|
Опрос
|
реклама
Быстрый переход
AMD представила мощнейший ИИ-ускоритель MI325X с 288 Гбайт HBM3e и рассказала про MI350X на архитектуре CDNA4
03.06.2024 [12:22],
Николай Хижняк
Компания AMD представила на выставке Computex 2024 обновлённые планы по выпуску ускорителей вычислений Instinct, а также анонсировала новый флагманский ИИ-ускоритель Instinct MI325X. 
Источник изображений: AMD Ранее компания выпустила ускорители MI300A и MI300X с памятью HBM3, а также несколько их вариаций для определённых регионов. Новый MI325X основан на той же архитектуре CDNA 3 и использует ту же комбинацию из 5- и 6-нм чипов, но тем не менее представляет собой существенное обновление для семейства Instinct. Дело в том, что в данном ускорителе применена более производительная память HBM3e.  Instinct MI325X предложит 288 Гбайт памяти, что на 96 Гбайт больше, чем у MI300X. Что ещё важнее, использование новой памяти HBM3e обеспечило повышение пропускной способности до 6,0 Тбайт/с — на 700 Гбайт/с больше, чем у MI300X с HBM3. AMD отмечает, что переход на новую память обеспечит MI325X в 1,3 раза более высокую производительность инференса (работа уже обученной нейросети) и генерации токенов по сравнению с Nvidia H200.  Компания AMD также предварительно анонсировала ускоритель Instinct MI350X, который будет построен на чипе с новой архитектурой CDNA 4. Переход на эту архитектуру обещает примерно 35-кратный прирост производительности в работе обученной нейросети по сравнению с актуальной CDNA 3. 
 Для производства ускорителей вычислений MI350X будет использоваться передовой 3-нм техпроцесс. Instinct MI350X тоже получат до 288 Гбайт памяти HBM3e. Для них также заявляется поддержка типов данных FP4/FP6, что принесёт пользу в работе с алгоритмами машинного обучения. Дополнительные детали об Instinct MI350X компания не сообщила, но отметила, что они будут выпускаться в формфакторе Open Accelerator Module (OAM). 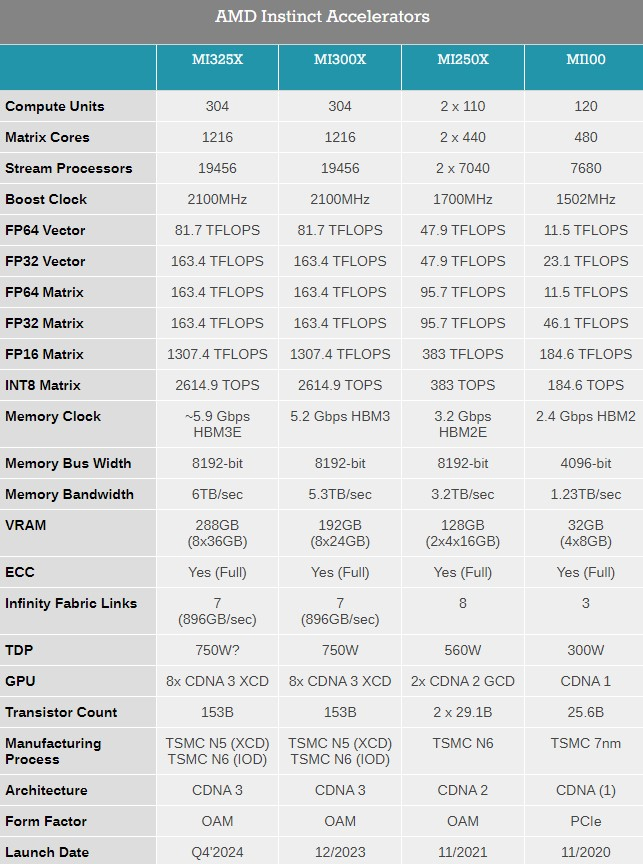
Источник изображения: AnandTech ИИ-ускорители Instinct MI325X начнут продаваться в четвёртом квартале этого года. Выход MI350X ожидается в 2025 году. Кроме того, AMD сообщила, что ускорители вычислений серии MI400 на архитектуре CDNA-Next будут представлены в 2026 году. AMD становится серверной компанией, а продажи Radeon и чипов для консолей упали вдвое
01.05.2024 [01:09],
Андрей Созинов
Компания AMD опубликовала финансовый отчёт за первый квартал текущего года. Финансовые показатели немного превзошли ожидания аналитиков Уолл-стрит, однако на большинстве направлений компания показала спад по сравнению с предыдущим кварталом. Акции AMD уже отреагировали падением на 7 % на расширенных торгах.  Чистая прибыль AMD в первом квартале текущего года составила $123 миллиона. Это значительно лучше показателя за первый квартал 2023 года — тогда компания сообщила о чистом убытке в $139 миллионов. Однако по сравнению с предыдущим кварталом, то есть четвёртой четвертью 2023 года, чистая прибыль обвалилась на 82 %. 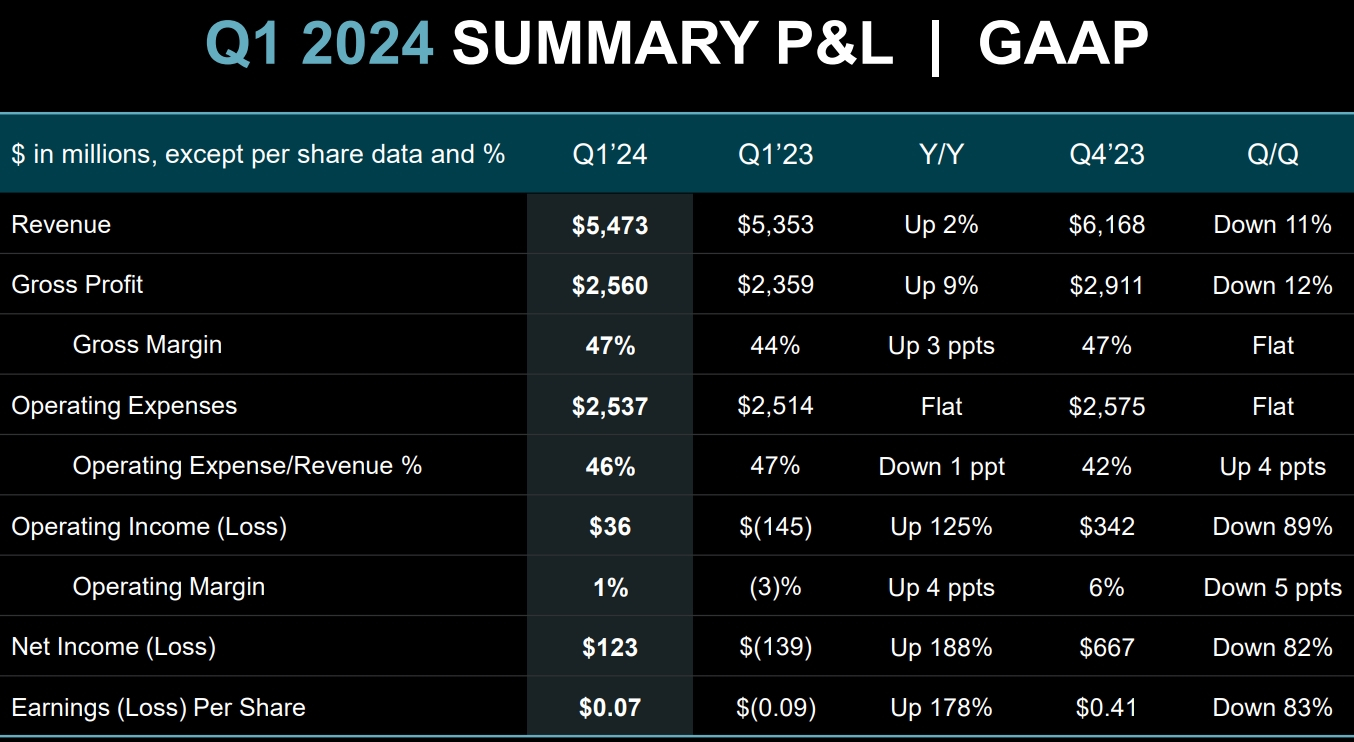
Источник изображений: AMD Выручка AMD в первой четверти 2024 года выросла в годовом сравнении примерно на 2 %, до $5,47 млрд. Однако по сравнению с предыдущим кварталом снова отмечается спад, но не столь значительный как для прибыли — на 11 %. При этом AMD превзошла ожидания аналитиков, которые прогнозировали ей $5,46 млрд выручки. 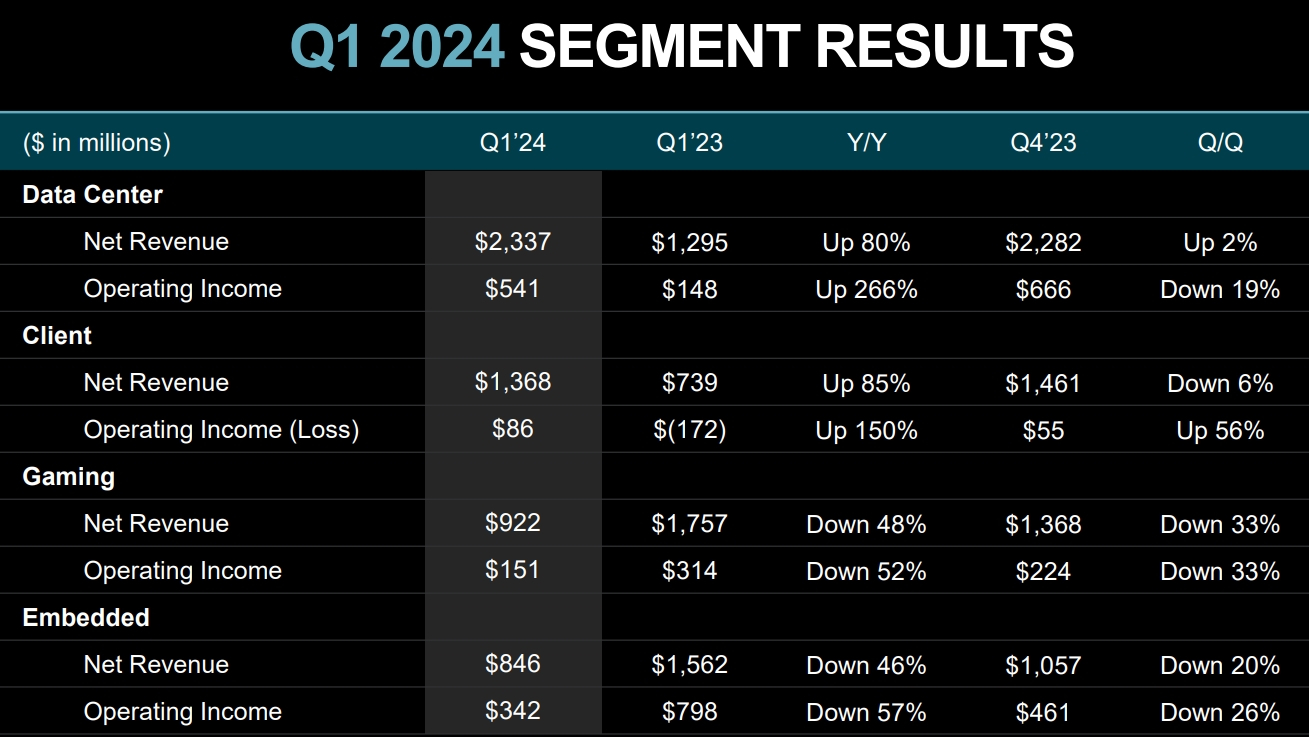 В большинстве сегментов AMD показали спад по сравнению с прошлым кварталом, что главным образом обусловлено сезонными колебаниями спроса — в конце года продажи обычно растут, а вот в начале слабеют. Единственным сегментом, показавшим рост по сравнению с предыдущим кварталом, оказалось направление продуктов для центров обработки данных: AMD заявила о последовательном росте выручки в данном сегменте на 2 %, до $2,3 млрд. А в годовом сравнении выручка и вовсе подскочила на 80 %. Такой рост обеспечили продажи ускорителей вычислений Instinct MI300, которые конкурируют с ускорителями от Nvidia на бурно развивающемся рынке ИИ-систем. AMD заявила, что с момента запуска в четвертом квартале 2023 года продала ускорителей Instinct MI300 на более чем $1 миллиард. В AMD отметили, что чипы MI300X используются компаниями Microsoft, Meta✴ и Oracle, а компания Lenovo не так давно анонсировала серверы с данными ускорителями. В целом по итогам 2024 года AMD планирует выручить $4 млрд от реализации ускорителей вычислений, что на $500 млн больше предыдущего прогноза. Тем не менее, Nvidia за один только первый квартал выручила на серверном направлении $18,4 млрд, поэтому прогресс AMD на этом фоне не кажется впечатляющим.  Также укрепить позиции AMD в серверном сегменте помог высокий спрос на центральные процессоры EPYC — AMD указывает, что их всё больше применяют корпоративные клиенты и облачные провайдеры, а также они активно используются в ИИ-системах.  Самым слабым сегментом у AMD в прошлом квартале стал игровой, который показал спад выручки на 48 % в годовом исчислении до $922 млн. Последовательно продажи сократились на внушительные 33 %. По словам компании, падение было вызвано снижением продаж чипов для игровых консолей, а также видеокарт для игровых компьютеров.  Основной бизнес AMD — процессоры для ПК — показал рост в годовом сравнении на 85 % до $1,37 млрд. Это говорит о том, что прошлогодний спад на рынке ПК позади и потребители снова стали активнее покупать компьютеры. Заметим, что в последовательном выражении здесь наблюдался спад, на 6 %. В данном сегменте AMD делает ставку на свежие чипы Ryzen 8000-й серии, которые способны локально запускать ИИ-приложения. Это открывает им путь в так называемые AI PC, на которые ставят многие компании в отрасли — ИИ-возможности должны стимулировать продажи новых ноутбуков и настольных ПК. На направлении встраиваемых решений, которое представлено главным образом продуктами, созданными с помощью приобретённой в 2022 году компании Xilinx, компания AMD отчиталась о снижении продаж на 46 % в годовом исчислении до $846 миллионов. Последовательное снижение выручки составило 20 %. На текущий квартал компания AMD прогнозирует последовательный рост выручки до $5,7 млрд, что совпадает с ожиданиями аналитиков. В годовом сравнении это будет соответствовать росту на 6 %. Наконец, AMD не забыла напомнить, что позже в этом году планирует выпустить серверные процессоры EPYC Turin на базе Zen 5, а во второй половине года ожидается выход процессоров для ноутбуков Strix Point также на Zen 5. Также в AMD отметили, что уже начали поставлять клиентам тестовые образцы процессоров EPYC Turin, так что их выход действительно не за горами. AMD опровергла опровержение NVIDIA — ИИ-ускоритель MI300X на 30 % быстрее NVIDIA H100, даже с оптимизациями
16.12.2023 [13:58],
Николай Хижняк
Компания AMD ответила на недавнее заявление NVIDIA о том, что ускорители вычислений NVIDIA H100, при использовании оптимизированных библиотек TensorRT-LLM для ИИ-расчётов, быстрее справляются с поставленными задачами, чем новые ускорители AMD Instinct MI300X. По мнению AMD, её ускорители всё равно выигрывают. 
Источник изображения: Wccftech Двумя днями ранее компания NVIDIA опубликовала свои результаты тестов специализированных ускорителей вычислений Hopper H100 и заявила, что они значительно быстрее новейших ИИ-ускорителей AMD MI300X, которые были представлены на мероприятии Advancing AI на прошлой неделе. По словам NVIDIA, AMD при сравнении своих MI300X с H100 не использовала для последних специальные оптимизированные программные библиотеки TensorRT-LLM, которые повышают эффективность ИИ-чипов NIVDIA. NVIDIA опубликовала данные своих тестов с использованием библиотек TensorRT-LLM, которые показали практически 50-процентное преимущество над ускорителями AMD MI300X. AMD решила ответить на это заявление, показав на новых графиках, как MI300X по-прежнему оказывается быстрее ускорителей H100, даже если последние используют оптимизированный под них стек программного обеспечения. По словам AMD, свои данные NVIDIA приводит:
Согласно новым тестам AMD, её ускорители MI300X, работающие с библиотеками vLLM, на 30 % производительнее ускорителей NVIDIA H100, даже если последние работают с библиотеками TensorRT-LLM. Ниже показан новый график результатов тестов ускорителей H100 и MI300X, предоставленный AMD. 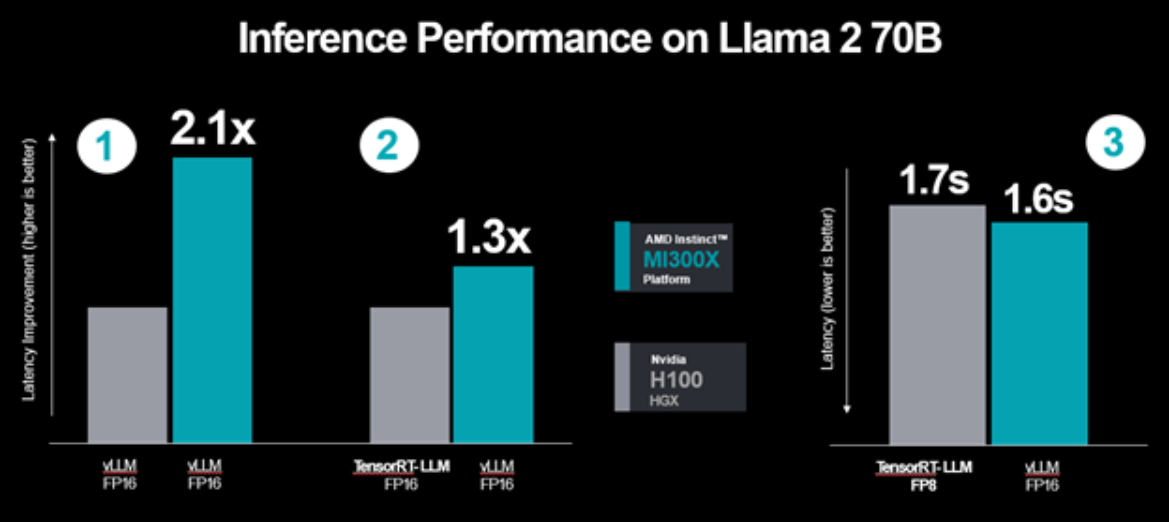
Источник изображения: Wccftech / AMD Ниже приведено заявление AMD.
Публичный спор между AMD и NVIDIA в очередной раз демонстрирует, что в сегменте ИИ-вычислений наблюдается очень высокая конкуренция между производителями аппаратного обеспечения, которые готовы бороться за каждого клиента. NVIDIA развенчала миф от AMD: ИИ-ускорители H100 в реальных задачах в разы быстрее Instinct MI300X
14.12.2023 [21:13],
Николай Хижняк
Компания NVIDIA опубликовала свежие данные о производительности своих ИИ-ускорителей H100, сравнив их с недавно представленными ускорителями Instinct MI300X от компании AMD. Этим сравнением NVIDIA решила показать, что на самом деле H100 обеспечивают более высокую производительность по сравнению с конкурентом, если использовать правильную программную среду для ИИ-вычислений. Компания AMD этого не учла в своём сравнении ускорителей, посчитали в NVIDIA. 
Источник изображения: Wccftech Во время презентации Advancing AI компания AMD официально представила специализированные ускорители вычислений для ИИ Instinct MI300X и сравнила их в различных бенчмарках и тестах с ускорителями H100 от NVIDIA. В частности, AMD заявила, что один ускоритель MI300X обеспечивает на 20 % более высокую производительность по сравнению с одним ускорителем H100, а сервер из восьми MI300X до 60 % быстрее сервера из восьми H100. NVIDIA опубликовала заметку на своём сайте, в которой утверждает, что эти заявления далеки от правды. Ускорители вычислений NVIDIA H100 были выпущены в 2022 году и с тех пор получили различные улучшения на уровне программного обеспечения. Например, наиболее свежие улучшения, связанные с программной средой для ИИ-вычислений TensorRT-LLM позволили ещё больше повысить производительность H100 в рабочих нагрузках, специфичных для искусственного интеллекта, а также провести оптимизацию на уровне ядра. Всё это, по словам NVIDIA, позволяет чипам H100 эффективнее работать с такими большими языковыми моделями, как Llama 2 с 70 млрд параметров с использованием операций FP8. 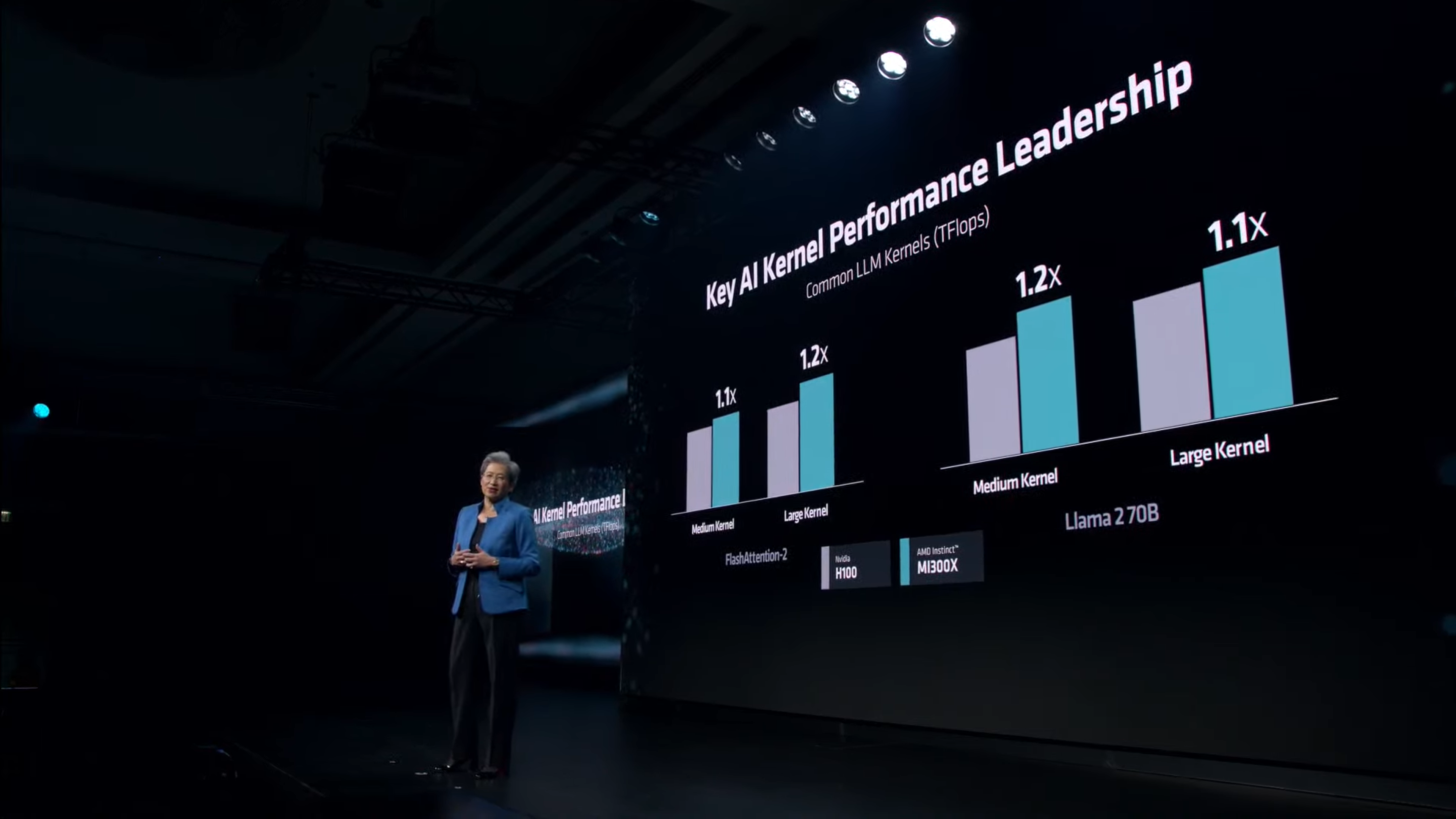 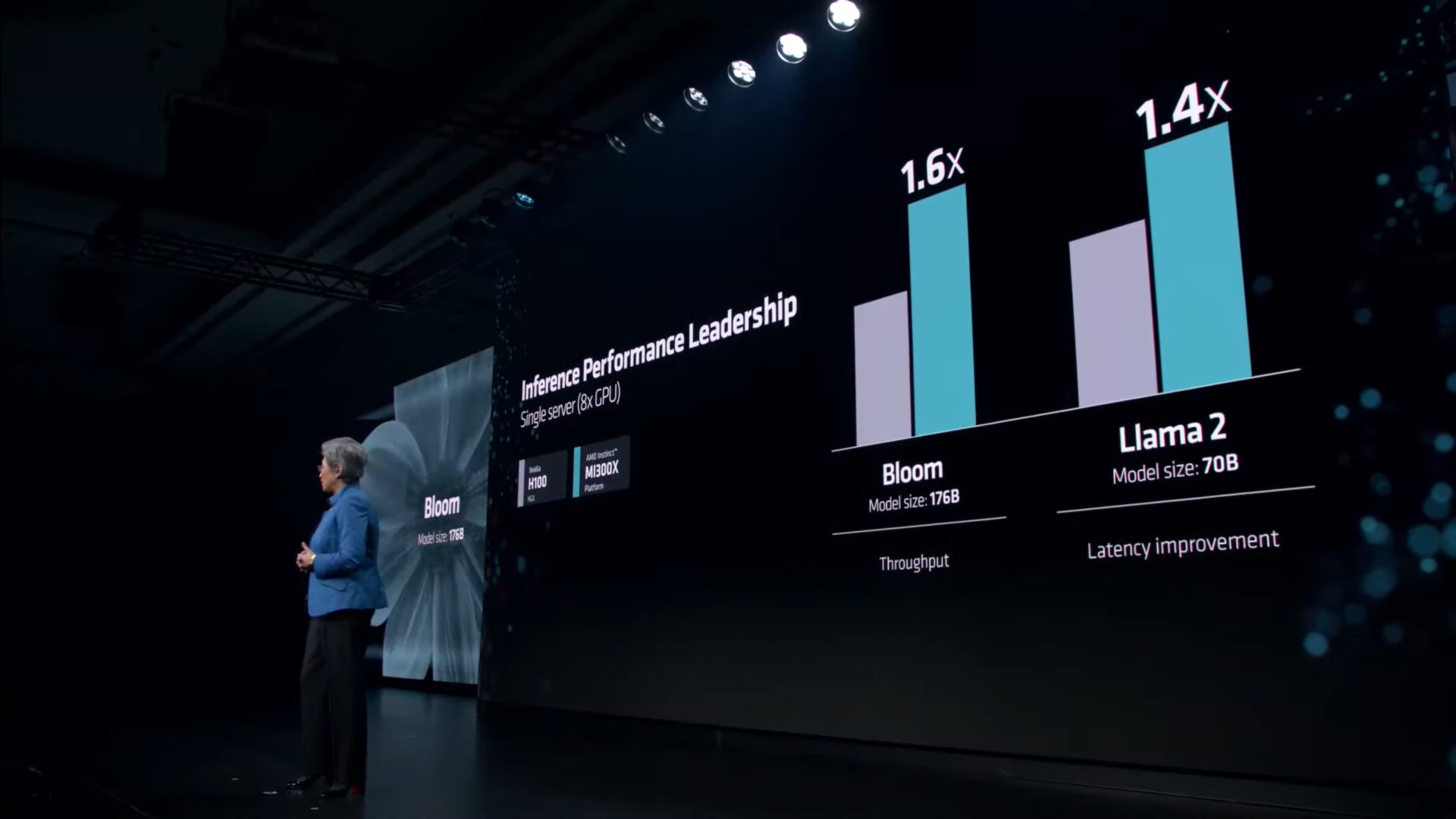 Сама AMD в своей презентации утверждала, что Instinct MI300X до 20 % быстрее H100 в Llama 2 70B, а также система из восьми ускорителей AMD обеспечивает превосходство по задержке на 40 % по сравнению с системой на восьми NVIDIA H100 в той же нейросети. Превосходство в операциях FP8 и FP16 составляет 30 % в пользу MI300X. 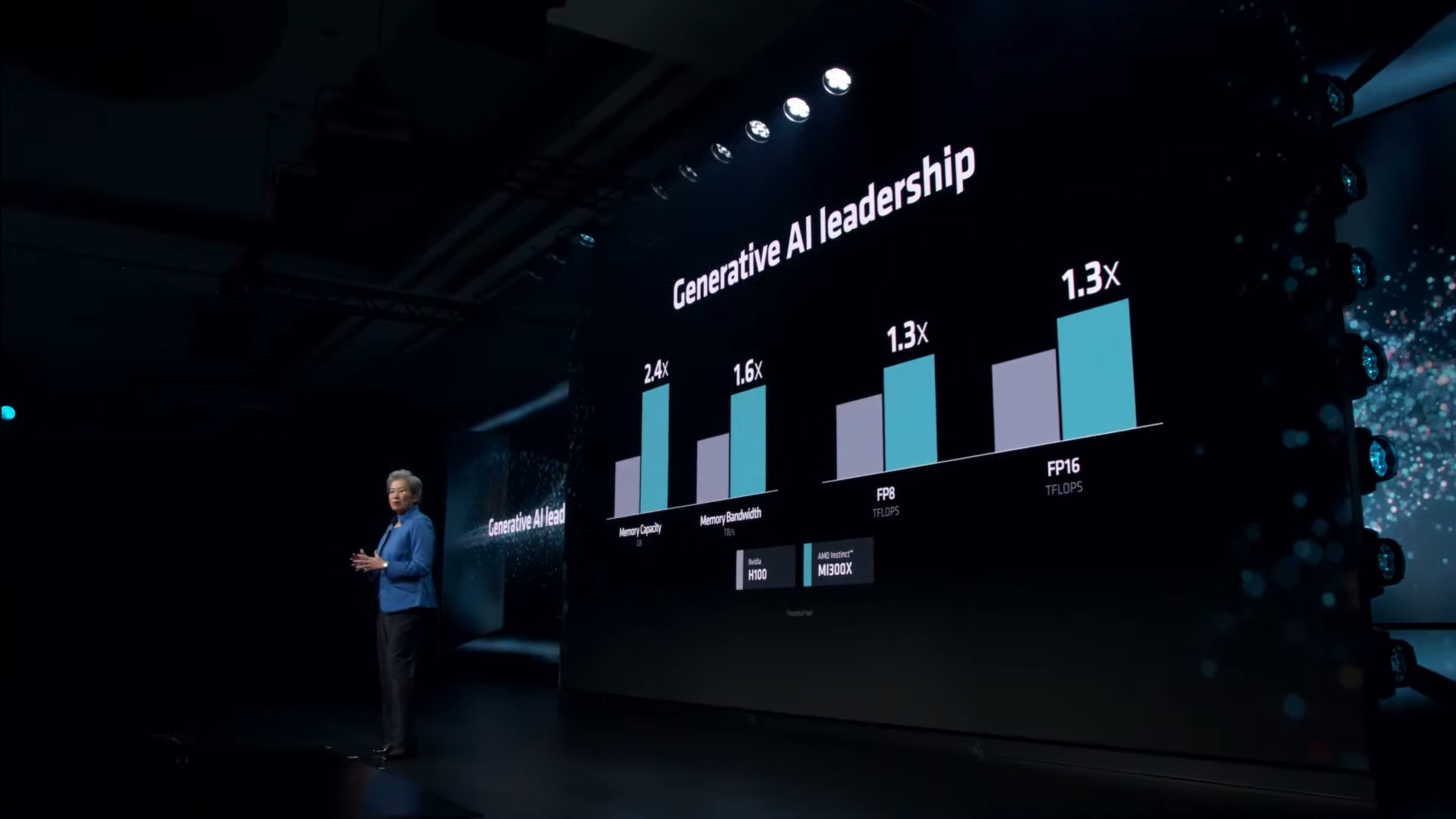 AMD проводила тесты своих ускорителей MI300X с использованием оптимизированных библиотек программной среды вычислений ROCm 6.0. Однако для NVIDIA H100 использовались данные без учёта применения оптимизированной программной среды TensorRT-LLM, предназначенной для этих задач. В свежей статье NVIDIA привела актуальные данные производительности одного DGX-сервера из восьми H100 в модели Llama 2 70B с учётом обработки одного программного пакета (Batch-1). 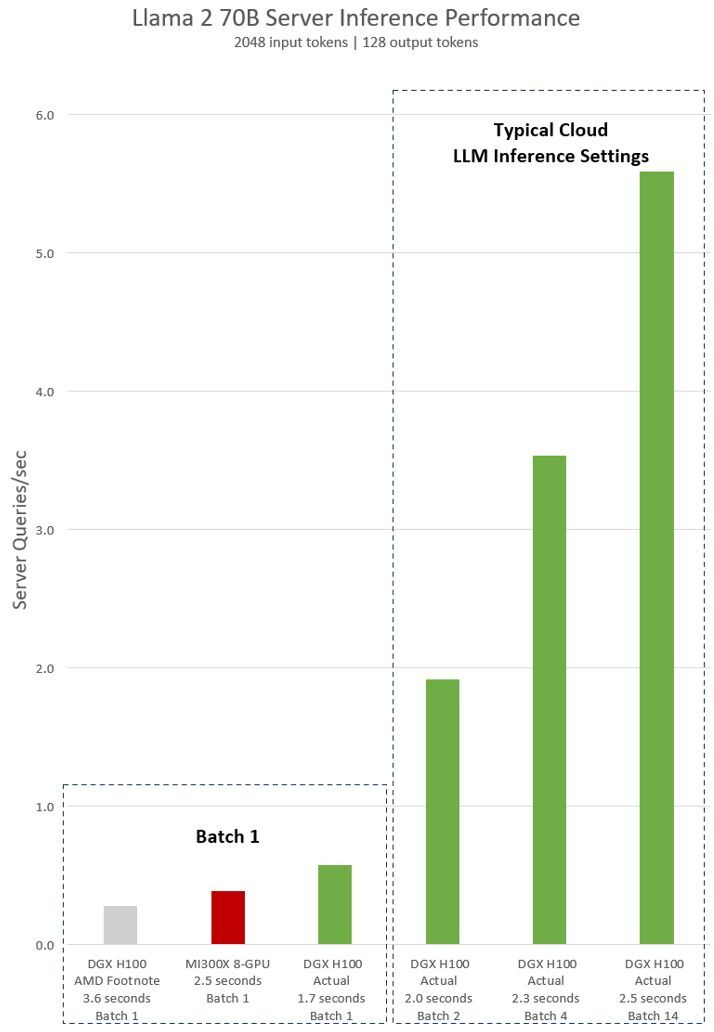
Источник изображения: NVIDIA NVIDIA поясняет, что выводы AMD (серым и красным на графике выше) о превосходстве над H100 основаны на данных, представленных в сноске #MI300-38 к презентации AMD. Для их получения использовалась система NVIDIA DGX H100, фреймворк vLLM v.02.2.2 и модель Llama 2 70B с длиной входной последовательности 2048 и длиной выходной последовательности 128. NVIDIA отмечает, что в AMD сравнили систему из восьми MI300X с системой DGX H100 из восьми H100. В свою очередь данные NVIDIA показаны на графике зелёным. Для их получения применена система DGX H100 из восьми NVIDIA H100 с 80 Гбайт памяти HBM3 в каждом, а также находящийся в открытом доступе фреймворк NVIDIA TensorRT-LLM v0.5.0 для расчёта Batch-1 и версии v0.6.1 для расчёта задержки. Рабочая нагрузка такая же, как указано в сноске AMD #MI300-38. Приведённые NVIDIA результаты показывают, что сервер DGX H100 вдвое быстрее при использовании оптимизированных фреймворков, чем заявляет AMD. Кроме того, сервер с восемью H100 до 47 % быстрее системы с восемью AMD MI300X. «Система DGX H100 способна обработать один инференс-запрос размером в один пакет (Batch-1) или иными словами, один запрос вывода за раз, за 1,7 секунды. Запрос уровня Batch-1 обеспечивает максимально быстрый показатель времени отклика для обработки модели. Для оптимизации времени отклика и пропускной способности ЦОД облачные сервисы устанавливают фиксированное время ответа для конкретной задачи. Это позволяет операторам ЦОД объединять несколько запросов на вывод в более крупные “пакеты” и увеличивать общее количество выводов сервера в секунду. Стандартные отраслевые тесты вроде MLPerf также измеряют производительность с помощью этого фиксированного показателя времени отклика», — продолжает NVIDIA. В NVIDIA поясняют, что небольшие компромиссы в вопросе времени отклика системы могут привести к увеличению количества запросов на вывод, которые сервер может обработать в реальном времени. Используя фиксированный бюджет времени отклика в 2,5 секунды, сервер DGX H100 с восемью графическими процессорами может обработать более пяти инференс-запросов Llama 2 70B за раз. Новая статья: AMD Instinct MI300: новый взгляд на ускорители
14.12.2023 [02:22],
3DNews Team
Данные берутся из публикации AMD Instinct MI300: новый взгляд на ускорители AMD готова создавать специальные ИИ-ускорители для Китая, учитывающие санкции США
02.08.2023 [11:55],
Алексей Разин
Власти США ещё осенью прошлого года ввели ограничения на поставку в Китай ускорителей вычислений, которые могут применяться в системах искусственного интеллекта. NVIDIA почти сразу предложила китайским клиентам специальным образом «урезанные» ускорители A800, позже появились H800, а компания Intel начала поставлять в Китай особые версии ускорителей Gaudi2 только недавно. AMD не исключает, что сможет последовать примеру конкурентов. 
Источник изображения: AMD Когда генерального директора AMD Лизу Су (Lisa Su) на квартальной отчётной конференции спросили, как она оценивает перспективы адаптации к усугубляющимся ограничениям США в части уровня быстродействия поставляемых в Китай ускорителей, она не стала скрывать, что местный рынок очень важен для компании, включая и сегмент ускорителей. «Наш план, конечно, заключается в полном следовании правилам экспортного контроля США, но мы верим, что существует возможность разработки продукта для наших клиентов в Китае, которые ищут решения для искусственного интеллекта, и мы продолжим работать в этом направлении», — буквально заявила глава AMD. Ожидается, что администрация президента США в ближайшие недели разродится новым набором экспортных ограничений в отношении Китая, но изнутри американской полупроводниковой отрасли уже звучат предупреждения о том, что дальнейшее усугубление санкций способно негативно сказаться на развитии собственной полупроводниковой отрасли США, поскольку потеря доступа к китайскому рынку для многих американских корпораций чревата существенным снижением выручки. Меньшие доходы позволят меньше средств выделять на исследования, разработки и строительство новых предприятий, поэтому существует риск замедлить темпы развития бизнеса. Как видим, в AMD готовы к дальнейшему усугублению ограничений, и в случае необходимости компания будет адаптировать свои ускорители вычислений для местного рынка. Сейчас AMD уже поставляет клиентам ускорители Instinct MI250, а в четвёртом квартале компанию им составят представители семейства MI300. В производстве чипов для ускорителей AMD MI300 оказалась занята китайская компания
19.06.2023 [11:53],
Руслан Авдеев
Производство, сборка и тестирование новых ИИ-чипов NVIDIA осуществляется компанией TSMC и другими тайваньскими подрядчиками. Китайским полупроводниковым бизнесам не удаётся пробиться в данную нишу из-за технологического отставания. Тем не менее, китайские предприятия, занимающиеся сборкой и тестированием полупроводников, похоже, смогут сыграть роль в производстве новейших ИИ-чипов AMD. 
Источник изображения: AMD AMD подготовила флагманскую серию Instinct MI300, уже представленную на днях. Она называет APU-модуль «первым в мире интегрированным CPU и GPU для ЦОД» на основе комбинации разных чиплетов. В то время как TSMC отвечает за выпуск кристаллов в соответствии с 5-нм и 6-нм техпроцессами, китайская Tongfu Microelectronics отвечает за их упаковку. Компания Tongfu уже сообщала, что участвует в тестировании Instinct MI300. Поскольку ожидается, что AMD в будущем полностью перейдёт на новую передовую архитектуру, высока вероятность, что благотворные плоды этого будет пожинать и Tongfu. Как оказалось, возможности применения TSMC передового метода упаковки CoWoS ограничены и компания уже подтвердила, что отдаст некоторые заказы соответствующего профиля на аутсорс. Tongfu Microelectronics, в числе прочего имеющей мощности для упаковки кристаллов, заявила, что не включена в список компаний-партнёров и не ведёт дел с NVIDIA. Тем не менее, Tongfu уже выполняет более 80 % заказов по упаковке и тестированию для AMD в сегментах продукции для дата-центров, клиентских устройств, игровых решений и встраиваемых систем — благодаря совместному предприятию и стратегическому партнёрству компаний. Ожидается, что такое партнёрство укрепит позиции AMD и в сфере чипов для ИИ-систем. Передовые технологии упаковки, используемые в решениях MI300, предусматривают как использование технологии 3D-штабелирования TSMC SoIC, так и CoWoS и, возможно, китайским компаниям удастся получить часть рынка упаковки и тестирования решений для ИИ в качестве аутсорс-партнёров. Впрочем, как сообщает портал DigiTimes, большинство процессов упаковки, вероятнее всего, всё равно останутся за TSMC. В 2016 году Tongfu Microelectronics приобрела у AMD заводы в Китае и Малайзии, после чего компании сформировали совместное предприятие. Долговременное сотрудничество между AMD и Tongfu уже продляется до 2026 года. AMD продемонстрировала ускоритель вычислений MI300X, который превосходит решение NVIDIA по объёму поддерживаемой памяти
14.06.2023 [05:17],
Алексей Разин
В этот вторник глава AMD Лиза Су (Lisa Su) на специальном мероприятии предсказуемо продемонстрировала образец ускорителя вычислений MI300X, который начнёт поставляться клиентам до конца текущего года. По сравнению с конкурирующим решением NVIDIA H100, он обеспечивает поддержку до 192 Гбайт памяти против 120 Гбайт соответственно. 
Источник изображения: Getty Images, David Becker В ходе демонстрации способностей ускорителей на базе MI300X была показана их способность работать с языковой моделью для искусственного интеллекта, содержащей 40 млрд параметров. Для сравнения, известная GPT-3 стартапа OpenAI располагает 175 млрд параметров. Как пояснила Лиза Су, языковые модели становятся значительно больше по этому критерию, поэтому разработчикам потребуется сразу несколько GPU для работы с одной моделью. Правда, за счёт поддержки большего объёма памяти AMD MI300X способен сократить потребность собственно в дополнительных ускорителях. Поддержка архитектуры Infinity Architecture позволяет клиентам AMD объединять в одной системе до восьми ускорителей MI300X. Конкурирующие решения NVIDIA опираются на программную экосистему CUDA для разработки приложений, формирующих систему искусственного интеллекта, а AMD опирается на платформу ROCm, которая работает с открытой экосистемой моделей. Архитектурно MI300X опирается на вычислительные ядра с архитектурой Zen 4 и CDNA 3, дополняя их стеками памяти типа HBM3 общим количеством до восьми штук. Общее количество транзисторов на одной подложке ускорителя MI300X достигает 153 млрд штук. Решение AMD превосходит продукт NVIDIA и по пропускной способности памяти, которая достигает 5,2 Тбайт/с, а интерфейс Infinity Fabric обеспечивает передачу до 896 Гбайт информации в секунду. Лиза Су впервые продемонстрировала ускоритель AMD Instinct MI300 с 146 млрд транзисторов
05.01.2023 [11:44],
Алексей Разин
Рассказав об ускорителе вычислений Instinct MI300 в общих чертах ещё летом прошлого года, компания AMD только в рамках презентации на январской CES 2023 уточнила некоторые особенности компоновки и характеристики этого долгожданного решения, которое найдёт применение в серверном сегменте в текущем году. Чиплетная компоновка позволяет новинке объединять несколько разнородных кристаллов с общим количеством транзисторов 146 млрд штук. 
Источник изображения: AMD, YouTube Как пояснила на презентации Лиза Су (Lisa Su), сложная компоновка Instinct MI300 позволяет разместить чиплеты не только рядом друг с другом, но и в несколько ярусов. Ускоритель впервые объединяет на одном чипе процессорные и «графические» ядра, причём для системы они считаются одним целым, обеспечивая и равноправный доступ к памяти типа HBM3, которая расположилась на общей подложке по соседству. Глава AMD справедливо назвала Instinct MI300 самым сложным чипом из когда-либо созданных компанией. Было заявлено, что Instinct MI300 сочетает ядра с архитектурой CDNA 3 и 24 процессорных ядра с архитектурой Zen 4. Объём памяти типа HBM3 достигает 128 Гбайт. Образец ускорителя был продемонстрирован на сцене Лизой Су, это было его первым появлением на публике. Как пояснила глава компании, в конструкции этого чипа девять 5-нм кристаллов располагаются на четырёх 6-нм кристаллах, а по бокам расположены стеки с микросхемами памяти типа HBM3. 
Источник изображения: AMD, YouTube По сравнению с Instinct MI250X, новинка обеспечивает в восемь раз более высокую производительность в вычислениях, при этом обеспечивая в пять раз более высокую энергоэффективность в задачах искусственного интеллекта. Использование Instinct MI300 позволяет сократить время обучения соответствующих систем с нескольких месяцев до нескольких недель, как пояснила Лиза Су, при этом существенно сокращая сопутствующие затраты на оплату электроэнергии. В лабораториях AMD образцы Instinct MI300 уже успешно работают, на рынке ускорители этой модели появятся во втором полугодии. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться