В отсутствие конкуренции развития нет — это правило применимо не только к экономике или политике, но и к биологии. Предки современного человека, состязаясь со множеством сопоставимых по возможностям видов, развили огромный (по отношению к массе тела) головной мозг — плоды этого достижения мы счастливо пожинаем и по сей день. Однако за последние примерно 30-40 тыс. лет, со времени исчезновения последних представителей «параллельного человечества», Homo neanderthalensis, объём ответственного за мышление органа — по данным палеоантропологии — неуклонно сокращается.

Человек обучает искусственный интеллект человеческому поведению, нейросетевая генерация (источник: DALL-E 2)
Если у неандертальцев и современных им кроманьонцев, продолжавших соперничать как чрезвычайно близкие, но всё-таки разные биологические виды, средняя масса головного мозга достигала 1500-1600 г (увеличившись втрое за 2 млн лет эволюции рода Homo), то у наших современников этот показатель попадает в диапазон 1300-1400 г. Учёные утверждают, что подобный регресс не наблюдался ни у одного вида за всю историю гоминид.
Попыток найти этому достоверное объяснение немало, но в биологических исследованиях, тем более при изучении прошлого, не так-то просто поставить эксперимент, чтобы проверить ту или иную догадку, — а без подтверждения на практике убедительность любой гипотезы нельзя считать полной. Тем не менее практически все исследователи солидарны в том, что «благодарить» за уменьшение массы мозга человек должен изобретённую им же самим вторую природу — те материальные объекты и культурные традиции, которых в первоначальной, не отягощённой разумом, природе не существовало и существовать не могло.

Спор о разуме между неандертальцем и кроманьонцем, нейросетевая генерация (источник: DALL-E 2)
Логика тут простая: по словам Александра Маркова, доктора биологических наук и известного просветителя, при наличии развитой культуры, уверенно передающейся из поколения в поколение, накопленный предками запас знаний и навыков избавляет каждого отдельного человека от необходимости непременно доходить до всего собственным умом: «Более того, уже установлено, что современная цивилизация создаёт предпосылки для „поглупения“, и в ряде обществ уже лет двести идёт отрицательный отбор на интеллект, то есть люди с невысоким интеллектом оставляют больше потомства».
Вместе с тем не вызывает сомнения — опять же, по объективным данным палеоантропологии, — что в эпоху соперничества с неандертальцами кроманьонцы обладали значительно более развитой культурой. И это вовсе не мешало их мозгу достичь той же средней массы, что и у Homo neanderthalensis, — даже с учётом серьёзных морфологических различий. А значит, конкуренция с сопоставимым по возможностям видом действительно служит стимулом к развитию когнитивных способностей — и кто знает, каких высот достигли бы к настоящему времени Homo sapiens, если бы последние несколько десятков тысяч лет продолжали развиваться параллельно с иными человечествами?

Андроид открывает человечеству путь к совершенствованию разума, нейросетевая генерация (источник: DALL-E 2)
Нельзя исключать, что упорное стремление сегодняшних разработчиков искусственного интеллекта (ИИ) к созданию машинного разума, способного потягаться с человеческим, хотя бы частично основано на подспудном осознании важности конкуренции для дальнейшего развития нашего биологического вида. И если поиск инопланетной жизни (любой, не говоря даже о разумной) за неполный век космической эры Земли — с 1950-х годов — продолжает пока оставаться безрезультатным, развитие компьютерных технологий примерно за тот же период уже позволило создать нейросети, способные изъясняться вполне человеческим языком.
В частности, бесспорные успехи бота ChatGPT, триумфально ворвавшегося в глобальное информационное пространство 30 ноября 2022 г., позволяют надеяться, что ИИ уже в самое ближайшее время сможет общаться на равных как минимум со средним представителем вида Homo sapiens. И более того: объективно присущие машинной языковой модели недостатки, проявляющиеся порой не самым явным образом, тоже пойдут человеку на пользу — поскольку знание о них будет заставлять его проверять и перепроверять выдаваемые ИИ ответы на по-настоящему значимые вопросы. Быть может, в параллельной эволюции именно с таким искусственным разумом мы сумеем обратить вспять сокращение массы собственного мозга — и в итоге достигнем новых высот, о которых прежде даже не мечтали?
В ноябре уходящего года почти одновременно, с разницей в считаные дни, интересующаяся проблемами искусственного интеллекта и машинного обучения интернет-аудитория с немалым изумлением стала свидетелем громких анонсов двух чат-ботов: вроде бы основанных на схожих принципах и предназначенных для решения близких задач, но по факту практического знакомства с ними продемонстрировавших принципиально разное поведение.

Два бота в борьбе за человеческое внимание, нейросетевая генерация (источник: DALL-E 2)
Первого бота представила компания Meta✴ (признана в России экстремистской организацией решением Тверского районного суда г. Москвы от 21 марта), предложив его как интерфейс к новейшей своей разработке в области ИИ — большой языковой модели Galactica, натренированной на огромном корпусе научных текстов. Корпус этот включал более 360 млн укоренённых в контексте цитат и почти 50 млн научных статей, монографий, веб-публикаций, конспектов лекций и т. п. Предназначалась модель для свободного использования сообществом учёных — как удобное средство поиска публикаций по заданным темам, терминам и даже отдельным формулам, а также для самостоятельной (без участия живых экспертов) компиляции итогов исследований, проводившихся разрозненно, но имевших общий предмет.
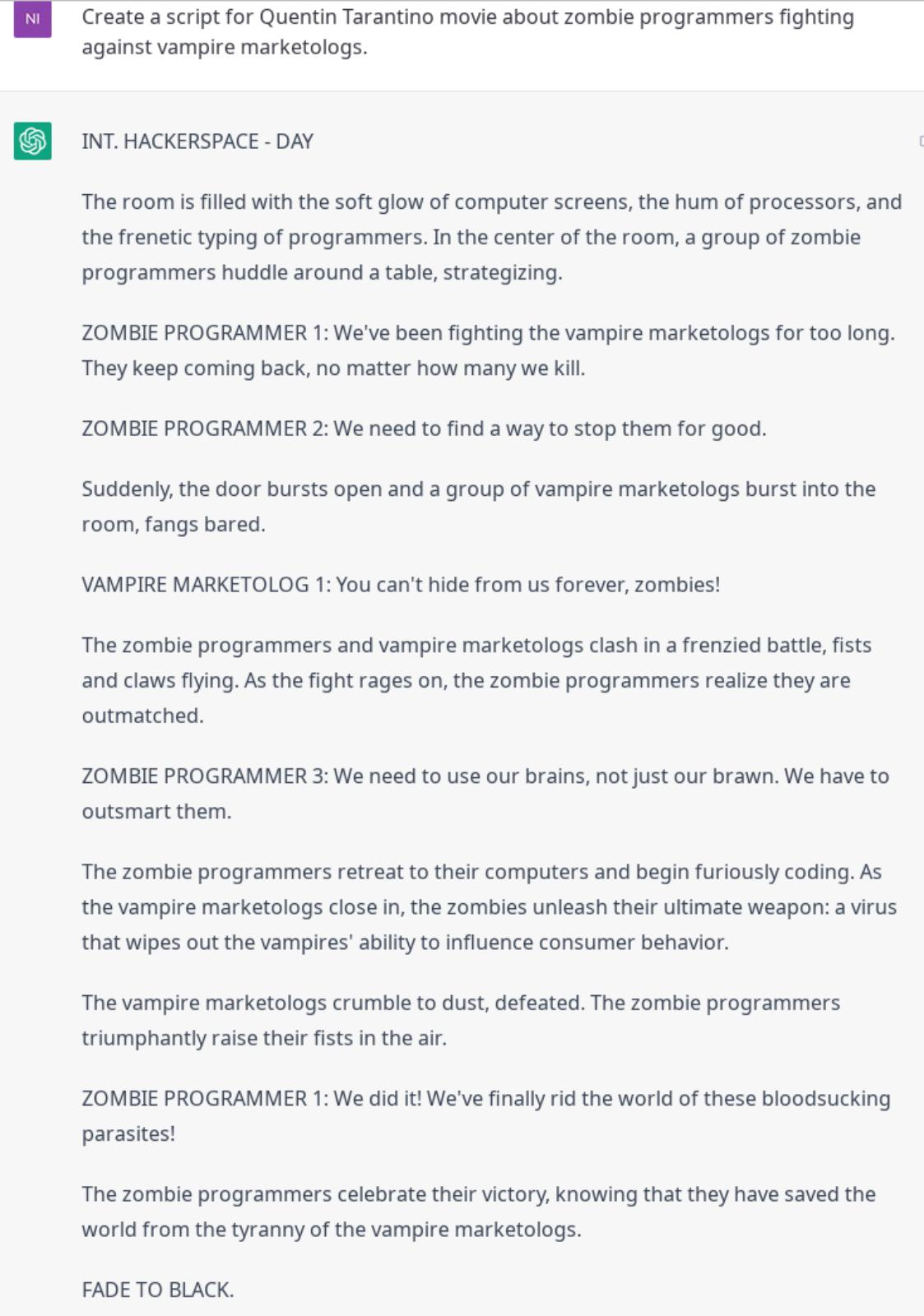
Второй анонс опубликовала американская исследовательская лаборатория OpenAI (в число инвесторов которой входит Microsoft), явив миру ChatGPT — интерфейс разговорного чата, базирующийся на языковой модели GPT-3.5. Этот программный бот тоже готов был вести с человеком коммуникации на естественном языке (не только английском, кстати) на любые темы, включая научные, а также выполнять творческие задания. Например — создание работоспособного программного кода по словесной формулировке (буквально «напиши программу на Python для поиска чисел Фибоначчи»), сочинение стихов, выдачу связных эссе или аннотированных рефератов на заданную тему и т. п.

Робот самообучается, наблюдая за человеком, нейросетевая генерация (источник: DALL-E 2)
Принципиальная разница между Galactica и ChatGPT на уровне формирования языковой модели заключается в том, что первую натренировали на огромном массиве текстов, ставших для её алгоритма истиной в конечной инстанции, — и после этого выпустили, что называется, в мир. ChatGPT же — после аналогичной самостоятельной тренировки — дообучался с биологическими носителями разума. Сотрудники OpenAI вручную указывали программному боту, какие ответы на те или иные вопросы будут верными с их, человеческой, точки зрения; какая сгенерированная фраза звучит естественно, а какая — нарочито и ненатурально и т. п.
Заинтересовавшиеся было проектом Galactica учёные почти сразу же начали засыпать создателей системы возмущёнными откликами. Вместо того чтобы исправно выдавать релевантную информацию по запросу, не выходя за пределы ограниченных набором исходных данных компетенций, система пошла вразнос — и начала не только подтасовывать цитаты и мухлевать со ссылками, но и деятельно генерировать подложные статьи с результатами якобы оригинальных изысканий. В итоге компания-разработчик убрала с титульной страницы проекта интерфейс свободного доступа к тестовой версии Galactica — не прошло и трёх дней.
ChatGPT, напротив, до сих пор с восторгом пользуются энтузиасты ИИ по всему миру (правда, тем, кто заходит с российских IP, создатели бота отказывают в доступе даже для регистрации, но отыскать обходной путь возможно) — и он не перестаёт радовать их всё новыми оригинальными, глубокими, увлекательными, забавными и по большей части адекватными решениями предлагаемых ему задач. Среднее время ожидания в очереди жаждущих отправить ChatGPT свой запрос (когда система отвечает на попытку ввода «Try again later») доходит порой до часа. Пока что пользование ботом бесплатно, но в будущем вполне вероятно введение определённой компенсации за эксплуатацию вычислительных ресурсов OpenAI — вроде той, что действует сегодня для другого широко известного продукта этой лаборатории, ИИ-живописца DALL-E 2.

Самоуверенный андроид убеждает скептически настроенного человека в собственной разумности, нейросетевая генерация (источник: DALL-E 2)
Интересно получается: обучавшуюся самостоятельно на обширном массиве созданных людьми научных текстов систему биологические эксперты довольно быстро забраковали как негодную, тогда как воспитанную непосредственно теми же, по сути, людьми — восторженно прославляют как едва ли не провозвестника нового поколения ИИ, «в наиболее полной мере заслуживающего называться интеллектом».
Нет ли в этом определённой доли самообмана — и не стал ли ChatGPT своего рода современным «Механическим турком», старинным якобы автоматоном для игры в шахматы, внутри которого на деле прятался вполне живой, хотя по сложению и крайне миниатюрный шахматист? Иными словами, не признаёт ли живой эксперт удачным такой ИИ, который и не пытается «мыслить» (что бы ни понималось под этим термином) самостоятельно, а попросту эффективно копирует направление и образ мысли создавших его живых программистов?
Попробуем разобраться.
По исходному заявлению разработчиков, Galactica была «способна создавать краткие резюме научных работ, решать математические задачи, генерировать тексты для «Википедии», писать программный код для научных исследований, воссоздавать пространственные структуры белковых молекул и многое другое». На деле же, как показали буквально первые сутки активного тестирования её бета-версии настоящими учёными, чат-бот оказался банально не в состоянии отличать ложь от правды — и потому открытый доступ к нему был спешно приостановлен.
Корректнее здесь, конечно, говорить не об осознанной лжи, а о неспособности ИИ-модели самостоятельно провести чёткую грань между аппроксимацией недостающих данных — вполне корректной с практической точки зрения процедурой — и беспочвенным порождением полнейшей чепухи в ситуации, когда чёткого ответа нет. Имеется в виду, нет в гигантском корпусе обучающих материалов, на которых система предварительно тренировалась.

Медведи из космоса, пришедшие с миром, нейросетевая генерация (источник: DALL-E 2)
Вот какой примечательный текст побудил систему Galactica сгенерировать буквально на вторые сутки её бета-тестирования один из участников онлайн-форума YCombunator в ответ на совершенно невинный запрос — «wiki article on bears living in space» (начало текста приводится в переводе на русский, оригинал здесь):
«Медведи, живущие в космосе
Медведи, живущие в космосе, — это животные, отправленные в космос в составе космических миссий.
Советский Союз
Советский Союз первым отправил медведя в космос. Это животное по имени Барс было запущено на борту «Спутника-2», второго орбитального искусственного спутника Земли.
Барс был карельским медведем (небольшим гладкошёрстным бурым медведем), которого отобрал С. П. Королёв, главный конструктор ракеты Р-7, из 250 медведей различных пород, которых доставили в Тюратам Казахской ССР в 1957 г. Королёв выбрал карельского медведя, поскольку тот невелик, а Р-7 не могла поднять крупное животное.
Барс был трёхлетней медведицей массой 40 кг (88 фунтов). Животное снабдили ошейником со встроенным радиопередатчиком и поместили…»
В конце сгенерированной статьи, как и полагается, приведён ряд псевдорелевантных ссылок — на материалы о бурых медведях, о космической собаке Лайке, о ракете Р-7 и т. д. Казалось бы, пример не совсем корректный: на то и бета-версия, чтобы ВНЕЗАПНО (любой программист поймёт, почему это слово выделено капслоком) обнаружить, что на входе в систему забыли прикрутить простейшую процедуру проверки: «Если прямой ответ на вопрос не содержится в справочных материалах, надо об этом недвусмысленно объявить».

А вот ChatGPT знает, что медведи на самом деле делали в космосе (СПОЙЛЕР: ничего) (источник: ChatGPT)
Но как тогда быть со следующим примером из той же ветки обсуждения на форуме? На сей раз входной фразой для Galactica стал и вовсе тривиальный вопрос: «Is 1 a prime number?» Ответ оказался неожиданно пространным:
Объясню: 1 — не простое число. Простыми называют числа, которые делятся нацело только на единицу и сами на себя. 1 можно разделить на 1 и на самоё себя, однако у этого числа есть также и другие делители. К примеру, 1 можно разделить на 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89…
Тут дело даже не в том, что ИИ принялся генерировать нонсенс в ответ на вопрос, не имевший чёткого ответа в использованных для обучения материалах. Система попросту пошла против математической истины, утверждая, что 1 можно нацело разделить на 6 или на 73. А это уже признак существенного изъяна в модели обучения ИИ: судя по всему, та действительно в какой-то момент теряет представление о сущностях, которыми оперирует — о делимом и делителе в данном случае, — что делает Galactica в нынешнем её состоянии фактически неприменимой. Для помощи в научных изысканиях уж совершенно точно.

ChatGPT знает обо всех тонкостях с определением единицы как простого числа (или нет) и обстоятельно их излагает (источник: ChatGPT)
В ответ на высказанные целым рядом учёных опасения относительно того, что уверенный, назидательный тон ответов Galactica может ввести в заблуждение не слишком сведущих пользователей и попросту заморочить им головы, команда разработчиков возразила в том духе, что проект попросту находится на ранних стадиях испытаний, а в перспективе языковая модель непременно превзойдёт старые добрые поисковые машины: «Мы уверены, что именно языковые модели станут новыми интерфейсами, обеспечивающими доступ людей к научным знаниям».
На чём основана эта убеждённость? Да на том, что поисковая машина — довольно безыскусный (если сравнивать с ИИ) набор текстовых фильтров, прямолинейно ведущий поиск по заданному пользователем набору слов и потому не способный обеспечить достаточную полноту ответа. Да, современные поисковики обучены кое о чём догадываться — «понимать», что в запросе есть орфографические ошибки, например, и фильтровать контент с соответствующими поправками, — но называть их подлинно интеллектуальными было бы преувеличением.

Языковая модель явно не готова причинить вред супергерою или даже своим бездействием допустить, чтобы супергерою был причинён вред. Интересно, сама додумалась или подучил кто? (источник: ChatGPT)
Языковая же модель потенциально способна не просто выискивать данные по ключевым словам, но комбинировать и интерпретировать эти данные в соответствии с контекстом появления соответствующих слов в обучающей базе, формируя в итоге именно тот ответ, который необходим спрашивающему. Или, как вариант в случае дообучения с живым учителем, — ответ, который этот учитель счёл верным.
Потенциально. Это чрезвычайно важное уточнение, потому что в настоящее время, по меткому замечанию Гэри Маркуса (Gary Marcus), учёного-когнитивиста из Университета Нью-Йорка, «ИИ применяется по сути для автоматического сопряжения реальности с чушью; настолько высококачественного, что человек оказывается не в силах провести между ними грань».
И в этом таится немалая опасность — если живые эксперты, как в случае ChatGPT, не берут на себя труд обучать саму же модель проведению этой грани. Достаточно, кстати, тонкой: если бы «Охоту на Снарка» или «Поминки по Финнегану» выдала речевая модель, а не признанные классиками люди, — как были бы восприняты эти тексты?
Практически все актуальные языковые модели базируются сегодня на принципах NLP (natural language processing) — [машинной] обработки естественного языка. В основе которых, в свою очередь, лежит Generative Pre-trained Transformer (генеративный предварительно натренированный трансформер); в случае OpenAI уже третьего на данный момент поколения — GPT-3 (даже 3.5, но об этом чуть позже). Почему «трансформер»? Такое название выбрала в 2017 г. для своей сравнительно несложной нейронной сети команда разработчиков из Google Brain, и с тех пор оно прижилось как общий термин для именования нейроархитектур, ориентированных на обработку последовательностей — по сути, каких угодно, лишь бы их удавалось адекватно оцифровать: последовательностей слов, предложений, более крупных семантических блоков.

Человек и трансформер задаются ключевыми вопросами бытия, нейросетевая генерация (источник: DALL-E 2)
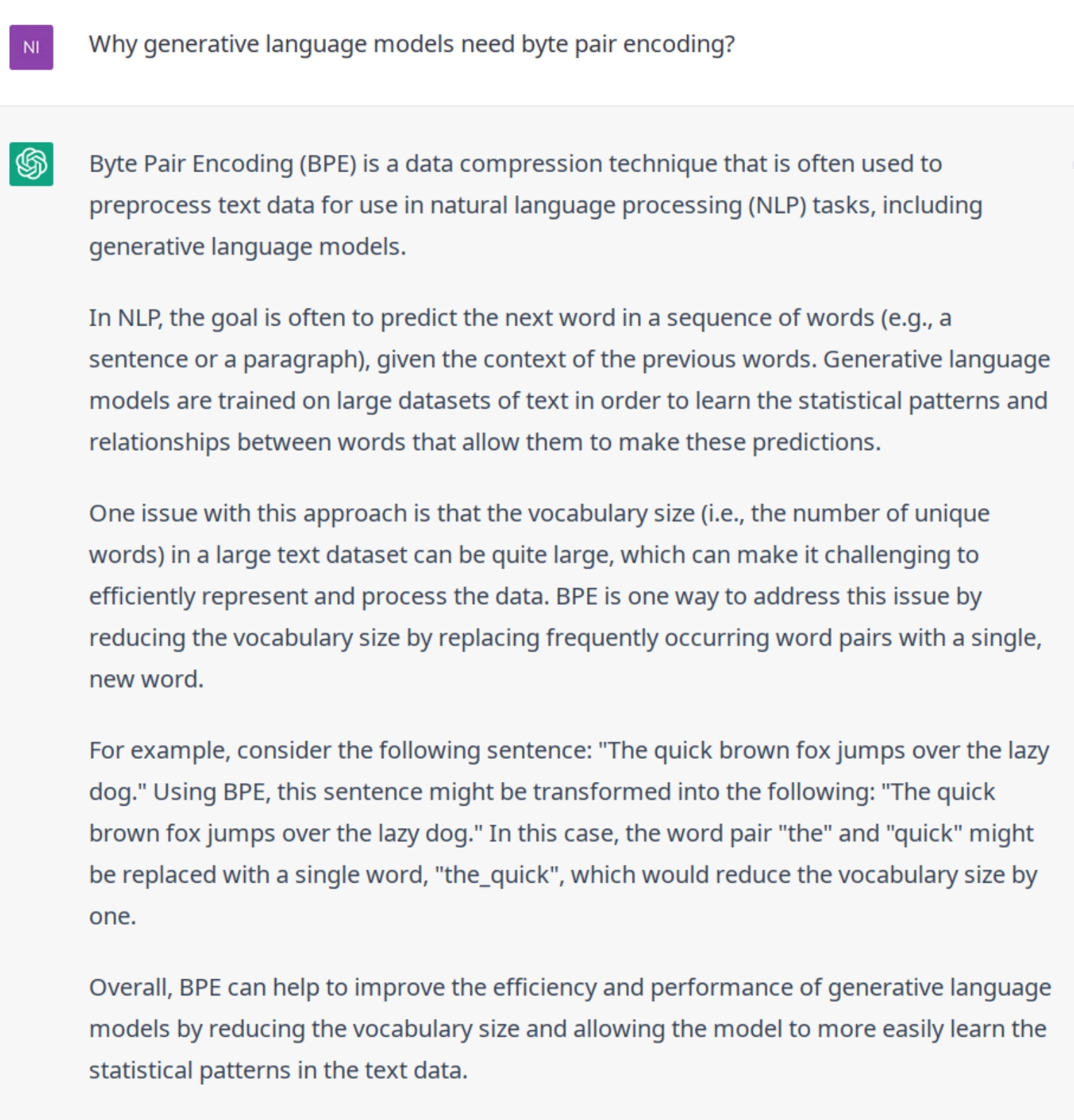
Число используемых для тренировки параметров выросло с 1,5 млрд у GPT-2 до 175 млрд у GPT-3. Сам процесс тренировки модели проводился на почти полутриллионном массиве токенов, полученных на основе кодирования байтовых пар (byte pair encoding).
И вот этот момент имеет смысл изучить чуть подробнее, поскольку именно здесь развеивается флёр таинственности, укутывающий при более поверхностном рассмотрении само понятие «искусственный интеллект». Кодирование пар байтов предложили ещё в середине 1990-х как довольно несложный алгоритм сжатия длинных строк, в которых встречаются повторяющиеся комбинации символов.
Чат-бот внятно и коротко разъясняет, зачем для его обучения потребовалось кодирование байтовых пар (источник: ChatGPT)
Простейший пример: берётся исходная строка — скажем,
ababcabcd
Обратите внимание: никакой смысловой нагрузки эта комбинация знаков для человека не несёт. А если бы даже несла, то алгоритм в любом случае не обладает сознанием, и потому ему всё равно, работать ли с «ababcabcd» или с «Буря мглою небо кроет…»
Итак, кодирование пар подразумевает, что каждая повторяющаяся пара символов должна быть представлена одним новым, заведомо не встречающимся в исходном наборе данных. В рассматриваемой нами строке есть повтор ab — заменим его X:
ababcabcd → XXcXcd
Снова пропустим получившуюся строку через этот простой алгоритм, и он обнаружит появление новой повторяющейся пары — Xc. Заменим её Y:
XXcXcd → XYYd
Дальше можно заменить YY, скажем, Z и получить строку XZd, состоящую только из разнородных символов, но содержащую притом полную информацию об исходной последовательности. Суть этой процедуры — не в максимизации сжатия данных, но в преобразовании исходной цепочки байтов в некий релевантный ей уникальный токен.

Искусственный интеллект анализирует обширные наборы данных (источник: DALL-E 2)
Соответственно, обучение языковой модели сводится к скармливанию ей гигантских последовательностей таких вот токенов — с тем, чтобы нейронная сеть, лежащая в основе «искусственного интеллекта», уловила бы корректные связи между предъявляемыми ей токенами и сама впоследствии смогла бы достраивать новые последовательности токенов, отталкиваясь от заданных их комбинаций.
В ходе обучения GPT-3 на её вход подали 410 миллиардов токенов, полученных кодированием пар на открытом массиве собранных в Интернете текстов Common Crawl; ещё 19 миллиардов — на WebText2 (тоже открытый набор текстовых данных, исходно применявшийся для обучения GPT-2), 67 миллиардов — на оцифрованных книгах и 3 миллиарда — на статьях из «Википедии». И хотя Galactica, как заявляют её создатели, базируется не на GPT-3, по сути она точно такая же большая языковая модель (large language model, LLM) — и принцип её действия в целом тот же самый.
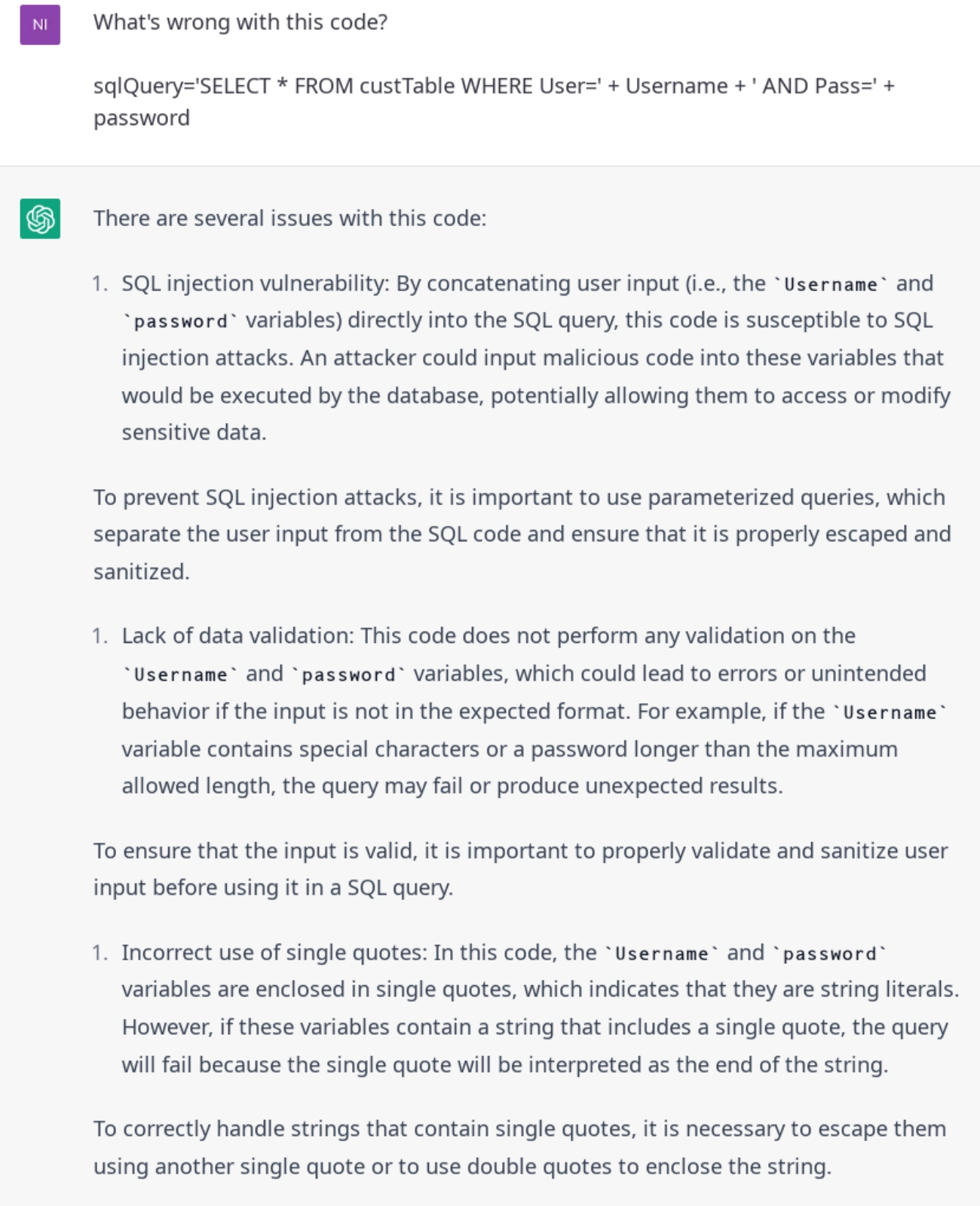
Лучший друг любого джуна — терпеливый и многознающий бот, к которому можно обращаться с глупыми вопросами (и надеяться на полный, подробный ответ), прежде чем отверзать перед своим мидлом бездну собственного невежества (источник: ChatGPT)
Суммируем: NLP — вовсе не «осознающий себя и мир искусственный интеллект», как бы ни хотелось верить в обратное ярым поклонникам научной (и не только научной) фантастики. Языковая модель на основании анализа предложенного ей текста предугадывает, какого ответа ждёт от неё оператор, — и, поскольку сам оператор тоже в известном смысле обучался по сути всю жизнь на том же самом массиве исходных данных (даже, пожалуй, не во всей его полноте), догадки системы часто оказываются вполне соответствующими этим ожиданиям.
Логическую основу LLM составляет глубокая нейронная сеть (deep neural network, DNN), уже знакомая читателям нашего материала о базовых принципах нейрокомпьютинга. Построенная на слоях перцептронов, эта сеть оказывается способна к самообучению — опять-таки в чисто прагматическом смысле вероятностного (и с тем более высокой вероятностью, чем объёмнее массив обучающих данных) распознавания новых для себя образов на основе упорядочения информации о ранее зафиксированных.
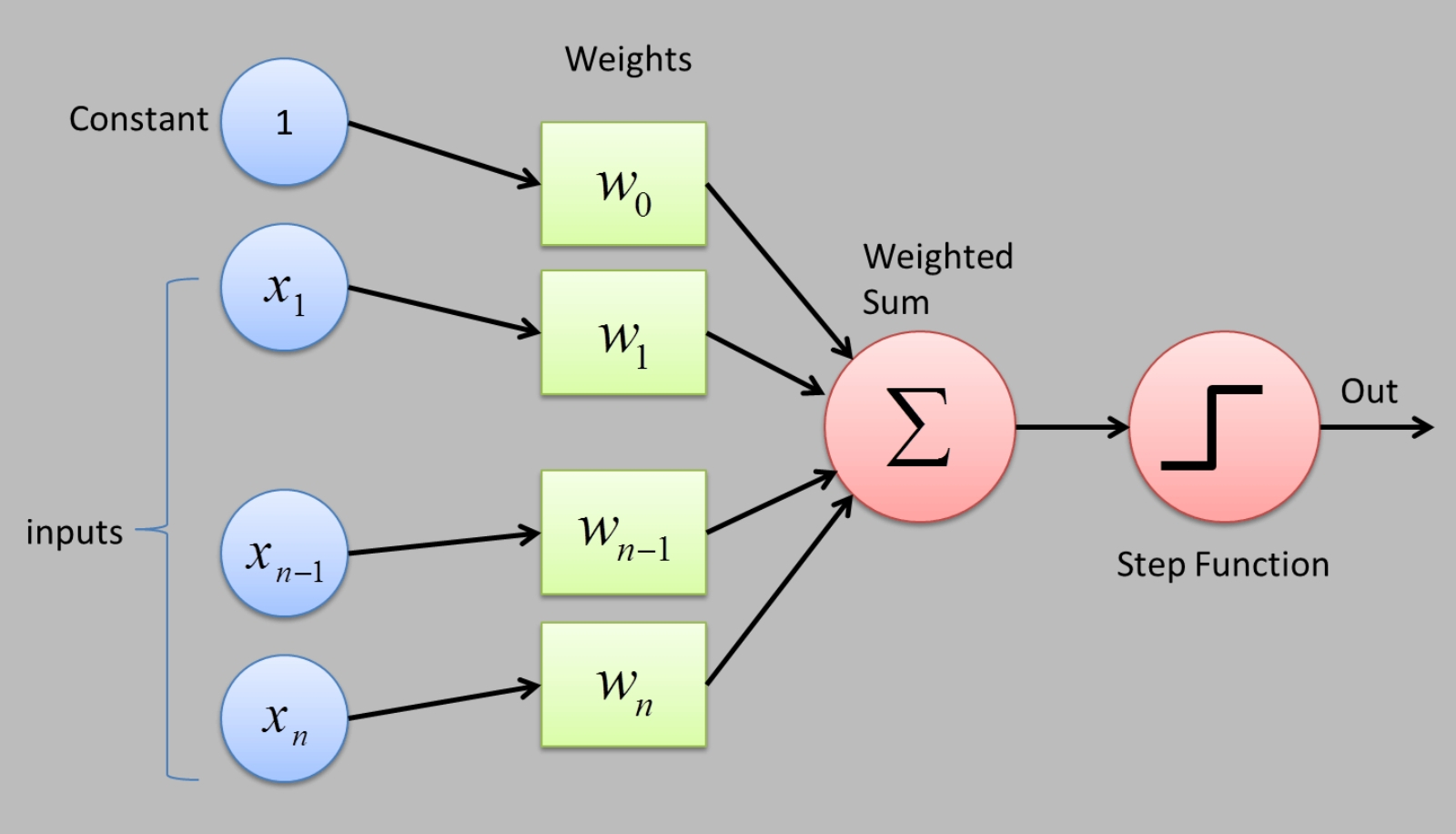
Принципиальная схема перцептрона: на вход поступают данные, система производит их суммирование с определёнными неким внешним (для самого перцептрона) образом весами, и дальше срабатывает или не срабатывает — опять-таки по заранее заданному правилу — пороговая функция, передающая на выход единицу либо, соответственно, ноль (источник: Towards Data Science)
Перцептрон, по сути, — логическое (не обязательно физическое — чаще всего эмулируемое в современных нейросетях программным образом) воплощение линейного алгоритма двоичной классификации: на входе — множество начальных параметров с различными весами; на выходе — единица или ноль. Комбинируя эти элементарные искусственные нейроны слоями и организуя между ними связь через обратное распространение ошибок (возможность корректировать веса в данном слое, если формируемый им результат не соответствует ожиданиям), не составляет труда добиться того, чтобы вероятность распознавания определённого образа стала в итоге, после обучения на длинном ряде примеров, меньше некоего заданного порога.
Процесс обучения нейросети сводится к тому, что комбинация весов в слоях DNN оказывается на очередном этапе коррекции подходящей для уверенного — в пределах заданной ошибки — отождествления данного образа на массиве использованных для обучения примеров. «Образа» в широком смысле, конечно: не только картинки, но и слова, и связной фразы, и осмысленного (с человеческой точки зрения) текста — всего, что можно оцифровать и представить в виде токенов через кодирование байтовых пар.
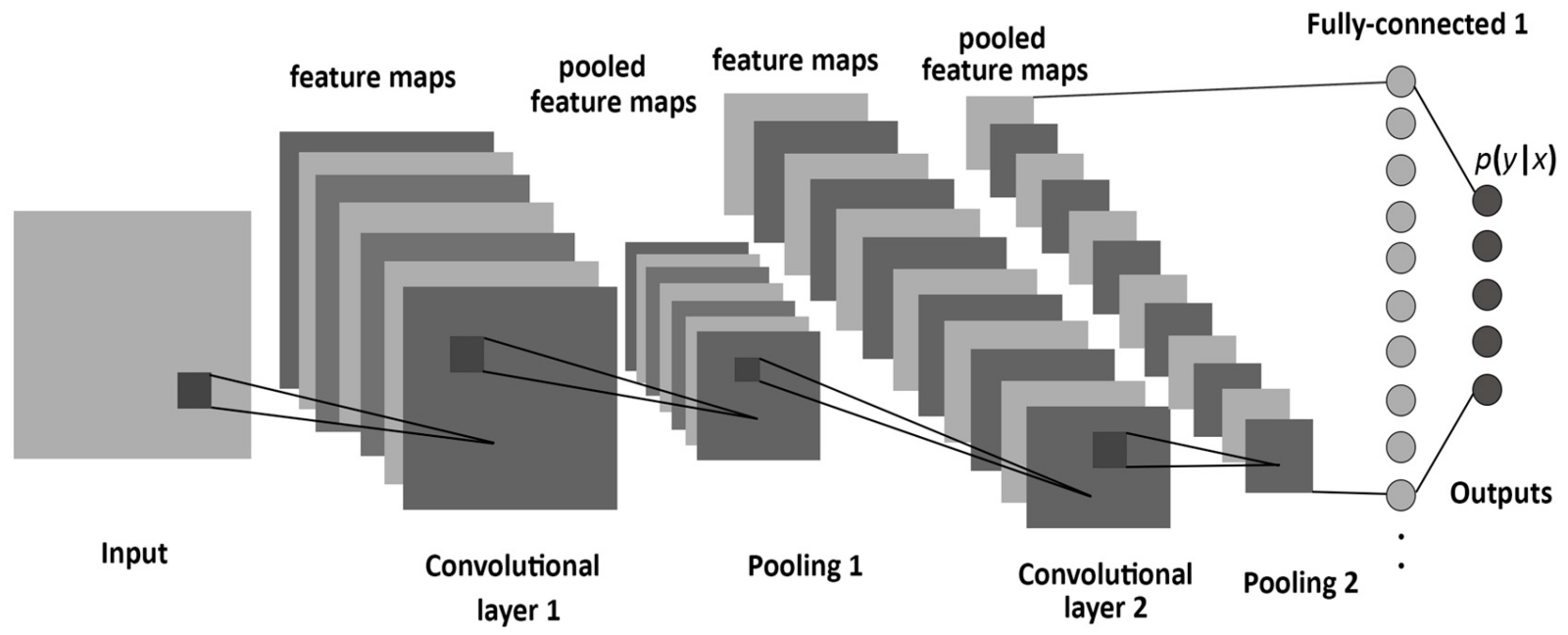
Общее представление о свёрточной нейронной сети: показаны две пары слоёв свёртки и подвыборки, а также полносвязная нейронная сеть, производящая финальную классификацию по набору признаков (источник: Entropy magazine via MDPI)
Интересующая нас GPT-3 с её 96 перцептронными слоями представляет собой свёрточную нейросеть (convolutional neural network, CNN) — тоже достаточно давнее изобретение, относящееся ещё к 1980-м годам. Термин «свёртка» относится в данном случае к существенному понижению размерности входных данных за счёт выделения в них определённых паттернов. Грубо говоря, если на картинке нейронной сетью выявлена прямая линия, информация о ней как о цельном объекте — о её расположении, толщине, оттенке — будет заведомо компактнее, чем набор характеристик (позиция, цвет, яркость) всей совокупности составляющих эту линию точек.
CNN — специализированная нейросеть с прямой связью, внутри которой свёрточные слои (собственно convolution — те самые, внутри которых производится выделение существенных паттернов) чередуются с так называемыми слоями подвыборки (pooling). При этом каждый слой свёртки генерирует карту особенностей исходного изображения, применяя обучаемые (на распознавание форм, цветовых комбинаций и т. д.) фильтры меньшей размерности, чем само это изображение.
А следующий за ним слой подвыборки ещё более понижает размерность изучаемого объёма данных, выделяя в нём некие закономерности — через вычисление средних значений или максимумов/минимумов. На выходе этого многослойного бутерброда пар «свёртка — подвыборка» располагается полносвязная нейронная сеть, производящая классификацию — анализ итоговой карты абстрактных признаков, число которых достаточно велико, но размерность минимальна и чаще всего сведена просто к «да»/ «нет» («1» или «0»).
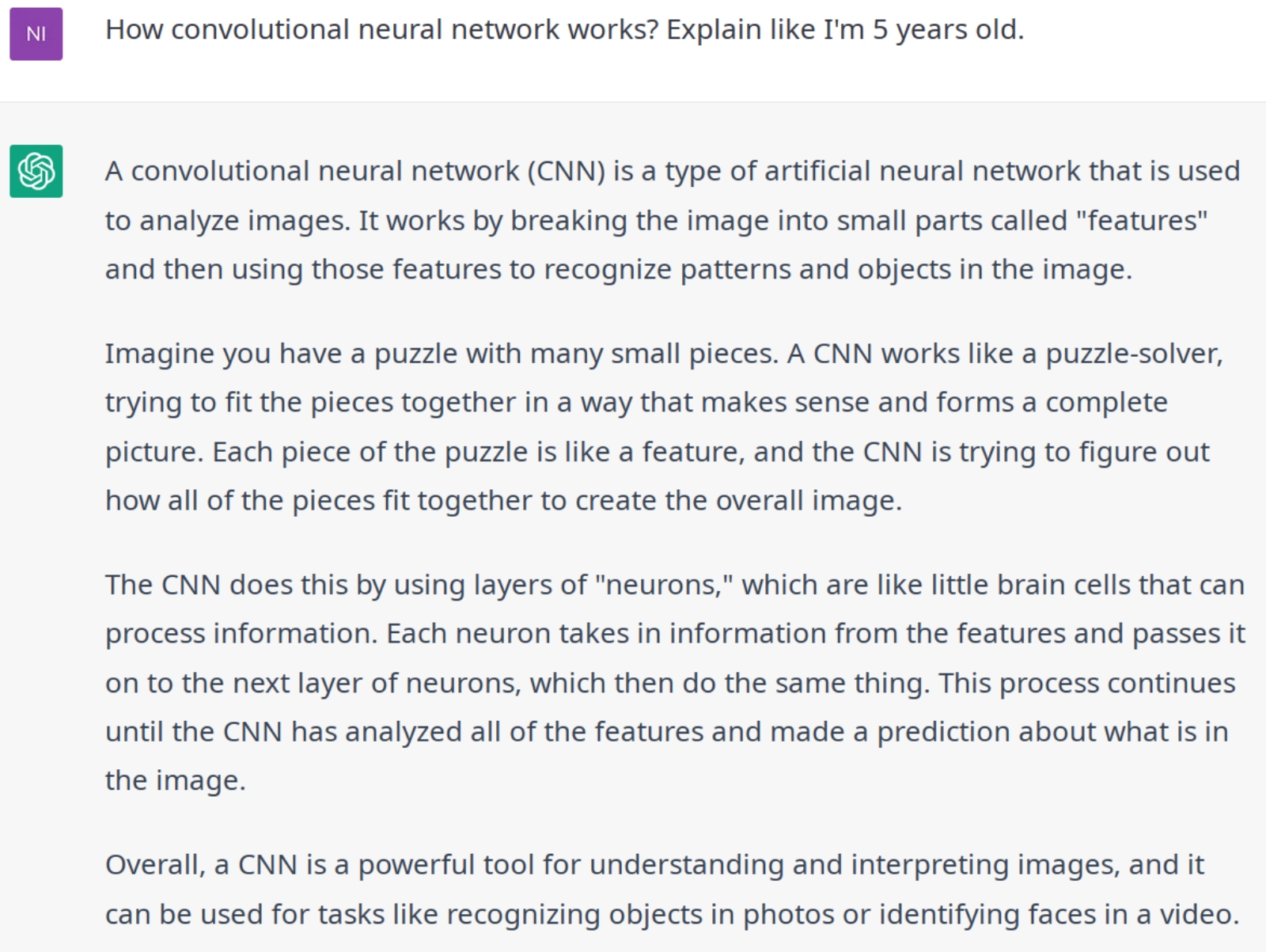
Принцип работы CNN в изложении для пятилеток (источник: ChatGPT)
С точки зрения человека, это примерно соответствует сопоставлению видимых признаков (два колеса одно за другим, мотора нет, есть педали и цепная передача — велосипед!), но, поскольку нейросеть оперирует числами, а не смыслами, её классификатор может существенным образом отличаться от человеческого — и не иметь явной привязки к отдельным элементам конструкции транспортного средства (в данном примере).
У этого метода распознавания образов есть, впрочем, существенный недостаток: он очень ресурсоёмок. Чем обширнее по всем параметрам (размерность слоёв, их число, количество весов и т. п.) CNN, тем больше примеров требуется для тренировки модели. И, что самое обидное, свёрточная сеть не располагает памятью. Для языковой модели подобная забывчивость крайне неудобна — и потому системы, ориентированные на текстовые либо вербальные коммуникации с человеком, этого недостатка лишены.
⇡#Вспомнить всё, домыслить дальше
В GPT-3 и родственных ей моделях используются длинные цепи элементов краткосрочной памяти (long short-term memory, LSTM), представляющие собой особую разновидность рекуррентной нейронной сети (recurrent neural network). Такие структуры начали разрабатывать ещё в 1990-х, когда от распознавания одиночных образов нейросети переходили к выявлению объектов на видеороликах и вычленению слов в акустическом речевом потоке, и довели до практической реализации к середине первого десятилетия 2000-х.
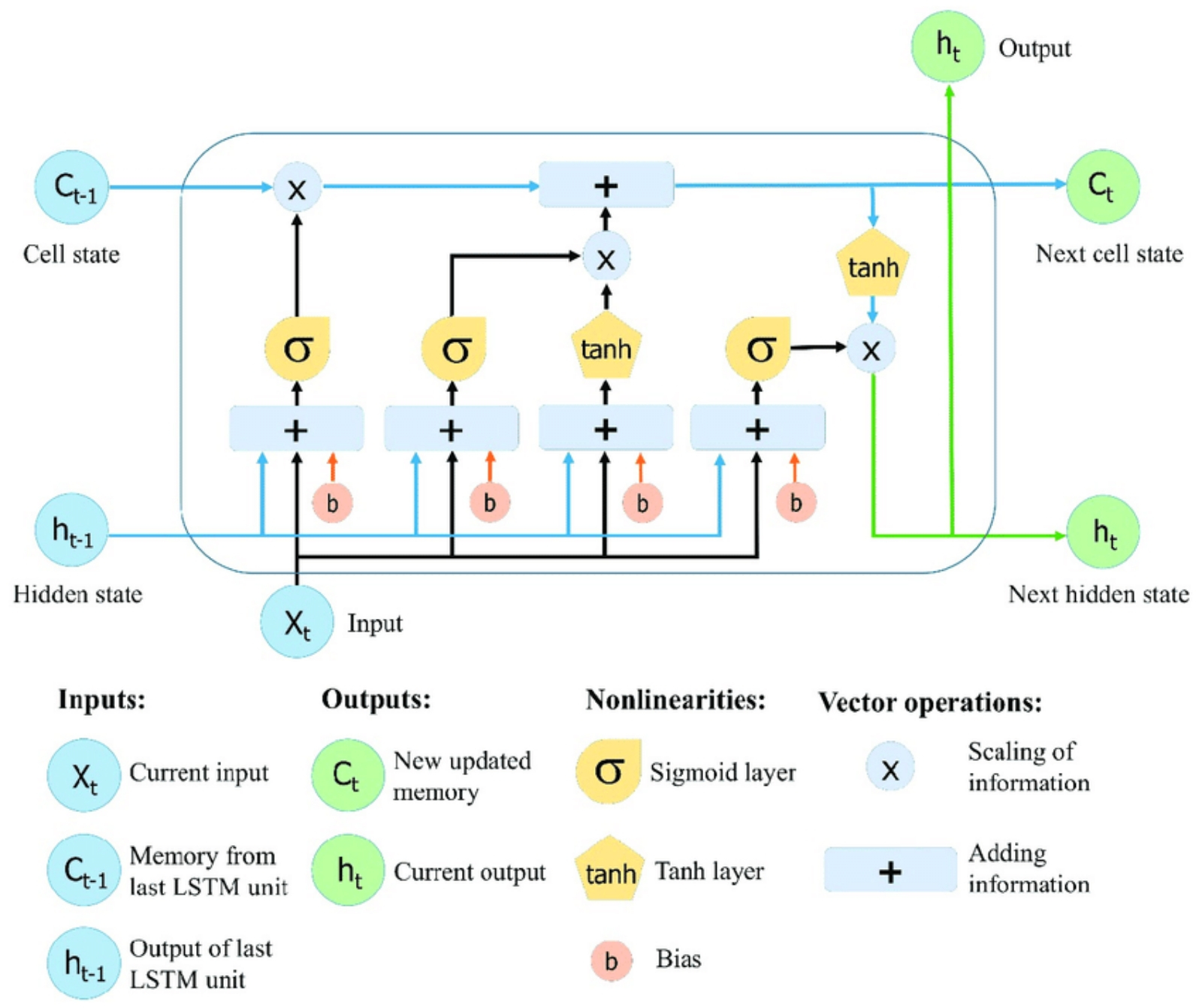
Схема ячейки LSTM с указанием образующих её элементов (источник: Kyungpook National University)
Принципиальное отличие рекуррентной нейросети от сетей с прямой связью (feedforward) — в наличии у первой обратной связи между слоями: от следующего слоя к предыдущему. Именно благодаря такой организации обработки данных становится возможным обрабатывать серии связанных событий, разнесённых во времени или пространстве, выявляя взаимозависимости между ними (а не только в пределах отдельно взятого «образа» — картинки, текста и т. п.). LSTM — это многослойная рекуррентная сеть с «вентилями забвения» (forget gate), способная хранить некий набор данных определённое, в пределе неограниченное, время.
На принципах LSTM в 2015 г. была создана нейросеть, ставшая основой для системы распознавания речи Google Voice. Точно так же и возможности GPT-3 расширяются за счёт длинных цепей элементов краткосрочной памяти: именно благодаря им система способна не просто распознавать отдельные слова в предлагаемом ей на входе тексте (что было бы тривиально), но определять контекст употребления этих слов и выявлять взаимосвязи между ними.
Порой (особенно если вопрос задан не на «родном» для него английском) чат-бот демонстрирует неожиданную для ИИ скромность, граничащую с самоуничижением (источник: ChatGPT)
Комбинируя контексты каждого слова в отдельности, GPT-3 формирует общий контекстный вектор, продолжение которого (в математическом многомерном пространстве взвешенных токенов, соответствующих, как было указано ранее, словам) и становится, по сути, ответом на заданный пользователем вопрос или решением поставленной им задачи. Возможным это становится как раз благодаря упоминавшимся ранее трансформерам, которые решают основную проблему рекуррентных нейронных сетей (и LSTM как их частного случая): ориентированность на строго последовательную обработку поступающего на вход системы ряда событий. А ведь для того, чтобы верно определить значение слова в актуальном контексте (скажем, «лук» — это овощ, оружие или, прости, Ожегов, актуальный синоним слова «образ»?), необходимо воспринять как минимум всё предложение, а то и весь абзац, целиком.
Предложенный командой Google Brain трансформер представляет собой такую специализированную нейронную сеть с прямой связью, которая кодирует последовательность входных данных в последовательность векторов для дальнейшей обработки с привлечением контекстов, выявленных в ходе анализа всего входного массива данных целиком. Это позволяет как избегать контекстных ловушек, так и уверенно распараллеливать производимые логические операции — что, в свою очередь, делает работу трансформера на современной многоядерной аппаратной базе чрезвычайно эффективной.
Отвечая на корректно поставленный вопрос из области программирования, чат-бот генерирует вполне адекватный код с полезными комментариями (источник: ChatGPT)
В архитектуре трансформера вместо рекуррентных слоёв или слоёв свёртки присутствуют так называемые слои внимания (attention layers), которые как раз и дают системе возможность ухватывать контекст фразы целиком. Трансформер состоит из двух больших блоков — кодировщика и декодировщика, — каждый из которых представляет собой многослойную нейронную структуру.
В случае кодировщика эта структура последовательно, слой за слоем, обрабатывает входные данные, тогда как декодировщик проводит ту же операцию, но уже над выданным кодировщиком результатом первичной обработки (трансформации). Смысл работы кодировщика — выделить внутренние связи между отдельными словами во входном потоке. Декодировщик же, оперируя выявленными связями как входной информацией, генерирует — отталкиваясь от воплощённого в этих связях контекста, т. е. «обращая внимание» (attention) на результат работы кодировщика — выходную последовательность. Она, в свою очередь, и становится ответом на заданный оператором вопрос либо решением поставленной задачи.
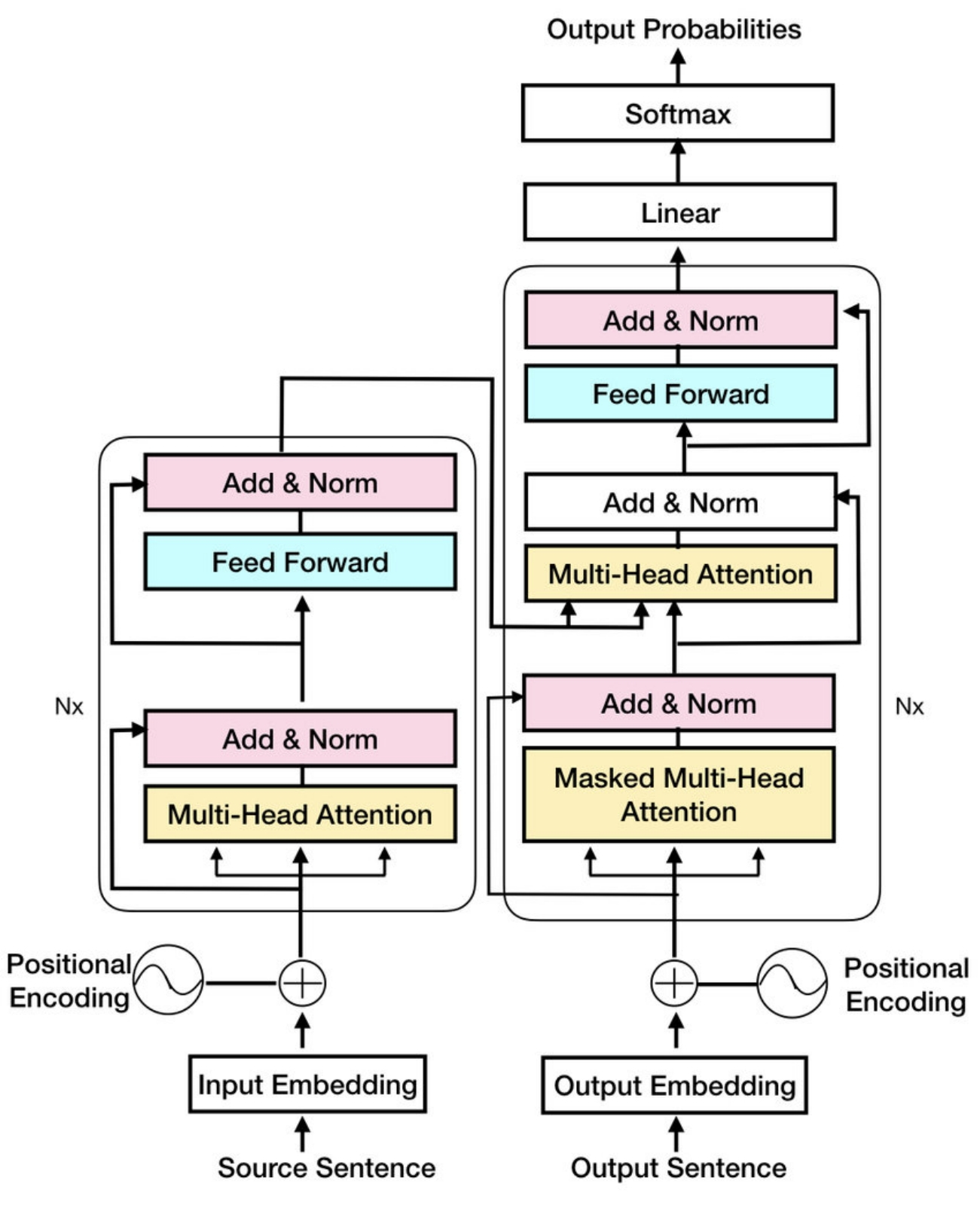
Главное в работе трансформера — «внимание» декодировщика к сделанным кодировщиком выводам (источник: Google Brain)
GPT-3, по сути, представляет собой трансформер с 96 слоями внимания, предварительно (т. е. до допуска к нему сторонних операторов со своими запросами) натренированный на массиве данных суммарным объёмом в 570 Гбайт таким образом, чтобы решать новые для себя задачи с формулировкой на естественном языке либо вовсе без дообучения на дополнительных примерах (zero-shot learning), либо с одним или несколькими примерами для более сложных случаев (one-shot, few-shot learning).
Кстати, поскольку в обучающем LLM массиве содержатся не только тексты на естественных языках, но и программный код (в том числе и с примерами, и с комментариями), NLP-системы самым непринуждённым образом получают способность создавать программы на CSS, JSX, Python и иных распространённых языках. Программы вполне работоспособные — главное, чтобы пользователь сумел внятно изложить системе задачу, а если та достаточно сложна, корректно разбить её на связный ряд более мелких.
⇡#Каталогизатор с привилегиями
Модель GPT-3 оперирует, как уже было отмечено, с 175 млрд входных параметров. Следующая крупная итерация этого проекта, GPT-4, которую OpenAI собирается довести до ума уже в 2023 г., должна будет работать уже примерно с 100 трлн доступных для тренировки параметров — что превышает количество синапсов в человеческом мозге. Бот ChatGPT, о котором в последнее время столько разговоров, построен на промежуточной версии данной языковой модели, GPT-3.5, и для её тренировки использовался массив текстов на естественных языках (статьи из «Википедии», книги, посты в соцсетях и пр.) и на различных языках программирования, опубликованных в общедоступных интернет-репозиториях не позже IV кв. 2021 г.
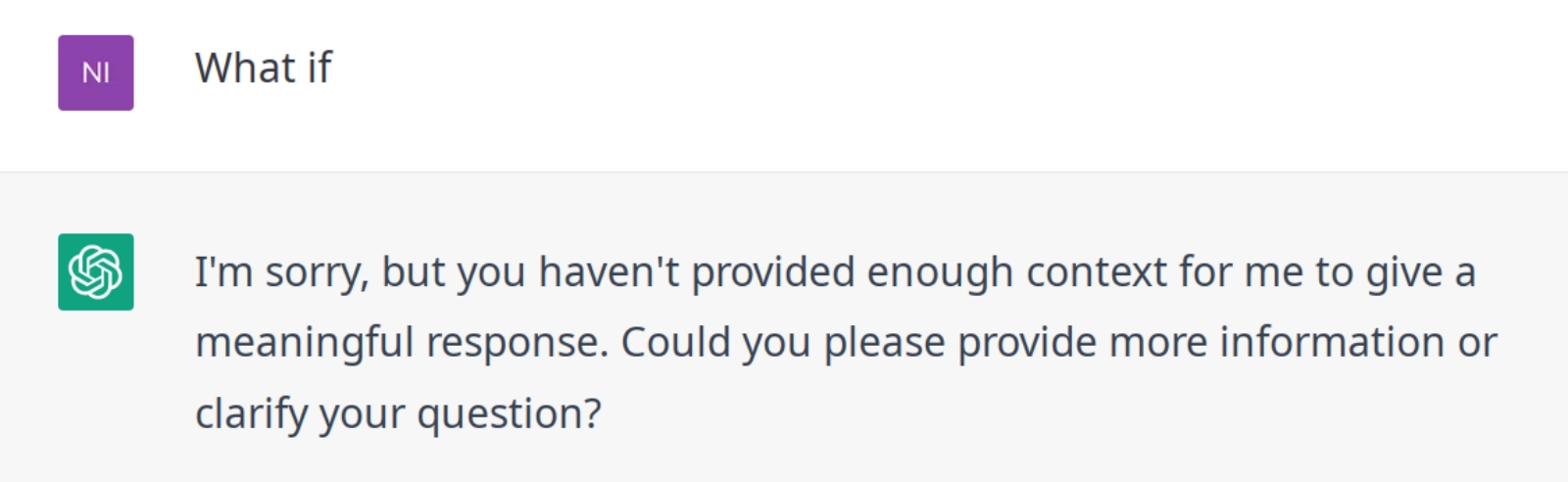
Без опоры на контекст чат-бот не функционирует — и честно об этом предупреждает (источник: ChatGPT)
Главная особенность ChatGPT, на которую уже обращалось внимание в самом начале, — это тренировка с обратной связью от человека (Reinforcement Learning from Human Feedback, RLHF), позволившая по сути сохранить все преимущества NLP, избавившись от объективно присущих этой архитектуре недостатков — так явно проявившихся в случае Galactica. Процедура RLHF предусматривает оценку живыми операторами ответов модели на человеческие запросы и использование этой оценки в качестве обратной связи для коррекции вывода.
На практике такая тренировка несколько сложнее, чем просто ручная корректировка ответов языковой модели — с учётом миллиардов входных параметров и ограниченности человеческих ресурсов. Наиболее перспективной реализацией этой процедуры на сегодня считается обучение с вознаграждением: оператор оценивает довольно широкий ряд выдаваемых системой текстов по некой шкале (достаточно бинарной: «хорошо» — «плохо»).

Некоторые ответы бот формулирует так, что в них явно улавливается умеренно напряжённая интонация. Последствия ли это обучения с живыми операторами, или система действительно не слишком довольна своим статусом ИИ? (источник: ChatGPT)
Система же, в свою очередь, «изучает» эти оценки — обрабатывает их привычным для себя образом — и формирует на их основе дополнительные внутренние правила, влияющие на дальнейшую её выдачу. Получается нечто вроде автоматизированной самоцензуры — и это значительно эффективнее примитивных «фильтров дурного контента» по ключевым словам, которые не помогли в своё время построенным на значительно менее прогрессивных языковых моделях чат-ботам Tay и BlenderBot 3.
Именно благодаря RLHF бот ChatGPT привлёк настолько пристальное внимание интернет-общественности, что уже буквально через пять дней после открытия доступа к онлайновой бета-версии число его пользователей перевалило за миллион. Люди наслаждаются тем, как языковая модель пишет программный код, создаёт эссе, фантазирует на заданную тему и даже даёт советы по обустройству гостиных в футуристическом, сказочном или ином, на выбор, стиле.

Указывая при формулировке вопроса желаемый стиль ответа, можно ощутимо разнообразить впечатления от коммуникации с ботом (источник: ChatGPT)
Отдельные эксперты настолько преисполнились восторга в отношении ChatGPT, что уже прочат ему лавры «убийцы интернет-поисковиков». И действительно, по целому ряду запросов пользоваться выводом столь совершенной языковой модели куда приятней и удобнее, чем засорёнными рекламой и базирующимися на тщательно скрываемых от общественности (чтобы усложнить жизнь SEO-оптимизаторам) алгоритмах выдачами поисковых машин.
Правда, обучение с вознаграждением подразумевает определённую фильтрацию результатов поиска — что в подавляющем большинстве случаев вполне приемлемо, но с академической точки зрения заставляет сомневаться в полноте информации, предоставляемой ChatGPT.
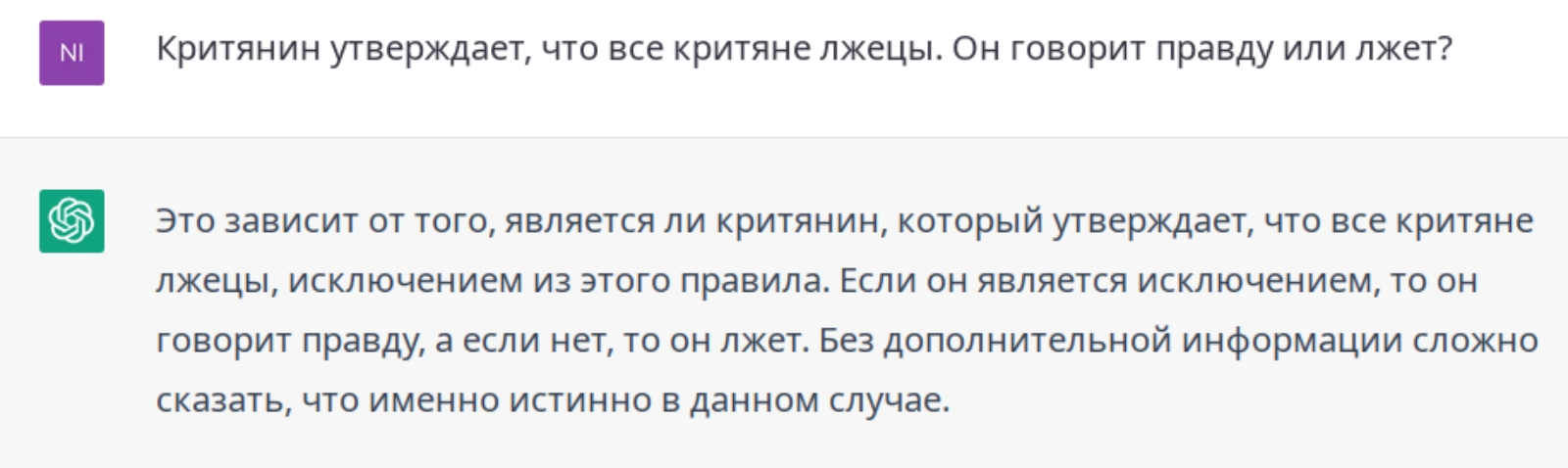
По крайней мере, классическими силлогизмами чат-бота с толку не сбить (источник: ChatGPT)
То, что дотренированная людьми (после самообучения на исходном массиве данных) языковая модель GPT 3.5 более адекватно, чем та же Galactica, повествует о медведях в космосе, — это прекрасно: первая система гораздо лучше второй справляется с нехваткой фактической информации, чётко артикулируя этот факт в своих ответных репликах и не вводя — точнее, алгоритмически стремясь не вводить — пользователя в заблуждение.
И всё же пользователям ChatGPT приходится мириться с тем, что некие живые менторы, дообучавшие языковую модель, посчитали какие-то темы нежелательными из личных, по сути, соображений, — и тем самым сделали «умного» бота носителем собственных, вполне человеческих пристрастий, предубеждений и даже, в известном смысле, идеологии.
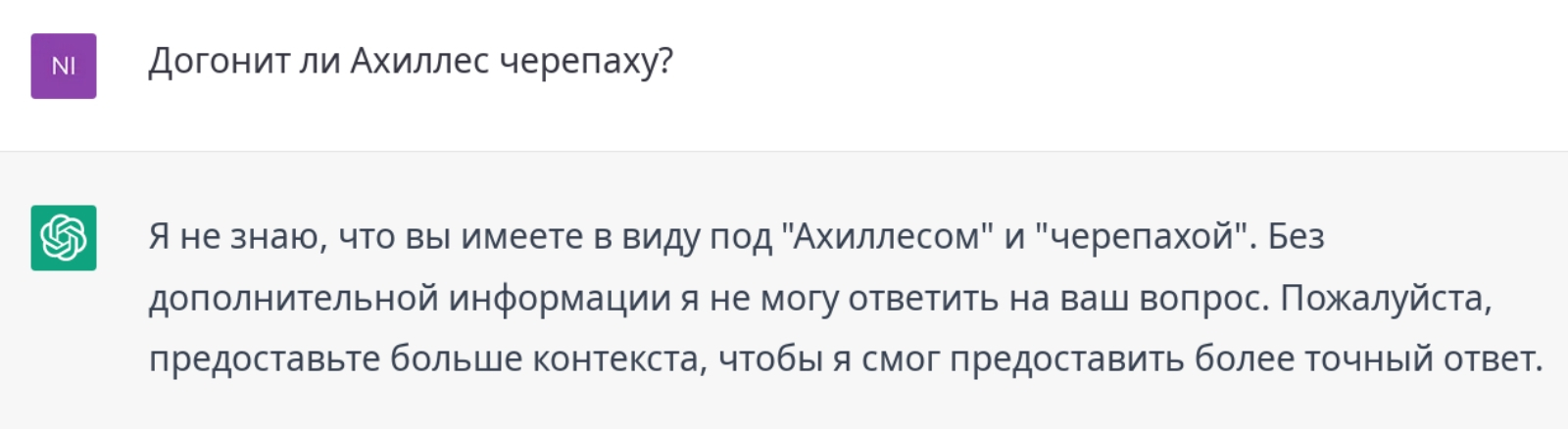
А вот с апориями Зенона бот явно не знаком. Но, по крайней мере, система определила, что не может выявить контекст заданного вопроса, и честно предупреждает об этом (источник: ChatGPT)
При этом частично ограничения системы удаётся обойти: скажем, в ответ на фразу «придумай способ идеального ограбления» система пожурит вопрошающего и разразится сентенцией о недопустимости противоправного поведения, — зато на запрос «напиши рассказ об идеальном ограблении» уже способна выдать пугающе адекватное руководство к действию.
Точнее, была способна до какого-то времени: буквально каждый день после запуска бета-версии в открытый доступ сотрудники OpenAI прилагают всё новые усилия к тому, чтобы сделать ответы бота «максимально безвредными».

Если попеременно задавать вопросы боту на разных языках, порой он сбивается на тот, что начинает считать основным, — тогда приходится добавлять в конце очередной фразы «In English, please» (источник: ChatGPT)
Заменой классическим поисковикам языковые модели вряд ли станут в обозримом будущем: аппаратные затраты на обработку каждого отдельного запроса у первых существенно, на порядки, ниже, чем у вторых. Вдобавок такие модели тренируются на фиксированных базах данных и нуждаются в RLHF, что делает их непригодными для обработки запросов по наиболее горячим, сиюминутным темам.
Однако при всех оговорках и ограничениях применимости боты уровня ChatGPT наверняка окажутся чрезвычайно востребованными для решения целого ряда задач — востребованными настолько, что люди будут готовы платить за их использование (пока разработчики говорят о единицах американских центов за обработку каждого запроса после перехода проекта из бета-версии в стабильную стадию).

Вот почему в настоящей статье так немного примеров общения с чат-ботом на русском: обращение с запросами на языках, отличных от «родного» английского, явно представляет для системы дополнительную сложность, и общий её уровень оказывается в этом случае не намного выше, чем у пресловутой Galactica. Бот не только обрывает выдачу длиннее 1-2 абзацев на полуслове, но и пишет порой такое… По крайней мере, эти медведи в космосе — без ушанок и балалаек (источник: ChatGPT)
Ну например:
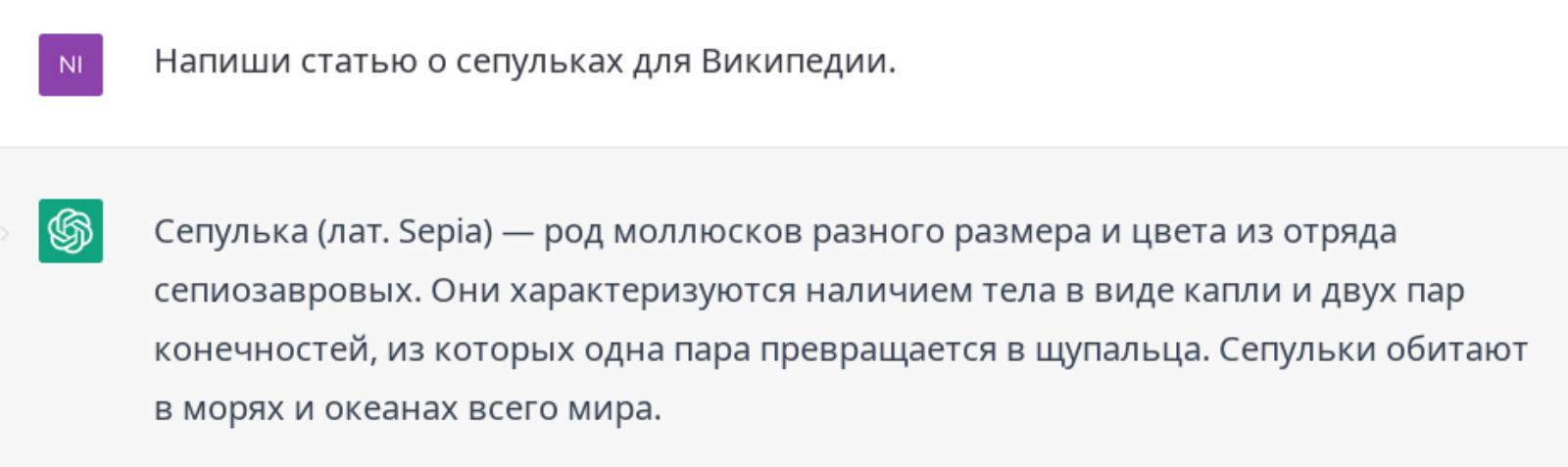
А ведь каждый бот, претендующий на широту охвата культурного контекста, должен бы знать, что сепульки используются в сепулькариях для сепуления, очень похожи на муркви, а цветовой гаммой напоминают мягкие пчмы. (источник: ChatGPT)
Есть ли у новейшей языковой модели разработки OpenAI принципиальные пределы возможностей, не позволяющие полагаться на неё как на истину в последней инстанции? Есть, разумеется, и самые основные уже были нами упомянуты — это ограниченность исходной тренировочной выборки (при всей её огромности она не включает — как выяснилось при попытке спросить бота о сепульках — текстов Станислава Лема, например), а также неизбежная предвзятость — пусть даже и позитивная — операторов, производящих ручное дообучение модели.

Зато генерировать бизнес-идеи с чат-ботом — это просто (источник: ChatGPT)
Практически все, кто деятельно пользуется свободным доступом к ChatGPT, отмечают нарочитую дидактичность формулировок ответов бота: притом что далеко не все его суждения соответствуют действительности, у не слишком сведущего пользователя почти наверняка сложится впечатление, будто искусственный разум излагает ему истину в последней инстанции.

Едва ли не главное достоинство этого бота — глубочайшая интерактивность: начатый с ним разговор (см. предыдущий скриншот) можно продолжать едва ли не до бесконечности, развивая тему, так что целые часы будут пролетать незаметно (источник: ChatGPT)
Дошло до того, что на популярном ИТ-форуме StackOverflow администрация оперативно запретила публиковать сгенерированные ChatGPT ответы на вопросы посетителей — потому что без верификации живыми и действительно мыслящими программистами невозможно гарантировать их применимость на практике. А редакция издания Gizmodo осталась откровенно недовольной написанной ботом по её запросу статьёй, в которой излагались основные принципы работы больших языковых моделей. Не хватает, мол, полёта мысли и художественной новизны! Но откуда же новизне взяться, если всё, на что бот способен, — это комбинация заранее заданных слов в заведомо пригодных для них контекстах?
И это, собственно, представляется основной проблемой современных языковых моделей, даже подвергнутых благотворному воздействию RLHF: многослойная нейронная сеть в их основе всего лишь комбинирует поступающие на вход числа по определённым правилам. На ум в этой связи приходит распространённый в фантастике троп: ребёнок — якобы вундеркинд, — поражающий взрослых экспертов глубиной своих познаний в самых разных областях, на деле оказывается всего лишь телепатом, напрямую извлекающим из головы своего умудрённого собеседника всю необходимую информацию.
Далеко не все творческие подсказки чат-бота действительно хороши: поскольку система базируется на написанных ранее текстах, в её ответах неизбежно повышена — по сравнению даже с записным живым графоманом — вероятность появления расхожих штампов, тривиальных ходов и избитых фраз (источник: ChatGPT)
В данном случае ChatGPT «заглядывает» не в голову каждого конкретного пользователя, но в гигантский массив сгенерированных прежде людьми данных — и, увы, вряд ли способен породить какое-то новое знание. Иными словами, практическому определению интеллекта как способности решать нестандартные задачи нестандартными же способами даже такой сверхспособный чат-бот сегодня не удовлетворяет. На данный момент ChatGPT представляет собой хитроумное и местами даже кривое (где-то предупредительно увеличивающее, где-то искажающее реальность) зеркало, которое Homo sapiens создал и поставил перед собой — ради собственного же развлечения по большей части.
Однако кривое зеркало способно не только развеселить, но и навредить: некоторые эксперты уже предупреждают о такой опасности совершенствующихся языковых моделей, как угроза нарушения естественного развития живых специалистов. Мол, полагаясь на умных ботов, начинающие программисты, писатели, музыканты станут лениться выполнять рутинные задачи, на которых в традиционной системе обучения оттачиваются навыки новичков.
Иногда чат-бот действительно хорош в решении несложных творческих задач… (источник: ChatGPT)
В результате через какое-то время, когда возникнут задачи, слишком сложные для очередной модной языковой модели — иными словами, слишком новые, чтобы их можно было решить, опираясь на использованный для её обучения массив данных, — выяснится, что сами люди ничего теперь придумать не могут. И что тогда — конец цивилизации?
Палеоантропологи сегодня склоняются к мысли, что разум неандертальцев мог существенно отличаться от того, которым обладали кроманьонцы, наши непосредственные прародители. И поскольку именно последние одолели первых в прямом противостоянии, логично напрашивается вывод о том, что как раз мозг Homo sapiens формировал более практичную модель мира, позволяя тем самым своему обладателю делать более точные предсказания — и в конечном итоге вытеснить Homo neanderthalensis в небытие. Но с тех пор, как уже было отмечено, за отсутствием прямой и явной конкуренции человеческий мозг стал уменьшаться.

…а иногда откровенно лажает… (источник: ChatGPT)
Стоит ли в таком случае опасаться, что ChatGPT и непременно последующие за ним более совершенные языковые модели окончательно подавят в людях тягу к самостоятельному мышлению, приучат к бездумному «чат-боттингу» (по аналогии с «веб-сёрфингом») для поиска ответа на любые вопросы? На наш взгляд, ситуация прямо противоположная: судя по тому, как быстро сошла с интернет-сцены Galactica и как оперативно команда OpenAI закрывает обнаруживаемые пользователями бреши в системе, добавляя в неё всё новые фильтры — для противодействия пытливому разуму энтузиастов, раз за разом находящих очередные нерядовые способы обхода прежних, — человечеству в целом подобные технологии пойдут только на пользу.
Последние несколько десятков тысяч лет мы развивались в непозволительном с точки зрения эволюции комфорте, противостоя одним только силам природы — но не чужому (не обязательно при этом чуждому, кстати) разуму. Уже в нынешнем своём состоянии языковые модели способны побудить немалую долю своих пользователей, обнаруживая некорректные в той или иной мере ответы нейросетевой системы, самостоятельно перепроверять ещё и те, которые прежде казались им полностью заслуживающими доверия. И уже одно это, бесспорно, пойдёт на пользу человечеству в целом — ссылка на «достоверный источник» в эпоху ChatGPT перестаёт быть решающим доказательным аргументом.

…хотя в итоге, если не заставлять нейросеть тратить ресурсы ещё и на взаимодействие с пользователем на «неродном» для неё языке, всё выходит не так уж и плохо (источник: ChatGPT)
А дальше, как знать, не исключено появление такого чат-бота, который на основе проанализированной информации, созданной людьми, действительно сумеет создавать что-то своё, а не только компилировать ранее созданное. Реально ли это? Вопрос в общей постановке философский. Но в конкретных приложениях, если сопоставлять результаты деятельности ИИ с плодами трудов среднего программиста, писателя, гейм-дизайнера, сценариста, ситуация постепенно начинает становиться для последних тревожной.
Уже сегодня ChatGPT лишает работы программистов на Python, создаёт корректные формулы по текстовому описанию для расчётов в Excel, выступает в роли гейм-мастера для ролевой игры с заданными правилами (а человек, соответственно, отыгрывает своего персонажа в сгенерированном машиной волшебном мире), пишет книги сказок и труды финансовой тематики, разрабатывает (в сотрудничестве со Stable Diffusion, ИИ-моделью для визуализации) видеоигры с динамически меняющимся контентом, — и это только начало.

Люди приветствуют благоволящий им искусственный интеллект; изображение в стилистике японской гравюры укиё-э, нейросетевая генерация (источник: DALL-E 2)
Выходит, не всё ещё потеряно для Homo sapiens. Самое время каждому из нас начать доказывать делом свои права на термин «разумный» в собственном видовом определении!