







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexКак мы убедились раньше, искусственный интеллект является междисциплинарной отраслью науки и благодаря этому находит множество применений. Посмотрите на интеллект-карту ИИ по подходу:
Здесь наглядно показано, какие алгоритмы относятся к какому типу ИИ: символическому, субсимволическому и статистическому. Наверняка вы видите много новых терминов. Но обо всём по порядку.
1. Символьные методы — логические, основанные на высокоуровневом «символическом» (человекопонятном) представлении. Когнитивное моделирование, алгоритмы поиска на графах — это всё сюда. Мы подробнее остановимся на таких алгоритмах, как поиск в пространстве состояний (state-space search) и алгоритм А*. Символический ИИ преобладал в исследованиях ИИ с середины 1950-х до конца 1980-х годов. Джон Хогеланд дал название GOFAI («Старый добрый искусственный интеллект») символическому ИИ в своей книге 1985 года «Искусственный интеллект: сама идея», в которой рассматриваются философские последствия исследований искусственного интеллекта. Символический ИИ был предназначен для создания в машине общего интеллекта, тогда как большинство современных исследований направлено на конкретные подзадачи. Подход основан на предположении, что многие аспекты интеллекта могут быть достигнуты посредством манипулирования символами. Пример — экспертные системы. Экспертная система может заменить человека-эксперта, обрабатывая правила, чтобы делать выводы и определять, какая дополнительная информация ей нужна, то есть какие вопросы задавать, с использованием удобочитаемых символов.
К символическому ИИ также относят чат-боты, детерминированные игры с полной информацией (шашки, шахматы и т. д.).
2. Статистические методы в ИИ — это интеллектуальный анализ данных, теория информации, Байесовские методы принятия решений и скрытые модели Маркова.
-
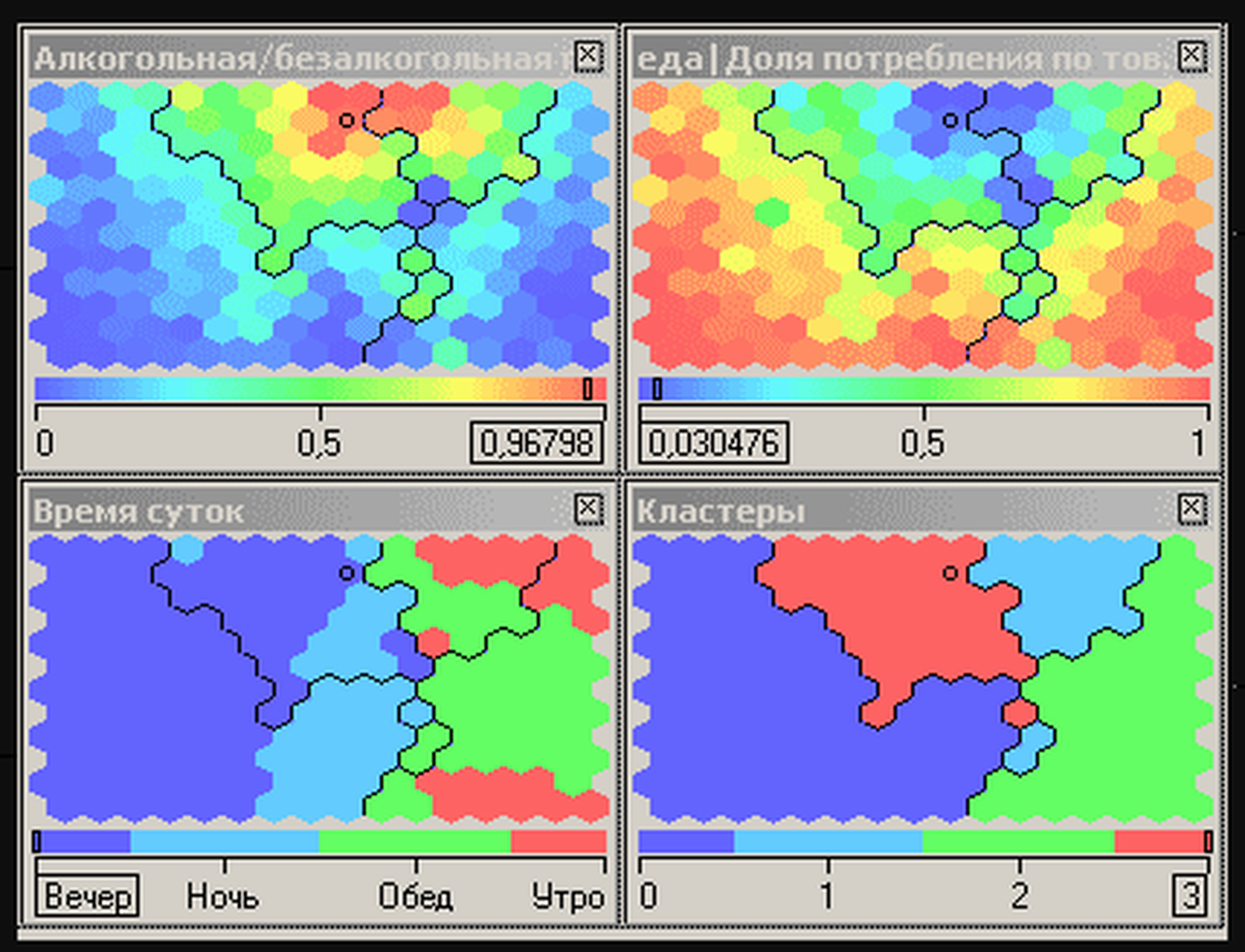
Интеллектуальный анализ данных (Data Mining) – исследование и обнаружение алгоритмами, средствами искусственного интеллекта в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации. Вот наглядный пример: предположим, вы хотите повысить лояльность своих клиентов. Для этого вам нужно провести качественную сегментацию, то есть не просто разделить своих клиентов на примитивные группы по полу и по возрасту, а использовать адекватные многомерные и желательно самообучающиеся алгоритмы сегментации. Например, это могут быть карты Кохонена, которые позволяют не только производить сегментацию объектов, но и выполнять визуализацию ее результатов. Посмотрите на эти карты — здесь клиенты разбиты на 4 сегмента (кластера) в зависимости от их предпочтений в продуктах питания, алкоголе и табаке и времени совершения покупок.
-
Термин «теория информации» введен в употребление в первой половине двадцатого века с подачи Клода Шеннона. Вам точно понадобится теория вероятности и матстатистика, чтобы разобраться в этой дисциплине. Это прикладная наука, изучающая закономерности, связанные с получением, хранением, обработкой и передачей информации. Теория информации используется для анализа процессов в биологии, психологии, компьютерной и телевизионной технике. Существуют энтропийный — вероятностный (шенноновский) и алгоритмический (колмогоровский) подходы к ТИ. Конечно, невозможно себе представить ИИ без теории информации.
-
Байесовские методы принятия решений используют теорию вероятностей для обработки неопределенности случайного характера и широко применяются в различных областях для анализа, прогноза и поддержки принятия решений. Мы вам расскажем о них на примере наивного байесовского классификатора — простого классификатора, который действует по формуле Байеса, наивно полагая, что наличие какого-либо признака в классе не связано с наличием какого-либо другого признака. Например, если я играю на балалайке, говорю по-русски и люблю Достоевского, то... нувыпонимаете. Каждый признак вносит свой независимый вклад в формирование стереотипа в принятии решения. Это очень удобный алгоритм, который, несмотря на свою «наивность», быстро работает на больших данных, часто лучше сложных алгоритмов классификации.
-
Скрытые модели Маркова. Конечно, как и другие алгоритмы, упомянутые в этой статье, они требуют более детального разговора. Сейчас мы просто создаём интуитивное понимание этих терминов, каждый из которых имеет формальное математическое определение. Теория скрытых марковских моделей не нова. Её основы опубликовал Баум и его коллеги в конце 60-х — начале 70-х годов. СММ может быть рассмотрена как простой пример байесовской сети доверия. Задачей при этом ставится разгадывание неизвестных параметров на основе наблюдаемых. Именно так врач ставит диагноз пациенту, наблюдая ряд симптомов заболевания. В ИИ СММ — это классический метод распознавания речи. Представьте, что у вас есть некое распределение фонем (звуков) на небольшом участке акустического сигнала — фрейме. Какая фонема была произнесена на этом фрейме? На этот вопрос сложно ответить однозначно — многие фонемы чрезвычайно похожи друг на друга. Но если нельзя дать однозначный ответ, то можно рассуждать в терминах «вероятностей»: для данного сигнала одни фонемы более вероятны, другие менее, третьи вообще можно исключить из рассмотрения. Собственно, акустическая модель — это функция, принимающая на вход небольшой участок акустического сигнала (фрейм) и выдающая распределение вероятностей различных фонем на этом фрейме. Таким образом, акустическая модель дает нам возможность по звуку восстановить, что было произнесено, — с той или иной степенью уверенности.
3. Субсимвольные методы в ИИ — если кратко, для них важны не столько сами элементы, сколько связи между ними.
В этой категории чаще всего интерес вызывают, конечно, нейронные сети. Нужно понимать, что искусственная нейронная сеть (ИНС) — это не что иное, как математическая модель, которая имитирует принципы работы биологических нейронных сетей. Помните наш исторический экскурс о первых нейросетях? Перцептро́н (англ. perceptron от лат. perceptio — восприятие) — математическая или компьютерная модель восприятия информации мозгом (кибернетическая модель мозга), предложенная Фрэнком Розенблаттом в 1957 году и впервые реализованная в виде электронной машины «Марк-1» в 1960 году. Перцептрон стал одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером. С точки зрения математики обучение нейронных сетей — это задача нелинейной оптимизации со множеством параметров. С точки зрения машинного обучения нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, кластеризации и т. д. ИНС состоит из искусственных нейронов, каждый из которых, как и живая нервная клетка, принимает сигнал, обрабатывает его и передает результат на другие. Существует несколько разновидностей нейронных сетей, пока достаточно будет упомянуть однослойные и многослойные — у первых сигналы от входного слоя сразу подаются на выходной слой, который преобразует сигнал и выдает ответ, а у вторых еще имеется один или несколько скрытых слоев. Уникальность нейронных сетей в том, что они не программируются в привычном смысле, а обучаются и способны обобщать информацию, делать верное заключение на данных, которых не было в обучающей выборке (training set), а также на данных, содержащих неточности, «шум» и т. д. Обучение нейронных сетей одним предложением — это поиск коэффициентов связей между нейронами.
Посмотрим еще раз на интеллект-карту. ИНС — это подмножество машинного обучения (machine learning), которое, в свою очередь, относится к мягким вычислениям (soft computing). К машинному обучению также относится метод опорных векторов (используется в задачах классификации — помню, как нам всем пришлось просить преподавателя объяснить ещё раз его математическую часть). Давайте разбираться по порядку, что есть что, пока глядя лишь с высоты «птичьего полёта».
Итак, машинное обучение — это метод искусственного интеллекта, который наделяет систему способностью автоматически обучаться на собственном «опыте», не будучи напрямую запрограммированной на все возможные решения проблемы. Процесс обучения заключается в поиске в данных закономерностей (patterns) и принятии всё лучших и лучших решений на основе имеющейся информации. Как говорят у нас, людей, «на ошибках учатся». Можно сказать, что конечной целью машинного обучения является автономное обучение системы (без помощи человека) с дальнейшей адекватной корректировкой действий. Существует много алгоритмов машинного обучения, и мастерство программиста заключается уже не в том, чтобы их запрограммировать, а в том, чтобы творчески подобрать или даже придумать для них подходящее приложение, что превращает работу в невероятно волнующий и интересный процесс. Очень популярны сейчас алгоритмы глубокого обучения — это своего рода машинное обучение следующего поколения, когда глубокой нейросети уже вообще ничего не надо объяснять — она сама в состоянии обучаться на неструктурированных данных (технически за счет большего количества скрытых слоев).
Поднимаемся на уровень выше… машинное обучение относится к так называемым мягким вычислениям — это понятие (1994) за авторством Лотфи Заде объединяет в общий класс неточные, приближённые методы решения задач, зачастую не имеющие решения за полиномиальное время. Сюда относится также нечеткая логика, вероятностные методы, эволюционное моделирование (особенно интересны алгоритмы swarm intelligence — роевые алгоритмы, которые мы подсмотрели в живой природе — у муравьев и т. д.), генетические алгоритмы и теория хаоса. Все их в рамках данного цикла рассмотреть не представляется возможным, но о генетическом алгоритме расскажем обязательно.
Конечно же, рассказ об алгоритмах ИИ может стать основой для целой книги — но для первого знакомства вы уже очень много знаете! Надеемся, что теперь вы приобрели структурированное представление о том, что же изучает ИИ и какие основные направления исследований сейчас актуальны — какое вам показалось особенно интересным?
Другие материалы цикла:











