Наглядный эксперимент показывает, насколько сложно в принципе выявить сгенерированный ИИ текст, исследуя частоту употребления в нём тех или иных слов, — особенно если английский (язык научных коммуникаций в мире) для авторов не родной. Слева — проценты ложноположительных идентификаций текстов ботом ChatGPT как ИИ-сгенерированных для иностранцев, владеющих языком на уровне TOEFL (красный столбец) и для американских восьмиклассников (серый): видно, что больше 60% даже весьма образованных не-носителей всё равно используют скудный вокабуляр и упрощённый синтаксис, что и сбивает бота с толку. Справа — результат «доработки» тех же текстов тем же ИИ, в ходе которой они были исправлены «для лучшего соответствия языковым нормам». При этом процент ложноположительных определений иностранцев как ботов резко упал — потому что содержание не пострадало, но форма его изложения стала совершенней, — а вот творениям восьмиклассников, напротив, генеративная «доработка» только навредила (источник: Stanford University)
⇡#Лекарство хуже болезни?
Один из сильнейших аргументов в пользу повсеместного внедрения ИИ — готовность его быстро и точно решать наиболее рутинные, утомительные, повторяющиеся задачи, снимая тем самым с живых сотрудников немалое бремя и высвобождая их творческий потенциал для подлинно прорывных свершений. Увы, и на этом направлении гладко, как выясняется, было только на бумаге: вездесущая «ИИ-бурда» (AI slop) находит путь и на рабочие места — заставляя имеющий дело с генеративными моделями персонал тщательно перепроверять плоды трудов искусственного интеллекта, чтобы не допустить возникновения более серьёзных проблем в дальнейшем. «ИИ-бурдой» обычно называют сляпанный на скорую руку генеративный контент, лишённый тщательного целеполагания перед началом генерации и контроля качества по её завершении. Такого, к сожалению, предостаточно нынче в соцсетях, на платформах мессенджеров и на видеохостинговых сайтах. Экстремистская Meta✴* в сентябре и вовсе решила, судя по всему, возглавить сомнительный slop-тренд, запустив платформу Vibes для создания с помощью ИИ коротких видео и моментальной их публикации, причём пользователи встретили новинку, мягко скажем, без особого энтузиазма.
Почти одновременно с этим исследователи из BetterUp Labs и Stanford Social Media Lab ввели в научный оборот термин «рабочая бурда» (workslop), утверждая, что уже 40% американских наёмных сотрудников сталкивались с этой сомнительной субстанцией, исполняя свои прямые обязанности. А именно — получая низкокачественные (де)генеративные материалы от коллег, контрагентов, подчинённых и начальства. Опрос почти 1,2 тыс. занятых полный рабочий день «белых воротничков» показал, что каждый инцидент с получением «рабочей бурды», т. е. наспех сгенерированного по не самой удачной подсказке и толком не отредактированного ИИ-контента, отнимает в среднем 1 час 56 минут бесценного человеческого времени, чтобы исправить ситуацию. Исправить — обычно значит выйти на связь с отправителем, оповестить его о проблеме и дождаться присылки уже пригодного для работы документа. Работодателям же эта напасть обходится почти в 200 долл. в пересчёте на каждого сотрудника каждый месяц. То есть если в организации действуют 10 тыс. человек наёмного персонала, владелец её недосчитывается 9 млн долл. ежегодно — только лишь из-за необходимости купировать последствия workslop-инцидентов. Уже 15,4% всего контента, что получают сотрудники в США на рабочих местах по разным каналам, — это «рабочая бурда», причём между равными по уровню коллегами эта доля доходит до 40%. Радует, что при иерархических коммуникациях процент «бурды» заметно ниже: в восходящем канале, от нижестоящих к вышестоящим, — 18%; в нисходящем, от менеджмента к подчинённым, — 16%. Мало того, что workslop отнимает время и иные ресурсы, которые можно было бы израсходовать более продуктивно. Сам факт получения такого контента ухудшает отношение работников (и в итоге качество деловых коммуникаций) к тем, кто не чурается его использовать: 42% респондентов начинают куда более скептически оценивать творческие способности и профессионализм отправителей «ИИ-бурды».
Ещё более неприятной оказывается ситуация, когда (де)генеративный контент проходит незамеченным и интегрируется в процессы, особенно если речь идёт о науке. В сентябре в Nature появилось исследование, утверждающее, что ИИ-инструменты уровня ChatGPT и Gemini уже активно используются горе-учёными для перелицовки ранее опубликованных научных статей с целью выдавать их за свои. В одной только базе данных medRxiv (что вызывает особое беспокойство — всё же речь идёт о медицине!) за последние 4,5 года таких статей было с высокой достоверностью обнаружено свыше четырёх сотен в 112 журналах. Дело, утверждают исследователи, поставлено на поток: существуют специализированные компании, предлагающие за определённую сумму «написать» заведомо достойную публикации статью на выбранную клиентом тему. Просто раньше там эксплуатировали человеческий труд, а теперь привлекают большие языковые модели. Помимо этических и квалификационных проблем, перелицовка научных статей порождает куда более опасные для общества в целом: неизбежные для ИИ галлюцинации, прокравшись незамеченными в (де)генеративные работы, особенно медико-биологической направленности, способны привести к крайне неприятным последствиям.

«Какое заявление на отпуск, Галя? Откуда у тебя выгорание? Опять галлюцинируешь?!» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Боязнь ИИ — просто ребячество
Опубликованное в сентябре исследование Deutsche Bank, охватившее 10 тыс. наёмных работников из США и развитых стран ЕС, продемонстрировало, что разные возрастные страты относятся к искусственному интеллекту в прикладном плане — оценивая, сумеет ли тот лишить их занимаемого места, — ощутимо по-разному. Среди тех, кому меньше 35 лет, высокий уровень опасений в этой связи (8 и более баллов из 10) проявляют 24% респондентов, тогда как работники от 55 и старше столь же мрачно оценивают свои перспективы лишь в 10% случаев. Более того: чем дальше, тем заметнее ослабевают такого рода страхи. Если в интервале последних пяти лет (а схожие исследования начали проводить регулярно ещё до оглушительного взлёта популярности ChatGPT осенью 2022-го) ИИ в тех или иных своих проявлениях пугал в среднем 22% участников опроса, то за последние два года этот показатель снизился до 18%. Впечатляет, кстати, что по уровню проникновения в рабочие процессы (AI adoption) изученные страны различаются просто-таки кардинально: если для США этот уровень (рассчитанный в интервале последних трёх месяцев) достигает 56%, для Германии — 41%, то в Великобритании до сих пор не поднялся выше 5%. Неужто пресловутая британская чопорность не позволяет адекватно взаимодействовать с сущностью, физически не способной выпить в пять часов вечера непременную чашечку чая? При этом 54% американских и 52% европейских наёмных работников сами желали бы обучиться практическому взаимодействию с ИИ за счёт своих работодателей. Выходит, большинство из тех, кого, как предполагалось, вот-вот заменят роботы (чисто программные или программно-аппаратные), готовы с открытым забралом встречать генеративный вызов.
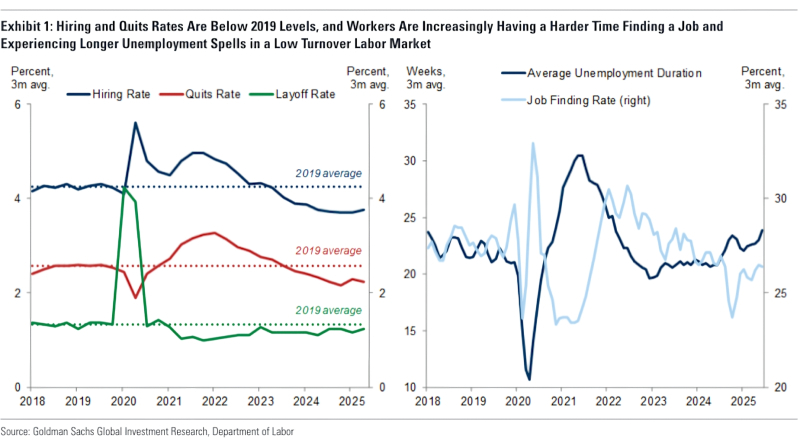
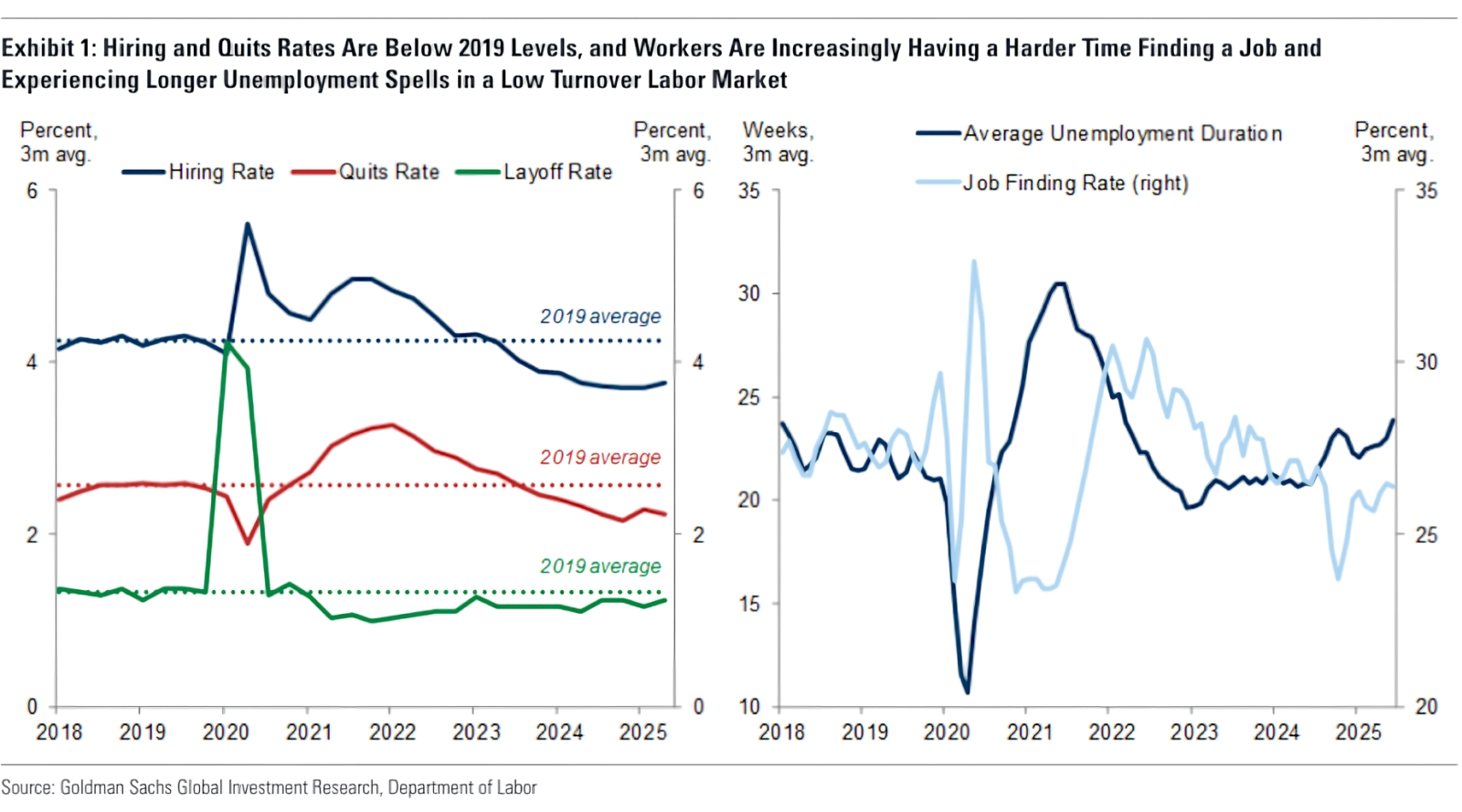
Плачевное актуальное состояние американского рынка труда. Слева — показатели частот найма, оставления работы по собственному желанию и увольнений в сравнении со средними величинами этих параметров для 2019 г.; справа — пульсировавшие почти в противофазе графики средней продолжительности периода временной безработицы и показателя скорости обретения новой работы в 2025-м вдруг стали демонстрировать схожую динамику (источник: Fortune)
⇡#Папа против
Искусственный интеллект развивается и совершенствуется не в вакууме: пусть бояться его влияния на общество и впрямь неразумно, игнорировать порождаемые им перемены тоже было бы опрометчиво. Впрочем, перемены эти охватывают пока не все стороны жизни: так, в духовную сферу генеративным моделям входа по-прежнему нет. Папа Римский Лев XIV отказался благословлять использование собственного ИИ-аватара, который проводил бы вместо него виртуальные аудиенции для католиков со всего мира. Нынешний понтифик, напомним, вовсе не из числа технологических евангелистов — он не раз предупреждал в своих речах, что автоматизация грозит качественным расслоением общества, когда «лишь избранные немногие смогут жить полнокровно, тогда как на долю большинства останется беспросветная борьба за существование». Да и тронное имя он взял себе в память о другом папе, Льве XIII, — а тот во времена Великой индустриальной революции призывал не забывать о правах рабочих. Вот и теперь, выходит, пришла пора обращать внимание работодателей на плачевное состояние рынка труда, ответственность за которое в известной мере лежит на ИИ — точнее, на коммерсантах, выбирающих инвестиции в эту перспективную технологию вместо найма живых сотрудников.
Эксперты Fortune — экономисты, представители центробанков ведущих стран, аналитики рынка — обращают внимание на крайне высокий для последних десятилетий уровень безработицы среди американцев 25 лет и младше (условного «поколения Z»). При этом на рынке труда наблюдается не самая рядовая ситуация «no fire, no hire»: показатели частоты найма на работу и увольнения с неё (как по собственной воле, так и в приказном порядке) одинаково низки, так что уже закрепившиеся на своих местах представители старших поколений на них и остаются, а новых вакансий для выпускников колледжей открывается гораздо меньше прежнего. Правда, хотя «вина» ИИ в этом определённо есть — генеративным моделям лучше всего удаётся выполнять именно ту сравнительно несложную работу с довольно низкой ценой ошибки, которую обычно и доверяют свеженанятому молодняку, — эксперты не склонны огульно обвинять роботов в вытеснении людей с рабочих мест. Скорее, это всего лишь один из множества факторов, что способствуют сегодня охлаждению мировой экономики. Но — всё-таки именно способствуют, а не препятствуют.
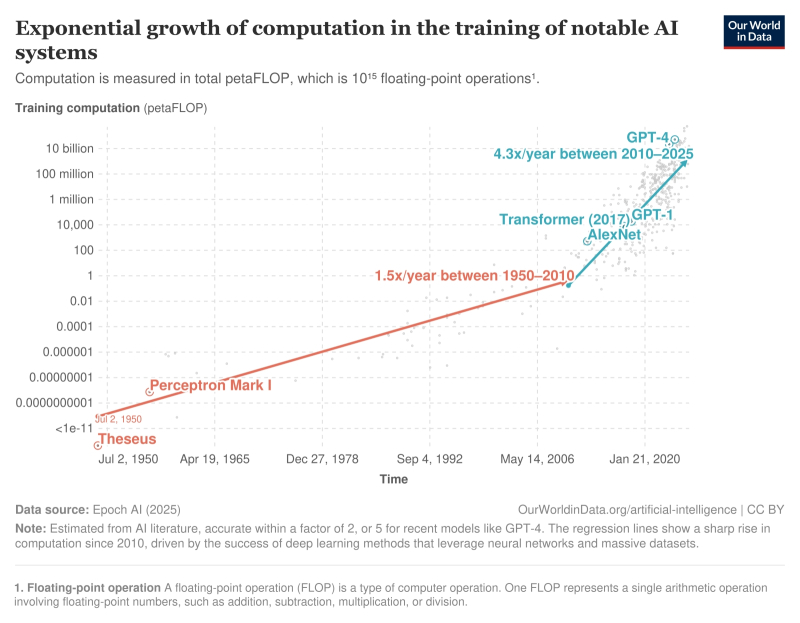
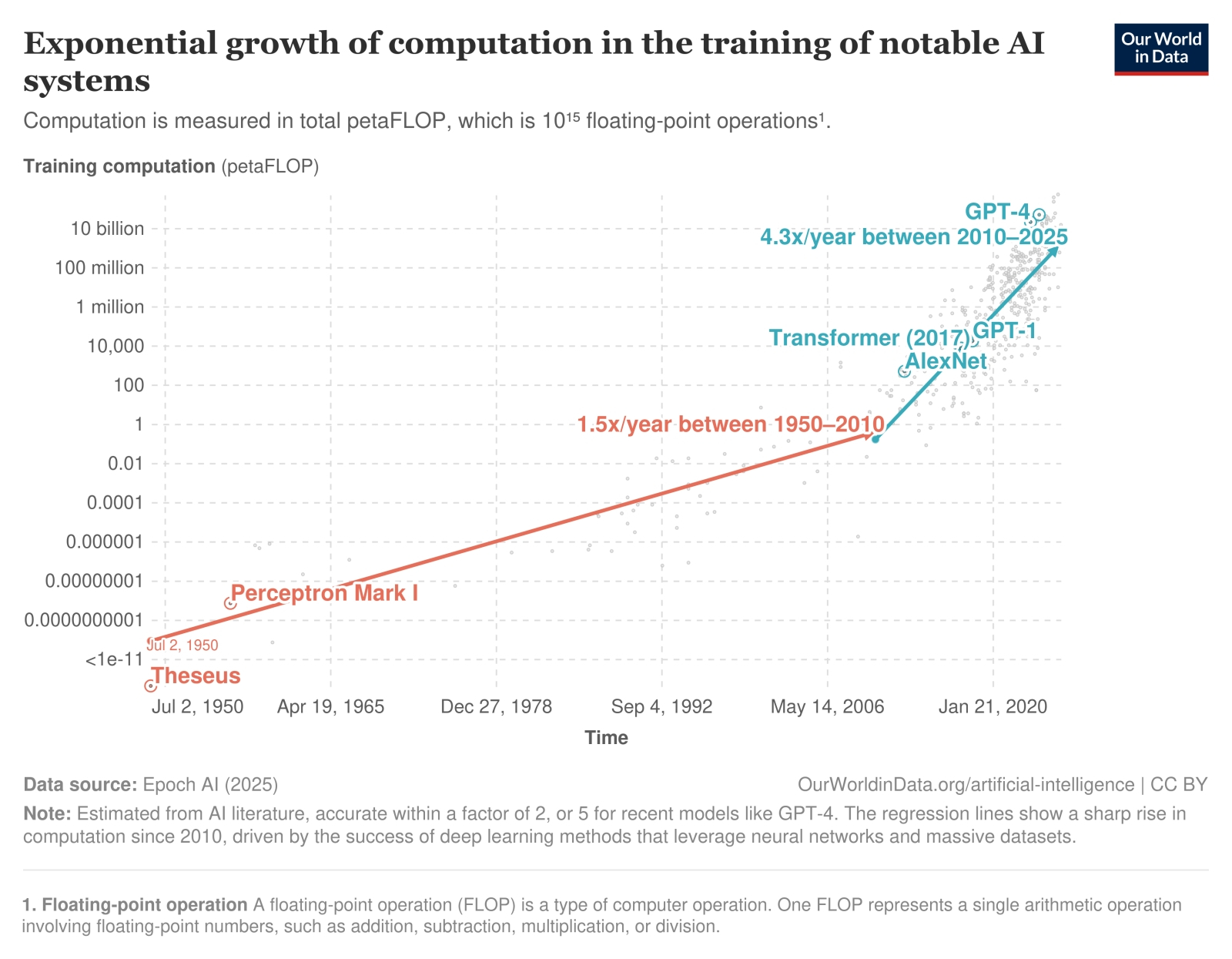
Рост вычислительной мощи, выраженной в единицах 10 в 15-й степени операций с плавающей точкой в секунду, которая требуется для тренировки наиболее выдающихся ИИ-моделей, в интервале 1950-2010 гг. неплохо аппроксимировался прямой (в логарифмическом масштабе по оси ординат, разумеется) с коэффициентом 1,5 раза в год, тогда как с 2010-го по 2025-й рост это резко ускорился — до 4,3 раза в год (источник: OurWorldInData)
⇡#Генерация не по средствам
Чтобы сделать генеративный ИИ более «разумным», необходимо увеличивать число параметров, которыми он оперирует, — вполне себя оправдывавшее в последние годы эмпирическое правило «bigger is better». Практическая же реализация такого подхода требует экстенсивного наращивания вычислительных мощностей — в которое, в свою очередь, необходимо инвестировать всё больше и больше средств. Специалисты из консалтинговой компании Bain & Co. уверены, что величина эта слишком уж быстро становится непозволительной: по их оценкам, переход к отрицательному балансу выручки и затрат грозит ИИ-отрасли уже в ближайшие годы. К 2030-му, подсчитали эксперты, годовые расходы работающих в этой сфере компаний достигнут 2 трлн долл. США, тогда как совокупная сумма поступлений от их клиентов не будет превосходить к тому времени 1,2 трлн долл. Гигантский кассовый разрыв в 800 млрд долл. ежегодно покрывать, судя по всему, окажется просто нечем. Монетизация передовых генеративных моделей — будь то предоставление доступа к премиальной функциональности ChatGPT частным лицам по подписке или API-интерфейсов её же и конкурентных моделей корпоративным заказчикам — откровенно недостаточна уже сегодня, и дальше, опасаются аналитики, будет только хуже. В условиях стагнирующей мировой экономики и ползучего роста цен решительно на всё, от микропроцессоров до электроэнергии, запрашивать с клиентов больше — значит сокращать количество покупок, чего поставщики ИИ-услуг не могут себе позволить. Экстенсивный путь развития генеративных моделей приведёт к тому, утверждают в Bain & Co., что в 2030-м мировое энергопотребление соответствующих дата-центров взлетит до 200 ГВт, причём половина этого объёма придётся на размещённые в США ИИ-ЦОДы. Примерно к тому времени именно нехватка энергии для дальнейшего наращивания мощностей для тренировки и даже инференса моделей должна стать, по оценке экспертов, главным препятствием на пути эволюции генеративного ИИ. Деньги, в конце концов, можно занять или напечатать, с гигаваттами же всё несколько сложнее.
И это не просто слова: американцы уже сталкиваются с ощутимым ростом цен на электроэнергию — спровоцированным в немалой мере как раз бумом ИИ. Аналитики из Grid Status указывают, что там, где в США возводят новые дата-центры (а предназначаются те сегодня прежде всего для решения генеративных задач), за последние пять лет цены на электричество выросли в среднем на 267%. К 2030-му же году до 10% общей электрогенерации в Штатах может потреблять вычислительная техника, решающая эти самые задачи. Едва ли не единственный выход видится в развитии атомной энергетики: в Bloomberg Intelligence подсчитали, что к 2050 г. как раз благодаря той выработка электричества в стране увеличится на 63%, — правда, обойдётся это удовольствие не менее чем в 350 млрд долл. А пока на паузу ставится программа свёртывания угольной генерации, причём ставки настолько высоки, что ведущие разработчики ИИ планируют сами становиться энергетическими компаниями. То бишь строить впрок новые электростанции, и, пока те дожидаются подключения очередных ИИ-ЦОДов, приторговывать излишками энергии — благо дешеветь она в обозримой перспективе навряд ли станет. Впрочем, не факт ещё, что излишки эти вообще появятся: проведённое платформой хостинга ИИ-проектов с открытым кодом Hugging Face исследование предупреждает, что энергетические аппетиты по меньшей мере одного класса крайне популярных сегодня ИИ-моделей, I2V, растут опережающими ожидания темпами. Оказывается, если генеративные модели для создания видео по текстовым подсказкам (image-to-video) увеличивают продолжительность выдаваемого ролика вдвое, то энергозатраты их при этом увеличиваются вчетверо. Тут не только уголь жечь начнёшь!
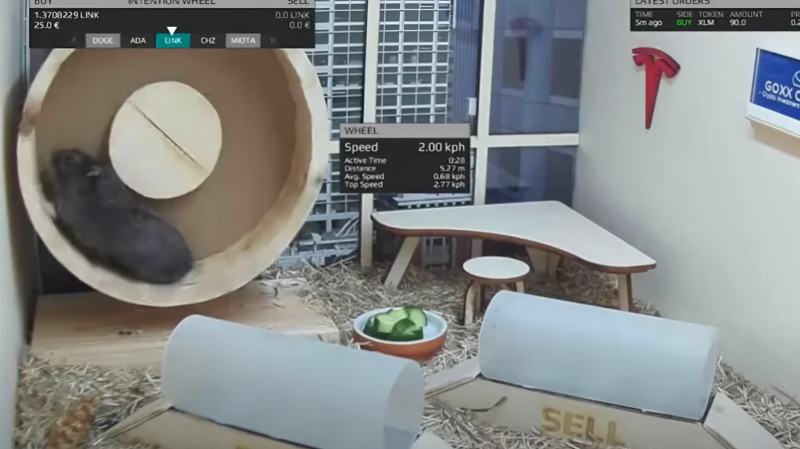
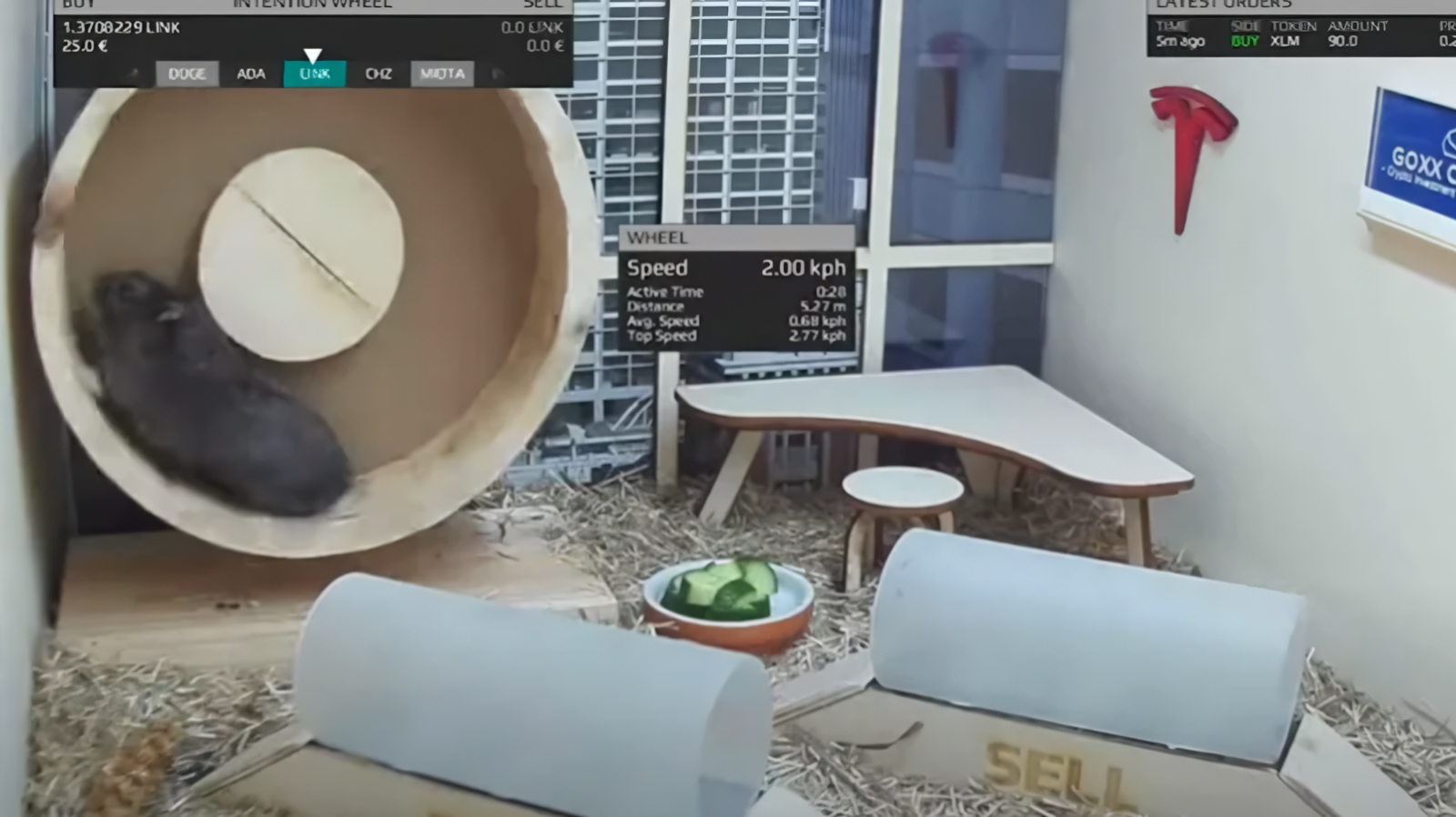
Мистер Гокс без устали трудится в комфортабельном германском офисе в последние дни своей суперуспешной трейдерской карьеры, безвременно прервавшейся, увы, в ноябре 2021 г. вследствие естественных для хомячков причин (источник: Goxx Capital)
⇡#Когда не выходит генеративный цветок
Программирование по наитию, точнее по подсказкам, скармливаемым ИИ-боту, — vibe-coding, — пользуется в последнее время немалой популярностью. Достаточно упомянуть стартап Replit, который разработал платформу для написания кода именно таким способом — и как раз в сентябре преодолел порог оценочной стоимости в 3 млрд долл.; причём подобных «единорогов по наитию» на одном только американском рынке не один и не два. Одна только занимательная особенность: и Replit, и подобные ему компании ориентируются на традиционных программистов — тех, что работают за ПК: интерфейс такого рода платформ рассчитан на отображение на крупном мониторе и на взаимодействие с клавиатурой и мышью. Казалось бы, не должна составлять ни малейшего труда модификация интерфейса для смартфонов — тем более что пользователей мобильных устройств в мире значительно больше, чем владельцев компьютеров, и вайб-кодингом наверняка многие из них не прочь были бы заняться. На деле же, как выясняется, именно смартфонные приложения для программирования по наитию никому не нужны: по данным AppFigures, топ-25 такого рода приложений по всему миру закачаны (как через AppStore, так и через Google Play) всего-то 27 тыс. раз, а полученная от них выручка составляет — по всему миру! — жалкие шесть тысяч долларов, да и то 1 тыс. долл. и более принесли своим разработчикам всего два приложения. Это что же выходит — интерес к вайб-кодингу проявляют в подавляющем большинстве те, кто уже предпочитает ПК смартфону, а значит, потенциально и сам готов научиться программировать по старинке, без этих ваших ИИ-наитий?
Ещё одна сфера деятельности, где наитие определяет если не всё, то очень многое, — биржевая торговля. С одной стороны, к ней применимы хорошо алгоритмизируемые правила вроде «покупай, когда все продают; продавай, когда все покупают». С другой — есть там и место для здоровой случайности: вспомним, как в 2021 г. на весь трейдерский мир прославился хомячок по имени Мистер Гокс (Mr. Goxx). Вращая колесо в своей клетке, он выбирал определённую криптовалюту, а пробегая по одному из расположенных там же туннельчиков, отдавал компьютеру команду — продавать этот актив или покупать. Казалось бы, в лучшем случае Мистер Гокс, оперируя таким образом некоторым капиталом, должен был бы в итоге остаться при своих, но нет! Где-то около полугода сформированный им портфель активов демонстрировал бóльшую прибыльность, чем акции компаний из списков S&P 500 и FTSE 100 и даже чем фонд Berkshire Hathaway легендарного Уоррена Баффетта (Warren Buffett)!
Вот же идеальная, судя по всему, область деятельности для генеративных авторегрессионных моделей, как раз сочетающих подчинение логическим закономерностям (пусть и опосредованным через тренировку) со здоровой долей стохастики. Однако, как свидетельствовало в сентябре агентство Reuters со ссылкой на крупную трейдерскую платформу eToro, лишь 13% частных инвесторов обращаются к ИИ уровня ChatGPT за советами, какие акции и прочие активы покупать, а какие продавать. И профильные эксперты горячо одобряют такую сдержанность: в последние годы американский рынок акций, а вслед за ним и мировой, уверенно растут (оставляем сейчас в стороне проблемы реального сектора экономики; речь именно о биржевых показателях — вон Nvidia к концу сентября уже подорожала до 4,5 трлн долл. с лишним) — индекс S&P 500 за 2024 г. подскочил на 23% год к году, а за 9 месяцев 2025-го успел взлететь ещё на 13%. И в такой ситуации не слишком-то сложно делать удачные ставки, чем авторегрессионные генеративные модели с успехом и пользуются. Зато, когда на биржах начнётся период турбулентности — а он, уверены прожжённые игроки уровня Баффетта, непременно начнётся, — натасканные на ламинарных потоках данных ИИ окажутся бесполезными. И вот тогда-то сделавшие на них ставку трейдеры пожалеют, что доверили управлять своими деньгами бездушной машине.

Физически корректно (в разумных пределах) падать с коня сгенерированным ИИ актёрам до появления Sora 2 не слишком-то удавалось (источник: OpenAI)
⇡#Боты творчества
Британская независимая студия звукозаписи Hallwood Media заключила контракт с Оливером Макканном (Oliver McCann), один из треков которого набрал три миллиона просмотров. Тонкость, впрочем, в том, что этот публикующий записи во множестве жанров, от инди-попа до кантри-рэпа, «инструменталист» не имеет, по его собственному признанию, ни музыкального образования, ни навыков владения каким бы то ни было инструментом, ни даже музыкального слуха. Зато неплохо наловчился формулировать такие подсказки для профильных генеративных платформ вроде Suno или Udio, что те частенько выдают в ответ собирающие множество «лайков» треки. И потому именно Макканн под псевдонимом imoliver стал первым в истории ИИ-музыкоделом (AI music creator), получившим официальное признание в форме юридически обязывающего договора.
На видеофронте ситуация в сентябре тоже складывалась угрожающим немалому числу кожаных мешков образом: OpenAI анонсировала Sora 2. Эту модель для генерации видео и аудио разработчики с гордостью называют прорывной, не менее значимой для этого мультимедиа направления, чем стала в своё время GPT-3.5 для генерации текста, поскольку она обеспечивает «понимание» (точнее, довольно прочное закрепление на уровне весов на входах перцептронов многослойной нейросети после её тренировки) физически корректной динамики объектов. Баскетбольные мячи на сгенерированных Sora 2 видео отскакивают от края кольца, соприкасаясь с ним, а не проходят насквозь, как это чаще всего бывало прежде; поскользнувшиеся на льду фигуристки довольно натуралистично движутся, распластавшись, по инерции, и т. д. Новая модель сохраняет также единство персонажей и объектов в кадре при смене планов, что для ИИ-генераторов видео было до самых последних пор настоящим камнем преткновения. Пользователь может также вставить свой собственный видеопортрет в генерируемый ролик — и это значит, что по мере продвижения Sora 2 в массы разнообразной, но на вид вполне удобоваримой ИИ-бурды в Сети будет становиться всё больше.
Microsoft тем временем старается не отставать от коллег из креативных индустрий, интегрировав на сей раз в Excel и Word функцию Office Agent на базе моделей Anthropic, — этот агент готов быстро создавать презентации и документы, в том числе со сложными таблицами, по подсказкам пользователя, причём делать это качественнее «штатного» Copilot. Как и полагается ИИ-агенту, цифровой офисный (есть же в фольклоре домовые, почему же в рабочем компьютере не сидеть виртуальному офисному?) прилежно разбивает предложенную задачу на элементарные шаги, формирует план работ и демонстрирует оператору, как справляется с его исполнением. Выходит, и работу с документами благодаря ИИ можно теперь превратить в творчество — vibe-writing, по сравнению с вайб-кодингом. Главное — подсказки поточнее формулировать и не забывать о выверке результатов: склонность генеративных моделей к галлюцинациям никуда не девалась.

«Он спрашивал меня, как получить анаболики без рецепта». — «М-м, вот он? Господи, ему-то зачем анаболики?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#«Вот этого арестуйте, офицер!»
Генеративный ИИ в нынешнем своём состоянии способен нанести людям немалый вред, даже если он изначально специализируется на решении медицинских задач. Недаром американские власти в сентябре взялись, наконец, за расследование в отношении семи крупных технологических компаний — разработчиков такого рода моделей, чтобы выяснить уже со всей (юридически значимой) определённостью, способны ли их творения негативно влиять на детей и подростков. Впрочем, и сами разработчики готовы, что называется, инициативно сотрудничать с государством с целью предотвращения нежелательных для всех инцидентов. Так, OpenAI не особенно даже скрывает, что сканирует диалоги, которые пользователи ведут с ChatGPT, задействуя для этого живых сотрудников, и те, если обнаруживают в переписке с ботом нечто априори неподобающее (а именно — вопросы о том, как навредить другим), моментально сообщают об этом в полицию. Такая политика, бесспорно, поднимает извечную проблему интернет-модерации — «а судьи кто?», — поскольку раз финальное решение принимает человек, то и ошибки он может совершать чисто человеческие. Правда, утешает тот факт, что как раз для выявления и исправления людских промахов, искренних заблуждений и злонамеренных действий и существует тысячелетия (со времён законов Ур-Намму как минимум) оттачиваемая офлайн юриспруденция. Уж по крайней мере не будет стоять вопрос, кто виноват, если чат-бот подаст начинающему террористу дельный совет, а живой модератор этот момент пропустит. Другое дело, что введение ручной перлюстрации чатов создаст дополнительную нагрузку на систему и ввергнет OpenAI в новые расходы, а это уже по-настоящему серьёзная проблема: хотя компания нарастила в первом полугодии 2025-го свою выручку до 4,3 млрд долл. (+16% год к году), до выхода на окупаемость ей ещё ох как далеко.
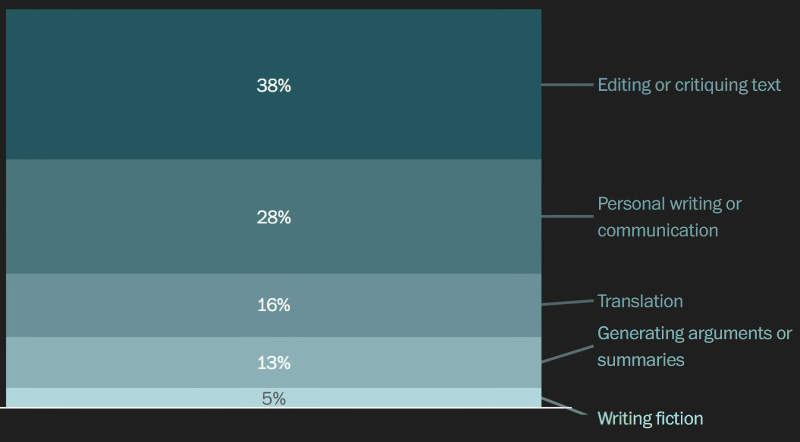
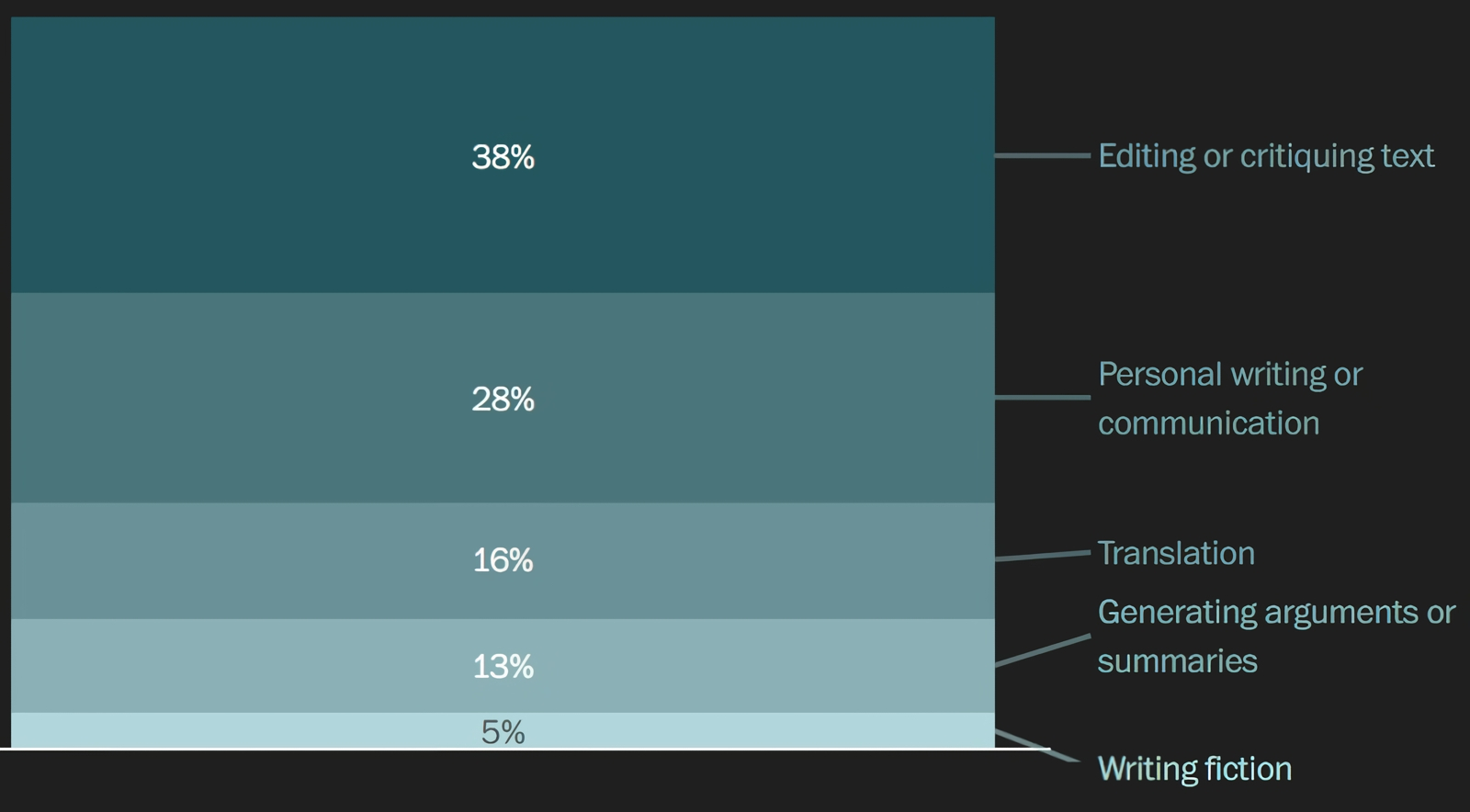
Чаще всего пользователи просят ChatGPT сгенерировать/отредактировать текст. На втором месте — помощь с частной перепиской; далее — перевод, создание краткого резюме и/или выделение основных тезисов. Получить же оригинальный, «из головы придуманный» текст — fiction — жаждут лишь 5% собеседников ИИ-бота (источник: OpenAI)
⇡#Зачем?
OpenAI изначально создавалась как некоммерческая организация, да и сегодня зарабатывающий миллиарды (и тратящий, впрочем, ещё больше) бизнес-проект под тем же названием по-прежнему контролируется и управляется тою же самой НКО. Возможно, по этой причине руководство коммерческой OpenAI не слишком удачно сводит концы с концами, так до сих пор и не начав зарабатывать деньги — т. е. не сведя положительный баланс затрат и доходов. Вот и первое публичное исследование того, кто и для каких целей обращается к её всемирно известному боту ChatGPT, компания обнародовала лишь в сентябре 2025 г., тогда как любой предприниматель, строго говоря, именно с исследования рынка (зачем и кому его товар/услуга может потребоваться) и должен начинать. В определённой степени столь вопиющую нерасторопность оправдывает тот факт, что до осени 2022-го никто и представить себе не мог, насколько привлекательными окажутся чат-боты — сперва для широких масс, а позже и для профессионалов в самых различных областях. Так или иначе, теперь мы знаем, что чаще всего — в 73% случаев — к ChatGPT обращаются по не связанным с работой вопросам. Практические советы от умного бота (как правильно тренироваться, о чём написать в заданном на дом эссе и т. д.) затребовали в 28,3% всех чатов, ещё 28,1% запросов были связаны с текстами (не только с их созданием, но и с редактированием и с критическим разбором), а 21,3% — с поиском данных. Далее с немалым отрывом идут «техническая помощь» (7,5%), создание/поиск/анализ медиа, самовыражение (4,3%) и прочее. Кстати, личную жизнь с генеративной моделью готовы обсуждать лишь 1,9% из тех, кто вступает с ней в контакт, а «игры и ролевые игры» затевают с ней и вовсе лишь 0,4% пользователей. Не готово всё-таки пока человечество в массе своей толковать с ботами по душам!
Приведённые OpenAI данные ценны широтой охвата аудитории; в более узких пользовательских стратах распределение по тематикам использования ИИ будет, конечно, иным. Так, исследование Inside Higher Ed, проведённое среди американских студентов, показало, что 85% из них за минувший год в той или иной мере прибегали к помощи генеративных инструментов в учёбе. В какой мере искренности заполнявшей опросники молодёжи следует доверять, вопрос отдельный, но подавляющее большинство респондентов сообщили, что обращались к ИИ-ботам исключительно для проверки собственных идей и поиска новых (brainstorming), за помощью в самоорганизации (tutoring assistance) и с целью получше подготовиться к экзаменам. Только 25% признались, что в значительной мере передоверяли генеративным моделям выполнение заданий, причём 19% использовали ИИ для генерации проверочных/курсовых работ (эссе) на все сто процентов. Занятно, что в два с лишним раза выше — 53% — оказался процент тех учащихся, которые выступают резко против обязательного введения проверок, «а не ИИ ли сгенерировал эту работу»: студенты предпочитают, чтобы вместо этого их обучали «этичному использованию искусственного интеллекта». Столь разительное различие даёт повод предположить, что на деле активно задействуют ботов при выполнении учебных заданий куда больше респондентов, чем готовы это открыто признать. Среди ответивших 35% не видят ни вреда, ни пользы от генеративных моделей для своего обучения, тогда как 23% считают, что полученные ими в вузе знания в эпоху ИИ станут ценнее, чем были бы прежде. Поучительно сопоставить этот оптимизм с актуальной ситуацией на американском рынке труда, о которой шла речь в начале настоящего материала.

«Ну-ка, дружней! Матрицы сами себя не перемножат!» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Китай не сбавляет обороты
Каково отставание КНР по микропроцессорному направлению от — ладно, пусть от не признанного почти никем в мире Тайваня (на TSMC приходится более 70% глобальной выручки от производства чипов на заказ), но хотя бы от США, чей полупроводниковый лидер — Intel — всё никак не может освоить необходимые Nvidia передовые техпроцессы? Всего примерно год назад американское аналитическое агентство ITIF оценивало объективно существующий до сих пор разрыв в пять лет. В сентябре же 2025-го основатель и глава всё той же Nvidia Дженсен Хуанг (Jensen Huang) говорил уже — пусть несколько эмоционально, но всё-таки — буквально о наносекундах, что отделяют китайских разработчиков чипов для ИИ от американских. Дело не в формальном освоении теми или иными производителями неких техпроцессов, а в том, что Intel продолжает испытывать трудности стратегического характера (с наймом квалифицированной рабочей силы прежде всего), хотя успешно привлекает финансирование и от правительства, и от потенциальных будущих заказчиков. В материковом же Китае, как подчеркнул Хуанг, достаточно талантливых специалистов и развиты традиции усердного труда. Вдобавок огромное население КНР позволяет различным провинциям страны конкурировать между собой, что способствует быстрому совершенствованию и внедрению технологических новшеств — тогда как США, Тайвань, Южная Корея и несколько в меньшей степени Япония вынуждены полагаться на одну и ту же, по сути, линейку литографического оборудования от голландской ASML.
Словно в подтверждение этих тезисов в том же месяце Huawei объявила о намерении создать «самый мощный в мире ИИ-кластер» — разумеется, на основе ускорителей Ascend 950 собственной разработки. Всего в состав кластера, запустить который планируют в 2026-м, должно войти свыше полумиллиона ИИ-чипов, причём отдельная его составная часть, «суперузел» на 8192 ускорителя, будет превосходить по вычислительной мощи систему Nvidia NVL144 (а её ввод в эксплуатацию тоже намечен на будущий год) более чем вшестеро. И угрожает позициям Nvidia на китайском для начала, а затем, вероятно, и на мировом рынке серверных решений для ИИ-задач не одна только Huawei. Другому ИТ-гиганту из Поднебесной, Alibaba, удалось разработать специализированную микросхему T-Head PPU, которая по рабочим характеристикам, как утверждается, вполне сопоставима с Nvidia H20. Учитывая, что власти КНР прямо начали запрещать местным компаниям импортировать ИИ-ускорители американской разработки (поток которых в страну, невзирая на запреты американского Минторга, долгое время не иссякал), можно понять разочарование мистера Хуанга: чем интенсивнее микропроцессорная конкуренция в серверном ИИ-сегменте, тем меньше выручки будет доставаться Nvidia. Соответственно, станут снижаться расходы на НИОКР, что, в свою очередь, притормозит темпы развития нынешнего лидера этого сегмента — и обеспечит догоняющим столь желанную для них фору. Тем более что остаются-то там считаные наносекунды.

«А вот ещё был случай: заходим мы как-то в бар с Куртом Кобейном...» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Сиди, слушай
Обидное название «ИИ-бурда» применяют по большей части к плодам генеративной обработки не самых умнó и тщательно составленных самими же пользователями подсказок — по сути, классическая ситуация «Над кем смеётесь?». А что, если искусственному интеллекту дать задание — позаботившись, разумеется, предварительно о должной его настройке, — развлекая, поучать? Быть может, именно такая идея посетила создателей очередного обновления для платформы YouTube Music, на которой ближе к исходу сентября в рамках программы Labs появились ИИ-диджеи. Перед ними поставлена задача «обогащать опыт прослушивания» транслируемых композиций — вплетая в музыкальную ткань «занимательные истории, интересные факты от поклонников и остроумные комментарии», связанные с тем или иным треком. При этом уточняется, что ИИ-диджей будет вести свою просветительски-развлекательную деятельность не между композициями, а частично накладывая на них свой голос, как это практикуется на довольно заметной доле радиостанций. Более того, после внедрения новой функциональности в приложении YouTube Music отключить её можно будет, нажав на особую кнопку, только на один час либо до конца текущего дня, но не раз и навсегда; по крайней мере, так ведёт себя ИИ-диджей в первой своей полуэкспериментальной версии, ограниченно доступной избранным пользователям на территории США.
Эксперты опасаются, что следующим шагом — не сразу, быть может, но через какое-то время — имеет все шансы стать интеграция рекламы непосредственно в реплики генеративного радиоведущего. Интересно, что в 1970-х — начале 1980-х многие коммерческие FM-радиостанции в США и других странах привлекали слушателей (до тех пор по привычке настраивавшихся на AM-волны), выпуская в эфир целые музыкальные альбомы без рекламных вставок — вполне отдавая себе притом отчёт, что композиции наверняка будут записаны поклонниками на магнитофоны, что в итоге снизит продажи на легальных носителях. Но, поскольку непосредственно радиостанции от таких продаж свою долю не получали, задача привлечь новых регулярных слушателей виделась более приоритетной. В общем-то, болтовня радиоведущих во время проигрышей до начала собственно пения и после его окончания, называемая на профессиональном сленге «talking to the post», и появилась, по одной из версий, как средство убрать саму возможность записи чистого полного трека, когда музыкальные лейблы начали договариваться с радиостанциями на иных условиях. Так что, похоже, с появлением ИИ-диджеев диалектическая спираль музыкальных трансляций совершает очередной виток — уже в цифровом пространстве.

«Ну вот. Опять расплескал. Всё с начала, да?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Уютный мирок для ИИ-сверхразума
Одна из причин сравнительно частого возникновения галлюцинаций у генеративных моделей — отсутствие жёсткой обратной связи, которая бы формировала сигналы «поощрения» и «наказания» за верно и неверно решённые задачи соответственно. Сам по себе этот механизм не так уж сложен — сенсорные системы «стимул — реакция» существуют даже у бактерий. Проблема лишь в том, что живые организмы вырабатывали такого рода поведение на протяжении миллиардов лет эволюции, взаимодействуя с окружающей средой, тогда как ИИ существует, буквально как в старом меме, сферическим в вакууме. В лучшем случае человек добавит в его систему предупреждение не выдавать по пользовательским запросам рецепт приготовления нитроглицерина и запретит изображать знаменитостей на генерируемых картинках, но и только. Добавка эта либо окажется внешней, заставляя ИИ «сознательно» игнорировать часть заложенных в него при обработке тренировочного массива данных, — и такое насилие над машинным разумом лишь увеличит вероятность появления у него галлюцинаций. Либо же сам этот массив придётся хорошенько обкорнать ещё до начала обучения, но в этом случае сложившаяся у многослойной нейросети картина мира тем более примется зиять самыми несуразными прорехами.
Вот почему ведущие игроки на рынке ИИ — Google, экстремистская Meta✴*, Nvidia и другие — всё деятельнее стремятся обучать свои новые модели не на массиве данных, а в живой, что называется, природе. Только не в реально существующей, а в смоделированной с высокой степенью правдоподобия, вплоть до законов физики, виртуальной среде — в так называемой модели мира. Заодно это очень здорово поможет развитию подлинно автономной робототехники, которая после всплеска интереса к ИИ в целом три года назад сегодня довольно заметно притормозила. Причина как раз понятна: генеративная модель, управляющая роботом, в отсутствие обратной связи с реальностью продолжает галлюцинировать, что частенько приводит к нежелательным последствиям. Если же такую обратную связь организовать — например, ввести контур дообучения модели, активирующийся всякий раз, когда робот производит небезопасное для него и/или для его окружения действие, — страдать (ради формирования корректирующего сигнала) будет физическая конструкция недешёвой машины. Что и затратно, и времени для формирования устойчивой реакции требует изрядного: нельзя ведь предсказать, в какой именно момент система примется галлюцинировать. Виртуальное окружение, в котором ИИ будет управлять неким аватаром, развивая и укрепляя естественным образом связь «стимул — реакция» при взаимодействии с виртуальными же объектами, подчиняющимися законам земной физики, подходит для выработки эффективной обратной связи как нельзя лучше. Как раз этот путь, уверены разработчики, и ведёт к вожделенному «машинному сверхразуму» — пресловутому сильному ИИ.

«Этот — ваш. Персональный. А вот мой OpenAI-кошелёк!» (Источник: Intel)
⇡#Каждому по ускорителю! Ох нет, не за мой же счёт, ну что вы начинаете…
Сколько на всю планету потребуется мощных ИИ-ускорителей, чтобы с их помощью эффективно решать всё новые, непрерывно встающие перед землянами генеративные задачи? На взгляд Грега Брокмана (Greg Brockman), президента OpenAI, оценку снизу сделать очень просто: на каждого по одному — и ещё немного сверху, про запас; всего примерно десять миллиардов. Генеральный директор той же компании, Сэм Альтман (Sam Altman), охотно поддерживает коллегу и заявляет, что сотрудничество OpenAI с Nvidia для достижения этой благородной цели, если вычислить её значимость для человечества, окажется важнее Лунной программы США, которая стала подлинно великим достижением второй половины прошлого века (настолько великим, что повторить высадку на наш естественный спутник по прошествии изрядного количества десятилетий всё никак не выходит). «Вам действительно захочется, чтобы у каждого человека был свой собственный выделенный GPU», — настоятельно увещевает Брокман: по его словам, мир уверенно движется к состоянию, при котором экономике придают импульс вычисления, а выделенный агентный ИИ усердно и, главное, проактивно (т. е. самостоятельно ставя перед собой цели и достигая их) трудится на каждого конкретного человека, даже пока тот спит. Бесспорно, признаёт президент OpenAI, достичь этой благородной цели будет непросто: вычислительная мощь, необходимая, по его оценке, для создания генеративного «супермозга» (superbrain), превосходит доступную ныне на три десятичных порядка величины, так что работать ещё есть над чем. Фактически речь идёт о том, что расходуемые на решение насущных ИИ-задач мощности — условные терафлопсы серверов в соответствующих дата-центрах — должны сделаться де-факто новой валютой, поскольку генеративные агенты самого разного рода обязаны стать для всех и каждого необходимыми как воздух.
Дойдёт до этого на самом деле или нет, увидим. Интересно только, какой рубеж человечество перешагнёт раньше: создание пресловутого «супермозга» — или всё-таки выход OpenAI на прибыльность?
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности».
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex