







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Занимательная многоядерность
Автор статьи Александр CD-RIPer Дьяченко, Embedded-разработчик с более чем десятилетним опытом работы в сфере телекоммуникаций. Ведет блог http://cd-riper.livejournal.com Появление на недавно отгремевших CES и MWC первой волны Android-смартфонов на двухядерных процессорах, а также слухи о том, что таковые скоро поселятся и в новых мобильных продуктах Apple, привели к тому, что в Сети посыпались высказывания на тему «Что многоядерность дает, и вообще — кому все это нужно?». Надо сказать, что мнения эти очень разнообразны и, к сожалению, многие из них элементарно безграмотны. Люди просто до конца не понимают — что такое многоядерность и с чем ее едят бедные программисты. Собственно, именно ради просвещения широких, но темноватых масс (а еще в робкой надежде, что это доброе дело зачтется мне на Страшном Суде) я и решил написать этот материал. Начать, как водится, придется издалека. ⇡#Кризис жанраТот фантастический темп, в котором идет развитие всей IT-отрасли последние ...надцать лет, был предсказан почти полвека назад, в далеком 1965 году (всего лишь через шесть лет после изобретения интегральной микросхемы) Гордоном Муром и всем хорошо известен как эмпирический закон имени его самого. Читатель 3DNews со стажем знает закон наизусть, но для новичков все же напомню: Мур предрек, что число транзисторов на одном кристалле будет удваиваться каждые два года. И вот тут хотелось бы отметить один интересный нюанс. Применительно к «обычным процессорам» (можно взять любого представителя древнейшего рода x86, который с ненулевой вероятностью стоит в компьютере практически каждого читающего эту заметку человека), простой рост числа транзисторов напрямую никак не сказывается на его производительности. Куда более значимым параметром выступает частота, на которой эти транзисторы работают. Если мы посмотрим на историю развития процессоров с архитектурой x86, то увидим, как рост числа транзисторов сказывался на общей производительности, чаще всего косвенным образом. Вспомним несколько вех:  Подходы к разработке процессоров, впервые примененные в Intel i386DX, оставались актуальными более 20 лет. И только сейчас они потихоньку сменяются новыми
Как видите, направлений для траты транзисторов было очень много, но, к сожалению, не все из них позволяют ускорить уже существующие программы. Когда вы делаете очередной апгрейд системы, есть желание получить результат здесь и сейчас, а не выслушивать от производителя процессора добрые сказки о том, что ваш любимый математический пакет написан неправильно, ибо не использует SSE, не критичен к объему кеша и не понимает прелестей многоядерности. И именно поэтому ваш новенький восьмиядерный процессор, в котором транзисторов в шесть раз больше, чем в старом, даст прирост при использовании этой программы в каких-то жалких два раза... Рост эффективности исполнения команд процессорным ядром — это весьма и весьма небыстрый процесс (и 5% прироста на мегагерц при смене поколения — это очень хорошая цифра). Поэтому долгие годы, до наступления кризиса в этой сфере и прихода эры многоядерности, рост производительности шел в основном за счет тактовой частоты. Тут все просто и понятно: заставил процессор, даже без всяких нововведений в области его архитектуры, работать на более высокой тактовой частоте — получил пропорциональный рост производительности. Причем, заметьте, даже для старых приложений.  Набор инструкций Streaming SIMD Extensions (SSE), появившись в слотовом Pentium III образца 99 года, тоже вызывал немало вопросов по поводу своей полезности. Сегодня же без применения SSE и его наследников обойтись почти невозможно.О том, что расти старыми темпами вверх по частоте до бесконечности не получится, в законодателе мод, компании Intel, задумывались еще в эпоху первого поколения Pentium. И понятно, что если не получается расти в высоту, то единственный способ роста — в ширину. Примерно в то время появился упомянутый выше набор инструкций для работы с массивами данных MMX. И именно в те годы в недрах компании начинают ковать процессор с принципиально новой архитектурой — создается семейство Itanium, которое управляется «широкими» инструкциями с так называемым явным параллелизмом (EPIC). Более того, перспективы роста в рамках x86-архитектуры в те годы казались настолько туманными, что на архитектуру Itanium предполагалось пересадить всю индустрию ПК (именно поэтому эти процессоры умели эмулировать x86 набор инструкций — планировался долгий «переходный период»). Как я уже писал, рост по частоте — это самый простой и заманчивый способ обеспечить прирост производительности процессоров. В конце 90-х инженеры Intel придумали архитектуру NetBurst, и тогда некоторым из них показалось, что кто-то Большой надежно схвачен за бороду. Самым юным читателям этой заметки напомню: в свое время руководитель СССР Никита Хрущев обещал советским людям коммунизм в отдельно взятом государстве к 1980 году, а Intel прогнозировала к 2010 году процессоры с частотой в 10 ГГц в практически каждом отдельно взятом ПК.  Как мы теперь знаем, оба прогноза не сбылись. А жаль, красивые были! На практике NetBurst масштабировался совсем не так хорошо, как представлялось поначалу. С одной стороны, рост частоты приводил к чрезмерным потреблению мощности и выделению тепла. С другой — архитектура процессора для работы на этих частотах требовала введения все большего и большего числа стадий конвейера, что самым прямым образом сказывалось на эффективности работы процессора в пересчете на один мегагерц (подробнее об этом можно почитать здесь). Как мы знаем, последователи NetBurst в один ничем не примечательный день были объявлены еретиками, корпорация вспомнила о старой-доброй архитектуре P6, и показанный публике Core 2 Duo ознаменовал собой начало новой эры — эры роста процессоров не в высоту, а в ширину. Какого впечатляющего роста можно добиться за счет «роста в ширину» лучше всего проиллюстрировать с помощью следующего графика (взято отсюда. Там же, кстати, есть интересная картинка с эффектом застывшей на много лет в районе 3.4 ГГц частоты процессоров Intel).
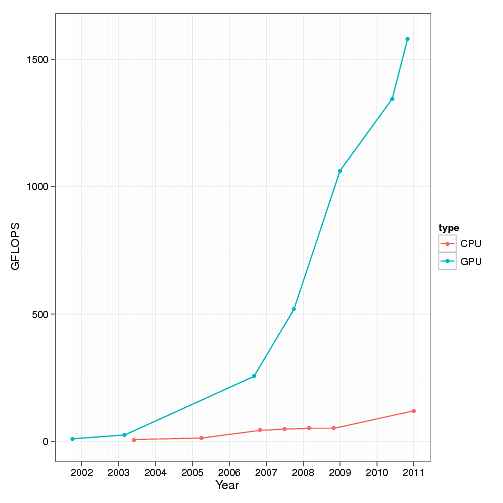
На нем мы видим рост производительности обычных процессоров (CPU) и графических процессоров (GPU) в области вычислений с плавающей точкой за последние 10 лет. Параллельная по своей сути природа построения 3D-изображений (а также относительная простота используемых при этом алгоритмов) позволила GPU уйти в такой отрыв, что современным процессорам общего назначения остается только, раскрыв рот, смотреть на эту стремительно растущую кривую. С такой же эффективностью использовать дополнительные транзисторы, которые из года в год индустрии дарит пока еще работающий закон Мура, разработчики CPU, увы, не могут. Итак, в середине 2000-х наступил кризис роста по частоте, производители процессоров подняли руки вверх и сказали «Мы сделали все что могли! Против законов физики не попрешь. Теперь ваше слово, товарищи программисты!» О том, в какую головную боль разработчиков вылилось бессилие производителей железа, — в продолжении нашего рассказа. ⇡#Глазами программистаСобственно, эта статья затевалась в первую очередь для того, чтобы на пальцах объяснить, что представляет из себя многоядерность с точки зрения простого программиста, которому с ней, родимой, очень нужно подружиться. Объяснить попытаюсь так, чтобы понял даже ортодоксальный гуманитарий, прогулявший (исключительно по религиозным соображениям) все до единого уроки информатики в школе. Но для начала надо вспомнить, что такое многопоточность (aka multithreading). Думаю, практически любой человек, работавший с Windows, знает, что это многозадачная ОС (нет, я почти не иронизирую, когда это пишу). Для простого смертного сие обычно означает, что он может одновременно паковать zip-архив, слушать музыку и при этом еще и набивать текст в Word. Если говорить строго формально, с точки зрения операционной системы, то в данном случае одновременно работает несколько процессов. Процесс — это, грубо говоря, «программа», главной особенностью которой является выделенное только ей одной собственное виртуальное пространство в памяти, изолированное от аналогичных пространств других процессов в системе (это сделано для того, чтобы ошибки одной программы не сказывались на работе других программ, работающих с ней одновременно). Так вот, на самом деле описанная выше иллюзия одновременной работы нескольких программ достигается не на уровне отдельных процессов, а на более низком уровне — на уровне так называемых потоков, или нитей (aka threads). Нить — это независимый поток исполнения команд процессором. Каждый процесс в системе имеет минимум один такой поток, но на практике обычно нитей больше чем одна. Для того, чтобы узнать, сколько у того или иного процесса нитей, можно воспользоваться «диспечером задач». Нажмите Ctrl-Alt-Del, выберите вкладку «процессы». В меню «вид», «выбрать столбцы» выберите столбец «счетчик потоков». Теперь можно узнать, у какого процесса сколько потоков. Например, в момент написания этой заметки у процесса explorer.exe (это всем известный «проводник») создано 11 нитей. 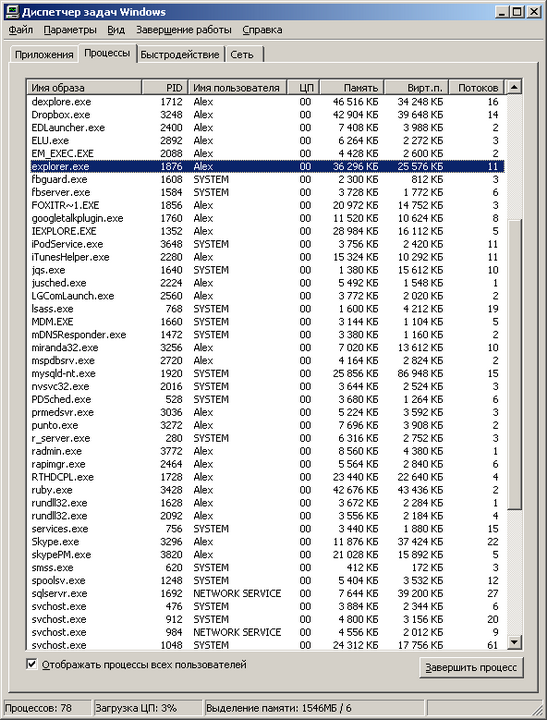 Концепция нитей и само понятие многопоточности были придуманы очень и очень давно. Еще во времена, когда все процессоры были исключительно одноядерными, а про частоты, на которых они при этом работали, даже смешно говорить. Придумано это было вот зачем. Во-первых, с помощью такого механизма операционная система создавала пользователю описанную выше иллюзию многозадачности. Во-вторых, есть целый ряд случаев, когда механизм очень сильно помогает программисту даже в рамках работы одной программы — именно поэтому типичный процесс в Windows редко имеет всего лишь один поток. По второму пункту приведу несколько простых и понятных примеров. Вы открыли несколько вкладок в браузере, и они грузятся одновременно. Процесс загрузки одной веб-страницы — действие независимое и самодостаточное, поэтому обычно загрузку каждой вкладки обслуживает как минимум один поток, специально созданный для этой цели. Вы набираете или просматриваете текст в Word, при этом в фоне происходит проверка орфографии. Код проверки текста обычно обслуживается отдельным потоком, также специально для этого предназначенным. Вы смотрите на окно музыкального плеера. Музыку играет отдельный поток. А визуализацию (например, спектр сигнала) рисует другой поток.  Многие даже не задумываются, насколько непросто «сделать красиво». И только мрачные программисты знают всю правду Существуют и более сложные примеры. Так, в операционных системах реального времени (RTOS) с помощью механизма вытесняющей многопоточности определяют важность реагирования и обслуживания того или иного события во внешнем мире (речь при этом идет о приоритетах исполнения того или иного потока). Еще раз замечу, что технология многопоточности была придумана очень давно и тогда же отлично себя зарекомендовала. На уровне программы, выполняющей несколько потоков, абсолютно все равно, сколько реальных физических ядер в компьютере, на котором она в данный момент выполняется. Количество физических ядер в процессоре сказывается лишь на одном факте — сколько разных потоков одновременно (по-честному одновременно!) система может исполнять в один момент времени. Если ядро у вас только одно, а потоков, которые необходимо исполнять, много, ОС создает иллюзию того, что эти потоки выполняются одновременно. Делается это самым банальным образом — какой-то небольшой промежуток времени (обычно порядка 50-100 мс) выполняется один поток, потом на точно такой же промежуток времени управление передается другому потоку и так далее. Если ядер у нас N, то наблюдается аналогичная картина — потоки по очереди выполняются на всех доступных ядрах. При этом надо помнить, что процесс переключения с потока на поток отнюдь не «бесплатен», и сам факт такого переключения снижает общий КПД потоков.  Интересная задачка для иностранных маркетологов: рассчитать — сколько эквивалентов мощности компьютера AGC, обслуживавшего первый полет человека на Луну, умещается в четырехъядерном кристалле Sandy Bridge при полном использовании его потенциала Для чего программисты в своих приложениях используют потоки естественным образом, я написал выше, а сейчас хотел бы рассказать, как на практике распараллеливаются изначально линейные (монолитные) задачи. Представим себе, что необходимо решить следующую задачу: посчитать среднюю температуру (нет, не по больнице) воздуха за последние 100 дней (и не спрашивайте меня, зачем программистам дают такие глупые задания!). Наши исходные данные (сотня значений температуры) хранятся в массиве. Для прогульщиков информатики объясняю: массив — это такой упорядоченный набор данных, где по индексу (фактически, порядковому номеру элемента массива) можно получить значение этого элемента. Если наш массив называется temperatures, то temperatures[1] даст нам первое значение, а temperatures[100] — соответственно — последнее. Все, что нам нужно сделать, чтобы решить эту очень сложную задачу, это просуммировать все значения в массиве и разделить их на 100 (именно так считается, если что, среднее арифметическое). В коде это будет выглядеть примерно так: temperatures[100] (по слухам, в этом массиве лежат наши значения температуры) Теперь представим себе, что мы хотим решить нашу задачу в два потока. Мы должны написать что-то в таком роде: temperatures[100] (вы должны помнить, что это такое, из предыдущего примера) Спешу вас обрадовать! Если вы поняли хотя бы треть из вышеприведенной абракадабры, то, при внезапном увольнении с текущей работы, с голода вы точно не помрете — можете смело идти работать программистом 1С! Еще раз пробежимся по второму примеру (только не говорите, что вы не поняли даже первый). Смысл в том, что мы запускаем расчет суммы массива в два разных потока, один считает сумму первой половины массива (первые 50 элементов), второй — сумму второй половины (мне подсказывают, это элементы с 51-го по сотый). Теперь самое интересное. Программа будет работать равноуспешно на системе с любым количеством ядер. В случае если у вас всего лишь одно ядро, то программа будет работать чуть хуже, чем наш первый однопоточный вариант. Зато если у вас два ядра, то — теоретически — задачу вы посчитаете в два раза быстрее, так как в системе появляется два потока (главный поток, создавший эти два потока-задания, ложится спать, ожидая окончания выполнения потоков), каждый из которых можно отдать на исполнение физическому ядру процессора, то есть выполнять их одновременно. PROFIT!  Еще в мае прошлого года Intel показывала работающий прототип 48-ядерного процессора с архитектурой x86, которому вполне хватало воздушного охлаждения. То-то простора для программистских экспериментов! Перед тем как выполнять все эти скучные температурные расчеты, вы можете спросить у операционной системы, на которой в данный момент работает ваша программа, а сколько, собственно, процессорных ядер у нее за душой? Она говорит — ядер у нас N. Тогда вы разбиваете исходный массив на N частей, считаете его в N потоков и тем самым загружаете процессор полностью! (Поздравляю! Теперь вы 1С-программист, который еще и умет писать эффективные многопоточные приложения!) Но шутки в сторону! Практическая часть этой заметки подошла к концу, и мы с вами переходим к заключительной части. ⇡#Ложка дегтяНа первый взгляд, даже измученному сессией студенту-филологу может показаться, что писать программки для метеорологов, на 100% использующие возможности современных многоядерных процессоров, проще простого. Огорчу вас. Это, мягко говоря, не так. Во-первых, само по себе многопоточное программирование довольно сложная и коварная штука, и у многих программистов есть проблемы с возможностью представить себе в голове, как программа будет работать на самом деле. Вследствие этого, многопоточные приложения обычно подвержены появлению в них очень тонких и неочевидных ошибок, которые трудно воспроизвести и обнаружить (любознательные бегут в поисковик с запросами deadlock и race condition). Момент второй — переход от линейного решения задачи к многопоточному его варианту, который был бы при этом еще и эффективнее линейного, чаще всего есть весьма и весьма нетривиальная задача. Код такого решения почти всегда объемнее и сложнее линейного кода, а значит его дольше писать, сложнее отлаживать и дороже сопровождать. Более того, в мире существует огромное число задач, которые крайне неохотно поддаются распараллеливанию (даю подсказку, это такие, где каждый последующий шаг вычисления жестко завязан на результат работы предыдущего).  В общем, умение писать хорошо масштабирующие по количеству ядер программы — это целое искусство. Лучшие умы человечества бьются над тем, чтобы упростить написание подобного рода программ. К примеру, есть целый класс языков программирования (так называемые функциональные языки), код на которых автоматически можно выполнять на любом количестве ядер. Одна проблема — языки эти довольно специфичны, они не очень хорошо подходят для решения целого ряда задач, и их доля на рынке колеблется в районе жалких пары процентов. Замечу, что, в противоположность экзотическим функциональным языкам программирования, существует целый ряд современных и популярных языков, которые вообще не поддерживают эффективную многопоточную модель. Например, к таким относится Python и Ruby.  Наверное, непросто будет устоять, когда такие красивые орудия маркетологов начнут убеждать нас в необходимости многоядерного смартфона? А теперь хотелось бы вернуться к тому, с чего я начал этот материал — к теме двухъядерных мобильных устройств. Почему производители начали растить свои процессоры вширь, а не в высоту, я подробно описал в первой части, теперь надо объяснить — почему по этой же проторенной дорожке вынуждены пойти производители мобильных решений. Как мы знаем, потолок частоты, которого достигли сегодня в мобильных одноядерных системах с ядром ARM, чуть больше 1 ГГц. Вроде бы не так много, по меркам 3+ ГГц, за которые мы шагнули на десктопах. Однако в мобильном мире есть два важных нюанса, предопределивших переход на многоядерность именно на этом рубеже. Первое — вопрос охлаждения. Мало того, что вы не можете использовать кулеры внутри корпуса современного смартфона, толщина которого составляет каких-то 10 мм, вы даже более-менее солидный радиатор вряд ли уместите.  Начинка двухъядерного смартфона LG нуждается в весьма внушительном по мобильным меркам радиаторе Второе — энергопотребление. Тут постоянно ищется баланс между мощностью процессора и потребляемой мощностью. Повышать частоты на текущем витке технологических возможностей означает, что ваш любимый «гуглофон» будет умирать не через 6 часов активного использования, а через каких-то жалких два. В общем, от прогресса никуда не убежишь — добрый дедушка Мур исправно дает каждые два года новую порцию транзисторов, и производители мобильных решений решили использовать ее для реализации второго ядра общего назначения (помимо всего прочего, немалая часть этих тразисторов в современных SoC идет на GPU, который, как мы помним, масштабируется куда как веселее).  Фантазируя по поводу смысла появления многоядерности в мобильных устройствах, маркетологи иногда придумывают совсем уж странные задачи, вроде транслирования HD-картинки с планшетного ПК на телевизор… Что же нам дает появление второго ядра в смартфонах? Честно говоря, не так уж и много. Точно так же, как и на десктопе, где обычно востребованы жалкие пара процентов от потенциальной мощности вашего четырехъядерного монстра, в мобильном мире есть очень узкий класс задач, где действительно нужны такие вычислительные ресурсы. Кроме хардкорных игр, честно говоря, даже мало что приходит на ум. Потому что даже задача кодирования/декодирования видео в высоком разрешении очень часто решается специализированным декодером, а не усилиями центрального процессора. А если вспомнить главную программу любого современного смартфона — браузер, то и тут есть много узких и неудобных мест, которые не дадут многоядерности сказать свое веское слово. К примеру, используемые сегодня JavaScript-движки многопоточность не поддерживают.  Второе ядро может пригодиться в смартфоне, если его владелец увлекается так называемой «дополненной реальностью». Есть люди, которые полагают, что появление второго ядра скажется на плавности работы и общей отзывчивости системы. Тут тоже есть свои нюансы. К примеру, общеизвестно, что Android OS страдает регулярно возникающими лагами в работе. Многие специалисты полагают, что вызваны они явлением под названием «сборка мусора» (это когда работа приложений приостанавливается для того, чтобы специальный механизм привел в порядок их динамическую память). Можно рассуждать так — раз у нас два ядра, то одно ядро будет заниматься сборкой мусора, а второе в это время будет себе работать дальше! Никаких лагов! На практике, написать хороший алгоритм сборки мусора так, чтобы во время его активности приложение продолжало работать дальше без потери производительности, — не такая уж тривиальная задача (аналогия — трудно переставлять в комнате мебель и одновременно делать в ней уборку). Некий concurrent garbage collector появился в Android 2.3, но пока трудно сказать — насколько он хорош в деле. Есть сильное ощущение, что на двух ядрах в смартфонах лежит толстый-толстый слой маркетинга, как в свое время на 64-битности процессоров Athlon 64. Когда таковая стала действительно востребованной, процессоры уже успели безнадежно устареть…  Нашумевший двухъядерный Motorola Atrix 4G основную часть времени работает смартфоном, но если владелец раскошелится на недешевую док-станцию, может превратиться в смартбук. Правда, пока трудно судить — насколько востребованным окажется такое решение ⇡#Сухой остатокЕсли кто не понял, то статья эта была о том, как трудно живется программистам после того, как их подставили нехорошие производители процессоров. Кроме шуток. Мы вступили в эпоху, когда разработчики игр для современных (читай — многоядерных) консолей выступают с большими докладами, суть которых сводится к тому, как, не слишком уродуя код, решить проблемы «modern hardware restrictions». Может быть, я наивен и старомоден, но мне всегда казалось, что прогресс должен снимать с разработчиков ограничения, а не наоборот (подробнее можно почитать, к примеру, здесь). К сожалению, рост процессоров в ширину, который до прихода на десктопы хорошо себя зарекомендовал в области серверных решений (потому что там постоянно нужно обслуживать несколько клиентов), на мирных компьютерах и в мобильной области в некотором смысле знаменует собой эпоху застоя и проблем, связанных с выбрасыванием старых подходов к решению задач, переучиванию квалифицированных специалистов и переписыванию большого количества существующего кода. Закон Мура все еще работает, но ощущаем ли мы это? P.S. Мы попросили прокомментировать этот материал представителя Intel Дмитрия Оганезова, менеджера сообщества Intel Software Network (http://software.intel.com/ru-ru/). Отдавая должное автору, рассказавшему в рамках одной статьи о значительной части проблем компьютерной индустрии, я бы все-таки не согласился со сделанными им выводами. И, в силу своей природной мягкости, изменил бы формулировку «эпоха застоя и проблем» на нечто более оптимистичное вроде «затишье перед бурей». Попробую обосновать свою точку зрения.  Вот уже лет пять, как частота процессоров замерла в районе 3 гигагерц (о, ужас!). Почему так вышло? Мы все еще не оставили надежду на то, что статью действительно прочитали несколько гуманитариев, а попытка объяснить сей феномен «на пальцах» может отпугнуть и их… Тем не менее, это поможет нам посмотреть на всю картину в целом. Итак, рост частоты интегральных микросхем ограничен не только и не столько потребляемой мощностью — эту проблему производители научились решать применением более «тонких» технологических процессов. К сожалению, есть еще одна загвоздка: современный процессор представляет собой крайне сложное устройство, некоторые модели содержат больше миллиарда транзисторов. Физические процессы, которые происходят при работе такого количества транзисторов на высоких частотах, неизбежно приводят к некоторым помехам (наводкам) внутри схемы, а как следствие — проблемам со стабильностью в целом. Очевидно, что простого и эффективного решения этих проблем на данный момент не существует. Что же делать? К счастью, на помощь приходит как раз пресловутая возможность совершенствовать техпроцесс. Это значит, что при той же тактовой частоте и потребляемой мощности можно делать процессоры с большим количеством транзисторов. Возникает резонный вопрос — как лучше использовать эти «лишние» транзисторы? Хорошая новость заключается в том, что значительное количество «бесплатных» транзисторов попадают в те блоки процессора, которые не связаны напрямую с «многоядерностью», как например блоки SSE/AVX, а также в кеш-память различных уровней. Это дает возможность повышать производительность процессора на десятки процентов от модели к модели при том же количестве основных вычислительных ядер.  Таким образом, те программисты, которые пока не осилили принципы параллельного программирования, могут быть спокойны: запаса «последовательной» производительности хватит еще надолго. Кроме того, как подсказывает практика, целый класс алгоритмов так и будет существовать только в том или ином последовательном виде. Тем же, кому действительно нужен существенный рывок в скорости, стоит отбросить смутные сомнения и приступать к распараллеливанию. Да, это не так просто. Но давайте вспомним, как оконные пользовательские интерфейсы и функциональная сложность программ прикончили структурное программирование и послужили началом великой эпохи ООП… К тому же, при всей своей сложности, параллельная парадигма, пожалуй, на данный момент является… наиболее простой из всех существующих парадигм. Вполне возможно, что мы стоим на пороге новой великой эпохи, а уж будет ли она эпохой параллельного программирования, или эпохой неоднородных вычислений, или еще какой-то там новой эпохой — покажет время. И само по себе наличие выбора никак не позволяет мне назвать нашу эпоху «эпохой застоя».
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











