Параллельно с конференцией Supercomputing 2016, которая состоялась 13–18 ноября в Солт-Лейк-Сити (см. репортаж нашего корреспондента), Intel провела отдельное мероприятие в Сан-Франциско — Intel AI Day, посвященное тематике искусственного интеллекта и машинного обучения, в котором участвовало высшее руководство компании, включая ее главу Брайна Кржанича. Мы также присутствовали на AI Day и готовы поделиться с читателями информацией из первых рук.
Содержание конференции частично перекликается с тем, о чем Intel говорила на SC16, но для AI Day компания приберегла наиболее значимые объявления в области ИИ, а именно — анонс аппаратной платформы Nervana для широкого класса задач машинного обучения и специализированных ускорителей глубинного обучения (бурно развивающегося сегодня компонента ИИ) — семейства Lake Crest/Knights Crest.

Intel сегодня безоговорочно доминирует на рынке центральных процессоров для серверов. Однако GPU, появившиеся на сцене HPC в 2010 году, за прошедшее время заняли место основной рабочей силы в массово-параллельных вычислениях. Intel, с другой стороны, понадобилось еще два года с тех пор для того, чтобы собраться с силами и выпустить альтернативный продукт Xeon Phi на основе предыдущих разработок графической архитектуры Larrabee.
В широкой области массово-параллельных вычислений Intel уже чувствует себя уверенно. В списке суперкомпьютеров TOP500 на данный момент есть 100 кластеров, оснащенных массово-параллельными процессорами, из которых 70 укомплектованы картами Tesla, а 22 — Xeon Phi (и есть лишь один на базе AMD FirePro).
Что касается машинного обучения, то в прошлом году, по данным Intel, лишь 0,15% всех серверов в мире были зарезервированы для тренировки и эксплуатации глубоких нейросетей. Но это направление выглядит столь многообещающим, что Intel готова пойти на серьезные перемены, чтобы не отдать развивающийся рынок ИИ в руки конкурентов. Новая стратегия в сфере HPC (High-Performance Computing), которая привлечет клиентов на сторону процессорного гиганта, включает создание специализированных аппаратных решений и полного стека ПО для машинного обучения.
К грядущему противостоянию с GPU Intel хорошо подготовилась за последний год. В 2015-м компания поглотила производителя FPGA (ПЛИС) Altera. Несмотря на то, что для создания сетей глубинного обучения используются ASIC (Application-specific Integrated Circuit), к которым относятся GPU и другие массово-параллельные архитектуры, FPGA могут стать удобным решением для эксплуатации готовых сетей. Это уже подтвердил опыт Microsoft, применившей FPGA для обслуживания поискового движка Bing, и Baidu (китайского конкурента Google), который использует программируемые микросхемы для поиска и распознавания изображений.
В число недавних приобретений Intel вошли компании Saffron, Modivius и Nervana Systems, которые обладают активами для разработки ПО и аппаратного обеспечения в сфере искусственного интеллекта. Saffron предоставила Intel высокоуровневую платформу для построения ИИ при помощи различных методов — как машинного обучения, так и аналитических. Кроме того, технологии Saffron подходят для работы на небольших вычислительных мощностях, а значит — для мобильных гаджетов и сферы IoT, к которой Intel также проявляет повышенный интерес.
Movidius (сделка по покупке которой сейчас находится в процессе завершения) занимается технологиями машинного зрения. В частности, компания проектирует ASIC для этой цели. Две микросхемы под маркой Myrad уже воплощены в кремнии.

Что касается Nervana, то этот стартап принес Intel наиболее значимые активы в сфере ИИ. Компания уже сникала славу создателя наиболее производительного фреймворка для обучения нейросетей — Neon — и проектирует аппаратные решения, обещающие радикально сократить время обучения: сначала с дней до часов, а в перспективе — минут. Специализированные чипы, построенные на логике Nervana Engine (Intel окрестила их Lake Crest и Knights Crest), как сообщает Intel, обеспечат не только беспрецедентную удельную производительность в целевых задачах, но и легкую масштабируемость суперкомпьютеров благодаря высокой вычислительной плотности и скорости коммуникации между узлами.
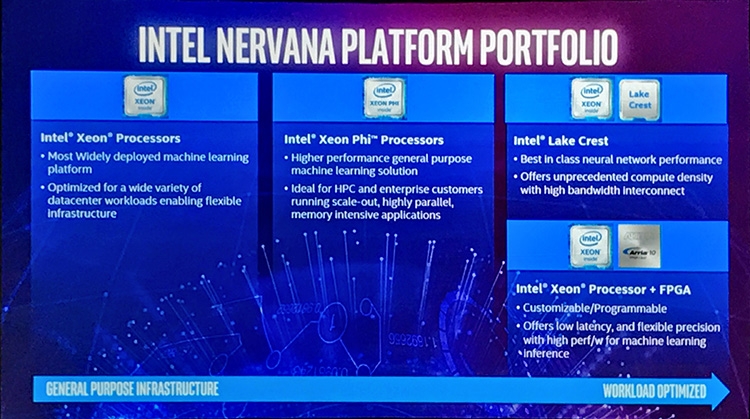
Объединенным результатом масштабных приобретений Intel и ее собственных разработок, представленным на AI Day, стала платформа для задач машинного обучения Nervana, которая на данный момент включает три категорий устройств — центральные процессоры Xeon, ускорители массово-параллельных вычислений Xeon Phi и, наконец, специализированные продукты, выполняющие, с одной стороны, обучение нейросетей и, с другой, применение готовых сетей на практике (inference).
CPU в суперкомпьютерах, посвященных созданию и применению ИИ, нужны по большей части только для загрузки ОС и управления работой, поэтому классическим Xeon на AI Day досталось немного внимания. Впрочем, одновременно с AI Day Intel представила на SC16 обновленный флагман линейки Xeon на чипе Broadwell-EP — Xeon E5-2699A v4, и уже стартовало опытное производство процессоров с кремнием Skylake-EP, который принесет наиболее масштабное обновление серверной платформы Intel со времен Sandy Bridge-EP.
Основной рабочей силой Intel для массово-параллельных вычислений вообще и тренировки нейросетей в частности являются ускорители Xeon Phi на базе чипа Knights Landing. И хотя Xeon Phi не достиг полного паритета по производительностис архитектурой Pascal от NVIDIA, Knights Landing имеет ряд преимуществ перед графическими процессорами.
Ускорители поставляются не только в виде дискретных плат PCI Express, но и в конструктиве LGA 3647 (общий разъем для Xeon Phi и Skylake-EP). Последний вариант, в отличие от GPU, может самостоятельно загружать ОС и наряду с массивом высокоскоростной набортной памяти MCDRAM (разновидность HBM) напрямую адресует внешние модули DDR4 SDRAM объемом вплоть до 384 Гбайт. На подложке процессора также есть выделенный контроллер высокоскоростного интерфейса Omni-Path для коммуникации с другими узлами в кластере.
Кроме того, архитектура MIC, лежащая в основе Xeon Phi, оперирует набором команд x86, что потенциально позволяет использовать код и практики программирования, наработанные для центральных процессоров. Отдельно Intel замечает, что благодаря оптимизации ПО скорость обучения нейросетей на Xeon Phi может быть увеличена 400-кратно (на примере задачи распознавания изображений).
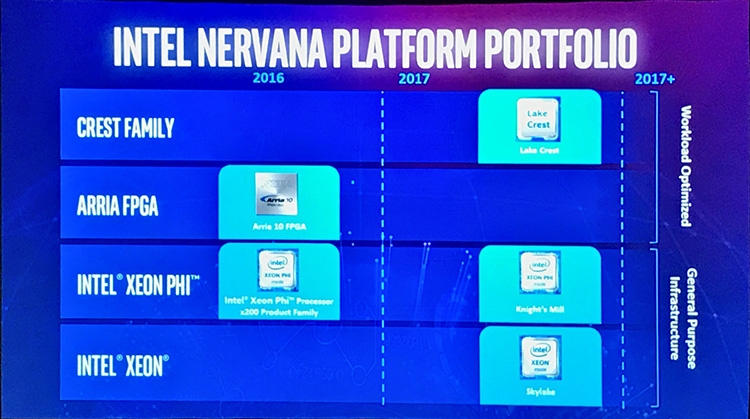
В 2017 году на замену Knights Landing в платформе Nervana придет процессор Knights Mill, специализирующийся на машинном обучении, о котором Intel объявила на последнем IDF. Ожидается, что Knights Mill обеспечит четырехкратный прирост быстродействия в задачах глубинного обучения по сравнению с предыдущей итерацией Xeon Phi и превзойдет архитектуру Pascal от NVIDIA. О самом чипе по-прежнему известно совсем немного, однако мы объединим всю доступную на данный момент информацию.
Определяющий признак Knights Mill — то, что Intel довольно расплывчато обозначила термином «переменная точность». Скорее всего, речь идет о поддержке формата чисел с плавающей запятой FP16 (половинная точность) либо других форматов с еще меньшей разрядностью. FP16 является удобным вычислительным примитивом для задач глубинного обучения, поскольку здесь не требуются полная точность, а пропускная способность возрастает при условии, что FP16 поддерживается процессором «в железе». Неспроста поддержка половинной точности включена в GPU последнего поколения от AMD и NVIDIA.
Заметьте, что на слайде отсутствует Knights Hill, который должен был стать преемником Knights Landing в качестве универсального процессора архитектуры MIC четвертого поколения. Intel перестала упоминать о нем после того, как представила Knights Mill на IDF, но, судя по имеющейся информации, разработка Knights Hill продолжается и он рано или поздно будет построен, уже на техпроцессе 10 нм.
Cледующее решение займет другую нишу — применение готовых сетей для обработки новых данных (inference). Плату DLIA (Deep Learning Inference Accelerator) на базе ПЛИС Arria 10 Intel продемонстрировала на Supercomputing 2016 и обещает выпустить в следующем году. Благодаря программируемой логике, DLIA способна пропускать данные через нейросеть с большей энергоэффективностью по сравнению с CPU или GPU. К примеру, производительность при распознавании изображений сетью AlexNet на базе фреймворка Caffe на DLIA составляет 25 кадров в секунду на ватт мощности (сравнительные данные, к сожалению, Intel не приводит).

DLIA является дискретным ускорителем с шиной PCI Express x8, но Intel уже экспериментирует с интеграцией FPGA в процессоры Xeon. Компания начала пилотные поставки специальной версии Xeon E5-2600 v4 в многочиповом корпусе с микросхемой Arria 10. В будущем разработчики планируют объединить кристаллы, что позволит ускорить коммуникацию между CPU и FPGA, а также снизить энергопотребление за счет передовой фотолитографии Intel.

Однако главное объявление Intel на AI Day — анонс нового ускорителя, еще лучше справляющегося с задачами глубинного обучения. Чип Lake Crest основан на разработках Nervana, которая планировала выпустить собственную ASIC — Nervana Engine, отличную по архитектуре и применяемой ISA как от предыдущих x86-совместимых чипов Xeon Phi, так и от графических процессоров. Nervana Engine воплощает в железе логику, необходимую для построения сетей глубинного обучения, и ничего кроме нее. Благодаря новой архитектуре ускорителей корпорация планирует к 2020 году достигнуть амбициозной цели — 100-кратного сокращения времени на тренировку сетей по сравнению с лучшими GPU сегодняшнего дня.
⇡#Что такое глубинное обучение
Чтобы объяснить, почему Lake Crest является идеальной машиной для глубинного обучения, уместно напомнить, как именно работает этот метод. В основе глубинного обучения лежит построение многоуровневой сети признаков, которая затем может выполнять категоризацию входящих данных на весьма абстрактном уровне, к примеру описать, что компьютер «видит» на картинке.
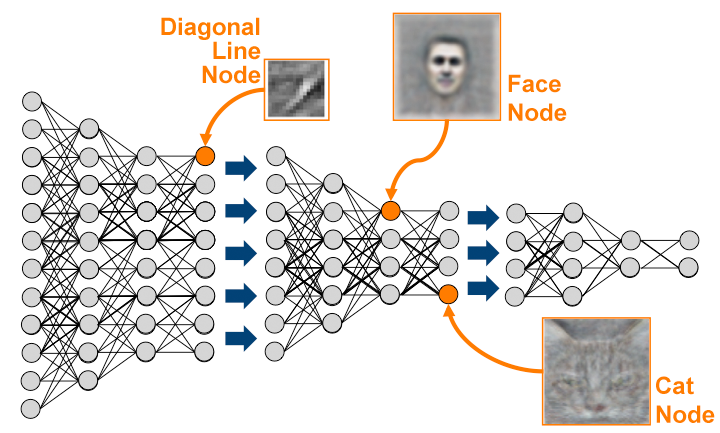
Нейроны на первом уровне обнаруживают базовые компоненты изображения (линии) и передают свое решение на уровень выше, «нейроны» которого (взвешивая ввод от отдельных нейронов предыдущего уровня и применяя нелинейную активационную функцию, которая включает либо выключает нейрон для передачи сигнала выше по цепочке) складывают входящие данные в простые формы и передают на следующий уровень. На самом верху находятся нейроны, соответствующие целым объектам («нейрон человеческого лица», «нейрон кошки» и т. д.).
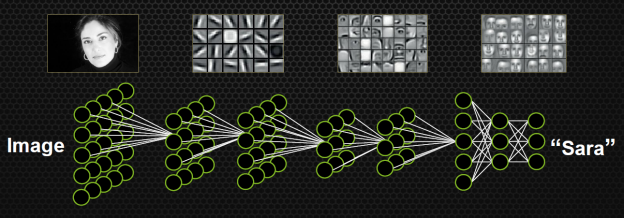
Согласно экспериментальным свидетельствам, по такому принципу действуют зрительные области в мозге живых существ (за это Дэвид Хьюбел и Торстен Визель получили Нобелевку в 1981 году), что и послужило прообразом для создания искусственных глубоких нейросетей. Однако в самой нейронауке возникают проблемы при попытке объяснить теорией обнаружения признаков весь процесс восприятия (тем более человеческого) — хотя бы потому что в коре мозга недостаточно клеток, чтобы выделить по одной на каждый возможный признак. Искусственные нейросети, напротив, лишены такого ограничения и могут быть сколь угодно крупными, чтобы решать с высокой точностью такие сложные задачи, как распознавание визуальных образов и человеческой речи. Фактически искусственный интеллект уже способен делать это не хуже, чем человек (как показали достижения Baidu и Microsoft), хоть и с некоторыми ограничениями.
Впрочем, преждевременно считать глубинное обучение последним словом в искусственном интеллекте. Такие сети подходят для классификации объектов или поиска скрытых структур в данных, но не могут, скажем, исследовать причинно-следственные связи и делать логические выводы. К примеру, знаменитый ИИ Watson компании IBM включает машинное обучение лишь как один из компонентов. Эта система была создана для игры Geopardy! (в России известна как «Своя игра»), где в 2011 году победила двух лучших игроков США на то время и заработала своим создателям приз в 1 млн. долларов (который IBM отдала на благотворительность).
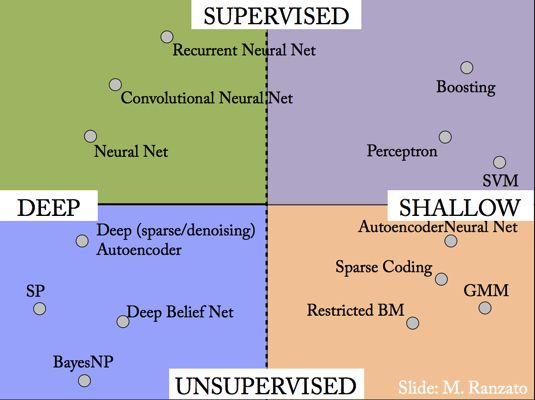
Глубинное обучение может происходить с вмешательством человека (supervised) — в таком случае для тренировки сети используются маркированные данные (labeled data), к примеру картинки с описанием изображенных на них объектов. Задача компьютера состоит в том, чтобы построить иерархию признаков, которая сможет связать набор пикселов на входе с заранее известным описанием. Иногда материал в основном состоит из немаркированных данных, но включает часть маркированных (semi-supervised) — это также называется обучением с подкреплением (reinforced learning).
В противоположном случае (unsupervised) алгоритм самостоятельно формирует «понятия», в которых описывает входящие данные. К примеру, Google еще в 2012 году построил нейросеть, используя 10 миллионов случайных кадров c YouTube для тренировки. Сеть в результате научилась распознавать человеческие лица с точностью 81,7% (а также человеческие тела и кошачьи мордочки), хотя в процессе ей ни разу не подсказывали, на какой картинке есть лицо, а на какой — нет. Всего модель включает 1 млрд признаков и состоит из девяти слоев.
Самообучающиеся глубокие сети хороши либо в таких случаях, когда нужно сэкономить человеческие ресурсы, избежав маркировки данных, либо для обнаружения скрытых закономерностей. К примеру, PayPal при помощи глубинного обучения ищет признаки криминальной активности в транзакциях между счетами.
⇡#Архитектура Intel Lake Crest/Knights Crest
Крупные глубокие нейросети, в особенности самообучающиеся, требуют огромной вычислительной мощности для тренировки в разумные сроки. Кроме того, вся модель уже не может поместиться в локальную память одного ускорителя. Как следствие, используются кластеры процессоров, а скорость коммуникации между узлами — это главный фактор, который ограничивает масштабирование производительности.

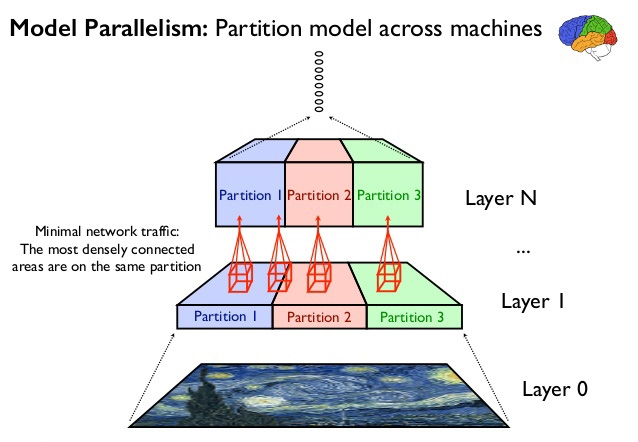
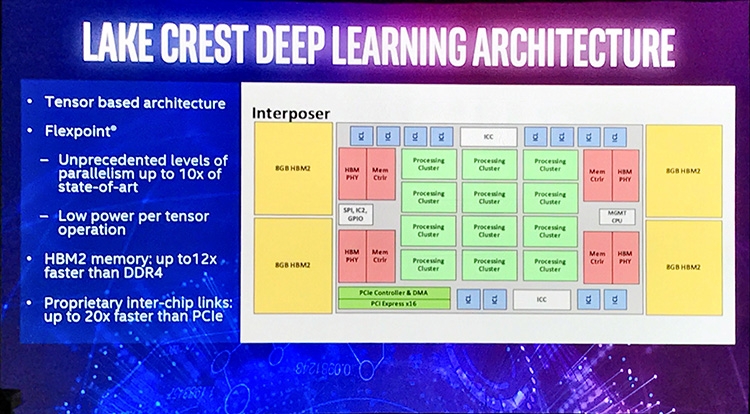
Разработки Nervana направлены на устранение этого бутылочного горлышка. Lake Crest изначально рассчитан на т. н. модельный параллелизм построения сети. При этом методе распределения нагрузки каждый узел работает с частью модели (группой нейронов на нескольких уровнях), но имеет доступ ко всему массиву обучающих данных (в противоположность параллелизму данных, когда узлу доступны все признаки, но лишь часть данных). Для коммуникации между узлами Lake Crest используется проприетарный интерфейс, который включает 12 каналов на чип с пропускной способностью 100 Гбит/с и позволяет соединять узлы как в пределах одного корпуса, так и в разных серверах. Интерфейс работает напрямую, без кеширования, что обеспечивает минимальную латентность транзакций. Быстродействие кластера Lake Crest будет прирастать практически линейно по мере увеличения количества узлов.
В качестве локальной памяти Lake Crest оснащается четырьмя сборками HBM2 совокупным объемом 32 Гбайт, размещенными вместе с самой ASIC на кремниевой подложке (точно так же, как это сделано в GPU Fiji от AMD и NVIDIA GP100). Совокупная пропускная способность установленной памяти составляет 1 Тбайт/с.
Другое достоинство архитектуры Lake Crest в том, что чип лишен элементов общего назначения, свойственных CPU и GPU. В число последних входит логика фиксированной функциональности для рендеринга графики — блоки наложения текстур, T&L, ROP и пр., но также контроллеры кеш-памяти, наличие которых для Lake Crest было бы не только бесполезно, но и вредно. В глубинном обучении доступ к памяти определяется перед исполнением программы, и при софтверном управлении кешем приоритетные данные (такие как веса нейронов) случайно не удаляются из кеша высокого уровня.
Еще одной фундаментальной особенностью Lake Crest является специальный формат данных FlexPoint, который сочетает лучше черты целочисленного формата (быстродействие операций) и формата с плавающей запятой (точность). В отличие от GPU NVIDIA и AMD последнего поколения, в которых при обучении нейросетей применяется формат половинной точности (FP16), Nervana Engine оперирует многомерными массивами 16-битных целых чисел — «тензорами» (что в данном случае не тождественно одноименному понятию в математике). Ранее тензоры уже нашли применение в ПО TensorFlow от Google и чипах TPU (Tensor Processing Unit), которые Google применяет для эксплуатации, но не обучения нейросетей. Благодаря FlexPoint параллелизм операций увеличивается в 10 раз по сравнению с GPU, а следовательно, повышается соотношение производительности на такт и на ватт мощности.

В кремнии Lake Crest Intel собирается получить уже в первой половине 2017 года. ASIC будет выполнена по технологической норме 28 нм, а подрядчиком по производству станет TSMC. По всей видимости, Nervana успела далеко продвинуться в проектировании микросхемы до того, как оказалась под крылом Intel. Конечный продукт будет выполнен в виде платы расширения с шиной PCI Express для соединения с хост-процессором. Помимо прямых продаж ускорителей, Intel откроет облачный сервис для клиентов, желающих воспользоваться кластером Lake Crest.
Впоследствии Intel будет производить детище Nervana на собственных фабриках в форме гибридного процессора Knights Crest, объединяющего x86-ядро Xeon (одно или несколько) и ускоритель глубинного обучения — либо в виде двух дискретных чипов на одной подложке, либо в виде единого кристалла. Процессор сможет самостоятельно загружать ОС, а единое пространство высокоскоростной локальной памяти упростит программирование и устранит издержки на перемещение данных между памятью CPU и ускорителя. Проприетарный интерфейс для соединения узлов наверняка сохранится в этом форм-факторе.
⇡#Стек ПО Intel для машинного обучения
На AI Day Intel представила большой набор программного обеспечения, связанного с глубинным обучением и, шире, искусственным интеллектом в целом. Эта часть не менее важна, чем анонс нового железа, т. к. архитектура x86 сама по себе еще не гарантирует простоты внедрения Xeon Phi для машинного обучения по сравнению с GPU. Напротив, NVIDIA за девять лет существования CUDA создала большое наследие ПО и приучила разработчиков к своему языку программирования. FPGA и ускорители Nervana, на которые сделала ставку Intel, потребуют отдельных усилий для интеграции в рабочий поток. Но теперь Intel располагает единым стеком ПО, начиная с вычислительных и коммуникационных примитивов и заканчивая SDK глубинного обучения и полной платформой для создания многокомпонентного ИИ.
В самом низу стека Intel предлагает библиотеку kernel’ов для глубинного обучения (Math Kernel Library for Deep Neural Networks — MKL-DNN) и библиотеку для коммуникации между узлами (DL Multi-node Scaling Library), а затем выпустит полный API для коммуникации между узлами в кластере ускорителей (Machine Learning Scaling Library — MLSL).
Фреймворк Neon, разработанный Nervana, также перешел в распоряжение Intel и в будущем будет дополнен ПО Nervana Graph Complier — прослойкой для распределения нагрузки между узлами и оптимизации под различное железо. Intel также владеет собственным вариантом Python — модели в среде Neon создаются именно на этом языке.

На высшем уровне находится программная платформа Saffron, которая организует весь процесс создания ИИ. Сюда входит не только глубинное, но и другие методы машинного обучения, а также алгоритмы «мышления» (reasoning). Весь рабочий поток в системе Saffron прозрачен для наблюдателя, т. е. исследователь сможет узнать, каким путем искусственный интеллект пришел к тому или иному выводу, в то время как зачастую процесс принятия решения нейросетью представляет собой «черный ящик».
Наконец, Intel выпустила предварительную версию Deep Learning SDK, которая позволяет создавать модели на базе глубинного обучения в графическом UI даже без необходимости писать код вручную, а затем оптимизировать и внедрять в эксплуатацию на различных устройствах, включая автомобили и БПЛА. Поддерживается импорт готовых моделей из других фреймворков. Для исследователей, студентов и программистов, желающих пройти ликбез по машинному обучению, Intel открыла на своем сайте программу Nervana AI Academy.

Глубинное обучение как метод создания искусственного интеллекта открывает головокружительные перспективы и уже привлекло влиятельных сторонников (таких как Google, Microsoft и Baidu), хотя пока составляет крошечный процент рынка HPC. NVIDIA смогла собрать первый урожай заказов, но в долговременном масштабе у Intel есть все возможности, чтобы завоевать лидерство.
На AI Day Intel представила программную платформу, покрывающую все стадии разработки и внедрения ИИ, совместимую с существующей аппаратурой широкого назначения — Xeon Phi и ПЛИС Altera. Однако основные надежды Intel возлагает на Knights Mill — все еще универсальный массово-параллельный процессор, оптимизированный для глубинного обучения, и Lake Crest/Knights Crest — специализированные чипы для тренировки нейросетей. Lake Crest — первый из процессоров, рассчитанных на столь узкую функцию, и это предвещает большие перемены на рынке ИИ.
Intel стремится сделать глубинное машинное обучение массово доступной технологией — как для исследователей и крупных корпораций, создающих нейросети, так и для частных пользователей, которые со временем смогут использовать ИИ в своих устройствах — компьютерах, гаджетах, дронах и беспилотных автомобилях.