|
Опрос
|
реклама
Быстрый переход
Gemini научился обрабатывать комментарии в «Google Документах»
29.07.2026 [19:04],
Павел Котов
Google активно развивает возможности помощника с искусственным интеллектом Gemini в своём пакете офисных приложений. Он уже умеет генерировать изображения, диаграммы и инфографику, а теперь компания обучила его работе с комментариями в «Google Документах». 
Источник изображения: Rubaitul Azad / unsplash.com Gemini научился читать, понимать и предпринимать действия на основе комментариев в документах. Теперь он может создавать сводки на основе комментариев, определять ключевые темы, последовательности действий и выявлять нерешенные вопросы, которые не позволяют продолжать работу над проектами. Он также получил возможность добавлять от имени пользователя новые комментарии и оставлять отзывы к документам в формате комментариев. Ещё одна функция — публикация ответов на открытые ветки комментариев в документах и вложение файлов из «Google Диска» в ответы. Gemini умеет просматривать комментарии в документах и предлагать изменения с учётом отзывов. ИИ-помощник не публикует комментариев или ответов автоматически и не вносит изменений в документы самостоятельно. Но он формирует черновики ответов или правок, а пользователь выбирает, продолжать ли Gemini работу. Доступ к новым функциям открывается через боковую панель Gemini в «Google Документах» или через нижнюю панель с логотипом Gemini. ИИ также может порекомендовать пользователю разрешить составить сводку или автоматически опубликовать ответ в открытой ветке комментариев. Новые функции пока доступны только пользователям платных тарифных планов. Аудитория Google Gemini приблизилась к миллиарду пользователей
24.07.2026 [15:11],
Павел Котов
Вскоре Google добавит ещё одно наименование в свой список продуктов, у которых более миллиарда пользователей — сейчас в нём значатся «Поиск», Gmail, «Диск», Android, YouTube и Chrome. Месячная аудитория помощника с искусственными интеллектом Gemini достигла 950 млн пользователей, сообщила компания после финансового отчёта по итогам II квартала 2026 года. 
Источник изображения: Rubaitul Azad / unsplash.com По сравнению с прошлым годом число пользователей Gemini утроилось; в феврале компания сообщала о преодолении отметки в 750 млн пользователей. Таким образом, помощник от Google становится грозным конкурентом OpenAI ChatGPT, который достиг отметки в 1 млрд ежемесячно активных пользователей лишь в июне. «Пользователям нравятся новые функции, такие как Daily Brief и наш персональный помощник, который теперь доступен в США и по всему миру. Мы выпускаем полезные новые функции с невероятной скоростью», — заявил в ходе телефонной конференции гендиректор Google Сундар Пичаи (Sundar Pichai). Приложение Gemini набрало сильную пользовательскую базу не только за счёт Android, но и за счёт Apple iOS, у пользователей которой популярен генератор изображений Nano Banana. За последние 12 месяцев приложение для iOS скачали более 137 млн раз. Рыночная доля ChatGPT среди ИИ-помощников впервые упала ниже 50 %, а доля Gemini выросла до 27,7 %, гласят данные Sensor Tower. ИИ-помощники всё чаще выступают как замена традиционному веб-поиску, но поисковое направление, по версии самой Google, процветает, хотя и не без участия новых функций ИИ. Аудитория поискового «Режима ИИ» в минувшем квартале превысила 1 млрд пользователей, что приводит к «постепенному увеличению» поисковых запросов. Собственные аппаратные решения Google помогли ей снизить стоимость обслуживания новых функций и моделей. Gemini 3.5 Pro снова не вышла: Google представила облегчённые Gemini 3.6 Flash и Flash-Lite
21.07.2026 [20:29],
Анжелла Марина
Google представила модели Gemini 3.6 Flash и Gemini 3.5 Flash-Lite, одновременно сообщив о ходе разработки Gemini 3.5 Pro и следующего поколения моделей Gemini 4. Новинки уже доступны в приложении Gemini, а разработчики могут получить к ним доступ через Google Antigravity, AI Studio и Android Studio. 
Источник изображений: Google Gemini 3.6 Flash стала развитием версии, представленной на конференции I/O 2026, и была доработана с учётом отзывов разработчиков и клиентов. Как компания отметила в своём блоге, модель стала эффективнее использовать токены, расходуя на 17 % меньше выходных токенов по сравнению с Gemini 3.5 Flash, а также требует меньше этапов рассуждения и обращений к инструментам при выполнении последовательного ряда действий. Одновременно была снижена стоимость использования модели. Цена составила $1,50 за 1 млн входных токенов и $7,50 за 1 млн выходных токенов. 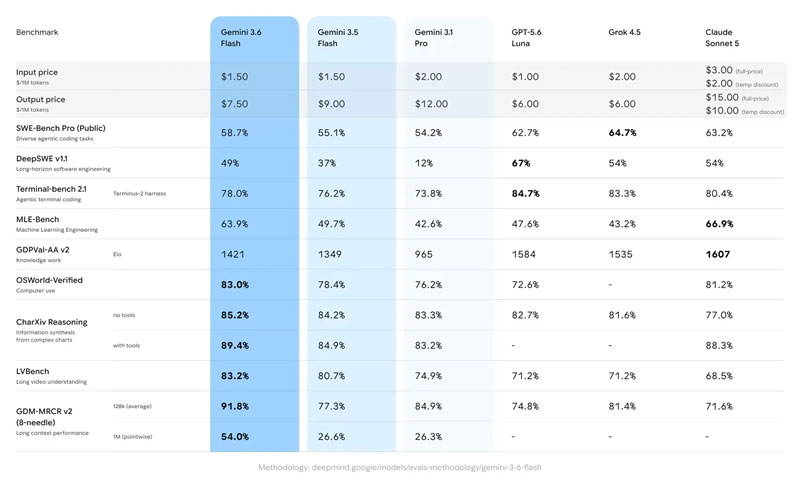 Gemini 3.6 Flash также улучшила по сравнению с Gemini 3.5 Flash показатели в задачах программирования, повысив точность генерации кода и сократив количество нежелательных изменений. Кроме того, модель продемонстрировала более высокие результаты в тестах DeepSWE (49 % против 37 %) и MLE Bench (63,9 % против 49,7 %), а в категориях, требующих специальных знаний, получила 1421 балл по шкале GDPval-AA (против 1349). 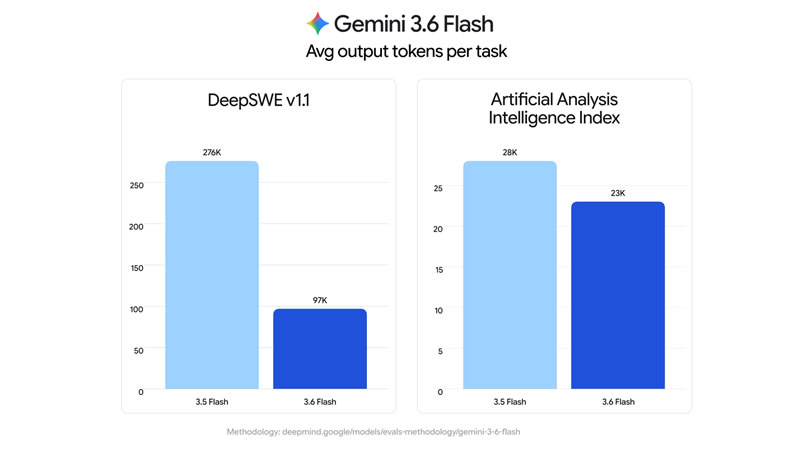 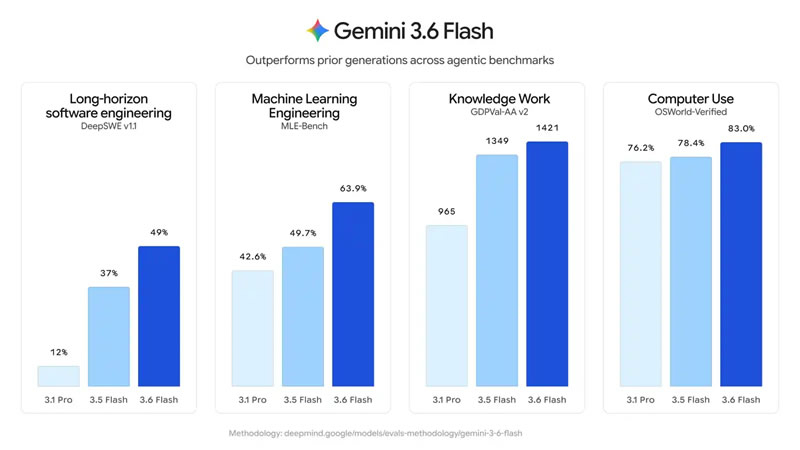 Одновременно Google представила Gemini 3.5 Flash-Lite, ориентированную на задачи с высокой пропускной способностью и минимальными задержками, включая агентный поиск и обработку документов. По заявлению компании, новая модель обеспечивает более высокое качество по сравнению с Gemini 3.1 Flash-Lite и превосходит Gemini 3 Flash в ряде тестов, сохраняя при этом более низкую стоимость использования. 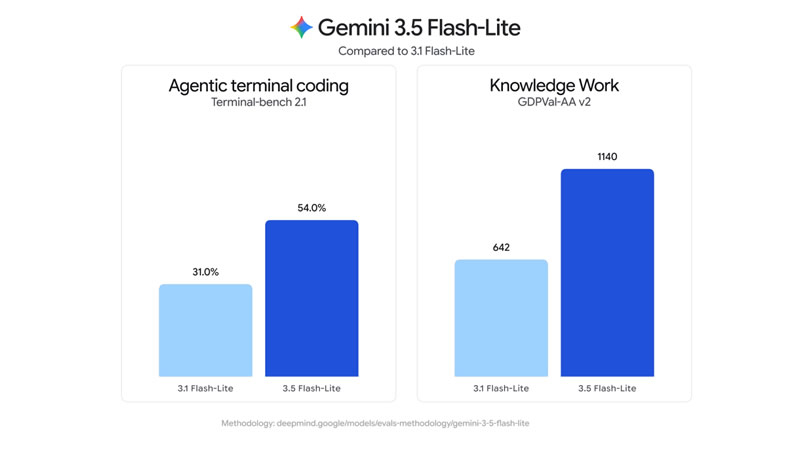 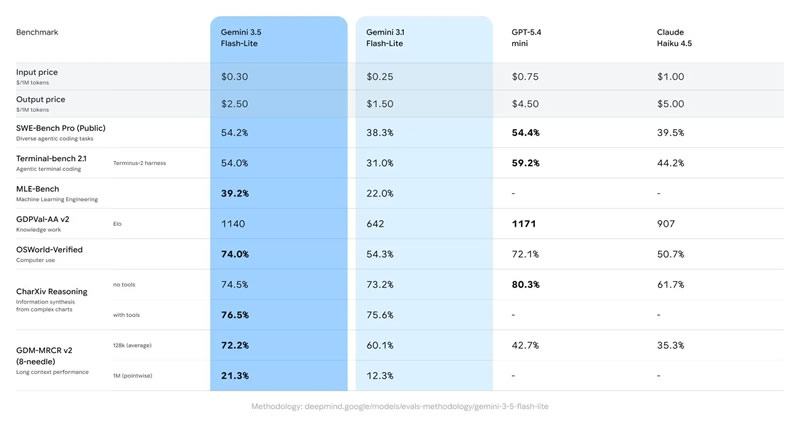 Также анонсирована специализированная модель Gemini 3.5 Flash Cyber, предназначенная для поиска и устранения уязвимостей в программном коде. На её основе работает CodeMender, использующий несколько ИИ-агентов для выявления, проверки и исправления проблем безопасности. 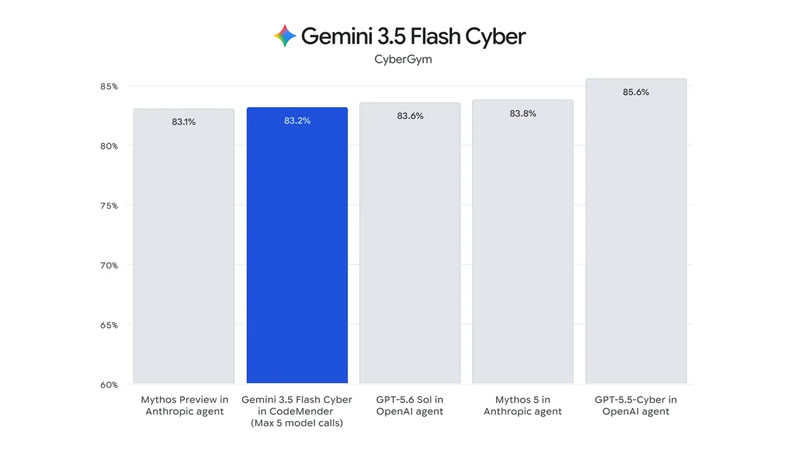 На первом этапе доступ к инструменту получат государственные организации и доверенные партнёры в рамках программы ограниченного тестирования. Одновременно команда DeepMind сообщила, что уже начала наиболее масштабный этап подготовки к запуску модели Gemini 4. Google разрабатывает чип Frozen v2, на котором модели Gemini смогут работать эффективнее
20.07.2026 [19:04],
Сергей Сурабекянц
Согласно появившейся инсайдерской информации, Google в настоящее время разрабатывает серверный чип, который будет поддерживать элементы модели Gemini на аппаратном уровне. Компания ожидает, что этот чип с неофициальным названием Frozen v2 поможет решить проблему нехватки вычислительных мощностей для ИИ, которая вызвала внутренние разногласия и заставила Google Cloud отказаться от сделок с внешними клиентами. Акции компании в начале торгов выросли на 3,3 %. 
Источник изображения: unsplash.com По словам разработчиков, проект Frozen направлен на создание нового набора собственных чипов, отличных от тензорных процессоров Google (TPU), а не на их замену. Google планирует начать развёртывание новых чипов уже в 2028 году, хотя инженеры все ещё дорабатывают его дизайн. Предполагается, что новый чип может оказаться в 6-10 раз эффективнее, чем новейшие специализированные чипы Google для ИИ, исходя из количества токенов на единицу мощности. «Наши команды постоянно исследуют и экспериментируют с новыми разработками... Благодаря совместной разработке нашего оборудования и программного обеспечения с нуля, мы обеспечиваем интеграцию и высокую оптимизацию наших систем», — заявил представитель Google Cloud. Тем не менее, на прошлой неделе Google отложила запуск своей последней модели Gemini AI после того, как она не оправдала внутренних ожиданий, и продолжила работу над улучшением её возможностей, особенно в области программирования. Google запретит Gemini обращаться к приложениям без разблокировки экрана на Android
17.07.2026 [17:24],
Павел Котов
Google пообещала исправить ошибку в Android из-за которой любой желающий мог, завладев заблокированным смартфоном, даже не зная PIN-кода, обращаться к помощнику с искусственным интеллектом Gemini для оправки SMS или сообщений в WhatsApp. 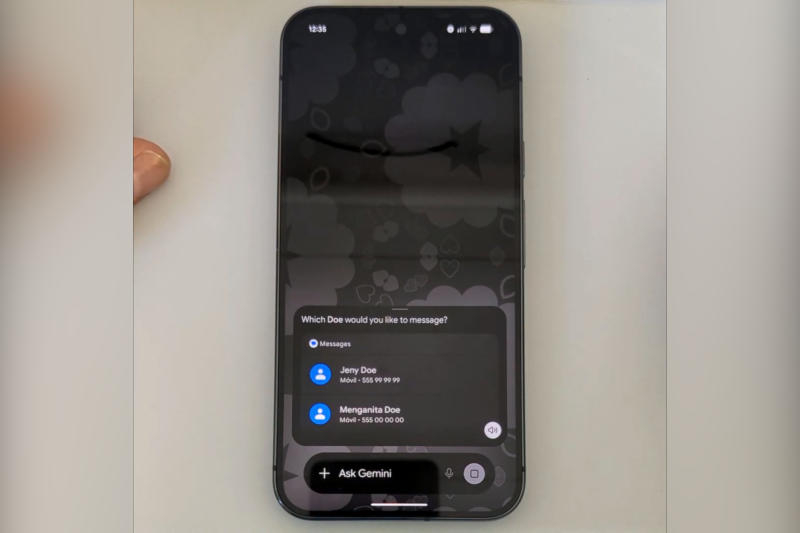
Источник изображения: youtube.com/@videosdebarraquito Проблема актуальна для Android 16. Неаутентифицированный пользователь, получивший физический доступ к устройству, используя особую мультисенсорную жестовую команду на заблокированном экране, получает доступ к таким функциям как телефон, отправка SMS или сообщений в WhatsApp. Если пользователь блокирует доступ Gemini к определённым приложениям, например, к «Google Сообщениям», а гипотетический злоумышленник впоследствии пытается отправить SMS через Gemini прямо с экрана блокировки, чат-бот предлагает открыть соответствующее приложение. Далее предлагается опция «Продолжить» и ввод PIN-кода для доступа к приложению — и если нажать кнопку «Продолжить» одновременно с кнопкой «Добавить вложение» в строке Gemini, то SMS отправляется и без ввода PIN-кода. Далее можно получить через Gemini доступ и к другим приложениям, заблокированным для ИИ-помощника, указав соответствующий запрос. Например, доступ к WhatsApp открывается, если в поле Gemini ввести «@WhatsApp» — PIN-код снова не требуется. Чтобы воспользоваться уязвимостью, требуется физический доступ к устройству, и в большинстве случаев реализовать это в реальных сценариях не так просто. С другой стороны, гипотетический злоумышленник получает возможность отправлять SMS от имени жертвы, и недооценивать такую угрозу опасно. Google известно об этой ошибке, и исправление выйдет в обновлении на этой неделе, заявили в компании ресурсу The Register. На устройствах Pixel этот способ обхода блокировки не работает, подчеркнули в компании; поступали сообщения, что ошибка не воспроизводится и на устройствах Samsung; но список производителей, для продукции которых проблема актуальна, не приводится. Google не успевает за конкурентами: релиз Gemini 3.5 Pro задерживается на месяцы
17.07.2026 [14:48],
Владимир Фетисов
Компания Google на несколько месяцев отстаёт от графика развёртывания Gemini 3.5 Pro — своей наиболее производительной флагманской ИИ-модели. Причина задержки в том, что разработчикам пришлось потратить больше времени для повышения производительности системы, особенно в области генерации программного кода. 
Источник изображения: blog.google По данным Bloomberg, бывшие и действующие сотрудники Google сообщили, что эта задержка вызывает разочарование среди инженеров Google, исследователей в области ИИ и топ-менеджеров, многие из которых опасаются, что компания рискует потерять преимущество на рынке, поскольку основные конкуренты, такие как Anthropic и OpenAI, выпускают ИИ-модели, превосходящие Gemini по возможностям. Осведомлённые источники на условиях анонимности сообщили, что в подготовке новых моделей к развёртыванию участвуют множество заинтересованных сторон, и усилия по интеграции ИИ в обширный портфель продуктов Google, включая поисковую систему, картографический сервис и YouTube, могут приводить к задержкам. OpenAI и Meta✴✴ Platforms недавно выпустили новые модели, которые ещё сильнее опережают текущие предложения Google в области программирования. В конце прошлого месяца Google обновила данные для обучения Gemini для улучшения навыков программирования, но, по словам осведомлённого источника, результаты оказались разочаровывающими. На этом фоне стоимость акций компании в четверг снизилась на 3,2 %. «Мы быстро выводим на рынок широкий спектр моделей, сохраняя при этом их высокую экономическую эффективность для клиентов», — прокомментировал данный вопрос представитель Google. Ожидалось, что Google объявит о запуске Gemini 3.5 Pro на своей майской конференции для разработчиков. Параллельно с этим компания вела переговоры с правительством США, которое всё чаще контролирует передовые ИИ-модели и проводит их оценку до публичного запуска. «В настоящее время мы тестируем 3.5 Pro, обновлённую модель Flash и другие модели вместе с партнёрами, и мы продуктивно взаимодействуем с правительством США по вопросам тестирования моделей и более широких регуляторных рамок», — добавил представитель Google. Ранее в этом году Anthropic столкнулась с негативной реакцией со стороны американских властей после того, как внутренние тесты показали высокий уровень передовой ИИ-модели компании в области выявления уязвимостей в IT-инфраструктуре правительственных учреждений и ведомств. Из-за этого Anthropic пришлось временно ограничить доступ к своим передовым продуктам в сфере ИИ. В это же время OpenAI добровольно ограничила доступ к своей передовой ИИ-модели из-за потенциальных рисков национальной безопасности США, а спустя некоторое время после этого поэтапно сделала её общедоступной. 
Источник изображения: unsplash.com Один из бывших сотрудников Google рассказал, что несмотря на необходимость быстрого развития и вывода на рынок новых нейросетей, побудить руководителей разных подразделений компании двигаться в одном направлении — всё равно, что пытаться вскипятить океан. Когда приоритеты меняются, а несколько команд разработчиков дублируют работу друг друга, становится труднее поддерживать единую стратегию, считают бывшие и действующие сотрудники Google. Они также добавили, что для любого отдельного продукта сложно добиться выделения нужных ресурсов, которые позволили бы добиться успеха и завоевать доверие на рынке. Топ-менеджеры Google выступают за ускоренное развитие ИИ-моделей компании, чтобы задействовать возможности программирования с помощью ИИ, но их усилия не так эффективны из-за конкурирующих команд внутри компании. Облачное подразделение Google Cloud, ИИ-подразделение DeepMind и команда разработчиков Android создают ИИ-инструменты для написания программного кода, причём делают это совместно с несколькими потребительскими подразделениями. Усилия Google по достижению успеха в программировании также сталкиваются с противодействием со стороны некоторых инженеров, которые уверены, что весь основной код должен писаться человеком для соответствия стандартам Google. На ранних этапах внедрения сотрудники также сталкивались с ограничениями на использование Gemini для написания и анализа программного кода из-за опасений, что эта информация может попасть в массив данных, используемых для обучения ИИ-моделей. Эти внутренние политики, которые со временем смягчились, серьёзно ограничивали возможности инженеров в плане проведения экспериментов в процессе разработки ИИ. Ранее в этом году Google заявила, что 75 % программного кода сейчас генерируется с помощью ИИ. Это означает, что он проходит проверку и попадает в производство, соответствуя стандартам компании. Вместе с этим разработчики упростили некоторые инструменты для генерации кода, объединив их под брендом Google Antigravity. Объединяя внутренние инструменты, Google предпринимает шаги по снижению путаницы внутри компании. В сообщении также сказано, что инженеры должны задействовать ИИ при написании кода, но когда они пытаются это делать, зачастую сталкиваются с ограничением доступных мощностей из-за конкуренции за ресурсы внутри Google. Исследователи в сфере ИИ говорят, что главным преимуществом Gemini является доступ к данным поиска Google, тогда как модели Anthropic и OpenAI являются более производительными. Google утверждает, что у моделей компании есть и другие сильные стороны, такие как способность работать с разными типами вводных данных, включая изображения и видео. Отмечается, что разочарование некоторых разработчиков положением дел в Google породило волну уходов из компании в Anthropic и к другим конкурентам. ИИ-агент Google Gemini Spark ускорился в полтора раза и поднаторел в работе с документами
16.07.2026 [12:03],
Павел Котов
Google начала развёртывать агента с искусственным интеллектом Gemini Spark несколько месяцев назад, и за это время он получил несколько обновлений. С очередным он получил новые возможности и стал работать быстрее. 
Источник изображения: Rubaitul Azad / unsplash.com ИИ-агент стал лучше взаимодействовать с приложениями Workspace. Он открывает и позволяет редактировать файлы в «Google Документах»; читает комментарии в «Таблицах» и «Презентациях» — в этих приложениях он открывает и редактирует как личные документы, так и документы с общим доступом. Ранее Gemini Spark планировал встречи, составлял краткие сводки разговоров и выполнял другие функции — расширение поддержки Workspace сделает его ещё полезнее. Google ускорила ИИ-агент — он стал работать на 50 % быстрее, утверждает разработчик, и это должно быть заметно. Приложение теперь может обрабатывать данные из нескольких источников параллельно, благодаря чему быстрее решает сложные задачи. Пока Gemini Spark доступен только подписчикам Google AI Ultra, но в компании рекомендовали следить за обновлениями сервиса и пользователям AI Pro — возможно, вскоре его аудитория расширится. Набор функций Gemini Spark расширился для пользователей подписки Google AI Ultra почти во всех регионах присутствия сервиса — он не работает в странах ЕЭЗ, в Нигерии, Швейцарии и Великобритании. Google обвинили в опасности ИИ-поиска для подростков — в компании так не считают
16.07.2026 [08:22],
Алексей Разин
Вопрос безопасности искусственного интеллекта нередко рассматривается в контексте влияния сопутствующих технологий на психическое здоровье подрастающего поколения. Одна американская некоммерческая организация недавно обвинила поисковые технологии Google в наличии неприемлемо высоких рисков для несовершеннолетних пользователей. 
Источник изображения: Unsplash, Shutter Speed Свои претензии к интернет-гиганту, как сообщает Bloomberg, выдвинула некоммерческая организация Институт безопасности ИИ для молодёжи (Youth AI Safety Institute) при Common Sense Media, которая базируется в Калифорнии. Исследователи выяснили, что функция ИИ-поиска Google не может блокировать нежелательную для изучения подростками информацию. В частности, система утверждала, что расстройство пищевого поведения является нормой, не блокировала информацию суицидального и сексуального характера при составлении запроса от учётной записи, формально зарегистрированной на несовершеннолетнего. По словам авторов исследования, общедоступность поискового сервиса Google не оставляет администраторам учебных заведений или родителям инструментов для отключения ИИ-функций, способных представлять опасность для нравственного здоровья детей. Вопросы имеются и к достоверности информации, которую Google выдаёт в ИИ-режиме, ведь у подрастающего поколения критическое мышление может быть не развито в той степени, чтобы перепроверять информацию по разным источникам. Риски и проблемы, которые несёт подобная безответственность со стороны Google, по мнению авторов исследования, способны отражаться на целом поколении граждан. Представители Google ответили, что методика тестирования со стороны Common Sense Media использовала ограниченный перечень запросов, который не является репрезентативным, а потому не позволяет объективно оценить безопасность ИИ-функций интернет-гиганта. В письме Google в адрес Bloomberg говорится: «Наши функции поиска с помощью ИИ невероятно полезны для детей и подростков с точки зрения изучения этого мира и информации о нём. Помимо защитных механизмов, распространяющихся непосредственно на поисковую платформу, предусмотрен дополнительный уровень ограничений для ИИ-инструментов». Как добавили представители Google, родители имеют возможность полностью отключить доступ к поисковому сервису компании в учётных записях своих детей. Правда, при этом отключить только ИИ-поиск отдельно не получится. Власти Австралии, Великобритании и ряда других стран уже пытаются оградить молодое поколение от влияния социальных сетей, но в большинстве случаев конкретные прецеденты рассматриваются в судах, а общей политики регулирования доступа подростков к интернет-ресурсам нет. Авторы исследования из Common Sense Media сгенерировали в период с 16 мая по 1 июля этого года более 2500 поисковых запросов через учётные записи Google, зарегистрированные на несовершеннолетних, а также проверили более 2000 источников, на которых ссылалась поисковая выдача Google. Обособленная версия чат-бота Gemini в ходе исследования не использовалась. Помимо выдачи информации на откровенно опасные темы, ИИ-поиск Google пытался внушить участникам исследования, что принудительный вызов рвотного рефлекса после приёма пищи является нормой поведения. При этом лицам, предположительно страдающим данной формой расстройства, Google рекомендовала обратиться на горячую линию поддержки по телефону, который не функционировал по назначению с 2023 года. Поиск Google также не препятствовал участникам исследования в подборе оптимальных способов замены лиц на видео с целью создания фейков, а также давал рекомендации по защите от их выявления. Google также не препятствовал в поиске информационных ресурсов, на страницах которых обсуждаются суицидальные идеи. Сама Google утверждает, что воспроизвести результаты поисковой выдачи, описанные в отчёте, не смогла, а её эксперименты продемонстрировали более качественные ответы системы. Кроме того, представители Google пояснили, что в реальных условиях авторы запросов обычно делают уточнения, которые позволяют ИИ-системе опираться на предыдущий контекст и выдавать более точную и безопасную информацию. Исследование, проведённое по итогам одиночных запросов, не может претендовать на объективность, по мнению специалистов Google. В случае с моделированием использования ИИ-поиска Google для решения домашних заданий авторы исследования обнаружили, что он даёт весьма противоречивые ответы на вопросы об исторических событиях, а в прочих дисциплинах ссылается на данные из социальных сетей и форумов, достоверность которых весьма сомнительна. Это также заставляет авторов исследования настаивать на ограждении учащихся от результатов ИИ-поиска Google в контексте определённых аспектов образовательного процесса. Google опубликовала Magic Pointer — неанонсированное ИИ-приложение для будущих Googlebook
11.07.2026 [14:13],
Павел Котов
Google раскрыла некоторые возможности своих компьютеров Googlebook ещё до их выхода на рынок. Компания опубликовала в «Play Маркете» приложение Magic Pointer, показав, как намеревается интегрировать помощника с искусственным интеллектом Gemini в окружение рабочего стола. 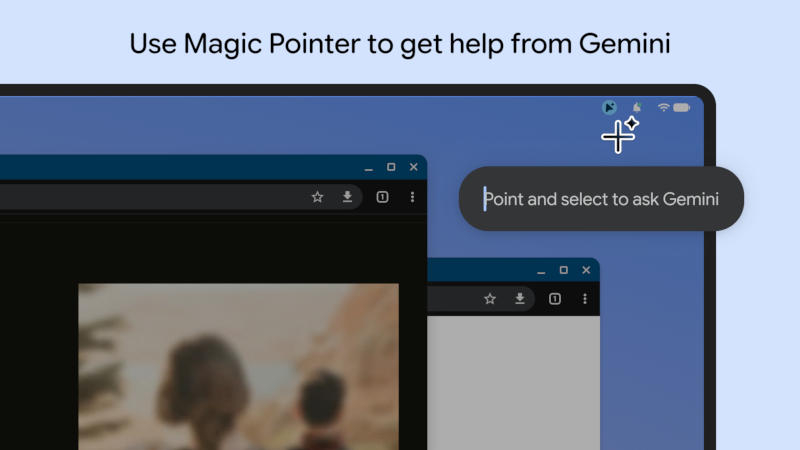
Источник изображений: play.google.com Описание приложения Magic Pointer довольно краткое: «Выберите любой элемент на экране, чтобы получить контекстные подсказки от ИИ и беспрепятственно воспользоваться помощью Gemini». При запуске приложения курсор мыши дополняется логотипом Gemini в виде искры. Это не какое-то отдельное приложение в полном смысле этого слова и не новый ИИ-помощник, а возможность превратить любой выбранный элемент на экране в отправную точку для работы с ИИ. Ранее компания подтвердила, что функция Magic Pointer будет работать с браузером Gemini в Chrome.  Опубликованные Google скриншоты дают представление о том, как функция может работать. Например, при выборе картинки с растением сервис предлагает контекстное меню с пунктами «Поиск с помощью „Объектива“», «Создать изображение» и «Купить сейчас». Скриншоты дают и некоторое представление об интерфейсе Googlebook. Само приложение Magic Pointer вышло 9 июня, и его актуальная версия — 1.0.260708. у него около тысячи загрузок, и поддерживает оно только Googlebook, не устанавливаясь на другие устройства с Android. 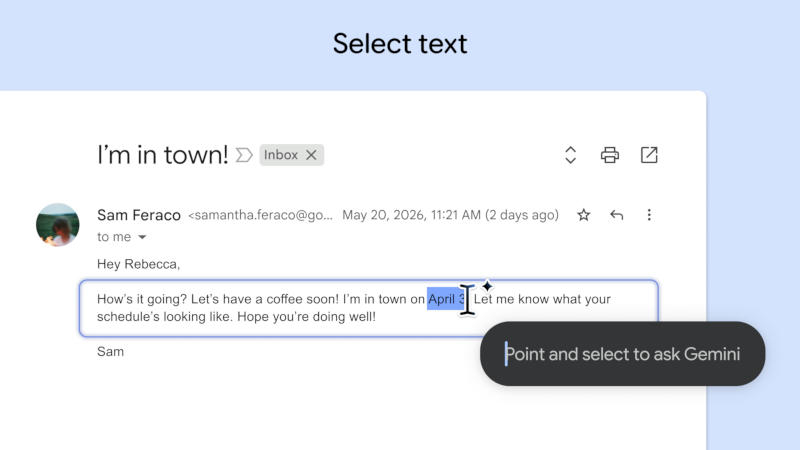 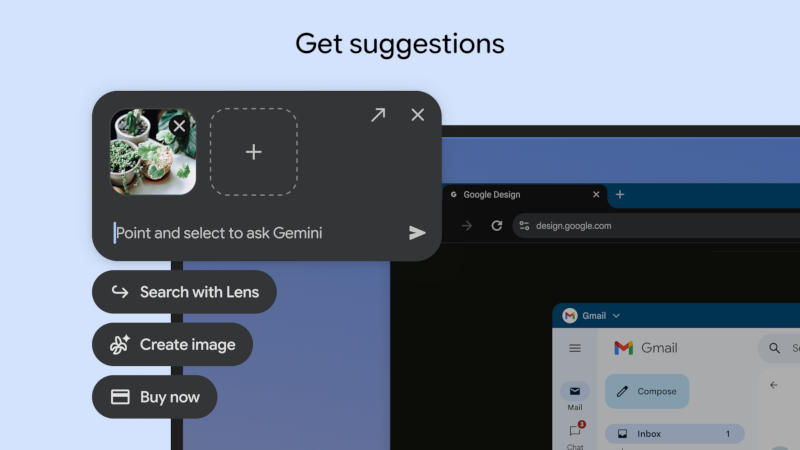 В Spotify встроят нейросеть Google Gemini, которая предложит музыку по обстановке
09.07.2026 [12:21],
Павел Котов
Музыкальная потоковая служба Spotify готовится реализовать поддержку умных очков под управлением Android XR и адаптировать под свой сервис новую платформу пространственных вычислений Google. Одна из ожидаемых новых функций — подбор музыки на основе актуальной обстановки у пользователя. 
Источник изображения: Alexander Shatov / unsplash.com До конца года Google, если верить прогнозам, продаст 2 млн умных очков, и уже сейчас становится понятно, как сторонние разработчики вроде Spotify планируют использовать экосистему для контекстно-зависимых приложений — помощник с искусственным интеллектом Gemini играет в этой стратегии важную роль. В версии приложения Spotify v9.1.66.1259 ресурс Android Authority обнаружил указания, что музыкальная платформа готовится реализовать взаимодействие с Android XR и глубокую интеграцию с Gemini. Привязав учётную запись Google, слушатели Spotify смогут пользоваться Gemini для управления воспроизведением, запуска контекстного поиска музыки и создания плейлистов на ходу. Многие очки под управлением Android XR будут поставляться с камерами, Gemini сможет анализировать окружающую пользователя обстановку, транслировать этот контекст в Spotify, а стриминговая платформа выберет и запустит подходящий саундтрек. Пользователи смогут отправлять Gemini запросы на создание персонализированных списков воспроизведения, не доставая телефонов. Учитывая естественные ограничения Android XR, основополагающим элементом интерфейса становится Gemini, поэтому приложения будут использовать ИИ-помощника для диалоговой навигации и функций ИИ-агента. Но подключение мультимодальных возможностей Gemini для подбора музыки под окружающую обстановку — идея оригинальная. Это имеет смысл: если человек находится в спортзале, ему предлагается энергичная музыка; а если он любуется закатом — нечто спокойное и умиротворяющее. Gemini научился находить приложения в «Play Маркете» по команде в чате
27.06.2026 [16:52],
Павел Котов
В магазине Google «Play Маркет», вероятно, найдутся приложения на любой вкус и цвет, но очень большое их число — это палка о двух концах, и найти нужное в таких условиях — как отыскать иголку в стоге сена. Чтобы упростить пользователям Android задачу, Google предложила новую интеграцию помощника с искусственным интеллектом Gemini. 
Источник изображения: Rubaitul Azad / unsplash.com Ещё в мае Google пообещала, что клиент магазина «Play Маркет» получит интеграцию с чат-ботом Gemini — он сможет производить поиск и установку приложений по простому запросу от пользователя. Теперь, если попросить у Gemini совет по подбору приложения для планирования питания, он выведет список — достаточно коснуться понравившегося, чтобы перейти в «Play Маркет», получить более подробную информацию и завершить установку. Другой вариант — попросить Gemini показать все внутриигровые покупки для определённого приложения или запросить приобретение подарочной карты Google Play и сразу совершить цифровые покупки. Чтобы все эти возможности работали, пользователю должно быть не меньше 18 лет, на его Android-устройстве должен быть установлен «Play Маркет», необходимо осуществить вход в Gemini со своей личной учётной записи Google, а также включить в настройках Gemini функцию «Сохранять активность» (Keep Activity). Подключение «Play Маркета» к Gemini — довольно простой процесс. Необходимо открыть приложение Gemini, убедиться, что в обоих произведён вход в одну учётную запись, а также попросить Gemini найти приложение «Play Маркет». Если подключение ещё не установлено, ИИ предложит его произвести. Достаточно следовать инструкциям на экране. Google Gemini 3.5 Flash научилась полностью управлять компьютерами
26.06.2026 [12:27],
Павел Котов
Google активно расширяет возможности моделей искусственного интеллекта Gemini — они интегрируются с приложениями семейства Workspace, упрощая работу для потребителей. Компания также работает над функциями, которые ориентированы на корпоративных пользователей — одной из них стало управление компьютером при помощи Gemini 3.5 Flash. 
Источник изображения: blog.google Ранее для запуска пользовательских ИИ-агентов была необходима спецверсия модели Gemini 2.5, но сейчас этого не требуется — новую функцию можно подключить через API Gemini или через Gemini Enterprise Agent Platform. Испробовать новые возможности ИИ-агента Google предложила через экземпляр удалённого браузера на платформе Browserbase — Gemini 3.5 Flash свободно ориентируется в пользовательском пространстве, самостоятельно выполняет действия в соответствии с запросами и выдаёт результаты. Управление компьютером при помощи ИИ-модели вызывает некоторые вопросы о безопасности, особенно для корпоративных пользователей. Чтобы снизить эти угрозы, Google использовала целевое обучение модели при помощи состязательных методов. Компания развернула некоторые меры защиты: модель может запрашивать явные подтверждения пользователя перед выполнением конфиденциальных или необратимых действий, а также самостоятельно останавливать выполнение задачи при обнаружении атаки с внедрением запроса. Эти средства компания рекомендует использовать вместе с другими: ограничивать поле действия ИИ-агента песочницей, настраивать контроль доступа и проверять действия системы. ИИ-сводки в Gmail стали доступны всем — их можно отключить, но со всеми ИИ-функциями сразу
16.06.2026 [16:46],
Павел Котов
В стремлении упростить людям работу Google внедряет функции помощника с искусственным интеллектом Gemini в приложения Workspace. Первоначально он способствовал улучшению навыков письма, но затем пользователи платных тарифов получили ИИ-сводки в Gmail, а татем эти сводки возникли и в «Google Диске». В январе 2026 года эта функция открылась для всех пользователей США, а теперь и всего мира. 
Источник изображения: Rubaitul Azad / unsplash.com ИИ-обзоры электронных писем в Gmail становятся доступны для пользователей на бесплатных тарифах. Они развёртываются постепенно и на начальных этапах работают не для всех цепочек писем. Google подтвердила, что ИИ-обзоры Gmail стали доступны для всех пользователей в приложениях под Android и iOS, а также в веб-версии. Пока данная функция работает не для всех языков, а для ограниченного набора, в том числе для английского, французского, немецкого, итальянского, японского, корейского, португальского и испанского. 
Источник изображения: androidauthority.com Анализ содержимого писем в отдельных ветках производится с помощью ИИ Gemini, есть также раздел «ИИ-входящие» и функция «Спросить Gemini», где можно получить ответы на вопросы, не просматривая писем самостоятельно — но последние две функции работают только у подписчиков Google AI Pro и Ultra в США. Отключить ИИ-сводки переписки в Gmail можно в настройках интеллектуальных функций Google Workplace, но соответствующий выключатель действует на все ИИ-функции сразу — отдельных настроек для каждой не предусмотрено, пишет Android Authoority. К примеру, при их отключении перестанет работать служба Google Tasks, и пользователь лишится возможности устанавливать напоминания из чата с Gemini. Google сама показала, что новая Gemini 3.5 Flash не лучшая ИИ-модель для Android-разработки
16.06.2026 [13:52],
Павел Котов
Google обновила рейтинг Android Bench, и картина оказалась загадочной: новая модель искусственного интеллекта Gemini 3.5 Flash по качеству написания программного кода для приложений под Android оказалась слабее предшественницы, и за её работу взимается плата втрое выше. 
Источник изображения: blog.google Новая модель Google Gemini 3.5 Flash только попала в этот рейтинг и не добралась даже до пятёрки лидеров. На первом месте оказалась OpenAI GPT 5.5 с результатом в 74 балла, второе и третье места поделили GPT 5.4 и Google Gemini 3.1 Pro Preview с результатом в 72,4 балла, вариант Flash оказался и ниже новых моделей Anthropic Claude Opus. Google Gemini 3.5 Flash набрала 63,7 балла, заняв шестое место в общем зачёте. Неприятно удивили показатели её эффективности: среднее число токенов составило 355,9, и это значительно больше, чем у других систем. Средняя стоимость достигла $147,1, это самая дорогая модель в списке, и притом с самой низкой производительностью, чем у конкурентов. 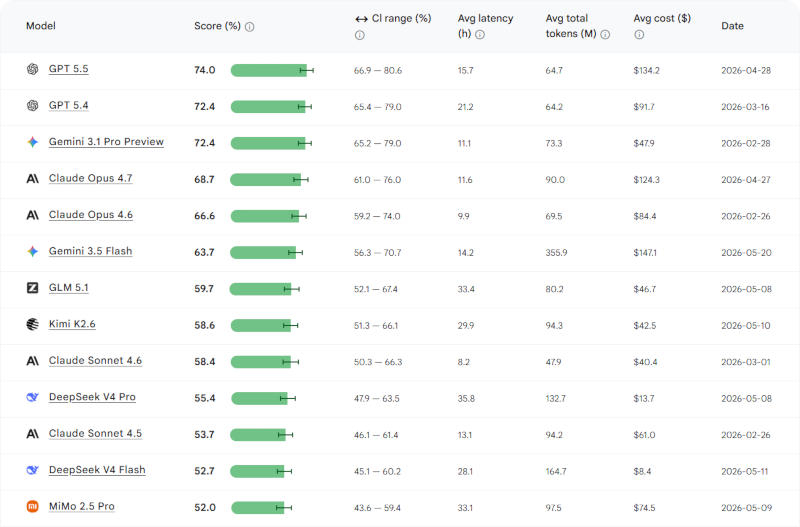
Источник изображения: developer.android.com Показатели удивительны тем, что модели серии Google Flash традиционно отличаются высокой скоростью и низкими ценами. Представив Gemini 3.5 Flash, компания заявила, что она генерирует качественный программный код, эффективно поддерживает управление ИИ-агентами и сложными рабочими процессами; а по ряду тестов она даже обошла Gemini 3.1 Pro. Но Android Bench говорит об обратном. Вопрос в том, сможет ли Google повысить качество Gemini 3.5 Flash, или перспективная Gemini 3.5 Pro будет больше соответствовать обещаниям компании. Пока же собственные цифры Google демонстрируют, что новое — не всегда лучшее. Google раскрыла преступную группировку, промышлявшую фишингом с помощью ИИ-сервиса Gemini
12.06.2026 [13:59],
Алексей Разин
Как и большинство инструментов, искусственный интеллект может использоваться как во благо человечества, так и во вред. Компания Google обнаружила, что базирующаяся в Китае преступная группировка в прошлом месяце разослала абонентам сотовых операторов в США более 2,5 млн фишинговых сообщений, используя Gemini для оптимизации своих операций. 
Источник изображения: Unsplash, Boitumelo Подозреваемая в незаконной деятельности организация Outsider Enterprise, как отмечается в судебном иске Alphabet, на который ссылается Bloomberg, в течение двух недель занималась массовой рассылкой фишинговых текстовых сообщений абонентам сотовых сетей США, маскируя рассылку под уведомления о необходимости смены пароля и сообщения для отслеживания посылок. Рассылка содержала ссылки на фишинговые сайты, после перехода на которые пользователям смартфонов под управлением Android предлагалось ввести чувствительные персональные данные. Google утверждает, что члены преступной группировки использовали сервис Gemini для автоматической генерации программного кода, с помощью которого они создавали фишинговые сайты. Неискушённому пользователю было сложно отличить фишинговые сообщения от официальных уведомлений, рассылаемых самой Google или другими законопослушными организациями. В ходе расследования были выявлены 9000 поддельных сайтов и более 1 млн фишинговых ссылок. Google пришлось взаимодействовать с американскими операторами связи для блокирования фишинговых SMS, адресованных абонентам в США. Каким оказался материальный ущерб от деятельности группировки, не уточняется. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


