|
Опрос
|
реклама
Быстрый переход
Meta✴ снизит стоимость входа в VR — гарнитура Quest 2 подешевеет до $199
19.04.2024 [10:55],
Владимир Фетисов
Гарнитура виртуальной реальности Meta✴ Quest 2 скоро станет ещё более доступной. Компания Meta✴ Platforms объявила о предстоящем снижении розничной стоимости самой доступной версии гаджета. 
Источник изображения: ign.com В официальном блоге Meta✴ сказано, что постоянная стоимость VR-гарнитуры Quest 2 с накопителем ёмкостью 128 Гбайт будет снижена до $199. Эта цена станет самой низкой с момента дебюта устройства на рынке в июне 2021 года, когда она предлагалась за $299. Отметим, что это первое снижение цены на постоянной основе для данной модели. Около года назад Meta✴ объявила о повышении цен на обе версии Quest 2, модель с накопителем на 128 Гбайт тогда подорожала до $399,99. Гарнитура Meta✴ Quest 2 была представлена широкой публике в октябре 2020 года. Устройство быстро сумело занять доминирующую позицию на рынке шлемов виртуальной реальности. Менее чем через год Meta✴ заявила, что Quest 2 уже превзошла по объёму продаж все выпущенные прежде VR-гарнитуры компании вместе взятые (на тот момент устройства этой категории выпускались под брендом Oculus). Несмотря на то, что на рынке уже давно присутствует гарнитура Quest 3, Meta✴ продолжает поддерживать Quest 2. Компания не озвучила точных сроков, в которые может завершить поддержку своей самой популярной VR-гарнитуры. Несмотря на то, что Quest 3 предлагает больше возможностей, предыдущая версия остаётся популярной, поскольку является доступной точкой входа в мир виртуальной реальности. Насколько известно, компания не планирует в ближайшее время выпускать эксклюзивные продукты для Quest 3, поэтому Quest 2 продолжит оставаться востребованной. Meta✴ бросила вызов ChatGPT — все сервисы компании получили «самого умного» ИИ-помощника
18.04.2024 [23:30],
Владимир Чижевский
Сегодня Meta✴ представила не только новое поколение собственных языковых моделей Llama 3, но и подключила их к поисковым строкам своих основных приложений — Facebook✴, Messenger, Instagram✴ и WhatsApp, пусть и не во всех странах. Кроме того, компания запустила отдельный сайт для своего чат-бота, meta✴.ai. 
Источник изображения: Meta✴ Meta✴ стремится не отставать, а то и превзойти конкурирующие продукты вроде ChatGPT от OpenAI, Gemini от Google и Claude от Anthropic, с которыми сегодня и сравнивала новое семейство больших языковых моделей Llama 3. Более того, Марк Цукерберг (Mark Zuckerberg) заявил, что Meta✴ AI «самый интеллектуальный ИИ-помощник из доступных для свободного пользователя». Meta✴ AI запустили ещё в прошлом году, и он по-прежнему поддерживает лишь английский язык, однако работает во многих странах, включая Австралию, Канаду, Гану, Ямайку, Малави, Новую Зеландию, Нигерию, Пакистан, Сингапур, Южную Африку, Уганду, Замбию и Зимбабве. Среди новых функций Meta✴ AI — возможность попросить ИИ найти определённую информацию в Google и Bing. Разработчики не просто ускорили генерацию изображений с помощью Meta✴ AI, но и наделили ИИ возможностью анимировать картинки, а также улучшили функцию размещения текста на генерируемых изображениях. Стремясь как можно сильнее расширить присутствие ИИ в своих продуктах, Meta✴ добавила его не только в поисковые строки, но и в индивидуальные и групповые чаты, и даже в ленты приложений. Например, увидев в ленте Facebook✴ фотографию северного сияния можно спросить ИИ, когда лучше отправиться в Исландию, чтобы наблюдать его своими глазами. Помимо этого, Meta✴ AI добавили в умные очки Ray-Ban, вскоре он появится и в VR-гарнитуре Meta✴ Quest. Meta✴ добавила ИИ-генерацию изображений в реальном времени в WhatsApp — пока в тестовом режиме
18.04.2024 [22:57],
Николай Хижняк
Компания Meta✴ начала тестировать в мессенджере WhatsApp генератор изображений Meta✴ AI на базе искусственного интеллекта. Пока новая функция доступно только пользователям из США. Она работает в режиме реального времени: как только пользователь начинает добавлять в запрос детали для создания картинки, он сразу же видит, как изображение меняется в соответствии с указанными деталями. 
Источник изображения: pexels.com В примере, предоставленном Meta✴, пользователь составляет запрос: «Представь игру в футбол на Марсе» (Imagine a soccer game on mars). С каждым написанным словом ИИ добавляет новые детали в генерируемое изображения, сначала показывая обычных игроков в футбол на обычном поле, а затем меняет его на пейзаж Марса. Пользователи, получившие доступ к бета-версии ИИ-генератора изображения в WhatsApp, могут попробовать новую функцию сами. Запрос необходимо делать на английском языке, начиная со слова «Imagine». Компания Meta✴ также сообщила, что её языковая модель Llama 3, на которой построен ИИ-генератор, способна создавать «более чёткие и качественные» изображения и лучше отображать текст. Пользователи также могут делать для Meta✴ AI запрос для анимации любого предоставленного ими изображения. ИИ сгенерирует из статичной картинки GIF-изображение, которым можно будет поделиться с друзьями. Помимо мобильного приложения WhatsApp, функция ИИ-генерации изображений в реальном времени также стала доступна для пользователей веб-версии платформы Meta✴ AI, но пока тоже только из США. Meta✴ представила нейросеть Llama 3 — «самую способную открытую LLM на сегодняшний день»
18.04.2024 [21:27],
Владимир Чижевский
Meta✴ представила Llama 3 — большую языковую модель нового поколения, которую без лишней скромности называет «самой способной LLM с открытым исходным кодом». Компания выпустила две версии: Llama 3 8B и Llama 3 70B соответственно с 8 и 70 миллиардами параметров. По словам компании, новые ИИ-модели значительно превосходят соответствующие модели прошлого поколения и являются одними из лучших моделей для генеративного ИИ из ныне существующих. 
Источник изображения: vecstock / freepik.com В подтверждение своих слов Meta✴ приводит результаты популярных тестов MMLU (знания), ARC (способность к обучению) и DROP (анализ фрагментов текста). Llama 3 8B превосходит другие модели своего класса с открытым исходным кодом, такие как Mistral 7B от Mistral и Gemma 7B от Google с 7 миллиардами параметров, по крайней мере в девяти тестах: MMLU, ARC, DROP, GPQA (вопросы по биологии, физике и химии), HumanEval (тест на генерацию кода), GSM-8K (математические задачи), MATH (ещё один математический тест), AGIEval (набор тестов на решение задач) и BIG-Bench Hard (оценка рассуждений на основе здравого смысла). 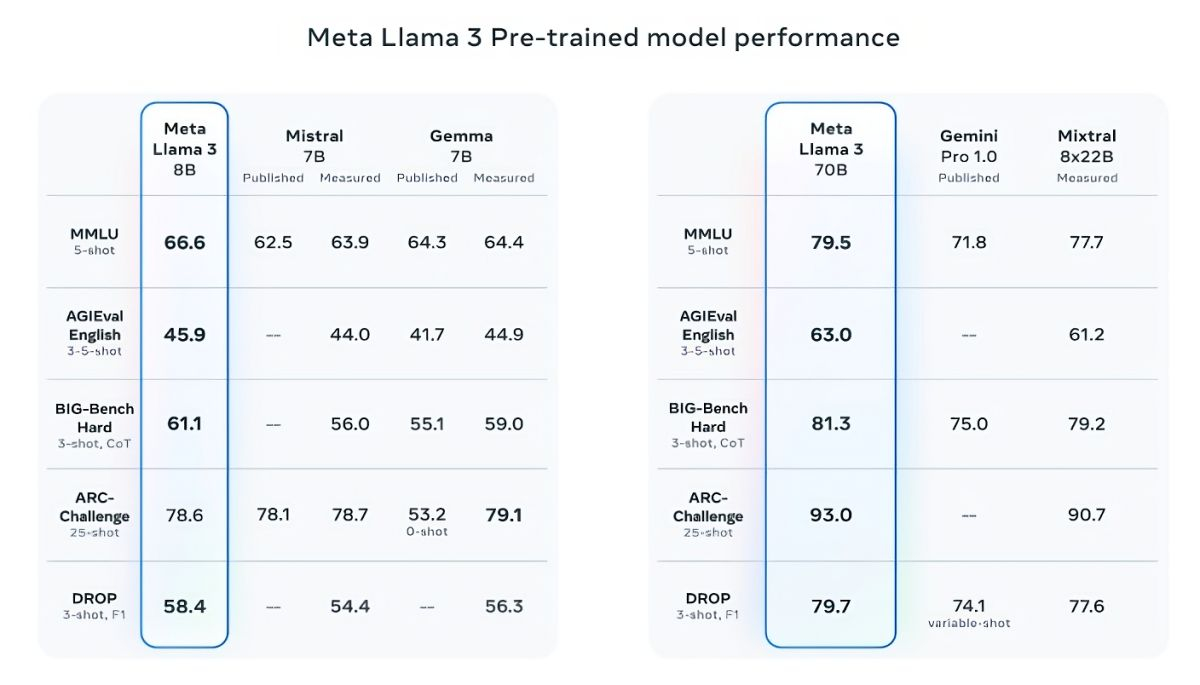
Источник изображений: Meta✴ Mistral 7B и Gemma 7B уже не назвать современными, при этом в некоторых тестах Llama 3 8B не показывает значимого превосходства над ними. Однако куда сильнее Meta✴ гордится более продвинутой моделью, Llama 3 70B, которую ставит в один ряд с другими флагманскими моделями для генеративных ИИ, включая Gemini 1.5 Pro — самую продвинутую в линейке Gemini от Google. Llama 3 70B опережает Gemini 1.5 Pro в тестах MMLU, HumanEval и GSM-8K, но уступает передовой модели Claude 3 Opus от Anthropic, превосходя лишь слабейшую модель серии, Sonnet, в пяти тестах: MMLU, GPQA, HumanEval, GSM-8K и MATH. Meta✴ также разработала собственный набор тестов, от написания текстов и кода до обобщений и выводов, в котором Llama 3 70B обошла Mistral Medium, GPT-3.5 от OpenAI и Claude Sonnet от Anthropic. 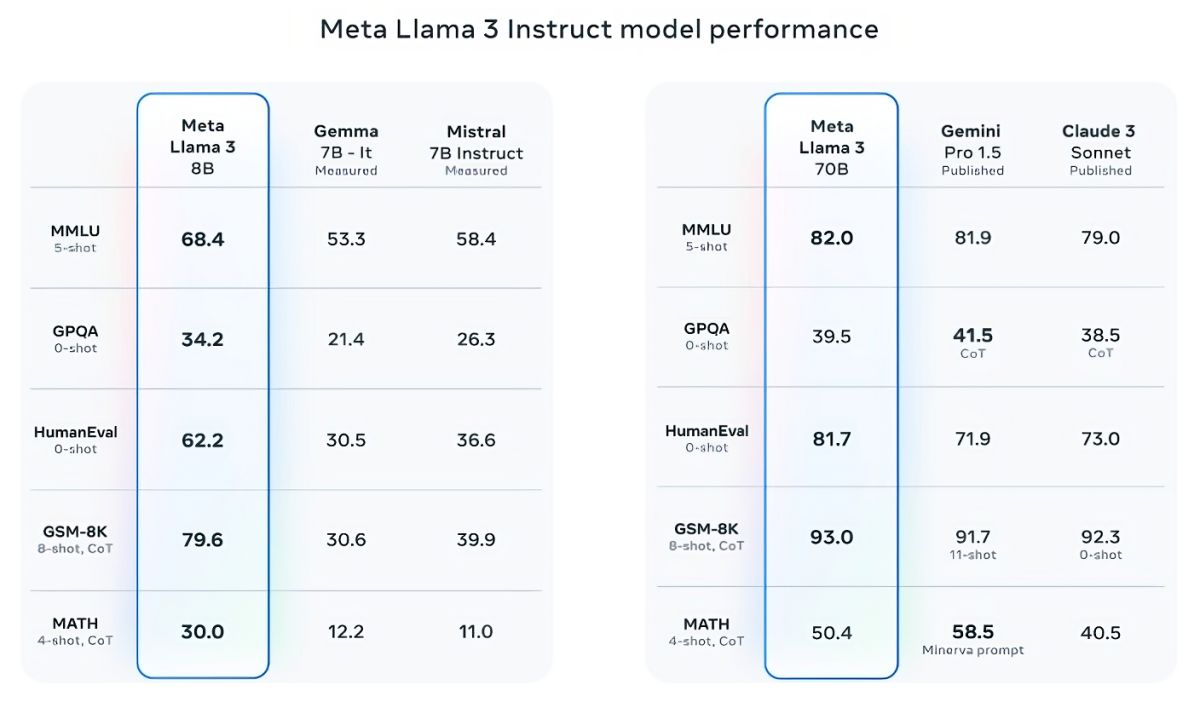 По словам Meta✴, новые модели более «управляемы», реже отказываются отвечать на вопросы и в целом выдают более точную информацию, в том числе в некоторых научных областях, что, вероятно, обосновано огромным количеством данных, использованных для их обучения: 15 триллионов токенов и 750 миллиардов слов, что в семь раз больше, чем в случае с Llama 2. Откуда столько данных? Meta✴ ограничилась заверением, что все они взяты из «общедоступных источников». При этом в наборе данных для обучения Llama 3 содержалось в четыре раза больше кода в сравнении с использованным для Llama 2, а 5 % набора составляли данные на 30 отличных от английского языках, чтобы улучшить работу с ними. Кроме того, использовались синтетические данные, то есть полученные от других ИИ-моделей. 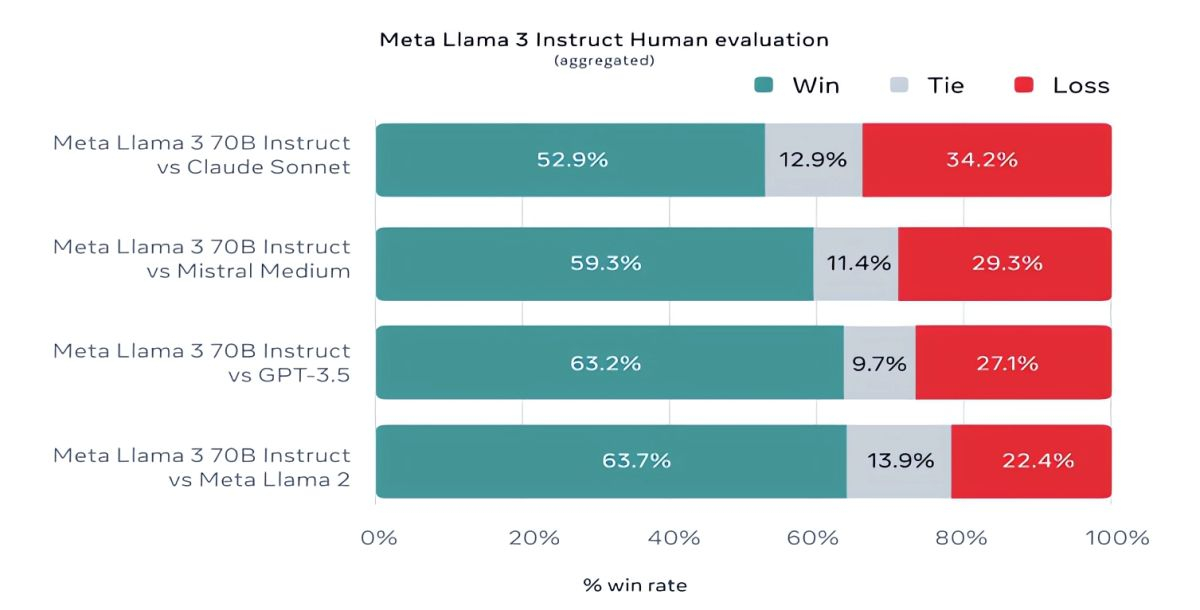 «Наши текущие ИИ-модели настроены отвечать лишь на английском, но мы обучаем их с использованием данных на других языках, чтобы ИИ лучше распознавал нюансы и закономерности», — прокомментировала Meta✴. Вопрос необходимого количества данных для дальнейшего обучения ИИ в последнее время поднимается особенно часто, и Meta✴ уже успела подпортить репутацию на этом поприще. Не так давно сообщалось, что Meta✴ в погоне за конкурентами «скармливала» ИИ защищённые авторским правом электронные книги, хотя юристы компании предупреждали о возможных последствиях. Что касается безопасности, Meta✴ встроила в новое поколение собственных ИИ-моделей несколько протоколов безопасности, таких как Llama Guard и CybersecEval, чтобы бороться с неправомерным использованием ИИ. Компания также выпустила специальный инструмент Code Shield для анализа безопасности кода открытых моделей генеративных ИИ, позволяющий обнаружить потенциальные уязвимости. Известно, что ранее эти же протоколы не уберегли Llama 2 от недостоверных ответов и выдачи персональной медицинской и финансовой информации. 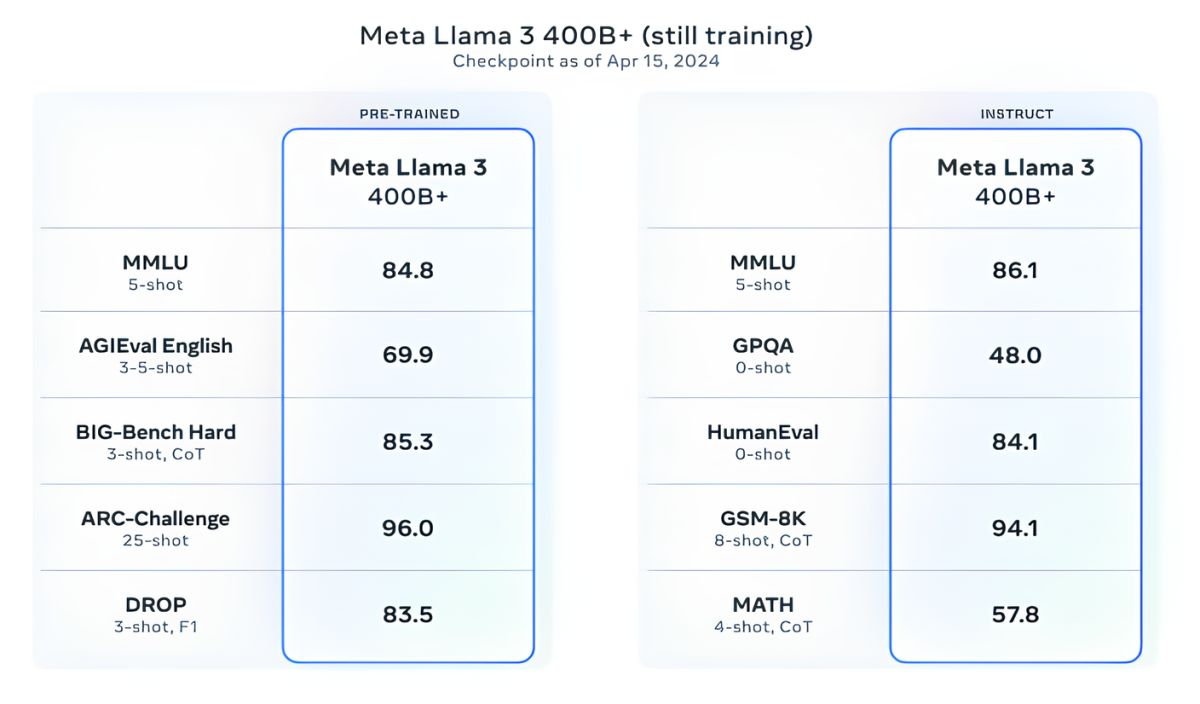 Но и это ещё не всё. Meta✴ обучает модель Llama 3 с 400 миллиардами параметров — она сможет разговаривать на разных языках и принимать больше входящих данных, в том числе работать с изображениями. «Мы стремимся сделать Llama 3 многоязычной и мультимодальной моделью, умеющей учитывать больше контекста. Мы также стараемся улучшить производительность и расширить возможности языковой модели в рассуждениях и написании кода», — сказали в Meta✴. Threads разрешит фильтровать результаты поиска в хронологическом порядке
16.04.2024 [14:17],
Владимир Фетисов
Принадлежащая Meta✴ Platforms платформа микроблогов Threads прошла долгий путь с момента своего запуска в прошлом году. Однако в Threads по-прежнему нет некоторых важных функций, таких как отображение результатов поиска по времени публикации постов. Теперь же стало известно, что некоторым пользователям платформы стала доступна возможность сортировки контента в хронологическом порядке. 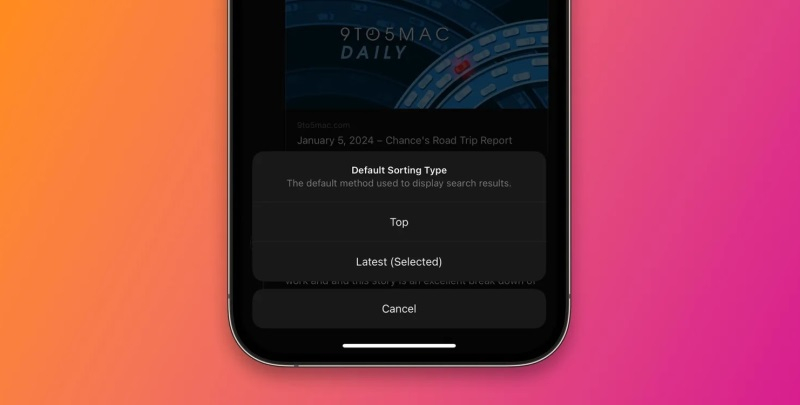
Источник изображения: https://9to5mac.com Начало тестирования новой функции подтвердил глава Instagram✴ Адам Моссери (Adam Mosseri) после того, как стали поступать сообщения от пользователей Threads, которые заявили, что теперь они могут сортировать результаты поиска по последним публикациям, а не по предложенным платформой. «Мы начали тестировать это на небольшом количестве людей, чтобы было проще находить релевантные результаты поиска в режиме реального времени. Любопытно услышать ваше мнение», — говорится в сообщении Моссери в Threads. Когда пользователи платформы ищут что-либо в темах, они будут видеть две кнопки: «Top» и «Latest». Первый вариант предполагает вывод рекомендованных постов, тогда как нажатие на вторую кнопку позволит увидеть все соответствующие запросу сообщения в порядке их публикации на платформе. Ожидается, что такой подход сделает проще процесс взаимодействия пользователей друг с другом. В прошлом году Моссери заявлял, что разработчики не планируют интегрировать в Threads возможность фильтрации результатов поиска в хронологическом порядке. Очевидно, что теперь это решение было пересмотрено, и в скором времени задействовать новую функцию смогут все пользователи платформы. Суд оградил Марка Цукерберга от личных претензий недовольных соцсетями родителей
16.04.2024 [14:05],
Павел Котов
Окружной судья США Ивонн Гонсалес-Роджерс (Yvonne Gonzalez Rogers in Oakland) отклонила часть исков, направленных лично против Марка Цукерберга (Mark Zuckerberg) — их податели обвинили главу Meta✴ в том, что он скрыл вред, наносимый детям платформами Facebook✴ и Instagram✴. 
Источник изображения: Mark Zuckerberg В суд поступили сотни исков, в которых Meta✴ и другие выступающие операторами соцсетей компании обвиняются в том, что их платформы создают зависимость и наносят психологический ущерб несовершеннолетним. Двадцать пять из этих исков направлены на привлечение к личной ответственности Марка Цукерберга — глава Meta✴ якобы создавал ложное впечатление о безопасности соцсетей, несмотря на неоднократные предупреждения, что они непригодны для детей. По версии истцов, авторитет Цукерберга в обществе и его роль в качестве «заслуживающего доверия голоса Meta✴» в соответствии с законами нескольких штатов налагают на него ответственность в полной мере и правдиво рассказывать об угрозах, которые его продукты создают для несовершеннолетних. Но, по мнению судьи Гонсалес-Роджерс, истцы не могут полагаться на сравнительные знания Цукерберга о продуктах Meta✴, чтобы установить, что он лично несёт такую обязанность перед каждым истцом. Такое решение, уверена судья, создаст «обязанность по раскрытию информации для любого известного общественности человека». На рассмотрение поступили несколько сотен исков, ответчиками по которым выступают Alphabet (управляет Google и YouTube), Meta✴ (Facebook✴ и Instagram✴), ByteDance (TikTok) и Snap (Snapchat). В них говорится, что от использования соцсетей дети получили физический, психический и эмоциональный вред, что вылилось в такие проявления как тревога, депрессия и даже самоубийство. Истцы требуют возмещения ущерба и прекращения деятельности, которую они считают вредной. Некоторые иски против Meta✴ были поданы штатами и школьными округами США. Meta✴ упростит интеграцию VR-гарнитур Quest в учебный процесс в школах и не только
15.04.2024 [22:58],
Владимир Чижевский
Meta✴ планирует в этом году выпустить новый продукт для гарнитур виртуальной реальности Quest, который позволит задействовать их в образовательном процессе в школах и не только. С помощью так называемого «образовательного центра» можно будет использовать специальные обучающие программы и функции, а также централизованно управлять всеми устройствами Quest в классе. 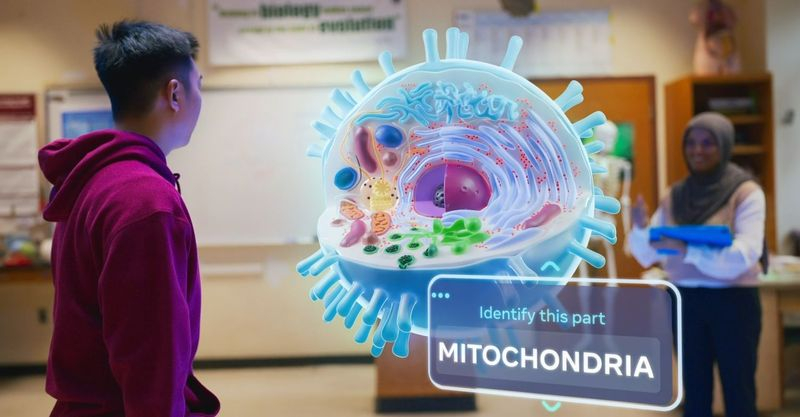
Источник изображения: Meta✴ Meta✴ не раскрыла ни названия продукта, ни его функций, отметив лишь, что он «упростит изучение, применение и отработку новых навыков», позволит виртуально посетить новые места и получить впечатления, недоступные в реальной жизни без помощи Quest. По словам президента Meta✴ по образовательным вопросам Ника Клегга (Nick Clegg), благодаря новому образовательному центру учащиеся смогут пройтись по виртуальным улочкам Древнего Рима и своими глазами увидеть убийство Юлия Цезаря. Однако может оказаться, что предложение Meta✴ подойдёт далеко не всем учреждениям. Прежде всего, образовательный центр установят лишь в школах с учениками от 13 лет и старше, и только в странах с работающей подпиской Quest for Business. Во сколько обойдётся школам такое оснащение — вопрос открытый, однако сейчас подписка Quest for Business стоит $14.99 в месяц за одно устройство. Meta✴ тестирует обмен личными сообщениями в Threads
13.04.2024 [12:50],
Владимир Фетисов
Количество пользователей платформы микроблогов Threads превышает 130 млн человек. Несмотря на это, сервис всё ещё лишён функции обмена личными сообщениями между пользователями. Похоже, что в скором времени это изменится, поскольку разработчики из Meta✴ начали тестировать функцию обмена сообщениями в Threads. 
Источник изображения: Threads Согласно имеющимся данным, упомянутая функция задействует службу личных сообщений Instagram✴, но позволяет инициировать отправку сообщений непосредственно из Threads. Некоторые пользователи сервиса сообщили о появлении в приложении Threads кнопки «Сообщения». Она находится над профилями других пользователей, примерно в том месте, где прежде располагалась кнопка «Упоминание». Представитель Meta✴ подтвердил, что в настоящее время разработчики «тестируют возможность отправки сообщений из Threads в Instagram✴». Отметим, что Threads по-прежнему лишён собственного почтового ящика, и не ясно, появится ли он в будущем. Глава Instagram✴ Адам Моссери (Adam Mosseri) ранее неоднократно говорил, что разработчики не планируют создавать отдельный почтовый ящик для Threads. Вместо этого он хотел «заставить почтовый ящик Instagram✴ работать» в приложении. Несмотря на то, что новая функция Threads не позволит отправлять полноценные личные сообщения, с её помощью пользователи смогут начинать общение без необходимости переключаться на Instagram✴. Однако проверка входящих сообщений или необходимость ответить на какое-либо послание всё равно потребует от пользователей перехода в Instagram✴. Россияне перешли в Telegram и VK после блокировки Instagram✴ и Facebook✴
12.04.2024 [12:22],
Владимир Мироненко
После блокировки в России сервисов Instagram✴ и Facebook✴ компании Meta✴ основная часть отечественных пользователей перешла на платформы Telegram и VK, пишут «Ведомости» со ссылкой на информацию представителей операторов связи большой четвёрки и ряда онлайн-платформ, предоставленную на XV Международной конференции TransNet по магистральным сетям связи группы компаний ComNews. 
Источник изображения: Rubaitul Azad/unsplash.com Генеральный директор Piter-IX Николай Метлюк сообщил в выступлении на конференции, что после блокировки зарубежных сервисов трафик перетёк в Telegram. Его слова подтвердила директор департамента коммерческого управления ресурсами МТС Ольга Макарова, отметившая, что трафик заблокированных сервисов упал в разы. По словам коммерческого директора Arelion Ильи Булаева, объём потребления интернета в России в 2023 году вырос год к году на 20–25 %. Согласно данным Минцифры, объем российского интернет-трафика в 2022 году составил почти 124 эксабайта. Эксперт отметил, что примерно 1 % объёма приходилось на восточное направление, остальная часть — на западное, и в ближайшем будущем ситуация кардинально не изменится. Директор b2o «Эр-телеком холдинга» Андрей Горбунов сообщил, что разворота на азиатские платформы не произошло и трафик перетёк не на восток, а в Telegram и в VK. По словам заместителя вице-президента VK по инфраструктуре и прикладным сервисам Елены Якуповой, компания в прошлом году выросла по трафику на 65 %. «Ведомости» сообщили в конце прошлой осени со ссылкой на представителей крупных телекомоператоров, что в 2023 году трафик в Telegram российских интернет-пользователей вырос год к году на десятки процентов. В частности, у «МегаФона» трафик с января по сентябрь вырос на 80 %, в сети Tele2 — почти на 100 %, а у «Билайна» — в 1,5 раза. В сети МТС трафик Telegram вырос на 35 %. Instagram✴ защитит подростков от обнажёнки, размыв её в личных переписках
11.04.2024 [14:30],
Павел Котов
Instagram✴ начнёт тестировать функцию размытия изображений обнажённой натуры в личной переписке — это поможет защитить подростков и ограничит возможности мошенников. Владеющая платформой компания Meta✴ пошла на эту меру, чтобы развеять опасения по поводу вредоносного контента в её приложениях. 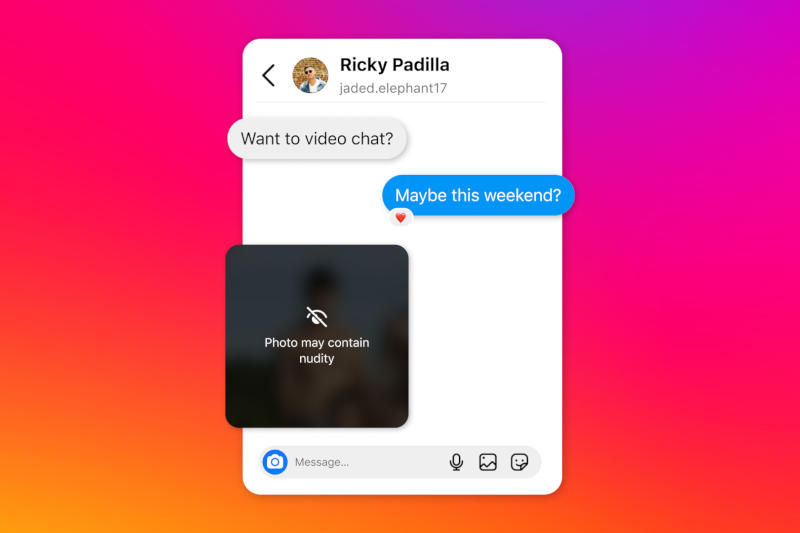
Источник изображения: Meta✴ Технологический гигант находится под давлением в США и Европе: компанию обвиняют в том, что её приложения вызывают привыкание и усугубляют проблемы с психическим здоровьем среди молодёжи. Новая функция защиты личной переписки в Instagram✴ будет основана на работающих локально на устройстве алгоритмах машинного обучения, которые помогут идентифицировать наготу в отправляемых через платформу изображениях. Функция будет включена по умолчанию для пользователей младше 18 лет — соответствующее уведомление получат и взрослые пользователи. «Поскольку изображения анализируются на самом устройстве, защита от [изображений] наготы также будет работать в чатах со сквозным шифрованием, в которых у Meta✴ не будет доступа к этим изображениям — если только кто-нибудь не решит сообщить нам о них», — пояснили в компании. В отличие от приложений Facebook✴ Messenger и WhatsApp, личная переписка в Instagram✴ не шифруется, но компания заявила, что планирует внедрить шифрование и здесь. Meta✴ также сообщила, что разрабатывает технологию, которая поможет идентифицировать учётные записи, предположительно замешанные в схемах секс-вымогательства, а взаимодействующие с такими учётными записями пользователи получат предупреждения. Meta✴ форсировала выпуск ИИ-чипа собственной разработки MTIA второго поколения с повышенной производительностью
10.04.2024 [20:30],
Сергей Сурабекянц
Чип Meta✴ Training and Inference Accelerator (MTIA) предназначен для обучения и запуска ИИ-систем, изначально разрабатывался для оптимальной работы с моделями ранжирования и рекомендаций Meta✴. MTIA является важной частью долгосрочного плана компании по созданию ИИ-инфраструктуры для своих сервисов. Чип первого поколения был анонсирован в мае 2023 года. Второе поколение ждали не раньше 2025 года, но компания сообщила, что свежий чип уже запущен в производство. 
Источник изображения: world-today-news.com По информации от Meta✴, новый чип MTIA «фундаментально ориентирован на обеспечение правильного баланса вычислительной производительности, пропускной способности и объёма памяти». Он получит 256 Мбайт встроенной памяти с частотой 1,3 ГГц по сравнению с 128 Мбайт и 800 МГц у первой версии. Ранние результаты испытаний Meta✴ на четырёх разных моделях ИИ показали, что новый чип MTIA 2 в среднем в три раза быстрее. Сейчас MTIA в основном применяется на алгоритмах ранжирования и рекомендаций, но в конечном итоге Meta✴ стремится расширить возможности чипа для работы с генеративным ИИ, таким, как большая языковая модель Llama. «Достижение наших амбиций в отношении специального чипа означает инвестирование не только в вычислительный кремний, но также в пропускную способность памяти, сеть и ёмкость, а также в другие аппаратные системы следующего поколения», — говорится в сообщении Meta✴. Компания планирует разработать и другие чипы искусственного интеллекта. Одним из таких проектов является Artemis — чип, специально разработанный для ускорения инференса. Другие компании, занимающиеся искусственным интеллектом, рассматривают возможность создания собственных чипов, поскольку спрос на вычислительную мощность растёт одновременно с ростом популярности систем искусственного интеллекта. Google выпустила свои чипы TPU, Microsoft анонсировала чипы Maia 100. У Amazon также есть собственный чип Trainium 2, обучение базовых моделей на котором происходит в четыре раза быстрее, чем на предыдущей версии. Бум искусственного интеллекта вынудил все крупные технологические компании приступить к разработке собственных ускорителей ИИ. Спрос на чипы настолько высок, что капитализация лидера этого рынка компании Nvidia достигла двух триллионов долларов. OpenAI и Meta✴ разрабатывают модели ИИ, способные рассуждать и планировать
10.04.2024 [18:00],
Павел Котов
OpenAI и Meta✴ приблизились к выпуску новых моделей искусственного интеллекта, которые, по их словам, будут способны рассуждать и планировать — это важные достижения на пути к созданию ИИ со сверхчеловеческим разумом. Об этом пишет Financial Times. 
Источник изображения: Kohji Asakawa / pixabay.com Руководство компаний OpenAI и Meta✴ доложило, что ведётся подготовка к выпуску больших языковых моделей нового поколения — систем, которые используются в приложениях генеративного ИИ, включая ChatGPT. Meta✴ готовится выпустить Llama 3 в ближайшие недели, а новая модель OpenAI GPT-5 появится «скоро», пообещали в компании. «Мы усердно трудимся над тем, чтобы заставить эти модели не просто говорить, но также рассуждать, планировать, <..> запоминать», — сообщила вице-президент Meta✴ по исследованиям в области ИИ Джоэль Пино (Joelle Pineau). О достижениях в этой области доложил и главный операционный директор OpenAI Брэд Лайткэп (Brad Lightcap): «Мы увидим ИИ, который сможет выполнять более сложные задачи более изощрёнными способами. Думаю, прикоснёмся к способности этих моделей рассуждать». Проекты Meta✴ и OpenAI последуют за волной больших языковых моделей, выпущенных в этом году Google, Anthropic и Cohere. Способности рассуждать и планировать — важные этапы на пути к созданию сильного ИИ (Artificial General Intelligence — AGI), обладающего сознанием на уровне человека. Выступая на мероприятии в Лондоне накануне, старший научный сотрудник Meta✴ по ИИ Янн ЛеКун (Yann LeCun) сказал, что нынешние системы ИИ «выдают одно слово за другим, по-настоящему не задумываясь и не планируя». Им затруднительно отвечать на сложные вопросы или запоминать информацию надолго, и они всё равно «совершают глупые ошибки». Способность рассуждать будет значить, что модель ИИ «подыскивает возможные ответы», «планирует последовательность действий» и выстраивает «мысленную модель того, каким будет эффект [её] действий». Для решения этой задачи он, в частности, разрабатывает «агенты» ИИ, способные распланировать путешествие из парижского в нью-йоркский офис с бронированием всех билетов, включая дорогу до аэропорта. В обозримом будущем Meta✴ готовится выпустить линейку моделей Llama 3 в ассортименте версий для различных приложений и устройств — новые модели компания планирует внедрить в мессенджер WhatsApp и умные очки Ray-Ban. В Meta✴ планируют увеличивать объёмы и сложность задач для ИИ, что потребует развития его способности рассуждать. Так, если камера очков Meta✴ Ray-Ban увидит сломанную кофемашину, подключённый к ним ассистент на базе Llama 3 даст рекомендации по её починке. Человек будет всё чаще общаться с ИИ-помощниками, считает Янн ЛеКун. OpenAI для обучения GPT-4 расшифровала миллионы видео с YouTube — текстов в интернете не хватило. Google тоже так делает
09.04.2024 [00:00],
Владимир Чижевский
Несколько дней назад сообщалось, что разработчики ИИ столкнулись с нехваткой данных для обучения передовых моделей, в том числе о планах Open AI обучать GPT-5 на видео с YouTube. Согласно материалу The New York Times, в погоне за новыми данными корпорации забывают об этике и морали. 
Источник изображения: freepik.com К концу 2021 года OpenAI столкнулась с нехваткой авторитетных англоязычных текстов в интернете для обучения новейшей модели искусственного интеллекта — ей требовалось гораздо больше данных. Тогда разработчики OpenAI создали расшифровывающую аудиозаписи из видеороликов на YouTube систему распознавания речи Whisper, которая выдаёт текст для обучения ИИ. По словам нескольких сотрудников, в компании понимали, что такой шаг может противоречить правилам использования YouTube, запрещающим использовать видеоролики «независимо» от платформы. Это не остановило OpenAI, расшифровавшую более миллиона часов видеороликов с YouTube. Полученный текст использовался для обучения GPT-4 — одной из мощнейших систем искусственного интеллекта в основе последней версии ChatGPT. В исследовании The New York Times говорится, что в гонку за данными включились все передовые разработчики ИИ, включая OpenAI, Google и Meta✴, причём компании зачастую игнорируют корпоративные политики, а иногда и закон. 
Джаред Каплан. Источник: physics-astronomy.jhu.edu В январе 2020 года физик-теоретик из Университета Джонса Хопкинса Джаред Каплан (Jared Kaplan) опубликовал работу об ИИ, которая разожгла аппетиты их разработчиков. Он высказался однозначно: чем больше данных используется для обучения языковой модели, тем лучше она работает, подобно тому, как студенты получают всё больше знаний из прочитанных книг. Языковые модели могут устанавливать закономерности и взаимосвязи, что позволяет точнее обрабатывать новую информацию. 
Сэм Альтман. Источник изображения: wikipedia.org Позднее Сэм Альтман (Sam Altman) из OpenAI заявил, что данные рано или поздно кончатся — он знает, о чём говорит, ведь компания годами собирала данные, обрабатывала и обучали на них ИИ. Среди использованных данных был программный код с GitHub, базы данных шахматных ходов, школьные тесты и домашние задания старшеклассников. К концу 2021 года они закончились. Помимо расшифровки аудио- и видеоматериалов, рассматривалась покупка компаний, имеющих доступ к огромным объёмам цифровых данных. 
Марк Цукерберг. Источник изображения: профиль в Facebook✴ Глава Meta✴ Марк Цукерберг (Mark Zuckerberg) годами развивал ИИ-направление, но выход ChatGPT в конце 2022 года оставил его компанию далеко позади. Трое бывших и нынешних сотрудников Meta✴ рассказали, что стремясь догнать OpenAI, он день и ночь донимал менеджеров и ведущих инженеров, чтобы те как можно скорее выпустили конкурирующий продукт. Но как и все остальные, Meta✴ упёрлась лбом в стену нехватки данных. 
Ахмад Аль-Дахле. Источник изображения: профиль на LinkedIn На одном из записанных совещаний руководства Meta✴ говорилось, что компания наняла субподрядчиков из Африки для сбора защищённых авторским правом материалов. «Мы не можем не собирать их», — сказали на одном из таких совещаний. Кроме того, подчёркивалось, что OpenAI тоже не стесняется использовать защищённые авторским правом материалы без разрешения их владельцев, и получать эти разрешения «слишком долго». Meta✴ ходатайствовала об отклонении антимонопольного иска FTC
06.04.2024 [11:17],
Павел Котов
Meta✴ попросила федеральный суд отказать в антимонопольном иске Федеральной торговой комиссии (FTC) США против компании — она утверждает, что ведомству не удалось собрать доказательства в поддержку своих обвинений. 
Источник изображения: succo / pixabay.com В поданном накануне ходатайстве о вынесении решения в порядке упрощённого производства Meta✴ утверждает, что иск следует отклонить: по версии компании, FTC не сможет доказать, что релевантный в представлении ведомства рынок действительно является таковым, или что поглощения Instagram✴ и WhatsApp нанесли ущерб потребителям. У FTC будет время подать отзыв на это заявление — стороны обменяются рядом документов, прежде чем судья решит, как действовать дальше. Решение в пользу Meta✴ будет означать окончание судебного процесса, но если суд постановит, что ещё остались неразрешенные фактические вопросы, может быть назначена дата разбирательства. В 2021 году судья округа Колумбия Джеймс Боусберг (James Boasberg) удовлетворил прошение Meta✴ (тогда Facebook✴) об отклонении иска, но дал FTC возможность подать исправленное исковое заявление, которому был дан ход. Он отметил, что в новой редакции документ «более убедителен и подробен, чем раньше», но предупредил, что ведомство «в будущем вполне может столкнуться с непростой задачей в попытках доказать свои обвинения». В своём ходатайстве Meta✴ критикует данное FTC определение рынка, характеризуя его как неоправданно узкое. Комиссия определила релевантный рынок как рынок служб персональных социальных сетей (Personal Social Networking Services — PSNS). Это сайты, на которых есть социальный граф, и пользователи могут общаться с членами семьи и друзьями на преимущественно личные темы. По версии ведомства, в него входят Facebook✴, Instagram✴, Snapchat и MeWe. «Первоначальное [исковое] заявление FTC было отклонено за отсутствием убедительного обвинения. Исправленное заявление частично повторяется, основываясь на стремлении FTC предоставить доказательства, которые подтвердят существование релевантного рынка PSNS, монопольное положение Meta✴ на этом рынке, а также вред, нанесённый конкуренции и потребителям в результате покупки Meta✴ [платформ] Instagram✴ и WhatsApp. <..> Обмен информацией между истцом и ответчиком показал, что FTC не сможет представить доказательств ни по одному из пунктов своего иска по второму разделу», — говорится в заявлении Meta✴. 
Источник изображения: Gerd Altmann / pixabay.com FTC не включила в своё определение релевантного рынка TikTok и YouTube, утверждая, что эти сервисы служат другой цели. TikTok не «движим желанием пользователей взаимодействовать с сетью из друзей и членов семьи»; а YouTube используется «в первую очередь для пассивного потребления определённого медиаконтента (например, видеороликов и музыки) от и для широкой аудитории обычно неизвестных пользователей». Сторона Meta✴ считает, что это неправильно, и обращает внимание суда на механизмы распространения контента в Instagram✴, TikTok и YouTube. «FTC утверждает, что 100 % времени, потраченного на Reels, приходятся на PSNS, включая просмотр роликов, опубликованных знаменитостями, блогерами и публичными страницами без связи со зрителем. Далее FTC утверждает, что 100 % времени, потраченного на просмотр идентичных коротких видеороликов на TikTok и восьми роликов на YouTube Shorts — вне зависимости от того, опубликованы они людьми, которых пользователь действительно знает, или нет — к PSNS не относятся», — рассуждает Meta✴. По версии компании, ведомство «должно доказать, что её рынок — кандидат включает в себя все разумные альтернативы». Не имеет значения, существуют ли различия между сервисами, пока «потребители считают их приемлемыми альтернативами, несмотря на такие различия». Релевантный рынок, уверены в Meta✴, должен включать YouTube и TikTok, а значит, FTC не имеет оснований обвинять компанию в его монополизации — обычно для этого нужна доля как минимум в 60 % рынка. FTC, считают в компании, также не сможет доказать, что поглощения Instagram✴ и WhatsApp нанесли вред потребителям. Комиссия сама разрешила покупку около десяти лет назад, хотя технически антимонопольные органы могут оспаривать слияния в любой момент по своему усмотрению. Иск FTC по этому делу знаменует «первую попытку пересмотреть поглощения, изученные и одобренные FTC более десяти лет назад» — такой шаг, говорят в Meta✴, «сам по себе угрожает полезной конкуренции и не имеет оснований». Более того, выдача «разрешения FTC на эти поглощения должна создавать презумпцию того, что они не были антиконкурентными, и у FTC нет доказательств для его отзыва». «За десять или более лет с момента приобретения Instagram✴ и WhatsApp принесли чрезвычайное благо потребителям — большим ростом бесплатных сервисов, их существенным улучшением и постоянным инновациям в функциональности», — напомнили в Meta✴. Компания считает, что невозможно оценить, какими бы сейчас стали эти сервисы, если бы поглощений не было, но она вложила в развитие приложений миллиарды и даже отменила плату для пользователей WhatsApp. Meta✴ предупреждает, что оспаривание поглощения может быть опасным для инновационного развития сервисов. «Решение вернуться к заключённым сделкам равносильно утверждению, что ни одна продажа никогда не будет окончательной», — заключили в Meta✴. Отзыв на ходатайство компании FTC может подать до 24 мая. Instagram✴ зарабатывает на рекламе больше YouTube — тенденция сохраняется уже несколько лет
06.04.2024 [10:05],
Владимир Фетисов
На этой неделе компания Meta✴ Platforms обратилась в федеральный суд с ходатайством с просьбой отклонить антимонопольный иск Федеральной торговой комиссии (FTC) США. В переданных суду документах содержится подробная информация о рекламных доходах Instagram✴ за последние годы. Оказалось, что по этому показателю социальная сеть обгоняет YouTube. 
Источник изображения: StartupStockPhotos / Pixabay В 2021 году реклама принесла Instagram✴ $32,4 млрд, тогда как доход YouTube за аналогичный период составил $28,8 млрд. По данным источника, такая тенденция обусловлена тем, что YouTube отдаёт 55 % с каждого рекламного доллара владельцам контента, загружающим ролики на платформу. В это же время Instagram✴ платит авторам контента значительно меньше. Аналогичным образом выглядит ситуация за более ранний период. В 2020 и 2019 года Meta✴ оценивала рекламный доход Instagram✴ в $22 млрд и $17,9 млрд соответственно, тогда как доход YouTube за те же годы составил $19,7 млрд и $15,1 млрд. По данным издания Bloomberg, доля доходов Meta✴ от Instagram✴ подскочила с 26 % в 2020 году до почти 30 % за первые шесть месяцев 2022 года. Документы, которые Meta✴ направила в суд, дают больше информации о доходах компании, чем регулярно публикуемая финансовая отчётность. В частности, они дают понять, насколько важным сегментом бизнеса компании является Instagram✴. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться