Выставка GTC, которую NVIDIA ежегодно проводит в Сан-Хосе (Калифорния), в этот раз еще сильнее сдвинулась от 3D-графики к неграфическим вычислениям (GP-GPU). Больше всего внимания было уделено машинному обучению, а если точнее – более узкой области этой тематики под названием глубинное обучение. Благодаря параллельным вычислениям на GPU в этой области достигнуты впечатляющие успехи. Системы глубинного обучения выполняют распознавание речи в смартфонах и прочих гаджетах, описывают и сортируют изображения. Не так уж долго осталось ждать беспилотных автомобилей, которыми будут управлять аналогичные системы.
Но обо всем по порядку. Несмотря на научную — по большей части — направленность конференции в этом году, начнем рассказ с традиционных «железных» анонсов NVIDIA, без которых не может обойтись ни одна GTC.
dfCамой яркой премьерой GTC 2015 стал, конечно же, GeForce GTC TITAN X – новый флагман линейки видеокарт NVIDIA, а в связи с отсутствием достойных конкурентов – неоспоримый лидер среди однопроцессорных графических адаптеров. TITAN X основан на самом крупном GPU микроархитектуры Maxwell – GM200 и получил рекомендованную цену (для рынка США) $999. Таким образом, чип GM200 повторил путь своего предшественника GK110, который также дебютировал в серии TITAN с тем же ценником. Однако жизненный путь GM200 начался более успешно, чем у GK110. В отличие от последнего, GM200 попал на рынок в полностью разблокированной конфигурации и в составе двух продуктов одновременно – собственно TITAN X и профессиональный ускоритель Quadro M6000.
Cамой яркой премьерой GTC 2015 стал, конечно же, GeForce GTX TITAN X – новый флагман линейки видеокарт NVIDIA, а в связи с отсутствием достойных конкурентов – неоспоримый лидер среди однопроцессорных графических адаптеров. TITAN X основан на самом крупном GPU микроархитектуры Maxwell – GM200 — и получил рекомендованную (для рынка США) цену $999. Таким образом, чип GM200 повторил путь своего предшественника GK110, который также дебютировал в серии TITAN с тем же ценником. Однако жизненный путь GM200 начался более успешно, чем у GK110. В отличие от последнего, GM200 попал на рынок в полностью разблокированной конфигурации и в составе двух продуктов одновременно – собственно TITAN X и профессионального ускорителя Quadro M6000.
Зная историю первого TITAN, можно предугадать дальнейшую судьбу GM200: рано или поздно этот GPU появится в основной, «нумерованной» линейке GeForce по меньшей цене. А пока TITAN X готов удовлетворить нужды наиболее нетерпеливых геймеров, а также профессиональных пользователей, которым важна высокая производительность в графике и вычислениях FP32.

GeForce GTX TITAN X
Не будем задерживаться на подробностях архитектуры GM200. Достаточно сказать, что кристалл GPU содержит 8 млрд транзисторов, которые образуют 3072 ядра CUDA, 256 текстурных блоков и 96 ROP. Чип обладает 384-битной шиной памяти, а объем RAM в TITAN X составляет 12 Гбайт. При этом видеокарта уложилась в стандартный для топовых моделей NVIDIA тепловой пакет 250 Вт.
Преимущество TITAN X в игровой производительности перед флагманскими адаптерами предыдущего поколения – GeForce GTX 780Ti и Radeon R9 290X (последний также отнесем к предыдущему поколению, поскольку новый GPU AMD Fiji уже не за горами) — составляет от 30 до 50%. За дополнительной информацией отсылаем вас к полному обзору TITAN X.
⇡#Новые Quadro и движок IRAY 2015
Видеокарта для рабочих станций Quadro M6000, также представленная на GTC вслед за TITAN X, с аппаратной точки зрения отличается от последнего немного пониженными частотами GPU и памяти: 988 и 6612 против 1000 и 7012 МГц соответственно. Однако это первый представитель линейки Quadro, наделенный технологией GPU Boost. Ранее этим могли похвастаться только игровые видеокарты и ускорители вычислений Tesla. Как и TITAN X, Quadro M6000 имеет TDP 250 Вт.
Кроме того, карта выделяется четырьмя разъемами DisplayPort 1.2, способными одновременно выводить сигнал на 4К-мониторы. На рынке США ускоритель будет продаваться за сумму в районе 4 тыс. долларов.

Quadro M6000
Одновременно представлена обновленная версия установки NVIDIA VCA (Visual Computing Appliance), предназначенной для рендеринга методом трассировки лучей. В корпусе, который предполагается монтировать в телекоммуникационную стойку, размещаются восемь ускорителей Quadro M6000. VCA – это самодостаточный компьютер с центральным процессором Intel Xeon, 256 Гбайт оперативной памяти и SSD объемом 2 Тбайт. Для коммуникации с внешним миром предусмотрены разъемы Gigabit Ethernet, 10GigE и Infiniband. Рекомендованная цена для рынка США составляет 10 тыс. долларов.

Для рендеринга методом трассировки лучей на установках VCA и отдельных ускорителях Quadro у NVIDIA существует собственный движок — IRAY, который используется во множестве приложений (3ds Max, Maya, Catia и пр.), связанных с дизайном и проектированием, — либо как встроенная опция, либо в форме плагина. На GTC NVIDIA представила обновленную версию продукта — IRAY 2015, которая включает формат описания материалов, независимый от конкретного приложения — MDL (Material Definition Language). MDL позволяет переносить материалы из одной рабочей среды в другую. Кроме того, IRAY 2015 позволяет на лету подключать к рендерингу в дополнение к локальным ресурсам рабочей станции вычислительные мощности других ускорителей Quadro, находящихся в локальной сети (например, пресловутую NVIDIA VCA).
Единственный изъян этих без преувеличения замечательных продуктов на базе GM200 – ограниченная производительность в вычислениях двойной точности (FP64), которая во всей линейке Maxwell составляет 1/32 от FP32. В обзоре TITAN X мы не успели уделить достаточно внимания этому предмету, поэтому сейчас воспользуемся возможностью восполнить пробел. Дело в том, что GM200 просто не имеет такого количества FP64-совместимых ядер CUDA, как GK110, чтобы обеспечить прежнее соотношение 1/3. Это неизбежная жертва, которую пришлось принести во имя прогресса в вычислениях FP32, к которым относится преимущественно графическая и мультимедийная нагрузка – шейдеры, трассировка лучей, рендеринг и кодирование видео. Кроме того, если бы GM200 следовал по стопам GK110, то NVIDIA, скорее всего, пришлось бы включить в транзисторный бюджет ядра FP64 в количестве 1/2 от ядер FP32, поскольку Kepler предусматривает конфигурацию «три блока ядер FP32 на каждый планировщик», а Maxwell – «два блока FP32 на каждый планировщик». Увы, оставаясь в рамках техпроцесса 28 нм, нельзя получить такое быстродействие в FP64, одновременно совершив рывок в графической производительности.
Все это, скорее всего, приведет к тому, что архитектура Kepler (а именно – GK110 в составе TITAN Z и GK210 – обновленный вариант для ускорителей Tesla) останется основной вычислительной платформой NVIDIA вплоть до появления первых продуктов поколения Pascal.
Заканчивая тему новых видеоадаптеров на GTC, упомянем о низкопрофильной карте Quadro K1200 на базе GPU GM107, которая предназначена для рабочих станций компактного форм-фактора.

Quadro K1200
Несмотря на литеру K в названии продукта, новая Quadro базируется на чипе GM107, принадлежащем к семейству Maxwell. Его также можно встретить в игровых ускорителях GeForce GTX 750 и GTX 750 Ti. Однако, в отличие от последних, в Quadro K1200 активны только 512 ядер CUDA из 640 имеющихся в кристалле GM107. Число текстурных модулей и ROP равняется 32 и 16 соответственно. Объём видеопамяти на борту Quadro K1200 составляет 4 Гбайт, шина — 128-битная. Энергопотребление устройства при типичной нагрузке не превышает 45 Вт. Плата несет четыре разъема DisplayPort 1.2, способные выводить изображение одновременно.
⇡#Новые оценки производительности Pascal
Архитектура Pascal, которая последует за Maxwell (и, предположительно, даст первые плоды в 2016 году), в очередной раз засветилась на GTC. Подтверждено, что в Pascal будет использоваться высокопроизводительная Stacked DRAM, а если точнее, то это будет так называемая 2,5D RAM – чипы памяти будут размещены на одной подложке с GPU. Всего Pascal сможет адресовать вплоть до 32 Гбайт локальной памяти, хотя сомнительно, что весь этот объем поместится в чипы 2,5D RAM.

По оценкам NVIDIA, пропускная способность памяти в Pascal превышает таковую в Maxwell в шесть раз. Общая производительность возрастет в пять раз, а в задачах, требовательных к пропускной способности хост-шины, благодаря новому интерфейсу NVLINK будет достигнуто десятикратное преимущество. Впрочем, этим числам следует доверять с оговоркой: оценки даны для вычислительных задач глубинного обучения, да еще и с применением FP16-операций. Последние – еще одно нововведение Pascal, не столь малозначительное, как может показаться (подробнее об этом ниже).
С недавних пор каждая GTC – это не только новый GeForce, но и новая Tegra. Сама система на чипе Tegra X1 была представлена чуть раньше на GDC (Game Developers Conference), но на GTC ей также уделили большое внимание.
Tegra X1 производится по техпроцессу 20 нм и обладает новым GPU с микроархитектурой Maxwell – более производительным и более энергоэффективным, чем графическое ядро Kepler в Tegra K1. CPU Tegra X1 состоит из четырех больших ядер ARM Cortex A57 и четырех мелких ядер ARM Cortex A53 – в соответствии со стандартной архитектурой big.LITTLE, которой пользуются другие производители, лицензирующие IP у ARM (например, Samsung). Внутри у Tegra X1 есть некоторые отличия от распространенной имплементации, но сейчас не будем заострять на них внимание.

Главным носителем Tegra X1 стало новое игровое устройство в линейке SHIELD – ТВ-приставка под управлением ОС Android TV. Использование мобильной SoC и выбор операционной системы классифицируют новый SHIELD как мультимедийный центр для трансляции видео – либо из локальной сети, либо из интернет-сервисов. Благо это первое устройство на базе Android TV, способное воспроизводить 4К-видеоряд с частотой смены кадров 60 Гц и аппаратным декодированием H.265 (HEVC).
И все же основное назначение новинки – игры. Если Tegra K1 по производительности уже сопоставима с большими консолями предыдущего поколения (PS3 и Xbox 360), то Tegra X1 их заведомо превосходит. Среди игр для Android, способных использовать эту мощь, уже есть порт Doom 3 BFG Edition, а Borderlands: The Pre-Sequel и Crysis 3 (да-да) готовятся к выходу. Другой источник игр для SHIELD — трансляция с домашнего ПК или онлайн-сервиса GRID, который официально вышел из стадии бета-тестирования.
Нам на GTC представилась возможность взглянуть на SHIELD своими глазами и немного поиграть. Первое, что стоит отметить, — это физическое воплощение устройства. Среди всего семейства SHILED этот представитель — не только самый мощный, но и лучший с точки зрения дизайна и качества материалов. Коробочка тяжелее, чем кажется на первый взгляд, — 654 г. Но для стационарного устройства это достоинство, а не изъян. Отдельно для SHIELD можно будет купить увесистую подставку, удерживающую устройство в вертикальном положении и не дающую соскользнуть со стола.
Щель между гранями корпуса на лицевой поверхности подсвечивается зеленым светодиодом. Щель на обратной стороне cлужит для охлаждения.
 |
 |
Приставка оснащена двумя портами USB 3.0, портом Micro USB 2.0, кард-ридером формата microSD. Видео выводится через интерфейс HDMI 2.0.

Впечатления от игр, работающих непосредственно на SHIELD, остались сугубо положительные. На выбор были предложены Doom 3 и бета-версия Crysis 3 – обе выводятся в разрешении Full HD. Doom 3, по субъективной оценке, нисколько не потерял в качестве изображения по сравнению с десктопным прообразом и работает очень плавно. Crysis 3, судя по всему, выдает частоту кадров в районе 30 FPS, кроме того, бросается в глаза такой дефект, как грубые полосы на градиентах. Но ведь и уровень графики в целом там намного выше, чем в Doom 3.

Сервис GRID мы тоже оценили. Калифорнийские серверы NVIDIA были совсем рядом, поэтому игры с GRID транслировались с безупречной графикой, чего нельзя сказать о времени реакции на ввод. Как ни крути, а даже с идеальным пингом все-таки есть небольшая задержка, которая быстро начинает действовать на нервы. Посмотрим, сможет ли NVIDIA что-то сделать с этой фундаментальной проблемой в будущем.
Первые партии ТВ-приставки SHIELD поступят в продажу в мае 2015 года по цене $199 (в комплекте с геймпадом, тогда как инфракрасный пульт ДУ нужно будет купить отдельно). В Россию новинка придет позже — не раньше осени.
⇡#Главная тема – глубинное обучение
Tegra X1, как и грядущая микроархитектура Pascal, обладает поддержкой вычислений FP16 (Mixed Precision). Вычисления FP16 исполняются на стандартных FP32-совместимых ядрах CUDA, а одинаковые операции FP16 могут комбинироваться в пары для совместного исполнения на одном ядре. Этот опциональный «даунгрейд» в точности вычислений с плавающей запятой имеет смысл в перспективе задач машинного обучения, к которым NVIDIA питает неослабевающий интерес.
Если на прошлогодней GTC шла речь главным образом о системах компьютерного зрения, оперирующих предопределенными критериями распознавания образов, то официальной темой GTC 2015 стало глубинное обучение. Этот термин нуждается в пояснении. Wikipedia говорит, что глубинное обучение – «набор алгоритмов машинного обучения, которые пытаются моделировать высокоуровневые абстракции в данных, используя архитектуры, состоящие из множества нелинейных трансформаций». Главная область применения глубинного обучения – это распознавание речи, визуальных образов, обучение машины сложному поведению.
Впрочем, чтобы получить общее представление о том, как действует глубинное обучение, не обязательно знать в точности всю математику, лежащую в основе этого метода. Слово «глубинное» в данном случае указывает на расстояние между входным и выходным узлом сети данных, которая формируется в результате обучения машины. Возьмем задачу распознавания образов. Первый ряд узлов здесь соответствует базовым паттернам пикселей – линиям, затем геометрическим примитивам, и в конце концов машина обучается идентифицировать такие сложные, абстрактные объекты, как человеческое лицо, или даже может рассказать, что изображено на предъявленной картинке. Идеальная задача для GPU, использование которых позволило осуществить прорыв в эффективности систем глубокого обучения. В некоторых подобных задачах процент точных ответов уже может достигать 99%, превышая результат живого человека.

Глубинное обучение используют Google и китайский поисковик Baidu для распознавания речи. Кроме того, на GTC Google показала впечатляющий и забавный пример, как машина (а именно ПО Google DeepMind) обучается играть в игры на консоли Atari (смотреть с 47:57).
А вот колесный робот Dave, созданный DARPA. Он научился прокладывать путь и избегать препятствий на сложной местности — в захламленном дворе.
Для того чтобы большие авто со временем тоже смогли обходиться без водителя, NVIDIA выпустила комплект для разработчика DRIVE PX на базе двух чипов Tegra X1 по цене 10 тыс. долларов. Альтернативный вариант – компьютер DRIVE CX с одной SoC в формате автомагнитолы. Программное обеспечение для навигации, компьютерного зрения и вывода изображения на бортовой экран входит в комплект поставки.

Руководитель компании Tesla Элон Маск в беседе с CEO NVIDIA Джен-Саном Хуангом заявил, что автоматическое пилотирование – почти решенная проблема и через несколько лет роботомобили уже повезут нас по дорогам.

Впрочем, выставочный зал GTC в этом году меньше напоминал гараж, чем на GTC 2014. Благо модифицированных машин с дисплеем вместо приборной панели мы уже насмотрелись. А вот автомобиль с корпусом, целиком изготовленным на 3D-принтере (запоздалый отголосок недавнего бума 3D-печати), – это что-то новенькое.
 |
 |

Для построения сетей глубинного обучения в исследовательских целях требуется более мощное железо, чем Tegra X1, и другое ПО. NVIDIA представила программный комплекс DIGITS (название расшифровывается как Deep Learning GPU Training System), который представляет собой полный набор программ для создания глубинных нейронных сетей (DNN) в ходе машинного обучения, а также для управления и диагностики данного процесса. DIGITS обладает графическим пользовательским интерфейсом и не требует от исследователя навыков программирования. В состав пакета входит веб-сервер, с помощью которого осуществляется коллективная работа над проектом. Ускорение вычислений на GPU выполняется посредством библиотеки cuDNN под API CUDA. DIGITS – бесплатный продукт.
 |
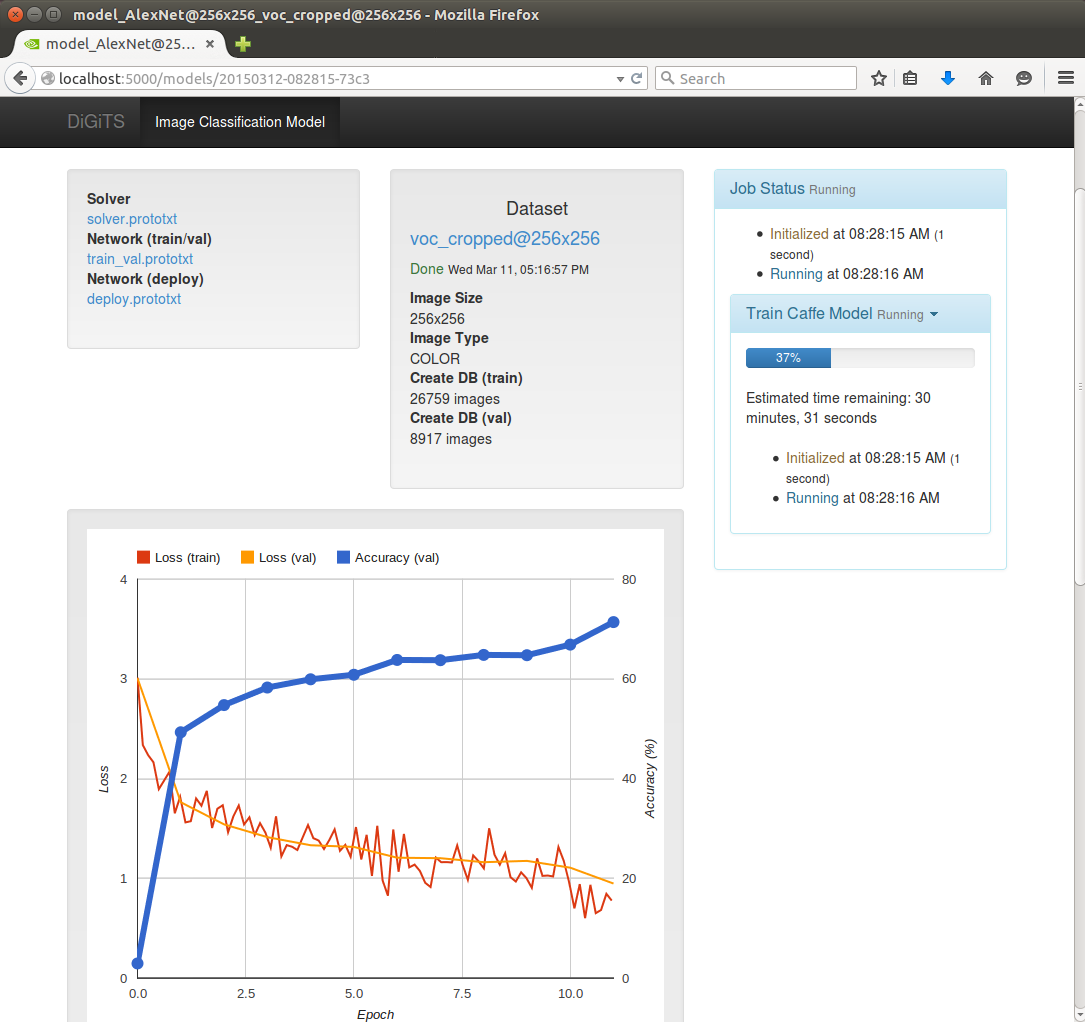 |
В качестве готового аппаратного решения для тренировки нейросетей предлагается DIGITS DEVBOX – рабочая станция на базе платформы Intel X99 с четырьмя ускорителями TITAN X на борту под управлением ОС Ubuntu 14. DEVBOX доступен для исследователей в США по цене 15 000 долларов.

Внутренности DIGITS DEVBOX
Один из журналистов на сессии вопросов и ответов пошутил, что NVIDIA больше не является графической компанией. Это, конечно, большое преувеличение. Вынужденная задержка на техпроцессе 28 нм сделала ландшафт графических ускорителей довольно унылым, но в случае с чипом GM200 и продуктами на его основе (TITAN X, Quadro M6000) NVIDIA грамотно распорядилась имеющимися ресурсами, чтобы обеспечить очередной рывок производительности в 3D-графике. И все-таки графика – это уже устоявшаяся и предсказуемая отрасль. Бурные преобразования происходят именно в тех темах, на которых была сфокусирована GTC 2015, – вычисления GP-GPU, гаджеты, машинное обучение. Кроме того, с каждым годом NVIDIA действительно отдаляется от позиции «чистого» производителя железа и стремится создать целостную экосистему в тех областях, которыми занимается (будь то глубинное обучение или игры на Android).
Кстати, советуем посмотреть наш репортаж из лабораторий штаб-квартиры NVIDIA в Санта-Кларе. Так работают над продуктами, которые затем появляются на GTC.