Meta✴ объявила о разработке модели искусственного интеллекта с открытым кодом, которая способна обрабатывать шесть потоков данных: текст, звук, статическое и динамическое изображение (видео), температуру, информацию о глубине сцены, а также информацию о движении.
Источник изображения: Meta✴
ИИ-модель ImageBind пока представляет собой исследовательский проект, о возможном практическом применении которого пока не говорится ничего, но этот проект указывает на перспективы генеративных систем. Стоит также отметить, что Meta✴ упорно продолжает делиться своими разработками с общественностью, тогда как её конкуренты масштаба OpenAI и Google становятся всё более закрытыми.
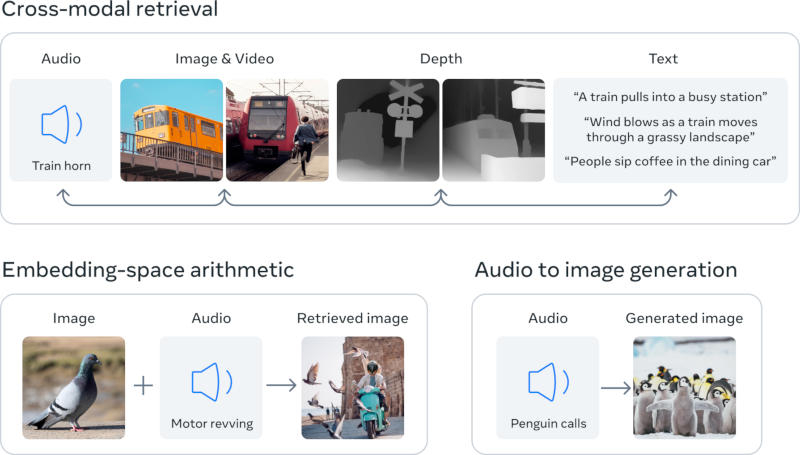
Ключевая концепция исследования — объединение данных различных типов в многомерный индекс. Это своеобразное развитие идеи генеративных ИИ, которые сегодня доступны потребителю. К примеру, генераторы изображений вроде DALL-E, Stable Diffusion и Midjourney обучаются на сопоставлении текста и изображения, то есть двух типов данных: нейросеть ищет закономерности в визуальных данных, которые связываются с описаниями изображений. Это в итоге позволяет системам генерировать картинки по произвольным описаниям. Схожим образом работают генераторы аудио и видео.
Проект ImageBind — попытка поместить в единое пространство сразу шесть типов данных: визуальные, в том числе неподвижные картинки и видео; тепловые, то есть информацию от инфракрасных сенсоров; текст; звук; данные о глубине; данные о движении от инерциального измерительного блока (IMU) — такие используются в смартфонах и смарт-часах. Разработчики платформы пытаются обучить её работать с этими данными так же, как с текстом или изображениями. Обученная таким образом будущая система виртуальной реальности сможет генерировать целостные окружения: так, если попросить её сымитировать морское путешествие, она поместит пользователя на корабль с шумом волн на заднем плане, дополнив его раскачивающейся палубой и океанским бризом.
В перспективе инженеры Meta✴ предполагают и далее расширять потоки сенсорных данных, добавив «осязание, речь, обоняние и сигналы функциональной МРТ мозга». Машины же, в свою очередь, получат возможность самообучаться в реальном времени на информации в различных формах.