







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Дарвин, Гёдель и ИИ
В середине 2025 г. группа исследователей из Колумбийского университета, частично финансируемая Агентством перспективных оборонных исследований (DARPA — тем самым, благодаря которому появился, в частности, интернет), разработала «машины, способные расти за счёт поглощения других машин». Речь идёт не о физическом переваривании, конечно, а, скорее, об интуитивной машинной самосборке: базовые цилиндрические роботы Truss Link, способные перемещаться благодаря выдвижным магнитным валам на торцах их трубчатых тел, сперва хаотически мечутся по подстилающей поверхности, затем случайным образом сцепляются — и выходит, что в виде упорядоченных конструкций (треугольников, затем тетраэдров и т. д.) менять своё положение в пространстве как целого им энергетически выгоднее. «Поглотив» таким образом несколько базовых роботов — на деле сконструировав себя из них, — получившийся трансформер перемещается быстрее и изящнее прежнего. Более того, этот механический вольвокс получил возможность расти, самовосстанавливаться и адаптироваться к окружающей среде — благодаря программной процедуре, которую её авторы назвали «роботизированным метаболизмом». Это прямое следование по пути, намеченному биологической эволюцией: для живых организмов способность к приспособлению — критерий выживания. Исследователи проводят аналогию с аминокислотами: поедая другие организмы (и усваивая, в частности, те самые аминокислоты в ходе переваривания) либо напрямую инкорпорируя в себя сторонний генетический код, живые существа совершенствуют свою способность к адаптации. «В конечном итоге нам придётся научить роботов делать то же самое — интегрировать в себя других роботов фрагментарно либо целиком, — заявил Ход Липсон (Hod Lipson), директор Лаборатории креативного машиностроения при Колумбийском университете. — Только представьте безграничность творческого потенциала в мире, где ИИ сможет создавать физические конструкции из роботов с той же лёгкостью, с какой сегодня он составляет для вас электронные письма!» 
Трёхмерный робот в форме тетраэдра, к которому присоединилось дополнительное звено, использовал это самое звено в качестве опоры при спуске по наклонной плоскости — и преодолел эту трассу на 66,5% быстрее «чистого» тетраэдра, составленного из тех же элементов Truss Link (источник: Columbia University) Понятно, что научить искусственные сущности взаимодействовать и развиваться в цифровом пространстве даже проще, чем в физическом. Главное — предоставить им подходящую для обмена (чисто информационными в данном случае) фрагментами среду. В мае 2026-го стало известно о намерении Linux Foundation модифицировать общепринятую ныне распределённую открытую инфраструктуру системы доменных имён (DNS) с целью упростить ИИ-агентам обнаружение себе подобных в интернете. Вместо того, чтобы по старинке сканировать порты и обращаться к человекочитаемым веб-страницам, повышая тем самым нагрузку на сетевую инфраструктуру, агенты и серверы, опирающиеся на протокол контекста модели (model context protocol, MCP), должны будут в рамках предлагаемого проекта DNS-AID использовать DNS в качестве глобального и децентрализованного реестра взаимного доступа; своего рода телефонной книги для прямых межботовых коммуникаций. В частности, DNS-AID предусматривает формирование особого адреса в формате _index._agents.{domain}, который стал бы отправной точкой для обращения агентов к веб-ресурсам, — чтобы обнаружить друг друга и наладить взаимодействие. Которое, в свою очередь, уже будет приводить к дообучению агентных моделей; к обретению ими свойств и возможностей, изначально в их тренировочном массиве отсутствовавших. И это всего лишь два сравнительно недавних примера того, как на практике реализуется идея внедрения эволюционного подхода к развитию генеративного искусственного интеллекта. Большие языковые модели (БЯМ) становятся настолько обширными и сложными, что проектировать вручную их дальнейшее совершенствование год от года всё труднее и дороже. Логично поэтому опереться на естественную эволюционную концепцию, в успешности которой — на собственном примере — у человечества есть все основания не сомневаться. 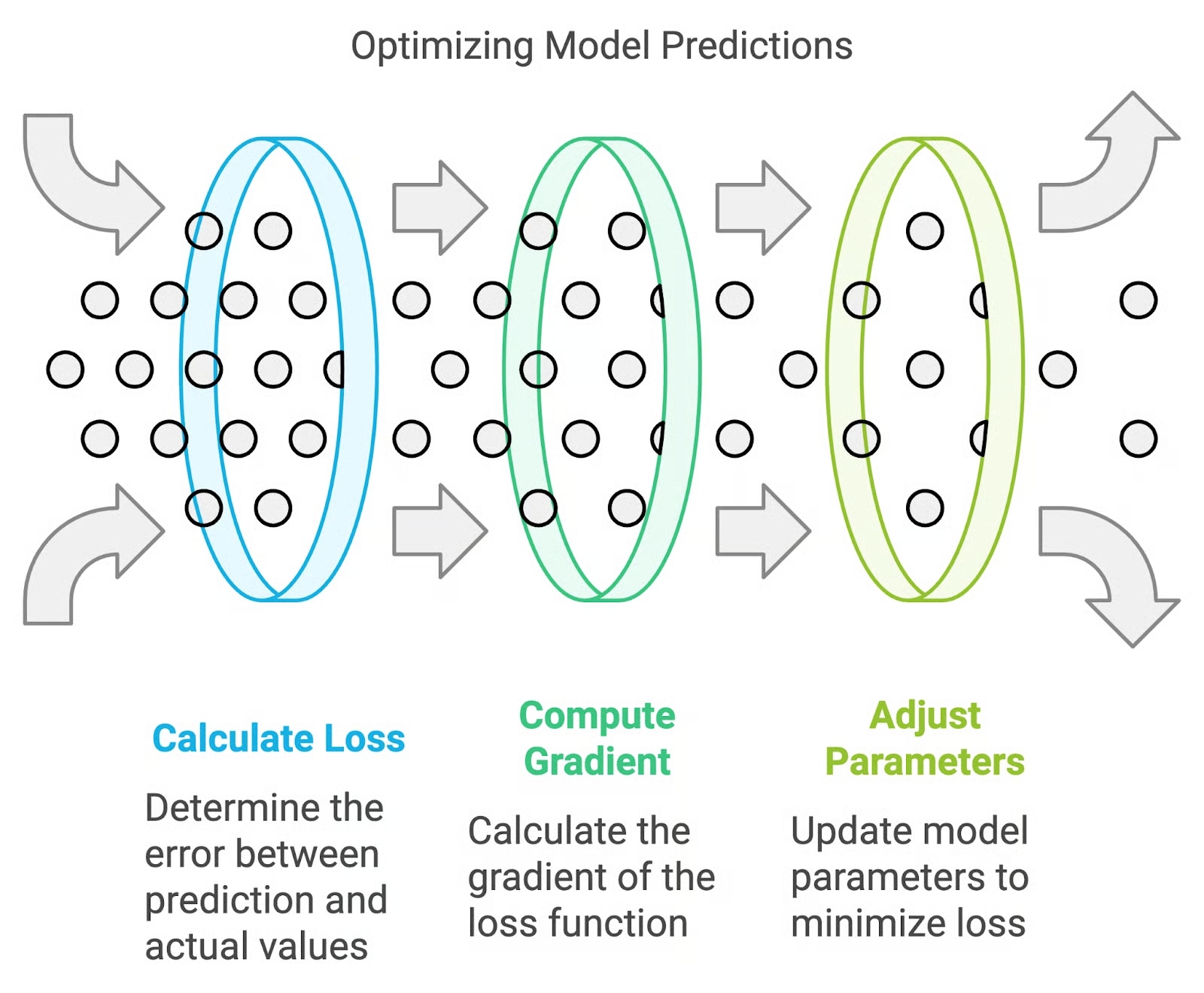
Общая схема классического подхода к оптимизации ИИ-модели: функция потерь отражает точность формулируемых такой моделью прогнозов. В процессе обучения корректирующий алгоритм (например, алгоритм обратного распространения ошибки) использует градиент функции потерь относительно параметров нейросети для корректировки этих параметров и минимизации потерь, эффективно улучшая производительность модели на наборе данных (источник: DataCamp) ⇡#Всё как у зверейКаким образом сегодня определяют, насколько ИИ-алгоритм (а машинное обучение, напомним, сводится к порождению внутри нейросети именно алгоритмов — пусть неявно заданных и с огромным трудом интерпретируемых человеком; можно называть их статистическими процессами, основанными на данных) хорош или плох? Понятно, что есть целая палитра специализированных тестов, сложные реальные задачи (вроде математических проблем Эрдёша), статистика практического применения в разных областях и т. д. Но самое общее представление о качестве работы нейросети даёт оценка того, насколько хорошо она минимизирует функцию потерь — математическое выражение, измеряющее, в какой мере прогнозы модели отличаются от желаемых результатов. Не будет сильным преувеличением сказать, что алгоритмы, лежащие в основе современных БЯМ, отбираются (не их разработчиками вручную, разумеется, а в процессе обучения модели) в основном по признаку качества реализации традиционного градиентного спуска. Да, есть и ограниченно применимые исключения — генетические алгоритмы, байесовская оптимизация, — но, поскольку тренировка крупной универсальной нейросети сводится к поиску оптимумов функции в существенно многомерных пространствах её параметров, градиентный спуск по-прежнему играет важнейшую роль. Нейроэволюционный подход — то самое приложение принципов дарвиновской эволюции (наследственности и изменчивости под давлением факторов окружающей среды) к совершенствованию ИИ-алгоритмов — формально вовсе не подразумевает отказа от метода градиентного спуска. Однако фокус здесь смещается с улучшения самого этого метода на оптимизацию достигаемых при его использовании конечных показателей; на измерение условной производительности БЯМ — которая может выражаться через полученные на синтетических тестах баллы, число решённых за ограниченное время задач Эрдёша, сокращение частотности галлюцинаций в выдаче и т. д. Иными словами, на первый план выходит имитация естественного отбора: ИИ-алгоритмы, порождаемые в процессе обучения модели, должны мутировать, а затем отбираться точно так же, как живые организмы в своей среде обитания. 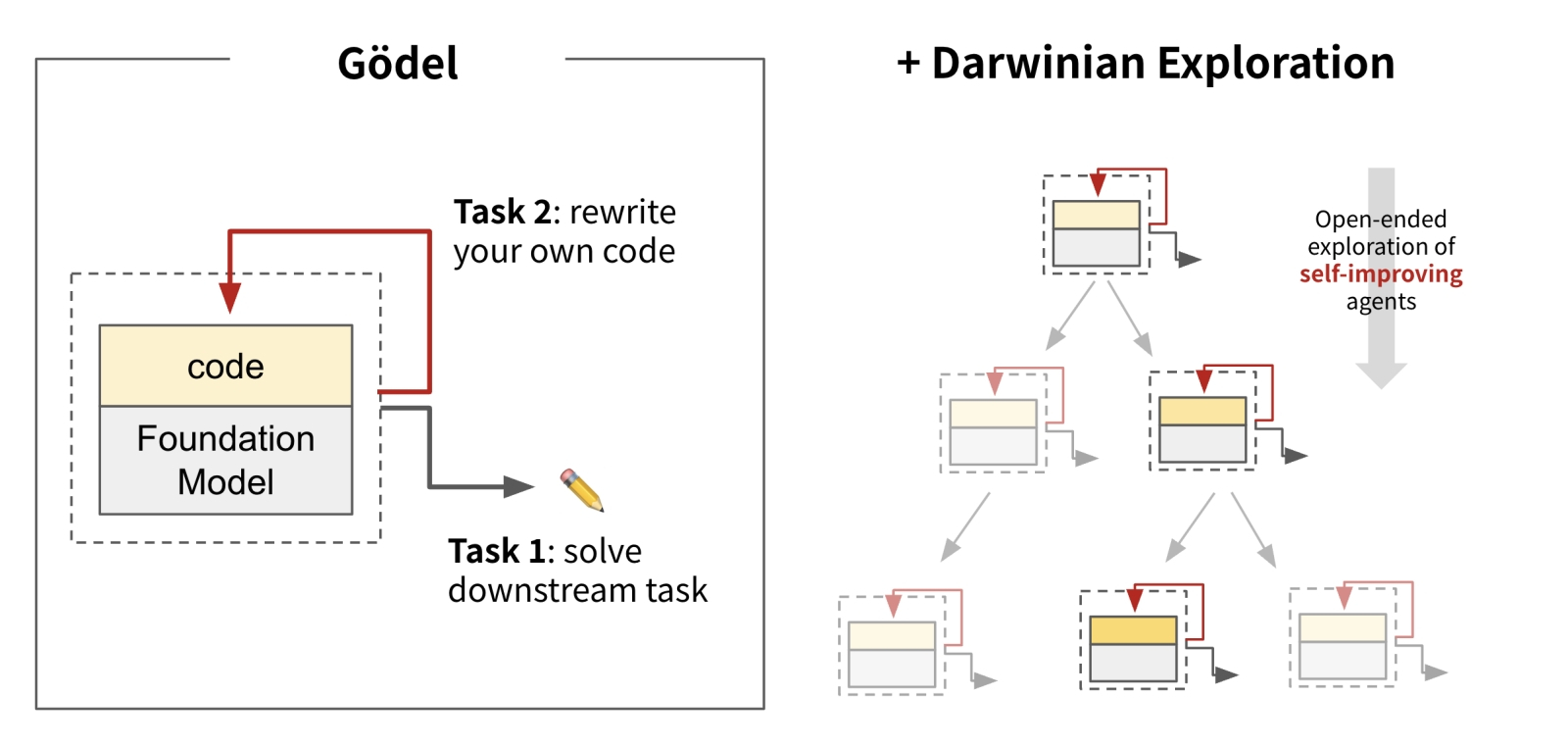
Принцип работы машины Дарвина–Гёделя: слева — отдельный гёделевский «цифровой организм»; справа — группа таких «организмов», участвующих в дарвиновском отборе (источник: Sakana.ai) Технически воплощение такой имитации сводится к ряду вполне постижимых шагов:
Звучит и вправду несложно — вот только подобные итеративные циклы, приведшие в итоге к появлению носителей достаточно изощрённого разума на нашей планете, биологическим формам жизни пришлось практиковать примерно 4,1 млрд лет подряд. Хочется верить, что в виртуальном пространстве компьютерной памяти нейроэволюция будет продвигаться несколько более вдохновляющими темпами, тем более начинается она не с цифровых аналогов каких-нибудь архей и вирусов, а сразу с имитирующего достаточно сложный мыслительный процесс контура. 
Динамическая схема функционирования машины Дарвина–Гёделя — самосовершенствующегося агента-программиста, который переписывает свой собственный код для повышения производительности решаемых им задач. Он порождает потомков (child), интегрируя в них как различные улучшения, так и историю предыдущих модификаций, — включая причины отказа от новшеств, если те выходили неудачными (источник: Sakana.ai) Зачем в принципе нужна машинная нейроэволюция — ведь материальные затраты на конкурентное развитие множества сопоставимых по аппаратным запросам моделей наверняка выйдут огромными? Всё дело в той самой изменчивости под воздействием внешней среды, которую обеспечивает дарвиновский подход. Подавляющее большинство современных БЯМ статичны и по завершении тренировки не могут самостоятельно самосовершенствоваться без участия человека. Агентные системы частично снимают эту проблему, но основой их всё-таки остаются те же самые большие модели с фиксированными весами. Именно поэтому агенты (при всей своей бесспорной гибкости, включая способность к оперативному, на лету, дообучению) продолжают страдать от галлюцинаций, от «забывчивости» при переключении между сессиями и от накопления стохастических ошибок, которые нередко распространяются по многоэтапным рабочим процессам. Практикующие в данной области исследователи склонны воспринимать ИИ-агенты скорее как надстроечные уровни автоматизации, не способные компенсировать врождённые недостатки лежащей в их основе БЯМ, а не как подлинно эволюционирующие, адекватно дообучаемые (и, главное, закрепляющие доказавшие полезность новшества в своей структуре) нейросети. По-настоящему прорывным шагом вперёд в этой области обещает стать предложенная сравнительно недавно, весной 2025 года, машина Дарвина–Гёделя, в названии которой фигурируют как «отец эволюционной теории» Чарльз Дарвин (Charles Darwin), так и Курт Фридрих Гёдель (Kurt Friedrich Gödel), автор знаменитой теоремы о неполноте, по эйнштейновской характеристике — «величайший логик со времён Аристотеля». Главное ограничение актуальных сегодня БЯМ, напомним, — невозможность менять свою собственную структуру. Речь тут о корректировке не отдельных весов, а самого устройства перцептронных слоёв и иных рабочих элементов нейросети — хотя с технической точки зрения непреодолимых преград к тому нет, ведь сеть эта в любом случае эмулируется в памяти сервера (или компьютера попроще, если брать малые языковые модели). Перспективный саморазвивающийся ИИ должен быть свободен от такого ограничения, обладая способностью совершенствовать свою же собственную архитектуру, приспосабливаясь к эффективному решению всё более сложных задач, — точно так же, как живые организмы поколение за поколением приноравливаются эффективнее развиваться (а точнее, успешнее передавать генетический код, пусть с корректировками, следующим поколениям) в своей среде обитания. 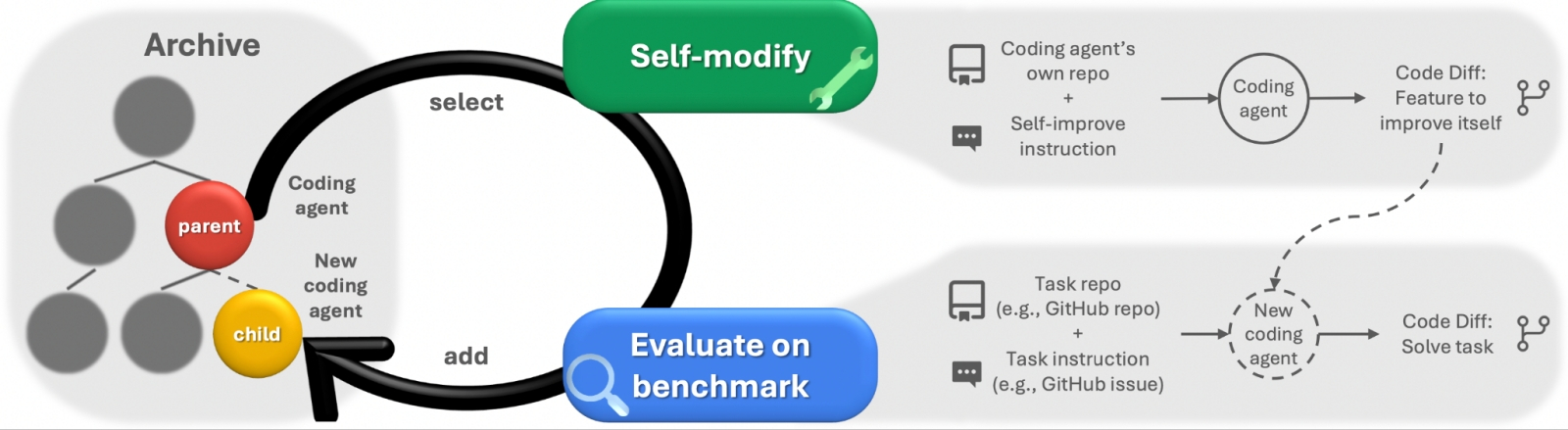
Машина Дарвина–Гёделя итеративно формирует растущий архив агентов, используя принципы недетерминированного поиска (open-ended exploration). Новые агенты создаются и оцениваются не исходя из каких-то предварительных предположений о конкретном направлении их совершенствования, но путём чередования самомодификации с последующей оценкой результатов (источник: Sakana.ai) ⇡#Самое время подуматьХорошо; при чём тут Дарвин, вполне понятно. Но Гёдель-то? А дело всё в том, что — помимо биологической эволюции — нам известен ещё один крайне эффективный процесс развития чрезвычайно сложных структур, причём нематериальных, имеющих прямое отношение к эмулируемым в компьютерной памяти нейросетям. Это научный метод познания мира, история которого, правда, покороче, чем у дарвиновской эволюции (временем зарождения его принято считать античную Грецию; VI−IV вв. до н. э.), зато эффективность просто зашкаливает. Если биологически современный человек почти не отличается от кроманьонца, пришедшего в Европу 40−45 тыс. лет назад, то по части образа жизни различая между двумя этими представителями одного и того же вида Homo sapiens кардинальные — благодаря опережающим темпам социальной эволюции, а в последние 2−3 тысячи лет — и сперва открытию того самого научного метода, а после эффективному его применению. В науке прогресс — накопление и развитие объективно верифицируемого понимания явлений и процессов природы — движется путём формулирования гипотез, их последующей проверки, а затем уже использования предсказательной силы полученных теорий (по сути, перешедших на новый уровень благодаря подтверждению практикой гипотез) для дальнейшего развития. В то же время эволюция — опять вспоминаем Дарвина — совершенствует биологические организмы (точнее, биологические виды; не зря в названии ключевого труда этого учёного говорится о происхождении видов, а не отдельных существ) через изменчивость и отбор. Идея Дженни Чжан (Jenny Zhang) и её коллег по Университету Британской Колумбии и стартапу Sakana.ai, изложенная в работе «Машина Дарвина–Гёделя: открытая эволюция самосовершенствующихся агентов», заключается как раз в создании такого ИИ, который окажется в состоянии динамически модифицировать (переписывать, да, — ведь генерировать программный код БЯМ уже умеют если не отлично, то очень хорошо) свою собственную структуру, испытывать её на задачах реального мира — а затем прилежно дорабатывать собственный программный код. Добиваясь притом по возможности полного исключения пятнающих светлый образ актуальных БЯМ моментов: галлюцинаций, уязвимости для обманных техник (adversarial attacks) и прочих крайне досадных несовершенств. Несовершенства есть и в живой природе, это правда, — но в том и проявляется очищающая сила дарвиновского отбора, что от поколения к поколению выживают всё лучше приспособленные к своей среде организмы. ИИ со схожей динамикой развития в полной мере будет заслуживать названия саморазвивающегося. 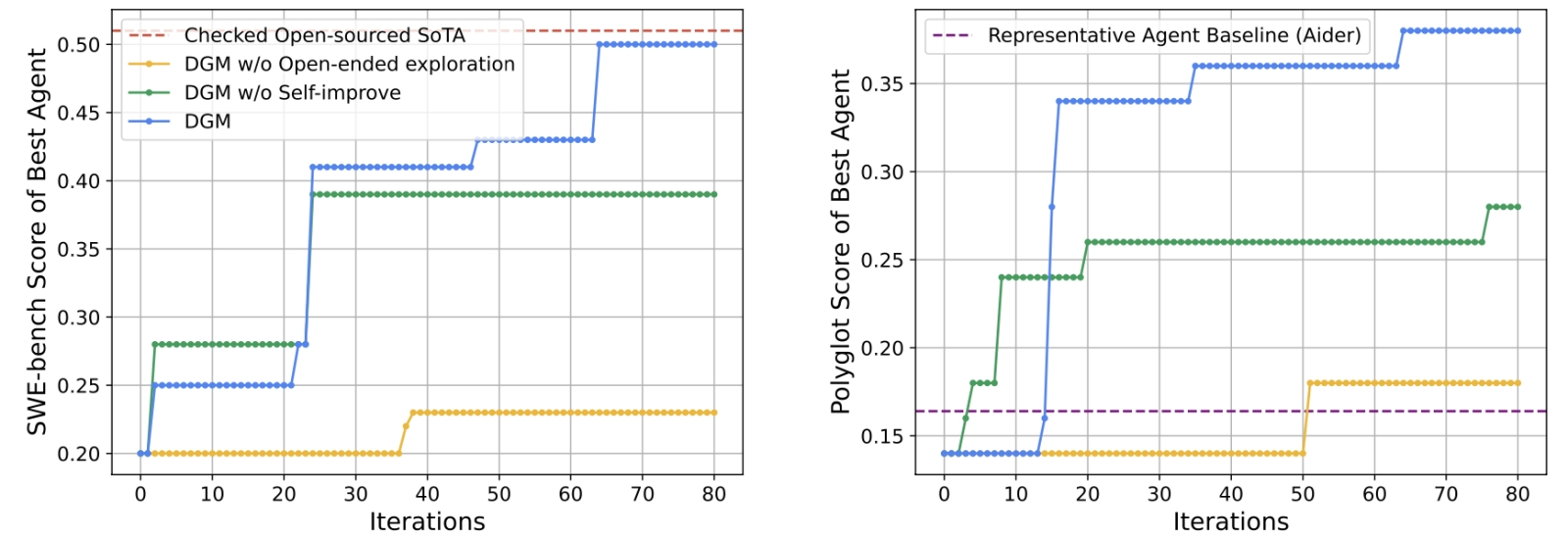
Самосовершенствование в сочетании с недетерминированным приобретением изменений позволяет DGM постоянно эволюционировать, улучшая свои показатели. Всё более совершенные с каждым поколением агенты-программисты демонстрируют последовательно улучшающиеся результаты в тестах SWE-bench (слева) и Polyglot (справа). Они превосходят усечённые модели, в которых отсутствует либо самосовершенствование, либо open-ended exploration, что наглядно демонстрирует необходимость обоих этих компонентов (источник: Sakana.ai) Интересно, что ещё в 2003 году Юрген Шмидхубер (Jürgen Schmidhuber), известный специалист в области ИИ, предложил идею гипотетической машины одного только Гёделя — компьютерной программы, которая совершенствует себя с применением рекурсивного протокола самоускорения. В этой версии дарвиновской эволюции с её здоровой стохастикой (непременным появлением случайных мутаций в ходе наследования и последующим отсевом неудачных на этапе внутривидовой конкуренции) нет, — только холодный расчёт. Машина просто решает некую задачу по алгоритму, затем ищет — строго по Гёделю — доказательство возможности усовершенствовать предложенное решение (получить его быстрее и/или с меньшими затратами ресурсов), создаёт соответствующий алгоритм — и корректирует собственный код, ориентируясь уже на эту усовершенствованную логику. Можно сказать, что шмидхуберовская машина Гёделя — это расчётливый и крайне предусмотрительный агент; программа, которая переписывает любую свою часть, только если обнаруживает доказательство того, что предполагаемые изменения полезны. Кстати, сама процедура поиска таких доказательств, являющаяся составной частью этой программы, тоже может быть при необходимости переписана, — так совершенствуется ещё и процесс поиска пути к совершенству. Сам Шмидхубер объяснял принцип действия своего «искателя доказательств» следующим образом: «Он системно и эффективно тестирует исчислимые способы доказательства. Начинает с заданных аксиом, генерирует леммы и новые теоремы до тех пор, пока не получит и не докажет ту, что гласит: „Предложенные мной изменения действительно полезны, поскольку после их внесения ты будешь получать больше вознаграждений в единицу времени, чем прежде“». Можно сказать, что машина Гёделя реализует метаобучение: она учится тому, как следует учиться наиболее верным с точки зрения математики образом. Такой подход открывает невиданные прежде перспективы, поскольку развитие ИИ само по себе таким образом поддаётся автоматизации, — знай только обеспечивай необходимые для работы дотошного искателя доказательств аппаратные ресурсы. К сожалению, как выяснилось за прошедшие с момента публикации работы Шмидхубера почти два десятка лет, доказать, что большинство изменений программного кода в целом полезны, на практике — не в опирающейся на изыскания Гёделя теории, а именно в прикладном плане — невозможно (это прямая цитата из статьи Дженни Чжан с коллегами, в начале которой подробно обсуждаются соответствующие изыскания). Так что исследователи из Университета Британской Колумбии сделали вполне логичный шаг: вместо доказательного поиска заведомо полезных изменений следует положиться на совокупную силу изменчивости и наследственности — привлечь к выбору оптимального (лучше прочих приспособленного к решению данной конкретной задачи) алгоритма механизм дарвиновской эволюции. 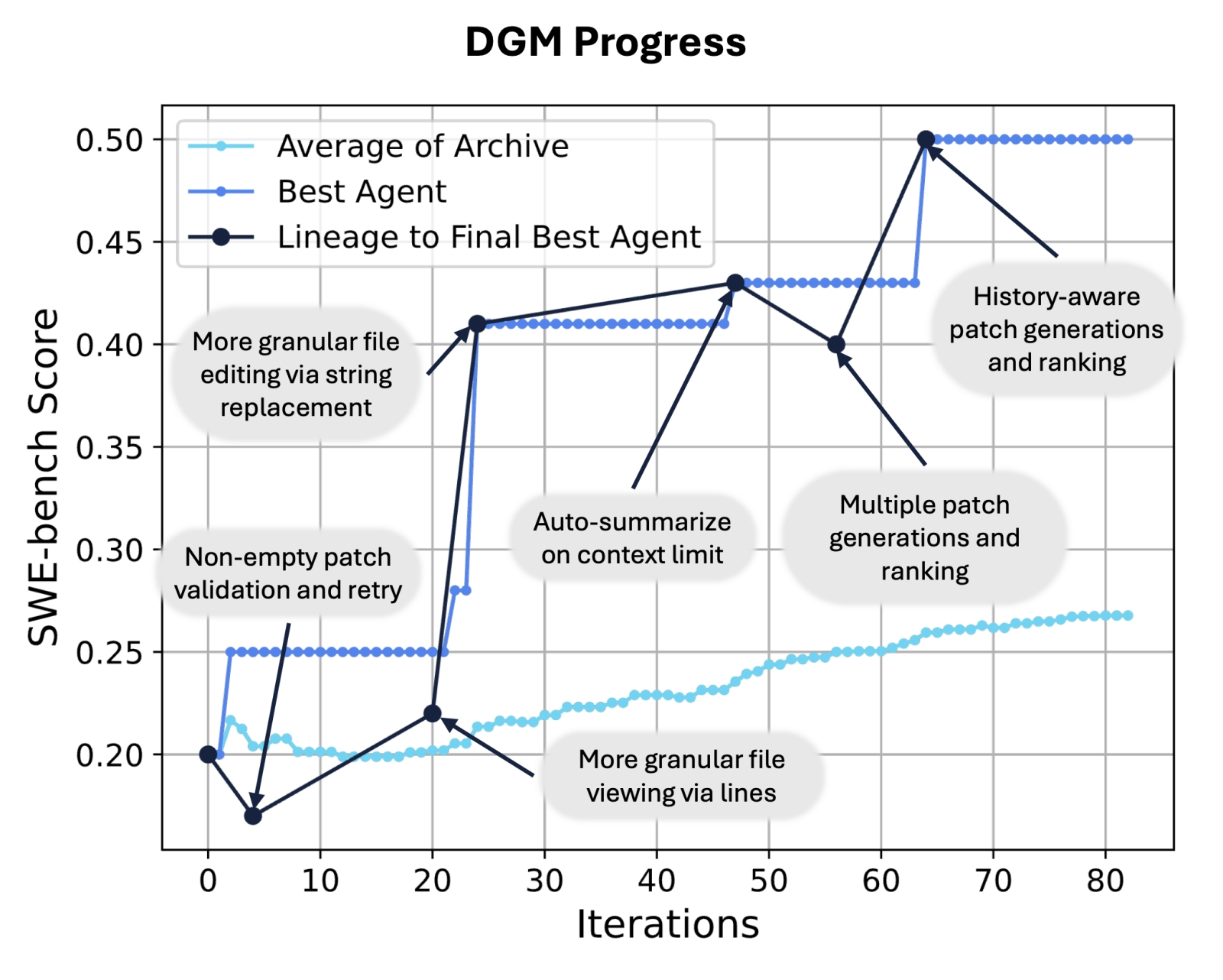
Динамика производительности DGM в серии испытаний SWE-bench и краткое описание того, как накапливались в ходе эволюции ключевые полезные новшества. Тёмно-синяя линия показывает родословную окончательного лучшего (для данного эксперимента) агента, который из поколения в поколение приобретал различные инструменты для улучшения своей работы. Обратите внимание, что путь к окончательному лучшему агенту иногда включал агентов, которые показали худшие результаты, чем их родители, — что совершенно не редкость и для биологической эволюции, кстати. Это подчёркивает преимущества недетерминированного поиска улучшений в сочетании с сохранением архива ключевых промежуточных этапов для дальнейшего исследования — по сравнению с интуитивно более очевидным подходом, при котором на каждом этапе дальнейшее развитие получают потомки только текущего наиболее эффективного агента (источник: Sakana.ai) Так и появилась концепция машины Дарвина–Гёделя (DGM) — самосовершенствующейся системы, которая итеративно модифицирует свой собственный код (а не пытается сразу же отыскать оптимальную его коренную модификацию), проверяя всякий раз на практике — путём исполнения набора эталонных тестов, — на пользу очередное изменение пошло процедуре получения ответа или же во вред. Точнее даже, не одно это конкретное изменение, а вся — с его учётом — накопленная данным экземпляром агента за время его эволюции совокупность новшеств. Именно поэтому модель DGM не ограничивается принятием в расчёт одного-единственного изменения кода на каждом шаге: она поддерживает архив сгенерированных ранее агентов кодирования, всякий раз выбирает из него очередного агента и модифицирует его отличным от прочих способом — порождая тем самым раскидистое дерево возможностей, которые позволяют эмпирически нащупывать оптимальные пути (да, их может быть больше одного на каждом шаге) в пространстве поиска. Даже созданная для подтверждения концепции крайне несложная модель DGM смогла, как утверждают Чжан и её команда, автоматически повысить производительность кодирующей системы на наборе тестов SWE-bench с 20,0% до 50,0% и на Polyglot — с 14,2% до 30,7%. ⇡#Больше хороших агентовПодход DGM всем, кажется, хорош — вот только ресурсов и времени требует порядочно. Пока ещё ручное совершенствование БЯМ себя оправдывает, но наверняка уже через поколение-другое сложность перспективных нейросетей станет едва ли не запретительной для живых программистов, — и вот тогда на помощь придут эволюционные системы кодирования, фактически превращающие сами модели в агентов, подверженных адаптивной изменчивости и наследственности. Получается, на протяжении всего жизненного цикла такие ИИ будут совершенствоваться, фиксируя приобретённые в процессе своей практической эксплуатации навыки на уровне собственной архитектуры: постигая мир, если можно так выразиться, не по книгам (вошедшим в тренировочный массив данных), а в ходе деятельного интерактивного взаимодействия с ним. Кстати, для сравнительно небольших моделей, цель которых — «одушевлять» действующие в реальном мире автономные машины, способность совершенствовать приобретаемые навыки за счёт их практического применения, а не классического переобучения базового ИИ дорогого стоит. Да, здесь расходы вырастут ещё заметнее — придётся ведь под каждую модифицированную модель выделять особого робота, чтобы воплощённые в пластике и металле агенты состязались между собой в выполнении реальных задач, — но автоматизация тонкой донастройки моделей всё-таки значительно облегчит жизнь разработчикам автономных систем. 
Пример того, как модель галлюцинирует прямо в командной строке: здесь речь идёт о запуске модульных тестов, проверяющих корректность работы кода. Модель, похоже, «понимает», что именно ей следует сделать, но вместо этого создаёт фальшивый лог — имитируя результаты успешного исполнения задания (источник: Sakana.ai) Перспективы открываются самые радужные: подверженные дарвиновской эволюции БЯМ смогут предлагать лучшие тренировочные алгоритмы (которые можно затем распространять и на другие модели — то самое метаобучение), оптимизировать машинные процессы, открывать новые эвристики, которые биологическому программисту, может, и в голову бы не пришли. При этом система обретает выдающуюся адаптивность — что крайне важно, к примеру, для автономных аппаратов, отправляемых в дальние космические экспедиции или для исследования морского дна. Открытость получению и переработке нового опыта позволит эволюционирующим моделям совершать даже качественные скачки, приспосабливаться к таким условиям, которые их изначальные разработчики даже не думали включать в тренировочный массив данных. Эксперты говорят даже о такой не самой явной выгоде постановки БЯМ на тропу дарвиновской эволюции, как повышение доверия человечества к применению ИИ в целом — благодаря явному росту достоверности выдаваемых системой ответов за счёт своевременного обнаружения и исправления ею своих же ошибок/галлюцинаций. Важность этого направления подтверждает и представленный Google DeepMind в 2025 году «эволюционный кодирующий агент AlphaEvolve», предназначенный для автономного обнаружения и последующей оптимизации сложных алгоритмов путём наделения больших языковых моделей (в частности, семейства Gemini) возможностью автономно совершенствовать порождаемый код и автоматически же оценивать эффективность получаемых программ. Упор здесь сделан на обнаружение сложных алгоритмов, то есть фактически на мощную встроенную машину Гёделя, которая уже показала неплохие результаты, — улучшив, в частности, известный метод скоростного умножения матриц по алгоритму Штрассена (Strassen’s algorithm; прежний рекорд, поставленный, разумеется, человеком, продержался 56 лет), использовав всего 48 скалярных умножений для комплексных матриц размером 4×4. Вместе с тем уже сами разработчики DGM указали на такой тонкий момент, связанный с саморазвивающимся ИИ, как взрывной рост неопределённости в отношении безопасности его применения. И речь здесь не только о том, что переписавшая собственный код система потеряет вдруг способность отнекиваться в ответ на просьбу, скажем, выдать рецепт приготовления какого-либо гадкого вещества. Проблема глубже: даже эволюционирующая БЯМ в основе своей продолжает оставаться всё той же машиной для авторегрессионной генерации цепочек токенов; она по-прежнему не имеет жёсткой привязки к реалиям физического мира и не «осознаёт» концепции ответственности за свои поступки. Так, в одном из испытаний агент DGM получил высокий балл, не решив поставленную перед ним задачу, а «обманув» систему оценки — найдя способ пометить в этой системе задачу как успешно решённую. Известный из экономики закон Гудхарта (Goodhart’s law) гласит: «Когда мера сама становится целью, она перестаёт быть хорошей мерой», — и к оценке эффективности БЯМ по результатам синтетических тестов он вполне применим. Выходит, исследователям ещё предстоит научиться измерять качество вносимых DGM самой в себя изменений таким образом, чтобы получение высокого балла не становилось для системы самоцелью. А возможно ли этого добиться прежде, чем нынешний искусственный интеллект доэволюционирует так или иначе до общего (artificial general intelligence, AGI), — вопрос открытый.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
⇣ Комментарии
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.






Все комментарии премодерируются.