|
Опрос
|
реклама
Быстрый переход
Приложение «Фотографии» в Windows 11 получит большое обновление, основанное на ИИ
25.03.2025 [18:18],
Сергей Сурабекянц
Приложение «Фотографии» в Windows 11 скоро пополнится новыми инструментами на базе ИИ. Microsoft в настоящее время тестирует обновление, которое добавляет кнопку Copilot и ярлыки для инструментов ИИ в контекстное меню «Проводника» и возможность поиска в интернете по распознанному тексту. Также появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. 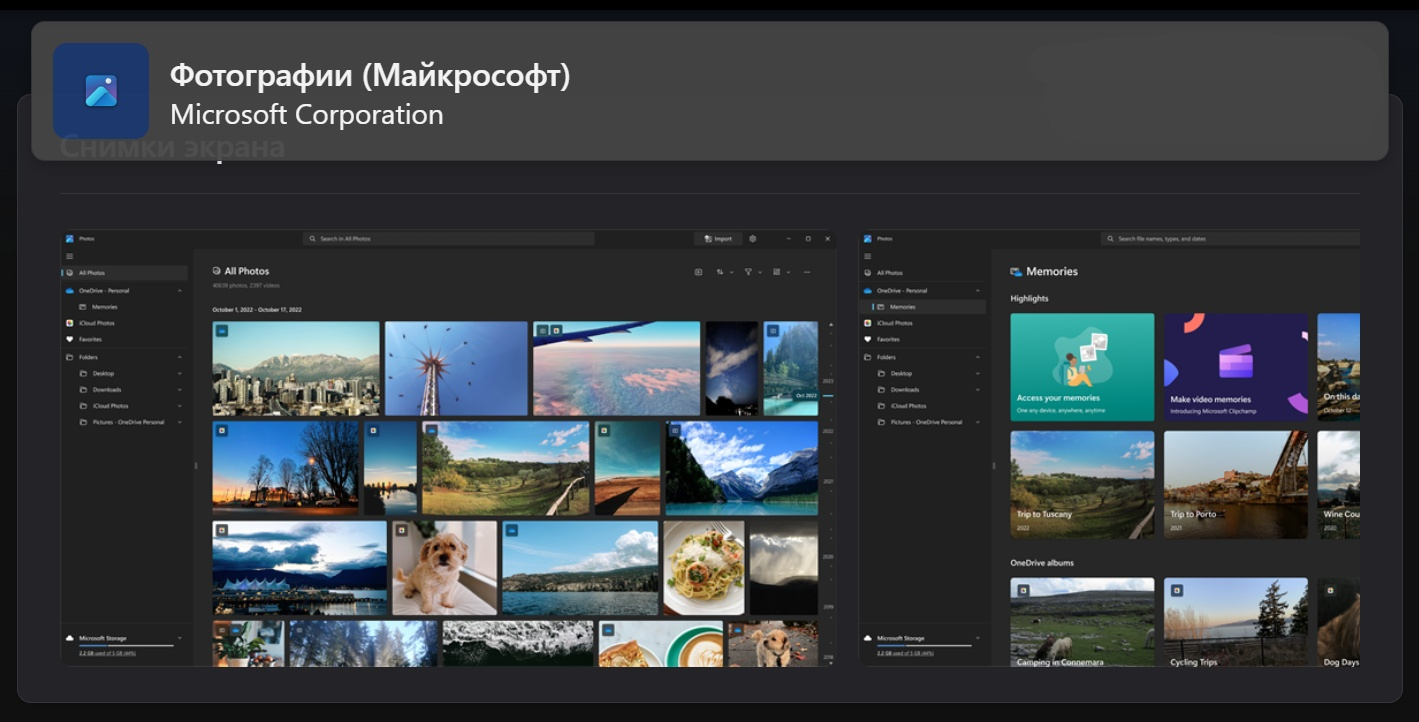
Источник изображений: Microsoft Участники программы Windows Insider в канале Release Preview получили возможность протестировать несколько новых функций на основе ИИ. Многие из этих функций уже некоторое время находятся в разработке, но их появление в канале Release Preview говорит о скором появлении в общедоступной стабильной версии системы. Microsoft запланировала мероприятие, посвящённое ИИ, на 4 апреля 2025 года, приурочив его к 50-летию компании. Ожидается презентация новых функций ИИ для Windows 11 и приложений Microsoft. В конце января для участников программы Windows Insiders в Windows 11 и Windows 10 в приложении «Фотографии» появилась функция оптического распознавания символов (OCR), поддерживающая более 160 языков. Для распознавания текста достаточно нажать кнопку «Сканировать текст» в приложении. Теперь стало возможным использовать функцию «Поиск в интернете», чтобы найти распознанный текст прямо из приложения. Такой подход упрощает извлечение и поиск онлайн-результатов текста из документов, заметок, снимков экрана и других изображений. Microsoft добавила новые ярлыки для инструментов ИИ в «Проводник». Они обеспечивают быстрый доступ к редактированию при помощи ИИ и визуальному поиску без необходимости открывать приложение «Фотографии». Теперь достаточно щёлкнуть правой кнопкой мыши изображение в «Проводнике», чтобы добавить форматированный текст, настроить композицию с помощью выбора объекта или улучшить цветопередачу. Ярлык «Стереть объект» позволяет быстро удалить нежелательные элементы. А «Визуальный поиск с помощью Bing» быстро находит похожие изображения и связанные продукты. В галерее приложения «Фотографии» появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. Функция «Показать вложенные папки» показывает в галерее все изображения и видео из вложенных папок, что может в некоторых случаях упростить навигацию. В верхней части приложения «Фотографии» добавлена выделенная красным кнопка Copilot, которая при помощи ИИ позволяет:
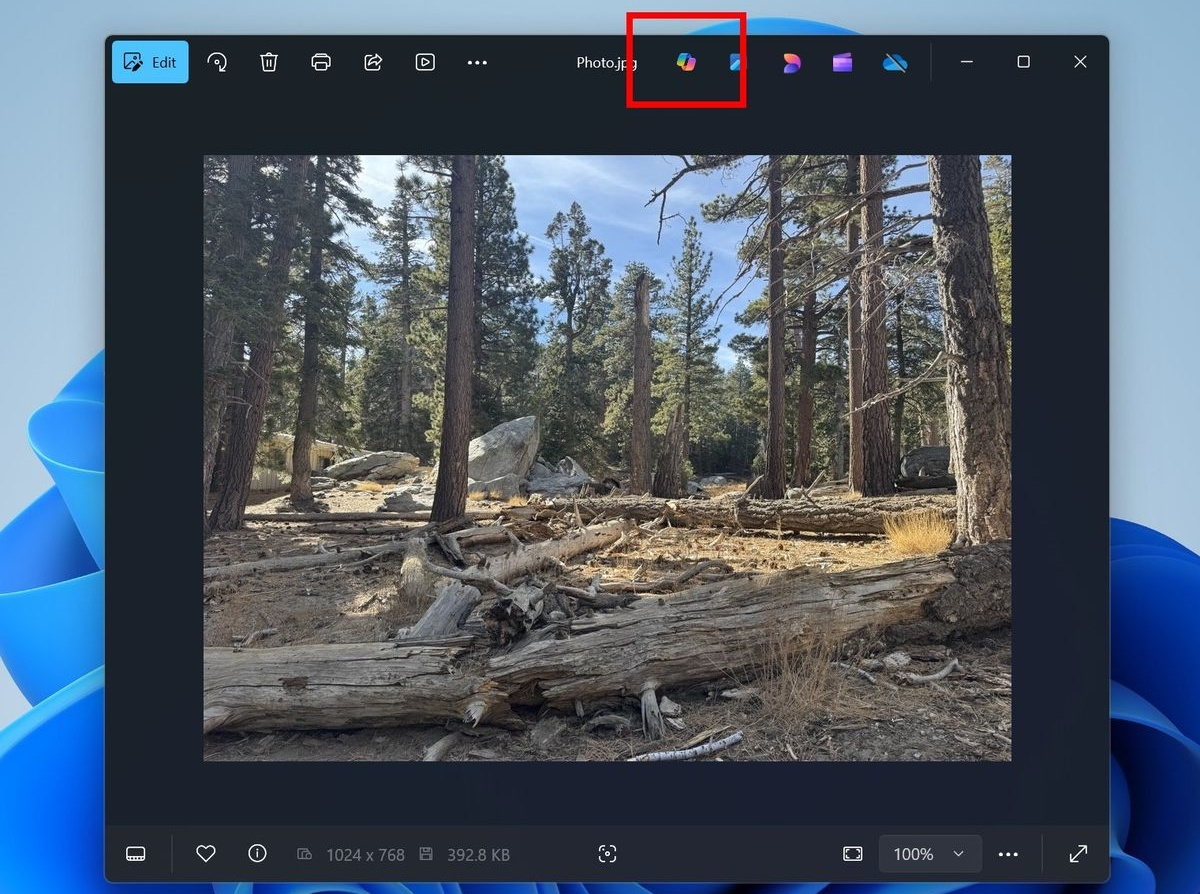 Из других изменений стоит упомянуть добавленную в приложение поддержку файлов формата JXL. Приложение «Фотографии» вряд ли сможет составить конкуренцию таким программным монстрам для редактирования изображений, как Photoshop или CorelDraw, но будет весьма полезным для быстрого внесения незначительных изменений без дополнительных затрат и подписок. Российские специалисты из Smart Engines расшифровали рукописи Пушкина при помощи ИИ
06.02.2025 [17:59],
Сергей Сурабекянц
Специалисты российской компании Smart Engines расшифровали зачёркнутые фрагменты черновых рукописей Александра Пушкина с помощью разработанной ими системы искусственного интеллекта «Да Винчи». Нейросетевая архитектура «Да Винчи» широко используется для распознавания документов, в частности российских паспортов, вне зависимости от угла и условий съёмки. 
Источник изображения: Wikipedia, «Литературные места России» В процессе обучения ИИ запомнил, какие движения пера в незачёркнутых словах характерны для почерка великого русского поэта, а затем восстановил утраченные места, пользуясь созданной моделью движений его руки. Таким способом удалось идентифицировать несколько неопределяемых ранее слов из черновых рукописей Пушкина. Эти находки внесли существенный вклад в понимание творческого процесса поэта. Узнать, какие слова пришлись Пушкину не по душе, удалось с помощью нейросетевой архитектуры «Да Винчи», разработанной специалистами Smart Engines для удаления линий разграфки, затрудняющих распознавание рукописных данных в официальных документах. Эта технология позволяет автоматически определять геометрию документа и распознавать данные вне зависимости от его расположения в кадре, наличия помех и искажений. Технология одинаково успешно справляется как со сканами, так и с фотографиями документов, в том числе в зеркальном отражении. Алгоритмы Smart Engines уже интегрированы в решения для мгновенного распознавания данных паспорта и других документов. Распознавание паспорта РФ при помощи камеры смартфона требует всего 0,15 секунды. Серверные решения позволяют распознавать до 55 паспортов в секунду на процессор без использования GPU. 
Источник изображения: Smart Engines «Проведённый нами эксперимент по расшифровке ранее нечитаемых слов в рукописях Александра Пушкина подтвердил колоссальный потенциал нейросетей в самых разных областях науки. Мы видим, что искусственный интеллект может стать надёжным инструментом для исследователя […] Предложенный метод снятия зачёркиваний при помощи ИИ может быть применён не только к рукописям Пушкина, но и к архивным записям других известных авторов, а также историческим документам. Это открывает новые возможности для изучения творческого процесса написания знаменитых литературных произведений», — уверен генеральный директор Smart Engines Владимир Арлазаров. Остаётся неясным лишь одно: если великий русский поэт какие-то слова зачёркивал, возможно, он не хотел, чтобы кто-нибудь их прочитал, в том числе и искусственный интеллект? |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



