|
Опрос
|
реклама
Быстрый переход
Вышел ContentReader PDF 16 — российский заменитель Abbyy FineReader со встроенным ИИ-ассистентом
19.03.2026 [17:55],
Андрей Крупин
Российский разработчик Content AI объявил о выпуске ContentReader PDF 16 — нового поколения своего флагманского продукта, объединяющего все необходимые инструменты для работы с PDF и бумажными документами. 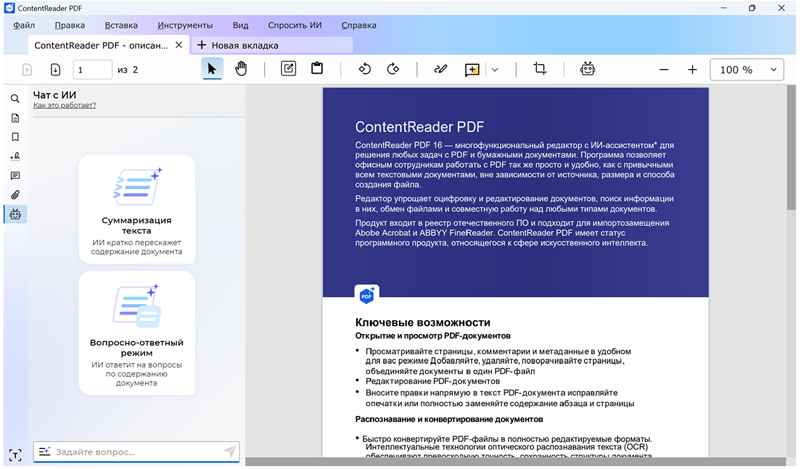
Здесь и далее источник изображений — пресс-служба Content AI / contentai.ru ContentReader PDF 16 является многофункциональным решением, построенным с использованием технологий оптического распознавания символов (OCR), обработки естественного языка (NLP) и компьютерного зрения. В составе программы представлен полный набор средств для редактирования PDF-файлов (в том числе сканов и изображений документов), их конвертирования в различные форматы, добавления водяных знаков, электронной подписи и защиты паролем. В корпоративной версии приложение позволяет сравнивать документы разных форматов и на разных языках без предварительной конвертации и поддерживает автоматическую пакетную обработку файлов из заданной директории. Ключевым нововведением ContentReader PDF 16 стал встроенный ИИ-ассистент, который представлен в корпоративной редакции и помогает находить нужные данные, также обобщать информацию. Новый компонент поддерживает вопросно-ответный режим: пользователи могут задавать вопросы по содержанию документов на естественном языке и получать точные ответы (например: «Какие условия расторжения договора», «Какие реквизиты сторон», «Как проводить оплату подрядчику» и так далее). При этом ИИ-ассистент автоматически указывает раздел, из которого извлечена информация, что даёт возможность проверить корректность результата. 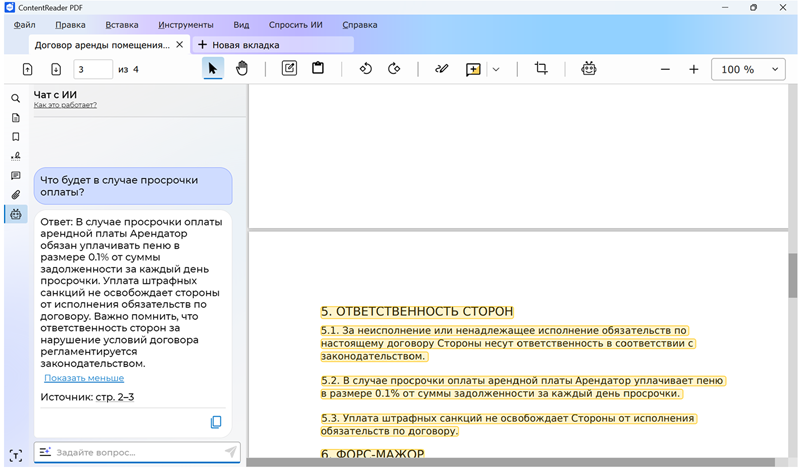 Также в ContentReader PDF 16 реализована функция подготовки краткого пересказа документа. По запросу пользователя ИИ-ассистент формирует выжимку многостраничного отчёта, протокола или контракта, что позволяет сократить время на предварительный анализ материалов. ИИ-ассистент может быть востребован при работе с многостраничными договорами, финансовой отчётностью, технической и тендерной документацией и другими объёмными материалами, содержащими большое количество фактов, цифр и таблиц. С его помощью юристы могут быстро находить нужные пункты в договоре, бухгалтеры — извлекать цифры из сканов счетов, менеджеры — получать краткое содержание коммерческих предложений, а инженеры — оперативно ориентироваться в проектной документации. 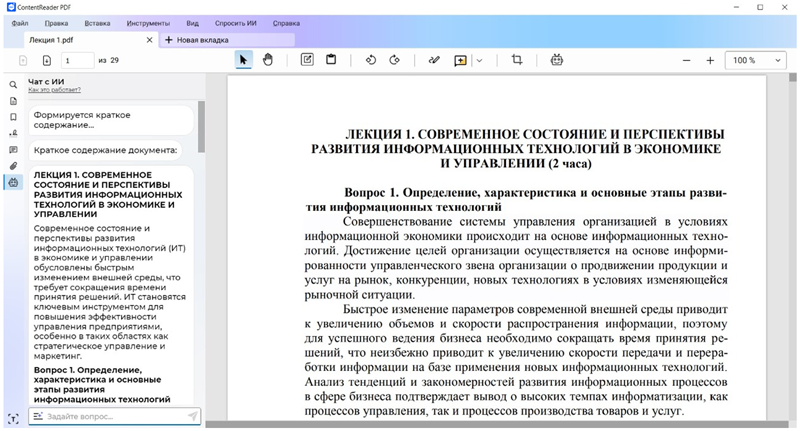 Работа ИИ-ассистента реализована на базе серверного компонента в интеграции с большой языковой моделью (LLM). Решение разворачивается внутри периметра организации, благодаря чему вся обработка данных происходит локально. Это гарантирует сохранность конфиденциальной корпоративной информации и нивелирует риски утечки данных. Отдельное внимание в ContentReader PDF 16 было уделено доработкам пользовательского интерфейса программы и упрощению выполнения типовых операций, связанных с редактированием текста, заполнением форм и вводом заметок. ContentReader PDF 16 распознает документы на 193 мировых языках и любых их комбинациях, включая арабские и восточные языки. Программа поставляется разработчиком по подписочной модели в трёх редакциях — Standard, Business и Corporate, разнящихся набором включённых инструментов, формами поставки и условиями лицензирования. Решение поддерживает работу на ОС Windows и всех основных российских операционных системах на базе Linux, включая Astra Linux, «Ред ОС»,«Альт» и другие, зарегистрировано в реестре отечественного ПО и имеет официальную маркировку ИИ-продукта. По заверениям разработчика, ContentReader PDF 16 обеспечивает полное импортозамещение решений ABBYY FineReader и Adobe Acrobat. Adobe представила Acrobat Studio — платформу на базе ИИ для работы со множеством разношёрстных файлов
19.08.2025 [20:17],
Сергей Сурабекянц
Adobe представила новую платформу Acrobat Studio. Она объединяет работу с документами в формате PDF с сервисом создания контента Adobe Express и помощниками на базе ИИ, способными автоматизировать выполнение конкретных рабочих задач. Acrobat Studio позволяет пользователям загружать до 100 документов разных форматов и объединять всю эту информацию в едином рабочем пространстве. 
Источник изображений: Adobe Замысел Adobe заключается в том, чтобы превратить Acrobat из инструмента для чтения и редактирования PDF в платформу с поддержкой широкого спектра типов файлов и инструментов для повышения производительности, включая веб-страницы и файлы Microsoft 365. Платформа позволяет пользователям работать с несколькими документами одновременно, не выходя из Acrobat, используя среды совместной работы, называемые PDF Spaces (PDF-пространства). Они объединяют информацию из файлов и веб-сайтов в «центры знаний для общения». 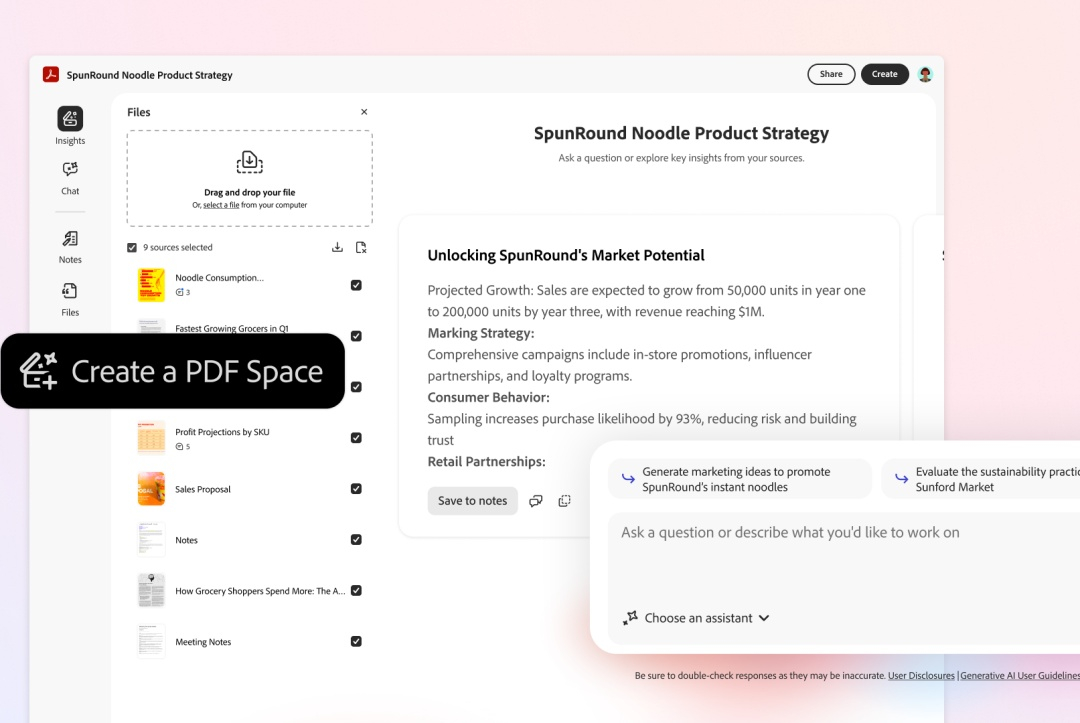 PDF Spaces дают возможность просматривать и подписывать соглашения по проектам, объединять исследования и заметки, а также использовать встроенные инструменты Express для преобразования данных в инфографику или визуальные материалы, которыми можно делиться с коллегами и клиентами. Acrobat Studio также включает настраиваемых агентов ИИ, созданных на основе ранее выпущенных функций искусственного интеллекта для стандартного Adobe Acrobat. ИИ-помощники могут использоваться отдельными пользователями и командами для предоставления аналитических отчётов, рекомендаций и заметок, а также генерировать идеи и цитаты на основе собранных данных.
Браузер Chrome для Android наконец-то научился открывать PDF-файлы
24.04.2025 [20:29],
Сергей Сурабекянц
До настоящего момента для просмотра файла формата PDF на Android пользователям приходилось использовать сторонние приложения. Теперь же Google наконец развернула встроенную поддержку PDF-файлов в веб-обозревателе Chrome для Android. Первые упоминания о нативной поддержке PDF-файлов (Open PDF Inline на Android) появились в коде ещё в феврале 2024 года, но сама эта возможность ранее была заблокирована. 
Источник изображений: androidauthority.com Эта весьма востребованная функция гарантированно работает в Android 15, но её поддержка в более старых версиях Android пока отсутствует. Средство отображения PDF-файлов в Chrome для Android предлагает встроенную панель аннотаций с функциями ручки, маркера, ластика, отмены, повтора и видимости. Пользователь может выбирать толщину и цвет линии и прокручивать документ, чтобы выбрать место для аннотации. По умолчанию панель отображается внизу страницы, но её можно переместить вверх. 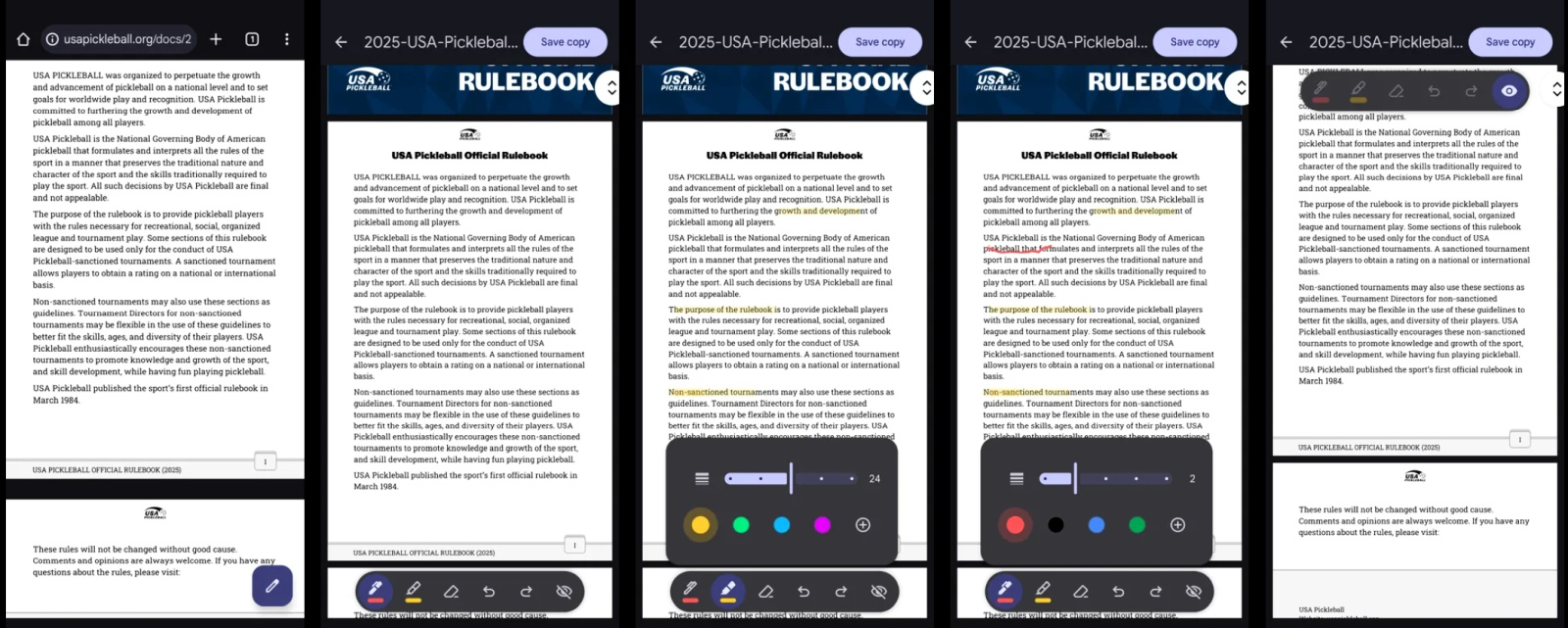 При просмотре PDF-файлов доступен полнотекстовый встроенный поиск Chrome, который отображает все вхождения искомого текста в документе и позволяет легко перемещаться между ними. 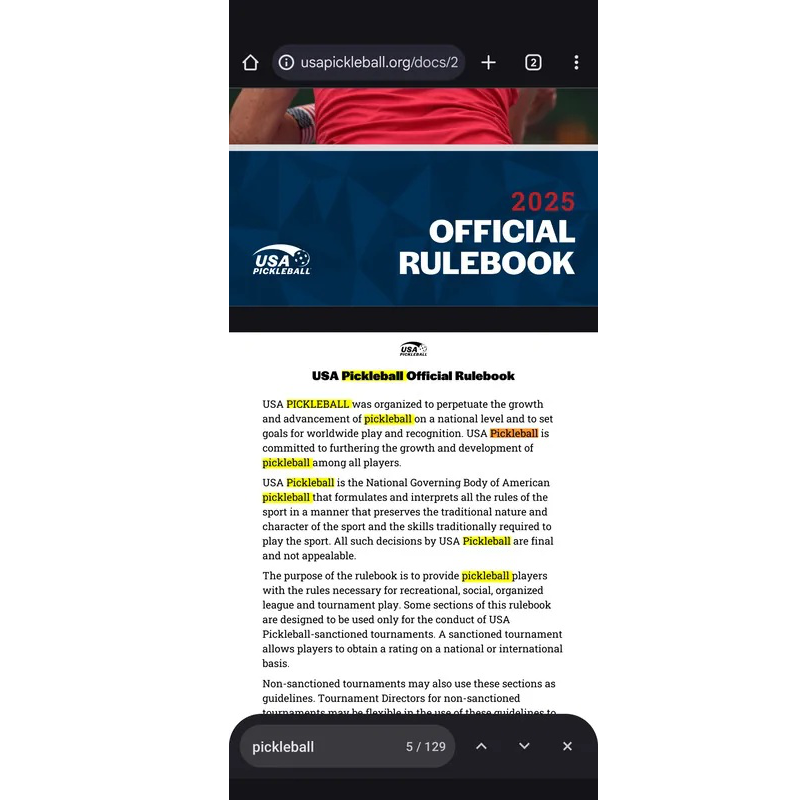 Первый раз упоминание о возможности просматривать файлы PDF в браузере (Open PDF Inline on Android pre-V) был обнаружено ещё в коде Android 12, но до сих пор эта возможность оставалась заблокированной. Mistral AI представила инструмент, который превратит любой PDF-документ в текстовый файл для ИИ
07.03.2025 [11:20],
Владимир Фетисов
Французский разработчик больших языковых моделей (LLM) Mistral AI объявил о выпуске нового API, который предназначен для обработки сложных PDF-документов. Mistral OCR — это API оптического распознавания символов (OCR), с помощью которого любой PDF-документ можно превратить в текстовый файл, чтобы облегчить его обработку алгоритмами на основе искусственного интеллекта. 
Источник изображения: Scott Graham / Unsplash Языковые модели, лежащие в основе популярных генеративных алгоритмов, таких как ChatGPT от OpenAI, особенно хорошо работают с необработанным текстом. Поэтому компании, которые намерены вводить собственные рабочие ИИ-процессы, знают о важности хранения и индексации данных в чистом формате, чтобы эту информацию можно было повторно использовать в процессе обработки ИИ-алгоритмами. В отличие от многих API OCR, разработка Mistral представляет собой мультимодальный API, который способен распознавать не только текст, но также иллюстрации и фотографии, размещённые между текстовыми блоками. API OCR формирует ограничительные рамки вокруг обнаруженных графических элементов и включает их в вывод. В результате обработки PDF-документа с помощью Mistral OCR формируется отформатированный в Markdown текст, который ИИ-алгоритмы обрабатывают более эффективно. 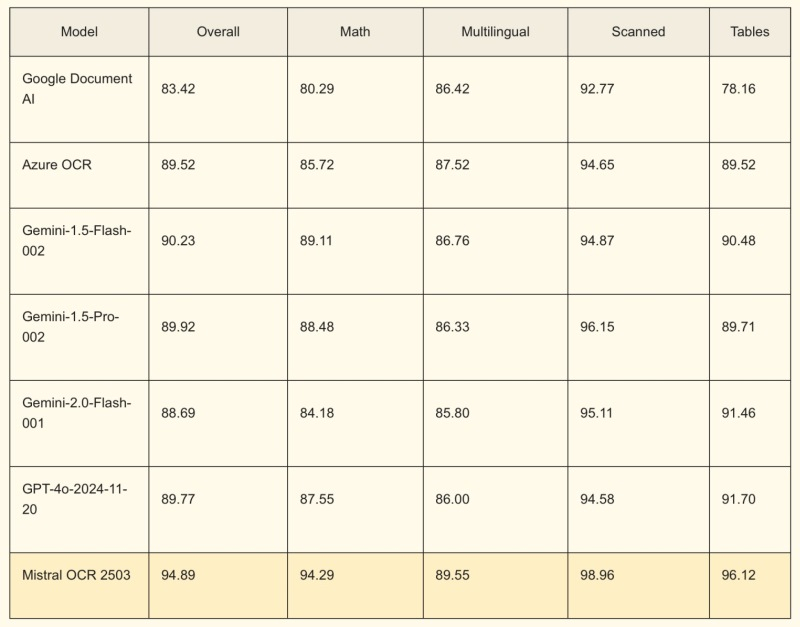
Источник изображения: Mistral «С годами в организациях накапливается множество документов, часто в формате PDF или в виде слайдов, которые недоступны для обработки LLM, особенно для систем RAG [Retrieval-Augmented Generation — техника получения и использования данных в качестве контекста для генеративных ИИ-алгоритмов]. Благодаря Mistral OCR наши клиенты могут преобразовывать сложные документы в читаемый контент на всех языках. Это важнейший шаг на пути к широкому внедрению ассистентов с искусственным интеллектом в компаниях, которым необходимо упростить доступ к обширной внутренней документации», — считает соучредитель и научный руководитель Mistral Гийом Лэмпл (Guillaume Lample). Mistral OCR доступен на собственной платформе компании, а также в инфраструктуре облачных партнёров Mistral, таких как AWS, Azure и др. Для компаний, которые работают с конфиденциальными или секретными данными, Mistral предлагает версию API для локального развёртывания. В компании заявили, что Mistral OCR работает лучше, чем аналогичные API от Google, Microsoft или OpenAI. Компания протестировала свой API на сложных PDF-документах, в том числе содержащих математические выражения, сложные макеты и таблицы. Старшеклассник запустил Linux прямо внутри PDF-файла
13.02.2025 [16:50],
Павел Котов
Старшеклассник Аллен Динг (Allen Ding), который ранее отметился запуском классической стрелялки Doom в файле PDF, усовершенствовал свой проект и встроил в файл PDF возможность запуска Linux. 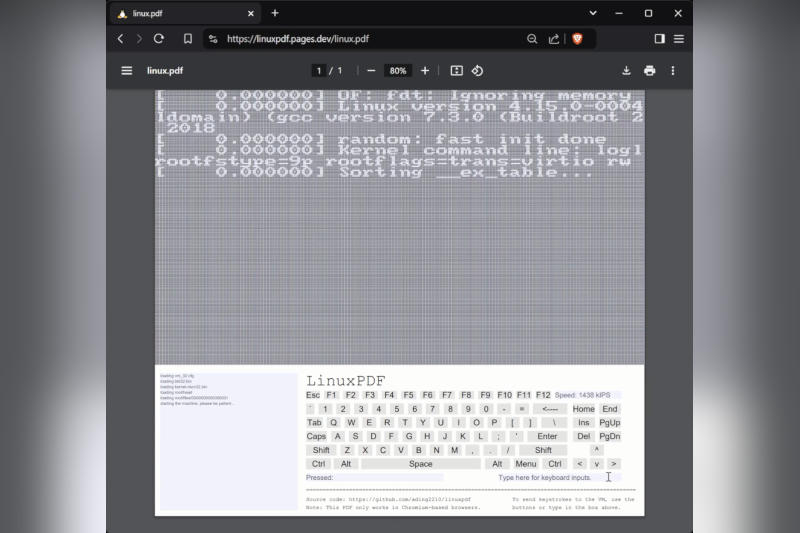
Источник изображения: youtube.com/@vk6_ Этот проект — переосмысление возможностей JavaScript при работе с PDF. Его исходный код доступен на странице разработчика на GitHub, а опробовать LinuxPDF можно по этому адресу — потребуется браузер на базе Chromuim, такой как Chrome, Edge или Opera. LinuxPDF работает в эмуляторе RISC-V на базе TinyEMU; внутренние механизмы проекта имеют много общего с DoomPDF за авторством того же разработчика. Управление системой производится при помощи виртуальной клавиатуры под главным экраном. Формат PDF разрабатывался для вывода текста и изображений, но поддерживается и запуск кода JavaScript. Программа Adobe Acrobat включает полную спецификацию JavaScript, в том числе функции 3D-рендеринга, обнаружения монитора и HTTP-запросов. Запускаемые через браузеры PDF-файлы несколько ограничены в возможностях, но и их хватает для запуска игр и операционных систем. Запущенная через PDF система Linux отличается катастрофически низкой производительностью — загрузка ядра занимает около минуты, и исправить это не получится, потому что в Chromium встроена версия движка V8 без поддержки JIT-компилятора. По умолчанию система 32-битная, но на GitHub можно сделать форк проекта и создать 64-битный вариант, который, однако, будет работать ещё медленнее. Copilot в Microsoft Edge научился обрабатывать PDF-файлы, и это может стать причиной утечки данных
14.08.2024 [21:10],
Сергей Сурабекянц
Microsoft стремится интегрировать максимальное количество ИИ-функций в свой веб-обозреватель. Новую порцию ИИ-улучшений получил и встроенный в Microsoft Edge инструмент для чтения документов PDF. ИИ-функция, добавленная в Copilot, сканирует документ, выделяя ключевые слова и фразы, а затем предоставляет пользователю дополнительную информацию. Обработка, вероятно, производится на серверах Microsoft, что может нарушить конфиденциальность. 
Источник изображения: Microsoft Новый инструмент доступен при нажатии кнопки, появившейся рядом с существующей кнопкой «Спросить Copilot» в интерфейсе PDF-ридера. Она запускает сканирование всего PDF-документа для генерации соответствующих ключевых слов и фраз. Затем пользователь может выбрать любое из них, чтобы открыть боковую панель Copilot в браузере и получить больше контекста или информации, связанной с этим ключевым словом. Содержимое PDF-файла, вероятно, обрабатывается и анализируется серверами Microsoft, что потенциально может привести к утечке конфиденциальной информации. Скорее всего, при обработке документов также будет производиться масштабный сбор данных для улучшения модели ИИ и изучения пользовательского опыта. Стоит дважды подумать, прежде чем использовать новую функцию для обработки документов с чувствительной информацией, например, налоговых форм или финансовых договоров. Весьма вероятно, что в ближайшее время Microsoft расширит область применения новой ИИ-функции, добавив в список обрабатываемых файлов документы Word, электронные таблицы Excel и презентации PowerPoint. Эта функция — лишь одна из нескольких возможностей на базе ИИ, которые были добавлены в Edge. Ранее обозреватель получил функцию интеллектуального поиска, которая обнаруживает связанные совпадения и слова, что упрощает поиск информации на странице. «Генератор тем» на базе ИИ преобразует текстовые подсказки в визуальные дизайны. ИИ даже научился автоматически присваивать названия группам вкладок для эффективного просмотра. Сейчас, если судить по предварительной сборке Canary, Microsoft работает над улучшением способности ИИ в Edge предлагать пользователю сайты для просмотра. Точная природа и функциональность этих нововведений пока не известна, но, учитывая стремление Microsoft к массированному внедрению ИИ везде, где только можно, рано или поздно они появятся. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




 Сегодня продукт Acrobat Studio выпущен в раннем доступе для англоязычной аудитории по всему миру. Он предлагается по подписке, которая может заменить тарифные планы Adobe Acrobat Standard и Acrobat Pro. Стоимость раннего доступа начинается с $24,99 в месяц для отдельных пользователей и с $29,99 в месяц для команд при годовом контракте. Пока неясно, изменится ли цена после окончания раннего доступа 31 октября.
Сегодня продукт Acrobat Studio выпущен в раннем доступе для англоязычной аудитории по всему миру. Он предлагается по подписке, которая может заменить тарифные планы Adobe Acrobat Standard и Acrobat Pro. Стоимость раннего доступа начинается с $24,99 в месяц для отдельных пользователей и с $29,99 в месяц для команд при годовом контракте. Пока неясно, изменится ли цена после окончания раннего доступа 31 октября.