Meta✴ доложила о результатах последних исследований в области искусственного интеллекта в рамках проектов FAIR (Fundamental AI Research). Специалисты компании разработали модель ИИ, которая отвечает за правдоподобные движения у виртуальных персонажей; модель, которая оперирует не токенами — языковыми единицами, — а понятиями; и многое другое.

Источник изображения: Google DeepMind / unsplash.com
Модель Meta✴ Motivo управляет движениями виртуальных человекоподобных персонажей при выполнении сложных задач. Она была обучена с подкреплением на неразмеченном массиве с данными о движениях человеческого тела — эта система сможет использоваться в качестве вспомогательной при проектировании движений и положений тела персонажей. «Meta✴ Motivo способна решать широкий спектр задач управления всем телом, в том числе отслеживание движения, принятие целевой позы <..> без какой-либо дополнительной подготовки или планирования», — рассказали в компании.
Важным достижением стало создание большой понятийной модели (Large Concept Model или LCM) — альтернативы традиционным большим языковым моделям. Исследователи Meta✴ обратили внимание, что современные передовые системы ИИ работают на уровне токенов — языковых единиц, обычно представляющих фрагмент слова, но не демонстрируют явных иерархических рассуждений. В LCM механизм рассуждения отделён от языкового представления — схожим образом человек сначала формирует последовательность понятий, после чего облекает её в словесную форму. Так, при проведении серии презентаций на одну тему у докладчика уже есть сформированная серия понятий, но формулировки в речи могут меняться от одного мероприятия к другому.
При формировании ответа за запрос LCM предсказывает последовательность не токенов, а представленных полными предложениями понятий в мультимодальном и многоязычном пространстве. По мере увеличения контекста на вводе архитектура LCM, по мнению разработчиков, представляется более эффективной на вычислительном уровне. На практике эта работа поможет повысить качество работы языковых моделей с любой модальностью, то есть форматом данных, или при выводе ответов на любом языке.
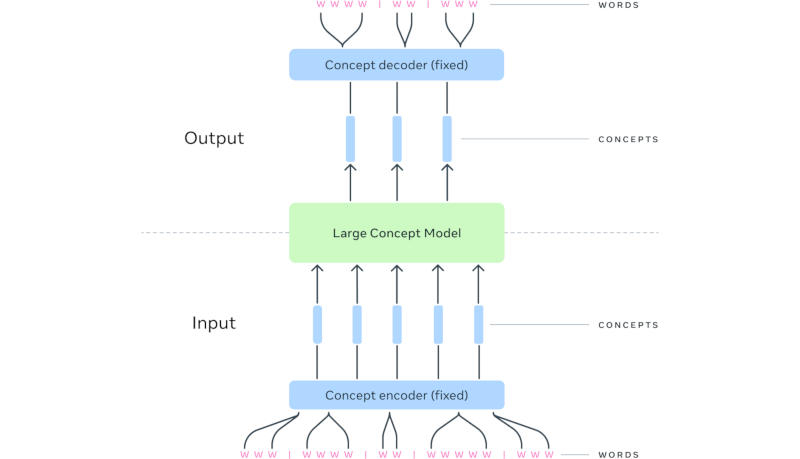
Источник изображения: Meta✴
Механизм Meta✴ Dynamic Byte Latent Transformer также предлагает альтернативу языковым токенам, но не посредством их расширения до понятий, а, напротив, путём формирования иерархической модели на уровне байтов. Это, по словам разработчиков, повышает эффективность при работе с длинными последовательностями при обучении и запуске моделей. Вспомогательный инструмент Meta✴ Explore Theory-of-Mind предназначается для привития навыков социального интеллекта моделям ИИ при их обучении, для оценки эффективности моделей в этих задачах и для тонкой настройки уже обученных систем ИИ. Meta✴ Explore Theory-of-Mind не ограничивается заданным диапазоном взаимодействий, а генерирует собственные сценарии.
Технология Meta✴ Memory Layers at Scale направлена на оптимизацию механизмов фактической памяти у больших языковых моделей. По мере увеличения числа параметров у моделей работа с фактической памятью требует всё больших ресурсов, и новый механизм направлен на их экономию. Проект Meta✴ Image Diversity Modeling, который реализуется с привлечением сторонних экспертов, направлен на повышение приоритета генерируемых ИИ изображений, которые более точно соответствуют объектам реального мира; он также способствует повышению безопасности и ответственности разработчиков при создании картинок с помощью ИИ.
Модель Meta✴ CLIP 1.2 — новый вариант системы, предназначенной для установки связи между текстовыми и визуальными данными. Она используется в том числе и для обучения других моделей ИИ. Инструмент Meta✴ Video Seal предназначен для создания водяных знаков на видеороликах, генерируемых при помощи ИИ — эта маркировка незаметна при просмотре видео невооружённым глазом, но может обнаруживаться, чтобы определить происхождение видео. Водяной знак сохраняется при редактировании, включая наложение эффекта размытия, и при кодировании с использованием различных алгоритмов сжатия. Наконец, в Meta✴ напомнили о парадигме Flow Matching, которая может использоваться при генерации изображений, видео, звука и даже трёхмерных структуры, в том числе белковых молекул — это решение помогает использовать информацию о движении между различным частями изображения и выступает альтернативой механизму диффузии.