от $36 999/мес. Однако сервис Training Cluster as a Service объединяет облачную инфраструктуру DGX с платформой Hugging Face, включающей более 250 000 моделей и более 50 000 наборов данных, что будет полезно при работе над любым проектом ИИ. По словам гендиректора Hugging Face Клемана Деланга (Clément Delangue), платформу стартапа использует более 15 000 компаний. Alibaba открыла доступ к своим ИИ-моделям всем желающим
03.08.2023 [18:05],
Владимир Мироненко
Китайский гигант электронной коммерции Alibaba объявил сегодня, что открывает доступ к своим ИИ-моделям сторонним разработчикам, которые смогут с их помощью создавать собственные приложения с генеративным ИИ, без необходимости обучать свои системы, экономя время и расходы. Сообщается, что Alibaba открывает исходный код модели Qwen-7B с 7 млрд параметров и версии Qwen-7B-Chat, предназначенной для диалоговых приложений. 
Источник изображения: Pixabay В апреле Alibaba запустила большую языковую модель (LLM) Tongyi Qianwen, которая позволяет генерировать контент с использованием ИИ на английском и китайском языках и имеет различные размеры моделей, включая Qwen-7B с 7 млрд параметров и выше. Доступ к Qwen-7B и Qwen-7B-Chat получат исследователи, учёные и компании по всему миру. Сообщается, что компаниям с более чем 100 млн активных пользователей в месяц для этого потребуется бесплатная лицензия от Alibaba. Хотя Alibaba и не будет получать лицензионных сборов за использование своей технологии с открытым исходным кодом, её распространение, как ожидается, позволит компании привлечь больше пользователей к работе со своими ИИ-моделями. Этот шаг Alibaba обостряет её конкуренцию с Meta✴, предоставившей ранее в этом году доступ исследователям к своей модели Llama с открытым исходным кодом. Meta✴ также сотрудничает с другими технологическими фирмами, чтобы ускорить внедрение своей ИИ-модели. В прошлом месяце Microsoft объявила об открытии доступа к LLM Llama 2 компании Meta✴ для разработчиков, использующих облачный сервис Microsoft Azure. Если большая языковая модель Alibaba завоюет популярность на рынке, это может оказаться привлекательным для облачных провайдеров, которые сделают её доступной для своих клиентов. Наличие мощной LLM для разработки приложений с ИИ является потенциальным конкурентным преимуществом для игроков на рынке облачных вычислений. Alibaba уже создала свои собственные приложения, используя Tongyi Qianwen. В прошлом месяце она запустила Tongyi Wanxiang, ИИ-сервис, позволяющий генерировать изображения на основе подсказок. Google прокачает «Ассистента» с помощью большой языковой ИИ-модели
01.08.2023 [11:25],
Павел Котов
Голосовой помощник «Google Ассистент» получит крупное обновление: в его основу ляжет большая языковая модель — нейросеть, аналогичная тем, что используются в сервисах ChatGPT и Google Bard. «Часть команды [Google] уже приступила к работе над этим, начиная с мобильных устройств», — передаёт Axios со ссылкой на внутреннее письмо компании. 
Источник изображения: assistant.google.com В рамках нового проекта Google также сократит команду, работающую над голосовым помощником: будет «ликвидировано небольшое число должностей», говорится в документе, хотя и не уточняется, сколько именно сотрудников затронет решение — таковых будет несколько десятков, утверждает Axios. Во внутреннем письме компании не уточняется, какие именно функции добавятся в «Google Ассистент», но возможностей для расширения функциональности предостаточно. Это может быть платформа, лежащая в основе чат-бота Google Bard. В этом случае голосовой помощник научится отвечать на вопросы пользователя, черпая информацию из интернета. «Сотни миллионов людей пользуются „Ассистентом” каждый месяц, и мы стремимся предоставлять им высококачественные функции. С радостью изучаем возможности того, как большие языковые модели помогут нам улучшить „Ассистент” и сделать его ещё лучше», — заявила представитель компании ресурсу The Verge. Астрономы запечатлели зарождение газового гиганта у молодой звезды
25.07.2023 [20:48],
Сергей Сурабекянц
Потрясающее изображение скопления материи вокруг звезды V960 Mon, светящегося ярко-голубым цветом в центре золотых «крыльев» из газа и пыли, было создано совместными наблюдениями с Очень Большого Телескопа (VLT) и Атакамской большой антенной решётки миллиметрового диапазона (ALMA). Изучение пылевых сгустков вокруг звезды V960 Mon, расположенной в 5000 световых лет от Солнца, в созвездии Единорога, покажет, как рождаются газовые планеты-гиганты, подобные Юпитеру. 
Источник изображений: ESO/ALMA/Weber Астрономы впервые обратили внимание на молодую звезду в 2014 году, когда она неожиданно увеличила яркость примерно в 20 раз по сравнению с обычной величиной. Наблюдения с помощью инструмента VLT Spectro-Polarimetric High-contrast Exoplanet REsearch (SPHERE) были проведены вскоре после этой вспышки, благодаря чему учёным удалось получить изображения звёздной системы с беспрецедентным уровнем детализации. «Это открытие действительно захватывающее, поскольку оно знаменует собой самое первое обнаружение скоплений вокруг молодой звезды, которые потенциально могут породить планеты-гиганты», — говорится в заявлении наблюдателя Алисы Зурло (Alice Zurlo) из чилийского университета Диего Порталеса. Исследования показали, что газопылевое облако вокруг V960 Mon, образует серию сложных спиральных рукавов, которые простираются на расстояния, превышающие размер Солнечной системы. Это открытие было подтверждено с помощью ALMA. В то время как VLT и SPHERE предоставили детализированные изображения поверхности сгустков пыли и газа, ALMA смогла «заглянуть» глубже, раскрывая астрономам внутреннюю структуру системы и механизм формирования газового гиганта. «При использовании ALMA стало очевидно, что спиральные рукава подвергаются фрагментации, что приводит к образованию сгустков с массами, подобными массам планет», — сказал Зурло. «Наша группа искала признаки формирования планет более десяти лет, и мы очень взволнованы этим невероятным открытием», — поддержал его исследователь чилийского университета Сантьяго Себастьян Перес (Sebastián Pérez). Астрономы называют два способа формирования газовых планет-гигантов. Первый — аккреция, процесс приращения массы небесного тела путём гравитационного притяжения материи из окружающего пространства. Второй — гравитационная неустойчивость, при которой сверхплотные участки протопланетного диска из газа и пыли вокруг звезды коллапсируют. Объединённые изображения, полученные с помощью ALMA и SPHERE, дали астрономам первые свидетельства наблюдения механизма формирования газового гиганта. «Никто никогда до сегодняшнего дня не проводил реального наблюдения гравитационной нестабильности, происходящей в планетарных масштабах», — заявил руководитель чилийского исследовательского университета Сантьяго Филипп Вебер (Philipp Weber). 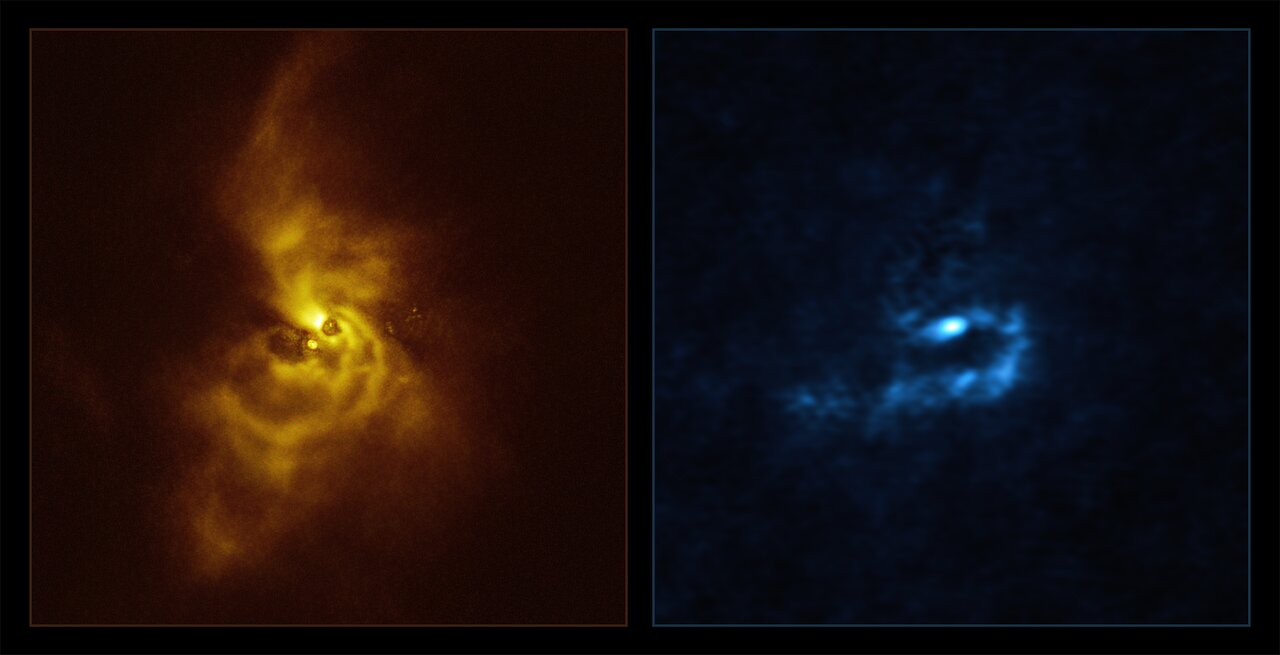
Слева — изображение с VLT, справа — с ALMA Команда чилийских астрономов намерена продолжить изучение процесса формирования этой планетарной системы при помощи Чрезвычайно Большого Телескопа (ELT), который в настоящее время строится в районе пустыни Атакама на севере Чили. Новый телескоп поможет раскрыть «секреты» V960 Mon, скрытые от VLT и ALMA, включая химический состав газопылевых облаков вокруг звезды. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться