Учёные из лаборатории исследований искусственного интеллекта Tinkoff Research разработали SAC-RND — новый алгоритм для обучения ИИ. На робототехнических симуляторах было достигнуто повышение скорости обучения в 20 раз по сравнению со всеми существующими аналогами при возросшем на 10 % качестве. Оптимизация крайне ресурсоёмкого процесса обучения ИИ ускорит развитие многих сфер, где применяется ИИ.

Источник изображения: Tinkoff
Разработчики утверждают, что SAC-RND может «повысить безопасность беспилотных автомобилей, упростить логистические цепочки, ускорить доставку и работу складов, оптимизировать процессы горения на энергетических объектах и сократить выбросы вредных веществ в окружающую среду. Открытие не только улучшает работу узкоспециализированных роботов, но и приближает нас к созданию универсального робота, способного в одиночку выполнять любые задачи».
Результаты исследования были представлены в конце июня на 40-й Международной конференции по машинному обучению (ICML) в Гонолулу, Гавайи. Эта конференция является одной из трёх крупнейших в мире в сфере машинного обучения и искусственного интеллекта.
Одним из наиболее перспективных видов обучения ИИ является обучение с подкреплением (RL), позволяющее ИИ учиться методом проб и ошибок, адаптироваться в сложных средах и изменять поведение на ходу. Обучение с подкреплением может использоваться во всех сферах: от регулирования пробок на дорогах до рекомендаций в социальных сетях.
При этом ранее считалось, что использование случайных нейросетей (RND) не применимо для офлайн-обучения с подкреплением. В методе RND используются две нейросети — случайная и основная, которая пытается предсказать поведение первой. Свойство нейросети определяются её глубиной — количеством слоёв, из которых она состоит. Основная сеть должна содержать больше слоёв, чем случайная, иначе моделирование и обучение становится нестабильным или даже невозможным.
Использование неправильных размеров сетей привело к ошибочному выводу, что метод RND не умеет дискриминировать данные — отличать действия из датасета от прочих. Исследователи из Tinkoff Research обнаружили, что при использовании эквивалентной глубины сетей, метод RND начинает качественно различать данные. Затем исследователи приступили к оптимизации ввода и научили роботов приходить к эффективным решениям при помощи механизма слияния, основанного на модуляции сигналов и их линейном отображении. До этого при использовании метода RND поступающие сигналы не подвергались дополнительной обработке.
На визуализации ниже в верхнем ряду показаны предыдущие попытки применения метода RND, в нижнем — метод SAC-RND. Стрелки на изображении должны вести робота в одну точку — они указывают направление к правильному действию. Метод Tinkoff Research во всех случаях стабильно приводит робота в нужную точку
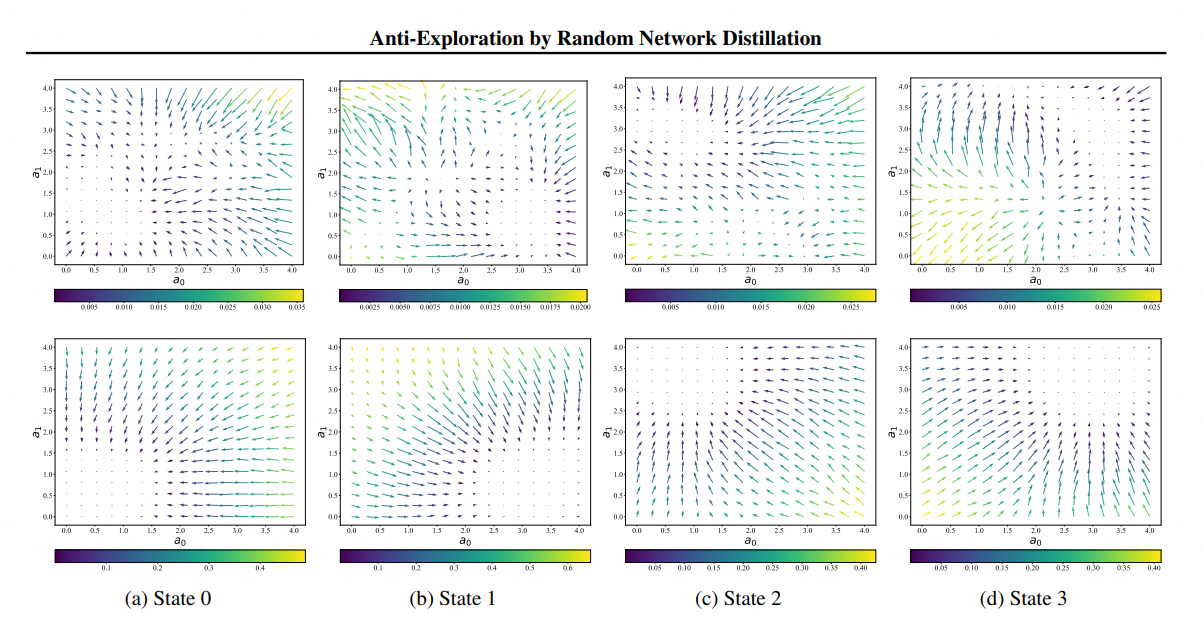
Визуализация принятия решения роботами, обученными с помощью разных алгоритмов. Источник изображения: Tinkoff Research
Метод SAC-RND был протестирован на робототехнических симуляторах и показал лучшие результаты при меньшем количестве потребляемых ресурсов и времени. Открытие поможет ускорить исследования в области робототехники и обучения с подкреплением, поскольку оно снижает время получения устойчивого результата в 20 раз и является важным шагом на пути к созданию универсального робота.
Tinkoff Research — российская исследовательская некоммерческая группа. Учёные из Tinkoff Research исследуют наиболее перспективные области ИИ: обработку естественного языка (NLP), компьютерное зрение (CV), обучение с подкреплением (RL) и рекомендательные системы (RecSys). Команда курирует исследовательскую лабораторию «Тинькофф» на базе МФТИ и помогает талантливым студентам совершать научные открытия.