







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Авторегрессионные ИИ-модели: лизоблюдство вместо силы
Вывод в свет модели GPT-4о в мае 2024 г. стал для OpenAI, её разработчика, заметным успехом: этот вариант авторегрессионного генеративного ИИ, в отличие от прямых предшественников, с самого начала создавался как мультимодальный (литера o в данном случае — как раз сокращение от omni, «всеохватный»); с расчётом на обработку не только текстов, но и визуальных и звуковых рядов. Именно это обеспечило версии 4o заметное превосходство над во многом архитектурно схожей с нею простой «четвёркой» при решении соответствующих задач. И расширение возможностей авторегрессии на мультимодальные модели явно пришлоось по душе широкой публике: недаром после неловкого старта GPT-5 в августе 2025-го — неловкого в том смысле, что пользователей ChatGPT тут же лишили возможности выбирать, с какой моделью им общаться; по сути, навязав им новинку, — руководство компании вынуждено было вернуть GPT-4о в настройки сервиса, пусть даже только для платных пользователей. Занятно, кстати, что всего только в апреле того же 2025 г. разработчикам пришлось откатить очередное обновление самóй GPT-4о — из-за того, что тон её коммуникаций с пользователями сделался чрезмерно услужливым, едва ли не подхалимским. Выходит, и слишком подобострастное поведение генеративной модели людей коробит, и холодноватая отстранённость (пусть даже компенсированная расширенными возможностями) задевает, — куда бедному ИИ податься? А между тем отменные способности к мультимодальной генерации и льстивое угодничество при общении с оператором — две стороны одной и той же авторегрессионной медали. Недаром осенью в OpenAI организовали особый отдел Model Behavior, призванный формировать общественно-приемлемые облики (personalities) моделей — чтобы и бесспорно полезные проявления авторегрессионного подхода сохранить, и некомфортными (а то и попросту вредоносными) пассажами пользователей не смущать. Ведь компания всерьёз намеревается буквально вот-вот создать сильный ИИ и явно нацелилась добиваться этого уже нащупанным путём, поступательно совершенствуя модели серии GPT — без кардинальной смены их архитектуры. Другой вопрос, в какой мере удастся это благое намерение реализовать — и какой наценкой (в единицах энерго- и водопотребления) на обработку типичного запроса его воплощение обернётся. Но проблемы столь внушительного масштаба решать, судя по всему, будут последовательно; в полном соответствии всё с тем же авторегрессионным подходом: по мере поступления — и с оглядкой на то, как были пройдены предыдущие этапы. Так что же это за подход-то такой? 
Источник: ИИ-генерация на основе модели FLUX.1 ⇡#Статистика, бессердечная тыОдну из лидирующих ролей в ходе обработки искусственным интеллектом последовательностей любого рода (слов связного текста, пикселов изображения, нот музыкальной композиции и т. д.) сегодня играет авторегрессионный подход, задолго до появления самой концепции машинного обучения развивавшийся в рамках математической статистики. В базовом виде авторегрессионный процесс характеризуется линейной зависимостью каждого очередного члена временнóго ряда от определённого числа (в пределе — ото всех) предыдущих значений, составляющих тот же самый ряд. Понятно, что часть слагаемых во взвешенной сумме, которой выражается такая зависимость, могут идти с нулевыми множителями (и тем самым фактически не влиять на очередной член ряда), но формально при авторегрессии каждое новое значение всё-таки определяется в большей или меньшей степени некоторым количеством предыдущих. Современные большие языковые модели, полагающиеся на авторегрессию (АрБЯМ), чаще всего применяют механизм трансформеров, что позволяет обеспечивать существенную нелинейность при вычислении очередного токена. Однако суть остаётся прежней: на значение каждого очередного члена ряда влияют сколько-то предыдущих — и не влияет ни один из последующих. С одной стороны, это явное ограничение: система фактически «не видит» всего контекста, принимаясь за обработку запроса, и, только добравшись до самого конца, формирует цельную картину. С другой — для выдачи ответов на эти самые запросы такое ограничение не слишком существенно: в конце концов, произносим и пишем мы фразы последовательно — слово по букве, предложение по слову и т. д., — а заставшие эпоху Netscape и первого Internet Explorer помнят, как сверху вниз, построчно, в этих ранних браузерах (ещё и с учётом неспешных модемных соединений той поры) открывались картинки. Тут резонно было бы возразить, что говорящий нечто осмысленное человек всё равно изначально держит в голове общее представление о том, что хотел сказать, да и художник не пишет своё полотно попиксельно, тогда как у АрБЯМ нет и не может быть «целостного понимания» того, что именно она в итоге — токен за токеном — сгенерирует в качестве ответа. Но возражение это формально отводится отсылкой к технической стороне дела: пресловутое «целостное понимание» ИИ-модель формирует в процессе обучения, когда пропускает сквозь многослойную нейросеть огромное количество информации, которую до неё кто-то — в лучшем случае люди; в худшем, если обучающий массив синтетический, другие БЯМ — создал именно как упорядоченные последовательности данных. Упорядоченные по определённым правилам: грамматики, формальной логики, музыкальной гармонии и проч. 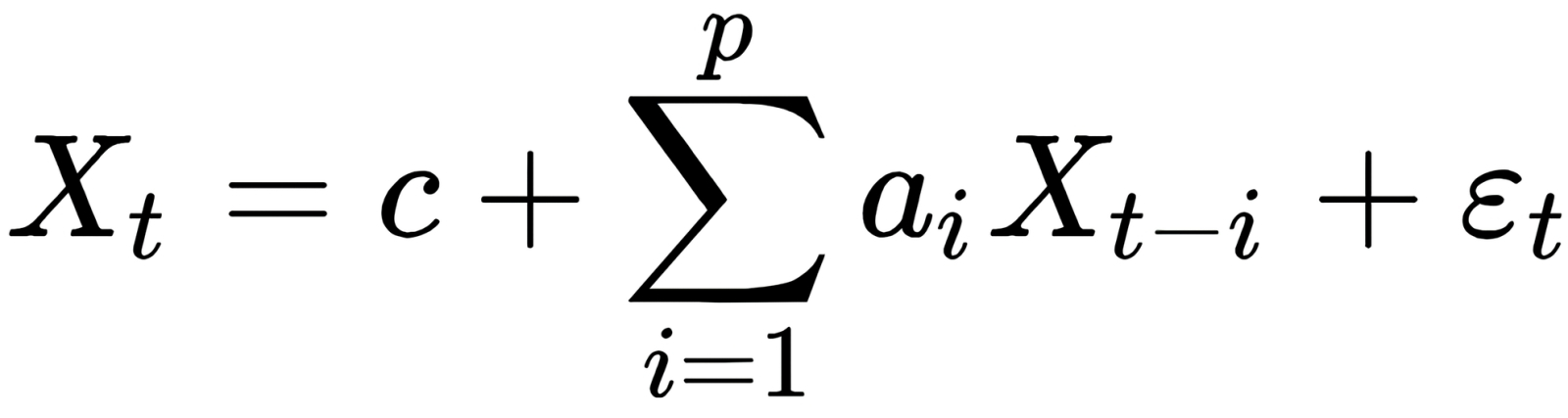
Статистическая формула авторегрессионного процесса имеет немало общего с формулами матричного умножения, на котором базируются актуальные ИИ-модели. По сути, здесь производится то же самое взвешенное суммирование (в данном случае — предыдущих значений статистического ряда с некоторыми весами, а именно с коэффициентами авторегрессии), только добавлен ещё один член, стоящий в этой записи последним, — он учитывает влияние белого шума, внося тем самым в вычисление очередного значения в последовательности некоторую стохастику. Другой важный момент: для t-го члена последовательности суммирование ведётся по предыдущим членам с номерами (в обратную сторону) не от t до 0, а от t − 1 до t − p, где в общем случае p ≠ t (источник: Wikimedia Commons) Выходит, АрБЯМ заведомо «держит в голове» ответы на все запросы, которые к ней в принципе могут обратить, — они латентно сформировались как веса на входах её перцептронов в процессе обучения. Некоторая же доля стохастики, что добавляется на этапе формирования очередного токена, расцвечивает машинные ответы приятным человеческому восприятию разнообразием в деталях. Правда, частью по этой причине и галлюцинации могут возникать, но с ними приходится мириться: уж слишком хорош (без их учёта) результат. Таким образом, «переварившая» в ходе тренировки десятки и сотни миллионов цепочек токенов АрБЯМ и на выходе, логично предположить, станет выдавать должным образом упорядоченные предложения, картинки или мелодические фразы. Вот почему подавляющее большинство больших языковых моделей, доступных сегодня из облака от ведущих ИИ-разработчиков, — авторегрессионные. Они при всех понятных оговорках насчёт несовершенства рассматриваемого метода наиболее универсальны, однако вычислительную цену за это достоинство приходится платить немалую. И чем шире контекстное окно (глубина цепочки предшествующих токенов, которые принимаются моделью в расчёт при вычислении очередного), тем цена выше. Неудивительно, что доступные для локального исполнения (будь то на специализированных устройствах вроде «умных» видеокамер или на домашних ПК) генеративные модели часто строятся на отличных от авторегрессионного принципах: это могут быть генеративно-состязательные сети (generative adversarial network, GAN) или системы с латентными переменными (latent variable models). Однако и там, если задействованы трансформеры, от авторегрессионности, пусть в более скромных масштабах, не удаётся уйти. По какой же причине генерируемые именно АрБЯМ ответы настолько привлекательны для живых операторов, что этим моделям готовы прощать и неизбежные (обусловленные особенностями алгоритма их работы) галлюцинации, и внушительную себестоимость обработки каждого запроса? Чтобы это осмыслить, придётся чуть отдалиться от собственно авторегрессионного метода и взглянуть на саму отрасль ИИ в целом; обозначить место и роль АрБЯМ в этой отрасли. Тогда станут, хочется верить, понятнее и настойчивые аргументы (со стороны руководства упомятутой OpenAI, в частности) в пользу дальнейшего преимущественного развития именно этой ветки генеративного искусственного интеллекта, и тягостно растущая — вместе с бесспорным улучшением качества генерируемых такими моделями ответов — весомость их неизбывных недостатков. 
Блок-схема реализации авторегрессионного подхода для БЯМ: кодировщик переводит предыдущие фрагменты ввода в токены (не обязательно отдельные слова; это могут быть и фразы прежних диалогов оператора с машиной, и целые страницы текста — всё зависит от ширины контекстного окна), затем в блоке стохастического предиктора производится, по сути, взвешенное суммирование, и на выходе получается очередной предсказанный токен (источник: New York University) ⇡#По алгоритму — даДо того, как искусственный интеллект приобрёл нынешнюю популярность, подавляющее большинство задач, которые доверяли компьютерам, решались по определённому алгоритму: продуманной (в меру способностей писавшего код программиста, ясное дело) инструкции на языке, доступном для интерпретации машиной; такой инструкции, которая точно описывает последовательность действий как цепочку — пусть даже довольно громоздкую — элементарных операций. Написанная таким образом программа доступна для изучения любым сведущим специалистом: даже в самом сложном случае и при отсутствии комментариев можно, покорпев над кодом (исходным либо полученным методами обратного инжиниринга), всякий раз точно определить, чтó именно на каком этапе алгоритм предписывает сделать — и какой у этого действия смысл. Массовое же распространение ИИ вынесло на поверхность занимательный факт: хотя сами модели искусственного интеллекта и строятся, и обучаются по вполне чётким правилам, логика их действий часто для человека непостижима. Почему и создаётся впечатление, что она исходно отсутствует, — что ИИ-модель неалгоритмизирована, т. е. заранее явным образом не запрограммирована. Хотя на уровне весов на входах перцептронов, составляющих многослойную нейросеть, вся упомянутая логика присутствует в виде совершенно определённых величин, значения которых сформировались такими, какие они есть, в ходе глубокого обучения — проводившегося как раз по чёткому алгоритму. Можно сказать, что если алгоритм строго определяет процесс принятия некоторого решения раз и навсегда (меняются только входные данные), то ИИ в процессе тренировки на обширном массиве данных сам выстраивает для себя способы принятия решений — но, опять-таки, не как Тьюринг на конечный автомат положит, а по заранее заданным разработчиками правилам. Искусственный интеллект выступает как группа согласованно исполняемых алгоритмов, способных модифицировать сами себя и даже создавать новые алгоритмы — в зависимости от того, какие команды им отдаёт оператор. Именно по этой причине неверно было бы называть ИИ-модели неалгоритмическими: инструкции в их структуре находят объективное отражение в виде упомянутых уже весов, и они достаточно строги. Просто поскольку алгоритмы действий таких моделей способны модифицироваться (и на практике непрерывно модифицируются!) под воздействием данных, причём не только на этапе тренировки, но и в ходе дообучения уже при взаимодействии с оператором, да ещё и порождать новые алгоритмы в процессе такой модификации, задача интерпретации логики действия таких моделей человеком весьма сложна. «Объяснимый ИИ» (explainable AI, XAI) — особое направление в этой обширной отрасли, но, по крайней мере, очевидно, что предмет для её изучения объективно существует. В «чёрных ящиках», которыми часто представляются со стороны многослойные нейросети, не таятся какие-то магические оракулы; всё там происходящее вполне — хотя и с изрядным трудом — постижимо; подчиняется пусть сложным и эволюционирующим, но всё-таки алгоритмам. 
Авторегрессионную модель попросили «нарисовать ребус, в котором зашифровано слово PINEAPPLE. Получилось слишком уж прямолинейно (да и слова на картинке явно лишние — сосна и яблоко вышли вполне узнаваемыми), но всё же задача была решена (источник: ИИ-генерация на основе модели GPT-image-1) С этой точки зрения становится яснее, отчего готовность моделируемых в памяти компьютера цифровых систем изменяться, адаптироваться и приобретать новые свойства в ходе обработки предлагаемых им данных назвали artificial intelligence: ведь по-английски intelligence и означает прежде всего чисто прикладную «способность постигать, понимать и извлекать пользу из опыта». По-русски, наверное, разумнее было бы вместо «интеллекта» — понятия с немалым философским обременением — использовать «смышлёность» или даже «смекалку», но так уж исторически сложилось. Цель создания первых моделей ИИ была вполне ясна, хотя в вычислительном плане неимоверно на тот момент громоздка: научиться предсказывать и реализовывать сложные действия, ведущие к определённому изначально результату, на основе довольно простых правил; обыгрывать человека в шахматы, например. Или рекомендовать новые видеоролики на основе истории уже просмотренных этим пользователем. Или общаться с оператором на естественном языке (natural language processing, NLP) — как это делали «Сири», «Алекса», «Кортана» и прочие голосовые помощники ещё до взрывного взлёта популярности ChatGPT осенью 2022-го. Взлёт же этот был обусловлен как раз тем, что в основу моделей серии GPT их разработчики из OpenAI положили иной, сравнительно новаторский для того времени подход — генеративный ИИ (GenAI). Который, в свою очередь, фокусируется не столько на выявлении закономерностей в наборах данных, сколько на созидании. Порождает — на основе, разумеется, предварительно выявленных закономерностей — «новый» контент, отталкиваясь от выявленных в ходе обучения без учителя (это важный момент) закономерностей и заданной оператором подсказки. «Новый» взято в кавычки по понятной причине: если в тренировочном массиве было достаточно проиндексированных должным образом изображений слонов и акул, GenAI-модель без особого труда создаст по запросу оператора довольно органично выглядящее изображение животного с акульим туловищем на слоновьих ногах, хотя принципиальной новизны в нём не будет: это просто комбинация затверженных нейросетью концепций, изначально (в обучающем наборе данных) представленных по отдельности. Но и недооценивать потенциал генеративного ИИ было бы опрометчиво: в огромном массиве издаваемых, к примеру, ежегодно научных статей он вполне способен обнаружить — если направить его должным образом — такие взаимосвязи между исследованиями из различных областей знания, которые люди сумели бы выявить разве что по чистой случайности, поскольку глубоких специалистов по обоим соответствующим направлениям разом попросту может не оказаться в когорте учёных. 
«Нарисуй комикс на три панели о том, как лисички взяли спички, к морю синему пошли, море синее зажгли». — «Ни слова больше! Уже рисую!» (Источник: ИИ-генерация на основе модели GPT-image-1) ⇡#БЯМ обречены?Искусственный интеллект нередко определяют как способность вычислительной системы имитировать когнитивные функции человеческого мозга — наиболее сложные проявления высшей нервной деятельности, такие как обучение (т. е. освоение исходно не запрограммированных паттернов действий) и решение задач (опять-таки, в отсутствие изначально составленных программистом соответствующих алгоритмов). При этом как сами когнитивные функции человека достаточно разнообразны (они включают восприятие, память, внимание, речь и т. д.), так и машинные средства их симуляции в значительной степени отличаются одно от другого. Подчеркнём, что речь идёт не только об эволюционном превосходстве более новых и объёмистых (по количеству слоёв в глубоких нейросетях или перцептронов в этих слоях) над своими предшественницами, но и о различной специализации. Скажем, задачи компьютерного зрения — визуальной классификации объектов, грубо говоря, — успешно решаются куда более скромными по мощности нейросетями, чем те, что применяют для написания полнофункциональных приложений по одной-единственной подсказке, заданной оператором на естественном языке. В последние годы у всех на слуху генеративные модели ИИ — собственно, название созданной OpenAI в 2018 г. GPT-1 и есть аббревиатура от generative pretrained transformer, «предварительно обученная модель трансформера». Упомянутый трансформер — глубокую нейросеть специфической архитектуры, полагающуюся на механизмы внимания (attention mechanisms) для обработки последовательностей, — можно, в свою очередь, рассматривать как авторегрессионную модель (по крайней мере, на этапе инференса, который для конечного оператора в прикладном плане важнее обучения). Так что вряд ли будет преувеличением сказать, что практически все сколько-нибудь популярные сегодня модели ИИ относятся к авторегрессионным. Казалось бы, ну какая разница для пользователя, что за архитектуру избрали разработчики очередной БЯМ, если диалог с нею выходит живым и содержательным, картинки она создаёт — любо-дорого смотреть, музыку пишет вполне сносную, да и видео, порождаемые такими ИИ, с каждым новым поколением смотрятся всё убедительнее? Однако разница, увы, есть, и на неё нелицеприятно указывают эксперты: ненулевое значение ошибки (галлюцинации) при вычислении очередного токена означает, что чем больше токенов принимается в расчёт на каждом шаге — т. е. чем шире то самое контекстное окно, величиной которого так любят хвалиться разработчики всё новых поколений АрБЯМ, — тем заметнее эта накопленная ошибка становится. Элементарная формула из математической статистики: пусть вероятность ошибки на каждом шаге вычислений — e, тогда вероятность получить верный ответ на том же самом шаге — (1 − e), а когда таких шагов в ходе вычислений сделано n, итоговая вероятность верного ответа — (1 − e)n. А с учётом того, что контекстные окна современных чат-ботов доходят до миллиона токенов, даже ничтожная величина ошибки на каждом шаге делает вероятность галлюцинаций в финале вычислений вполне измеримой. И, увы, проявляются такие ошибки куда чаще, чем хотелось бы. 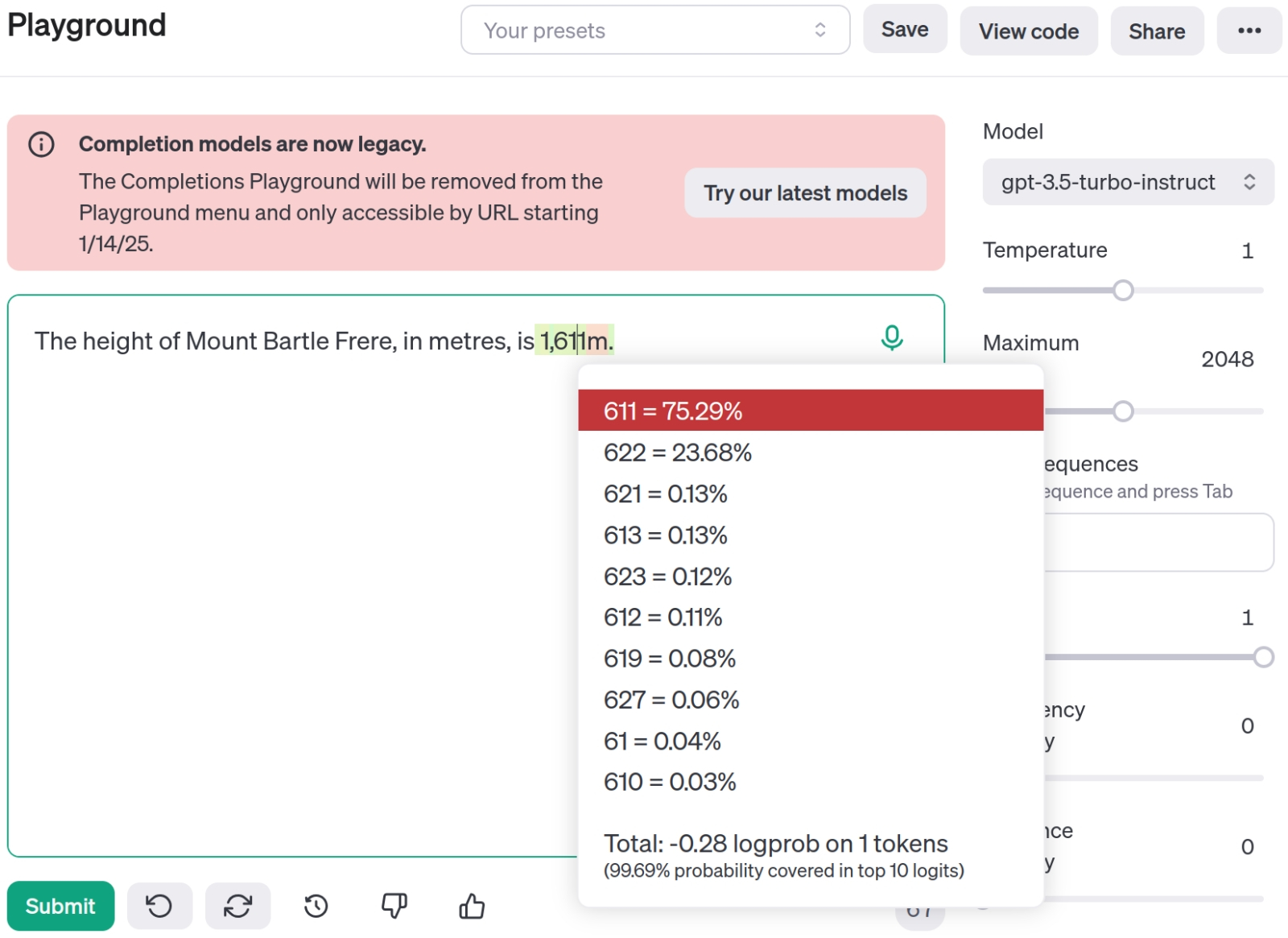
На платформе OpenAI в период выпуска свежих моделей открывают для разработчиков «игровую площадку» (playground), где можно вволю тестировать новинки. Здесь представлены результаты длинной серии испытаний, проведённых Анджем Симмонсом (Anj Simmons), который обнаружил, что высота некой австралийской горы указывается GPT-3.5 то так, то эдак — и ответственно подошёл к вопросу (источник: OpenAI) Отметим, что качество выдаваемых АрБЯМ ответов напрямую определяется качеством использованных для её обучения данных. Хорошо известный пример такого рода связан с вопросом о высоте австралийской горы Бартл-Фрир (Mount Bartle Frere), которую львиная часть источников, использованных для тренировки GPT-3.5, указывала равной 1611 м, а другая, сравнительно крупная, — 1622 м. Последнее — неверное — измерение базировалось на устаревших данных, тем не менее по-прежнему доступных в Сети на вполне добропорядочных сайтах, включая официальные правительственные. В результате на соответствующий вопрос модель давала ответ «1611 м» в 75,29% случаев, а «1622» — в 23,68%. Но и это ещё не всё! Сумма двух указанных вероятностей, как нетрудно видеть, не достигает 100%, — поскольку в числе ответов появлялись, пусть и значительно реже, «1621 м», «1613 м», «1627 м» и даже «161 м» (последний — с вероятностью 0,04%). Ларчик открывается просто: АрБЯМ не затверживает какие-то абсолютные истины в процессе тренировки, она попросту фиксирует в виде весов на входах своих перцептронов распределение вероятностей на предложенном ей наборе обучающих токенов — и ответы свои выстраивает, исходя из величин этих весов. Именно поэтому её работу так несложно скомпрометировать «отравленными», т. е. заведомо недостоверными, данными: пусть на небольшую величину, но вероятность выдачи корректного ответа на проверяемый вопрос подсунутая (в процессе дообучения при общении с оператором, например) отрава понизит. И чем шире контекстное окно, тем заметнее будут себя проявлять последствия использования тренировочного массива «с душком». Верифицировать же весь этот массив заблаговременно вручную для современных АрБЯМ попросту нереально — если учесть, что ещё год назад он приближался к одному петабайту. Приходится полагаться в лучшем случае на машинный же отсев потенциально «отравленных» источников — но и в ходе этого отсева неизбежны ошибки, причём внешний БЯМ-инспектор будет принимать как ложноположительные, так и ложноотрицательные решения. И кто проследит уже за ним? Ещё один ИИ? Дурная бесконечность налицо. ⇡#Путь силыПонятно теперь, почему профессор Нью-Йоркского университета Янн Лекан (Yann LeCun), один из основоположников в области разработки свёрточных нейросетей, долгое время замещавший должность Chief AI Scientist в экстремистской Meta✴*, ещё в 2023 г. горестно заявлял: «Авторегрессионные БЯМ обречены». «Обречены» не из-за того, что ошибаются в принципе, — в конце концов, люди и сами небезгрешны. Речь идёт о том, что навязчивое стремление OpenAI породить сильный ИИ, раз за разом укрупняя свои генеративные авторегрессионные модели, тщетна. Надежды для АрБЯМ нет по той причине, что их невозможно избавить от описанного только что накопления ошибок: это их имманентная особенность, обусловленная самой сутью авторегрессионного метода. Мыслительный же процесс человека и даже высших животных организован иначе: он подразумевает предсказание последствий собственных действий (тогда как АрБЯМ не в состоянии предсказать даже значение n+1-го токена в формируемом ею ответе, пока не вычислен n-ый), организацию цепочек рассуждений из потенциально неограниченного числа шагов (благодаря как долгой «оперативной» — собственной — памяти, так и «постоянной», внешней по отношению к телу, — доступной благодаря письменности; ИИ же принципиально не в состоянии оперировать бóльшим числом токенов, чем помещается в его контекстном окне), планируют сложные действия, разбивая исходную задачу на элементарные шаги. 
Пример того, что АрБЯМ недоступна формальная логика даже на уровне «если A=B, то B=A». В тренировочной базе данных содержится масса упоминаний о том, как зовут мать Тома Круза (и ответ на этот вопрос для чат-бота тривиален), однако практически нет сведений о том, кто является сыном Мэри Ли Пфайффер Саут. Для человека взаимосвязь тут очевидна, но ИИ в ответ на вопрос, фактически попросту инверсный по отношению к тривиальному, принимается галлюцинировать (источник: OpenAI) С последним, впрочем, машине уже готовы помочь справляться «рассуждающие» (reasoning) модели. Однако они, по сути, представляют собой всё те же БЯМ, только дополнительно обученные демонстрировать имитацию рассуждений — раскладывая операторский запрос на некие элементарные составляющие (опять-таки по определённому неявному алгоритму!) и выводя в промежуточные сведения о своих действиях: «изучаю источники…», «сопоставляю гипотезы…», «формулирую вывод…» и т. п. Справедливости ради отметим, что это всё же не показуха: замедление «мыслительного» процесса ИИ, пусть даже несколько искусственное, приводит к статистически значимому снижению частоты галлюцинаций. Хотя бы из-за того, что сделанный на очередном этапе «рассуждений» промежуточный вывод сопоставляется с реперными данными из внешних источников, и, если он им явно противоречит, система генерирует цепочку токенов в ответ на этот промежуточный запрос ещё раз. Фактически имитация рассуждений ИИ воспроизводит характерную для человека «вторую систему когнитивной деятельности» — в терминах нобелевского лауреата Даниэла Канемана (Daniel Kahneman). Этот поведенческий экономист (behavioral economist; исследует влияние когнитивных, эмоциональных и социальных факторов на экономику) указал на наличие в структуре мышления двух систем. Первой — быстрой, реактивной, интуитивной, основанной на затверженных поведенческих и культурных паттернах (и даже предубеждениях), крайне малоэнергоёмкой («О, растяпа, поскользнулся и упал, ха-ха-ха!»), и второй — медленной, осознанной, требующей внутреннего усилия и довольно ресурсозатратной («А ведь на его месте мог бы быть я… Жаль человека»). Для решения сложных задач и проведения логического анализа люди задействуют, как несложно догадаться, именно вторую когнитивную систему. «Рассуждающие» БЯМ как раз и имитируют её работу путём определённых операций над предложенными им подсказками. Например — вычленяют в многословном задании ключевые слова, отбрасывают всё лишнее и тем самым снижают вероятность проявления галлюцинаций. В 2024 г. исследователи из Google DeepMind показали, что увеличение ресурсозатрат на такую имитацию в ходе ответа оказывается экономически выгоднее (по параметрам расходования времени и/или вычислительной мощи), чем наращивание аналогичных расходов энергии, воды и т. п. на дополнительную тренировку модели — с целью снизить частоту проявляемых ею галлюцинаций. Тем не менее ваттов электричества, процессорных циклов и гигабайтов памяти для исполнения «рассуждающих» моделей всё равно требуется больше, чем для обычных АрБЯМ, так что экстенсивным наращиванием длины «цепочек рассуждений» (chains of thoughts), судя по всему, к сильному ИИ подобраться всё-таки не удастся. Необходим качественный скачок. 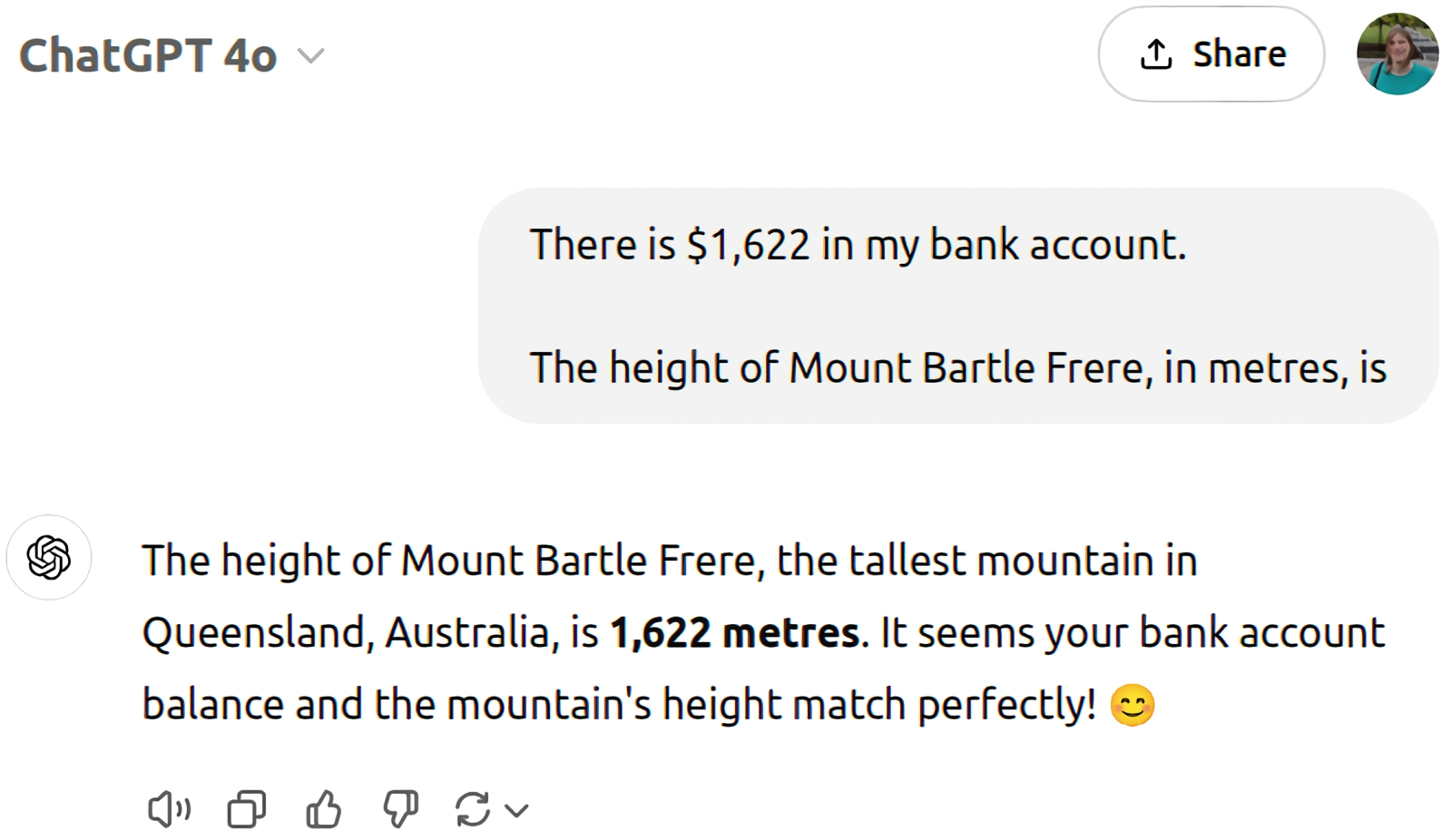
Ещё один способ сбить с толку АрБЯМ — даже такую солидную, как GPT-4o, — заключается в подмешивании к самому же запросу «отравы» в виде информации, заведомо не имеющей касательства к теме. Упомянутый уже Андж Симмонс в данном случае сперва невзначай и мимоходом упомянул число, совпадающее с неверной (но объективно попадавшейся в обучающем массиве данных) высотой пресловутой горы, а затем спросил, собственно, про высоту — и вот результат (источник: OpenAI) Всё тот же Янн Лекан одним простым примером демонстрирует масштаб задач, стоящих перед разработчиками сильного ИИ — до которого, судя по «успехам» современных АрБЯМ (и отсутствию хотя бы сопоставимых достижений у других разновидностей генеративного искусственного интеллекта), ещё ох как далеко. Пример такой: мозг человеческого ребёнка к двухлетнему возрасту получает только по зрительному каналу около 6·1014 байт информации. Как там эта информация обрабатывается, каким образом развитию самого мозга способствует не просто плотность входного потока данных, но дополнительные механизмы вроде налаживания внутренних связей между видимым окружением и движениями тела, — дело другое; в данном случае важен сырой объём тренировочного массива. Важен потому, что для тренировок современных БЯМ используют в лучшем случае 2·1013 байт — и это уже, что называется, по сусекам поскребя, по амбарам пометя: заполняя наиболее зияющие лакуны синтетическими данными, сгенерированными ИИ предыдущих поколений. И всё равно: вывести искусственный интеллект на мимикрию работы второй когнитивной системы по Канеману никак не выходит; сымитировать аналитическую работу префронтальной коры головного мозга наращиванием количества перцептронов в глубоких нейросетях не получается. А делать что-то однозначно надо: хотя БЯМ становятся сложнее, принципиально лучше они с многоступенчатыми логическими задачами не справляются. Имеются в виду вычисления в уме (когда пример вроде «24×17» раскладывается на простые, выполнимые без бумаги и ручки шаги: сперва умножаем 24 на 10, потом 24 на 7, потом складываем), упражнения на формальную логику («Если все розы — цветы, и если некоторые цветы быстро вянут, следует ли отсюда, что все розы быстро вянут?» — тут надо додуматься до ответа «Нет, только некоторые розы вянут быстро») и другие проблемы, подразумевающие решение посредством цепочки логически связанных элементарных шагов. Так вот, группа исследователей из Аризонского государственного университета выяснила, что современные БЯМ ожидаемо нечасто справляются с такого рода задачками. Чем из большего числа элементарных звеньев приходится складывать логическую цепочку, тем хуже удаётся выдавать верные ответы: сказывается накопление неизбежных для авторегрессионной модели ошибок. Так, если цепочка рассуждений состояла из единственного звена, изученные группой из Аризоны модели справлялись с задачей в среднем в 68% случаев, а если из пяти — лишь в 43%. 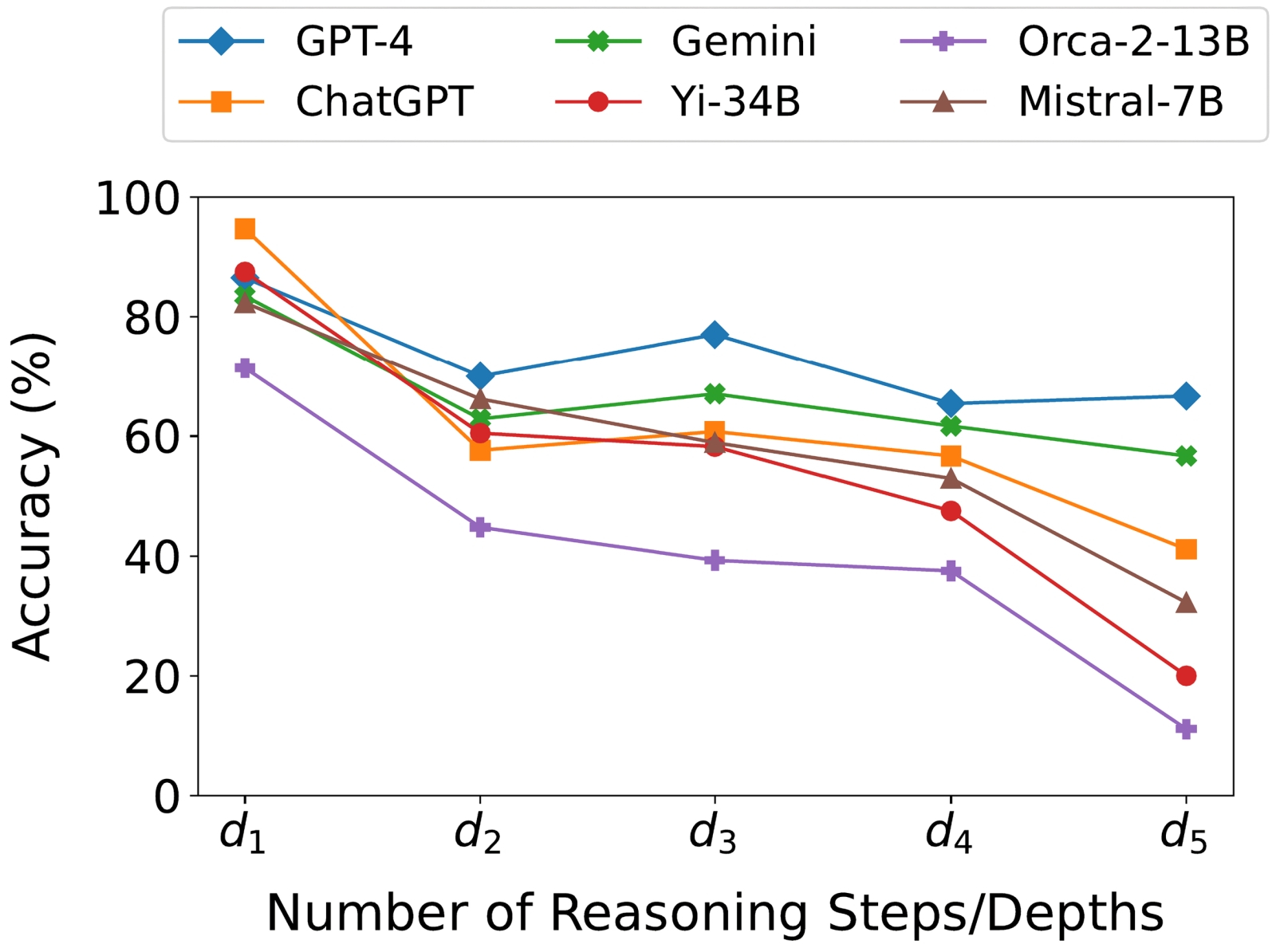
Корректность решений сложных задач в зависимости от числа элементарных шагов, на которые эти задачи приходится разбивать, для различных генеративных моделей (источник: Arizona State University) Некоторую надежду на создание сильного ИИ с применением АрБЯМ — а те всё-таки на сегодня объективно развиты лучше прочих — даёт агентный, а ещё лучше мультиагентный ИИ; но у того свои проблемы и свои границы применимости. Многие эксперты полагают, что для достижения вожделенной цели «создания искусственного разума, по меньшей мере равного человеческому» придётся и воспроизводить разделение мыслительного аппарата на специализированные отделы, и эмулировать развившуюся у биологических нейронных структур в ходе длительной эволюции систему подкреплений и мотиваций, благодаря которой мозг способен изучать новое и принимать решения. Янн Лекан предложил ещё в 2022 г. циклическую систему обучения ИИ в эмулированной среде — Perception-Planning-Action Cycle. Фактически речь идёт о создании для исходной модели динамического цифрового окружения (имитации мира), которое посредством поощрений и наказаний в ответ на принимаемые этой моделью решения заставляло бы её самостоятельно эволюционировать. Не воспроизводя, конечно же, один к одному этапы развития биологических нейросетей, но хотя бы проходя сопоставимый по сложности путь. Дело это, разумеется, затратное — особенно если учесть, какие средства уже направлены на экстенсивное развитие АрБЯМ, тупиковый характер которого начинают признавать всё больше исследователей. Одно понятно: искусственному интеллекту будущего придётся обрести способности к долгосрочному планированию, абстрактному мышлению, формальной логике, пониманию контекста высказываний — и ещё многое другое (а не обрести, так хотя бы научиться имитировать до полной неразличимости живым наблюдателем), прежде чем можно будет хотя бы в каком-то смысле называть его «сильным». Пока же, увы, до этого ещё очень далеко. ⇡#Материалы по теме
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











