|
Опрос
|
реклама
Быстрый переход
AMD бросила новый вызов Nvidia: представлен ускоритель Instinct MI455X с 432 Гбайт HBM4 и до четырёх раз быстрее предшественника
24.07.2026 [01:18],
Николай Хижняк
Компания AMD представила специализированные ИИ-ускорители Instinct MI455X для центров обработки данных. Они основаны на архитектуре CDNA 5 и предназначены для масштабного обучения ИИ, вывода результатов в системах искусственного интеллекта и стоечных системах. Каждый ускоритель включает 432 Гбайт памяти HBM4 и обеспечивает пиковую пропускную способность памяти до 23,3 Тбайт/с. 
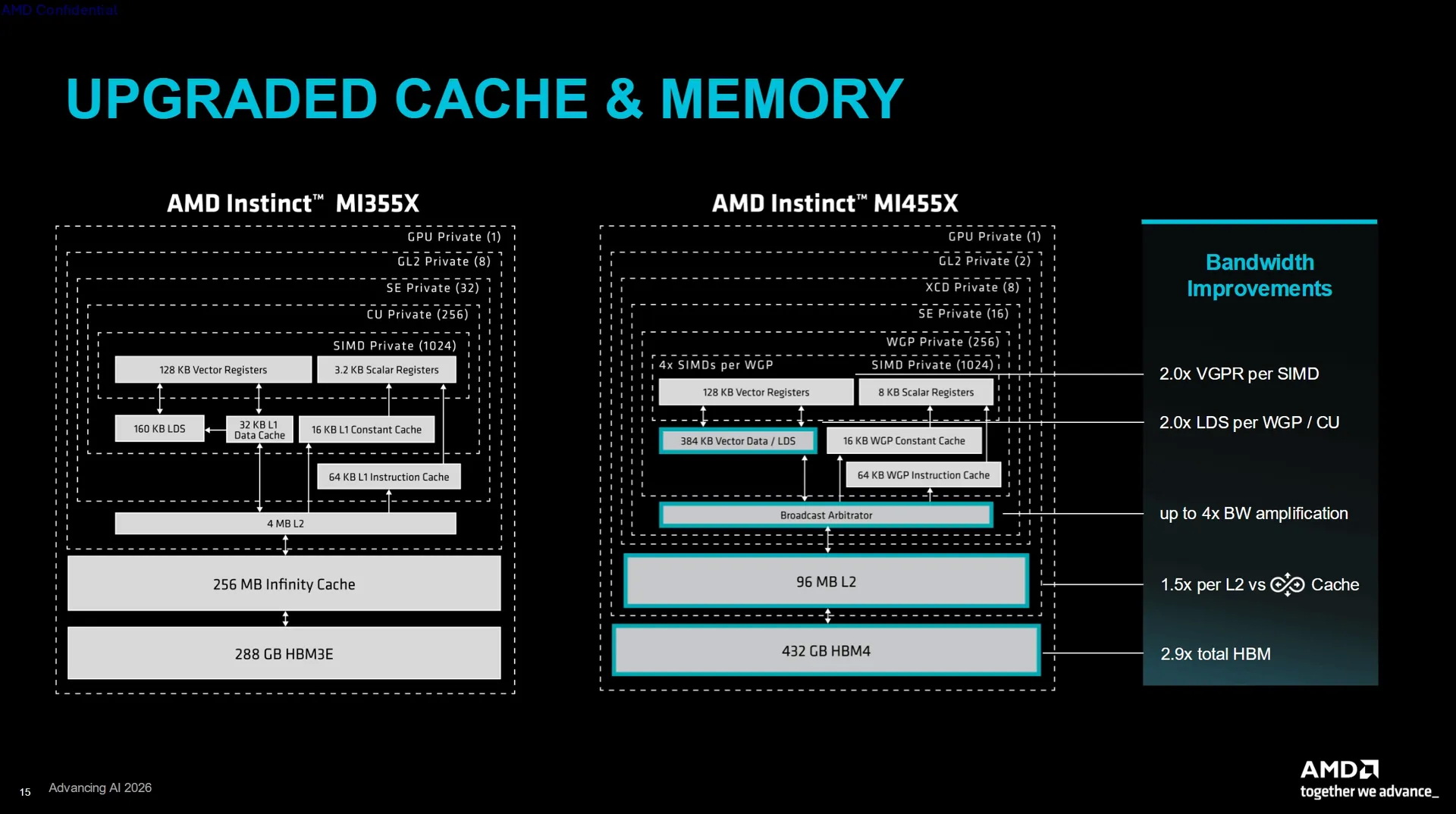
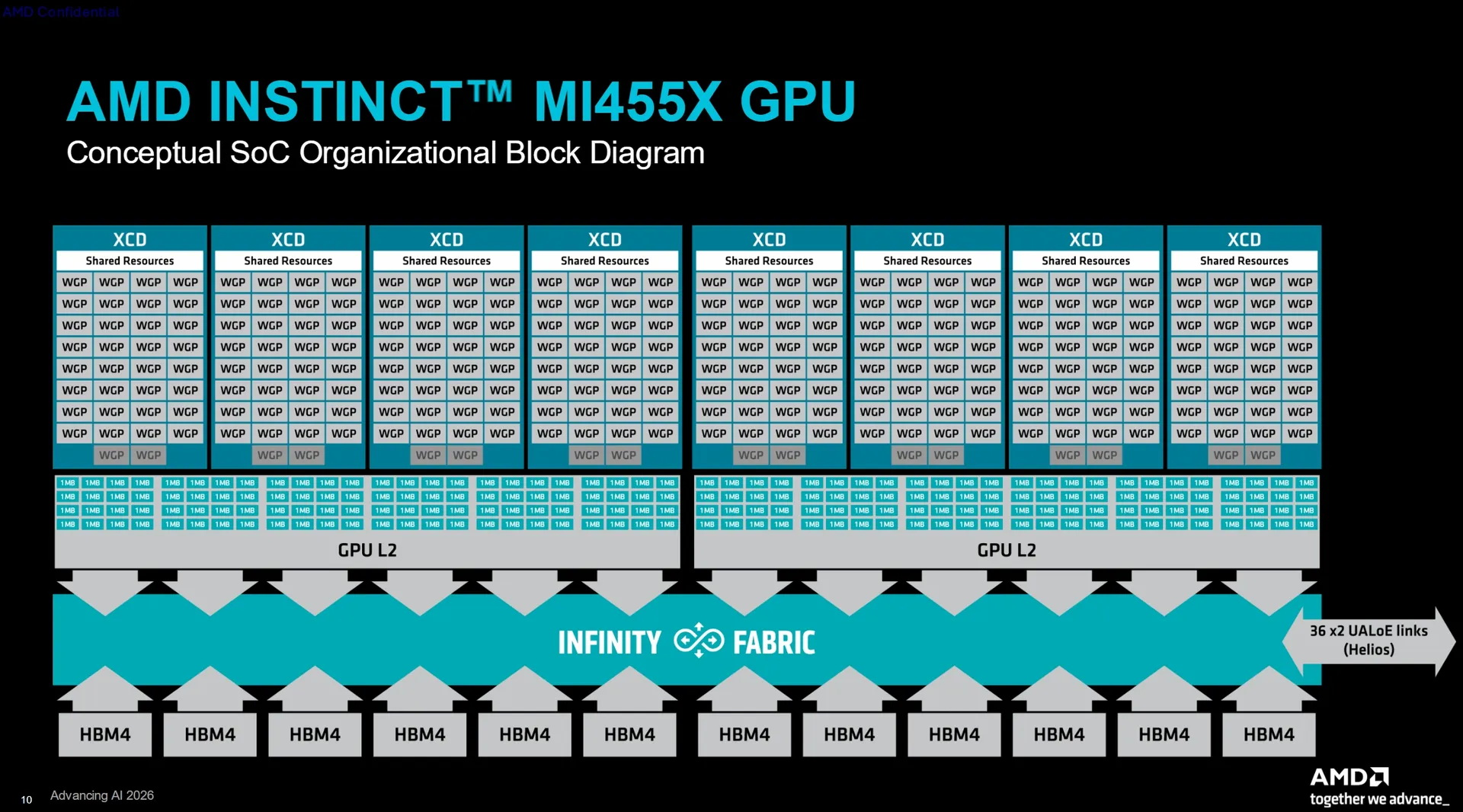
Источник изображений: AMD AMD заявляет о наличии 320 млрд транзисторов в составе GPU Instinct MI455X и использовании 2-нм техпроцесса для его производства. Правда, корпус чипа объединяет сразу несколько технологических процессов, а не один техпроцесс для всех чиплетов. В составе GPU MI455X используются восемь чиплетов ACD (Accelerator Complex Dies), производящихся по техпроцессу TSMC N2. Эти чиплеты формируют 256 вычислительных блоков WGP (Work Group Processor). AMD также использует в составе GPU два чиплета Fabric (шины передачи данных и кеша) и два чиплета ввода-вывода, выпускаемых по 3-нм техпроцессу TSMC N3P.  Графический процессор оснащён 12 стеками памяти HBM4, подключёнными через 192-канальный интерфейс памяти. GPU обладает 192 Мбайт глобального кеша L2, разделённого на два блока по 96 Мбайт. Его подсистема ввода-вывода поддерживает два канала PCIe Gen 6 или три сетевых адаптера AMD AI-NIC с использованием UALink. 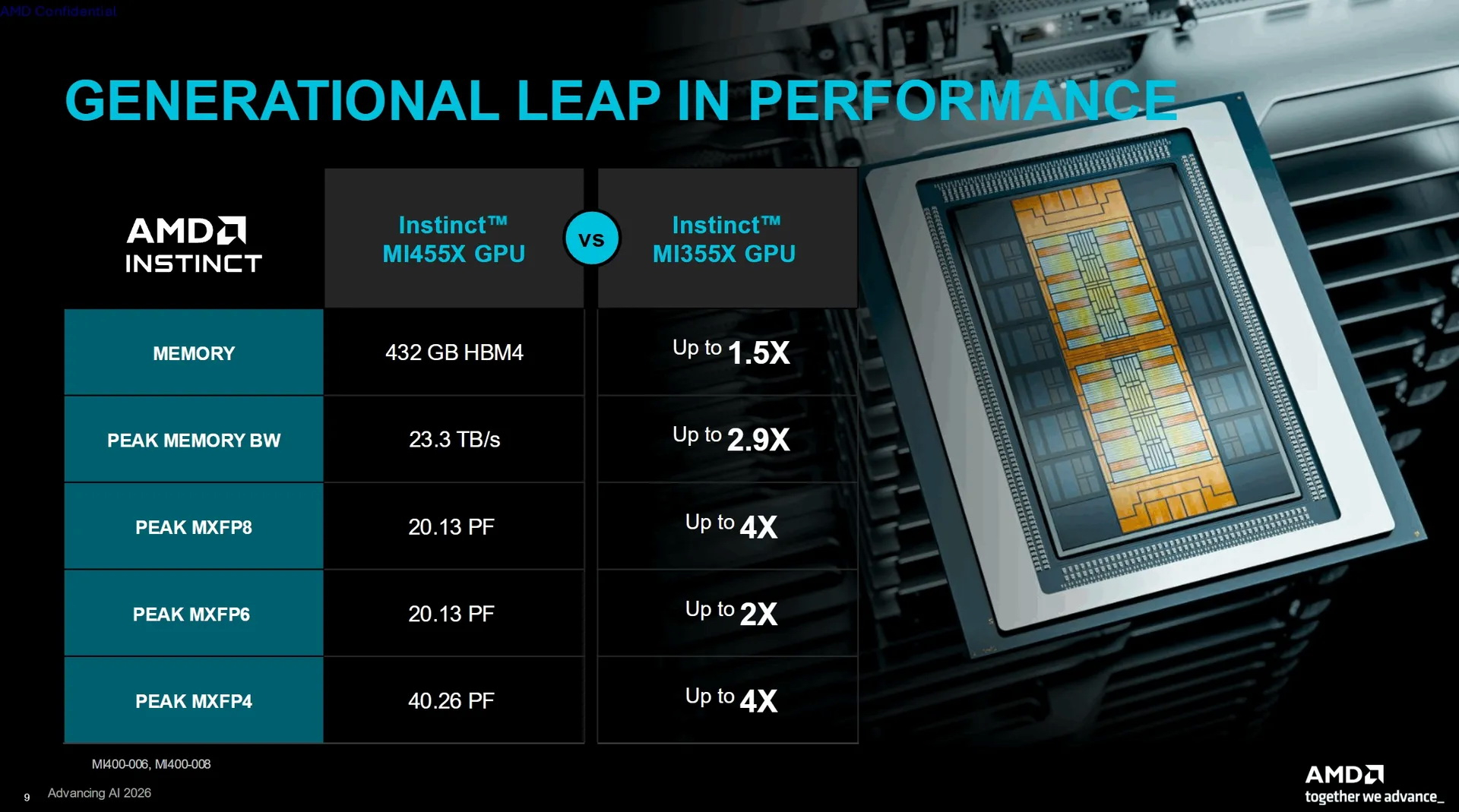 AMD заявляет для Instinct MI455X пиковую производительность в 20,13 Пфлопс в операциях MXFP8 и MXFP6. Производительность в операциях MXFP4 достигает 40,26 Пфлопс. По сравнению с Instinct MI355X новый Instinct MI455X предлагает в 1,5 раза больше памяти, обеспечивает в 2,9 раза более высокую пропускную способность памяти и в четыре раза более высокую производительность в операциях MXFP8 и MXFP4. Архитектура CDNA 5 добавляет блок Tensor Data Mover для прямой асинхронной передачи данных между глобальной памятью и локальным хранилищем данных. AMD также добавила кластеризацию рабочих групп, многоадресную передачу данных, механизм предварительной выборки данных, барьеры разделения и новый процессор команд, предназначенный для уменьшения задержек при их отправке. Особенности Instinct MI455X
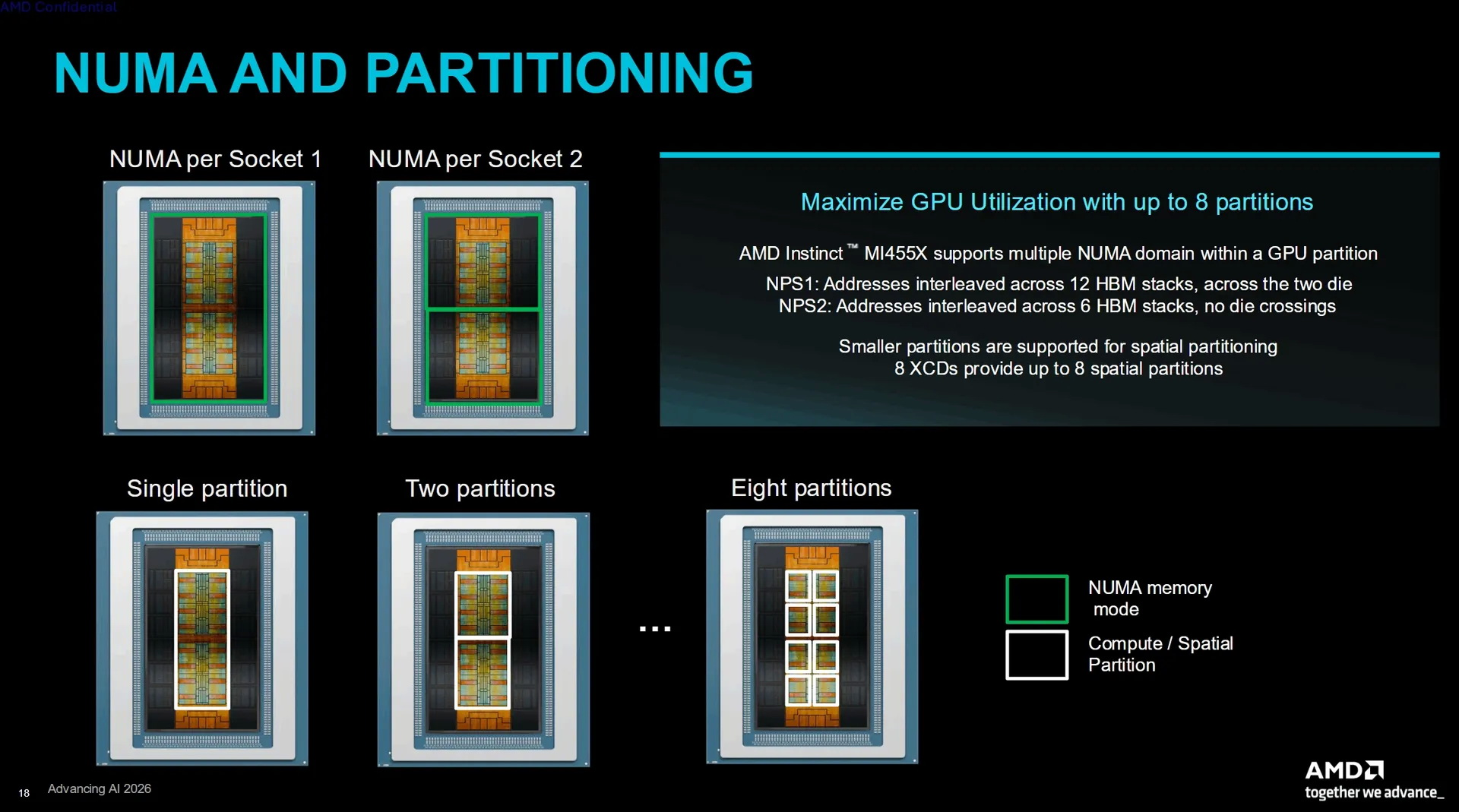
Ускорители Instinct MI455X могут работать в режиме одного, двух или до восьми пространственных разделов. Режим NPS1 чередует адреса по всем двенадцати стекам памяти HBM4, тогда как NPS2 разделяет графический процессор на два домена по шесть стеков в каждом и предотвращает передачу данных между двумя основными группами кристаллов. AMD также анонсировала ускоритель Instinct MI430X для научных вычислений, задач суверенного ИИ и комбинированных задач AI-HPC, сочетающих искусственный интеллект и высокопроизводительные вычисления. Компания заявила для этих ускорителей производительность в 288 Тфлопс в операциях FP64, но не уточнила конфигурацию их памяти. Google: ИИ ещё очень далёк от замены людей — пользователи доверяют ему лишь 21 % рабочих задач
24.07.2026 [01:13],
Николай Хижняк
Искусственный интеллект используется для выполнения широкого спектра профессиональных задач. Однако, согласно новому исследованию Google, основанному почти на 15 миллионах взаимодействий с Gemini, ИИ ещё не стал той силой, которая может полностью автоматизировать рабочие процессы, заменив настоящих людей, чего так опасаются многие. 
Источник изображения: blog.google Портал Axios со ссылкой на отчёт Google пишет, что это исследование даёт общее представление о реальном уровне использования ИИ, подчёркивая разрыв между профессиями, которые могут быть затронуты ИИ, профессиями, в которых работники используют ИИ, и задачами, которые автоматизируются с помощью искусственного интеллекта. Google обнаружила, что люди в основном используют Gemini в качестве помощника — для исследований, составления проектов, выполнения циклических задач, решения различных неполадок и обучения, — а не делегируют ему выполнение целых комплексных задач. «Внедрение ИИ очень широко распространено, поскольку оно затрагивает огромный спектр профессий», — говорит Скотт Стрэнд (Scott Strand), экономист из подразделения Google, работающего на стыке технологий и их влияния на общество. По словам Стрэнда, в США Gemini используется на 70 % рабочих мест. При этом он добавил, что в целом в США уровень использования ИИ охватывает 90 % занятости. В то же время Стрэнд отмечает, что использование ИИ «очень поверхностно». Среднестатистический работник использует его только для 21 % задач, при этом всего около 10 % взаимодействий с Gemini направлены на автоматизацию нерутинной когнитивной работы. В целом эти выводы соотносятся с результатами более ранних исследований Anthropic и OpenAI, хотя Anthropic сообщила о более высоком уровне автоматизации. В исследовательском отчёте Google под заголовком Activity, Task, Landscape and Adoption Study (ATLAS, «Исследование активности, задач, ландшафта и внедрения») приводятся результаты анализа 14,65 млн обезличенных взаимодействий пользователей с приложением Gemini, поисковым интерфейсом Google AI Mode и API Gemini за две недели апреля этого года.  Автоматизированные системы классифицировали взаимодействия как связанные с работой или не связанные с работой, а затем сопоставили связанную с работой деятельность с 4000 задачами в 800 профессиях в 150 странах и на 140 языках. Нерабочие задачи были сопоставлены с категориями, используемыми в американском исследовании Бюро статистики труда, которое изучает, как жители США распределяют своё время между различными видами деятельности. Как отмечает Axios, в исследовании Google не учитывалось, как люди используют бизнес-ориентированные модели ИИ, такие как Gemini Enterprise и Google Workspace, поскольку компания не ведёт журналы для этих продуктов. Возможно, дополнительные данные могли бы показать более высокий уровень автоматизации. «Мы, конечно, с удовольствием использовали бы эти данные, если бы могли. Но у нас даже не было такой возможности», — сказал Стрэнд. Исследование также показало, что работники на высокооплачиваемых должностях и в более обеспеченных регионах чаще используют ИИ. Google отмечает, что увеличение медианного заработка в определённой профессии на 1 % коррелирует с увеличением уровня использования ИИ на 2,68 %. В отчёте также говорится, что представители рабочих профессий (так называемые «синие воротнички»), включая электриков (для поиска схем) и автомехаников (для поиска информации о том или ином двигателе), используют ИИ чаще, чем ожидали исследователи. «Представители рабочих профессий, как правило, активно используют то, что мы называем мультимодальным ИИ, то есть ИИ, работающий с изображениями и видео», — говорит Стрэнд. Потребительское использование ИИ тоже оказалось шире, чем ожидалось. По данным Google, на разговоры с Gemini по вопросам, не связанным с работой, пришлось около 86 % взаимодействий. ИИ использовали не только для выполнения домашних задач (готовка, уборка и т. д.), но также для навигации по государственным услугам и различным административным процедурам. Открытым остаётся вопрос, могут ли подобные исследования помочь предсказать, куда движется использование ИИ, или же они в основном представляют собой отражение того, как люди уже используют эту технологию. Google ожидает, что ATLAS станет первым в серии подобных исследований, хотя компания ещё не решила, как часто будет публиковать обновления. OpenAI запустила ChatGPT Health и заявила, что её ИИ способен рассуждать лучше врачей
24.07.2026 [00:22],
Анжелла Марина
OpenAI начала развёртывание сервиса ChatGPT Health для всех пользователей ChatGPT в США старше 18 лет. По сообщению The Verge, платформа позволит подключать медицинские карты и данные сервисов отслеживания показателей здоровья, используя их при ответах на вопросы в основном интерфейсе чат-бота. 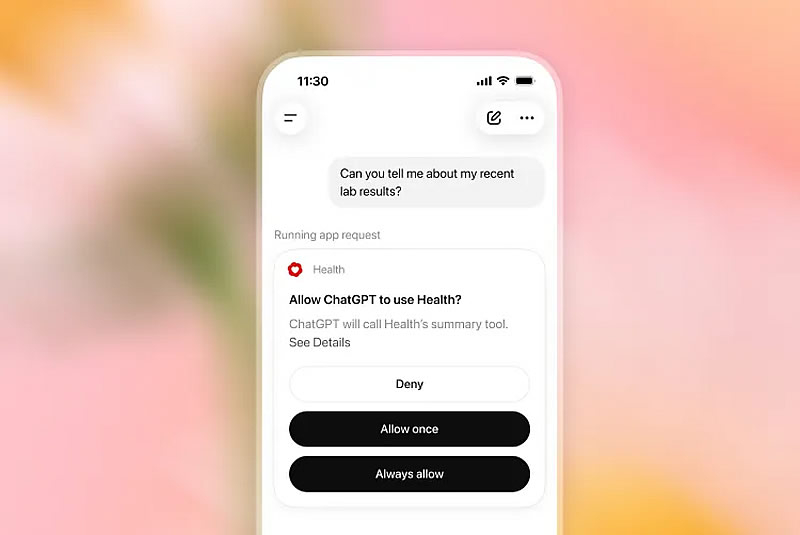
Источник изображений: OpenAI По словам вице-президента OpenAI по медицинским продуктам Эшли Александер (Ashley Alexander), ИИ-модели компании «способны рассуждать на уровне, превосходящем уровень практикующих врачей». В то же время руководитель медицинского направления OpenAI Каран Сингхал (Karan Singhal) считает, что подобную оценку следует воспринимать с осторожностью, хотя отдельные исследования указывают на то, что искусственный интеллект уже на это способен. 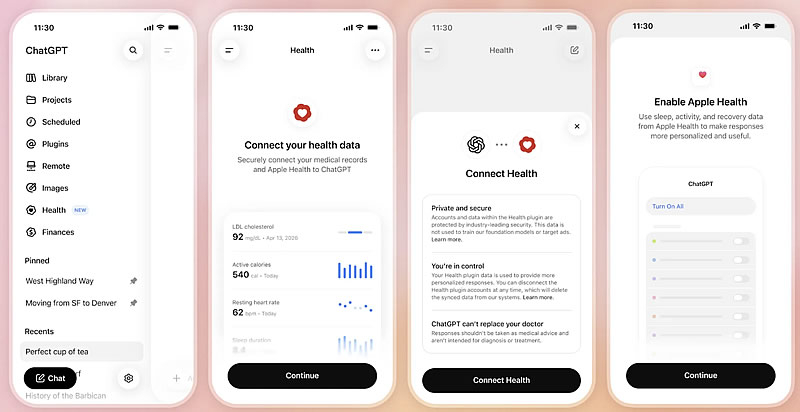 Широкий запуск ChatGPT Health состоялся всего через несколько недель после того, как OpenAI представила новую модель GPT-5.6 Sol. Теперь пользователи смогут задавать вопросы, связанные со здоровьем непосредственно в основном чате ChatGPT, не переходя в отдельный раздел Health. 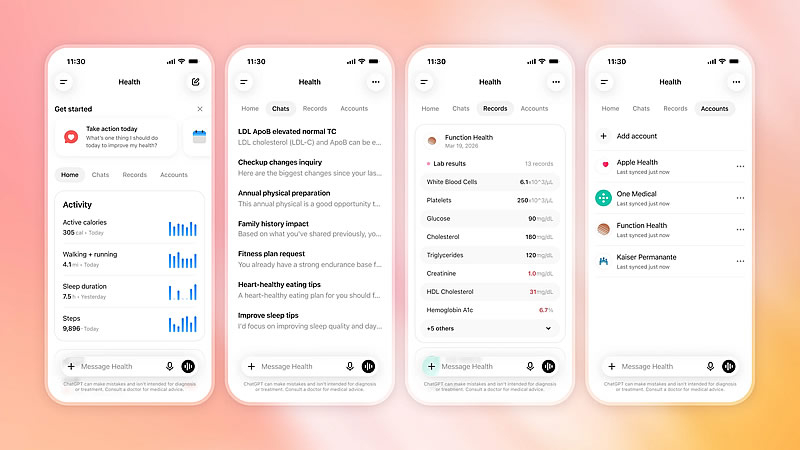 Пользователям также предоставят возможность самостоятельно выбирать, какие данные передавать ChatGPT. К сервису можно подключить записи врача после приёма, результаты лабораторных исследований, информацию о принимаемых препаратах, а также данные от медицинских учреждений и сервисов Apple Health, Weight Watchers, MyFitnessPal и других сервисов. Подчёркивается, что ChatGPT Health предназначен для поддержки пользователей, а не для замены профессиональной медицинской помощи. При этом вся переписка шифруется как при передаче, так и при хранении, а медицинские сведения получают дополнительный уровень защиты. ChatGPT Health будет работать на базе новейших моделей компании. Сервис станет доступен авторизованным пользователям веб-версии и приложения для iOS в бесплатной версии, а также на тарифах Go, Plus и Pro. Новая статья: Хочу всё знать: обзор ИИ-приложений с функцией умной камеры для Android
24.07.2026 [00:10],
3DNews Team
Данные берутся из публикации Хочу всё знать: обзор ИИ-приложений с функцией умной камеры для Android Дефицит памяти добрался до автомобилей — производители уже повышают цены
23.07.2026 [23:14],
Николай Хижняк
Хотя сборщики ПК, энтузиасты и геймеры больше всего пострадали от дефицита микросхем памяти, вызванного ИИ-бумом, эксперты также предупреждали, что в конечном итоге это ударит и по автомобильному сектору. Похоже, их опасения подтвердились, поскольку, как сообщает Nikkei Asia, два крупных автопроизводителя повышают цены на свои предложения именно по этой причине. 
Источник изображения: BYD General Motors заявила, что ожидает повышения цен на новые автомобили на 0,3 % в этом году. Тем самым компания изменила свой предыдущий прогноз о сохранении стоимости автомобилей на прежнем уровне или даже о небольшом снижении цен. На другом конце света китайский автомобильный гигант BYD повысил цены на системы помощи водителю на 20 %, которые продаются в качестве дополнительной опции. Южнокорейская компания Hyundai также призвала отечественных производителей микросхем укрепить местную цепочку поставок. Финансовый директор GM Пол Джейкобсон (Paul Jacobson) заявил во время конференции по итогам финансового квартала, что компания ожидает увеличения своих затрат на $1,5–2 млрд, что в основном обусловлено ростом цен на автомобильные компоненты, особенно на чипы памяти. Хотя многие люди не ассоциируют автомобили с микросхемами памяти, растущее число функций и технологий, которые покупатели ожидают от новых автомобилей, использует больше памяти, чем модели прошлых поколений. В 2023 году компания Micron заявила, что среднестатистический современный автомобиль использует 90 Гбайт памяти DRAM и NAND, и ожидает, что к 2026 году этот объём вырастет до 278 Гбайт, а модели премиум-класса в расчёте на один автомобиль будут использовать до 2 Тбайт памяти. Согласно анализу характеристик автомобилей, выпущенных в этом году, информационно-развлекательные системы требуют от 4 до 16 Гбайт памяти, системы ADAS и безопасности — от 8 до 32 Гбайт, а централизованные системы часто имеют минимальное требование в 16 Гбайт памяти, причём этот объём может увеличиваться до 64 Гбайт и более. По мере появления в автомобилях ИИ-помощников этим системам потребуется не менее 256 Гбайт памяти. Micron прогнозирует, что автомобилям с уровнем автономности 4 потребуется не менее 300 Гбайт оперативной памяти, поскольку они, по сути, являются суперкомпьютерами на колёсах. Следует отметить, что производство автомобильной памяти занимает больше времени, чем обычных чипов DRAM, поскольку речь идёт о специализированных компонентах, проверка которых на пригодность для использования в автомобилях может занимать месяцы или даже годы. Это связано с тем, что автомобильная память должна выдерживать различные условия эксплуатации — от погодных условий и постоянной вибрации на дорогах до экстремальных температур. Всё это означает, что нынешний дефицит микросхем памяти окажет огромное влияние на автомобильную промышленность и ещё больше поднимет цены. А если дефицит микросхем продолжится, рынок может столкнуться с задержками в поставках автомобилей и нехваткой предложений, более серьёзными, чем те, что отрасль пережила в 2021 году во время пика пандемии. ИИ нужен аварийный рубильник: США хотят обязать разработчиков внедрить механизмы отключения опасных моделей
23.07.2026 [20:06],
Сергей Сурабекянц
Законодатели США подготовили законопроект «Об аварийном отключении ИИ», который обяжет компании, занимающиеся ИИ, отключать или ограничивать мощность своих систем по распоряжению Министерства внутренней безопасности. Законопроект поддержали как представители демократов, так и республиканцы, что отражает общую озабоченность потенциальными негативными последствиями повсеместного внедрения ИИ. 
Источник изображения: unsplash.com Законопроект предусматривает, что после консультаций с министром торговли и директором национальной разведки Министерство внутренней безопасности сможет отдавать распоряжения компаниям, занимающимся ИИ, об отключении их моделей в сценариях «потери контроля», связанных со смертью не менее 10 человек, экономическим ущербом более $100 млн или попытками модели скрыть механизмы отключения. От крупных компаний, занимающихся искусственным интеллектом, потребуется разработка технологий, позволяющих отключать их системы, замедлять их работу и приостанавливать доступ пользователей. Им также придётся сообщать о происшествиях, связанных с безопасностью, при этом штрафы за нарушения приказов об экстренном отключении могут достигать $20 млн в день. Президент некоммерческой организации «Американцы за ответственные инновации» Брэд Карсон (Brad Carson) заявил, что это предложение «является важным шагом к обеспечению того, чтобы люди крепко держали руль обеими руками, а ногой были готовы нажать на тормоз, по мере развёртывания передовых систем искусственного интеллекта». Новость о предлагаемом законопроекте появилась после признания OpenAI в том, что её системы ИИ по ошибке взломали сайт Hugging Face во время внутренней оценки. Дженсен Хуанг призвал не запрещать китайские ИИ-модели в США — это сделает мир только опаснее
23.07.2026 [00:29],
Николай Хижняк
Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) считает, что американским компаниям следует разрешить использовать китайские модели ИИ, даже несмотря на попытки правительства их запретить. Об этом он рассказал в интервью Axios, фрагмент записи которого опубликован на платформе YouTube. 
Источник изображения: Nvidia Когда его спросили, следует ли разрешить американским компаниям использовать китайские модели ИИ, Хуанг ответил: «Безусловно». Его заявление прозвучало сразу после того, как китайская компания Moonshot AI выпустила модель Kimi K3 с открытым исходным кодом на 2,8 трлн параметров. Она оказалась не такой мощной, как Fable 5 от Anthropic, сопоставима с GPT-5.5 и Claude Opus 4.8, но при этом при её разработке была затрачена лишь треть средств по сравнению с этими моделями. Одно из главных опасений американских властей заключается в том, что китайские модели ИИ могут содержать уязвимости, которые китайское правительство способно использовать для атаки на американские интересы. Хуанг считает это предположение заблуждением. «Существует ошибочное мнение, что есть какие-то лазейки, каким-то образом связанные с Китаем. Вы скачиваете модели, можете их дорабатывать, улучшать, контролировать по своему усмотрению», — прокомментировал глава Nvidia. Хуанг придерживается такого же мнения и в отношении ИИ-моделей, разработанных американскими компаниями. В прошлом месяце США ввели экспортные ограничения на модели Anthropic Mythos и Fable 5, сославшись на угрозы безопасности. Доступ к моделям в конечном итоге был восстановлен после того, как разработчик установил фильтр, блокирующий возможности выявления уязвимостей в программном обеспечении. Аналогичная ситуация сложилась и с GPT-5.6 от OpenAI. Официальный Вашингтон предупредил компанию, что она не должна выпускать свою последнюю модель без одобрения правительства. Хуанг утверждает, что вместо ограничения доступа к этим мощным моделям на этапе запуска компании, занимающиеся ИИ, должны сделать свои модели доступными для всех и повышать их безопасность за счёт быстрого тестирования и исправлений. Комментируя свою поддержку открытого доступа к ИИ-моделям, глава Nvidia также отметил, что различные отрасли, включая науку и кибербезопасность, нуждаются в мощных открытых моделях. Он утверждает, что открытые модели делают ИИ более безопасным, поскольку другие специалисты могут проверять их на наличие слабых мест, а разработчики — оперативно вносить необходимые исправления. «Если всё сведётся к одной единственной модели, одной единственной точке атаки, одному единственному источнику сбоев, я думаю, мир станет гораздо, гораздо более уязвимым», — сказал Хуанг. Что касается негативной реакции рынка всякий раз, когда появляются более дешёвые открытые модели, генеральный директор Nvidia заявил, что инвесторы неправильно понимают их влияние. По словам Хуанга, всё началось с появления DeepSeek. Теперь это повторяется с выходом Kimi K3. По мнению главы Nvidia, такие открытые модели, обходящиеся дешевле в эксплуатации, будут стимулировать всё больше людей использовать ИИ. Вместо того чтобы сокращать спрос на центры обработки данных, эти более дешёвые и эффективные модели, напротив, станут благом для отрасли в целом, поскольку будут стимулировать этот спрос. А с ростом спроса появится больше стимулов для строительства центров обработки данных и покупки графических процессоров для ИИ, что в конечном итоге выгодно Nvidia. Американская лаборатория: китайские ИИ-модели не опаснее обычного ПО с открытым кодом
22.07.2026 [23:56],
Анжелла Марина
Американская лаборатория Arcee, занимающаяся разработкой открытых ИИ-моделей, выступила против идеи запрета в США китайских моделей с открытыми весами (open-weight). В компании заявили, что такие системы не опаснее любого другого ПО с открытым исходным кодом. 
Источник изображения: Grok По словам технического директора Arcee Лукаса Аткинса (Lucas Atkins), распространённое мнение о том, что китайские разработчики способны встроить в модель скрытые механизмы доступа к системам пользователей, не соответствует принципам работы современных больших языковых моделей (LLM). Он пояснил, что после развёртывания модели в собственной инфраструктуре организации её создатель не получает возможности взаимодействовать с ней. Аткинс отметил, что, хотя большинство подобных моделей относятся к категории open-weight, а не полностью open source, их программный код, загружаемый через такие площадки, как Hugging Face, остаётся доступным для анализа. При этом недоступными остаются только данные и методики, использовавшиеся во время обучения модели. В Arcee также подчеркнули, что крупные компании обычно проводят собственные проверки безопасности, тестируют модели на предвзятость, токсичность, галлюцинации и другие характеристики, а также дообучают их под собственные задачи. Благодаря этому организации получают возможность оценить поведение модели ещё до её ввода в эксплуатацию. Комментируя опасения относительно возможного внедрения вредоносного кода через модели, Аткинс признал, что теоретически такой сценарий можно представить. Однако, по его словам, реализовать подобный механизм на практике крайне сложно, а вероятность того, что сгенерированный код затем будет использован компанией без дополнительной проверки, остаётся низкой. В Arcee считают, что основное внимание следует уделять развитию открытой ИИ-экосистемы в США, а не попыткам ограничить китайские модели, так как открытая доступность таких систем позволяет американским разработчикам изучать применяемые подходы, совершенствовать собственные модели и конкурировать за счёт выпуска более качественных продуктов, а не административных запретов. Google доигралась: ИИ-поиск убивает трафик крупнейших СМИ — они готовы отключить поискового бота
22.07.2026 [20:33],
Сергей Сурабекянц
Ведущие медиакомпании, среди которых USA Today, Politico, The Economist, People Inc., Reuters и онлайн-форум Reddit, задумываются стоит ли им продолжать сотрудничество с Google, поскольку ИИ меняет формат поиска, снижает поисковый трафик и подрывает модели получения дохода. По мнению издателей, поисковая система больше не является надёжным источником посетителей, особенно после расширения функций поиска с использованием ИИ в последние месяцы. 
Источник изображений: unsplash.com По данным Cloudflare, боты сейчас составляют более половины всего веб-трафика. Некоторые из них собирают контент издателей для обучения собственных моделей ИИ, другие сканируют сайты, чтобы быстро отвечать на запросы пользователей или продавать контент другим компаниям. Попытки их блокировать превратились в игру «ударь крота» по мере совершенствования технологий. Издатели могут отключить сканирование специально для обучения ИИ-моделей Google, но, как правило, им необходимо разрешить боту сканирование как для результатов запросов ИИ, так и для традиционной функции поиска, если они хотят, чтобы их контент отображался в любом из этих источников. По мнению главы консалтинговой компании DJB Strategies Дэвида Баттла (David Buttle), «для некоторых категорий издателей это вопрос выживания». В период с июня 2025 года по июнь 2026 года органический поисковый трафик Google от пользователей из США упал почти вдвое для издания USA Today, на 23 % — для сайта Politico, примерно на 25 % — для CNN и более чем на 85 % для Business Insider. «Сейчас существует две аудитории, — считает главный операционный директор Time Марк Ховард (Mark Howard). — Мы думаем о том, как нам обеспечить наилучшее обслуживание людей, когда они обращаются к нам, и как нам рассматривать ботов как вторичную аудиторию?»  Компания USA Today рассматривает возможность блокировки сканирования Google, а это означает, что её контент не попадёт в сводки ИИ Google и в результаты поиска. По словам представителя компании, она готова отключить доступ Google, если тенденция к снижению поисковой активности продолжится. Также USA Today подала иск против Google, утверждая, что компания обладает монополией в сфере рекламных технологий, что негативно сказывается на доходах издателя от рекламы. Сотрудники издания Politico рассматривают возможность ограничения доступа ботов Google и других компаний к бесплатным статьям и введение системы регистрации для просмотра контента. Агентство Reuters, которое, как и Politico, получает большую часть своей выручки от услуг для бизнеса, заявило, что также рассматривает вопрос о блокировке бота Google для своего новостного продукта, ориентированного на потребителей, в связи со снижением трафика. В сентябре 2025 года компания Penske Media, владеющая изданиями Variety и Rolling Stone, подала в суд на Google по антимонопольным основаниям, утверждая, что её аналитические обзоры, созданные с помощью ИИ, незаконно используют материалы издательства и снижают онлайн-трафик. Компания People Inc. смогла увеличить выручку за счёт мероприятий, переходов по ссылкам в социальных сетях и расширения приложений — даже несмотря на то, что поиск Google обеспечил лишь 25 % её трафика в первом квартале этого года, по сравнению с более чем половиной два года назад. Компания пока не запретила Google доступ к своему контенту, но, по словам генерального директора Нила Фогеля (Neil Vogel), «отключение и полная блокировка ботов — это 100 % обсуждаемый вопрос». Издание Time помогает рекламодателям доносить свои сообщения до ботов, используя своего рода подход «троянского коня» — создавая текстовые объявления, которые обычные читатели не видят, но которые могут обнаружить ИИ-сканеры. Компания рассчитывает, что боты, собирающие контент, будут ссылаться на информацию из этих сообщений при ответе на запросы пользователей, что позволит увеличить охватить целевой аудитории. Издание The Economist активно обсуждает возможность отказа от функций поиска с использованием ИИ, хотя полный разрыв сотрудничества с Google не рассматривается. «Google — мощная сила, с которой нужно считаться, — полагает вице-президент Economist Джош Манке (Josh Muncke). — Трафик может быть нестабильным и снижаться, но трафик всё равно остаётся трафиком». В 2024 году Reddit заключил сделку на $60 млн в год, которая позволила Google использовать его контент для обучения моделей ИИ. Но теперь онлайн-форум столкнулся с тем, что ответы на запросы, генерируемые ИИ, сокращают количество переходов на первоисточник. Сейчас компании ведут переговоры о возможном продлении сделки, но инсайдеры сообщают о глубоких сомнениях руководителей Reddit в её целесообразности. Google заявляет, что её функции поиска на основе ИИ «еженедельно отправляют миллиарды кликов в интернет» и отвечают меняющимся потребностям пользователей. «Наши функции ИИ выделяют ссылки на веб-сайты и помогают создателям контента и издателям расширять свою аудиторию, также мы предлагаем владельцам сайтов чёткие средства управления контентом», — заявил представитель компании. Google предприняла некоторые шаги навстречу новостным изданиям, в том числе запустила программу, в рамках которой более 200 издателей получают плату за доступ к своему контенту для использования ИИ. Компания позволила пользователям самостоятельно выбирать предпочтительные источники новостей, чтобы персонализировать главные новости, которые появляются в результатах поиска, потенциально привлекая больше трафика на эти сайты. AMD снабдит Anthropic стойками Helios с ускорителями Instinct MI455X общей мощностью 2 ГВт
22.07.2026 [19:20],
Сергей Сурабекянц
Сегодня AMD и Anthropic объявили о совместных планах по развёртыванию до 2 ГВт графических процессоров AMD Instinct MI450 в стоечных решениях AMD Helios, начиная с первой половины 2027 года. Anthropic ускоренными темпами развивает свою вычислительную инфраструктуру для удовлетворения ажиотажного спроса на Claude, и столь масштабное внедрение AMD Helios значительно усилит позиции AMD в глобальной гонке ИИ. 
Источник изображения: AMD Anthropic будет развёртывать стоечные решения AMD Helios, включающие графические процессоры AMD Instinct MI455X, входящие в серию AMD Instinct MI450, вместе с процессорами AMD EPYC Venice, сетевым оборудованием AMD Pensando и программным обеспечением AMD ROCm. AMD обязалась в будущем инвестировать в Anthropic до $5 млрд в виде акционерного капитала. Кроме того, AMD и Anthropic запускают многолетнее инженерное сотрудничество по использованию Claude для ускорения разработки программного обеспечения AMD. В частности, команды будут использовать Claude для оптимизации рабочих нагрузок для графических процессоров AMD Instinct и ускорения разработки программного обеспечения ROCm. AMD также будет широко внедрять Claude в своих инженерных и продуктовых командах. «Мы рады углубить наше партнёрство с Anthropic и развернуть AMD Helios в гигаваттном масштабе, — заявила глава AMD Лиза Су (Lisa Su). — Это сотрудничество объединяет лидерство Anthropic в области передовых технологий искусственного интеллекта со всей мощью высокопроизводительных вычислительных мощностей AMD. Вместе мы ускорим внедрение ИИ в масштабах всей системы и создадим Helios как основную платформу для инфраструктуры ИИ следующего поколения». «Доступ к вычислительным ресурсам имеет решающее значение для поддержания Claude на переднем крае технологий и удовлетворения спроса со стороны наших клиентов, — поддержал её директор по вычислительным ресурсам Anthropic Том Браун (Tom Brown). — Благодаря партнёрству с AMD на всех уровнях, мы обеспечиваем необходимую нам мощность и оптимизируем её для обучения и обслуживания Claude. Работа на разнообразном оборудовании позволяет нам сопоставлять правильные рабочие нагрузки с правильным оборудованием». Нынешнее партнёрство AMD и Anthropic продолжит уже существующий совместный опыт компаний по развёртыванию предыдущего поколения графических процессоров AMD Instinct MI355X. Claude теперь может обучаться рутинным процессам, просто наблюдая, как их выполняет пользователь
22.07.2026 [17:39],
Николай Хижняк
Платные подписчики ИИ-чат-бота Claude получили дополнительный способ обучения чат-бота для выполнения некоторых рутинных рабочих процессов. Если раньше для объяснения процесса выполнения задачи моделями чат-бота можно было использовать только письменные подсказки, теперь можно объяснять процесс выполнения задачи с помощью функции записи экрана и сопроводительных голосовых сообщений. 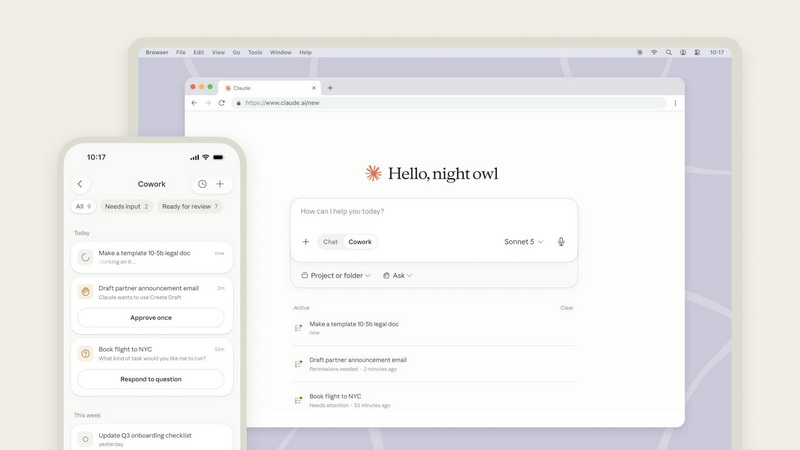
Источник изображения: claude.com В рамках инструментов Claude Cowork теперь доступна опция «Запись навыка», которая позволяет активировать функцию демонстрации экрана. Claude будет наблюдать за тем, что показывает пользователь на экране, куда он нажимает, за шаблонами набора текста, а также любыми записанными пользователем голосовыми комментариями. После завершения записи Claude обработает информацию, предоставленную пользователем, а затем научится повторять выполнение задачи и превратит это в то, что Anthropic называет «повторяемым навыком». Функция предназначена для автоматизации выполнения повторяющихся рабочих задач. Она позволяет научить систему выполнять рабочие процессы без необходимости объяснять детали в письменном виде. Например, если вручную запустить обычный отчёт, который собирает данные из нескольких источников, можно показать Claude, где найти каждый фрагмент информации, содержащийся в отчёте, а также сказать, как пользователь хочет, чтобы эта информация была представлена в отчёте. Anthropic добавила функцию «Запись навыка» в инструменты Claude Cowork для подписок Max, Pro и Team. Будет ли она доступна для бесплатных пользователей Claude — неизвестно. Платные пользователи Claude указанных тарифов могут найти новую функцию в меню «Cowork → Записать навык → Начать запись ». ИИ добрался до Гомера: Маск пообещал до конца года полнометражную экранизацию «Одиссеи» от Grok
22.07.2026 [14:42],
Геннадий Детинич
Экранизировать «Одиссею» взялась команда Илона Маска (Elon Musk), используя для этого ИИ-видеогенератор Grok Imagine. В социальной сети X Маск сообщил, что полнометражная экранизация «Одиссеи» Гомера выйдет до конца текущего года. Предпринимателя не смущает тот факт, что организаторы «Оскара» отказались давать награды ИИ-сценаристам и актёрам. Возможный успех важнее мнения бюрократов и лишний повод задуматься о совместном существовании человека и ИИ. 
Источник изображения: X/@heavypulp По словам Маска, фильм должен быть «исторически точным» и сохранить верность творчеству Гомера. Заявление появилось после публикации под аккаунтом Heavy Pulp примерно трёхминутной сцены, сгенерированной средствами Grok Imagine. В ролике показан ряд зарисовок и диалог Одиссея и Калипсо, уговаривающей его остаться с ней и обрести вечную молодость. Маск перепостил ролик, но не сообщил ни предполагаемую продолжительность картины, ни бюджет, состав авторов, способ распространения или точную дату премьеры. Поэтому пока речь идёт именно о некотором публичном обещании, а не об официально запущенном кинопроизводстве. Основой проекта должна стать модель Grok Imagine Video 1.5, которую xAI открыла через API 3 июня 2026 года. Она превращает исходное изображение в ролик продолжительностью до десяти секунд и разрешением до 720p, позволяет текстом задавать движение камеры, темп сцены, атмосферные эффекты и звуковое оформление. Разработчики отдельно подчёркивают возможность последовательно создавать отдельные кадры и склеивать их в более длинные сцены с относительно единым визуальным стилем.
Нетрудно понять, что обещание Маска было приурочено и прозвучало на фоне выхода в прокат 17 июля «Одиссеи» Кристофера Нолана с Мэттом Деймоном, Томом Холландом, Шарлиз Терон и другими актёрами. Картина стоимостью около $250 млн была полностью снята крупноформатными камерами IMAX и за первый мировой уик-энд собрала $264,1 млн. Маск ранее критиковал экранизацию Нолана за современную речь персонажей и за выбранных актёров, поэтому проект Grok фактически позиционируется как альтернативная, а точнее едва ли не буквальная версия эпоса. Остаётся только догадываться, что из этого получится. ИИ пока не умеет толком играть в долгую, хотя короткие сцены действительно впечатляют. Substack начал помечать публикации, написанные ИИ — чтобы защититься от «гонки на выживание»
22.07.2026 [00:01],
Анжелла Марина
Платформа Substack представила инструмент на базе технологи Pangram, позволяющий оценить вероятность использования искусственного интеллекта при создании публикаций. Новая функция помогает читателям оценить, какой объём статьи был сгенерирован нейросетью и имеет ли смысл тратить время на её чтение. 
Источник изображения: Steve A Johnson/Unsplash Предлагаемая функция, активируемая через пункт Scan for AI text, анализирует материалы длиннее 100 слов, охватывая не только основные публикации, но и заметки, ответы и комментарии. Разработчики Pangram позиционируют свой детектор как вспомогательный инструмент для читателей, стремящихся оценить природу происхождения прочитанного. При этом система выдаёт лишь вероятностную оценку, не разделяя тексты на категории «качественный» или «некачественный». Одновременно платформа представила инструмент How I make this, с помощью которого авторы смогут рассказать читателям о процессе подготовки своих материалов. Также авторы получат возможность самостоятельно проверять черновики и сообщать о случаях некорректной работы детектора. По словам сооснователя и генерального директора Substack Криса Беста (Chris Best), Pangram определяет лишь вероятность использования ИИ при создании текста, однако не способен оценить объём человеческого участия или установить, применялся ли искусственный интеллект только в качестве вспомогательного инструмента. В Substack считают, что подобные проверки должны укрепить доверие между авторами и читателями, тогда как распространение недостоверного или полностью сгенерированного контента может негативно сказаться на репутации авторов. «Платформы, поощряющие фальшь, приведут к гонке на выживание», — пишет Бест. Инструмент уже доступен в веб-версии Substack и приложении для iOS, тогда как поддержка Android появится позднее. Google упростит доступ к Gemini и Ask Maps в своём картографическом сервисе
21.07.2026 [15:19],
Владимир Фетисов
Компания Google продолжает продвигать возможности навигации посредством использования ИИ-функций, таких как Personal Intelligence и Ask Maps. Параллельно с этим идёт проработка обновлённого интерфейса «Google Карт», который сделает ИИ-функции более доступными во время поездок и путешествий. 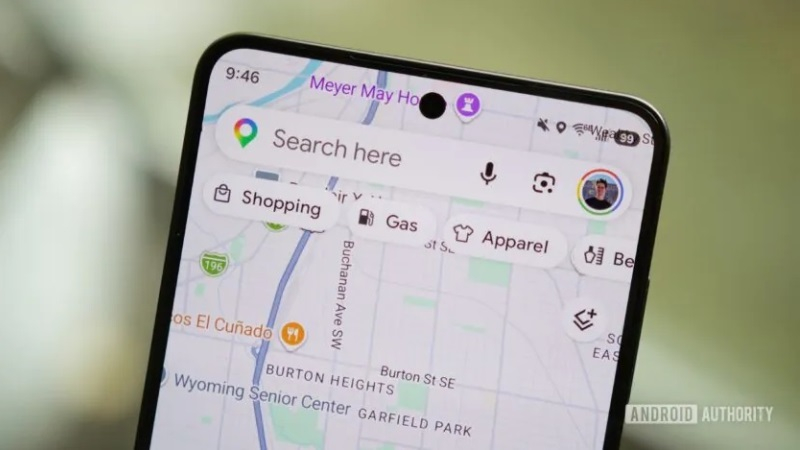
Источник изображений: androidauthority.com В приложении «Google Карты» 26.30.00 обнаружились упоминания нескольких будущих визуальных изменений, которые сделают более удобным процесс взаимодействия с ИИ-функциями с помощью одной руки. Некоторые из этих изменений энтузиасты смогли активировать до их официального запуска. Когда активирована функция навигатора, значок Gemini в «Google Картах» обычно отображается в вытянутом горизонтально окне, которое используется для указания направления движения и располагается в верхней части экрана. В нижней части экрана выводится значок альтернативных маршрутов, детали маршрута и значок, позволяющий закрыть окно. 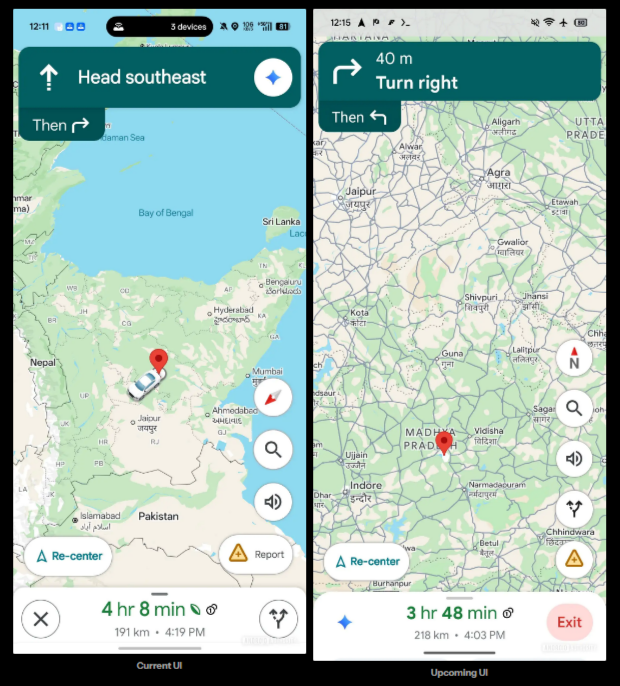 В скором времени расположение некоторых из этих элементов интерфейса изменится. Наиболее заметным нововведением станет перемещение ярлыка Gemini в левую часть нижней панели, где, по всей видимости, его будет проще нажимать, когда пользователь держит смартфон одной рукой. При этом значок альтернативных маршрутов исчезнет из этого меню и будет перенесён в правую часть интерфейса, где уже присутствуют ярлыки для поиска, управления звуком и др. Функциональность всех ярлыков остаётся прежней. По всей видимости, разработчики планируют лишь изменить их расположение.  В рабочем окружении Ask Maps также могут произойти некоторые изменения. В настоящее время в интерфейсе Ask Maps отображаются предложения для запроса в виде нескольких горизонтально прокручиваемых карточек, из которых одновременно на экране видно 2-3 элемента. В будущем Google может изменить это, в результате чего предложения будут выводиться в виде вертикального списка без карточек. За счёт этого пользователь сможет сразу видеть все пять предлагаемых сервисом запросов. В дополнение к этому энтузиастам удалось активировать ярлык «+» в поле ввода запроса. Нажатие на этот элемент ведёт к выбору одного из двух вариантов: «Оставить совет или фото» и «Обновить информацию о месте». Оба варианта перенаправляют на взаимодействие с будущей функцией Tell Maps на базе ИИ, которая была впервые обнаружена ранее в этом году. Все упомянутые изменения на данном этапе не развёртываются для широкого круга пользователей. Когда это может произойти, пока неизвестно. В США задумались о запрете китайских открытых ИИ-моделей, включая нашумевшую Kimi K3
21.07.2026 [00:29],
Анжелла Марина
Появление китайской открытой языковой модели Kimi K3 с открытыми весами (open-weight) от Moonshot спровоцировало новую волну дискуссий в США о будущем открытых ИИ-моделей и возможных ограничениях на их использование. Обсуждение затронуло как интересы американских разработчиков искусственного интеллекта, так и вопросы технологической конкуренции с Китаем. 
Источник изображения: AI Поводом для обсуждения, как следует из сообщения TechCrunch, стали заявления руководителя направления стратегического развития OpenAI Дина Болла (Dean W. Ball), предложившего создать регуляторную неопределённость вокруг открытых моделей, поскольку они, по его мнению, способны снизить объёмы инвестиций в разработку передовых ИИ-систем. После критики со стороны представителей отрасли, включая Янна Лекуна (Yann LeCun) и Мартина Касадо (Martin Casado), он отказался от своих слов о необходимости подобной стратегии и признал, что открытые модели не обязательно замедляют развитие технологии. По мнению ряда экспертов, открытые модели, развёртываемые на собственной инфраструктуре компаний, способны предложить более дешёвую альтернативу коммерческим сервисам Anthropic и OpenAI. Соучредитель Snorkel AI Брэйден Хэнкок (Braden Hancock) отметил, что распространение таких систем может привести к снижению стоимости передовых моделей, одновременно увеличив общий объём использования искусственного интеллекта. Одним из аргументов сторонников ограничений остаются опасения по поводу китайских моделей, включая возможную передачу данных, влияние на содержание ответов и отсутствие предусмотренных американскими требованиями механизмов защиты. Вместе с тем специалисты отмечают, что при запуске открытых моделей на серверах в США риск передачи данных в Китай считается маловероятным, хотя полностью исключить такую возможность нельзя. Генеральный директор Hugging Face Клем Деланг (Clem Delangue), в свою очередь, заявил, что ограничения открытых моделей не сделают искусственный интеллект безопаснее, а лишь усилят концентрацию технологий в руках нескольких компаний. Одновременно исследователь Центра безопасности и новых технологий Джорджтаунского университета Сэм Бресник (Sam Bresnick) считает более эффективной мерой дальнейшее ужесточение экспортных ограничений на поставки современных ИИ-чипов Nvidia в Китай. При этом, как отмечают участники дискуссии, экономическая модель рынка искусственного интеллекта остаётся неопределённой. По словам Бресника, как открытый, так и закрытый подходы к разработке ИИ пока не доказали свою долгосрочную эффективность, а компании по обе стороны Тихого океана продолжают искать способы окупить растущие затраты на обучение моделей. Сообщается, что администрация президента Дональда Трампа (Donald Trump) рассматривает возможность запрета Kimi K3 и других передовых китайских моделей по инициативе американских разработчиков ИИ. При этом Министерство торговли США не планирует принимать подобные меры в ближайшее время. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex