MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Свёрточные нейронные сети — надежда и опора генеративного ИИ
Согласно определению из «Философского словаря», интеллект есть способность мыслить, т. е. совокупность тех умственных функций — включая сравнение, порождение абстракций, формирование понятий, суждений, умозаключений и проч., — что превращают восприятие (иными словами, неизбирательную фиксацию потока входящей информации) в знание (обладающее потенциалом практического действия структурированное понимание подноготной объекта, процесса, явления). В этом смысле генеративный ИИ — да и в целом модели машинного обучения — никаким интеллектом, ясное дело, не обладает. Наученная распознавать изображения кошечек с точностью 99,999% машина не способна сформулировать, что есть «кошечка» в её представлении, т. е. свести выработанные ею критерии этого самого распознавания к виду, заведомо постижимому биологическим оператором. А значит, прямого знания она ему не передаст, — лишь продемонстрирует результат работы своей интуиции. 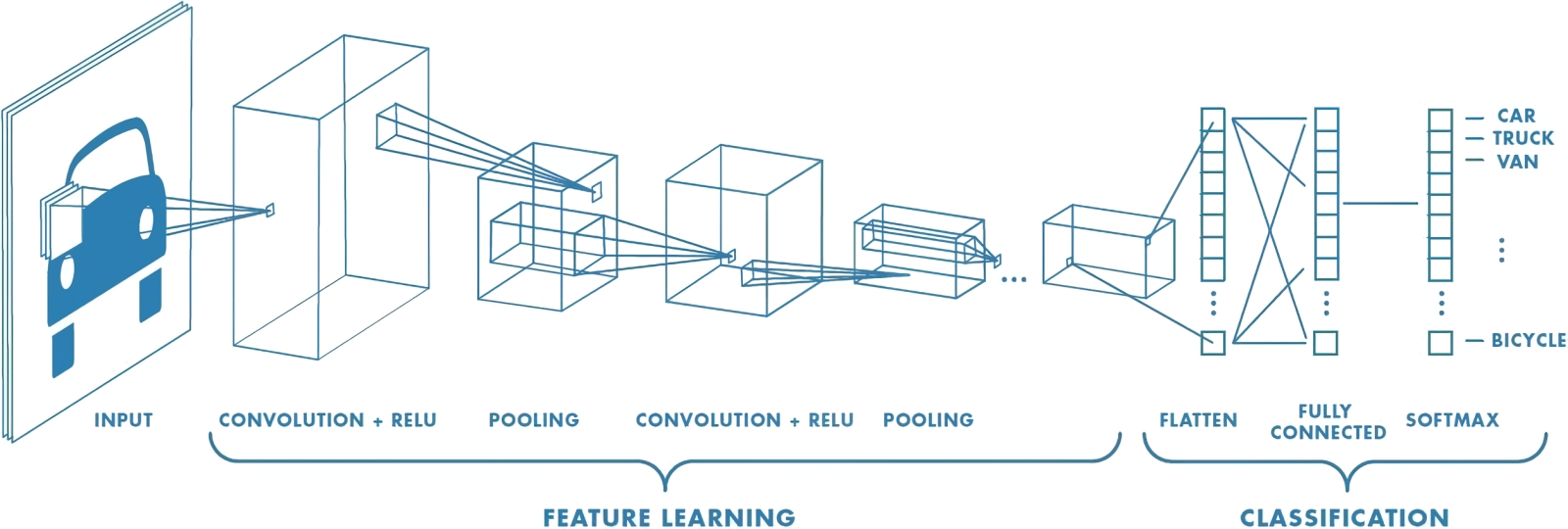
Общая схема работы нейросети, распознающей (классифицирующей) объекты на изображениях: feature learning — участок со свёрточными подсетями (источник: Saturn Cloud) Зато интуиция, согласно тому же словарю, — это переживание или вдохновенное постижение, приобретённое непосредственно. То бишь реализованное не путём интроспективного размышления (рефлексии), без которого непредставима работа интеллекта, а через подспудное, неосознаваемое в явном виде, неинтерпретируемое ухватывание (кто сказал: «Извлечение из латентного пространства»?) некой сути. Вот же она, корректная расшифровка второй литеры в акрониме «ИИ», — «интуиция»! Хорошо натренированная система просто берёт и ставит в соответствие одной оцифрованной сущности другую. Запросу «напиши за меня курсовую» — адекватно отвечающий определению «курсовой» убедительно складный текст; подсказке «заброшенный замок на мрачной скале» — проникнутую ожидаемым настроением картинку и т. д. Притом ни чуточки не рефлексируя в процессе выдачи над тем, в какой мере соответствуют действительности сделанные в тексте выводы или к какой исторической эпохе либо фэнтезийной вселенной могла бы относиться (если это не указано явно в подсказке) воспроизводимая в изображении структура. Интуиция в чистом виде. Роднит с человеческой интуицией (да и с животной, кстати, тоже — в отличие от развитого интеллекта это вовсе не видовая особенность Homo sapiens) работу генеративного ИИ и сам принцип действия цифровой нейросети. По многослойной плотной связке искусственных нейронов (перцептронов) проходят сигналы, формируя не поддающиеся адекватной интерпретации человеком промежуточные результаты, — но в итоге получается текст, или картинка, или иная выдача, вполне доступная для постижения тем же самым человеком. Более того, в ряде случаев ИИ справляется с задачами распознавания определённых объектов (на снимках из космоса, например) лучше занимавшихся этим годами живых операторов — просто потому, что не подвержен усталости, минутной рассеянности и иным влияющим на человека факторам. Ключевую же роль в процессе формирования искусственной интуиции — выявления в наборе входных данных закономерностей, не поддающихся чёткой фиксации, зато прекрасно работающих, — играют свёрточные нейронные сети. ⇡#Отбрасывая несущественноеВ первом приближении устройство и принцип действия компьютерных нейросетей мы уже описывали: будем надеяться, представление о перцептроне и о многослойной плотной нейронной сети унитарной размерности (с одним и тем же числом перцептронов в каждом слое) у внимательного и памятливого читателя уже имеется. И оно придётся, именно как основа, весьма кстати для понимания того, о чём мы собираемся говорить далее, — поскольку свёрточная нейронная сеть (convolutional neural network, CNN) отличается переменной размерностью: не все её слои равновелики. Именно за счёт этого она способна, как станет вскоре понятно, более эффективно — в сравнении с унитарной — решать поставленные перед нею практические задачи. Чаще всего — распознавание образов на статичных изображениях и видео, а также обработку определённых данных внутри более крупных генеративных моделей машинного обучения. 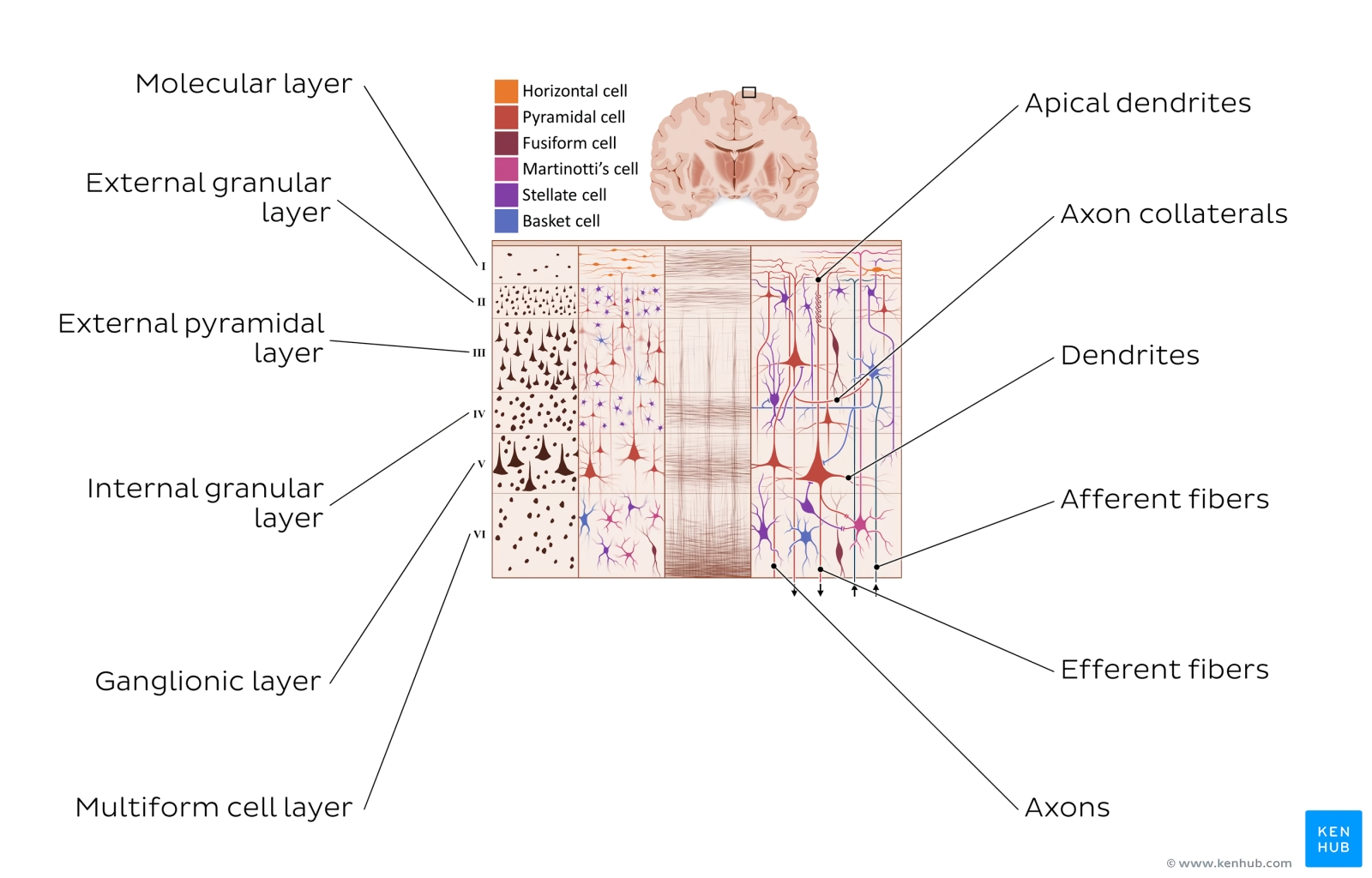
Различные слои и клетки коры головного мозга (источник: Kenhub) Откуда вообще взялась идея усложнить конструкцию нейросети, дифференцировав различные её слои? Начнём с того, что такая эталонная природная нейросетевая структура, как кора головного мозга человека, существенным образом неоднородна. Даже не говоря уже о том, что в ней выделяются зоны, выполняющие различные задачи (распознавание речи, восприятие тактильных ощущений и т. п.), сама кора в целом многослойна, причём различные участки её слоёв устроены по-разному и содержат разные же — и по габаритам, и по числу образуемых связей — нервные клетки. Более того: даже в пределах одного уровня одного и того же слоя активность разных нейронов может значительным образом различаться. В частности, зрительная кора, благодаря которой в сознании формируется визуальная картина окружающего мира, составлена из весьма неоднородных клеток. У каждого из зрительных нейронов имеется своё рецептивное поле — участок с рецепторами, реагирующими на те или иные стимулы. Например, для ганглиозной клетки сетчатки глаза рецепторами служат знакомые по школьному курсу физиологии человека палочки и колбочки — клетки, реагирующие на силу воспринимаемого света и/или его спектральный состав. В свою очередь, определённая совокупность ганглиозных клеток работает в качестве рецептивного поля для нейрона, расположенного уже в зрительной коре головного мозга — в затылочной его части, довольно далеко от сетчатки. И критерии срабатывания этих нейронов довольно избирательны: к примеру, часть нейронов в зрительной зоне V1 возбуждается исключительно в ответ на появление в поле зрения вертикальных структур (сплошных линий — либо выстроенных по вертикали точек, штрихов и т. п.), а другая часть — только горизонтальных. 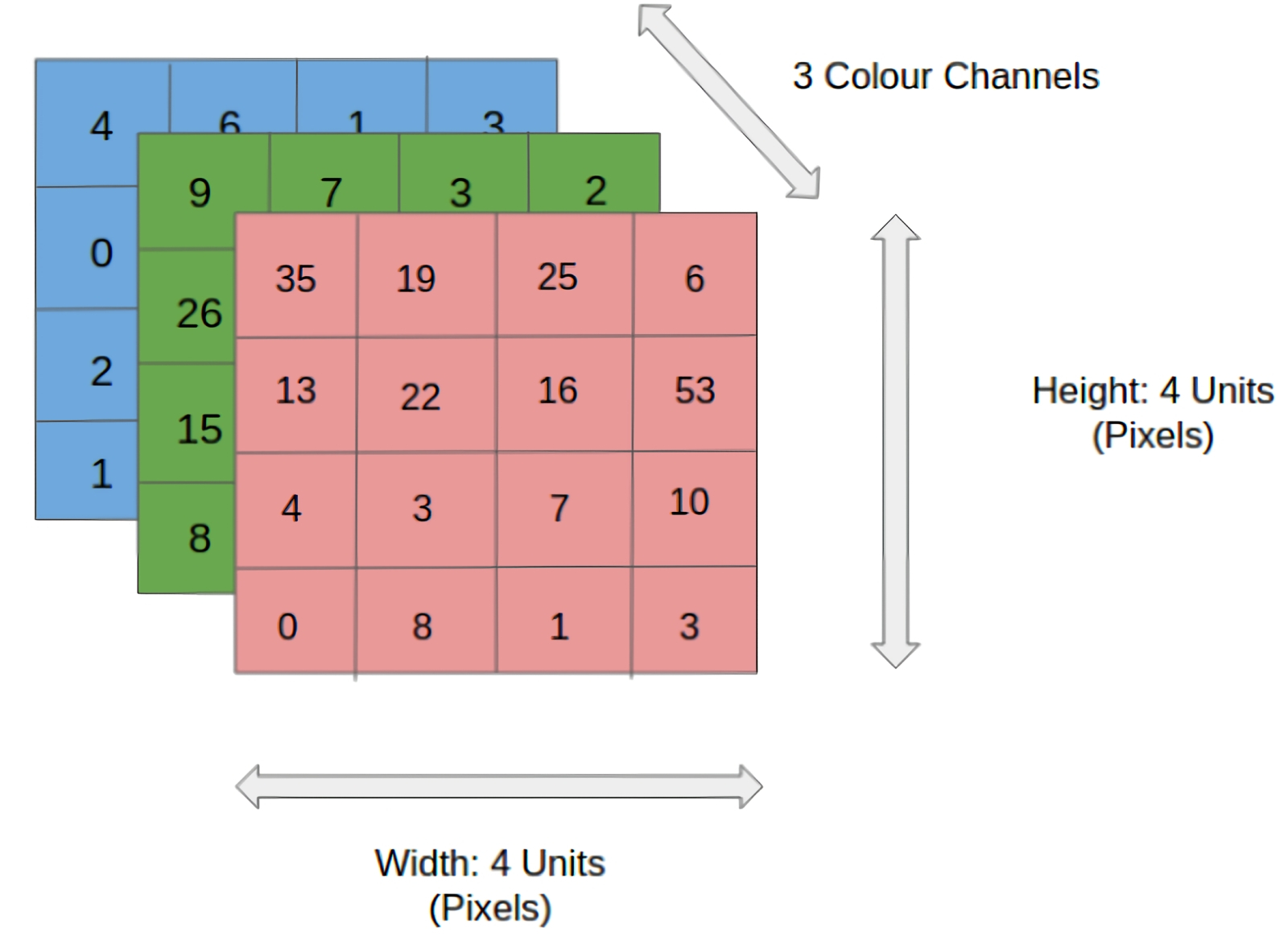
Кодирование цветного изображения 4 × 4 × 3 — с разбиением на квадрат 4х4 пискела и заданием трёх каналов цветности (источник: Saturn Cloud) Помимо очевидного соображения «раз эволюция выбирает для обработки визуальных данных нейросети с понижением размерности в последующих слоях, это может оказаться наиболее эффективно», для предпочтения CNN машинным сетям унитарной размерности есть и другое обоснование, не менее убедительное: технико-экономическое. Допустим, некая квадратная цветная картинка в первом грубом приближении может быть закодирована всего 16 пикселами, — в сетке 4 × 4 (схожую задачу, только в обратную сторону, решают системы преобразования текстовых подсказок в изображения, вроде рассматривавшейся нами ранее Stable Diffusion: они мозаику из разноцветных крупных пятен преобразуют, постепенно добавляя в нужных местах нужного «шума», в идентифицируемое человеком изображение). Кстати, не стоит забывать, что для сохранения информации о цвете потребуется сформировать уже три матрицы 4 × 4 — для красного, зелёного и синего каналов. Таким образом, запись данных даже о столь грубо закодированной картинке будет представлена не 16, а 48 числами (кодировка 4 × 4 × 3, где первые два значения соответствуют размерности изображения, а последнее указывает на число цветовых каналов: если выбрать кодировку CMYK, последних станет уже 4). Да, технически совсем не сложно преобразовать эти 48 чисел из матричного формата в векторный (из нескольких таблиц — в единый столбец) и подать получившуюся последовательность данных на вход унитарной полносвязной нейросети с обратным распространением ошибок — пусть выискивает там закономерности. Но с ростом габаритов исходной картинки задача становится всё менее подъёмной. Для кодирования обоев «Рабочего стола» в Full HD понадобится 1920 × 1080 × 3 ≈ 6,22 млн чисел — вот почему, кстати, формат BMP (картинки в котором примерно схожим неэкономным образом и сохранялись) к настоящему времени практически вышел из употребления: слишком уж непрактично тяжёлыми становятся представленные в таком виде файлы. Понятно теперь, что и нейросеть для обработки изображений в высоком разрешении — будь то классификация объектов на них или же, напротив, создание картинок по текстовым подсказкам — нуждается в понижении размерности; из соображений хотя бы разумной достаточности затрачиваемых на её функционирование вычислительных мощностей. Но каким именно образом производить это понижение? ⇡#Только не в трубочку!Собственно, «свёрточная» в названии CNN как раз и указывает на способ, применяемый для понижения размерности слоёв нейросети и именуемый попросту свёрткой. Интуитивно ясно, что «свернуть» в приложении к данным значит не просто «сократить» (тогда логичнее было бы сказать «обрезать» или «округлить»), а «компактифицировать с сохранением наиболее важной информации». И вот каким образом это делают CNN.
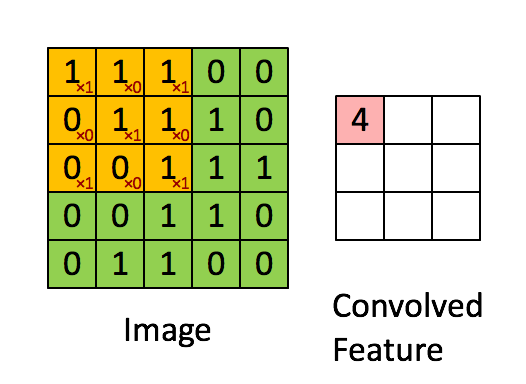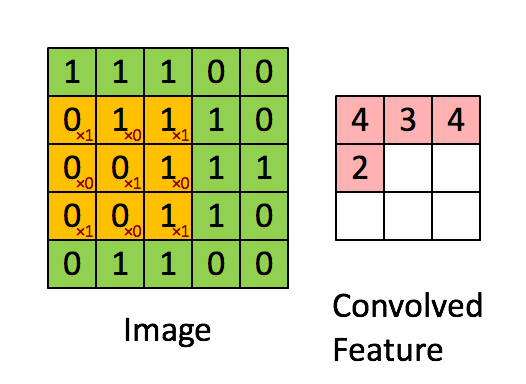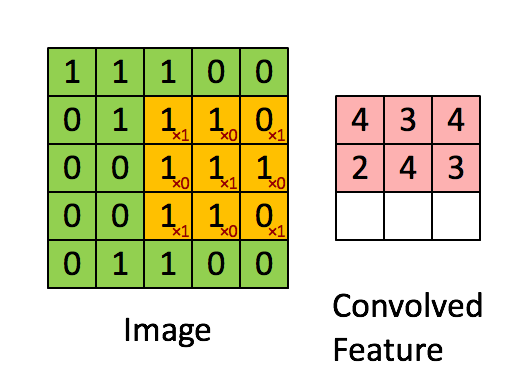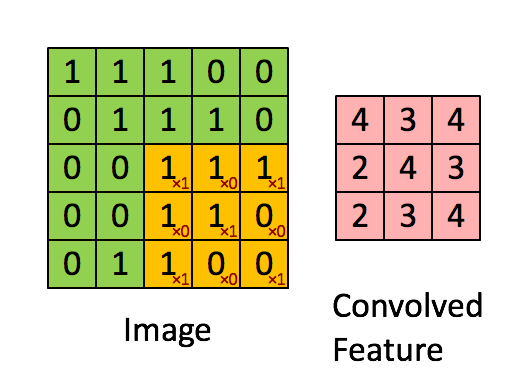
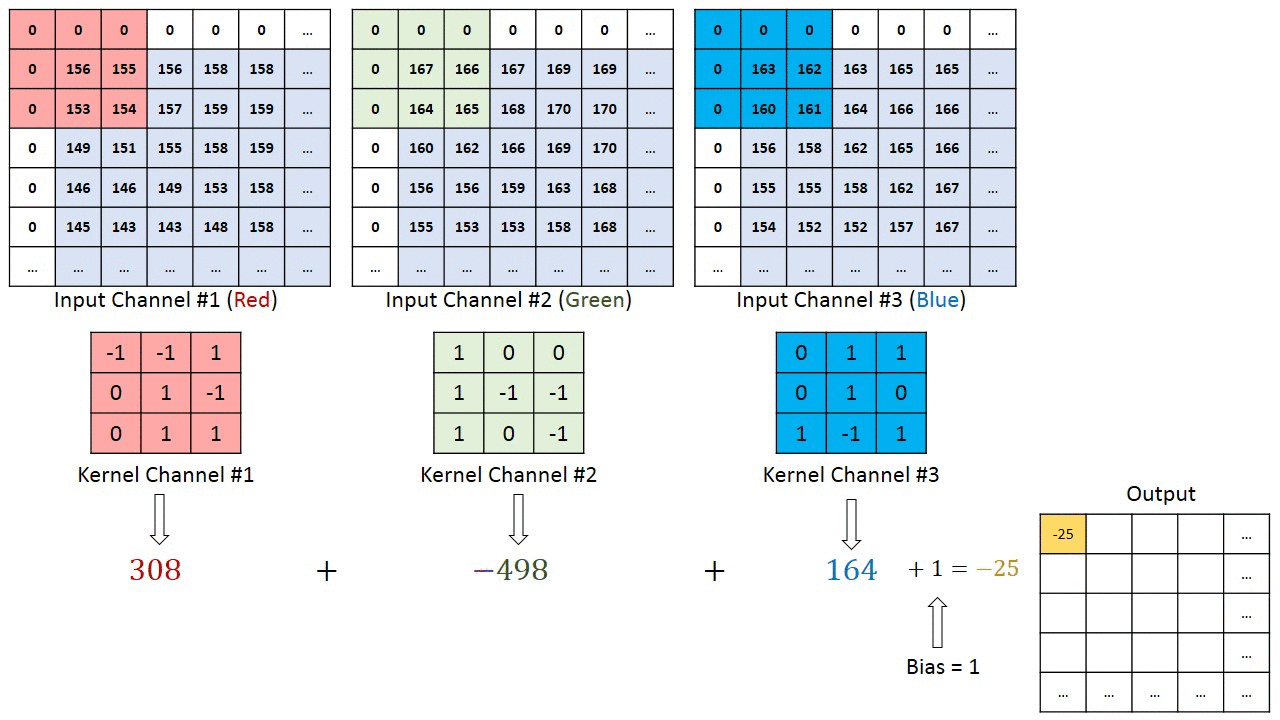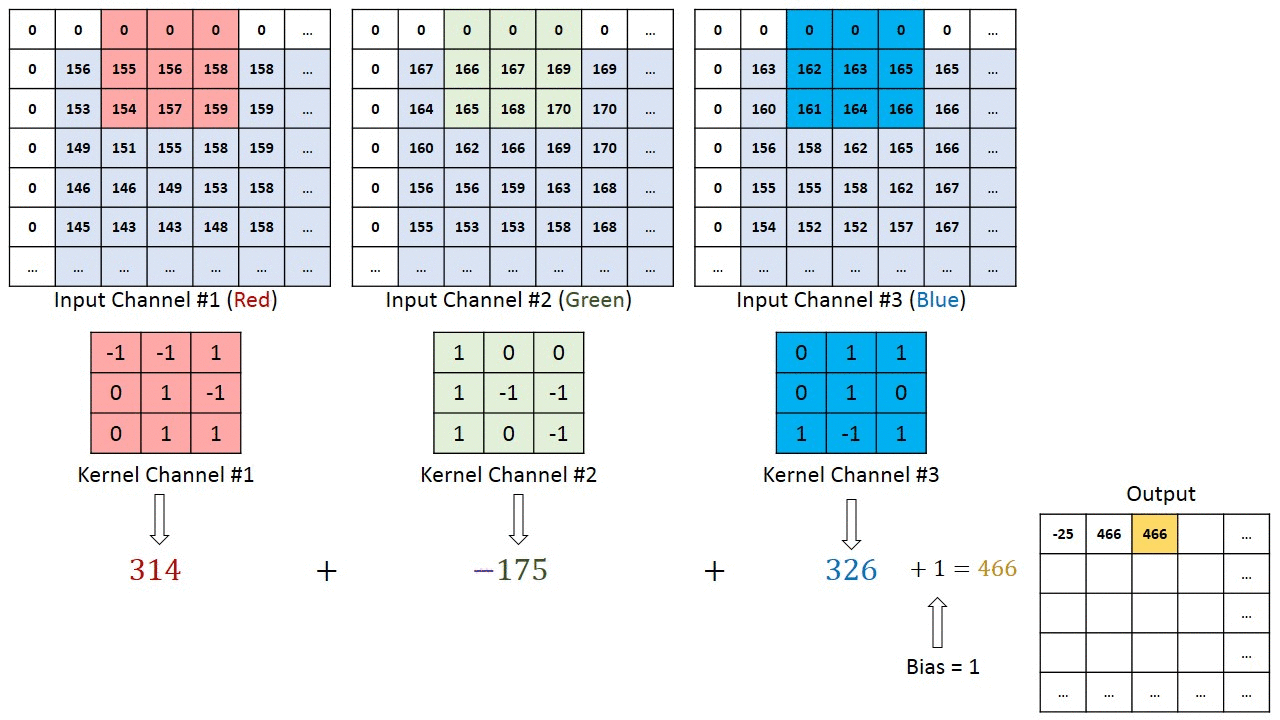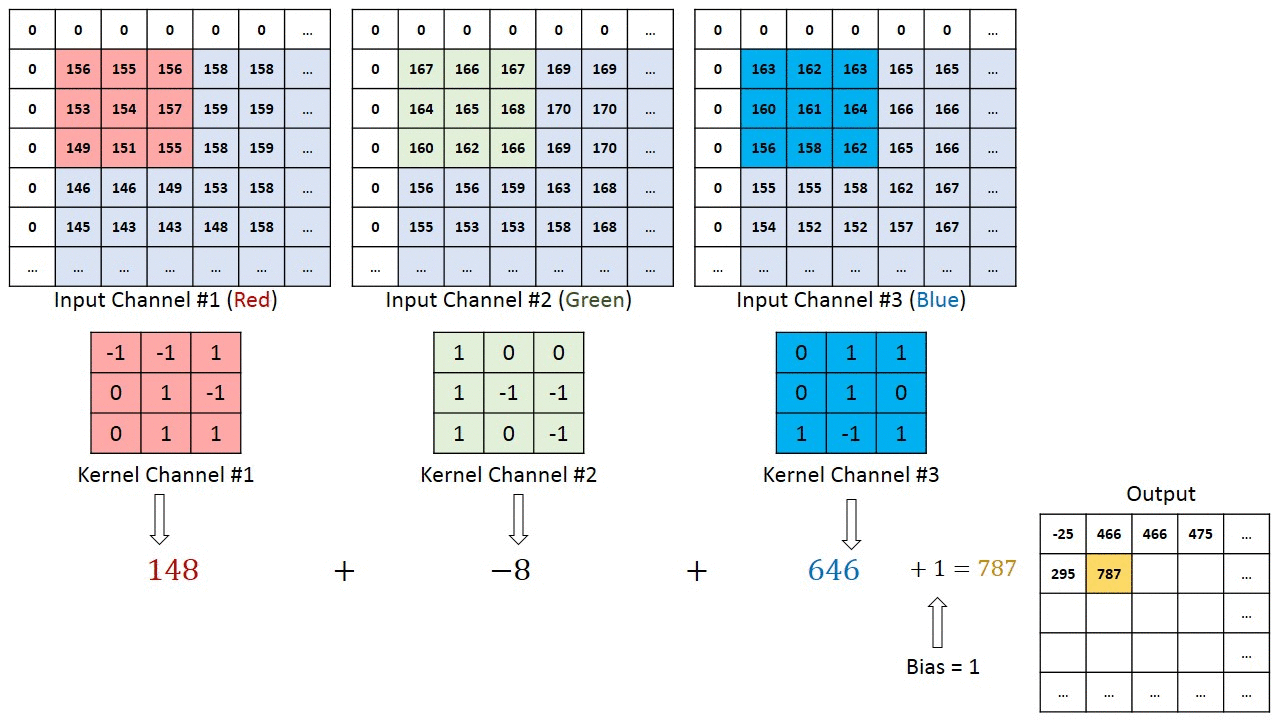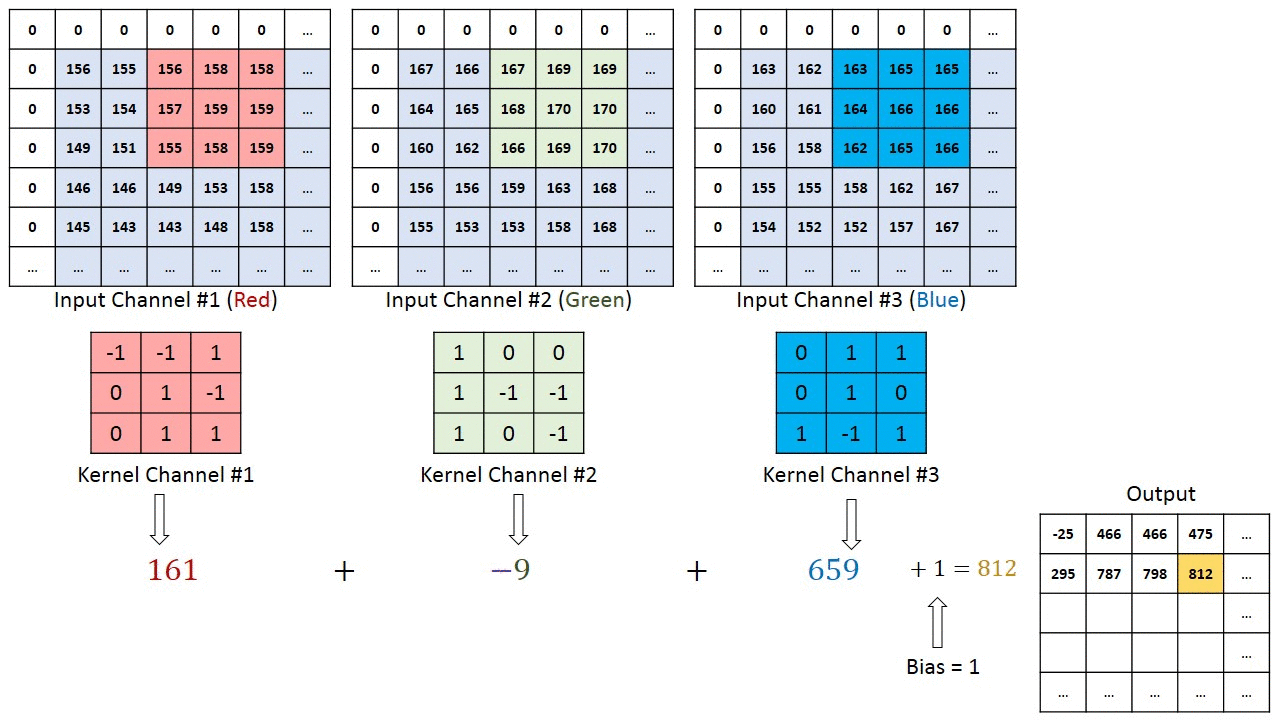
Последовательное применение операции свёртки к одному из слоёв исходного оцифрованного изображения (источник: Saturn Cloud) Пусть имеется исходная матрица значений — допустим, пикселы какого-то изображения — высокой размерности. В нашем примере — 5 × 5 (точнее, 5 × 5 × 1, — не будем забывать, что каждой позиции может соответствовать не просто число, но вектор, кодирующий некую дополнительную информацию). Для операции свёртки применяется так называемое ядро или фильтр (kernel/filter) — небольшая матрица весов, представленных обычно целыми числами. Точно так же, как веса на входах перцептронов, составляющие ядро весовые компоненты могут (и должны, в общем случае!) корректироваться в процессе работы нейросети методом обратного распространения ошибки, но пока для определённости примем, что ядро — фиксированная матрица 3 × 3 следующего вида: 1 0 1 0 1 0 1 0 1 Собственно свёртка заключается в:
Квадрат 3 × 3 допускает перемещение по матрице 5 × 5 со сдвигом на одну позицию (без выхода за её пределы) ровно три раза и по горизонтали, и по вертикали — потому в рассматриваемом примере выходная матрица будет иметь размерность 3 × 3. Если бы при том же ядре (3 × 3) исходная матрица была 7 × 7, выходная получила бы уже размерность 5 × 5. 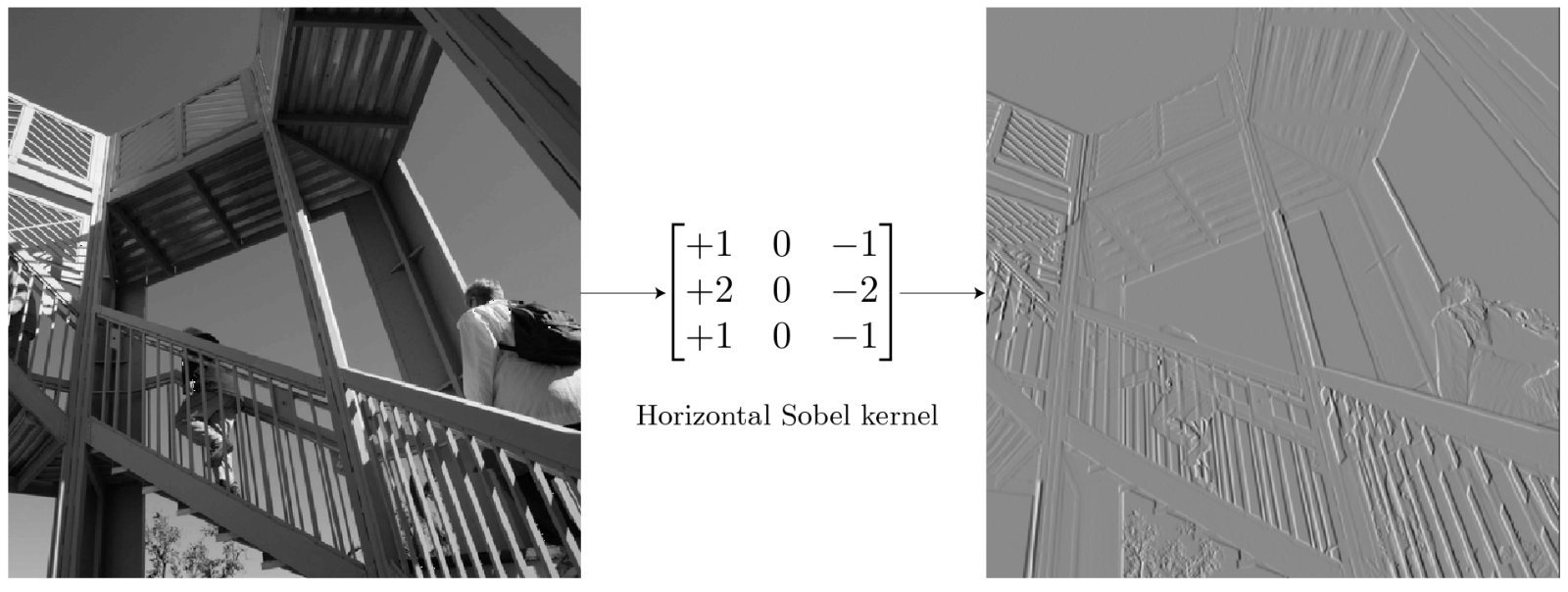
Классический фильтр Собеля производит свёртку исходного изображения по одному из измерений, явственно выделяя края вытянутых в этом же измерении структур (источник: TowardsDataScience) Сегодня практически у каждого под рукой, а именно в предустановленном почти на любой смартфон простеньком фоторедакторе, имеется аналоговый свёрточный фильтр Собеля — средство для усиления границ объектов на изображении. В частности, горизонтальный фильтр Собеля представляет собой матрицу +1 0 –1 +2 0 –2 +1 0 –1 при умножении исходного изображения (в оцифрованном виде, конечно) на которую пропадают малоконтрастные детали, а резкие границы ещё более усиливаются. Причина в том, что в ходе такой операции соседние пикселы — ячейки исходной матрицы — с примерно равными величинами (в данном случае яркости) после свёртки с матрицей-фильтром дают на выходе близкие к нулю значения, а если соседние значения в ячейках сильно разнились, то в результате эта разница окажется существенно усиленной. Собственно, в этом и состоит цель свёртки: не просто понизить размерность изначальной матрицы в целях снижения вычислительной нагрузки на аппаратную часть системы, — но выявить в исходном массиве данных некие закономерности, причём в различных каналах (т. е. на каждом этапе свёртка производится не с одним, а с несколькими фильтрами, и далее эти потоки данных — каналы — обрабатываются раздельно). Очередная операция свёртки преобразует входной массив данных в очищенный линейный блок (rectified linear unit, ReLU), что представляет собой карту усиленных (за счёт отбрасывания всего малозначимого; отсюда термин «очищенный») отличительных особенностей этого массива, в которой с каждой итерацией всё более и более явно проступают нелинейные связи между её компонентами.
Если исходное изображение оцифровано трёхканальной матрицей M × N × 3, для корректной свёртки могут потребоваться разные фильтры для каждого из цветокодирующих каналов (источник: Saturn Cloud) Однако не следует забывать, что интерпретировать сколько-нибудь явным (постижимым для человеческого сознания) образом результаты свёртки имеет смысл лишь в том случае, когда эта операция применяется к самой первой матрице данных — в рассматриваемом примере к оцифрованному и разбитому на пикселы изображению. Современные же нейросети существенно многослойны, и, когда операция свёртки выполняется для одного из глубинных (скрытых) слоёв модели, да ещё и с применением фильтра со скорректированными в процессе обратного распространения ошибки весами, уже по сути невозможно зафиксировать смысловое наполнение получаемых в итоге этой операции величин. На этом, собственно, и основано предложение сопоставлять работу ИИ с интуицией и наитием, а не со строго логичными операциями естественного интеллекта. Помимо свёртки с понижением размерности и единичным сдвигом фильтра по исходной матрице применяются и другие операции, такие как сдвиг с перескоком ядра на 2 ячейки (в этом случае может потребоваться дополнение исходной матрицы строками и/или столбцами с нулевыми значениями, чтобы соблюсти размерность) и даже «раздувание» — своего рода обратная свёртка, на выходе которой получается матрица большей размерности. Свёрточная арифметика — существенно важная для области глубокого машинного обучения дисциплина, но углубляться в неё в рамках обзорной статьи было бы излишним. 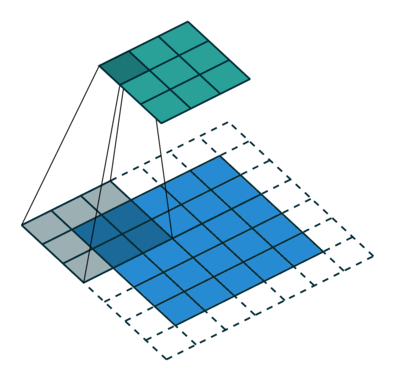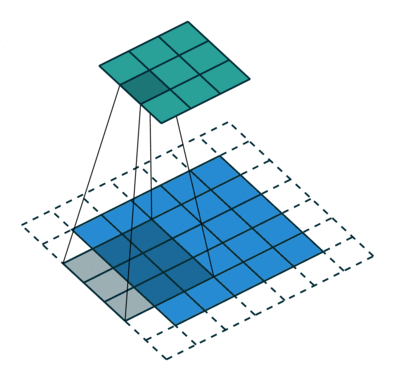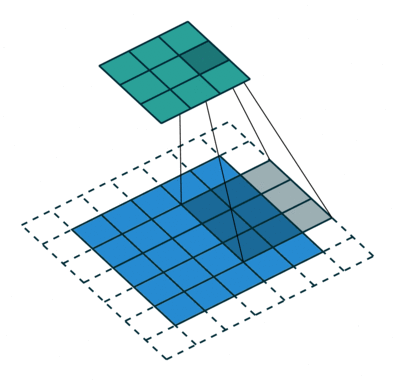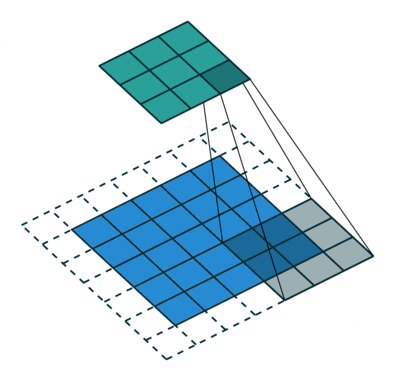
Если исходное изображение оцифровано трёхканальной матрицей M × N × 3, для корректной свёртки могут потребоваться разные фильтры для каждого из цветокодирующих каналов (источник: Saturn Cloud) Поскольку сами свёрточные слои располагаются один за другим последовательно (переложенные слоями группировки, речь о которых пойдёт чуть ниже), это позволяет выявлять в исходном массиве данных скрытые закономерности всё более высокого уровня — от обнаружения пары горизонтальных и пары вертикальных отрезков переходить к отождествлению изображённого на картинке квадрата, например. Грубо говоря, схожий принцип лежит в основе процесса устойчивого размывания (stable diffusion), благодаря которому нейросеть сперва обучают ставить в соответствие термину «квадрат» (точнее, кодирующему его набору токенов) вполне определённые веса на свёрточных матрицах, а затем инвертируют процесс — так что из исходной мешанины разноцветных пятен по соответствующей подсказке за несколько итераций проступает вполне геометрически правильная фигура. После свёртки отдельные слои в ИИ-модели подвергаются несколько иной, хотя во многом и схожей операции — объединению, или группировке (pooling). Вместо того чтобы — как в случае свёртки — поэлементно перемножать фрагмент исходной матрицы на весовые коэффициенты фильтра и затем суммировать полученное, при группировке производится вычисление некой статистической функции для фрагмента исходной матрицы, покрытого фильтром-ядром. Эта функция чаще всего оказывается простым «максимальным значением»: если выборка 3 × 3 выделила такой вот фрагмент матрицы — 3 3 2 0 0 1 3 1 2 — то «максимальным значением» для взятых таким образом элементов в данном случае окажется «3» (а если бы хотя бы в одной ячейке оказалась четвёрка — тогда было бы «4»). Можно применять и более ресурсоёмкую функцию — вычисление среднего. Суть процедуры группировки заключается, во-первых, в понижении размерности матрицы (что опять-таки облегчает нагрузку на аппаратную часть ИИ-системы), а во-вторых — в более эффективном, чем у свёртки, выявлении инвариантных признаков представленного исходной матрицей объекта. Грубо говоря, если прямоугольное окно показано на оцифрованной картинке в перспективе, да ещё и снято под углом (dutch angle shot), для отождествления такого объекта нейросетью именно как окна одних свёрточных слоёв потребуется в общем случае больше, чем если комбинировать их с группировочными. Объединение в целом оптимизировано для обнаружения обобщённых и высокоуровневых признаков, не сводимых к простым геометрическим закономерностям, — с последним как раз лучше справляется свёртка. 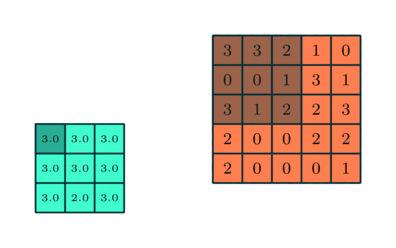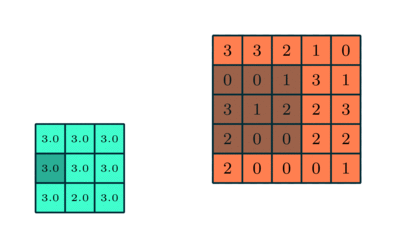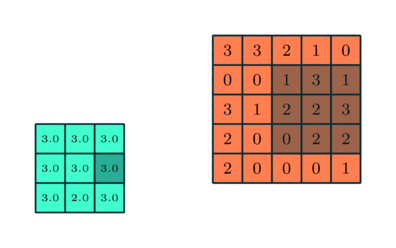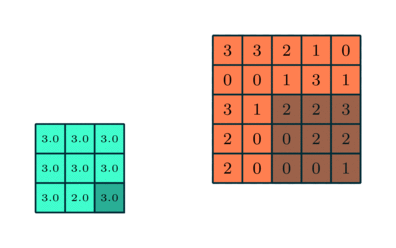
Операция группировки с выборкой максимального значения в каждом из фрагментов исходной матрицы, покрываемом на очередном шаге фильтром (источник: Saturn Cloud) Обыкновенно в системах машинного обучения, ориентированных на распознавание образов, свёрточные и группировочные слои в каждом канале располагаются парами, причём число таких пар может быть весьма велико. В результате на каждом уровне обработки исходной матрицы (разбитого на пикселы изображения) исходная картинка порождает абстракции всё более высокого уровня, отбрасывая несущественные детали — включая шум, незначительные цветовые градиенты и даже частичное затенение/перекрытие. Скажем, античная колонна, видимая сквозь ветви деревьев, будет в итоге классифицирована благодаря свёрткам — и в особенности группировкам — именно как единый цельный объект заднего плана. Однако чтобы разглядеть «образ античной колонны» в ячейках соответствующей матрицы в глубине свёрточной нейросети, представленный в виде целого ряда заполненных числами таблиц, любопытствующему энтузиасту понадобятся сверхспособности — вроде тех, которыми обладали «натуральные» (рождённые вне Матрицы) операторы из культовой киносаги братьев Вачовски. ⇡#Что здесь?В приведённом примере с нейросетью, ориентированной на распознавание визуальных образов, структура самой этой сети разделена на два крупных блока: «выявление особенностей» (feature learning) и собственно «категоризация» (classification). Причём если над выявлением особенностей трудится многослойная подсеть из пар свёрточных и группировочных слоёв, то классификацией занимается тоже многослойная, но уже унитарная полносвязная подсеть, в которой каждый слой образован одним и тем же числом перцептронов. «Полносвязная» в данном случае означает, что выходы каждого из перцептронов предыдущего слоя передают сигналы на входы каждого из искусственных нейронов последующего. 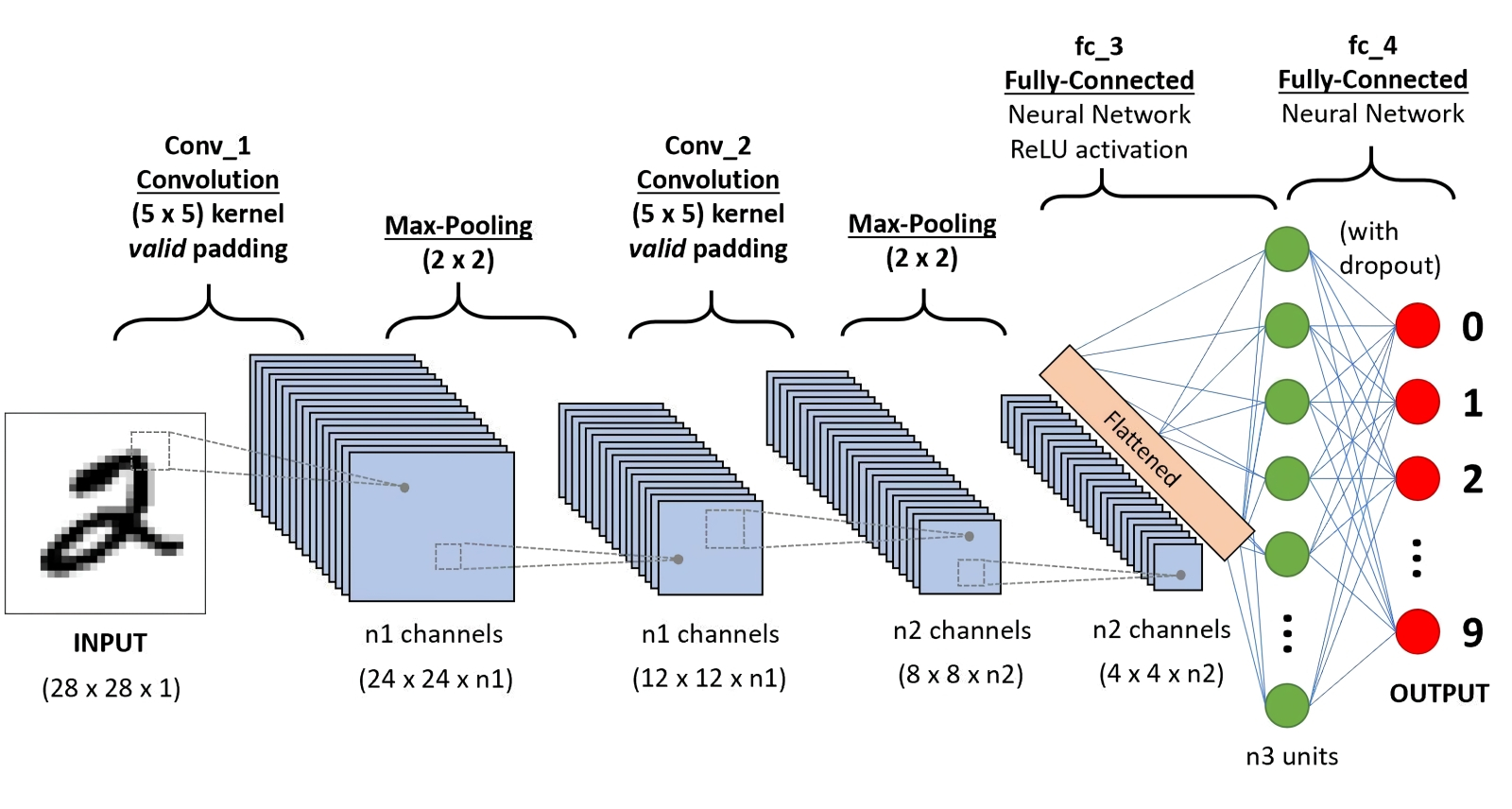
Принципиальная схема CNN, применяемой для распознавания рукописных цифр: после двукратного повторения операций свёртки и выборки во множестве каналов выдача «уплощается» из матрицы в вектор и передаётся на вход полносвязной плотной нейросети (источник: Saturn Cloud) Строго говоря, такая полносвязная сеть и сама в состоянии заниматься уверенным распознаванием образов, — в предыдущем материале на эту тему мы для примера рассматривали устройство именно такой сети с обратным распространением ошибок, занятой идентификацией рукописной тройки. Другое дело, что для крупных, высокодетализированных изображений распознавание через полносвязную унитарную сеть обойдётся слишком дорого — и по времени, и по затраченным аппаратным ресурсам, и по расходу электроэнергии. Блок выявления особенностей, производящий раз за разом операции свёртки и группировки, нужен именно для того, чтобы самым существенным образом понизить размерность исходного массива данных, сохранив притом всю содержавшуюся в нём ключевую информацию (в закодированном, многократно преобразованном виде, конечно). И вот уже этот высокорафинированный (многократно ректифицированный, если вспомнить о ReLU) набор данных подаётся на вход полносвязной нейросети, отлично справляющейся с задачей классификации по существенно разнородным признакам, — как и было продемонстрировано нами ранее. Причём здесь не имеет значения, каких размеров был исходный массив: полносвязная нейросеть в любом случае будет работать с одномерным и сравнительно недлинным вектором данных. Получается он крайне незамысловато: допустим, исходное изображение обрабатывалось в блоке выявления особенностей по 50 каналам, каждый из которых на выходе серии операций свёртки и группировки выдал по одной матрице 3 × 3. Эти матрицы преобразуются в векторы (первая ячейка в первой строке становится первым элементов вектора, последняя — третьим, первая во второй строке — четвёртым и т. д.), а затем векторы точно так же прямолинейно выстраиваются в один общий — размерностью в данном случае 450 × 1. Дальнейший процесс классификации на полносвязной нейросети с обратным распространением ошибок должен уже быть в общих чертах знаком нашим читателям. Свёрточные сети в течение многих лет исправно служили делу машинного зрения, поскольку ранее для выявления важнейших особенностей изображений применялись статичные инструменты, вроде упомянутого ранее фильтра Собеля. CNN же с обратным распространением ошибок для тонкой настройки фильтров в процессе обучения дали возможность, в частности, автоматизировать выявление определённых объектов на фото/видео, — причём делать это на сравнительно скромной аппаратной базе, включая интегрированные чипы не самых дорогостоящих веб-камер. Однако в последнее время у них появилось ещё более впечатляющее (по крайней мере, для заметной части интернет-аудитории) приложение: работа в составе генеративно-состязательных сетей (generative adversarial networks, GAN). Тех самых, что после обучения на обширном массиве аннотированных визуальных данных становятся способны сами создавать изображения объектов реального либо фантастического мира — с человеческой точки зрения вполне достоверные. Ну или абстрактные/сюрреалистичные, но ровно в той степени, в какой этого ожидает составивший соответствующую текстовую подсказку оператор. Наиболее общим образом генеративное моделирование — кстати, не так уж и важно, чего именно: изображений, видеоряда, звуков или текстов — определяется как результат автоматизированного (т. е. реализуемого в ходе машинного обучения в отсутствие учителя, unsupervised learning) выявления неких закономерностей в большом массиве входных данных с последующим применением полученной модели для порождения настолько правдоподобных с точки зрения человека-оператора объектов аналогичной природы, что они могли бы быть включены им в исходный массив тренировочной информации. Звучит несколько уроборосно, но по сути так оно и есть: цель генеративного моделирования — машинное порождение таких сущностей (для определённости — картинок), которые, на взгляд человека, оказались бы неотличимы от созданных другими людьми. Действительно, генеративный ИИ, однажды натренированный с получением фиксированной модели (определённого набора весов на входах всех своих перцептронов, — того, что в ИИ-рисовании принято называть чекпойнтом), прекрасно справляется с самостоятельным — в отсутствие дополнительного стороннего надзора — рисованием картинок по текстовым подсказкам: в этом читатели соответствующих «Мастерских» могли убедиться на собственном опыте. Но вот чтобы такой чекпойнт натренировать, необходимо уже обучение с учителем (supervised learning) в рамках упомянутой чуть выше генеративно-состязательной сети. Оно подразумевает деятельную совместную — да вдобавок ещё и состязательную! — работу двух ИИ-моделей, выступающих соответственно в ролях творца (generator) и критика (discriminator). 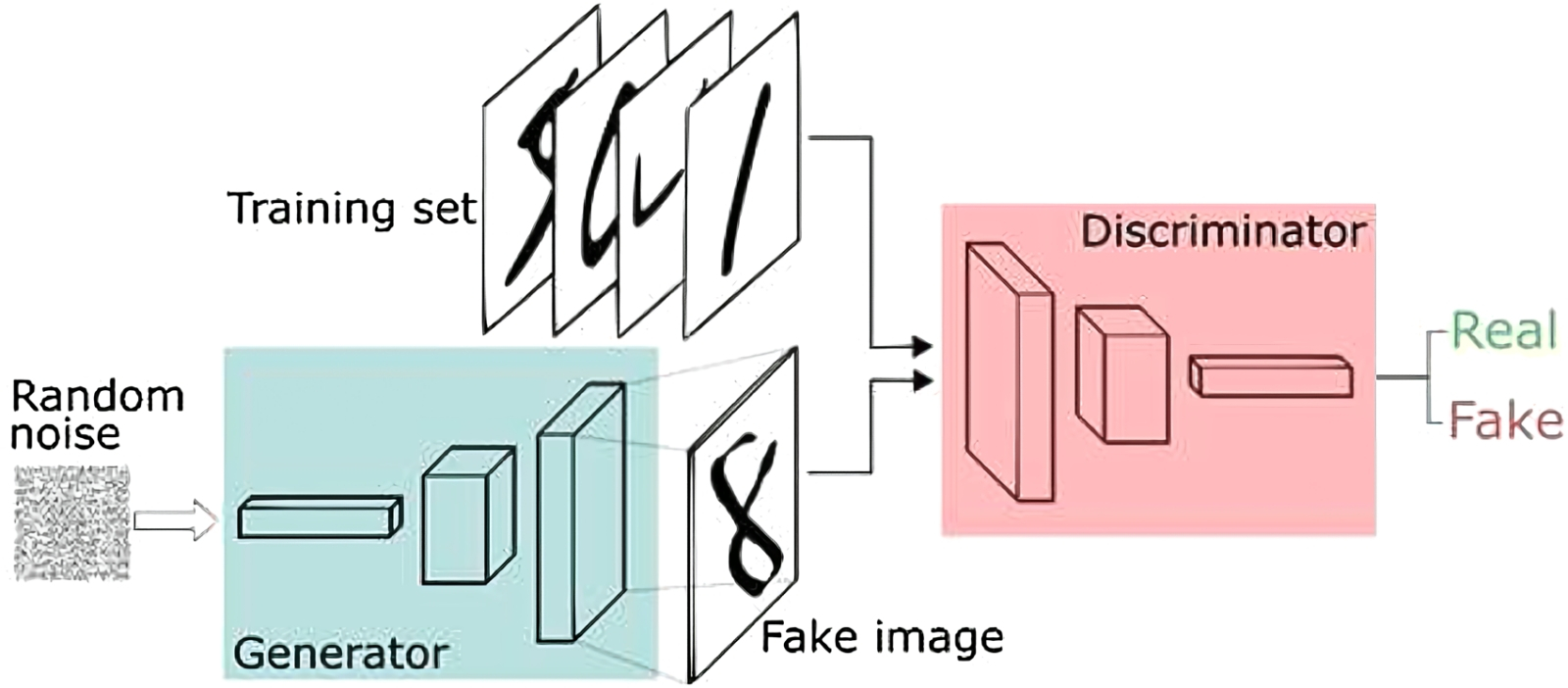
Структура типичной GAN: на вход предварительно натренированного генератора подаётся белый шум, на основе которого создаётся «поддельный» (не входивший в тренировочный набор данных) образ, — а дискриминатор, анализируя тот же исходный набор (но не прямым перебором, а тоже как нейросеть), решает, фейковую ему предложили картинку или нет (источник: Journal of Real-Time Image Processing) Генератор натренировывается на создание новых образов на основе переработки исходного массива данных; дискриминатор же пытается распознать, принадлежит очередное полученное генератором изображение к обучающему пулу — или разительно отличается от него. Окончанием обучения обычно считается момент, когда критик начинает принимать за априори входящие в исходный массив картинки более половины из тех, что создаёт творец. То бишь в данном случае «обучение с учителем» подразумевает участие не живого оператора, а ещё одной ИИ-модели, задача которой — проверять, успешен ли генератор в создании обманчиво правдоподобных изображений. Или синтезированных под человеческий голос фраз, или притворяющихся авторскими текстов, — словом, всего, что поддаётся оцифровке для формирования первичного (тренировочного) пула данных. Важно, что обе модели в составе GAN обучаются одновременно: как генератор со временем становится успешнее в создании походящих на исходные сущностей, так и дискриминатор — в выявлении недостоверных. Так вот, одним из наиболее распространённых подходов при построении GAN стала архитектура глубоких свёрточных генеративно-состязательных сетей (deep convolutional generative adversarial networks, DCGAN). Достоинство её в том, что DCGAN ощутимо снижает вероятность обрушения режима (коллапса режима, mode collapse) в ситуации, когда разброс вариативности выдач генератора оказывается значительно ýже, чем широта исходного набора данных по некоторому параметру. Это своего рода аналог перетренировки перцептронной модели, о которой шла речь в одном из прежних наших материалов: если в ответ на текстовую подсказку «собака» чекпойнт, которому добросовестно скармливали в процессе обучения множество изображений самых разных пород, с вероятностью 0,6 рисует шарпеев, а с вероятностью 0,4 — колли, это прямое свидетельство обрушения режима. Загвоздка здесь в том, что, поскольку тренировка генератора производится в отсутствие человеческого присмотра, а машина на данном этапе технологической эволюции всё-таки не мыслит, mode collapse автоматически крайне сложно отловить: дискриминатор ведь исправно подтверждает, что получаемые им для проверки изображения шарпеев и колли вполне адекватны имеющимся в тренировочной базе. 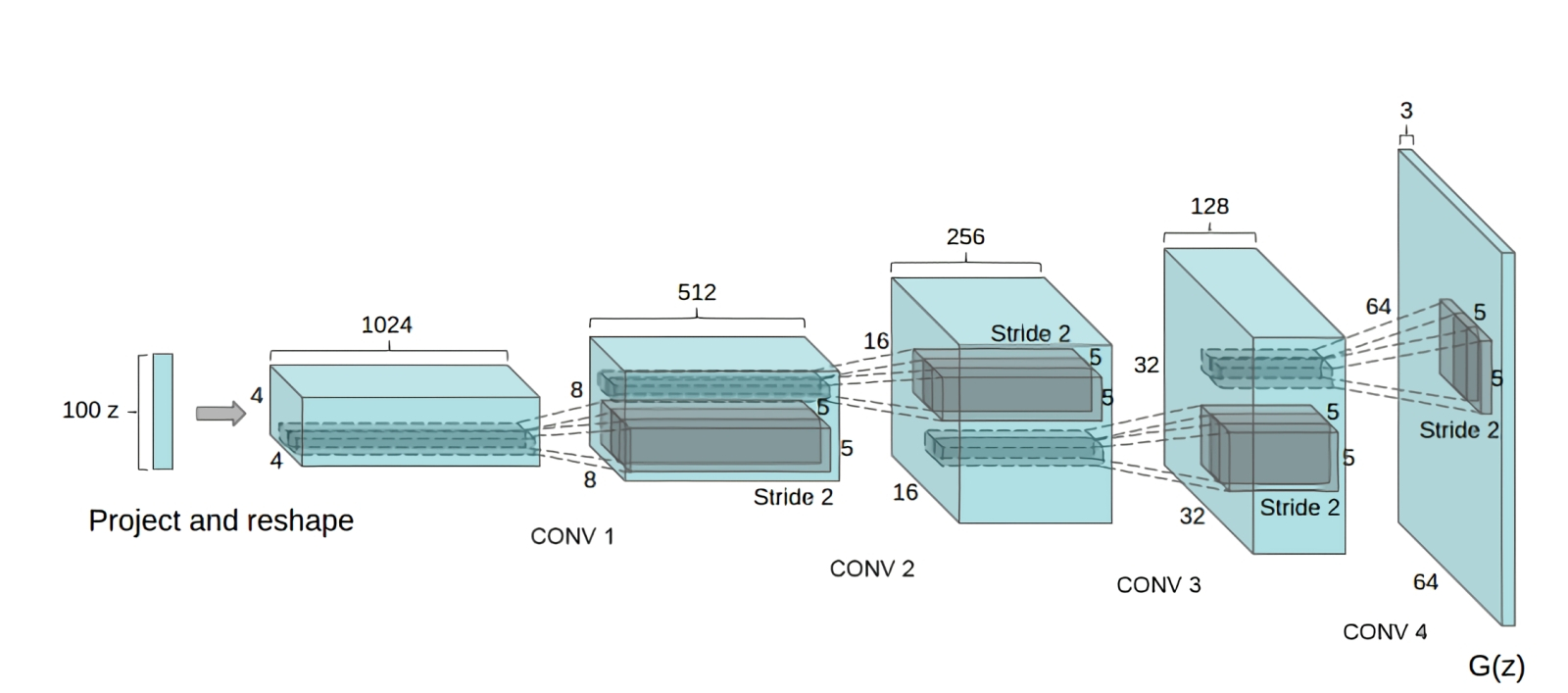
Архитектура генератора DCGAN напоминает запущенную в обратную сторону CNN для распознавания образов (источник: GeeksForGeeks) Суть архитектуры DCGAN заключается в том, что на вход дискриминатора образцы для контроля подаются не поодиночке, а небольшими группами, а структура этой нейронной сети организована таким образом, что на каждом шаге свёртки размерность обрабатываемых матриц увеличивается, а число каналов параллельной обработки сокращается. В целом дизайн дискриминатора напоминает устройство самой обычной свёрточной нейросети — с рядом специфических особенностей вроде того, что шаг сдвига фильтра (convolutional stride) вместо типичной для сетей распознавания образов единицы обычно принимается равным двум, что позволяет эффективнее отбрасывать незначительные детали и выявлять более общие закономерности в исследуемом изображении. Работа нейронной сети, порождающей некие воспринимаемые человеком сущности, в первом приближении сводится к двум операциям — кодированию и декодированию; сжатию информации и развёртыванию полученной компактной формы до итогового изображения, текста, набора звуков и пр. Но, в отличие от алгоритмической архивации (когда исходный массив данных без потерь информации уменьшается в объёме, а затем восстанавливается), в процессе отсечения нейросетью всего лишнего порождается латентное (скрытое) пространство сущностей, в котором сохраняется лишь наиболее существенная информация — и полностью игнорируется любой шум. 
Затравочное изображение, проходя через генеративную ИИзобразительную нейросеть, постепенно словно бы освобождается от излишнего шума — в соответствии с текстовым описанием (источник: ИИ-генерация на основе модели SDXL 1.0) Сохраняется, например, понятие о «собаке в общем» — точнее, интуитивное понимание сути этого термина, сформированное у модели в процессе обучения, — а в конкретное изображение пса той или иной породы в том или ином ракурсе и антураже оно преобразуется уже псевдослучайным образом в процессе декодирования — восстановления с применением, в частности, свёрточной нейросети. Так что если бы не эти сети — кто знает, могли бы мы сегодня с такой же лёгкостью извлекать из латентного пространства всё то, чему имеем возможность удивляться, радоваться и даже чем можем возмущаться сейчас?
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.