В то время, когда 3dfx была на коне, народ искал Voodoo2-киллеров, которые дали бы большую производительность по сравнимой цене. Именно тогда начался успех компании nVidia, превратившейся сегодня в огромного монстра. Примерно в момент выхода GeForce2 компания заматерела, перейдя из разряда догоняющих в лидеры. Многие пытались сместить с трона 3D графики nVidia, но никто так и не достиг в этом успеха. Причина ясна – nVidia обладает тремя дизайн-командами, работающими параллельно и состоящими из бывших сотрудников самых прославившихся графических фирм в индустрии (3dfx, Appian, Matrox, PixelFusion и др.). Добавим высокий коэффициент удержания персонала – более 95% сотрудников компании работают в компании более 5 лет, одаренность программных инженеров (в компании больше программных, нежели аппаратных инженеров) и, конечно, огромный капитал компании.
Обеспокоена ли nVidia выходом 3DLabs P10? Конечно да, потому что хорошо помнит свою историю, как она сама
вышла на рынок. Но существует очень небольшой шанс того, что в следующие несколько месяцев какие-либо конкурирующие компании отнимут заметную рыночную долю от nVidia. Однако в промежутке между выходами новых продуктов от nVidia компании могут привлечь внимание к своим графическим решениям. ATI уже использовала подобный подход с Radeon 8500 и с намного более успешным Radeon 8500LE 128 Мб. 3DLabs также вклинилась со своим P10 VPU, и вот настала очередь Matrox.
Компания отошла от 3D рынка примерно два года назад, но сегодня они пришли к пониманию, что и далее игнорировать рынок производительной 3D графики нельзя.

К великому счастью (как для Matrox, так и конечных пользователей), Parhelia-512 не является дальнейшим развитием ядра G400. Parhelia-512 – это результат более чем двухлетней работы инженеров Matrox, причем чип уже готов к публичному выпуску.
Перед глубоким анализом архитектуры Matrox давайте обратимся к спецификациям.
| Чип | Parhelia-512 | P10 | GeForce4 (NV25) | Radeon R200 |
| Число транзисторов | 80M | 76M | 63M | 60M |
| Техпроцесс | 0,15 мкм | 0,15 мкм | 0,15 мкм | 0,15 мкм |
| Ширина шины памяти | 256-битная DDR | 256-битная DDR | 128-битная DDR | 128-битная DDR |
| Пиковая пропускная способность памяти | 20 Гбайт/с | 20 Гбайт/с | 10 Гбайт/с | 10 Гбайт/с |
| Программируемость | 4 програм. модуля vect4 вершинных шейдеров | Универсальная, включая циклы и процедуры | Ограничена DX8 вершинными и пиксельными шейдерами | Ограничена DX8.1 вершинными и пиксельными шейдерами |
| Точность цвета ЦАП | 10 bpp | 10 bpp | 8 bpp | 8 bpp |
| Поддержка мониторов | Три | Два | Два | Два |
Мы не будем еще раз подробно описывать все ступени конвейера рендеринга Parhelia-512, поскольку они подробно освещены в статье про 3DLabs P10 VPU.
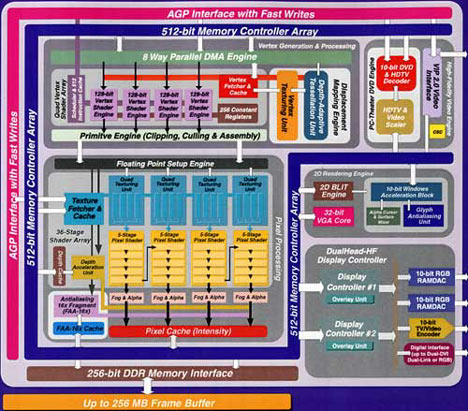
Мы уже разобрались, откуда появилось имя Parhelia. Теперь настала очередь разобраться с числом 512. Как вы увидите ниже, 512 используется во многих местах архитектуры Parhelia. Ну а в целом решение назвать чип Parhelia-512 очень близко по смыслу к переименованию NV10 в GeForce256.
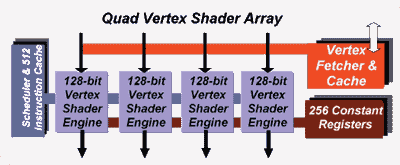
Массив из четырех модулей вершинных шейдеров
В самом начале графического конвейера Parhelia-512 (после AGP интерфейса) находятся вершинные процессоры. Matrox включила в Parhelia-512 четыре модуля вершинных шейдеров, называемых "128-битный движок вершинных шейдеров/128-bit vertex shader engine". Если вы умножите 128 бит на 4 модуля, то получите магическое число 512. 128 бит получаются из расчета, что каждый из этих модулей может работать с четырьмя 32-битными числами с плавающей точкой одновременно, при условии что они составляют 4-операндный вектор. Движки вершинных шейдеров совместимы с двумя движками вершинных шейдеров в GeForce4 или с четырьмя вершинными процессорами в 3DLabs P10. Так что Parhelia-512 может работать с шейдерами в два раза быстрее GeForce4 при равных тактовых частотах.
Модули вершинных шейдеров Parhelia полностью совместимы с DX8.1 и предлагают даже большую гибкость, чем DX8.1, поэтому в дальнейшем будет объявлена совместимость с версией 2.0 (DX9). Впрочем, такая гибкость будет полезна, прежде всего, разработчикам до тех пор, пока весь конвейер (в его пиксельных и вершинных частях) не будет совместим с DX9. Помните, что основная цель модулей вершинных шейдеров заключается в подготовке вершин для последующих операций, осуществляемых модулями пиксельных шейдеров. Однако если пиксельные шейдеры не будут столь же гибки и программируемы, или если они не будут использовать числа с плавающей точкой, то вы можете бесконечно улучшать вершинные шейдеры, но вы будете ограничены пиксельными шейдерами.
После того, как вершины выйдут из движков вершинных шейдеров, они передаются на движок примитивов, который начинает собирать треугольники и отбрасывать вершины, выходящие за пределы экрана. Здесь обычно находится логика по отбрасыванию невидимых вершин, скрытых за поверхностями, чтобы чип не отрисовывал ненужные пиксели. К примеру, в Radeon 8500 используется технология HyperZ, а в GeForce4 – визуальная подсистема. Однако Matrox пришлось идти на компромисс с реализацией других возможностей, так что в Parhelia-512 не используется системы по отбрасыванию невидимых вершин, как у конкурентов.
В Parhelia-512 задействована логика быстрой очистки по Z (Fast Z-clear), которая нужна для быстрого заполнения Z-буфера массивами нулей. Подобная технология реализована в чипах ATi и nVidia. С таким количеством пропускной способности памяти, Parhelia-512 может обходиться и без использования эффективной технологии управления памятью, что потенциально может привести к задержкам только в будущих более сложных играх. Если вы накладываете большую пиксельную программу-шейдер (скажем, 50-100 инструкций) на пиксель, то при этом вы тратите жизненно важные такты. Однако если пиксель так никогда и не будет показан, то значительная часть исполнительных ресурсов пошла впустую. Как только все большее число игр будет задействовать пиксельные шейдеры DX8, то подобные недостатки смогут стать "Ахиллесовой пятой" Parhelia.
Ниже по конвейеру расположены четыре конвейера рендеринга пикселей. Такой учетверенный подход схож с nVidia GeForce256 и ATI Radeon 8500, или даже с 3DLabs P10. Собственно, именно по этой причине Matrox и выбрала такое решение. Но где Matrox действительно отличается от конкурентов, так это в возможности Parhelia в обработке четырех текстур на конвейер за такт, против двух у всех конкурентов. Благодаря такой особенности Parhelia-512 может обеспечить значительно более высокую производительность в играх следующего поколения, в которых используется несколько текстур. Причем этот шаг Matrox в достаточной степени безопасен, так как для разработчика намного легче задействовать несколько текстурных слоев, чем использовать пиксельные программы-шейдеры, учитывая сложность написания подобных программ и то малое количество карт, которые совместимы с пиксельными шейдерами DX8. В будущем ситуация, конечно, изменится, но живем то мы сейчас.
![]()
Каждый из текстурных модулей достаточно гибок для выделения вычислительных ресурсов в зависимости от типа приложения. К примеру, в Quake III Arena с преимущественно двойным текстурированием, Parhelia-512 может использовать незадействованные ресурсы текстурирования для осуществления 8-tap анизотропной и трилинейной фильтрации практически без ущерба производительности. Такая функция как нельзя лучше подходит для современных игр.
В каждом из текстурных модулей вычисляются координаты текстуры, текстура загружается и фильтруется, и, наконец, пиксели отсылаются на модули пиксельных шейдеров Parhelia-512.
Программируемость пиксельных шейдеров в Parhelia-512 не выше GeForce4, что означает их принадлежность больше к эффективным регистровым комбайнам, нежели к полностью программируемым модулям. В то же время они работают с целочисленными данными, а не с 32-битными числами с плавающей запятой, что требуется для совместимости с DX9. Таким образом, Matrox не может объявить о наличии этих двух ключевых функций, причиной чего, как и раньше, являются жесткие ограничения на площадь чипа. Поскольку чип изготовляется по 0,15 мкм техпроцессу и на нем присутствуют 80 млн транзисторов, Matrox пошла на ряд уступок для получения максимальной производительности под современными и будущими DX8 приложениями. Поэтому в Parhelia-512 нельзя назвать пиксельные шейдеры полностью программируемыми. Как уже упоминалось в обзоре 3DLabs P10, для перехода конвейера на числа с плавающей точкой, вам нужен, по крайней мере, 0,13 мкм техпроцесс, который придет в нормальное отлаженное состояние (на TSMC) только осенью.
Если сравнить с GeForce4, то конвейер пиксельных шейдеров в Parhelia-512 прогрессивнее, поскольку здесь мы наблюдаем пять ступеней конвейера пиксельных шейдеров (по сравнению с двумя в GeForce4). Таким образом, количество проходов по конвейеру пиксельных шейдеров в Parhelia-512 можно сократить, поскольку чип может не только выполнять 5 операций пиксельного шейдера за один проход на одном конвейере, но и выполнять 10 операций пиксельного шейдера за один проход на двух конвейерах. Как вы знаете, меньшее количество проходов обеспечивает большую пропускную способность и экономию ресурсов.
Итак, основной 3D конвейер Parhelia подходит к концу. Дальше данные отсылаются по 256-битной DDR шине памяти (256x2 опять же дают магическое число 512). Но мы пропустили две очень важные части конвейера, так что давайте остановимся на них поподробнее.

Детализация рельефа, осуществляемая путем
использования большего количества полигонов
Цель HDM заключается в получении более реалистичных 3D окружений и персонажей с использованием большего количества геометрии (большее количество вершин), но достигается эта цель максимально простым и компактным способном из всех возможных. Скажем, вам нужно создать детализированную 3D карту поверхности Марса. Для этого вы можете просто увеличить число полигонов сцены для отражения каждой впадины на поверхности планеты. Однако если вы посмотрите на иллюстрацию выше, то вы заметите, что такой подход значительно увеличивает число полигонов. Если, скажем, такая поверхность будет использоваться в Unreal Tournament 2003, то вы получите значительный удар по производительности при росте числа полигонов выше оптимального значения.
HDM решает описанную проблему по генерации большего числа геометрических деталей, возникающую при попытке создать более детализированное 3D окружение и персонажей. Для этого берется исходная сетка треугольников и на нее накладывается карта смещения. Карта смещения очень похожа на 2D текстуру, за исключением того, что вместо цветовых значений в каждой точке в ней используется значение смещение каждой точки карты (отсюда и имя). Когда вы накладываете карту текстуры на полигон, каждый пиксель внутри полигона принимает цвет соответствующего пикселя карты текстуры. Точно так же, когда вы накладываете карту смещения на полигон, каждый пиксель внутри полигона смещается на значение соответствующего пикселя карты смещения. К примеру, если координата (1,1) на карте смещения показывает значение +10, то соответствующая координата сетки будет поднята на 10 позиций. Нижняя иллюстрация поможет вам наглядно понять весь процесс.

Точно такая же карта смещения может быть наложена и на персонажей. Если у вас есть один герой, вы можете наложить на него разные карты смещения. Таким образом, вы можете изменять вид персонажа и получить несколько персонажей из одного. Карта смещения с большими значениями ближе к центру карты может дать персонажу большой живот, а в другом месте – накачанные мускулы и т.д.
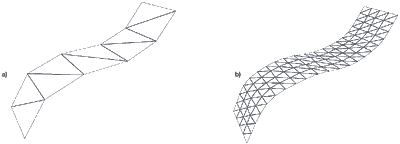
Сетка справа является сеткой слева после тесселяции
Название тесселяция по глубине говорит само за себя, но мы все же постараемся детально ее рассмотреть, чтобы вы смогли оценить все ее преимущества. Поскольку пример с 3D ландшафтом самый наглядный, мы вновь его используем. Как только вершины, создающие сетку треугольников посланы на GPU, сетка будет тесселирована для повышения детализации. Однако во время процесса тесселяции, тесселяцией по глубине позволяет использовать различные уровни детализации (level of details, LOD) вдоль поверхности сетки. Чем дальше элемент сетки находится от экрана, тем более низкий уровень детализации используется. Затем карта смещения накладывается на тесселированную сетку, и каждая вершина смещается на соответствующее значение карты.

Теперь давайте поговорим о перемещении по сцене. Если мы стоим в одном углу территории, то мы ясно видим только лишь небольшую часть рельефа, так что эту часть необходимо отображать с максимально возможным уровнем детализации (наиболее тесселированная сетка, и соответственно, максимально возможное число полигонов без значимого ущерба производительности). Та же часть рельефа, которую мы четко не видим, должна быть отображена с уменьшенным уровнем детализации, что приведет к уменьшению тесселяции, и соответственно, уменьшит число полигонов сцены. Как только вы будете двигаться по сцене, то уровни детализации будут изменяться в зависимости от вашего местоположения, таким образом, на всем окружающем пространстве используется адаптивная тесселяция основной сетки полигонов в зависимости от местоположения пользователя. Следовательно, мы всегда получаем максимально детализированные полигоны без потери производительности на тесселяцию удаленных частей окружения, где большое число полигонов не нужно.
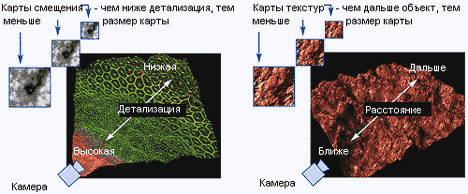
Такой подход очень близок к кратной фильтрации (mip-mapping) в части текстур, но он также применяется и для карт смещения. Matrox лицензировала технологию Microsoft для использования в DX9, и мы наверняка станем свидетелями того, как и другие производители внесут схожую функциональность в свои будущие GPU.
Основное преимущество HDM заключается в том, что, используя технологии типа тесселяции по глубине, вы можете получить достаточно детализированную сцену, используя базовую сетку с низким количеством полигонов и очень маленькие карты смещения (размером в несколько килобайт). Благодаря чему экономится пропускная способность памяти и AGP шины, в то же время получаемые сцены отличаются высокой детализацией.
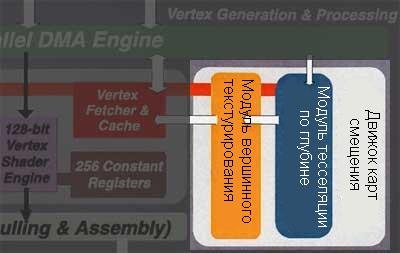
HDM движок Parhelia-512 находится в самом начале конвейера
параллельно со ступенями установки вершин и
вершинными шейдерами.
FAA движок в Parhelia определяет граничные пиксели с 16 отсчетами на точку экрана (16x). То есть каждый пиксель делится на 16 частей, и цвета каждой части анализируются для определения того, покрыт ли пиксель и насколько полно. Все пиксели, которые были определены как частично покрытые (то есть они находятся на краю треугольника), посылаются в FAA движок, где над ними производится сглаживание. Благодаря использованию 16 отсчетов на пиксель технология была названа 16x FAA.
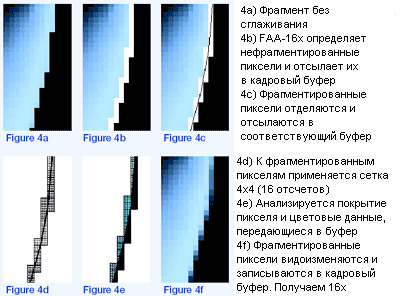
Красота данного метода заключается в том, что пиксели, не принадлежащие границам полигона, напрямую записываются в кадровый буфер, минуя FAA движок, что экономит драгоценную пропускную способность. В соответствии с данными Matrox, число фрагментированных пикселей находится примерно в границах от 5 до 10% от всех пикселей сцены. Вы можете представить, насколько такая технология позволяет увеличивать производительность при использовании сглаживания.
Из-за такого способа работы выявляется еще одна интересная особенность – чем выше вы ставите разрешение, тем меньше пикселей проходят через FAA движок, в результате удар по производительности на высоких разрешениях становится меньше. Такой способ действительно является демонстрацией того, как нужно осуществлять сглаживание с точки зрения чистой производительности и эффективности. Про качество мы пока умолчим, так как мы не имеем экземпляра карты для тестирования. Но наверняка качество будет сравнимо с аналогами от ATi и nVidia.
К сожалению, с движком Parhelia FAA не все так безоблачно. Существует целый ряд ситуаций, когда определение частично покрытых пикселей работает небезупречно, в результате в игре появляются артефакты. Для таких ситуаций вы можете выключить FAA или перейти на алгоритм суперсэмплинга, который влияет на производительность примерно так же, как и включение сглаживания в Radeon 8500. Сейчас невозможно предсказать, в каких играх появятся артефакты, но они явно будут. Matrox заявила, что они протестировали приблизительно
40 игр, и только в 5-7 были выявлены артефакты при включении FAA.
Мы уже объясняли в предыдущих статьях, почему аналоговый сигнал ухудшается на больших разрешениях. Однако Matrox провела собственные исследования для поиска ограничений конкурирующих карт.
Когда видеосигнал покидает RAMDAC, он посылается через серию фильтров низких частот. Как понятно по названию, фильтры пропускают только низкие частоты, отбрасывая высокие. Благодаря этому достигаются две цели: 1) соответствие требованиям FCC, определяющим, что через VGA выход должны пропускаться только нужные частоты, и 2) высокие частоты не будут каким-либо образом влиять на низкочастотный сигнал.
Низкочастотные фильтры главным образом изготавливаются из пассивных элементов типа резисторов, конденсаторов и катушек индуктивности. Поскольку низкочастотный фильтр не может усиливать сигнал, он работает лишь как шлюз, пропуская определенные частоты.
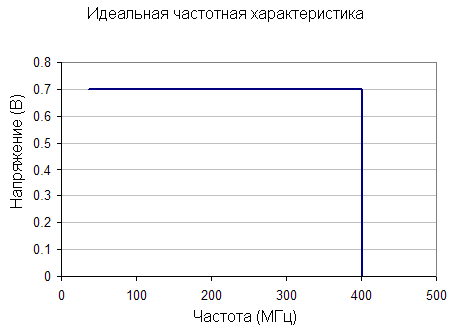
Самая высокая частота, которая пропускается низкочастотным фильтром, называется граничной. К сожалению, простейшие низкочастотные фильтры далеко не идеальны. Если вы установите граничную частоту в 400 МГц, некоторые большие частоты все равно пройдут через фильтр. Для предотвращения этого используются два метода – вы можете выставить граничную частоту немного ниже или использовать более сложный фильтр.
Самый простой (и дешевый) – это первый подход выставления граничной частоты немного меньше требуемого значения. В результате вместо идеальной частотной характеристики вы получаете следующую картину.
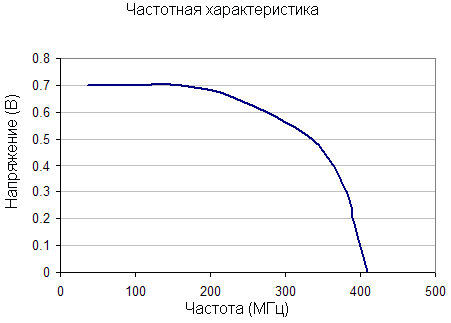
Подход подороже заключается в использовании более сложного фильтра - более высокого порядка. Порядок фильтра напрямую определяется компонентами фильтра. Мы не будем вдаваться в характеристики фильтров различных порядков, просто считайте, что чем больше пассивных компонентов присутствует в фильтре, тем выше его порядок.
Преимущество фильтра высокого порядка заключается в том, что частоты выше граничной отсекаются более эффективно. То есть через фильтр будет проходить меньшее количество мусорных частот. Такой подход, конечно, лучше, но он и дороже – на плату потребуется установить дополнительные катушки индуктивности и конденсаторы.
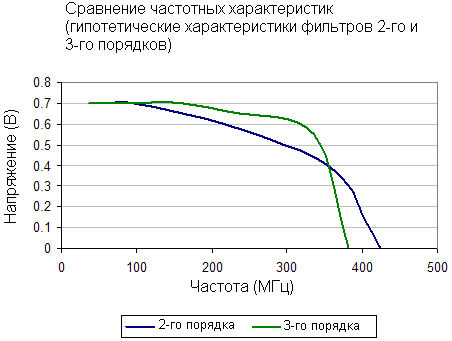
Фильтр 3-го порядка имеет более крутую частотную характеристику по сравнению с фильтром 2-го порядка зато пропускает меньше мусорных частот.
В данном случае переход на фильтр 2-го порядка повышает качество, поскольку вы пропускаете больше высоких частот (на высоких разрешениях) без изменения граничной частоты.

Множество катушек индуктивности и емкостей, показанное на иллюстрации, и составляют фильтры 5-го порядка на Parhelia
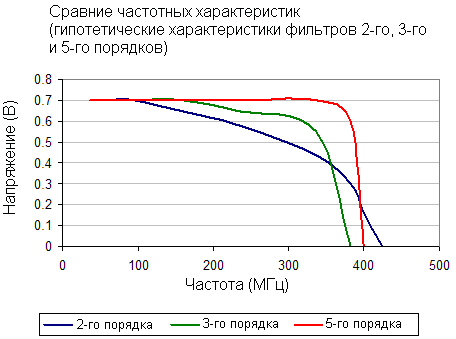
Карты на Parhelia-512 будут использовать точно подогнанные низкочастотные фильтры 5-го порядка на своих аналоговых выходах. Они помогут значительно улучшить качество изображения на высоких разрешениях, особенно близких к граничному значению частоты. Ниже вы можете посмотреть на пример, сравнивающий частотную характеристику фильтра 5-го порядка с характеристиками фильтров 2-го и 3-го порядков.
Для дальнейшего понимания темы нашего разговора посмотрите на таблицу соответствия частот и разрешений.
| Частота сигналов для разрешений @ 85Hz | |
| Разрешение | Частота |
| 640x480 | 37 МГц |
| 800x600 | 58 МГц |
| 1024x768 | 95 МГц |
| 1280x1024 | 159 МГц |
| 1600x1200 | 233 МГц |
| 1920x1440 | 336 МГц |
| 2048x1536 | 382 МГц |
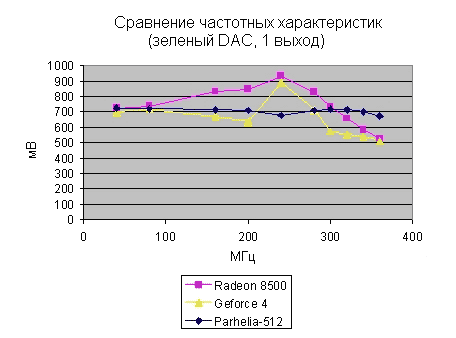
Как вы можете заметить, GeForce4 и Radeon 8500 отнюдь не обеспечивают равного напряжения при всех частотах. Важно отметить, что поскольку здесь видно усиление выходного напряжения, то такая ситуация не является всецело следствием плохих низкочастотных фильтров на Radeon 8500 и GeForce4. Скорее всего, для компенсации плохих фильтров RAMDAC усиливает выходное напряжение на высоких частотах. Впрочем, выходное напряжение Parhelia всегда остается относительно постоянным на разных частотах. Для того чтобы вы могли представить себе качество картинки более наглядно, Matrox приводит следующую иллюстрацию.
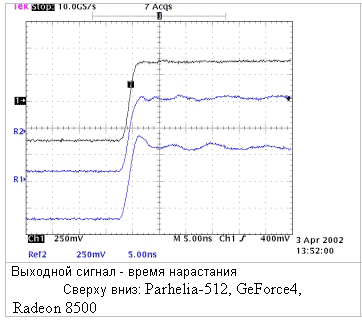
График показывает длительность времени нарастания сигнала на трех картах. Вы должны обратить внимание на то, сколько времени уходит на стабилизацию сигнала после достижения нужного уровня напряжения. Parhelia-512 стабилизирует напряжение почти мгновенно, в то время как Radeon 8500 это не удается совсем. Нестабильный сигнал приводит к размыванию текста на высоких разрешениях.
Как только мы получим карту от Matrox, мы попытаемся провести реальное тестирование качества изображения.

Получаемый эффект очень правдоподобен. Представьте, как вы проходите через дверь в стрелялке от третьего лица. Благодаря трем монитором вы сможете краем глаза заметить поджидающего за стенкой врага с двустволкой. Все это происходит благодаря увеличению поля зрения и фактическому расположению двух мониторов по разные стороны от главного.
Конечно, такая функциональность пока еще слишком необычна, тем более что вряд ли у большинства людей найдется место на столе для трех мониторов (равно как и средства). Однако подобная "трехголовочность" может быть полезна и в профессиональных применениях, когда двух рабочих столов бывает недостаточно.
"Я уже несколько лет проталкиваю дополнительные биты, но на самом деле мне нужны полные 16-битные цвета с плавающей точкой в графическом конвейере. Поэтому какие-то промежуточные решения типа формата RGB 10/12/10 отнюдь не есть лучшие" - Джон Кармак, .plan апрель 2000.
И снова ограничивающим фактором для Matrox стал недостаток места на кристалле, иначе мы наверняка бы увидели полную поддержку 16-битных цветов с плавающей точкой в графическом конвейере.
10-битный цветовой режим Parhelia может быть включен через панель управления (потом требуется перезагрузка). Но, к сожалению, такой режим в настоящее время приводит к ошибке MS Word (равно как и других приложений, которые недостаточно хорошо поддерживают 2-битные альфа-каналы). Так что пока о 10-битном режиме следует забыть.
Карта также поддерживает аппаратное сглаживание текста для режимов типа ClearType под Windows XP. Как объявляет Matrox, переход на Parhelia приведет к заметному росту 2D производительности.
Главной целью при дизайне чипа было достижение максимально возможной производительности в будущем DX8 поколении игр. Ставка здесь сделана на то, что для DX9 игр потребуется столько же времени, сколько ушло на выход DX8 игр, поэтому в момент выхода Parhelia-512 будет достаточно быстро работать как на существующих играх, так и на продуктах "ближней перспективы" в сравнении с NV25/NV30 и R200/R300. Как мы считаем, подобная ставка является лучшей из всех возможных и, вероятно, верной. Конечно, Matrox не получит такую долю на рынке, как nVidia, однако в определенной степени компания поправит свой имидж на рынке. С какой же скоростью будет работать Parhelia-512?
Однако нам следует отметить и ряд недостатков архитектуры Parhelia-512.
Parhelia-512 может стать самым быстрым продуктом с момента своего выпуска и до выхода NV30. Наверное, Parhelia – это лучший прорыв, который Matrox когда-либо осуществляла в компьютерной графике. Те, кому нужна картинка экстремально высокого качества и "трехголовый" выход, остаются практически без альтернативы. Причем на сей раз, они получают и высокопроизводительный 3D ускоритель.
Однако успех Matrox не обусловлен целиком лишь Parhelia-512. Как мы уже видели в новейшей истории, все зависит от последовательной поддержки технологий. Parhelia-512 не должна превратиться в еще одну G400, которая просуществовала на рынке два года без серьезного улучшения. Matrox выставила достойный продукт с большими перспективами, но для компании очень важно не стоять на месте.
Matrox уверила нас, что у них есть четкие планы на будущее, однако они не будут переходить на жесткие 6-месячные циклы выпуска продуктов, как то делает nVidia. Подведем итог: Matrox достойный конкурент на рынке 3D графики, и они действительно сделали очень хорошую работу, выпустив Parhelia.
Использованы материалы Matrox и Anandtech