Весной 2024 г. южнокорейская компания Samsung объявила, что вот уже совсем скоро, в течение каких-то четырёх лет, сумеет вывести на рынок серийную 3D DRAM — точнее, предложить готовый к коммерциализации производственный процесс. Примерно год спустя американская NEO Semiconductor предложила уже своё видение 3D DRAM — с куда более оптимистичным прогнозом получения первых микросхем, готовых для испытания в составе рабочих модулей DIMM, уже в 2026-м. И это как нельзя более своевременно: если SSD повышенной плотности — это, что называется, nice to have, «неплохо, если есть под рукой, но можно и обойтись» (обойтись тем, что было доступно прежде, — накопителями с однослойными чипами), то с учётом стремительно растущих аппетитов новейших генеративных моделей именно к оперативной памяти высокоплотная и быстрая 3D DRAM — это просто-таки must have, «решительно необходимо».

Микросхема DRAM ёмкостью 256 Кбайт, изготовленная в 1984 г. (источник: IBM)
Осенью 2024 г. в возрасте 91 года ушёл из жизни Роберт Деннард (Robert Dennard) — изобретатель динамической памяти с произвольным доступом (dynamic random-access memory, DRAM), каждая ячейка которой содержит ровно по одному конденсатору и полевому транзистору (MOSFET, metal–oxide–semiconductor field-effect transistor). До 1966 г., когда Деннарда посетила эта блестящая в своей лаконичности идея, для оперативного размещения обрабатываемых процессором данных и временной (до записи на постоянный носитель) фиксации результатов такой обработки использовались куда более громоздкие и энергоёмкие технологии — вроде конденсаторных массивов или магнитных сердечников: чаще всего несущий заряд элемент обозначал там логическую «1», а незаряженный — «0». С середины 1960-х распространение получила память на биполярных транзисторах, но число их на каждую ячейку (в которой, напомним, хранится всего лишь 1 бит) было достаточно велико: так, инженерная команда в структуре компании IBM, частью которой был в те времена Деннард и которая разрабатывала новые принципы сохранения промежуточных вычислительных данных, изначально принялась совершенствовать шеститранзисторные ячейки памяти с произвольным доступом. Здесь уместно напомнить о микросхемах SRAM, ячейки которых организованы как раз по принципу 6T (6 transistors), — мы уже рассматривали её довольно подробно, рассказывая о том, почему современные полупроводники недостаточно хороши для ИИ. У статической памяти (S в её названии — как раз от static) с произвольным доступом масса достоинств, включая длительный срок удержания заряда в отсутствие необходимости его перезаписи. Вот только аппаратных ресурсов она требует очень много: всё-таки шесть транзисторов на бит, когда речь идёт о хранении многих десятков, а то и сотен гигабайт данных, — не шутка.
Деннард же рассудил здраво: да, пусть в пришедшей ему на ум схеме 1T1C (1 transistor, 1 capacitor) на миниатюрном конденсаторе плоховато удерживается заряд, который со временем утекает на «землю», что ведёт к потере записанного в ячейку бита данных, — но если применять такую память именно для временного хранения промежуточных результатов вычислений, которые производит процессор, то это не так уж и страшно. Вдобавок считывание логической «1» из ячейки 1T1C и так приводит к разряду её конденсатора — т. е. по итогам выполнения этой операции информация в любом случае окажется потеряна. Поэтому проще с самого начала проектировать такую память с учётом необходимости освежать (refresh) её с определённой периодичностью, подзаряжая соответствующие конденсаторы, зато потери данных удастся избежать. Реализующую описанный подход память на ячейках 1T1C потому, собственно, и назвали динамической — ведь, в отличие от тоже энергозависимой SRAM, в ячейке DRAM однажды записанная туда логическая «1» не сохраняется в неизменности, пока к цепи подведено питание: требуется регулярное освежение сохраняемых данных, так что динамика тут налицо.
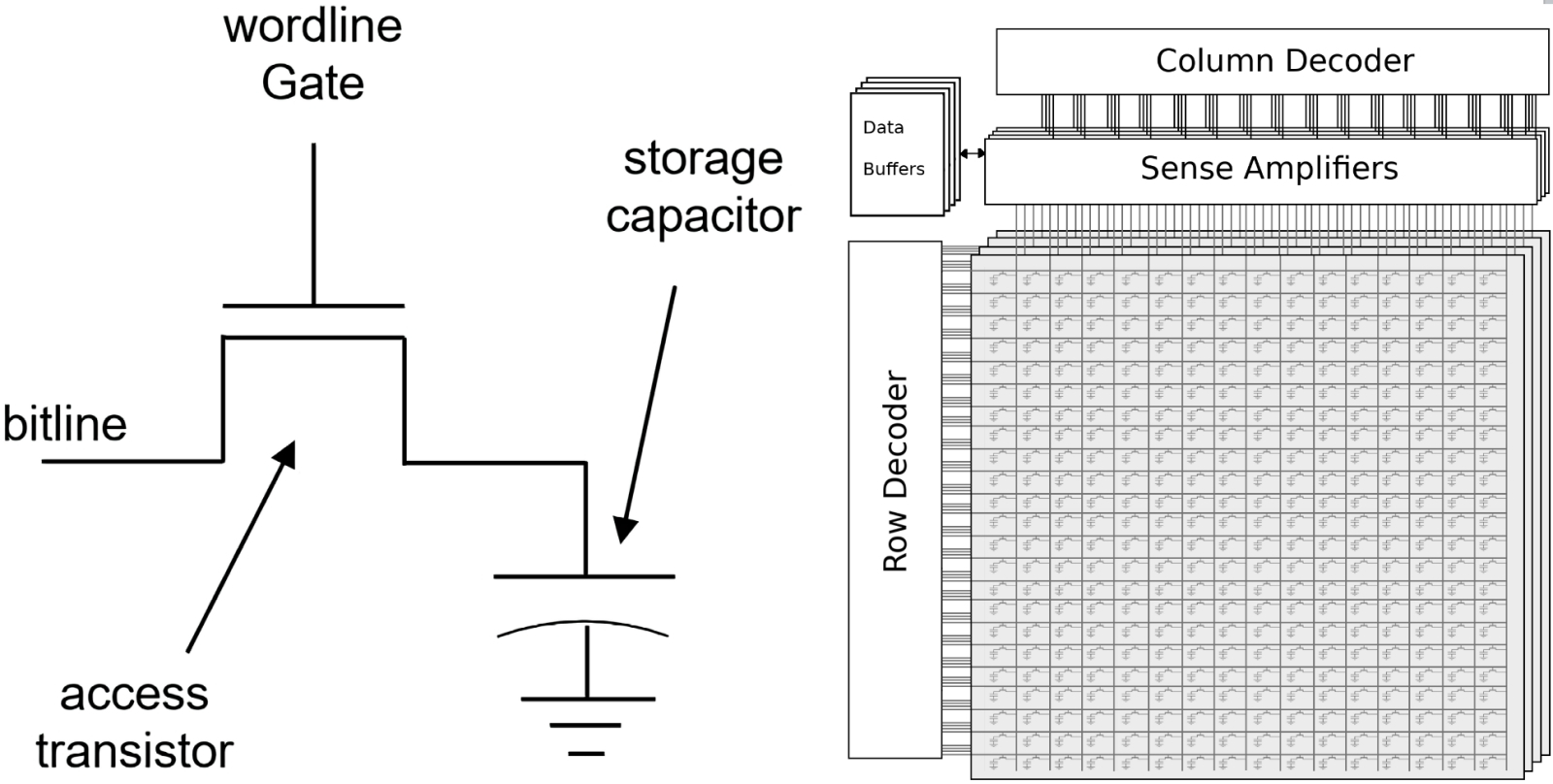
Слева — схема одиночной ячейки DRAM: просто, как всё совершенное. Словарная линия (worldline), к которой подключён затвор транзистора, контролирует прохождение заряда по битовой шине (bitline), куда присоединён транзисторный исток: либо в сторону конденсатора, для записи, либо в обратную сторону — для считывания. Справа — общая организация массива ячеек DRAM с необходимой для считывания и записи данных логической обвязкой (источник: Imec, AllAboutCircuits)
Зато конструктивно простые битохранилища DRAM несложно выстраивать в прямоугольные матрицы — правда, с одной оговоркой: формально прямой доступ к каждой из ячеек таким образом оказывается невозможен. Словарные и битовые линии в таких матрицах пересекаются, и, если подать напряжение на одну из словарных линий, активируются все ячейки вдоль неё. Эта совокупность ячеек вдоль одной словарной линии называется страницей (memory page). В ходе операции считывания — т. е. определения, в каком состоянии находится ячейка на пересечении указанных строки (словарной линии) и столбца (битовой), логический «0» или «1», — на уровне декодера строк прежде всего формируется сигнал RAS# (row address strobe — строб выборки строки). По соответствующим битовым линиям от ячеек этой строки, где содержались логические «1», идут слабые токи, которые попадают на усилители чувствительности (sence amplifiers), они же компараторы, венчающие каждую битовую линию: величина заряда в отдельном конденсаторе слишком мала, чтобы её можно было безошибочно считать напрямую. Таким образом вся страница памяти — строка — попадает в буфер строк (он же «защёлка», latch). Тот по сути выполняет кеширующую функцию: чтó именно хранилось в конкретной ячейке считанной строки, логический «0» или же «1», определяется как раз на уровне буфера — путём подачи на адресные линии микросхемы памяти заданного адреса столбца вместе с сигналом CAS# (cloumn address strobe — строб выборки столбца). Сигналы RAS# и CAS# подаются попеременно, один за другим: сперва в буфер помещается строка памяти, затем происходит выбор столбца. Понятно, что это лишь самое приблизительное описание работы DRAM, — скажем, если нужно считать несколько последовательно расположенных битов данных, нет смысла соответствующее число раз проводить операции RAS#/CAS#; куда проще на уровне контроллера модуля памяти задать выборку всех нужных ячеек разом, — но общий принцип именно таков.
Если даже оставить в стороне процедуру освежения заряда в конденсаторах (её нужно производить довольно часто; характерный интервал между двумя такими операциями составляет 64 миллисекунды, притом сама она достаточно коротка, 75-120 наносекнуд, но, пока она идёт, пользоваться DRAM невозможно), обращение к оперативной памяти характеризуется сразу несколькими задержками: RAS#-to-CAS# Delay (tRCD), CAS# Latency (tCL) и др. Чем меньше по физическим габаритам конденсаторы, применяемые для формирования особенно малоформатных ячеек 1T1C, и чем протяжённее словарные и битовые линии, тем дольше в общем случае приходится накапливать для последующего усиления полезный сигнал — и тем больше в процесс считывания данных из страниц памяти вкрадывается ошибок. Уже отсюда понятно, что миниатюризация микросхем DRAM — значительно более сложное дело, чем логических контуров. А следовательно, «простым» переходом к менее масштабному производственному процессу ёмкость стандартной плашки оперативной памяти не нарастить. Приходится применять другие методы — и в этой связи качественный скачок к 3D DRAM представляется едва ли не более простым и логичным шагом, чем попытка и дальше экстенсивно совершенствовать планарное ОЗУ.
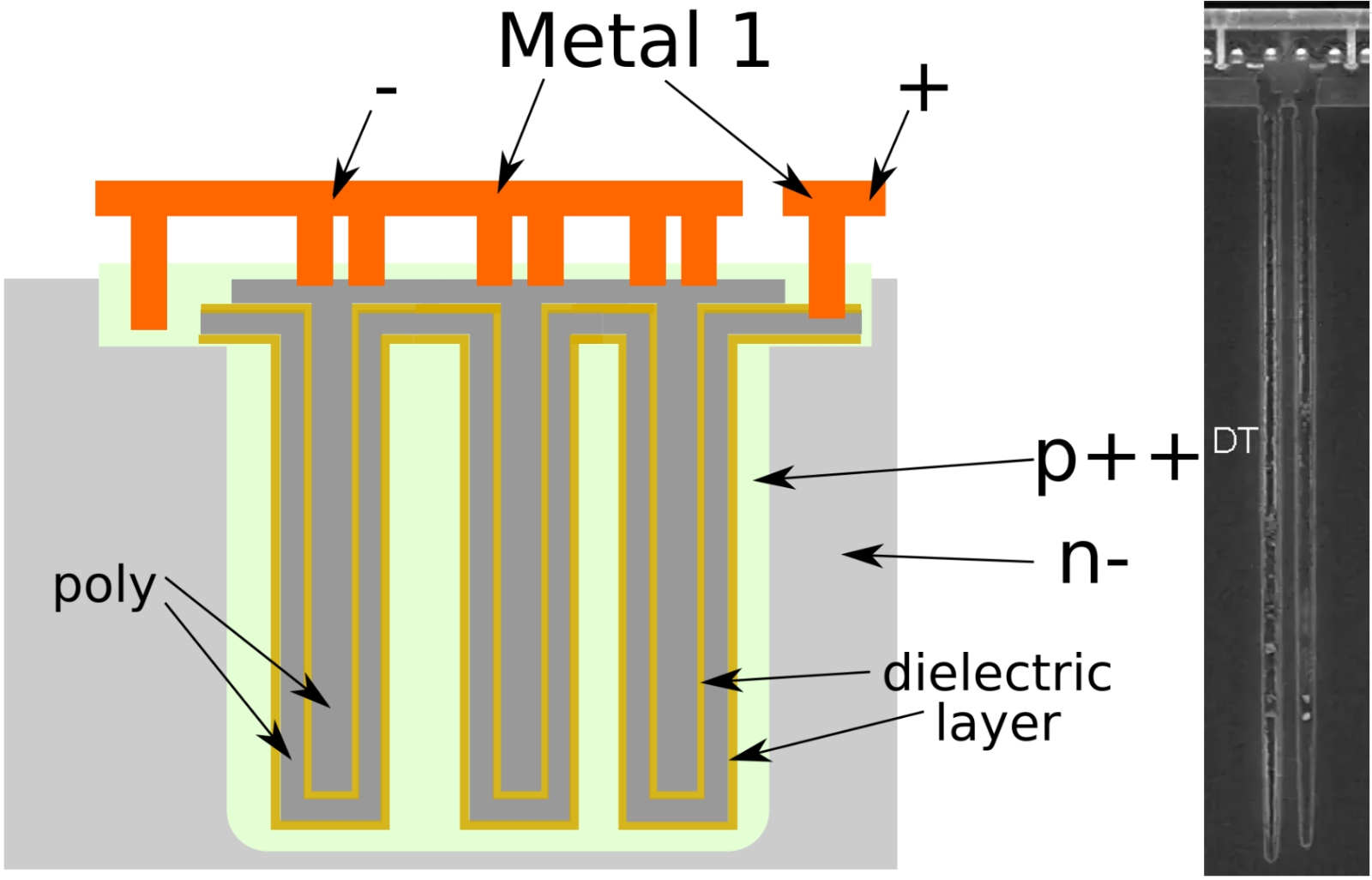
Слева — схема организации глубокого канавочного конденсатора (deep trench capacitor, DTC) для ячейки DRAM на кремниевой подложке, где собственно канавки получены травлением; справа — электронная микрофотография такого конденсатора, выполненного по 32-нм технологии, в разрезе (источник: WikiChip)
Упорядоченная структура 1T1C-матрицы DRAM представляется вполне пригодной для миниатюризации: полупроводниковые элементы (с некоторыми оговорками касательно конденсаторов), по крайней мере, вполне её допускают. Другое дело — сигнальные шины (слов и битов), которые приходится выполнять в металле: по физическим причинам ширина их — не маркетинговое обозначение техпроцесса, а именно объективно измеримая ширина — не может быть меньше примерно 10 нм, что накладывает крайне весомое ограничение на переход ко всё более компактным производственным нормам при изготовлении оперативной памяти. Пример 3D NAND свидетельствует, что выход в третье измерение вполне оправдан: таким образом на единицу площади чипа приходится кратно больше ячеек памяти (благо толщина каждого из слоёв ничтожно мала по сравнению с шириной и длиной), так что фактически без изменения конструкции вычислительной системы в целом можно на ту же стандартную по размерам и интерфейсу плашку DRAM умещать гораздо больше столь вожделенных генеративными моделями гигабайтов ОЗУ, а на отведённые для чипов GDDR площадки на монтажных платах видеокарт, соответственно, больше видеоОЗУ. Ещё в марте 2023 г. — всего примерно полгода спустя после начала глобальной ИИ-революции — коммерческий директор Micron Сумит Садана (Sumit Sadana) заявлял, что типичному серверу, ориентированному на исполнение генеративных задач, требуется втрое больше NAND-памяти, чем обычному, и в восемь раз больше DRAM. Аппетиты же актуальных сегодня моделей ещё менее сдержанны.
Внимательный читатель именно в этот момент (если только не раньше) может указать на память HBM (High Bandwidth Memory), которая как раз и применяется сегодня сплошь и рядом в серверных видеокартах, обеспечивая тем высокую плотность временного хранения и значительную скорость обмена данными между вычислительными ядрами и видеоОЗУ. Однако чип HBM представляет собой буквально стопку уложенных одна на другую планарных микросхем DRAM, пронизанных сквозными каналами TSV (through-silicon via) и контактирующих между собой посредством проводящей электрический заряд микрозерни (microbumps). Это, конечно, здорово помогает в деле компактификации подсистемы ОЗУ, но с тем уровнем плотности, которую обеспечивает единый многоуровневый чип 3D NAND, сравнения нет никакого. Именно поэтому, глядя на трёхмерную флеш-память, микроэлектронщики в последние годы активно взялись за создание монолитных — в смысле, выполняемых сразу единым блоком в ходе фотолитографического процесса, а не собираемых из предварительно подготовленных пластинок — чипов 3D DRAM.
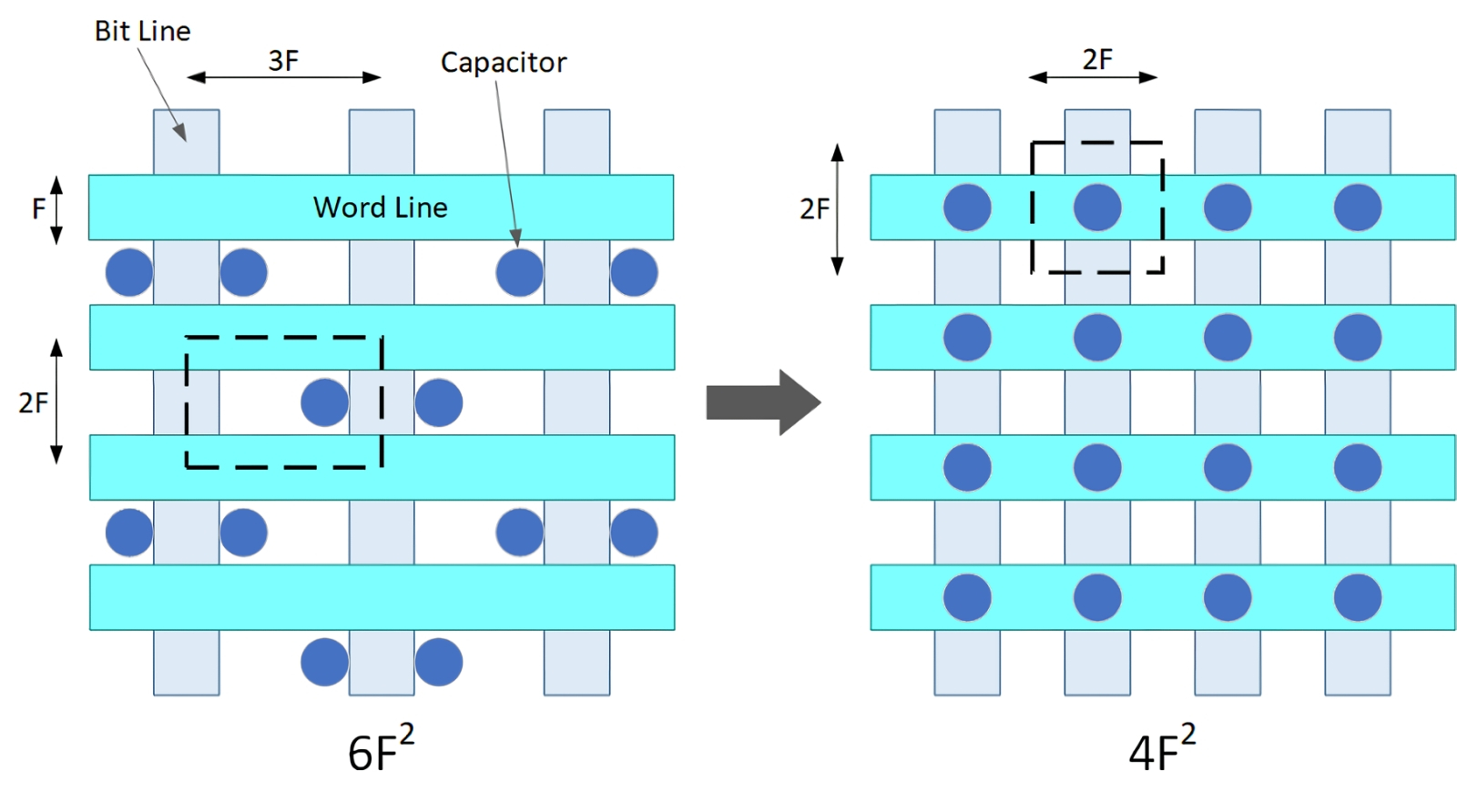
Если размещать конденсаторы прямо под пересечениями словарных и битовых линий, это позволит перейти от 6F²-ячеек к 4F² (источник: SemiEngineering)
И сразу же столкнулись с не самой тривиальной задачей: как уменьшить габариты единичной ячейки 1T1C? Начинать логично с её площади: хотя мы и упоминали ранее, что сделать токоведущие металлические дорожки намного ýже нынешних в обозримом будущем навряд ли удастся, всё-таки реально оказывается сразу на треть сократить площадь каждой отдельной ячейки. Если фактический минимальный размер металлической шины (feature size) обозначить как F, то в подавляющем большинстве случаев современные ячейки DRAM по площади занимают 6F², а то и 8F² — поскольку технология их изготовления подразумевает размещение конденсаторов (например, прогрессивного канавочного типа) рядом со словарными и битовыми линиями. Если же выполнять конденсаторы прямо под пересечениями двух этих разновидностей линий, в узлах образованной металлическими шинами решётки, то на каждую 1T1C-ячейку придётся площадь лишь 4F². Этот подход сегодня активно развивает Samsung, рассчитывая именно с его помощью преодолеть «прóклятый десятинанометровый барьер» техпроцесса, миниатюрнее которого планарные чипы DRAM никак не удаётся изготавливать. Инженеры южнокорейской компании уверяют, что уже во второй половине 2020-х оперативная память на 4F²-ячейках начнёт выпускаться серийно, — правда, для этого придётся внедрять транзисторы с вертикальным каналом (vertical-channel transistor, VCT), что позволит размещать транзистор и конденсатор 1T1C-ячейки на общей оси, экономя тем самым занимаемую такой ячейкой площадь.
Увы, даже если эти усилия увенчаются успехом в ожидаемые сроки, значительно переход к 3D DRAM они не приблизят: да, площадь одиночной ячейки оперативной памяти сократится, зато объём — за счёт довольно внушительной высоты конденсатора, да ещё и увенчанного VCT, — останется довольно заметным. Располагать один над другим толстые планарные слои 4F²-памяти, формируя последовательно из них монолитный чип, технологически затруднительно: по сути, на каждый слой с глубокими структурами «вертикальный конденсатор + VCT» потребуется едва ли не кратно увеличивать толщину пластины-заготовки, — проще тогда уж прекратить лицемерить и сразу направить усилия на совершенствование технологий изготовления HBM.
А что, если взять и положить высоченную колонку 1T1C на бок? Ну да, габариты ячейки на плоскости таким образом заметно увеличатся, зато можно будет эффективно наращивать новые тонкие слои!
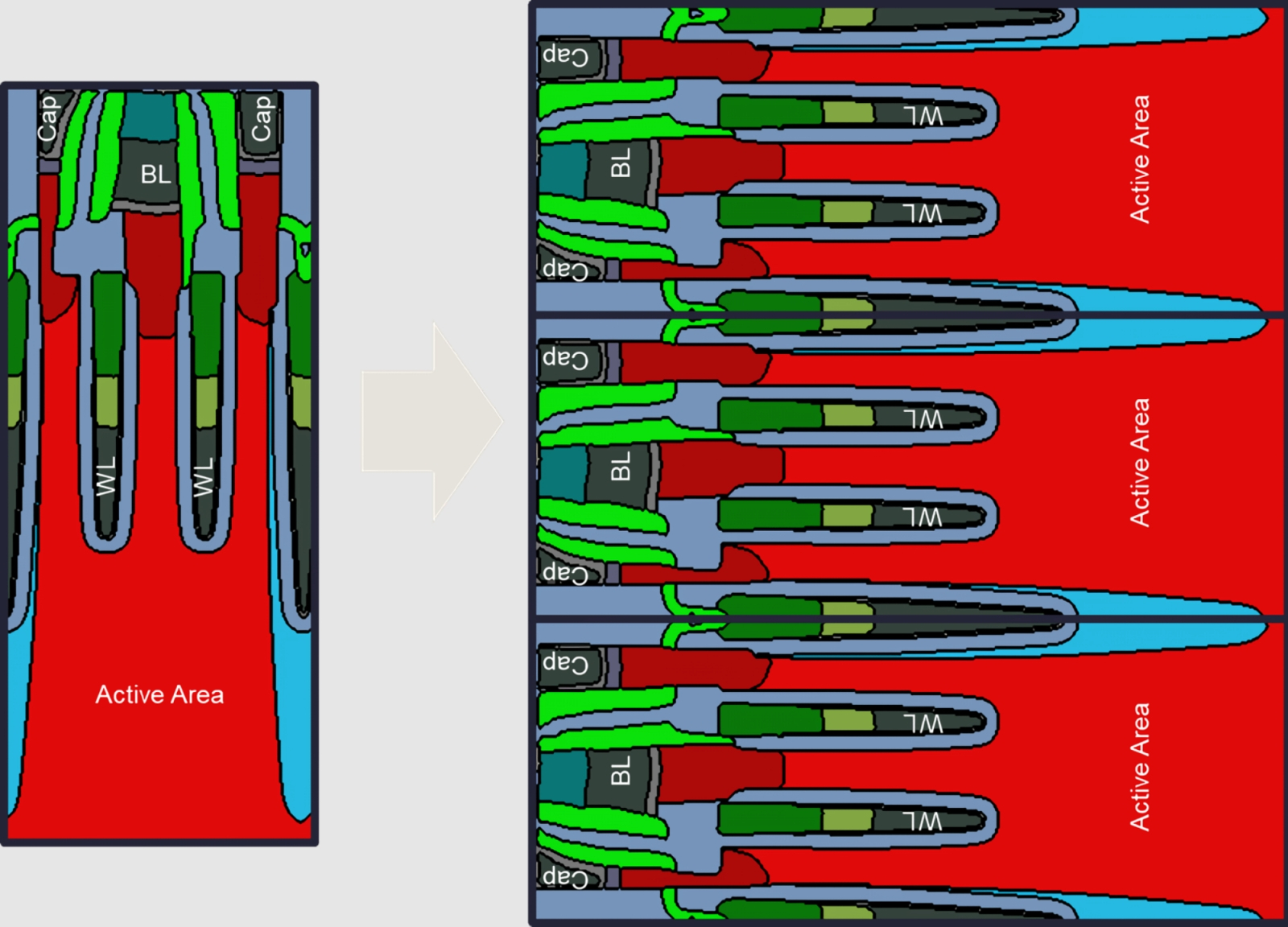
Слева — микрофотография разреза вертикально ориентированной ячейки стандартной на сегодня планарной DRAM в условной расцветке; в частности, серым обозначены металлические линии — словарные (WL) и битовые (BL), а также конденсаторы (CAP). Справа — сам собой напрашивающийся, но на практике недостижимый способ получения 3D DRAM путём укладки конструктивно тех же самых одиночных ячеек на бок с последующим послойным их расположением (источник: Lam Research)
Один из ведущих в мире производителей чипмейкерского оборудования, компания Lam Reserach, изучила возможность такой горизонтальной укладки 1T1C-ячеек — и пришла к выводу, что без существенного изменения отработанных за десятилетия технологий полупроводникового производства задача представляется недостижимой. В частности, вместо вертикального травления здесь придётся использовать боковое (lateral etching), причём на различную протяжённость для разных элементов ячейки, и, каким образом это реализовать на практике с приемлемым для массового производства уровнем точности, пока что совершенно непонятно. Зато очевидно другое: раз конденсатор и прочие компоненты 1T1C всё равно будут лежать на боку, нет уже принципиального смысла делать их максимально узкими и длинными. Для планарной DRAM вытянутая конфигурация важна, поскольку ячейка такой памяти располагается вертикально — а значит, при меньшей площади сечения занимает меньше места на подложке. Но раз в случае 3D DRAM конденсаторы будут укладывать на бок, их, наоборот, есть смысл делать более кубическими, что ли (а то и вовсе сферическими — что, впрочем, с точки зрения полупроводникового производства представляет отдельный вызов), чтобы при сохранении объёма минимизировать площадь поверхности, т. е. физическую протяжённость сторон конденсатора по всем трём измерениям сразу.

Первые два этапа трансформации формально уложенной на бок, но изначально не пригодной к изготовлению на имеющемся оборудовании 1T1C-ячейки в более практичную конструкцию; см. пояснения в тексте (источник: Lam Research)
Кроме того, в Lam Reserach предлагают для начала разместить битовую шину (BL) на противоположной от конденсатора (CAP) относительно словарной линии (WL) стороне ячейки. Суть этой рокировки в том, что ток, заряжающий конденсатор при записи «1» в ячейку 1T1C, протекает (см. чёрные линии со стрелками на приведённой выше схеме) от BL к, собственно, CAP через WL — если WL это позволяет, конечно; её посредством, напомним, контролируется положение затвора транзистора. Теперь путь, который необходимо пройти заряду в толще полупроводника от BL к CAP, заметно сокращается. Если вдобавок (это уже будет второй шаг реконфигурации 1T1C-ячейки) использовать нанолистовые транзисторы с окольцовывающим затвором (gate-all-around nanosheet transistor), выйдет изрядно минимизировать протяжённость участка WL, тем самым на исходной площадке, отведённой под одну ячейку DRAM, останется куда больше места для увеличения плоскостных габаритов конденсатора. Соответственно, тот выйдет сделать тоньше, сокращая тем самым вертикальное измерение всего единичного слоя будущей 3D DRAM.
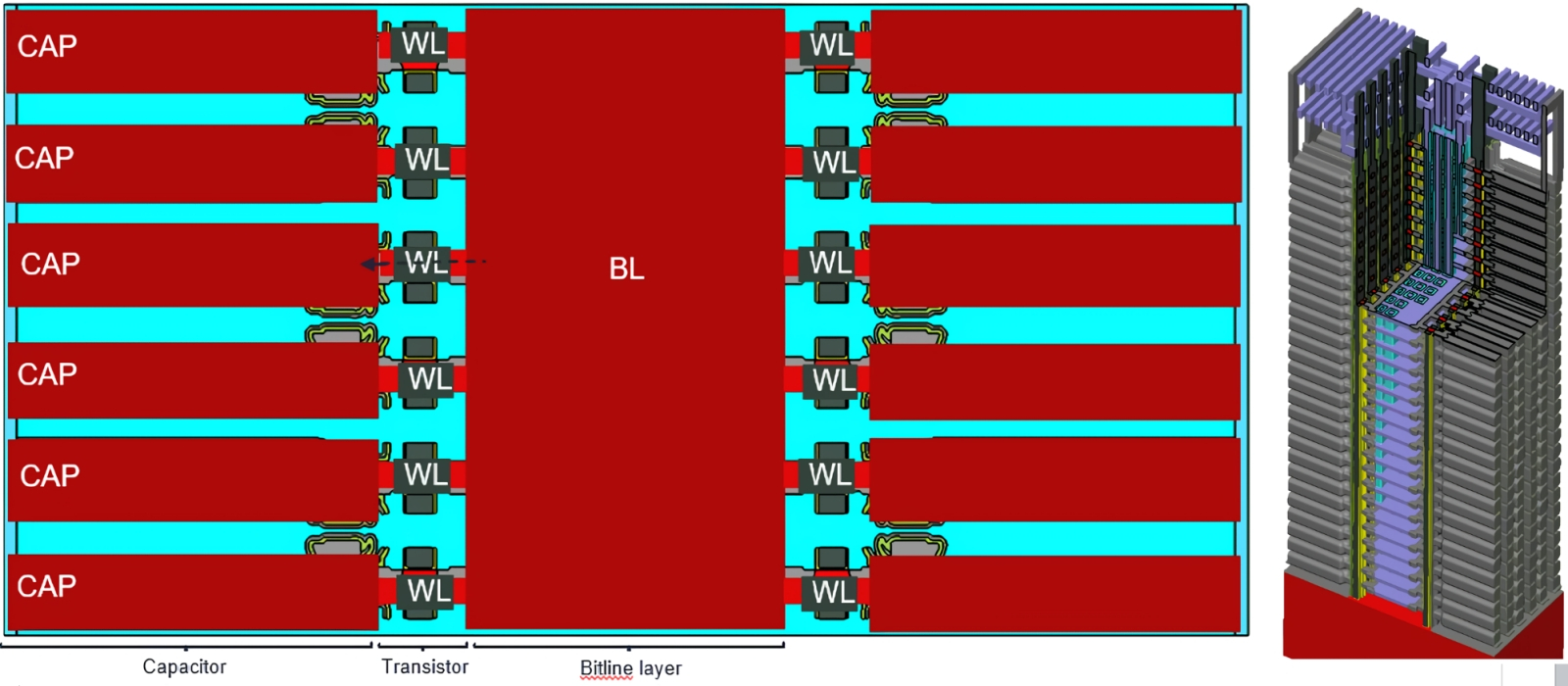
Слева — третий этап предложенной микроэлектронщиками реконфигурации ячеек 1T1C (это ещё не вертикальная укладка — показан вид одиночного слоя сверху); справа — 3D-рендер полученной многоуровневой 3D DRAM из такого рода плоских слоёв, размещённых вертикально (источник: Lam Research)
Битовая шина становится в такой конфигурации горизонтальным каналом, по обе стороны от которого располагаются модифицированные ячейки 1T1C. Вся конструкция с сохранением как физических, так и логических свойств DRAM обретает таким образом малую толщину — и становится отменно пригодной для последовательного, слой за слоем, изготовления; примерно теми же методами, что применяют уже довольно долго для получения 3D NAND. Важно отметить, что если пирамидальная структура контактов 3D NAND, посредством которой управляющие шины подводятся к каждой ячейке, отнимает заметную долю полезной площади готового чипа, то в случае 3D DRAM предлагается для той же цели управления и контроля использовать сквозные колодцы (via) внутри «слоёного пирога» с ячейками оперативной памяти. Это позволит получать микросхемы предельно высокой ёмкости на каждый квадратный миллиметр, вот только бросает прикладникам-микроэлектронщикам такие вызовы, отвечать на которые прежде им не приходилось. Бенджамин Винсент (Benjamin Vincent), один из ведущих инженеров Lam Reserach, отмечал в конце 2024 г., что такие колодцы придётся создавать — сперва протравливать, а затем выстилать их стенки изнутри покрытием с необходимыми свойствами — с поистине огромным отношением глубины (около 2 мкм) к характерному поперечному размеру (порядка 30 нм), и это только для первой планируемой разновидности 3D DRAM, толщиной всего в 28 слоёв, — сравним с 3D NAND, для которой сегодня 200+ слоёв — уже обыденность. Пока, кстати, в точности не известно, какую именно технологию для своей намеченной к выпуску в ближайшие годы 3D DRAM избрала Samsung, равно как и объявившая недавно об успехах на этом направлении SK Hynix. Но, судя по всему, именно предложенная Lam Reserach схема с уплощением слоёв за счёт «боковой укладки» конденсаторов и прочих компонентов ячейки DRAM — наиболее перспективная. По крайней мере, на ближайшее время, поскольку все необходимые для её воплощения в жизнь производственные процессы уже прекрасно освоены.
Другое дело — кардинальный пересмотр самой конструкции элементарной ячейки оперативной памяти, например отказ от привычного конденсатора в качестве хранилища электрического заряда. По фундаментальным физическим соображениям внутренний объём конденсатора (точнее даже, геометрическое соотношение его сторон), способного хранить уверенно измеримый электрический заряд, жёстко ограничен, что и делает изготовление планарной DRAM по техпроцессам ощутимо миниатюрнее «10-нм» класса делом практически невозможным. Но что, если удастся найти иной способ сохранять, а при необходимости отдавать обратно по битовой шине электрический заряд без конденсатора? Идеально было бы, если бы такой способ реализовывался с использованием некоего полупроводникового устройства, — тогда его миниатюризация не представляла бы сколько-нибудь существенной проблемы.

Схема бесконденсаторной ячейки DRAM на управляемом тиристоре с тремя словарными шинами (источник: SemiEngineering)
И такие устройства известны, в пример можно привести запираемые тиристоры с управляющим затвором (gate-controlled thyristors). Тиристор представляет собой четырёхслойный (PNPN — так обозначены чередующиеся слои с p- и n-проводимостью) полупроводниковый прибор: запираемая его разновидность способна открываться и закрываться в ответ на управляющие сигналы; положительный импульс тока открывает запираемый тиристор (соответственно, обеспечивает прохождение заряда по цепи, в которую тиристор включён), а отрицательный — закрывает. В отличие от транзистора, проводящий канал между истоком и стоком которого поддерживается, лишь пока на затвор подано управляющее напряжение, открытый тиристор в составе цепи, по которой идёт ток, остаётся открытым до тех пор, пока не получит команду на закрытие: таким образом, энергопотребление тиристорной схемы оказывается в среднем меньше, чем транзисторной. Другое дело, что сам по себе тиристор — конструкция более сложная: чтобы им эффективно управлять, одной словарной шины (WL) недостаточно; потребуются в исходном случае три (правда, уже есть идеи, как сократить их число до двух), да не простые, а составные. Каждая такая шина должна содержать раздельные управляющие каналы, по которым будут подаваться различные контрольные напряжения на соответствующие — прилегающие к данной WL — участки с n- и p-проводимостью. Словом, с учетом того, сколько в этом случае придётся городить токоведущих дорожек для обеспечения работы тиристорной DRAM, даже на глаз очевидно, что площадь её ячейки многократно будет превосходить таковую для старой доброй 1T1C. И лишь в том случае, если тиристорную 3D DRAM с ходу и со сравнительно небольшими затратами удастся изготавливать существенно многослойной, овчинка будет стоить выделки.
Впрочем, и это ещё не всё: компания Neo Semiconductor уверяет, что достигла уже немалого прогресса в разработке бесконденсаторных ячеек DRAM на основе полевых транзисторов с плавающими затворами (аналогичных тем, что лежат в основе памяти NAND). В каком-то смысле транзистор с плавающим затвором (последний располагается между основным затвором и той зоной полупроводника, разделяющей исток и сток, где образуется проводящий канал) схож с тиристором: при прохождении заряда по каналу, который удерживает в открытом состоянии основной затвор, на затвор плавающий «перескакивают» (за счёт квантового эффекта — туннелирования сквозь потенциальный барьер) отдельные, наиболее высокоэнергичные электроны. И, однажды перескочив, остаются там довольно надолго — поскольку плавающий затвор окружён изолятором, а на обратный туннельный переход энергии электронам уже не хватает. Таким образом формируется удерживающая электрический заряд (в отсутствие внешней энергоподкачки, как и у тиристора) конструкция — миниатюризировать которую, в отличие от конденсатора, можно с тем же успехом, что и любые другие транзисторы. И которая — в отличие от тиристорной ячейки — не требует избыточного количества управляющих шин. Сплошная выгода!
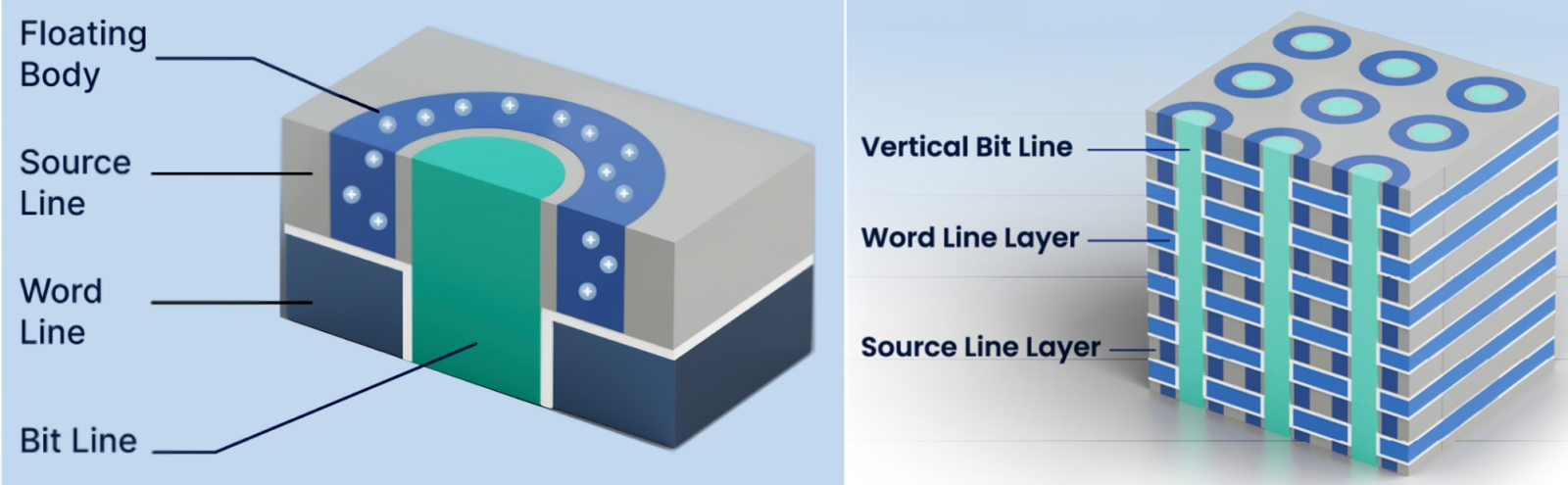
Слева — схема однотранзисторной бесконденсаторной (1T0C) ячейки DRAM с плавающим затвором; справа — принцип организации таких ячеек в трёхмерную структуру (источник: Neo Semiconductor)
Правда, с уменьшением габаритов такого транзистора существенно сложнее оказывается контролировать потенциал, что накапливается на плавающем затворе, — в конце концов, речь идёт о квантовых (вероятностных) явлениях: вероятность прекрасно проявляет себя на большой выборке, но, если требуется поместить заряд на конкретный плавающий затвор и за крайне ограниченное время — а в этом и заключается смысл работы быстрого ОЗУ, — гарантировать результат чрезвычайно сложно. Тем не менее Neo Semiconductor заверяет, что сложности эти вполне преодолимы, и указывает на такой бесспорный плюс 1T0C-ячеек, как недеструктивный характер считывания информации из них: заряд на плавающем затворе (сохраняемая в ячейке логическая «1») оказывает воздействие на идущий по каналу ток (что, собственно, и позволяет производить операцию считывания), но сам при этом никуда не девается. Конечно, и плавающий затвор разряжается со временем, но происходит это куда медленнее, чем в случае крохотного конденсатора, и потому на довольно длительных интервалах такая разновидность DRAM может считаться по сути энергонезависимой. Разработчики предложили также более громоздкий вариант бесконденсаторной ячейки с тремя транзисторами (3T0C), позволяющий, по их словам, свести к минимуму сложности управления зарядом на плавающем затворе (а в Imec и вовсе развивают подход 2T0C на тонкоплёночных транзисторах IGZO — кристаллическом полупроводниковом материале из индия, галлия, цинка и кислорода), но в любом случае серийный выпуск «плавающей» оперативной памяти начнётся явно не завтра.
Представители мировой полупроводниковой индустрии, от инженеров до топ-менеджеров, прекрасно осознают важность скорейшей постановки 3D DRAM на поток, однако пока трудно сказать, когда же первые чипы такого рода пойдут на оснащение серийных модулей оперативной памяти; для начала серверных, а позже, возможно, и предназначенных для ПК. Среди соперничающих между собой подходов к организации 3D DRAM пока нет явного лидера, и потому инвесторы колеблются — неясно, ставка на какую из технологий в итоге сыграет. Одно можно сказать с уверенностью: чем дольше продолжится ажиотаж вокруг ИИ, тем больше средств эта отрасль ИТ-рынка привлечёт — а значит, есть шанс, что и разработчикам 3D DRAM достанется ощутимая часть этого финансового потока.
Материалы по теме