
Архитектура графических процессоров AMD (ATI) не подвергалась существенным изменениям со времен серии Radeon HD 2000: вплоть до HD 6000 в GPU использовался VLIW-дизайн. Что это такое? Сначала вспомним, как работает центральный процессор в наших персоналках. Современные CPU – суперскалярные, то есть их вычислительные блоки могут выполнять несколько инструкций из одного потока одновременно. Но инструкции при этом должны быть независимыми друг от друга, поэтому процессор непрерывно проверяет, когда можно выполнять параллельные операции, а когда нужно подождать разрешения очередной зависимости. Кроме того, CPU занимается предсказанием ветвлений и может делать часть работы заранее (out-of-order). Оптимизация этих функций – сложная техническая задача, а схемы, на которых они построены, занимают добрую часть кристалла CPU.
Но есть другой путь: задать порядок исполнения инструкций на этапе компиляции кода. Компилятор сам находит инструкции, которые можно выполнять одновременно, и формирует из них длинные составные конструкции. Отсюда и термин VLIW – very long instruction word. VLIW в общем случае показывает высокую эффективность, когда код содержит мало зависимостей, а ход программы предсказуем. Компилятор «знает» код от начала до конца и может задать исполнение определенных фрагментов с большим запасом по времени. Но планирование получается жестким, и в случае когда ход программы зависит от внешних данных, хитроумная компиляция уже мало помогает, исполнительные блоки простаивают и производительность идет вниз.
Но рендеринг 3D-графики – предсказуемая задача и отлично распараллеливается. Поэтому ставка на VLIW, которую сделала тогда еще независимая канадская компания, себя полностью оправдала. Переложив функции планировщика на компилятор, ATI могла делать относительно компактные чипы с бешеными сотнями исполнительных элементов внутри, и видеокарты в результате получились относительно недорогими. Звездный час VLIW в исполнении AMD пришелся на время Radeon HD пятитысячной серии, когда дебют архитектуры Fermi от NVIDIA (GeForce 400) немного забуксовал. И неудивительно, ведь «зеленым» приходится делать огромные чипы, вплоть до трех миллиардов транзисторов. И даже сейчас, когда в адаптерах GeForce 500 архитектура Fermi уже работает на полную мощность, а топовые ускорители NVIDIA побеждают в бенчмарках продукцию AMD, шеститысячные Radeon все еще обеспечивают отличную производительность в играх.
В таком случае, зачем AMD решилась на столь резкий поворот? Казалось бы, достаточно немного отполировать дизайн GPU, нарастить вычислительных блоков тут и там, внедрить более тонкий технологический процесс — и VLIW будет жить долго и счастливо. Зачем тратить время и деньги на разработку совершенно новой архитектуры? Но дело не только и не столько в играх. GPU медленно превращаются из устройств, предназначенных исключительно для 3D-рендеринга, в процессоры общего назначения (GPGPU – general purpose GPU), которые можно использовать для любых массированных параллельных вычислений. Однако на сегодняшний день вышло так, что если мы говорим GPGPU, то подразумеваем CUDA. Ни родной для «красных» API под названием ATI Stream, ни Open CL не имеют такой популярности, как CUDA от NVIDIA. Между тем AMD очень хочет откусить кусок от этого рынка, но чтобы это стало возможным, со старой доброй архитектурой VLIW придется расстаться. Для неграфических вычислений она не подходит, ибо они менее предсказуемы, чем 3D-рендеринг, и GPU просто не в состоянии работать в полную силу.
⇡#Архитектура Graphics Core Next
Возьмем последнего представителя VLIW-архитектуры от AMD, процессор Cayman, который лежит в основе адаптеров Radeon HD 6950/6970/6990. Основным компонентом шейдерного домена у него является SIMD Engine – блок из шестнадцати потоковых процессоров. Все они одновременно исполняют одну VLIW-инструкцию, но применительно к разным данным (потому и SIMD – single instruction, multiple data). В свою очередь, в одной VLIW-инструкции может быть упаковано вплоть до четырех скалярных операций, что соответствует четырем ALU внутри одного потокового процессора.

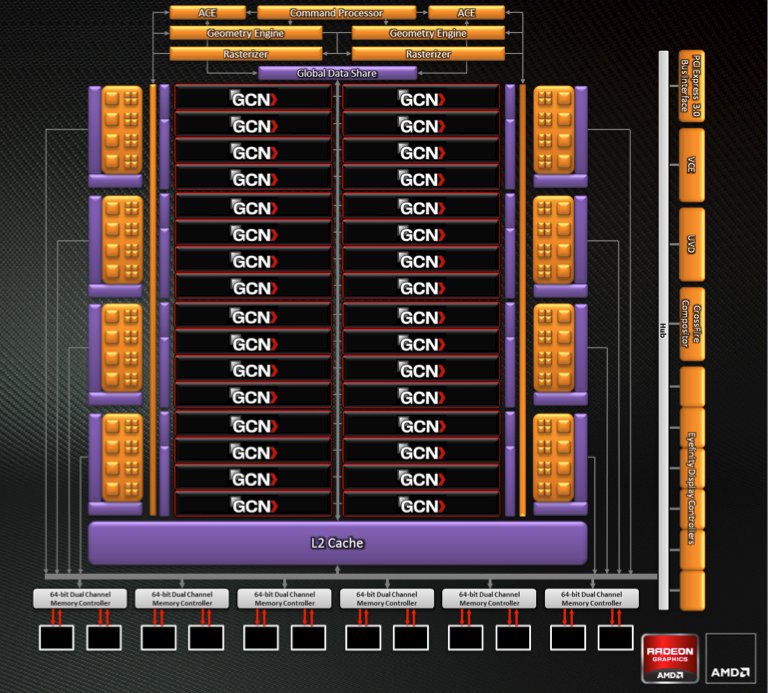
Строительный блок ядра Graphics Cores Next (GCN) называется Compute Unit, и он устроен совершенно по-другому. В нем тоже 64 ALU, но они разделены на четыре отдельных векторных SIMD-модуля по 16 штук плюс блок планировщика. Проще говоря, раньше параллелизм был реализован за счет нескольких операций в одной инструкции, а теперь за счет нескольких отдельных SIMD-блоков. И если производительность старой архитектуры зависит от того, сколько скалярных операций компилятор может закодировать в одной VLIW-инструкции, то Compute Unit в ядре GCN может динамически распределять нагрузку между SIMD-блоками.
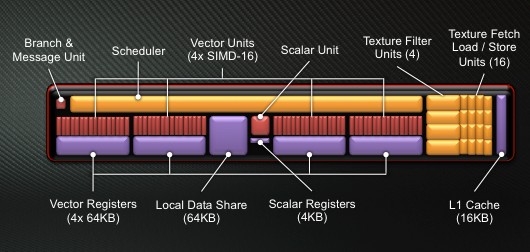
Нагрузка для параллельного исполнения в SIMD-блок поступает в виде массива (wavefront) из 64 инструкций, который выполняется за четыре цикла. И хотя одновременно в работе могут быть только четыре массива, еще 28 находятся у Compute Unit в прямом доступе, за счет чего планировщик и получает пространство для маневра. В ситуации, когда зависимость в коде мешает комбинированному SIMD-блоку VLIW-процессора работать на полную мощность, отдельные SIMD-блоки чипа GCN просто переключатся на другие массивы из той же задачи либо вовсе на другие задачи.

Изюминка GCN – отдельный скалярный модуль в каждом Compute Unit. Он предназначен для разовых операций, не укладывающихся в wavefront (что избавит SIMD-модули от неэффективного использования), а еще – для контроля исполнения программы: условных ветвлений, переходов и прочих событий, которые Cayman переваривал с трудом. Скалярный модуль выполняет одну операцию за цикл.
Кеш-память
Новая конструкция исполнительных модулей требует более быстрой и объемной кеш-памяти по сравнению c VLIW-дизайном. У каждого CU есть отдельный кеш L1 объемом 16 Кбайт плюс хранилище для инструкций и данных на 16 и 32 Кбайт, общее для четырех CU, – буфер для разделения данных между массивами. Еще есть полностью когерентный кеш L2, поделенный на порции по 64 Кбайт между двухканальными контроллерами памяти. В нем хранятся копии вышеупомянутых буферов

Шины кешей L1 и L2 имеют разрядность 64 байт. AMD сообщает, что пропускная способность L1 достигает почти 2 Тбайт/с, а L2 – 700 Гбайт/с, и, судя по всему, здесь имеется в виду суммарное значение для процессора с 32 CU.
Для сравнения: у Cayman каждый SIMD-модуль имеет кеш L1 объемом 8 Кбайт с шиной 16 Байт.
Обработка геометрии, растеризация
О собственно графических компонентах чипа в презентациях AMD, сопровождающих релиз, сказано немного. Судя по блок-схеме, их внутреннее устройство не изменилась, только «Тесселятор» прокачался до девятой версии и обеспечивает гигантский прирост быстродействия в соответствующих задачах.

Между тем, если верить информации из посторонних источников и слайдам самой AMD с июньского Fusion Development Summit, то изнутри Geometry Engine и Tesselator выглядят совсем по-другому. Как и Cayman, ядро GCN содержит два Graphics Engine, но если раньше они состояли из отдельных блоков для растеризации, тесселяции и так далее, то теперь в каждом GE может быть произвольное количество конвейеров для обработки пикселей и геометрических примитивов.
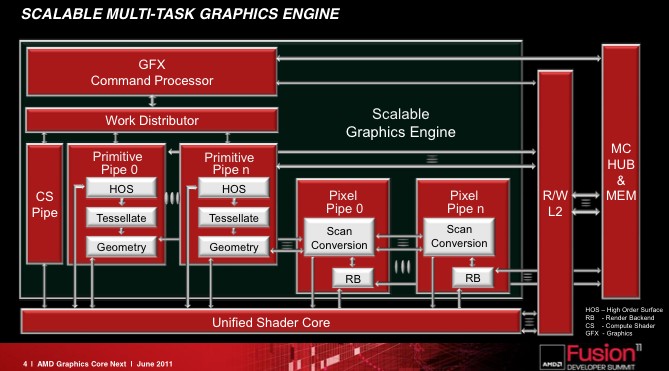
Вероятно, такой дизайн поможет производителю легко наращивать графическую мощь либо выпускать бюджетные GPU, урезанные по этой части. Быстрая работа с геометрией придется в современных играх как нельзя кстати.
PCI-E 3.0
Заголовок говорит за себя: AMD внедрила шину PCI-E нового поколения со вдвое большей пропускной способностью. Непонятно, нужна ли она сегодня для 3D-рендеринга, но для неграфических расчетов наверняка пригодится. AMD внесла в архитектуру GCN массу нововведений с далеким прицелом на такое применение и специальную функцию графики, которая тоже отлично сочетается с новым интерфейсом.
Новые функции GCN
В GCN есть два дополнительных блока распределения команд под названием Asynchronous Compute Engine, которые работают совершенно независимо друг от друга и графического командного процессора. AMD планирует открыть доступ к ACE через Open CL, и тогда в распоряжении программистов окажутся три отдельных устройства, каждое со своей очередью команд. Кроме того, по информации из третьих рук, ACE обеспечивает внеочередное исполнение на уровне отдельных задач. Сами CU хоть и поумнели по сравнению с SIMD-модулями VLIW-архитектуры, но могут обрабатывать свои wavefront’ы строго в прямом порядке.

Ядро GCN и центральный процессор компьютера могут иметь общее адресное пространство. В таком случае все инструкции, которые попадают на исполнение в GPU, указывают на адреса в пространстве x86-64, а он уже самостоятельно перекодирует их в адреса локальной видеопамяти при помощи специального модуля. В результате GPU получает прямой доступ к системной памяти. Кроме того, ядро GCN наделили рядом функций для поддержки языков высокого уровня: виртуальными функциями, указателями, рекурсией и так далее. Это позволит программистам писать универсальный код, пригодный для исполнения на CPU или на GPU.
Новые GPU полностью совместимы с API OpenCL 1.2, DirectCompute 11.1 (и DirectX 11.1 как таковой) и C++ AMP. Появились специальные инструкции, полезные для производства мультимедийного контента. Кроме того, чипы на базе архитектуры GCN стали первыми GPU со встроенным кодировщиком видео стандарта H.264, который можно будет использовать, как только AMD выпустит необходимую библиотеку софта.
В свою очередь, декодер приобрел поддержку нескольких дополнительных форматов: MVC, MPEG-4/DivX и Dual Stream HD + HD. Вообще, видеокарты Radeon были сильны по части воспроизведения видео еще во времена ATI. У семитысячной серии есть масса «улучшайзеров» картинки, например алгоритм Steady Video, устраняющий дрожание камеры.
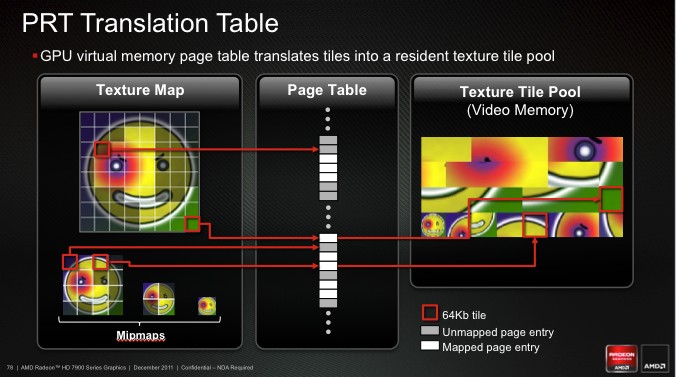
Partially Resident Textures – еще один трюк с виртуальной памятью, который предназначен уже для 3D-рендеринга: приложение или шейдер работают с адресным пространством, превышающим объем набортной памяти адаптера, а она сама выступает лишь в качестве быстрого кеша. Таким образом можно использовать текстуры объемом до 32 Тбайт, порции которых GPU будет динамически подкачивать поближе к себе. Поддержка со стороны ОС в этом не требуется.
Тормоза, которые неизбежно возникнут при загрузке текстур из системной памяти, AMD отчасти компенсирует использованием MIP mapping’a. Гигантская текстура наверняка будет храниться в нескольких вариантах с различным разрешением (mipmaps). Каждый из них разделен на фрагменты объемом 64 Кбайт. Когда адаптеру требуется определенный фрагмент, и он уже есть в локальной видеопамяти, то нет проблем. Если же фрагмента не оказалось, то программа может немедленно потянуть его из системной памяти, а может отложить чтение и взять для текущего кадра соответствующую копию фрагмента с низким разрешением (если он уже есть в видеопамяти).
Небольшое дополнение к вопросу о тесселяции. В GCN реализован алгоритм Ptex (Per-face texture mapping). В общем случае в 3D-моделировании текстура накладывается на модель целиком и вершины необходимо аккуратно совмещать с нужными участками двухмерного полотна. Нетрудно представить, как аппаратная тесселяция, плодящая дополнительные вершины, усложняет задачу дизайнера. При использовании Ptex на каждый полигон накладывается отдельная текстура, в результате – никаких видимых стыков. Кроме того, Ptex позволяет упаковывать в один файл текстуры с различным разрешением.

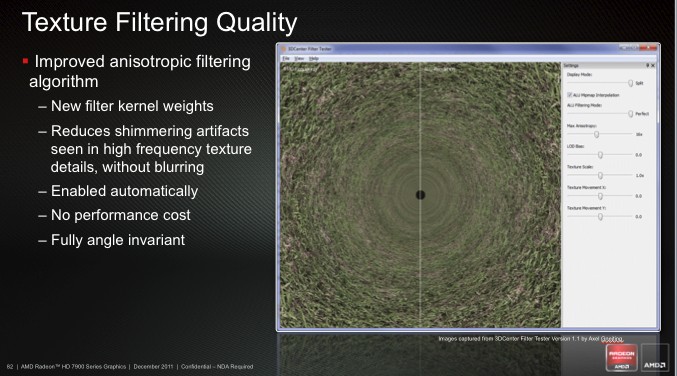
Наконец, AMD немного поработала над анизотропной фильтрацией с целью устранить едва заметное мерцание на текстурах высокого разрешения. Изменение алгоритма не должно сказаться на быстродействии.
Контроль энергопотребления
AMD отмечает, что производители GPU и видеокарт всегда перестраховываются на счет энергопотребления и устанавливают тактовые частоты с учетом пиковой нагрузки, которая возможна лишь в самых жадных приложениях или даже в стресс-тестах (FurMark. OCCT). А в обычных играх графический процессор мог бы работать на более высокой частоте. Для того чтобы всегда выжимать из GPU максимум, предназначена технология PowerTune – калькулятор, который в реальном времени с интервалами в единицы миллисекунд рассчитывает энергопотребление карты на основе анализа выполняемой задачи (без всяких аналоговых сенсоров). И если есть возможность, тактовая частота GPU увеличивается. Заметьте, это не сброс частоты относительно номинала при достижении порога мощности, а наоборот – точно выверенный динамический разгон.

А еще ядро GCN умеет полностью отключаться, когда на экране долго ничего нет, и останавливать кулер (технология ZeroCore). В конфигурации CrossFire процессоры на дополнительных картах (и на одной – тоже) и вовсе не работают без 3D-нагрузки.

Eyefinity 2.0
Вместе с Radeon HD 7000 дебютирует вторая версия технологии Eyefinity, которая принесла массу нововведений. Многие представленные «фичи» не нуждаются в комментариях, поэтому перечислим их кратко:
Новые Radeon поддерживают DisplayPort 1.2, а значит – технологию Multi-Stream. С ее помощью можно подключать к одному выходу три дисплея по цепочке или через специальный хаб. Причем на выходе хаба может быть не только DisplayPort, но и интерфейсы HDMI, DVI и VGA. AMD обещает, что хабы появятся в продаже летом 2012 года.
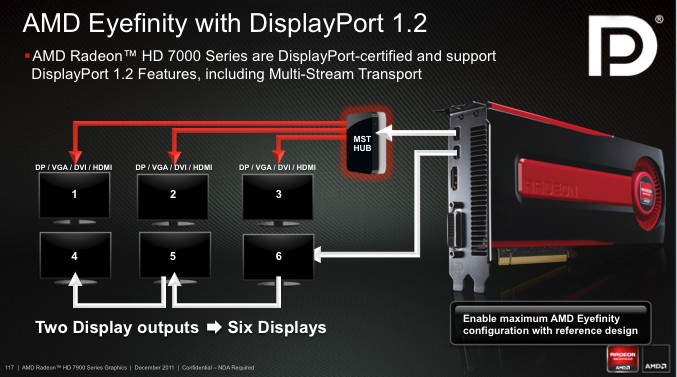
HDMI-выход соответствует стандарту 1.4а, поэтому может передавать двойной сигнал на 3D-телевизор с частотой 24 кадра на каждый канал. А специально для игр есть поддержка 3 GHz HDMI с частотой 60 Гц на канал.
Кроме того, стандарты DisplayPort 1.2 HBR 2 и 3 GHz HDMI пригодятся для подключения грядущих дисплеев с разрешением 4096x2160.
HD 7970 – одночиповый флагман линейки, представляющий архитектуру GCN во всей мощи. Его GPU называется Tahiti и содержит 32 CU (Compute Units), устройство которых подробно описано выше. Если пересчитать это на количество отдельных ALU, как AMD делала до сих пор, то получится 2048 штук – в полтора раза больше, чем в ядре Cayman! И блоков TMU (texture mapping units) в Tahiti тоже 128 против 96. Шина памяти – 384-битная вместо 256-битной. Если учесть, сколько дополнительной логики добавили в архитектуру, то совершенно не удивительно, что Tahiti состоит из 4,31 миллиарда транзисторов. Просто для сравнения: в Cayman – 2,64 миллиарда, а в GF110 от NVIDIA – три. Работает все хозяйство на частоте 925 МГц.

Однако чипы с архитектурой GCN печатают по техпроцессу 28 нм, так что по электрической мощности новинка удержалась в рамках HD 6970 – те же 250 Вт, да и сам кристалл не выглядит устрашающе.

Карта комплектуется видеопамятью GDDR5 объемом 3 Гбайт. Массив набран микросхемами Hynix H5GQ2H24MFR со штатной частотой 1500 МГц (эффективная частота – 6 ГГц), но здесь они работают на частоте 1375 (5500) МГц.

Рекомендованная цена HD 7970 составляет 549 долларов, что делает его самым дорогим одночиповым адаптером Radeon за всю их историю.

В оформлении семитысячной серии AMD отступила от брутальных форм Radeon HD 6000 и выбрала броский дизайн с плавными линиями и глянцевой поверхностью кожуха. Вернулся узнаваемый красный текстолит, в этот раз – с малиновым оттенком. По габаритам Radeon HD 7970 не отличается от предшествующих одночиповых флагманов AMD/ATI.

Продукция кирпичного завода AMD
Карта тяжелая. Берешь в руку – и чувствуется мощь. Все дело в системе охлаждения с крупной испарительной камерой, приделанной к толстой раме. Со времен Radeon HD 6970 конструкция не претерпела больших изменений, разве что вентилятор-турбинка стал шире.


Для лучшего охлаждения с заглушки убрали один порт DVI, чтобы целиком занять слот выхлопной решеткой.

С задней стороны, как и раньше, есть прижимная крестовина. От сплошной крышки решили отказаться.

На печатной плате, как и у HD 6970, есть переключатель между основным и резервным BIOS. А еще по задней поверхности разбросано несколько мелких сдвоенных переключателей неизвестного назначения, которые мы, от греха подальше, решили не трогать. Возможно, что перед нами лишь инженерный образец HD 7970 и на серийных платах этих странных элементов уже не будет.


В хвосте платы расположены семь катушек индуктивности и восьмифазный контроллер напряжения CHiL CHL8228G, чему, без сомнения, будут рады оверклокеры, ведь он уже использовался на картах Radeon HD 6970, . Скорее всего, и схема питания карты организована по-старому: шесть фаз приходятся на GPU и одна отдана для питания внутренних цепей микросхем GDDR5. В противоположном углу платы находится двухфазный чип uP1509P от uP Semiconductor со своей катушкой, который, по аналогии с HD 6970, должен контролировать напряжение на буферах ввода-вывода видеопамяти.

| Конфигурация тестового стенда | |
|---|---|
| Центральный процессор | Intel Core i7-2600K @ 4,8 ГГц (100x48) |
| Материнская плата | ASUS Maximus IV Extreme-Z |
| Оперативная память | DDR3 Kingston HyperX 4x2 Гбайт @ 1600 МГц, 9-9-9 |
| ПЗУ | Intel SSD 510 120 Гбайт |
| Система охлаждения ЦП | Cooler Master Hyper 612S + 2 кулера 120 мм |
| Блок питания | HIPER K1000W, 1000 Вт |
| Корпус | Cooler Master Test Bench 1.0 |
| Операционная система | Windows 7 Ultimate X64 Service Pack 1 |
| ПО для карт AMD | AMD Catalyst 11.12 |
| ПО для карт NVIDIA | 285.88 |
| Настройки драйвера AMD Catalyst — по умолчанию | |
|---|---|
| Antialiasing | Application Settings |
| Anisotropic Filtering | Application Settings |
| Tesselation | AMD Optimized |
| Catalyst A.I. Texture Filter Quality | Quality, Enable Surface Format Optimization |
| Wait for V-Sync | Disable, unless application Specifies |
| AA Mode | Multisample |
| Triple buffernig | Disable |
| Настройки драйвера NVIDIA | |
| CUDA графические процессоры | Все |
| Анизотропная фильтрация | Управление приложением |
| Вертикальная синхронизация | Использовать настройку 3D-приложения |
| Затенение фонового освещения | Выкл. |
| Максимальное количество заранее подготовленных кадров | 3 |
| Потоковая оптимизация | Авто |
| Режим управления электропитанием | Адаптивный |
| Сглаживание — гамма-коррекция | Выкл. |
| Сглаживание — режим | Управление от приложения |
| Тройная буферизация | Выкл. |
| Ускорение нескольких дисплеев | Режим многодисплейной производительности |
| Фильтрация текстур — анизотропная оптимизация | Выкл. |
| Фильтрация текстур — качество | Качество |
| Фильтрация текстур — отрицательное отклонение УД | Разрешить |
| Фильтрация текстур — трилинейная оптимизация | Вкл. |
| Программа | API | Настройки | Режимы тестирования | Разрешение |
|---|---|---|---|---|
| 3DMark Vantage | DirectX 10 | Профили Performance, High, Extreme | ||
| 3DMark 11 | DirectX 11 | Профили Performance, Extreme | ||
| Unigine Heaven 2 | DirectX 11 | Максимальная детализация, DirectX 11, тесселяция в режиме Extreme | Без АА и AF / AA 4х, AF 16x | 1920х1080 / 2560х1440 |
| Crysis 2 + Adrenaline Crysis 2 Benchmark Tool | DirectX 11 | Карта Downtown/Adrenaline. Макс. детализация, текстуры высокого разрешения, DirectX 11 | Edge AA | 1920х1080 / 2560х1440 |
| Far Cry 2 + Far Cry 2 Benchmark Tool | DirectX 10 | Карта Ranch Small. Макс. детализация | Без АА / AA 4х | 1920х1080 / 2560х1440 |
| Metro 2033 + Metro 2033 Benchmark | DirectX 11 | Максимальная детализация, DirectX 11, DOF, тесселяция, NVIDIA PhysX выкл. | Analytical AA, AF 4x / MSAA 4x, AF 16x | 1920х1080 / 2560х1440 |
| Aliens versus Predator + Alien vs Predator Benchmark Tool | DirectX 11 | Максимальная детализация, DirectX 11 | Без АА и AF / AA 4х, AF 16x | 1920х1080 / 2560х1440 |
| DiRT 3 | DirectX 11 | Максимальная детализация | Без АА и AF / AA 4х, AF 16x | 1920х1080 / 2560х1440 |
| Mafia 2 | DirectX 11 | Максимальная детализация, NVIDIA PhysX выкл. | Без АА, AF 1x / AA вкл., AF 16x | 1920х1080 / 2560х1440 |
| Just Cause 2 | DirectX 10 | Максимальная детализация, Bokeh Filter выкл., Enhanced Water Detail выкл. | Без АА, AF 2x / AA 4х, AF 16x | 1920х1080 / 2560х1440 |
В качестве соперников Radeon HD 7970 в тестировании приняли участие следующие видеокарты:
⇡#Разгон, температура, энергопотребление
AMD пообещала, что процессор HD 7970 без проблем разгонится до 1 ГГц и выше, во что легко можно поверить, так как 75 МГц при новом техпроцессе – не столь уж большое достижение. Но наш тестовый экземпляр легко прибавил 200 МГц (!) сверх штатной частоты GPU, а память разогналась с 5500 до 6300 эффективных МГц, и все это без подъема напряжения. Дальнейший разгон уперся в ограничения функции Overdrive, и преодолеть их при помощи известных трюков с ключами реестра и сторонних оверклокерских утилит не удалось. HD 7970 даже не позволяет считать BIOS с помощью существующего ПО, поэтому настоящие рекорды еще впереди.
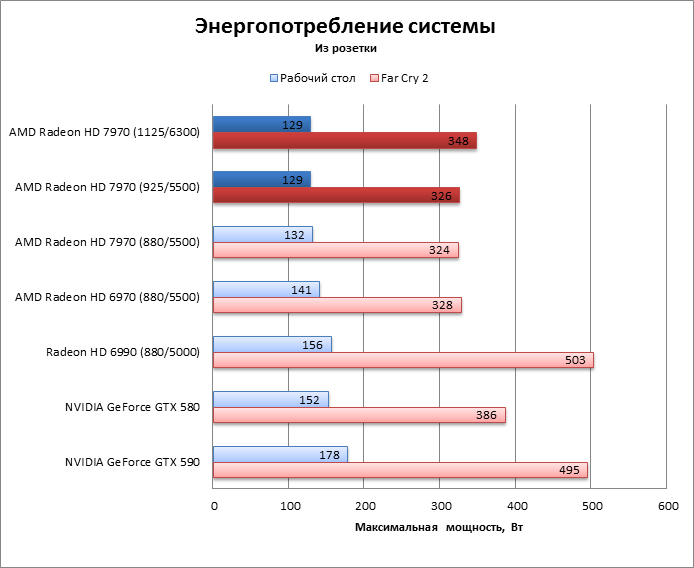
Похоже, что Radeon HD 7970 действительно не отличается от HD 6970 по TDP. Потребляемая мощность системы под нагрузкой точно такая же, а в режиме 2D HD 6970 даже более прожорлив. Оверклокинг немного прибавил к энергопотреблению, но результат все равно гораздо меньше, чем у прочих конкурентов – «двухголового» HD 6990 и ускорителей GeForce.
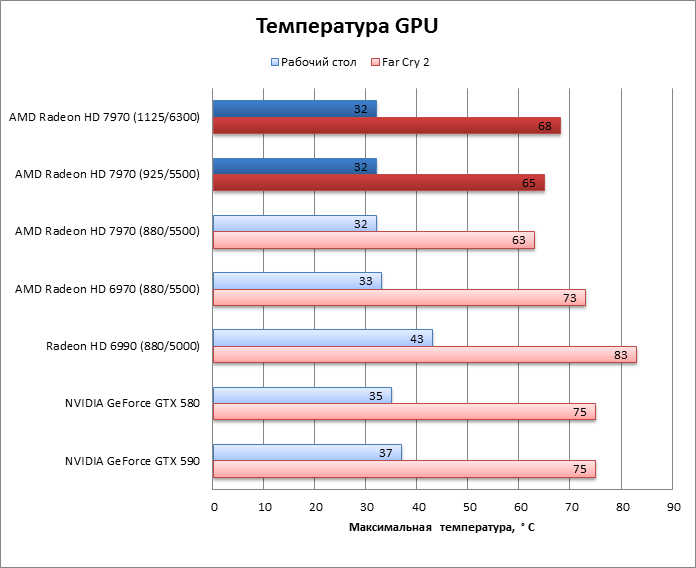
Кроме того, HD 7970 оказался самой холодной картой из всех участников тестирования. Даже при максимальном разгоне он греется меньше, чем HD 6970. А так как потребляемая мощность у карт одинакова, то стоит сказать спасибо новой системе охлаждения. Эффект особенно выражен, если опустить частоту процессора HD 7970 до уровня HD 6970.
⇡#Производительность, синтетические тесты
3DMark Vantage
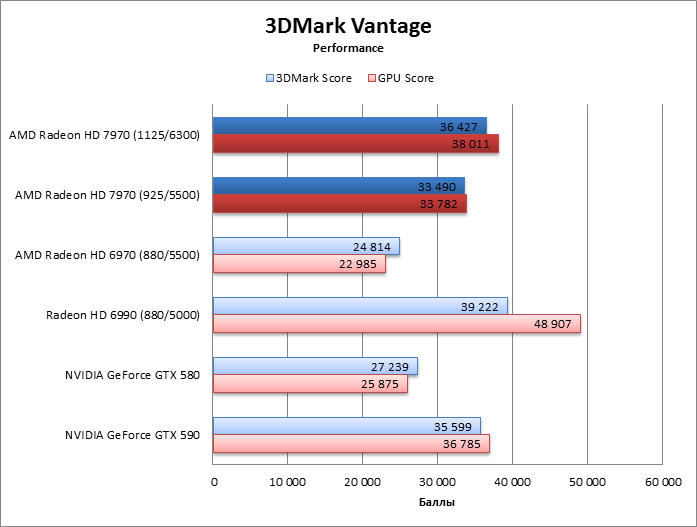
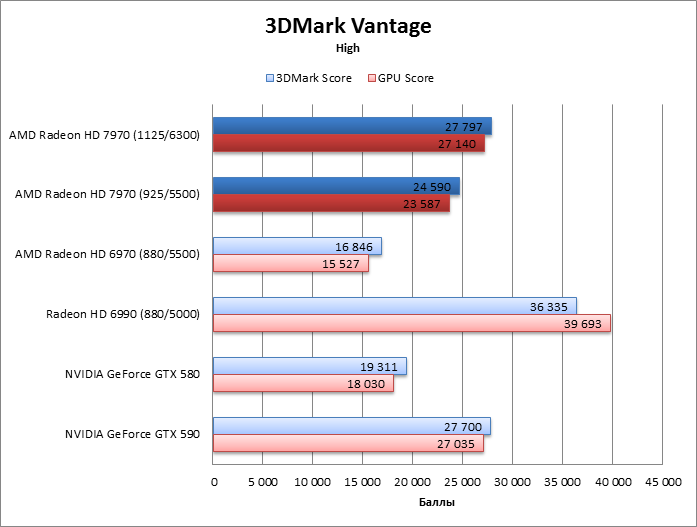

3DMark 2011
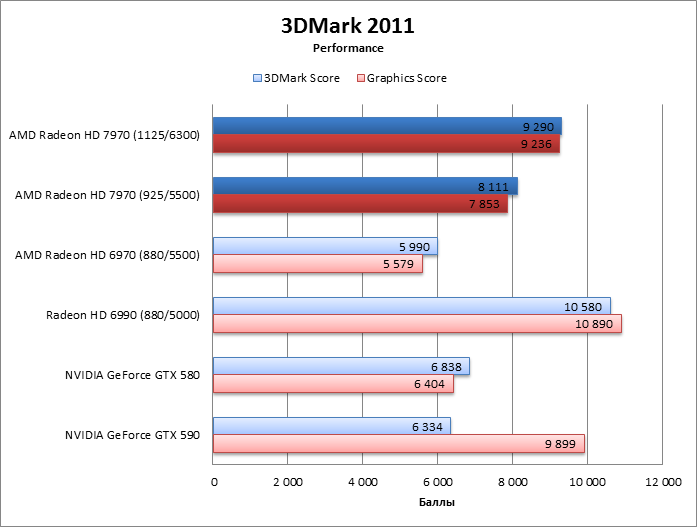
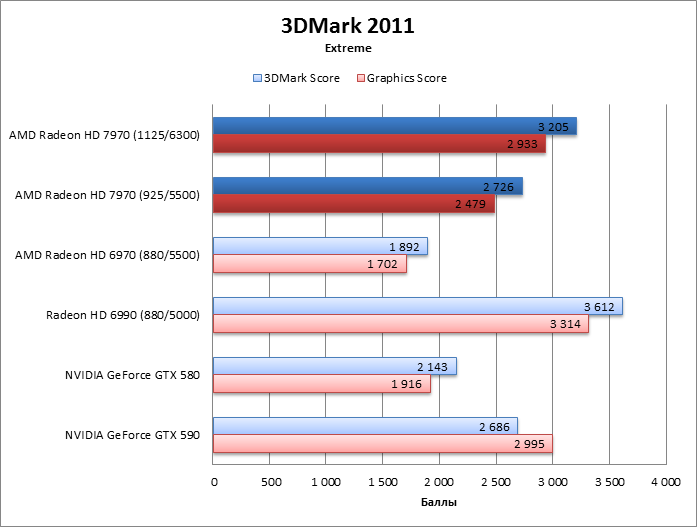
⇡#Производительность, игровые тесты
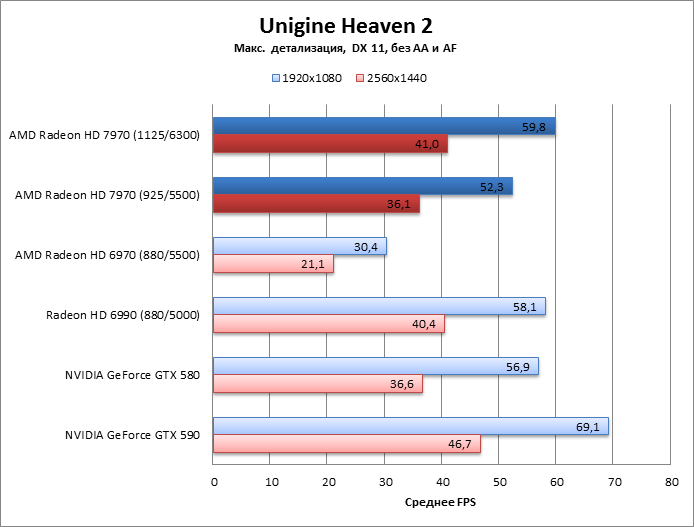
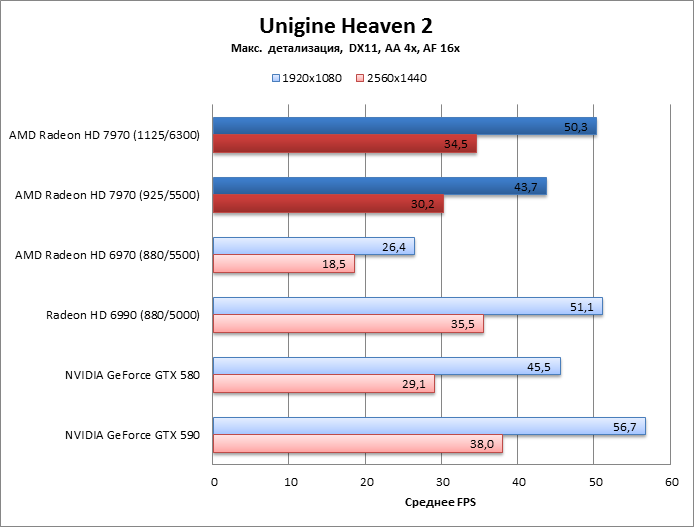
Unigine Heaven 2
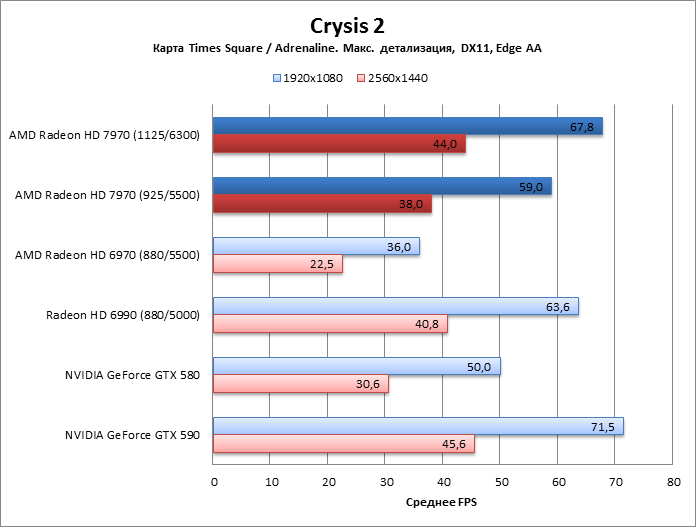
Crysis 2
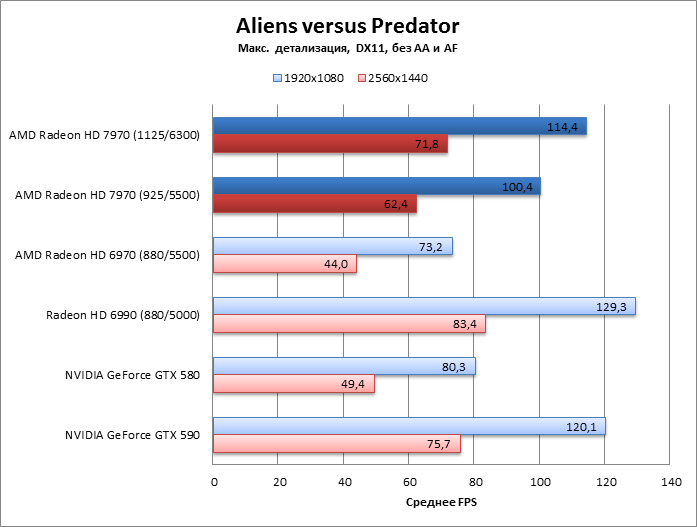
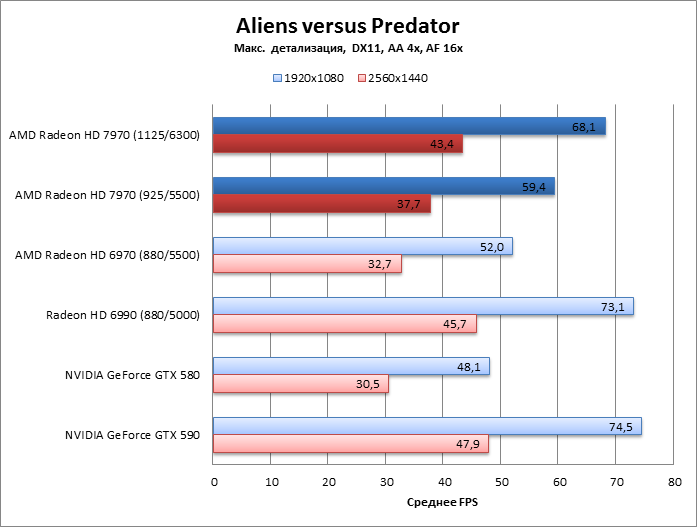
Aliens vs Predator
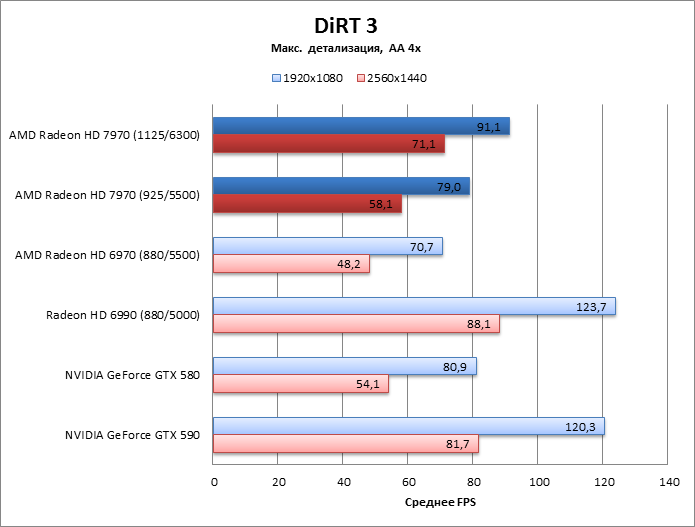
DiRT 3

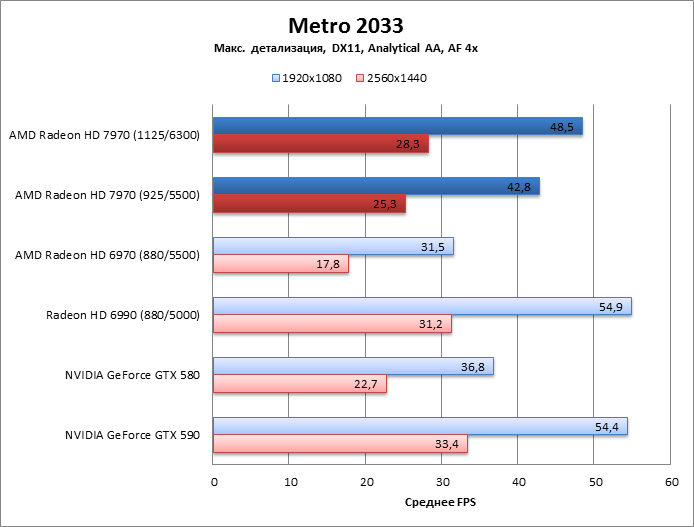
Metro 2033

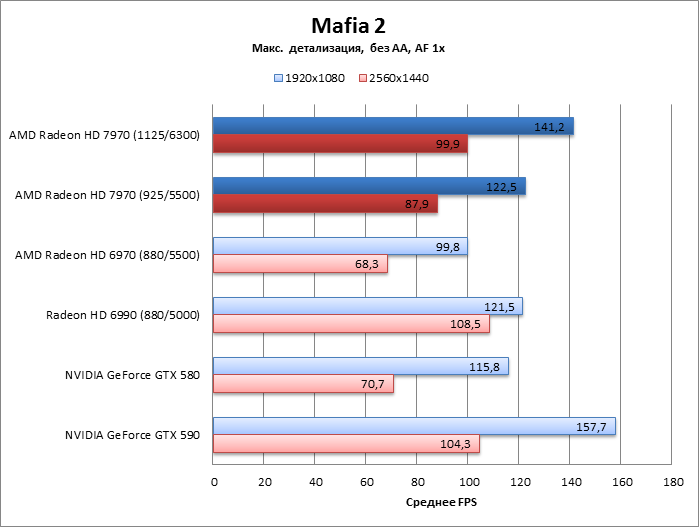
Mafia 2

Just Cause 2
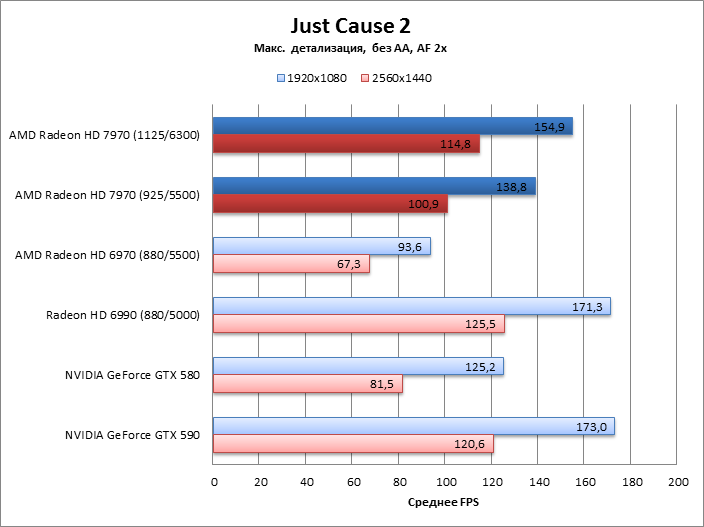
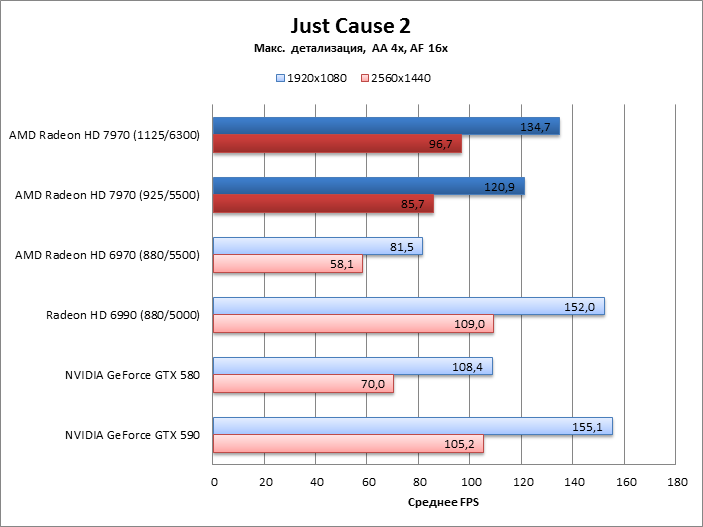
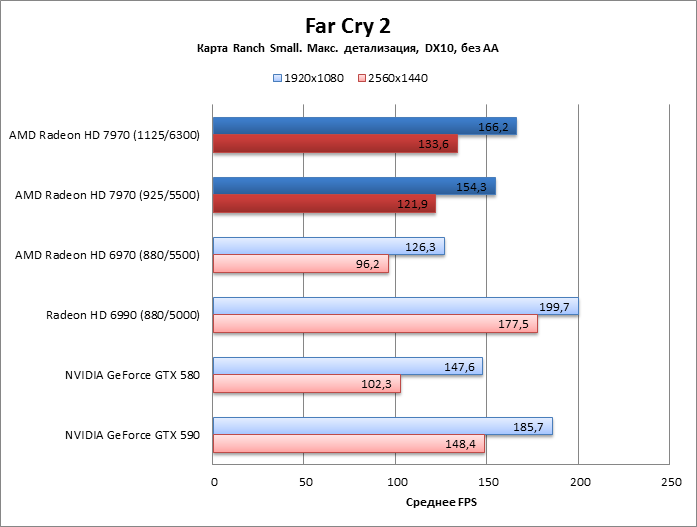
Far Cry 2

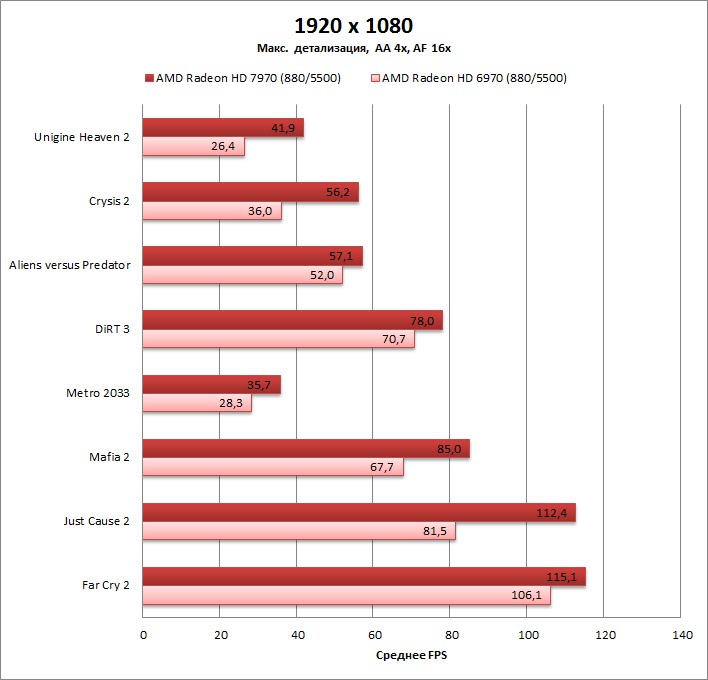
VLIW4 vs GCN
Напоследок мы прогнали Radeon HD 7970 через игровые тесты на равных частотах с Radeon HD 6970. Диаграмма наглядно показывает, какое преимущество новая архитектура GCN дает сама по себе по сравнению c VLIW4.
AMD с чистого листа создала GPU, которые радикально отличаются от всего, что было выпущено под маркой Radeon за последние несколько лет. По масштабу изменений событие сопоставимо с внедрением унифицированной шейдерной архитектуры VLIW5 в чипе R600 (Radeon HD 2900). Но если вы вспомните, какой нелегкий путь пришлось проделать VLIW5, прежде чем раскрылись заложенные в нее возможности, то станет заметно, что на этот раз все совсем по-другому.
Архитектура GCN в лице чипа Tahiti уже сейчас представляет собой зрелый и чрезвычайно эффективный продукт. Radeon HD 7970 на 20-50% быстрее по сравнению с одночиповым флагманом AMD предыдущего поколения и легко справляется с основным конкурентом – GeForce GTX 580. При этом, несмотря на то что Tahiti – это огромный GPU доселе невиданной сложности, карта потребляет не больше энергии, чем HD 6970, и имеет высокий потолок для оверклокинга. А при разгоне производительность уже приближается к уровню двухпроцессорных адаптеров Radeon HD 6990 и GeForce GTX 590.
Отметим, что позиции архитектуры Fermi все еще сильны в задачах с активным использованием возможностей DirectX 11. В некоторых играх GTX 580 лишь немного уступает новинке от AMD, так что у NVIDIA еще есть все шансы взять реванш в следующем году. Не менее интересно будет наблюдать, как AMD шаг за шагом сближает GPU с процессорами общего назначения. CUDA от NVIDIA получила большую фору за прошедшие годы, но теперь у AMD есть столь же мощная графическая архитектура, а еще – процессоры Fusion, которые рано или поздно тоже получат встроенные ядра GCN.