Инженеры «Сбера» выложили в открытый доступ нейросетевую модель ruGPT-3.5, лежащую в основе сервиса GigaChat, который до сих пор проходит стадию закрытого тестирования. Лицензия MIT позволяет использовать материалы проекта в коммерческих целях.
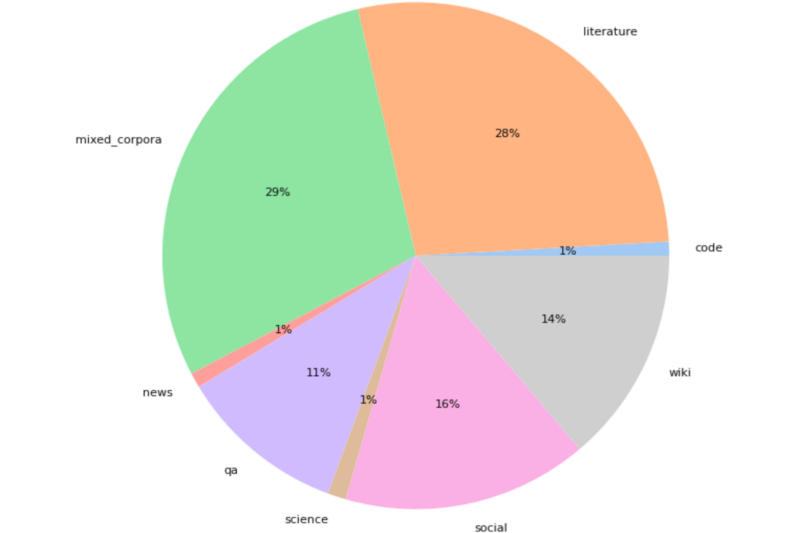
Структура датасета ruGPT-3.5. Источник изображения: habr.com
Важнейшим недостатком открытых больших языковых моделей вроде Meta✴ LlaMA является ограниченная поддержка русского языка — обычно это русский раздел «Википедии» и некоторое количество общедоступных текстов. Это оказывает негативное влияние на понимание моделью языка и качество её ответов. Модель ruGPT-3.5, основанная на архитектуре OpenAI GPT-3, создана в первую очередь для работы в русскоязычной среде, поэтому она более качественно обрабатывает такие запросы.
Обучение модели производилось в два этапа. Первый этап продлился 1,5 месяца — за это время платформа обработала 300 Гбайт данных: книги, энциклопедийные и научные статьи, социальные ресурсы и другие источники. Потребовались ресурсы 512 ускорителей NVIDIA V100. На втором этапе проводилось дообучение на 110 Гбайт данных из датасета The Stack, юридических документов и обновлённых текстов «Википедии» — это заняло три недели и потребовало 200 ускорителей NVIDIA A100.
В результате у ruGPT-3.5 13 млрд параметров при длине контекста 2048 токенов — для сравнения, привели пример разработчики, рассказ А. П. Чехова «Хамелеон» разбивается на 1650 токенов при его длине в 901 слово.