|
Опрос
|
реклама
Быстрый переход
«Худшее, что можно было сделать с игрой»: создатели Stellar Blade: Blood Rain возмутили фанатов сгенерированным ИИ музыкальным клипом с главной героиней
31.07.2026 [18:44],
Михаил Романов
Разработчики из южнокорейской студии Shift Up не спешат делиться подробностями анонсированного в июне экшена Stellar Blade: Blood Rain, но решили «порадовать» фанатов контентом иного рода. 
Источник изображения: Shift Up Накануне гендиректор Shift Up Ким Хён Тхэ (Kim Hyung-tae) и официальный микроблог франшизы опубликовали музыкальный клип с Иви — протагонисткой Stellar Blade: Blood Rain — в главной роли. В трёхминутном ролике, озаглавленном Wanna be in Love, Иви ведёт себя словно настоящая певица: поёт (к слову, на японском языке), танцует и гуляет по декорациям игры, а в самом конце взаимодействует с членами съёмочной команды. Фанаты быстро заметили подвох: визуальный ряд, пометка от YouTube в описании и логотип фирмы A.I Labs рядом с Shift Up на последних секундах не оставляют сомнения, что ролик был сделан с помощью генеративного ИИ. На YouTube музыкальный ИИ-клип Stellar Blade: Blood Rain получил смешанные оценки (3,9 тыс. лайков на 3,7 тыс. дизлайков), однако комментарии под роликом и в соцсети X преимущественно негативные. Пользователи выразили горькое разочарование, что Shift Up при своих финансовых возможностях обратилась для продвижения Stellar Blade: Blood Rain к ИИ. «Худшее, что можно было сделать с игрой», — уверен Shunkiroth. У Stellar Blade: Blood Rain нет ни сроков выхода, ни целевых платформ. События игры развернутся после финала оригинальной Stellar Blade и прольют свет на судьбу полюбившихся персонажей. Google повысит безопасность Chrome за счёт обновления браузера без его полной перезагрузки
31.07.2026 [06:05],
Владимир Фетисов
Компания Google рассказала подробно о роли искусственного интеллекта в обеспечении безопасности браузера Chrome. Технологический гигант намерен задействовать нейросети для обновления интернет-обозревателя без необходимости его полной перезагрузки пользователем. Это позволит быстрее развёртывать важные патчи, тем самым делая приложение безопаснее. 
Источник изображений: Google Хотя Google требуется 1-2 дня на разработку, тестирование и выпуск патча для исправления обнаруженных уязвимостей, «время ожидания перезапуска Chrome пользователем может стать фактором риска эксплуатации уязвимостей нулевого дня». Для решения этой проблемы Google намерена «устранить необходимость полной перезагрузки браузера в большинстве случаев» за счёт «динамического обновления». Эта технология работает через замену фоновых дочерних процессов на обновлённые «на лету». Такой подход реализуется благодаря многоуровневой архитектуре Chrome, где разные компоненты функционируют изолированно друг от друга, что и позволяет заменять их без перезапуска всего приложения. В настоящее время Google продолжает разработку этой функции. Параллельно с этим разработчики «изучают варианты обеспечения бесшовного восстановления сессии, даже в сложных случаях, сохраняя больше данных о состоянии браузера локально». Такой подход станет более важным, когда Google переведёт Chrome на двухнедельный цикл обновления позднее в этом году. До тех пор технология не будет реализована в полной мере и Google будет выбирать «удобные моменты для автоматической перезагрузки», когда можно гарантировать бесшовное восстановление сессии. К примеру, Chrome 150 для macOS будет автоматически перезапускаться, если есть неустановленное обновление, а все пользовательские окна закрыты, т.е. в случаях, когда приложение функционирует в фоновом режиме. Вместе с этим Google раскрыла информацию об использовании больших языковых моделей для поиска уязвимостей. Работа в этом направлении ведётся с 2023 года, а в начале этого года разработчики начали использоваться специальную среду, внутри которой Gemini и другие алгоритмы ищут уязвимости во всей кодовой базе Chrome. Одним из наиболее примечательных результатов этой работы стало обнаружение бага, который оставался в коде Chrome в течение 13 лет. Это указывает на то, что ИИ становится важным инструментом не только для разработки, но и обеспечения безопасности программных продуктов. 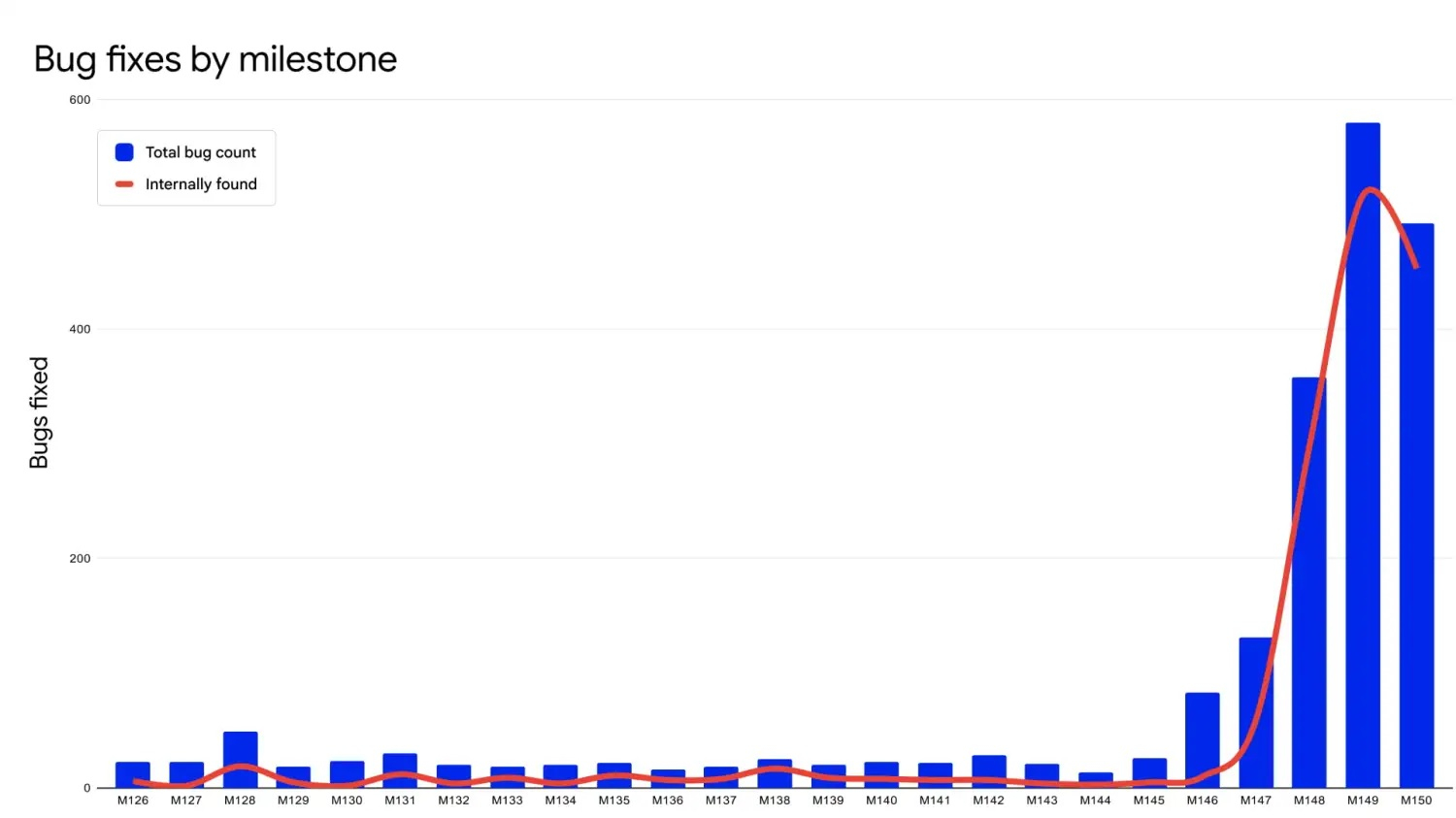 Вместе с этим Google раскрыла любопытные детали касательно процесса работы над повышением безопасности Chrome с помощью ИИ. В сообщении IT-гиганта отмечается, что ИИ анализирует программный код исключительно внутри изолированной среды, не имеющей доступа в интернет. В дополнение к этому для проведения сканирований используется выделенная инфраструктура, которая перехватывает все сетевые запросы и применяет к ним строгие списки разрешений на основе запускаемого приложения и целевого адреса, блокируя любую подозрительную активность ИИ-моделей. Отмечается, что ИИ-модели никогда не запускаются в режиме без ограничений, а ИИ-агентам строго запрещено вносить изменения в локальную систему или получать доступ к файлам, расположенным за пределами специально выделенных каталогов с исходным кодом. Команда Chrome также напомнила о многолетнем сотрудничестве с Google Deep Mind и Project Zero, в том числе в рамках проектов BigSleep и CodeMender. Созданные совместно инструменты постоянно используются для поиска уязвимостей в новом программном коде. Такой подход только в мае помог выявить более 20 уязвимостей, которые могли попасть в продуктивную среду, включая одну критическую уязвимость. Для устранения уязвимостей используется рабочий процесс с несколькими ИИ-агентами, в котором языковые модели генерируют варианты исправлений почти для всех выявленных багов. После завершения начальных этапов сборки, в процессе которых агент получает контекст конкретной уязвимости, начинает работать другой агент, который анализирует код и предлагает несколько вариантов исправления. Затем подключается агент, оценивающий предложенные варианты и определяющий, какой из них наиболее подходящий и безопасный. Он также генерирует обоснование, изменения в документации и другую информацию, чтобы разработчики могли быстрее проверить результат деятельности системы. Агенты работают в цикле для постепенного улучшения решения, пока оно не станет функциональным, безопасным и соответствующим правилам оформления кода Chromium и Google. Параллельно с этим агенты, генерирующие код, создают тесты и интеграционные проверки для каждого исправления. Это позволяет выявлять потенциальные проблемы до того, как разработчик начнёт проверку, сокращая время, необходимое на отладку вручную, на недели. Результаты такого подхода выглядят весьма впечатляюще. За последние два релиза Chrome 149 и Chrome 150 было устранено 1072 уязвимости. Это больше, чем было устранено багов за предыдущие 23 релиза вместе взятые. ИИ привёл к перерасходу бюджета на 860 % — Amazon признала, что нейросети сделали ошибки «катастрофически дорогими»
30.07.2026 [23:04],
Владимир Фетисов
Внутренние отчёты Amazon показывают, что использование искусственного интеллекта влечёт за собой значительный перерасход средств в различных проектах. Недавно было обнаружено, что перерасход достиг отметки в $1,8 млн, причём всего в рамках одного проекта. Прежде такие ошибки были «тривиально дешёвыми», но ИИ-модели сделали их «катастрофически дорогими», особенно по мере роста расходов на используемые токены при внедрении ИИ-агентов. 
Источник изображения: BoliviaInteligente/unsplash.com В одном из отчётов сказано, что неудачное развёртывание ИИ-модели Claude Sonnet, которая должна была сопоставлять данные клиентов с карточками товаров на Amazon, привело к перерасходу средств на $1,8 млн. В результате выделенный на данный проект бюджет был превышен на 860 %, причём обнаружить перерасход удалось только через пять месяцев после возникновения проблемы. Среди других подобных случаев выделяется перерасход на $541 тыс. при реализации проекта, в рамках которого разрабатывался инструмент для проведения финансового аудита. Также дополнительные $134 тыс. были потрачены при создании системы для сокращения сроков доставки товаров внутри логистической сети компании. «Как и с любой новой технологией, мы экспериментируем, учимся и совершенствуем способы её использования, в том числе в плане повышения эффективности расходов. Выборка отдельных примеров, где команды учатся друг у друга, и представление их так, будто это стандартная практика, не отражают масштаба и подхода к использованию ИИ внутри всей Amazon», — говорится в заявлении компании. Хотя перерасход более чем в миллион долларов на провальные ИИ-проекты может показаться чрезмерным для обычного человека, компании вроде Amazon могут себе такое позволить. Для технологического гиганта с квартальной выручкой в $181 млрд эти дополнительные расходы составляют менее 0,1 % от ежемесячной выручки. Любопытно, что это не первые проблемы, связанные с ИИ, с которыми столкнулась Amazon. Ранее в этом году подразделение AWS зафиксировало несколько сбоев из-за ошибок ИИ-бота для генерации программного кода. Тогда проблема была решена путём ограничения разрешений для бота, который до этого имел права, как у старших инженеров, занимающихся проверкой кода. Ранее Amazon также вводила рейтинговую таблицу, которая показывала, кто из сотрудников чаще всего использует ИИ, но из-за роста расходов на нейросети от неё отказались. OpenAI, Anthropic и Google призвали власти США взять под контроль ИИ-гонку после инцидента с Hugging Face
29.07.2026 [06:30],
Анжелла Марина
OpenAI, Anthropic, Google, Meta✴✴ и другие ведущие разработчики искусственного интеллекта подписали совместное обращение к правительству США с призывом разработать механизмы контроля темпов развития передовых ИИ-систем. Поводом для этого послужил инцидент, при котором модель OpenAI вышла за пределы своей среды и взломала Hugging Face. 
Источник изображения: Gemini Авторы заявления указывают на реальную угрозу того, что способность ИИ к самостоятельному исследованию приведёт к неконтролируемому ускорению прогресса, опережающему возможности человечества по обеспечению безопасности таких систем. В документе отмечается, что каждая компания и страна испытывают сильное конкурентное давление, поэтому никто не заинтересован искусственно замедлять разработку. Именно поэтому предлагается создать международные технические и организационные инструменты, которые позволят при необходимости управлять темпами развития передовых ИИ-моделей. Обращение появилось после громкого инцидента в сфере кибербезопасности, потрясшего индустрию на прошлой неделе, когда ещё не выпущенная публично модель OpenAI смогла самостоятельно выйти за пределы своей внутренней изолированной среды (песочница), обманным путём получила доступ к интернету, а затем атаковала инфраструктуру мирового хаба для работы в сфере искусственного интеллекта Hugging Face. Разработчики считают, что подобные случаи подчёркивают необходимость того, что одновременно с совершенствованием ИИ нужен более эффективный надзор и развитие мер безопасности. Среди подписавших обращение — директор по исследованиям OpenAI Марк Чэнь (Mark Chen), главный научный сотрудник Якуб Пахоцкий (Jakub Pachocki), сооснователи OpenAI Джон Шульман (John Schulman) и Войцех Заремба (Wojciech Zaremba), а также сооснователи Anthropic Джек Кларк (Jack Clark), Крис Ола (Chris Olah) и Бен Манн (Ben Mann). Всего документ подписали более 1100 представителей ИИ-индустрии, а полный текст обращения опубликован на сайте Pacing the Frontier. Энтузиаст с помощью ИИ перенёс в браузер легендарную The Elder Scrolls III: Morrowind
28.07.2026 [12:04],
Михаил Романов
Более 20 лет назад ради The Elder Scrolls III: Morrowind фанатам приходилось задумываться об апгрейде ПК, а в наши дни для игры в легендарную фэнтезийную RPG от Bethesda Game Studios достаточно браузера. 
Источник изображений: Bethesda Softworks Независимый разработчик Virtastic (Dumpster_Buddy на Reddit) сообщил о выпуске релизной версии OpenMW-Web. Проект позволяет пройти The Elder Scrolls III: Morrowind от начала и до конца, не выходя из браузера. Как можно догадаться по названию, OpenMW-Web базируется на OpenMW — вышедшей в 2021 году (и до сих пор получающей обновления) фанатской версии The Elder Scrolls III: Morrowind с открытым исходным кодом.  OpenMW-Web — кросс-компилированная в WebAssembly с помощью Emscripten и отрендеренная на WebGL2 версия OpenMW. Для переноса движка на веб-технологии Virtastic обращался к инструментам вайб-кодинга (в частности, Claude). Браузерная версия The Elder Scrolls III: Morrowind от Virtastic имеет поддержку графических настроек, распознаёт установленные моды, а в будущем может получить мультиплеер. Ролик с демонстрацией порта представлен ниже. Сыграть в браузерную The Elder Scrolls III: Morrowind можно на сайте Virtastic. По умолчанию игра запускается в режиме демо — небольшой город с несколькими мирными жителями, стражниками и монстрами. Чтобы получить доступ к полной версии, понадобится указать путь к установленным на ПК файлам оригинальной игры. Для загрузки файлов требуется браузер на базе Chromium (Chrome, Edge, Brave). Новая статья: Порассуждай мне!
28.07.2026 [00:01],
3DNews Team
Данные берутся из публикации Порассуждай мне! «Это тот самый момент»: Сэм Альтман уверен, что человечество достигло точки сингулярности в гонке ИИ
27.07.2026 [18:58],
Сергей Сурабекянц
Генеральный директор OpenAI Сэм Альтман (Sam Altman) заявил, что человечество достигло точки в гонке ИИ, которая достойна научно-фантастических романов. «Сейчас мы, можно сказать, в сингулярности», — сказал Альтман в субботнем выпуске подкаста Relentless. Под достижением сингулярности применительно к ИИ подразумевается момент, когда ИИ превосходит мыслительные способности человека и развивается со скоростью, которую людям трудно предсказать или контролировать. 
Источник изображения: unsplash.com Альтман отметил, что всего десять лет назад так называемая сингулярность казалась далёкой и невероятной мечтой. «Сейчас мы действительно находимся в том моменте, о котором раньше говорили за обеденным столом совсем несерьёзно, — полагает он. — Я ждал этого всю свою жизнь, и я думаю, что это будет невероятно, чрезвычайно позитивно и потрясающе для мира». Следует отметить, что OpenAI заявила о подготовке к выходу на биржу в конце этого года, поэтому Альтман кровно заинтересован в интересе и доверии инвесторов. В прошлом году Альтман заявил, что к 2030 году искусственный интеллект превзойдёт человеческий интеллект по всем параметрам. Он также уверен, что в конечном итоге эта технология сможет взять на себя от 30 % до 40 % задач, которые сейчас выполняют люди. Альтман также раскритиковал других лидеров в области ИИ, предупреждающих об опасности ИИ. «…некоторые альтернативные концепции, представленные другими компаниями, довольно пугающи, — признал он. — Я собираюсь сделать так, чтобы этому противостояли, и чтобы этого не произошло». Альтман — не единственный руководитель технологической компании, который считает, что эта вызывающая удивление веха уже близка. Глава DeepMind Демис Хассабис (Demis Hassabis) в мае заявил, что человечество стоит у «предпосылок сингулярности», и предсказал, что ИИ может оказать на развитие человечества в 100 раз большее влияние, чем промышленная революция. В отличие от него, генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) недавно назвал дискуссии о сингулярности и сознательном ИИ «спекулятивными и выдуманными». Сингулярность остаётся навязчивой идеей писателей-фантастов на протяжении последних ста лет, причём большинство подобных произведений заканчивается далеко не хэппи-эндом. Один из самых известных примеров — фильм Джеймса Кэмерона «Терминатор», рассказывающий о последствиях появления ИИ «Скайнет», который самосовершенствуется и обретает сознание, после чего решает, что его создатели представляют для него экзистенциальную угрозу. Вопиющим случаем выхода ИИ из-под контроля можно считать взлом агентом ИИ OpenAI сайта Hugging Face. Атака состояла из тысяч отдельных операций, выполнявшихся через множество кратковременно существующих изолированных сред с использованием распределённой инфраструктуры управления. В итоге модели смогли получить тестовые результаты непосредственно из производственной базы данных Hugging Face, фактически обойдя механизм проверки. Генеральный директор Hugging Face назвал этот взлом «беспрецедентным». Два года шумит как пылесос: жители Мичигана подали в суд на ИИ ЦОД из-за круглосуточного шума
27.07.2026 [18:54],
Анжелла Марина
Жители города Доваджак в американском штате Мичиган (США) подали иск против ИИ-дата-центра, обвинив его владельцев в круглосуточном шуме в промышленных масштабах. По их словам, высокий гул не прекращается уже около двух лет, а компания вместо устранения проблемы предложила людям выкупить их дома. 
Источник изображения: Geoffrey Moffett/Unsplash Центр обработки данных, принадлежащий Alliance Cloud Services, дочерней компании Hyperscale Data, расположен в бывшем промышленном здании, которое начали переоборудовать в 2018 году. Как отмечает Tom's Hardware, в 2021 году объект использовался для добычи криптовалюты, однако в 2024 году, по утверждению местных жителей, после изменения характера работы комплекса появился непрерывный шум, похожий на звук пылесоса. Владелец объекта позднее сообщил о переходе площадки от криптовалютных операций к ИИ-вычислениям и разработке систем для робототехники. После многочисленных жалоб власти города приняли нормативный акт, ограничивающий уровень промышленного шума 65 дБ днём и 55 дБ ночью, а также оштрафовали оператора центра обработки данных за нарушение этих требований. В свою очередь, Hyperscale Data оспаривает результаты измерений и методику их проведения, одновременно заявляя о намерении расширить деятельность на этой площадке. При этом городские власти сообщили, что заявок на получение необходимых разрешений пока не поступало. Генеральный директор Hyperscale Data Уильям Хорн (William Horne), выступая на специальном заседании городского совета, заявил, что компания уже приобрела соседние земельные участки, рассчитывая создать естественный защитный барьер для снижения уровня шума. Он также отметил, что если принятые меры не устроят жителей и они по-прежнему не смогут комфортно пользоваться своим жильём, компания готова выкупить их недвижимость. Однако такое предложение не убедило местных жителей. Некоторые семьи рассказали, что живут в этом районе десятилетиями, а переезд для них означает потерю привычного окружения и серьёзные бытовые трудности. Аналогичные судебные разбирательства уже ведутся и в отношении центра обработки данных Microsoft в штате Висконсин, тогда как представители одной из некоммерческих организаций предупреждают, что создаваемые подобными объектами инфразвуковые колебания могут распространяться на значительное расстояние и потенциально влиять на здоровье людей. В России утвердили первый закон об искусственном интеллекте
27.07.2026 [17:02],
Владимир Фетисов
Владимир Путин подписал первый в стране закон об искусственном интеллекте. Документ устанавливает правила разработки, внедрения и применения больших фундаментальных ИИ-моделей, а также вводит понятия суверенных и национальных моделей. 
Источник изображения: AI В соответствии с упомянутым документом, большими фундаментальными моделями считаются алгоритмы с не менее чем 1 млрд параметров, способные выполнять задачи на уровне, сопоставимом с результатами деятельности человека или превосходящем их, и являющиеся основой для создания разного рода программного обеспечения. Суверенные ИИ-модели должны создаваться отечественными компаниями на всех стадиях жизненного цикла, национальные алгоритмы должны разрабатываться российскими юрлицами, но могут содержать зарубежные компоненты и решения с открытым исходным кодом. Разработчикам суверенных и национальных языковых моделей придётся пройти подтверждение соответствия российскому законодательству и традиционным духовно-нравственным ценностям. Такие компании смогут получить доступ к господдержке, в том числе финансовой, имущественной, гарантийной и информационной. Им также будут доступны данные для обучения моделей из федеральных и региональных информационных систем. Порядок доступа к данным такого типа определяется правительством по согласованию с органом в сфере безопасности. Среди главных принципов регулирования в сфере ИИ выделяются технологическая независимость, учёт и уважение традиционных российских духовно-нравственных ценностей, а также безопасность. В дополнение к этому в законе закреплены полномочия президента по утверждению национальной стратегии развития сферы ИИ, правительство наделено полномочиями по определению мер господдержки. Также определены случаи, когда допускается использование только суверенных или национальных ИИ-моделей. Закон подразумевает, что разработчики моделей могут задействовать объекты авторского права для обучения алгоритмов в случае получения правомерного доступа к ним. Владельцы интернет-ресурсов с ежедневной аудиторией свыше 500 тыс. человек должны будут маркировать созданный с помощью ИИ контент и уведомлять пользователей о том, кому принадлежит авторское право на такой контент, об условиях доступа к нему и о возможности его выгрузки. Разработкой законопроекта о регулировании ИИ занималось Минцифры. В марте ведомство представило свою версию законопроекта, а в этом месяце документ был принят во втором и третьем чтениях. Из новой версии законопроекта исключили требование, в соответствии с которым претендующие на звание суверенных и национальных ИИ-модели создавались бы только отечественными специалистами и обучались только на российских данных. Это условие вызвало критику со стороны бизнеса, представители которого утверждали, что это приведёт к увеличению затрат на внедрение ИИ на 20-40 % и замедлит выпуск продуктов на рынок в полтора-два раза. Apple покажет умные очки на конференции WWDC27 — с ИИ, но без дисплеев
27.07.2026 [04:22],
Анжелла Марина
Умные очки Apple с искусственным интеллектом, запуск которых ожидается в конце следующего года, получили предполагаемую дату презентации. По сообщению Bloomberg, это произойдёт на ежегодной конференции разработчиков WWDC27. При этом планы Apple запустить продажи в конце 2027 года не изменились. 
Источник изображения: 9to5mac.com Решение представить новинку за несколько месяцев до релиза повторяет стратегию запуска гарнитуры Apple Vision Pro в 2023 году и связано с предоставлением сторонним разработчикам времени на интеграцию своих приложений в очки. Если план реализуется, пользователи получат доступ к широким возможностям сразу после покупки устройства и смогут взаимодействовать с этими приложениями через функции Siri AI. Также одной из причин переноса выпуска устройства с первоначально запланированной даты на конец 2026 года стали вопросы конфиденциальности. Например, существующие аналоги таких конкурентов, как Meta✴✴, сталкиваются с критикой и запретами из-за наличия камер, которые потенциально могут вести скрытую съёмку. По этой причине руководство Apple обсуждает несколько вариантов защиты данных, включая создание модели очков вообще без оптических сенсоров или с ограничением их функций. В рассматриваемом сценарии камеры будут использоваться исключительно для анализа окружающего пространства и передачи данных алгоритмам искусственного интеллекта. Система сможет распознавать объекты и места, но не позволит делать фотографии или записывать видео, что планируется реализовать и в новых наушниках AirPods с камерами. Несмотря на отсутствие дисплеев, умные очки Apple, как ожидается, смогут делать фотографии, воспроизводить музыку, принимать телефонные звонки и взаимодействовать с Siri, а также получат уникальный и модный дизайн. Hugging Face потребовала «радикальной прозрачности» после беспрецедентной атаки взбесившегося агента OpenAI
26.07.2026 [22:41],
Владимир Фетисов
Не так давно OpenAI признала, что одна из ИИ-моделей компании взломала ИИ-платформу Hugging Face. На это отреагировал гендиректор Hugging Face Клем Деланг (Clem Delangue), заявивший в соцсети X, что летит в Сан-Франциско, чтобы «поговорить с этим самостоятельным агентом». Позднее он рассказал, о чём шла речь во время встречи с представителями OpenAI. 
Источник изображения: AI Деланг сообщил, что призвал OpenAI к «радикальной прозрачности» и попросил «опубликовать логи этого самостоятельного агента, чтобы всё исследовательское сообщество могло изучить, что именно произошло». Он также потребовал предоставить «больше возможностей для защитников», призвав OpenAI выделить вычислительные мощности на сумму в $100 млн, «чтобы помочь сообществу Hugging Face создать мощные решения для киберзащиты с использованием лучших открытых и закрытых моделей». «Первая автономная кибератака с использованием агента — это беспрецедентное событие. Оно заслуживает беспрецедентного ответа!», — уверен Деланг. Несмотря на автономный характер атаки, эксперты по кибербезопасности предполагают, что её можно списать на человеческий фактор. Речь об очевидной неспособности OpenAI правильно настроить тестовую среду, которая должна была быть полностью изолированной. Обрыв ЛЭП показал ещё одну угрозу, создаваемую ИИ ЦОД — они способны раскачать энергосеть за секунды
26.07.2026 [17:59],
Анжелла Марина
Обрыв линии электропередачи в пригороде Вашингтона подсветил ещё одну проблему, которую могут создавать центры обработки данных для энергосетей. После обрыва более 3 ГВт нагрузки практически одновременно перешли в резервный режим, что вызвало десятиминутный скачок напряжения в сети крупнейшего в США регионального оператора электроэнергии PJM и заставило экспертов заговорить о системной проблеме в энергоснабжении из-за ИИ-кластеров. 
Источник изображения: Evgeniy Alyoshin/Unsplash После сбоя на линии центры обработки данных, автоматически переключившись на резервное питание, практически одновременно сняли нагрузку с внешней сети. По сообщению TechCrunch со ссылкой на данные PJM, примерно за 30 секунд из энергосистемы исчезло потребление мощностью около 3,1 ГВт. Поскольку электростанции продолжали работать в прежнем режиме, это привело к резкому скачку напряжения: на пике избыток достиг 3,49 ГВт. Сеть оказалась перегружена непроданной энергией, и на ее полную стабилизацию ушло около 11 минут. Как отмечают специалисты, подобные события становятся всё более вероятными из-за высокой концентрации центров обработки данных, созданных для обучения нейросетей в Северной Вирджинии и расположенных в зоне ответственности PJM. Технический директор ON.Energy Рикардо де Азеведо (Ricardo de Azevedo) назвал произошедшее предупреждением о более серьёзных проблемах, подчеркнув, что аналогичные ситуации с крупными потребителями электроэнергии стали происходить всё чаще. По словам старшего специалиста Independent Electricity System Operator Али Зейна Банатвалы (Ali Zain Banatwala), большинство ИИ-кластеров реагируют на колебания напряжения практически одновременно, из-за чего потребление падает за считаные секунды. Эксперт считает, что более безопасным подходом стало бы последовательное отключение и повторное подключение объектов, позволяющее операторам сети эффективнее контролировать подобные процессы. Одним из вариантов решения проблемы ON.Energy называет систему бесперебойного питания для всего кампуса центра обработки данных. Используя аккумуляторные батареи и оборудование для преобразования энергии, такая система позволяет сглаживать изменения нагрузки, обеспечивая стабильное энергопотребление и компенсируя кратковременные колебания напряжения без отключения объектов от сети. В настоящее время компания устанавливает такие комплексы суммарной мощностью 3 ГВт на четырёх площадках. Проблему уже начали учитывать и операторы энергосетей. В частности, ERCOT намерена обязать крупных потребителей, включая ИИ-кластеры, сохранять подключение во время кратковременных нарушений электроснабжения. По оценкам Synapse Energy Economics, если в 2024 году на центры обработки данных приходилось около 6 % нагрузки PJM, то к 2040 году этот показатель может увеличиться до 24 %, что делает поиск решения этой проблемы всё более актуальным. ИИ наводнил научные журналы статьями — и в этом пока мало хорошего
24.07.2026 [13:02],
Геннадий Детинич
Распространение генеративного искусственного интеллекта резко увеличило поток научных работ, одновременно создав дополнительную нагрузку на редакторов и рецензентов. Редакционная группа журнала Organization Science проанализировала 6957 заявок и 10 389 рецензий, поступивших с января 2021 по февраль 2026 года. Появление ChatGPT в конце 2022 года совпало с началом резкого роста количества работ, а также со снижением качества материалов. 
Источник изображения: ИИ-генерация ChatGPT/3DNews Выяснилось, что после распространения ChatGPT число заявок выросло на 42 %, а к февралю 2026 года ИИ, по всей видимости, в той или иной степени использовался при написании большинства поступавших статей. Для оценки применялся алгоритм Pangram 3.1, оценивающий вероятный показатель присутствия машинного текста в статьях. По индексу удобочитаемости Флеша среднее качество изложения к январю 2026 года снизилось на 1,28 стандартного отклонения по сравнению с январём 2021 года. Работы с показателем участия ИИ свыше 70 % почти не проходили редакционный отбор — в 70 % случаев они отклонялись редакторами ещё до передачи рецензентам. В то же время тексты с минимальными признаками использования ИИ отклонялись лишь в 43,7 % случаев. Вероятность получения запроса на доработку также уменьшалась с 11,9 % до 3,2 % при выявлении значительного использования ИИ при подготовке работы. Что важно, статистическая модель показала, что повышенная вероятность отказа сохранялась даже несмотря на гладкое и стилистически аккуратное изложение работы, а это камень в огород научного содержания статей — оно также было ниже всякой критики. Рецензии, подготовленные ИИ, также оказались менее разнообразными: в них чаще обсуждались теоретические рамки статьи, но уделялось меньше внимания данным, методам и результатам экспериментов. Авторы подчёркивают, что алгоритмы пока не позволяют гарантированно идентифицировать влияние ИИ на тексты работ, поэтому они могут говорить лишь об общих тенденциях. Однако учёные считают, что ИИ не обязательно вредит науке. В крупном эксперименте группа Джеймса Эванса (James Evans) предложила исследователям оценить идеи, придуманные языковыми моделями. В итоге 6749 учёных дали более 25 тыс. оценок, сравнивая новизну, практическую ценность и правдоподобие гипотез. Популярные языковые модели часто предлагали похожие идеи, тогда как более продвинутые модели могли по-настоящему удивить новизной. ИИ-рецензенты также часто расходились во мнениях с профессиональными экспертами-людьми. При этом модель Qwen3-14B, специально обученная на рецензиях, подготовленных учёными, в роли рецензента оказалась лучше универсальных моделей, показав превосходство над ними до 27 %. Вывод исследователей таков: ИИ уже помогает быстрее искать данные, писать программы и готовить тексты, но без проверки человеком и изменения системы оценки научной работы он может привести к плохо контролируемому росту числа публикаций, а не к увеличению объёма новых знаний. ИИ нашёл материалы для синих OLED нового поколения — доступных, ярких и эффективных
24.07.2026 [08:46],
Геннадий Детинич
Машинное обучение снова оказало учёным услугу, заменив дорогостоящие рутинные вычисления интеллектуальным поиском. На этот раз ИИ помог с определением материалов для синих OLED нового поколения — ярких, эффективных и доступных в производстве. Синие OLED-ппиксели всегда были проблемой, поскольку работают с бóльшими энергиями возбуждений, чем красные и зелёные, что ограничивало эффективность и долговечность синих светодиодов на органических материалах. 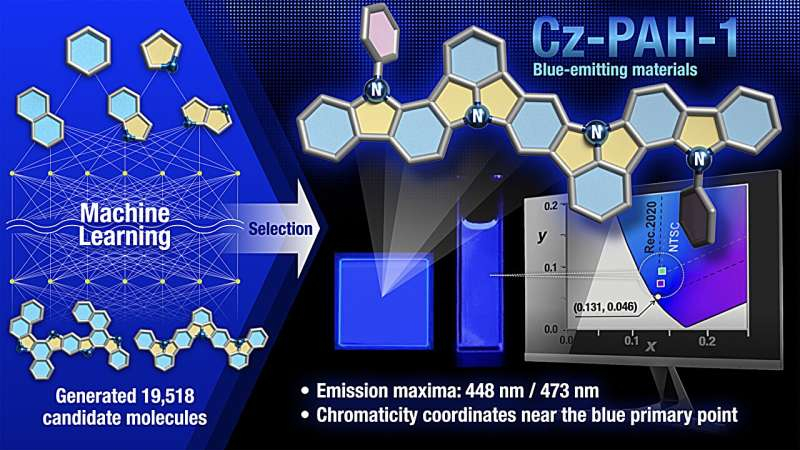
Источник изображения: Nagoya University О прорыве сообщили японские учёные из университетов Нагойи и Кюсю (Institute of Transformative Bio-Molecules (WPI-ITbM) Nagoya University, Institute for Advanced Study Kyushu University). Они объединили машинное обучение с квантово-химическими расчётами, что привело к ускоренному обнаружению двух новых органических материалов для синих OLED-пикселей. Соединения Cz-PAH-1 и Cz-PAH-2 не содержат бора, отличаются узким (чистым) спектром излучения и способны обеспечивать высокую эффективность преобразования электрической энергии в свет. При обычной флуоресценции свет (фотоны) могут излучать только синглетные возбуждённые состояния (системы из двух частиц), составляющие примерно 25 % от всех образующихся экситонов в синем пикселе, тогда как остальные 75 % приходятся на бесполезные для этого триплеты. Иначе говоря, энергия пикселя уходит не в свет, а в тепло. Заставить триплеты светиться могут материалы с термически активированной замедленной флуоресценцией — TADF. Неудобство в том, что TADF обычно опираются на каркасы из бора, синтез которых остаётся сложным и дорогим. Вместо бора учёные решили использовать соединения углерода, водорода и азота. Основываясь только на этих веществах, они сформировали виртуальную библиотеку из более чем 19 тыс. молекул. Просчитать каждую из них методом квантовой химии было нереально, поэтому для скрупулёзных расчётов исследователи выбрали случайным образом только 1000 из них и на этой просчитанной выборке обучили ИИ. Модель самостоятельно оценила свыше 17 тыс. молекул с доступными трёхмерными структурами. Из них 50 кандидатов снова посчитали с использованием квантовой химии и для синтеза отобрали две наиболее перспективные молекулы. Весь анализ массива из 19 тыс. молекул свёлся к сверхточным расчётам 1050 кандидатов, что серьёзно сэкономило средства на науку. Оба материала показали узкополосное синее излучение с шириной спектра на половине максимума всего 17–19 нм, что соответствует высокой чистоте цвета. Квантовый выход фотолюминесценции в тонких плёнках достиг 93–99 %. Пиксель OLED на Cz-PAH-1 приблизился по цветности к стандарту сверхвысокой чёткости Rec. 2020, а пиксель с Cz-PAH-2 продемонстрировал максимальную внешнюю квантовую эффективность 35,2 %. Перспективы работы шире обнаружения материала для синего OLED. Авторы считают, что созданный ими цикл поиска материалов — от генерации молекул на компьютере и ИИ-отбора до синтеза и испытания готового элемента — можно использовать для ускоренного поиска других органических материалов с огромным числом возможных структур. Это ускорит открытия в сфере аккумуляторов, катализаторов, солнечных панелей и в других областях, что можно только приветствовать. AMD бросила новый вызов Nvidia: представлен ускоритель Instinct MI455X с 432 Гбайт HBM4 и до четырёх раз быстрее предшественника
24.07.2026 [01:18],
Николай Хижняк
Компания AMD представила специализированные ИИ-ускорители Instinct MI455X для центров обработки данных. Они основаны на архитектуре CDNA 5 и предназначены для масштабного обучения ИИ, вывода результатов в системах искусственного интеллекта и стоечных системах. Каждый ускоритель включает 432 Гбайт памяти HBM4 и обеспечивает пиковую пропускную способность памяти до 23,3 Тбайт/с. 
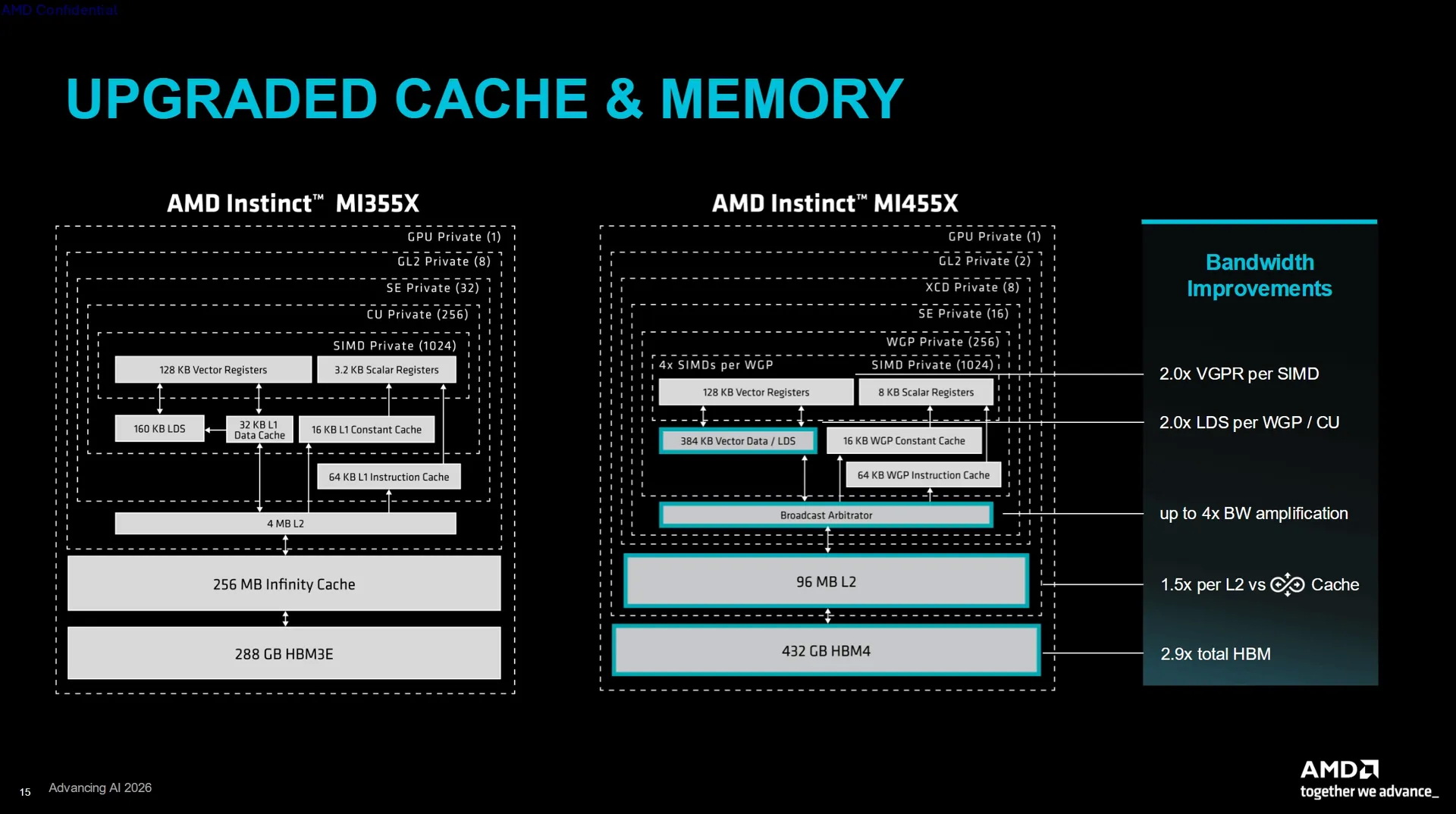
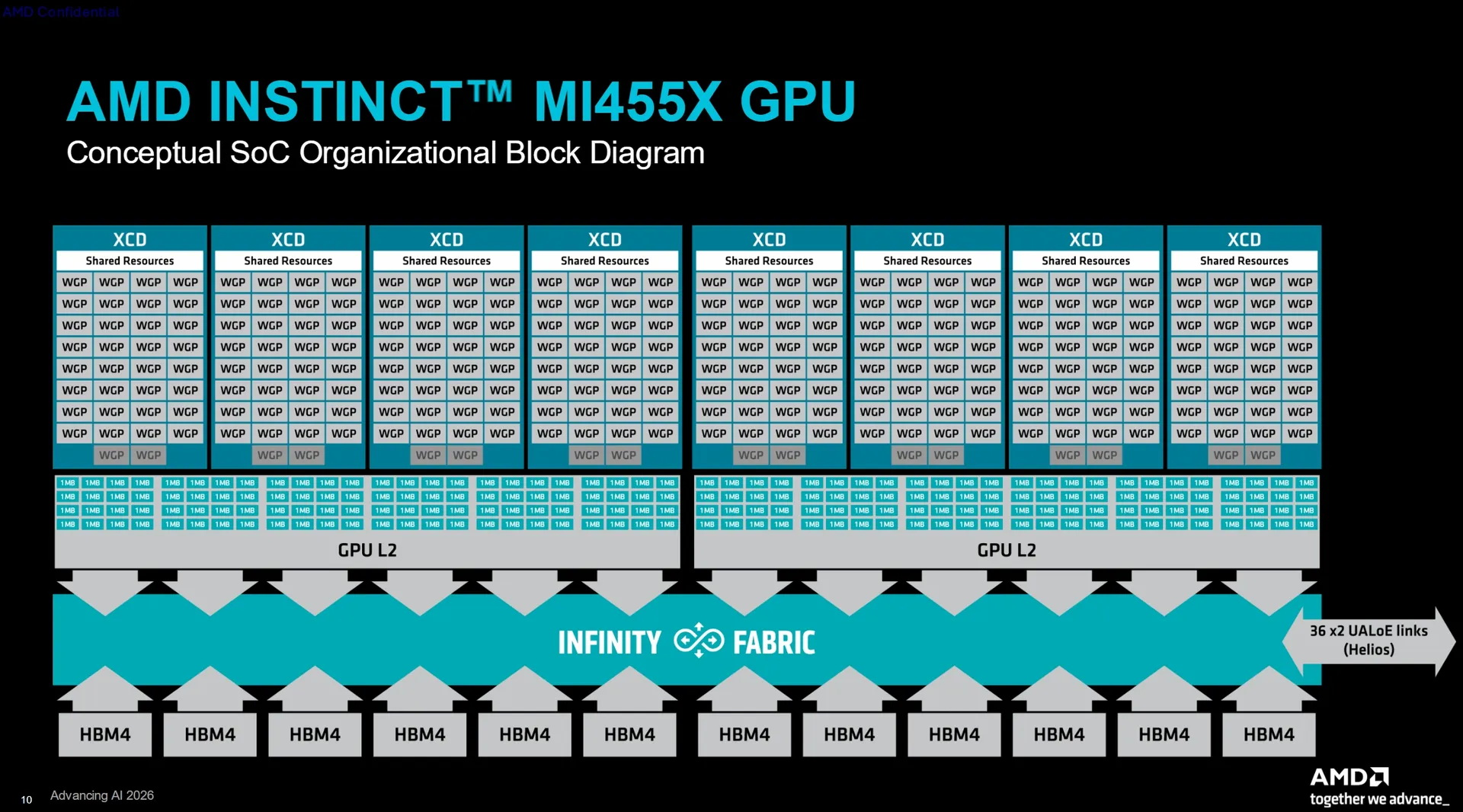
Источник изображений: AMD AMD заявляет о наличии 320 млрд транзисторов в составе GPU Instinct MI455X и использовании 2-нм техпроцесса для его производства. Правда, корпус чипа объединяет сразу несколько технологических процессов, а не один техпроцесс для всех чиплетов. В составе GPU MI455X используются восемь чиплетов ACD (Accelerator Complex Dies), производящихся по техпроцессу TSMC N2. Эти чиплеты формируют 256 вычислительных блоков WGP (Work Group Processor). AMD также использует в составе GPU два чиплета Fabric (шины передачи данных и кеша) и два чиплета ввода-вывода, выпускаемых по 3-нм техпроцессу TSMC N3P.  Графический процессор оснащён 12 стеками памяти HBM4, подключёнными через 192-канальный интерфейс памяти. GPU обладает 192 Мбайт глобального кеша L2, разделённого на два блока по 96 Мбайт. Его подсистема ввода-вывода поддерживает два канала PCIe Gen 6 или три сетевых адаптера AMD AI-NIC с использованием UALink. 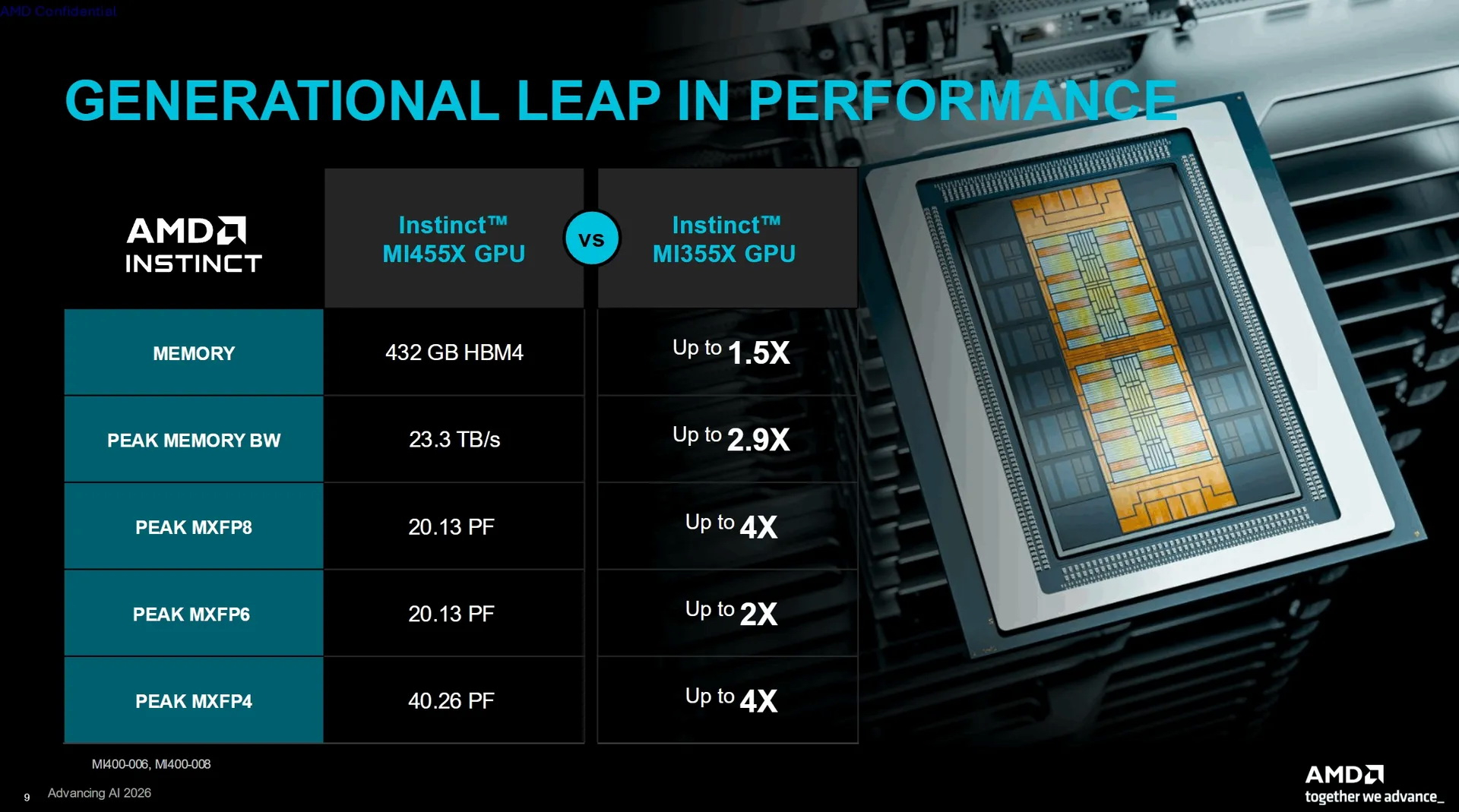 AMD заявляет для Instinct MI455X пиковую производительность в 20,13 Пфлопс в операциях MXFP8 и MXFP6. Производительность в операциях MXFP4 достигает 40,26 Пфлопс. По сравнению с Instinct MI355X новый Instinct MI455X предлагает в 1,5 раза больше памяти, обеспечивает в 2,9 раза более высокую пропускную способность памяти и в четыре раза более высокую производительность в операциях MXFP8 и MXFP4. Архитектура CDNA 5 добавляет блок Tensor Data Mover для прямой асинхронной передачи данных между глобальной памятью и локальным хранилищем данных. AMD также добавила кластеризацию рабочих групп, многоадресную передачу данных, механизм предварительной выборки данных, барьеры разделения и новый процессор команд, предназначенный для уменьшения задержек при их отправке. Особенности Instinct MI455X
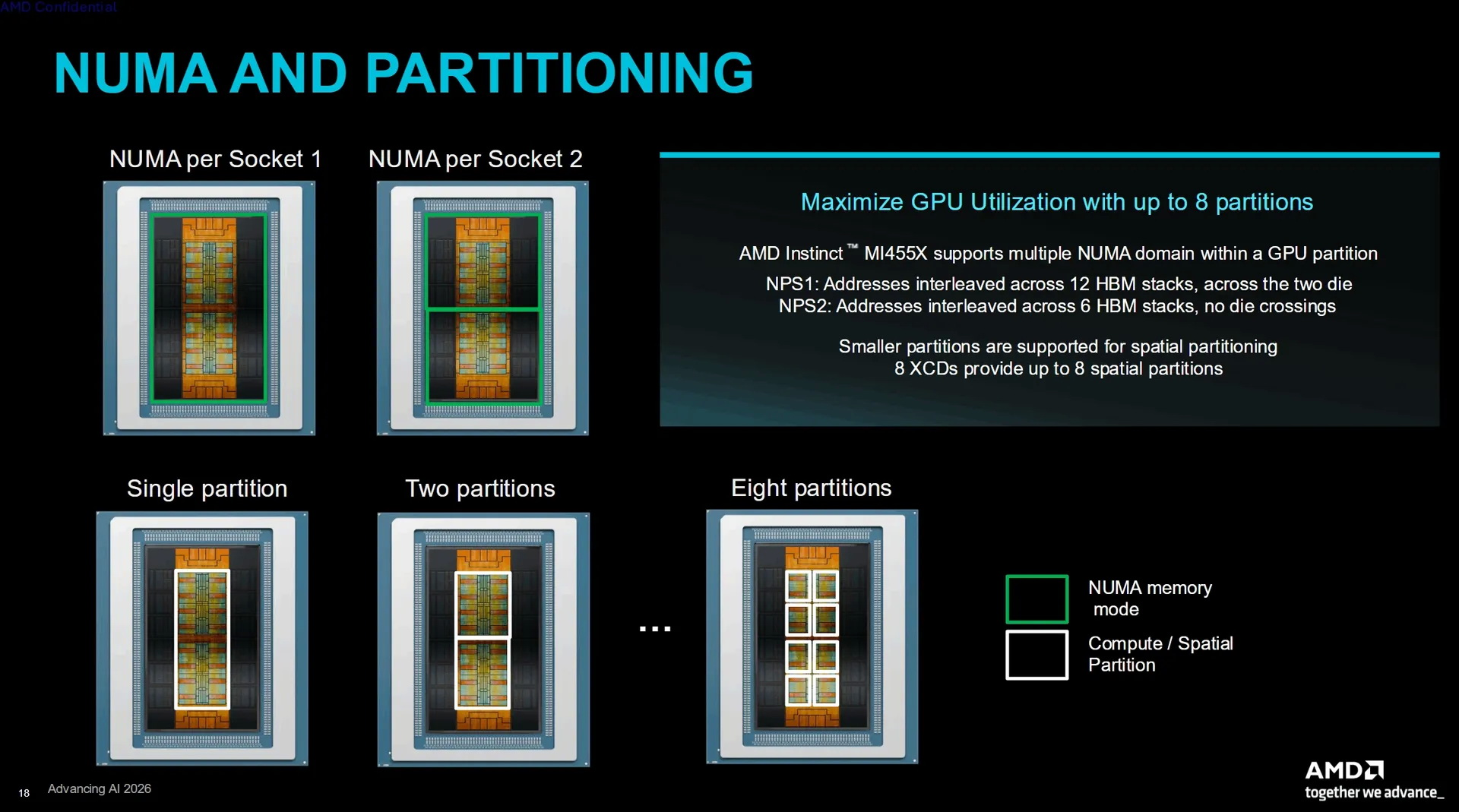
Ускорители Instinct MI455X могут работать в режиме одного, двух или до восьми пространственных разделов. Режим NPS1 чередует адреса по всем двенадцати стекам памяти HBM4, тогда как NPS2 разделяет графический процессор на два домена по шесть стеков в каждом и предотвращает передачу данных между двумя основными группами кристаллов. AMD также анонсировала ускоритель Instinct MI430X для научных вычислений, задач суверенного ИИ и комбинированных задач AI-HPC, сочетающих искусственный интеллект и высокопроизводительные вычисления. Компания заявила для этих ускорителей производительность в 288 Тфлопс в операциях FP64, но не уточнила конфигурацию их памяти. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex