Заводя разговор о функциональной начинке FineReader, первым делом следует вкратце рассказать о трех базовых принципах — целостности, целенаправленности и адаптивности (Integrity, Purposefulness and Adaptability, сокращенно IPA), лежащих в основе OCR-решений ABBYY и применяющихся на всех стадиях и уровнях обработки документов. Принципы эти взяты не с потолка и продиктованы многолетними научными исследованиями о зрительном восприятии объектов человеком, и именно благодаря им технологии распознавания ABBYY могут принимать решения, самообучаться и эволюционировать.
Согласно первому правилу — принципу целостности (integrity) — наблюдаемый объект всегда рассматривается как целое, состоящее из множества взаимосвязанных частей. Принцип целенаправленности (purposefulness) говорит, что любая интерпретация данных должна преследовать какую-то цель. Таким образом, распознавание — это процесс выдвижения гипотез обо всем объекте целиком и целенаправленная их проверка. Третий принцип — адаптивности (adaptability) — подразумевает способность системы к самостоятельному обучению и умению использовать ранее накопленные знания об объектах. Полученная при распознавании информация упорядочивается, сохраняется и используется впоследствии при решении аналогичных задач.

Базовые принципы технологий распознавания текста ABBYY
В соответствии с ключевыми положениями IPA, разбираемый ABBYY FineReader фрагмент изображения, согласно принципу целостности, будет интерпретирован как некий объект (символ), только если на нем присутствуют все структурные элементы с соответствующими взаимосвязями. При этом система выдвигает ряд гипотез относительно того, на что похож обнаруженный объект, затем они целенаправленно проверяются с использованием принципа адаптивности, подразумевающего наличие накопленных ранее сведений о возможных начертаниях символа в распознаваемом документе.
⇡#Предварительная обработка и структурный анализ изображения
На этапе предварительной обработки и анализа графических данных перед любой OCR-системой стоят две основные задачи: подготовка изображения к процедурам распознавания и выявление логической структуры документа — с тем, чтобы в дальнейшем иметь возможность воссоздать ее в электронном виде.
Для решения первой задачи в ABBYY FineReader задействован механизм бинаризации, то есть преобразования цветного или полутонового образа в монохромный (глубина цвета 1 бит). Бинаризация существенно ускоряет процесс анализа графических элементов. В случае обработки документов с подложенными текстурами и фоновыми рисунками в дело вступает система адаптивной бинаризации (Adaptive Binarization, AB), исследующая яркость фона и насыщенность черного цвета на протяжении всей строки или слова и подбирающая оптимальные параметры преобразования для каждого фрагмента изображения по отдельности.

Без обработки процедурой адаптивной бинаризации этот документ может быть распознан с ошибками
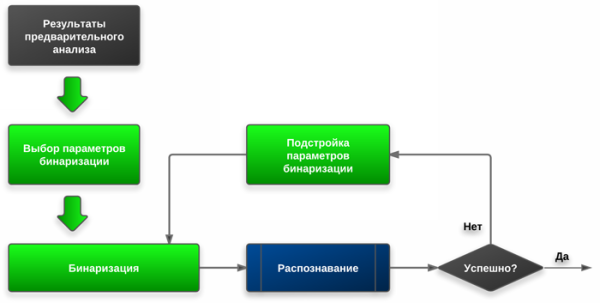
Обобщенная блок-схема алгоритма процедуры адаптивной бинаризации
С точки зрения технической реализации идея AB заключается в использовании обратной связи для оценки качества преобразования того или иного участка изображения. Если система видит, что после бинаризации появляется куча мелких элементов и ломаных кривых, не представляющих связные области, похожие на символы, то она автоматически корректирует порог бинаризации на конкретном участке до тех пор, пока не останется картинка, похожая на чистый текст. В случае обработки текстов со сложным фоном могут слушаться погрешности, и от этого никуда не деться.
Вторая задача в ABBYY FineReader решается с использованием алгоритмов многоуровневого анализа документов (Multilevel Document Analysis, MDA), осуществляющих разбор последних поэтапно, сверху вниз, посредством деления страниц на объекты низших уровней вплоть до отдельных символов. При этом обработка изображений осуществляется в полном соответствии с упомянутыми выше принципами IPA: в первую очередь выдвигаются гипотезы относительно типов обнаруженных объектов, затем они целенаправленно проверяются с учетом зафиксированных ранее особенностей данного документа.
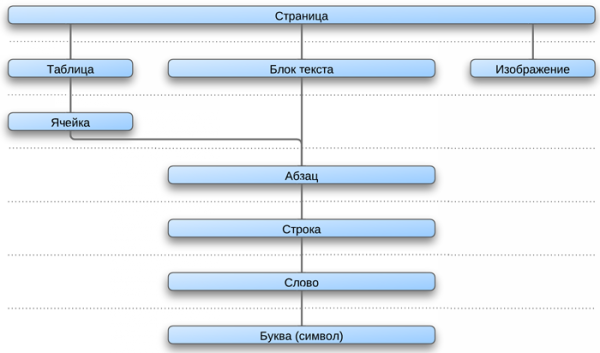
Иерархическая структура документа
Ключевую роль в процессе предварительного анализа изображения и последующей сборки обработанных данных в единое целое играет адаптивная технология распознавания документов ADRT (Adaptive Document Recognition Technology). Лежащие в ее основе алгоритмы «смотрят» на контекст документа, находят общие структурные элементы, выявляют связи между ними и сохраняют полученные сведения для использования на финальных этапах синтеза либо экспорта данных в выбранный пользователем формат. Система распознает колонтитулы, нумерацию страниц, разноуровневые заголовки, подписи к картинкам, а также стили шрифтов и прочие элементы. ADRT буквально «понимает» структуру документа и «знает», где должны находиться те или иные элементы, в каком порядке и в каком формате. Так, например, верхний колонтитул будет воссоздан как настоящее поле колонтитула при конвертировании документа в Word, и пользователь при необходимости сможет отредактировать или удалить его на всех страницах одновременно.
⇡#Распознавание символов. Классификаторы
Для распознавания символов в программе FineReader используются специальные механизмы, именуемые классификаторами и порождающие список гипотез, которые затем целенаправленно проверяются. Входными данными для классификаторов можесть служить не только графическая информация, но и сформированный в ходе распознавания список гипотез. В последнем случае классификатор не выдвигает новых гипотез, а лишь изменяет веса имеющихся, подтверждая или опровергая их. Такой подход, в котором также четко прослеживаются принципы IPA, обеспечивает более интеллектуальный анализ изображения и наиболее точное распознавание документа.
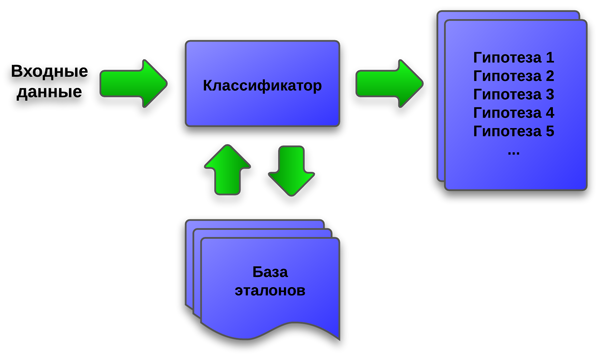
Упрощенная схема работы классификатора
В OCR-решениях ABBYY задействованы шесть классификаторов — растровый, признаковый, признаковый дифференциальный, контурный, структурный и структурный дифференциальный, применяющиеся в зависимости от контекста документа, входных параметров изображения и задач распознавания. Набор используемых классификаторов во многом зависит от сложности обрабатываемого изображения и результатов первого прохода распознавания.
Рассмотрим вкратце свойства и особенности каждого из перечисленных классификаторов.
Растровый классификатор. Один из самых простых и быстрых классификаторов, принцип действия которого основан на прямом сравнении изображения символа с эталоном. Степень несходства при этом вычисляется как количество несовпадающих пикселей. Для обеспечения приемлемой точности растрового классификатора требуется предварительная обработка изображения: нормализация размера, наклона и толщины штриха. Эталон для каждого класса обычно получают, усредняя изображения символов обучающей выборки. В OCR-решениях ABBYY растровый классификатор, как правило, используется на начальных этапах распознавания для оперативного порождения предварительного списка гипотез.
Признаковый классификатор. Логика работы этого классификатора заключается в формировании для каждого изображения символа N-мерного вектора признаков и его последующем сравнении с набором эталонных векторов той же размерности. Формирование вектора (извлечение признаков) производится во время анализа предварительно подготовленного изображения. Эталон для каждого класса получают путем аналогичной обработки символов обучающей выборки. Назначение признакового классификатора — то же, что у растрового: быстрое порождение списка предварительных гипотез.
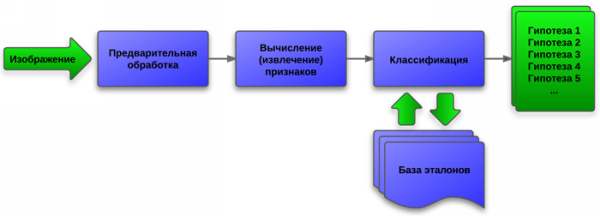
Блок-схема работы признакового классификатора
Признаковый дифференциальный классификатор. В задачи этого модуля входит обработка похожих друг на друга объектов, таких, например, как буква «m» и сочетание «rn». Он анализирует только те области изображения, где может находиться информация, позволяющая отдать предпочтение одному из вариантов. Так, в случае с «m» и «rn» ключом к ответу служит наличие и ширина разрыва в месте касания предполагаемых букв. Признаковый дифференциальный классификатор представляет собой набор признаковых классификаторов, оперирующих полученными для каждой пары схожих символов эталонами.
Контурный классификатор. Первоначально был создан и использовался для распознавания рукописного текста средствами ICR-технологий (Intelligent Character Recognition), затем был успешно применен и для обработки печатных документов. Механизм работы во многом схож с принципом действия признакового классификатора, а различие состоит в том, что для извлечения признаков контурный классификатор использует контуры, предварительно выделенные на изображении символа.
Структурный классификатор. Еще один классификатор, заимствованный из мира ICR-систем и анализирующий, как следует из названия, структуру символов: различные составляющие элементы, куски окружностей и отрезков, фрагменты, соединения, крайние точки, разрывы и тому подобное. Реализация структурного классификатора позволила разработчикам ABBYY избавиться от сбоев OCR-платформы при обработке букв различного размера и создать шрифтонезависимое решение, отрабатывающее на завершающих этапах распознавания. Входными данными для структурного классификатора являются изображение символа и ранжированный список гипотез, сформированный по результатам работы остальных распознавателей. Собственных гипотез не выдвигает, подтверждая либо опровергая ранее выдвинутые гипотезы.
Структурно-дифференциальный классификатор. Как и признаково-дифференциальный, этот классификатор решает задачи различения похожих объектов, например таких, как символы C и G. Анализируя соответствующие части изображения, вычисляя значения признаков, структурно-дифференциальный классификатор позволяет различать каждую конкретную пару символов, опираясь на накопленные при обучении сведения. Характеризуется высокой точностью распознавания и требовательностью к вычислительным ресурсам компьютера. Используется в основном для обработки тех пар символов, которые не удалось хорошо различить признаковым дифференциальным классификатором.
⇡#Структурирование гипотез. Словарная проверка
По приведенным выше рисункам видно, насколько внушительным может быть объем генерируемых классификаторами на каждом логическом уровне документа гипотез. С целью оптимизации проверки оных в ABBYY FineReader задействован алгоритм обработки, предусматривающий структурирование гипотез в составе многоуровневых структур — моделей различных типов (словарное слово, несловарное слово, арабские цифры, римские цифры, URL, регулярное выражение и проч.). В результате такого структурирования количество подлежащих проверке гипотез существенно сокращается, и последующая проверка происходит максимально быстро и эффективно.
Чтобы читателю было проще вникнуть в механизм структурирования гипотез, рассмотрим его работу на примере слова turn. Предположим, что в процессе обработки данного слова системой было выдвинуто две гипотезы относительно возможного деления на символы: первая гипотеза соответствует прочтению tum, вторая — turn. Распознаватель, обработав изображения символов, предложил для каждого варианта деления некоторый ряд гипотез. Все они упорядочены в рамках структуры, строки которой соответствуют различным моделям.
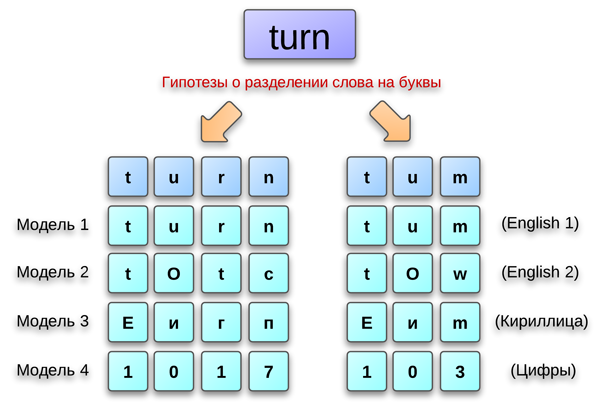
Структурирование гипотез
В приведенном примере произойдет следующее: поскольку оценка гипотез, порожденных моделью английского слова, больше, чем гипотез от модели русского слова, то английские гипотезы попадут в начало списка. Гипотеза чисел будет иметь низкую оценку. После этого активируется проверка по словарю, которая подтвердит, что в словаре английского языка слова tum нет, а turn — есть. Следовательно, гипотеза относительно слова turn приобретет еще больший вес, что позволит ей в итоге оказаться доминирующей, а программе — без ошибок распознать символы. Важно отметить, что в OCR-системах ABBYY для некоторых языков предусмотрены словари и морфологические модели, которые позволяют генерировать все допустимые в языке словоформы. FineReader 11, например, имеет морфологическую поддержку 45 языков.
⇡#Сборка электронного документа
Реконструкция обработанного документа осуществляется FineReader в два этапа. Первый этап — страничный синтез — запускается на каждой странице сразу после выполнения соответствующих OCR-процедур, второй — документный синтез — начинает работу после распознавания всех страниц документа. Свою лепту на этапе синтеза документа вносит и технология ADRT, общие принципы и методы работы которой были рассмотрены ранее. Повторяясь, скажем, что именно благодаря им OCR-решения ABBYY могут практически «видеть» весь документ целиком и распознавать его не просто как набор символов и элементов, а как организованную, логически структурированную сущность.
Мы рассмотрели базовые аспекты функционирования OCR-систем компании ABBYY — приведенное описание технологий распознавания не претендует на всеобъемлющий обзор. Тем не менее даже перечисленных особенностей архитектуры FineReader достаточно, чтобы оценить потенциал заложенных в основу российской разработки инновационных подходов, совершенствуемых от версии к версии программы.
FineReader развивается, однако фундаментальные принципы целостности, целенаправленности и адаптивности, которым разработчики следуют с первой редакции продукта, по сей день остаются неизменными. Именно они позволяют решениям ABBYY приближаться к логике мышления, свойственной человеку, и справляться с гораздо более сложными задачами, чем распознавание текста. Ярким примером тому является лингвистическая платформа Compreno, о которой мы уже рассказывали.
Автор благодарит коллектив компании ABBYY за помощь в подготовке статьи.