|
Опрос
|
реклама
Быстрый переход
Вторичный рынок завалило заблокированными за пиратство Nintendo Switch 2
19.06.2025 [20:03],
Сергей Сурабекянц
Nintendo применяет жёсткие меры к владельцам Switch 2, которые пытаются использовать пиратские копии игр или нарушают условия использования. При выявлении манипуляций приставка начинает показываешь ошибку с кодом 2124-4508 и не позволяет использовать онлайн-сервисы Nintendo, фактически блокируя немалую часть функций устройства. На этом фоне особенно опасно покупать подержанные консоли, так как чаще всего заманчивая цена предвещает уже «окирпиченную» приставку. 
Источник изображения: X / @SwitchTools Многие владельцы Switch 2 сообщают о частичном выходе консоли из строя после попытки использовать картридж MiG Switch. Эти картриджи можно применять для запуска как пиратских, так и резервных копий законно купленных игр. Nintendo считает оба варианта использования нарушением своих условий использования и не делает различий между ними при блокировке консоли. По этой причине вероятность выхода из строя подержанных консолей Switch 2 особенно высока. В интернете уже растёт число сообщений о том, что купив приставку с рук пользователи наткнулись на ограниченную в функциях консоль. И сделать с этим сейчас ничего нельзя. Так что, по всей видимости, число подобных жалоб будет только расти. В настоящее время нет возможности снять блокировку консоли, поэтому перед покупкой необходимо включить игровую приставку и проверить, может ли она подключаться к серверам Nintendo. Если протестировать консоль самостоятельно нет возможности, лучше отказаться от такой сделки. 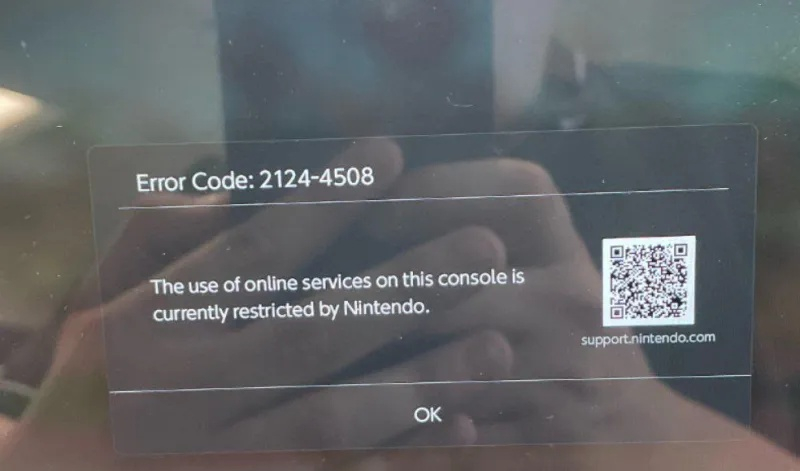
Источник изображения: X / @SwitchTools Стоит отметить ещё один неприятный момент при покупке с рук комплекта Nintendo Switch 2 и игры Mario Kart World (в фирменном магазине цена консоли — $449, а комплекта — $495). Поскольку комплектная игра представлена кодом загрузки, приобретение комплекта из вторых рук, скорее всего, оставит покупателя без возможности загрузки игры, даже если консоль не заблокируется. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



