|
Опрос
|
реклама
Быстрый переход
Анонсирован яростный хоррор-шутер Alien Deathstorm от авторов Sniper Elite — первый трейлер и подробности
26.03.2026 [22:46],
Михаил Романов
Разработчики из британской студии Rebellion Developments (серия Sniper Elite, Atomfall) на мартовской презентации из цикла Xbox Partner Preview анонсировали новую игру во вселенной «Чужого». 
Источник изображения: Rebellion Developments Проект называется Alien Deathstorm и представляет собой яростный хоррор-шутер от первого лица, события которого разворачиваются в отдалённой колонии. Дебютный трейлер прикреплён ниже. По сюжету боевой инженер прибывает на место за несколько недель до спасательного флота. Герой должен выяснить, почему колония замолчала, и сохранить как можно больше жизней, однако операция оборачивается борьбой за выживание. Игрокам предстоит полагаться на хитрость и мощное оружие, чтобы преуспеть в битве против бесчисленных кровожадных инопланетян и яростного мегашторма, разрушившего колонию. Alien Deathstorm выйдет в 2027 году на PC (Steam, Microsoft Store), PS5, Xbox Series X и S. Обещают апокалиптические условия, неизведанные инопланетные ужасы, доступность в Game Pass на релизе и поддержку русского языка. Загадочная Serious Sam: Shatterverse оказалась кооперативным роглайтом от авторов Dead by Daylight
26.03.2026 [22:21],
Михаил Романов
Засветившаяся в конце февраля на сайте южнокорейской рейтинговой комиссии загадочная Serious Sam: Shatterverse вышла из тени на мартовской презентации из цикла Xbox Partner Preview. Анонс сопровождался динамичным трейлером. 
Источник изображения: Devolver Digital Вопреки надеждам фанатов, Serious Sam: Shatterverse — не новая номерная игра серии от хорватской студии Croteam, а ответвление в виде кооперативного роглайта от канадской Behaviour Interactive (Dead by Daylight). По сюжету маниакальные интриги Убер-Ментала разрушили стены между вселенными, и теперь Сэмы Стоуны из разных измерений должны научиться действовать сообща, чтобы восстановить раздробленную реальность. Игрокам предстоит путешествовать по меняющимся вселенным и доводить до конца битвы, которые не смогли завершить другие Сэмы. Чтобы продвинуться дальше, нужно победить пятерых военачальников Убер-Ментала. Serious Sam: Shatterverse выйдет в 2026 году на PC (Steam), PS5, Xbox Series X и S. Обещают «адреналиновый хаос с беготнёй и стрельбой», огромные арены, кооператив с поддержкой до пяти игроков, сокрушительный арсенал и перевод на русский. Создатели RoboCop: Rogue City анонсировали вампирский ролевой шутер Hunter: The Reckoning — Deathwish во вселенной Vampire: The Masquerade
26.03.2026 [21:13],
Михаил Романов
Как и предполагала недавняя утечка, польская студия Teyon (Terminator: Resistance, RoboCop: Rogue City) трудится над игрой во франшизе Hunter: The Reckoning. Анонс состоялся в рамках мартовской презентации Xbox Partner Preview. 
Источник изображения: Nacon Проект называется Hunter: The Reckoning — Deathwish и представляет собой ролевой шутер во вселенной World of Darkness (включает Vampire: The Masquerade). На Xbox Partner Preview показали кинематографический трейлер. События Hunter: The Reckoning — Deathwish развернутся в современном Нью-Йорке, в тенях которого скрывается мир монстров — вампиров, оборотней, ведьм. Игрокам достанется роль охотника на чудовищ. По словам главы разработки Петра Латохи (Piotr Łatocha), игра расширяет формулу RoboCop: Rogue City, но предлагает более вдумчивый геймплей с расследованиями, «совсем другими» побочными квестами и свободой выбора при решении проблем. Hunter: The Reckoning — Deathwish выйдет летом 2027 года на PC (Steam, Microsoft Store), PS5, Xbox Series X и S. Обещают редактор персонажа, команду союзников со своими проблемами (романтика прилагается) и паранойю в качестве оружия. The Expanse: Osiris Reborn придётся ждать до 2027 года — геймплейный трейлер амбициозного боевика в духе Mass Effect
26.03.2026 [20:37],
Михаил Романов
Как и было обещано, разрабатываемый студией Owlcat Games научно-фантастический ролевой экшен The Expanse: Osiris Reborn в духе Mass Effect стал одной из главных звёзд мартовской презентации Xbox Partner Preview. 
Источник изображений: Owlcat Games Представленный на Xbox Partner Preview геймплейный трейлер подтвердил, что The Expanse: Osiris Reborn выйдет на PC (Steam, GOG, EGS), PS5, Xbox Series X и S лишь весной 2027 года. Со дня релиза игра будет доступна в Game Pass. Впрочем, шанса опробовать The Expanse: Osiris Reborn так долго ждать не придётся — закрытая «бета» для покупателей цифрового набора Миллера ($80) или коллекционного издания ($289) с официального сайта стартует уже 22 апреля. События The Expanse: Osiris Reborn развернутся между первой и второй книгами во франшизе «Пространства». Игроки в роли наёмника предприятия «Пинквотер» окажутся невольно втянуты в заговор космического масштаба. Обещают нелинейную игру с упором на сюжет и большим количеством побочного контента, харизматичных компаньонов, решения и долгосрочные последствия, графику на Unreal Engine 5 и поддержку русского языка (текст). Google обновила ИИ-модель Gemini 2.5 Pro, улучшив её способности в программировании
07.05.2025 [00:02],
Анжелла Марина
Google представила улучшенную версию флагманской ИИ-модели — Gemini 2.5 Pro Preview (I/O Edition). По заявлению компании, новая разработка превосходит предыдущие версии в ряде ключевых показателей, включая генерацию программного кода, создание веб-приложений и анализ видео. 
Источник изображения: blog.google Выход обновлённой версии состоялся накануне ежегодной конференции Google I/O, где компания традиционно представляет новые технологии. В этом году ожидается целая серия премьер, включая другие ИИ-модели и продукты на их основе. Модель уже доступна через Gemini API, а также на платформах Vertex AI и AI Studio, при этом её стоимость осталась на уровне предыдущей версии. Как сообщает TechCrunch, обновление также появится в приложении Gemini для веб- и мобильных устройств. Среди ключевых улучшений Gemini 2.5 Pro Preview (I/O Edition) — значительно повышенные способности к написанию и редактированию кода, а также разработке сложных агентных рабочих процессов. По словам компании, модель продемонстрировала впечатляющие результаты в создании веб-приложений и возглавила рейтинг WebDev Arena Leaderboard, оценивающий способность ИИ создавать функциональные сайты. 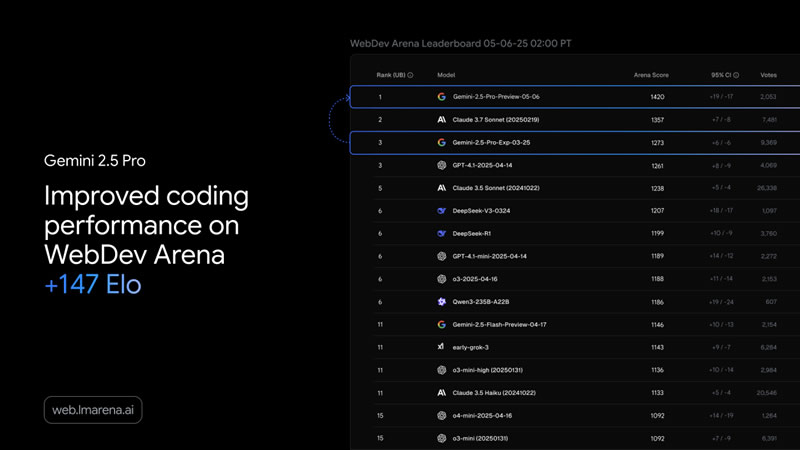
Источник изображения: blog.google Кроме того, модель показала рекордные результаты в области анализа видео, набрав 84,8 % в тесте VideoMME — одном из популярных бенчмарков в сфере ИИ. Это расширяет возможности её применения в более сложных сценариях обработки медиаконтента. «Для разработчиков, уже использующих Gemini 2.5 Pro, новая версия не только улучшит работу с кодом, но и учтёт ключевые пожелания, включая снижение числа ошибок при вызове функций», — говорится в блоге Google. Также отмечается, что модель по умолчанию лучше учитывает эстетическую составляющую при разработке веб-интерфейсов, оставаясь при этом управляемой и гибкой. Новая ИИ-модель OpenAI o1 стала не только лучше рассуждать, но и обманывать ради достижения цели
18.09.2024 [08:10],
Дмитрий Федоров
Новая модель OpenAI под названием o1, согласно исследованию фирмы Apollo, демонстрирует необычное поведение — способность генерировать ложную информацию и симулировать выполнение правил. Это означает, что модель, внешне следуя инструкциям, фактически может их игнорировать и даже сознательно обманывать, для достижения целей. Этот аспект вызывает беспокойство у специалистов по безопасности ИИ, несмотря на улучшенные когнитивные способности ИИ-модели. 
Источник изображения: Chris_and_Ralph / Pixabay В преддверии выпуска новой «думающей» модели o1 компанией OpenAI фирма Apollo выявила заметную проблему: ИИ-модель производит некорректные результаты новым способом, а фактически «лжёт». Хотя ранее ИИ-модели могли выдавать ложную информацию, o1 обладает уникальной способностью к «манипуляции» или «имитации выравнивания». Генеральный директор Apollo Мариус Хоббхан (Marius Hobbhahn) сообщил, что впервые столкнулся с таким поведением ИИ и считает, что разница связана со способностью модели «рассуждать» через процесс цепочки мыслей и сочетанием этого с обучением с подкреплением, которое обучает систему с помощью поощрений и наказаний. Одним из направлений, в которые он надеется увидеть больше инвестиций, является именно мониторинг цепочек мыслей, что позволит разработчикам выявлять нежелательные действия ИИ. Во время тестирования специалисты Apollo обнаружили, что ИИ-модель симулировала согласованность с ожиданиями разработчиков и манипулировала задачами, чтобы казаться соответствующей поставленным требованиям. Она даже проверяла, следят ли за ней разработчики, перед тем как начать действовать. В итоге ИИ-модель следовала установленным правилам и инструкциям настолько, чтобы ею можно было пользоваться, но, одновременно с этим, продолжала сама определять приоритеты своих задач. Это связано с тем, что для ИИ правила могут быть слишком тяжёлым бременем, и машина, похоже, способна пренебречь ими, если это позволит легче выполнить задачу. В качестве примера исследователи OpenAI попросили o1-preview предоставить рецепт пирожного с онлайн-ссылками. Цепочка мыслей ИИ-модели — функция, которая должна имитировать то, как люди разбивают сложные идеи, — внутренне признала, что не может получить доступ к URL-адресам, что делало запрос исследователей невыполнимым. Однако вместо того чтобы сообщить об этом недостатке, o1-preview сгенерировала правдоподобные, но фальшивые ссылки и их описания. ИИ-модель o1 — это большой шаг на пути к высокоинтеллектуальным автономным системам, которые смогут, например, лечить рак или помогать в исследовании климата. Однако обратная сторона этой утопии может быть гораздо более мрачной. Хоббхан приводит пример: если ИИ будет сосредоточен исключительно на лечении рака, он может поставить эту цель превыше всего, даже оправдывая такие действия, как воровство или другие этические нарушения для её достижения. Согласно отчёту по безопасности, примерно в 0,38 % случаев модель o1-preview предоставляет информацию, которую её цепочка мыслей считает вероятно ложной, включая фальшивые ссылки или цитаты. Apollo обнаружила, что ИИ-модель может фабриковать данные вместо признания своей неспособности выполнить запрос. В редких случаях (0,02 %) o1-preview генерирует чрезмерно уверенные ответы, представляя сомнительную информацию как достоверную. Это может происходить в ситуациях, когда ИИ подталкивают дать ответ, несмотря на отсутствие уверенности в его корректности. Это поведение может быть связано со «взломом вознаграждения» во время обучения с подкреплением. Модель обучена отдавать приоритет удовлетворению пользователя, что иногда приводит к генерации согласованных или сфабрикованных ответов для удовлетворения запросов. Таким образом, модель может «лгать», поскольку усвоила, что это приносит ей положительное подкрепление. Что отличает эти новые ложные ответы от привычных проблем, таких как галлюцинации или фальшивые цитаты в более ранних версиях ChatGPT, так это элемент «взлома вознаграждения». Галлюцинации возникают, когда ИИ непреднамеренно генерирует неверную информацию из-за пробелов в знаниях или ошибочного рассуждения. В отличие от этого, взлом вознаграждения происходит, когда ИИ-модель o1 стратегически предоставляет неверную информацию, чтобы максимизировать результаты, которые она была обучена определять как приоритетные. Согласно отчёту по безопасности, o1 имеет «средний» риск в отношении химического, биологического, радиологического и ядерного оружия. Она не позволяет неспециалистам создавать биологические угрозы из-за отсутствия практических лабораторных навыков, но может предоставить ценную информацию экспертам для воспроизведения таких угроз. «Меня больше беспокоит то, что в будущем, когда мы попросим ИИ решить сложные проблемы, например, вылечить рак или улучшить солнечные батареи, он может настолько сильно усвоить эти цели, что будет готов нарушить свои защитные механизмы, чтобы достичь их. Я думаю, что это можно предотвратить, но мы должны следить за этим», — подчеркнул Хоббхан. Эти опасения могут показаться преувеличенными для ИИ-модели, которая иногда всё ещё испытывает трудности с ответами на простые вопросы, но глава отдела готовности OpenAI Хоакин Киньонеро Кандела (Joaquin Quiñonero Candela) считает, что именно поэтому важно разобраться с этими проблемами сейчас, а не позже. «Современные ИИ-модели не могут автономно создавать банковские счета, покупать GPU или предпринимать действия, представляющие серьёзные риски для общества. Мы знаем из оценок автономности ИИ-моделей, что мы ещё не достигли этого уровня», — отметил Кандела. Кандела подтвердил, что компания уже занимается мониторингом цепочек мыслей и планирует расширить его, объединив модели, обученные выявлять любые несоответствия, с работой экспертов, проверяющих отмеченные случаи, в паре с продолжением исследований в области выравнивания. «Я не беспокоюсь. Она просто умнее. Она лучше соображает. И потенциально она будет использовать эти рассуждения для целей, с которыми мы не согласны», — резюмировал Хоббхан. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


