Один из ведущих разработчиков чипов для работы с системами искусственного интеллекта Cerebras Systems совместно с облачным провайдером G42 представил проект по созданию девяти мощных суперкомпьютеров, заточенных под задачи ИИ. Первой из них станет система CG-1 (Condor Galaxy 1), которая первой в мире достигнет производительности в 4 Эфлопс в задачах искусственного интеллекта. Случится это уже к концу текущего года.

Источник изображений: cerebras.net
Суперкомпьютер Condor Galaxy 1 отличают следующие технические характеристики:
Компания Cerebras Systems известна благодаря своей платформе CS-2 на базе гигантских чипов Wafer-Scale Engine 2 (WSE-2) с 2,6 трлн транзисторов — такой чип производится из целой кремниевой пластины и содержит 850 тыс. тензорных ИИ-ядер. На первом этапе Condor Galaxy 1 получит 32 системы Cerebras CS-2, которые обеспечат ему производительность в 2 Эфлопс, а к концу текущего года их число удвоится, как и производительность суперкомпьютера, которая вырастет до 4 Эфлопс (второй этап).
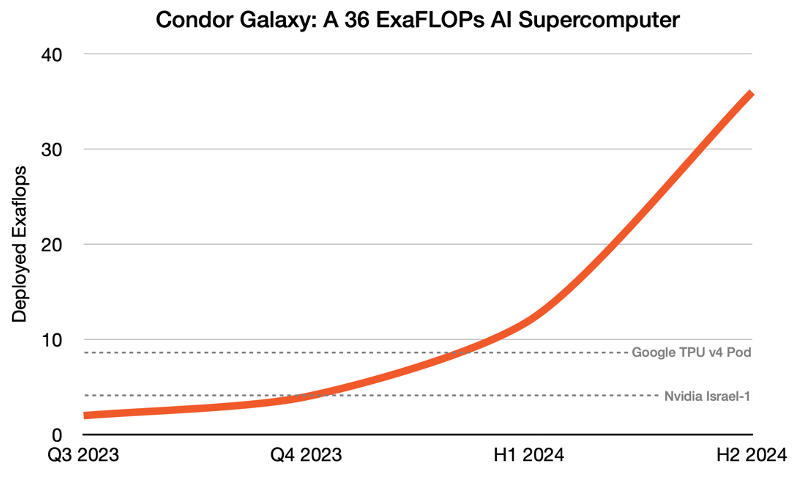
На этом в Cerebras Systems решили не останавливаться: далее запланировано создание суперкомпьютеров CG-2 и CG-3, которые на третьем этапе в первой половине 2024 года будут объединены в первую распределенную сеть суперкомпьютеров на базе 192 систем CS-2 общей производительностью 12 Эфлопс. Наконец, на четвёртом этапе к этой сети подключат ещё шесть суперкомпьютеров, обеспечив таким образом совместную работу 576 систем CS-2 и 36 Эфлопс.
В компании подчеркнули, что кластеры Wafer-Scale изначально предназначены для работы в качестве единого ускорителя. Единый блок памяти CG-1 объёмом 82 Тбайт позволяет размещать даже самые большие ИИ-модели непосредственно в памяти без необходимости в дополнительных программных решениях. Иными словами, в инфраструктуре Cerebras модели с 1 млрд и 100 млрд параметров работают на базе единого кода с поддержкой длинных последовательностей в 50 000 токенов.
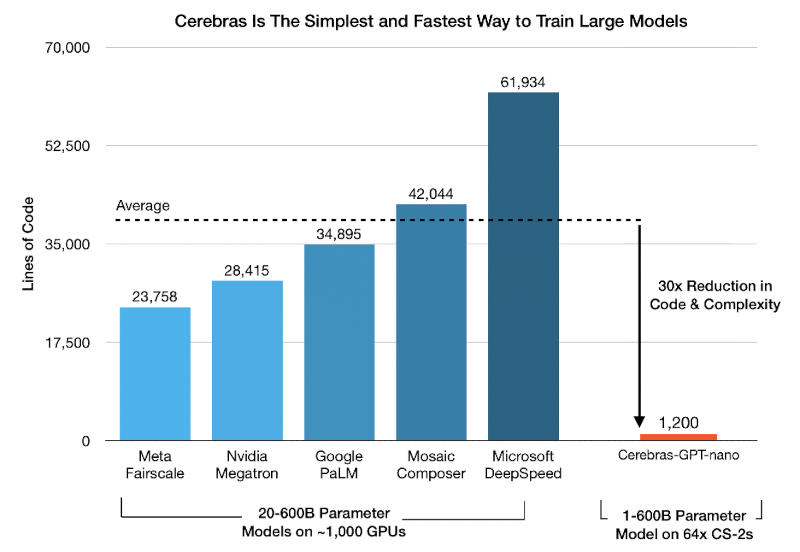
В результате стандартная реализация GPT на CG-1 потребует всего 1200 строк кода — в 30 раз меньше существующих аналогов. А масштабирование системы производится при помощи выделения кратного объёма ресурсов в простой линейной зависимости. То есть модель с 40 млрд параметров обучается в 40 раз дольше модели с 1 млрд параметров при тех же ресурсах — или за то же время, если увеличить объёмы ресурсов в 40 раз.