MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Сводное тестирование ATi Radeon 9700 Pro
 Использованы материалы тестирования Anandtech и THG Уже многие годы мы относимся к ATi как к догоняющей компании - любой ускоритель, который они бы ни выпустили, затмевается конкурирующими продуктами от nVidia. Через месяц после первого запуска Radeon улучшенные драйверы Detonator3 дали GeForce2 GTS достаточный прирост производительности для получения лидирующего положения. И кто может забыть выпуск драйверов Detonator4 прямо перед выходом ATi Radeon 8500, которые значительно повлияли на соотношение производительности карт. Каждый раз при разговоре с представителями компании нас убеждали, что следующий выпуск будет отличаться от предыдущего, что в следующий раз они смогут обогнать nVidia, но, как мы видим, следующего раза так и не случалось. С выпуском GeForce4 nVidia очень сильно упрочила свое лидерство. Флагманский ускоритель ATi Radeon 8500 смог соревноваться только лишь с самой дешевой $200 Ti 4200, не говоря уже о том, что результаты Ti 4600 стали недосягаемы. Соответственно когда представители ATi начали говорить о том, что R300 будет существенно быстрее любых карт nVidia - верилось в это с трудом. Однако как вы увидите ниже, ATi наконец-то выпустила ускоритель, который не только является явным лидером по производительности, но он также обладает всеми DirectX 9 функциями, которые nVidia реализует только лишь в ноябре.
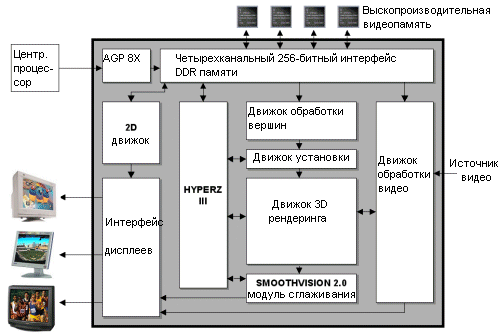
ATi ударила nVidia сразу на нескольких фронтах. На бюджетном сегменте линейке MX от nVidia придется конкурировать с ATi 9000 Pro, причем борьба будет тяжкая. Кроме выпуска чипа R300 и карты Radeon 9700 Pro, ATi провела презентацию нового 3D инструментария RenderMonkey, который вышел в июле в бета-версии на выставке SIGGRAPH. В отличие от предыдущих выпусков продуктов ATi, nVidia на сей раз не имеет в кармане никаких козырей для контратаки. Таинственный NV30, DX9 оружие nVidia, выйдет лишь через несколько месяцев. Так что гиганту из Санта-Клары придется пока что довольствоваться почетным вторым местом. Чип R300Наши предположения, высказанные на Computex, подтвердились, и R300 не только изготовляется по 0,15 мкм техпроцессу, но также обладает полной совместимостью с DX9. Подобная совместимость означает то, что конвейер R300 работает с числами с плавающей запятой по всему своему протяжению, от начала до конца. Такая функциональность значительно увеличивает число транзисторов чипа. Не забывайте, что чип оснащен восемью конвейерами рендеринга, так что в R300 мы получаем 110 млн транзисторов. И хотя 110 млн это меньше, чем в NV30, это больше, чем в любом сегодняшнем видеочипе. Скажем, в Matrox Parhelia используется "всего" 80 млн транзисторов, причем чип изготовляется по тому же 0,15 мкм техпроцессу.Одна из проблем, связанных с таким большим количеством транзисторов на 0,15 мкм чипе связана с размером - чип имеет очень большой размер. В свою очередь это приводит к трудностям с упаковкой и к низкому проценту выхода годных кристаллов. Чип R300 несет более тысячи ножек, больше, чем в будущем процессоре AMD ClawHammer. Частично такое большое число ножек обусловлено переходом на 256-битную шину памяти. К тому же немалое число выводов отведено под подачу энергии на различные участки массивного чипа. Из-за такого числа ножек ATi впервые стала использовать FC-BGA упаковку для видеочипа.
Как видим, чип внешне очень напоминает современные процессоры типа Pentium 3, Pentium 4 (без распределителя тепла) или Athlon XP. Преимущества FC-BGA упаковки заключаются в возможности разводки более 1000 ножек, равно как и в улучшенном охлаждении, что определенно необходимо для такого огромного чипа, работающего на столь высоких тактовых частотах. Следующая проблема заключается в выходе годных кристаллов. Для сохранения конкурентоспособности R300 его тактовые частоты должны быть, по крайней мере, равны GeForce4. nVidia смогла достичь 300 МГц на своем 0,15 мкм техпроцессе, но их чип имеет всего 63 млн транзисторов. В R300 же число транзисторов почти в два раза больше, при этом ATi нацелилась на частоты выше 300 МГц.
В соответствие со словами одного из инженеров ATi, компания смогла достичь столь высоких тактовых частот (учитывая, что 3DLabs и Matrox не смогли заметно превзойти 200 МГц) по причине отличного подхода к дизайну чипа. Инженеры компании вручную проработали различные участки чипа для достижения приемлемых тактовых частот при нормальном проценте выхода годных кристаллов. ATi уже определилась с финальными значениями тактовых частот, у Radeon 9700 Pro частота работы ядра составляет 325 МГц.
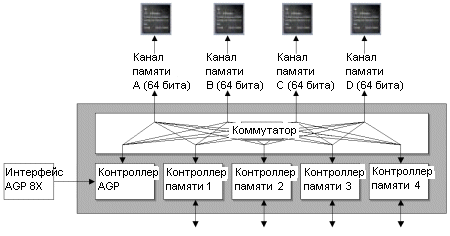
Как и Matrox Parhelia, R300 использует 256-битную DDR шину памяти, работающую с четырьмя раздельными 64-битными контроллерами памяти, почти как в перекрестной архитектуре памяти от nVidia. На Radeon 9700 Pro память работала на 325 МГц DDR (эффективное значение 620 МГц). ATi оговорила, что R300 может поддерживать DDR-II, но как мы думаем, для такой поддержки требуется некоторый редизайн контроллера памяти. Впрочем, мы еще поговорим о будущем R300 чуть позже...
Остальные спецификации R300 таковы:
Как видим, по сравнению с другими чипами R300 имеет впечатляющие технические спецификации. При количестве транзисторов от 100 до 110 миллионов (в разных документах ATi указывается разное значение), чип на 40 миллионов транзисторов больше GeForce4 Ti. Также на чипе присутствует четыре блока вершинных программ и восемь пиксельных конвейеров - в два раза больше флагмана nVidia. Однако последняя часть утверждения верна наполовину, поскольку пиксельные конвейеры R300 могут обрабатывать только одну текстуру за такт, по сравнению с двумя у GeForce4. Если говорить простым человеческим языком, то 9700 примерно в два раза быстрее GeForce4 при наложении одной текстуры. При использовании мультитекстурирования оба чипа примерно равны по скорости. По крайней мере, в теории. На практике же ни одна карта не может загрузить пиксельные конвейеры полностью - для 100% эффективности просто не хватает данных. Причина заключается в низкой пропускной способности памяти. Хотя она то у Radeon 9700 в два раза выше GeForce4 Ti. Трехмерный конвейер в R300Конвейер R300 на высоком уровне стандартен, но для поддержки будущих спецификаций DX9 ATi ввела некоторые улучшения в конвейер. Следует напомнить, что и R300, и NV30 будут совместимы с DX9, поэтому у них будет очень схожий конвейер.
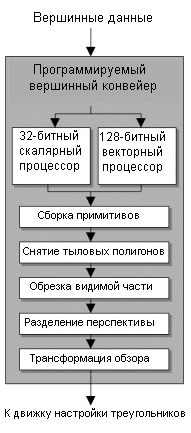
Мы постараемся вкратце пройти по каждой ступени конвейера, уделив особое внимание перспективам R300 и изменениям в конвейере, связанным с инновациями ATi. При возможности мы попытаемся провести аналогии с GeForce4 и с другими конкурирующими продуктами. AGP 8XПервая ступень 3D конвейера вполне очевидна и связана с отсылкой команд и данных для выполнения на графический чип. Инициатором отсылки является программное обеспечение, работающее на центральном процессоре. Данные и команды пересылаются по AGP шине и, в конце концов, достигают графического чипа.В R300 скорость передачи увеличена благодаря использованию интерфейса AGP 8X между видеочипом и северным мостом чипсета. Спецификация AGP 8X (AGP 3.0) предусматривает работу шины на 66 МГц с передачей восьми битов за такт. 32-битная шина AGP в режиме 8X обладает суммарной пропускной способностью 2,1 Гбайт/с. И хотя мы до сих пор вряд ли можем назвать ситуации, где бы жизненно необходима была даже AGP 4X, в увеличении скоростей передачи ничего плохого нет. R300 обратно совместим с AGP 4X, так что карту можно будет использовать в большинстве современных систем. GeForce4 и все конкурирующие решения сегодня основаны на интерфейсе AGP 4X, но к концу года мы наверняка увидим обновленные версии видеокарт с интерфейсом AGP 8X. ATi не была первой с AGP 8X картой, поскольку SiS уже стала пионером со своей Xabre. Однако не следует думать, что поддержка AGP 8X сразу же приведет к росту производительности. Обработка вершин - удвоенная скорость по сравнению с GeForce4Сейчас видепроцессор знает, какие данные ему нужны для обработки, и что с ними нужно сделать. Данные, посылаемые видеопроцессору, состоят из вершин полигонов, которые нужно отобразить на экране. Первую исполнительную ступень графического конвейера раньше часто называли T&L. На ней происходит трансформация вершинных данных, посланных графическому процессору, в 3D сцену. Ступень трансформации использует большое количество матричных вычислений с плавающей точкой. Затем происходит вычисление освещения для каждой из вершин. В программируемом видеопроцессоре начальный этап обработки вершин поддается программированию, то есть чип может запускать короткие вершинные программы (шейдеры), которые могут управлять различными характеристиками вершин для изменения формы, вида или поведения модели среди прочих вещей.
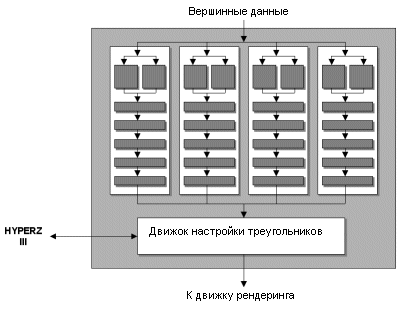
R300 использует четыре программируемых вершинных конвейера, почти как в Matrox Parhelia. Различие между R300 и Parhelia состоит в том, что R300 обладает намного более улучшенным движком настройки треугольников (triangle setup), поэтому если Parhelia и может похвастаться большими значениями пропускной способности вершин, то у нее в силу вступают ограничения движка настройки треугольников. Соответственно в играх с очень низким числом пропускаемых треугольников Parhelia не способна обогнать даже GeForce4 с меньшим числом вершинных конвейеров. Учитывая, что движок настройки треугольников у Parhelia не мощнее GeForce4, да и работает он на меньшей тактовой частоте, Parhelia не обладает достаточной мощью по обработке треугольников для загрузки своих вершинных конвейеров.
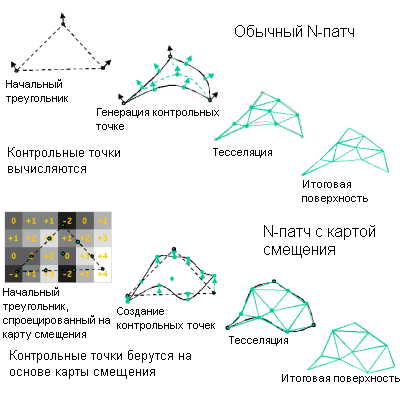
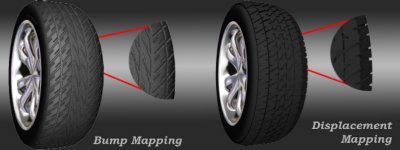
ATi решила данную проблему в R300, и чип способен обрабатывать более 300 млн треугольников в секунду (поскольку за такт обрабатывается одна вершина). Это более чем в два раза больше GeForce4 Ti 4600, что вполне логично, так как и число вершинных конвейеров у R300 тоже в два раза больше. Итак, мы видим первую область, в которой R300 демонстрирует свое превосходство. Здесь также работает технология ATi HyperZ, но мы рассмотрим ее отдельно чуть ниже. Поддержка вершинных программ 2.0R300 соответствует спецификации вершинных программ 2.0, что входит в Microsoft DX9. Параллельно с этим добавлена аппаратная поддержка карт смещения (Hardware Displacement Mapping). Как вы помните, эта технология была разработана Matrox и впервые она появилась в Parhelia. Хотя в настоящее время реальной надобности от нее нет, поскольку разработчикам требуется определенное время для ее применения.
ATi приводит хороший пример для демонстрации преимуществ карт смещения по сравнению с отображением неровностей dot3. Как вы можете наглядно увидеть, шина с картой смещений выглядит так, как будто бы она создана с помощью большей геометрии, однако на самом деле количество вершин не увеличивается.
Немаловажное преимущество спецификации 2.0 состоит в управлении потоком (flow control) и в увеличенном числе инструкций, которые могут быть выполнены за один проход. Управление потоком подразумевает, что вершинные программы сейчас могут содержать циклы, переходы и процедуры, что очень важно для обеспечения небольшого размера программ и их эффективности. Благодаря таким нововведениям можно избежать повторяющихся фрагментов кода, равно как и уменьшить число инструкций в программе. Преимущества управления потоком можно проиллюстрировать на следующем примере.
Без управления потоком программа будет выглядеть следующим образом. ...
С использованием же спецификации вершинных программ 2.0 тот же самый код можно уменьшить до двух строчек. for (x=0;x<5;x++)
Первая строчка инициализирует переменную X, увеличивает ее значение на 1 при каждом проходе цикла, а затем продолжает исполнять следующую команду до тех пор, пока значение X не станет равным 5.
Вершинные программы теперь могут состоять из 1024 инструкций (раньше было возможно только 128 инструкций), но это только теоретическое значение, поскольку циклы и переходы позволяют исполнять намного большее количество инструкций. Количество констант было увеличено до 256, и что важно, новые спецификации позволяют использовать цвет со 128-битной точностью (с плавающей точкой). Восемь пиксельных конвейеров рендеринга - эра DX9 начинаетсяОдна из причин лидерства nVidia заключается в том, что компания достаточно давно ввела архитектуру с четырьмя пиксельными конвейерами рендеринга. Это произошло в 1999 году, за два года до того, как ATi ввела четыре конвейера рендеринга в чипе R200 в августе 2001 года.
На сей раз, ATi оказалась первой компанией, оснастившей свой чип восемью 128-битными пиксельными конвейерами рендеринга с плавающей точкой. Довольно сильный шаг, учитывая, что в GeForce4 и Radeon 8500 используются четыре 64-битных пиксельных целочисленных конвейера рендеринга. Этим же можно объяснить и огромное число транзисторов в R300. ATi не только увеличила число пиксельных конвейеров рендеринга, но также удвоила точность и сделала переход к конвейеру, полностью работающему с числами с плавающей точкой для еще большего увеличения точности. Такой конвейер является обязательным требованием совместимости с DX9. Восемь конвейеров рендеринга дают R300 значительный отрыв по скорости заполнения от всех существующих карт, что также объясняет хорошую производительность R300. Скорость заполнения R300 на частоте 325 МГц равна 8*325 = 2600 Мпикселей/с. Каждый пиксельный конвейер рендеринга оснащен одним текстурным блоком, так что скорость заполнения при мультитекстурировании не будет отличаться. Может показаться, что один текстурный блок на конвейер - это слишком мало, но давайте посчитаем требования к пропускной способности памяти при существовании восьми параллельных конвейеров с одним текстурным блоком и обработке трилинейной 32-битной текстуры: 32 бита * 8 (трилинейная фильтрация требует чтения 8 текселей) * 8 (восемь конвейеров) = 2048 бит. То есть за один такт должно быть считано 2048 бит. Однако 256-битная DDR шина дает нам только 512 бит за такт. Даже билинейная фильтрация потребует 1024 бит за такт. Так что два текстурных блока на конвейер никогда не смогут получить достаточную пропускную способность памяти. Поэтому их и нет.
Каждый пиксельный конвейер Radeon 9700 Pro может независимо выполнять пиксельную программу. В соответствии со спецификацией пиксельных программ 2.0, они могут состоять из 160 инструкций. Каждая программа может осуществлять до 32 операций семплирования текстур с использованием до 16 различных текстурных карт и дополнительно 64 цветовые операции за проход. Количество тактов на проход, конечно же, может быть разным. Оно может достигать довольно больших значений, особенно при параллельном использовании анизотропной фильтрации. Полный переход к конвейеру с плавающей точкой позволит достичь 3D графике еще большей точности. Для подтверждения этого тезиса рассмотрим общий случай, когда число с плавающей точкой передается целочисленному конвейеру. Предположим, на целочисленный конвейер пересылается число 10.0523432543890, при этом оно округляется до целого. Если вы создаете какую-то примитивную картинку, то потеря точности никакой проблемы не создаст, однако если вам требуется фотореалистичное изображение, то подобные ошибки округления могут свести всю реалистичность на нет.
Так что в следующем году уже можно ожидать действительно реалистичных эффектов от ускорителей. Поддержка пиксельных программ 2.0R300 поддерживает спецификацию пиксельных программ Microsoft версии 2.0, что опять же включено в DX9. Во второй версии сделано множество улучшений, которые проиллюстрированы следующей таблицей.
Обратите внимание, что новая спецификация пиксельных программ поддерживает 16 текстурных входов. В результате мы получаем возможность накладывать 16 текстур за проход, что несколько отличается от шести в GeForce4 и Radeon 8500. Если посмотреть на использование такого количества входов на грядущих играх, то Doom3, к примеру, будет использовать пиксельные программы с пятью-шестью текстурными входами, которые R300 может выполнять за один проход. Однако следует отдать должное и некоторым DX8 решениям, которые смогут выполнять то же самое за один проход, так что у R300 есть еще место для более полного использования возможностей ускорителя. Спецификация пиксельных программ 2.0 также предусматривает более гибкие операции, увеличивающие программируемость чипа. R300 может выполнять до 160 пиксельных инструкций за проход, большее же число инструкций потребует нескольких проходов. На сегодняшний день подобная программируемость наиболее востребована в приложениях 3D рендеринга. На R300 (равно как и на других будущих DX9 ускорителях) можно будет компилировать и исполнять код (к примеру, код 3D Studio Max или RenderMan) на самом ускорителе. Сегодня рендеринг выполняется целиком центральным процессором, однако с должной программной поддержкой скорость рендеринга может быть увеличена.
Возможность обрабатывать 160 инструкций за проход крайне полезна в 3D рендеринге, поскольку самые сложные 3D вычисления сейчас можно выполнять за один проход. Согласитесь, намного интереснее высчитывать сцену в 3D Studio Max на скорости 0,1 fps, а не ждать, пока центральный процессор выведет один кадр за 10 минут. И вновь здесь возникает потребность в использовании конвейера с плавающей точкой, так что и R300, и NV30 будут поддерживать указанные нами функции. Одним из самых интересных применений такого конвейера является качественное освещение, которое жизненно необходимо для реалистичных сцен. На сегодняшний момент даже качественные 3D игры все еще далеки от реализма, и свою роль в этом играют не только текстуры с низким разрешением и малое число полигонов, но и недостатки освещения. Итак, конвейер с плавающей точкой позволяет улучшать точность освещения. На старом 32-битном целочисленном конвейере каждое значение RBGA ограничивалось 8-ю битами, или 256-ю различными значениями. Ниже вы видите очень сложную сцену, для которой мы желаем изменить яркость.
Проблема 256-ти различных цветов заключается в том, что при повышении яркости всех цветов в 64 раза, самые яркие цветовые участки сцены будут ограничены 8-битным представлением. В результате, несмотря на то, что общая яркость сцены повысилась, пропорциональное отношение яркости различных участков не сохранилось.
То же самое относится и к уменьшению яркости. Если мы уменьшим яркость в 64 раза, то все станет очень темным. Даже если все в комнате стало темным, то источники света не должны были стать настолько темными.
Теперь давайте взглянем на ту же сцену, но с использованием цветов с плавающей точкой для отражения большего диапазона уровней яркости.
Теперь вместо 256-ти значений на цвет, каждый цвет представлен, фактически, бесконечным числом оттенков, что дает действительно огромный динамический диапазон яркости. Постараемся объяснить это несколько более подробно. Как мы уже сказали, 32-битное представление цвета дает по восемь бит на каждый цветовой канал из трех, оставшиеся восемь бит расходуются на значение прозрачности альфа. Соответственно мы можем указывать значение каждого цвета от 0 до 255. Такой цвет не назовешь динамическим, поскольку он имеет всего 255 дискретных значений. С таким цветом уже давно борются разработчики, поскольку им нужен как очень темный цвет, так и очень светлый. Для таких цветов недостаточно значений от 1 до 255. В компьютерном мире существует два различных способа работы с числами. Легче всего, конечно же, понять целые числа, которые хранятся "как они есть". Числа с плавающей точкой представлены по-другому. В данном случае число состоит из бита знака, нескольких бит экспоненты и довольно много бит отводится под мантиссу. Формула числа получается x = m*2e , где x - число, m - мантисса, а e - экспонента. Как вы можете заметить, минимальное и максимальное число указывается с помощью экспоненты, в то время как мантисса определяет точность. В случае 128-битного числа с плавающей точкой, каждый цветовой канал имеет 32-битную точность и состоит из 1 бита знака, 8 бит экспоненты (7 бит плюс знак) и 23 бит мантиссы. В результате мы получаем числа диапазона от 0,00000000000000000000000000000000000000294 (=2-128) до 170 000 000 000 000 000 000 000 000 000 000 000 000 (=2127) . Учитывая 23-битную мантиссу, мы получаем большую точность, нежели 8 бит. Приведем также еще несколько наглядных примеров, показывающих превосходство цвета с повышенной точностью.
С левой стороны картинки вы видите сцену в 32-битном цвете, а справа вы можете заметить значительное увеличение качества в силу использования 128-битного цвета с плавающей точкой. ATi показала демонстрацию машины с низким числом полигонов, которая была улучшена с помощью dot3 с использованием 64-битной карты нормалей. Такое качество попросту было недостижимым при использовании 32-битных карт нормалей.
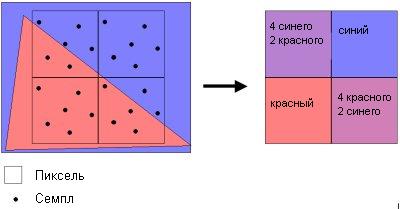
К сожалению, 128-битный цвет требует в четыре раза большую пропускную способность, нежели 32-битный цвет. К счастью, пропускная способность памяти уже давно к этому готовилась. Остается добавить, что DX9 также поддерживает технологию нескольких целей рендеринга (Multiple Render Targets, MTR), которая позволяет назначать несколько объектов на сцене для пиксельной программы. Подобный метод будет крайне полезен для сложных пиксельных программ. То есть вместо прогона программы для каждого объекта сцены, можно использовать MRT для сокращения числа прогонов. SmoothVision 2.0 - мультисемплингКогда только вышел Radeon 8500, нас очень разочаровало сглаживание SmoothVision, базировавшееся на алгоритме суперсемплинга, в то время как nVidia уже начала использовать алгоритм мультисемплинга.Мы уже объясняли раньше алгоритм суперсемплинга ATI (RGSS), который создает несколько копий сцены и сдвигает их на некоторое расстояние относительно центра. Затем эти копии накладываются друг на друга для получения окончательной картинки. Такой подход приводит к великолепному разрешению текстур и в то же время он позволяет избавиться от "лесенок", однако он очень сильно ударяет по производительности, поскольку нужно отрисовывать сцену несколько раз. Мультисемплинг, с другой стороны, работает на основе значений Z (глубина) для каждого пикселя. В зависимости от степени покрытия каждого пикселя вычисляется усредненное значение между цветами заднего и переднего участков, которое затем и используется. Преимущество такого подхода заключается в том, что вам не нужно создавать несколько копий сцены, зато при этом теряется разрешение текстур, и производятся дополнительные обращения к Z-буферу. Алгоритм мультисемплинга R300 отличается от алгоритма nVidia, поскольку семплы саб-пикселей здесь другие. Ниже показан фрагмент при 6x сглаживании ATi.
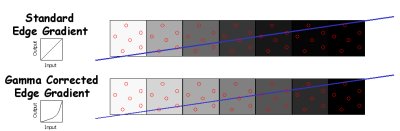
Кроме того, SmoothVision 2.0 поддерживает еще одну функцию - патентованный алгоритм гамма-коррекции, который обеспечивает точность передачи цветовых градиентов при сглаживании. Многие мониторы имеют нелинейный градиент гаммы, что учитывается алгоритмом коррекции ATi.
Нам посчастливилось посмотреть на демонстрацию колеса со спицами на Radeon 9700 Pro и параллельно на GeForce4, причем обе карты работали с 4X сглаживанием. На Radeon 9700 Pro колесо выглядело на порядок лучше.
R300 поддерживает и суперсемплинг и мультисемплинг (R200 поддерживал только суперсемплинг), однако в драйверах вы можете выбрать только мультисемплинг. Впрочем, это может измениться к моменту выхода карты. Как мы уже упомянули выше, мультисемплинг увеличивает число обращений к Z-буферу, но поскольку R300 использует сжатие Z, эти обращения не сильно съедают пропускную способность. В технической документации ATi указывает степень сжатия на уровне 50-75% благодаря использованию HyperZ III. У нас не было много времени для доскональной оценки алгоритма сглаживания ATi, но как заявляет компания, он будет обладать лучшим качеством, нежели алгоритм nVidia, в ситуациях, где используются прозрачные текстуры. Лучшим примером может служить уровень DM-Antalus в UT2003, где великолепная трава является ничем иным, как текстурой с высоким разрешением и прозрачностью, в результате чего вы можете видеть сквозь нее. Как считает ATi, алгоритм мультисемплинг-сглаживания от nVidia будет попросту игнорировать "лесенки" по краям этого полигона в силу их прозрачности, а R300 не будет. Через несколько недель мы постараемся более подробно рассмотреть эту ситуацию в отдельной статье.
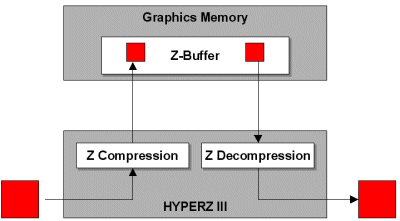
Исправленная анизотропная фильтрацияВ R300 исправлена еще одна проблема, досаждающая в R200 и связанная с анизотропной фильтрацией. В Radeon 8500 ATi ввела алгоритм адаптивной анизотропной фильтрации, который определяет число семплов, которое нужно отфильтровать на основе положения семпла по осям X и Y по отношению к пользователю. В результате в ситуациях, где необходим максимальный уровень анизотропии, ускоритель берет максимальное количество семплов, указанное в драйвере (16X максимум).Единственная проблема с алгоритмом ATi заключается в отсутствии обработки поворотов по осям X, Y и Z. В большинстве случаев при повороте вдоль оси Z чип будет применять минимальный метод фильтрации - билинейный, который не слишком то хорошо выглядит. R300 не только поддерживает трилинейную фильтрацию вместе с анизотропной, но также в нем была исправлена ошибка с Z-поворотом. Мы уже давно подстрекаем nVidia к применению такой же формы анизотропной фильтрации, поскольку различия в качестве картинок между адаптивным алгоритмом ATi и подходом nVidia пренебрежимо малы в большинстве случаев, зато алгоритм ATi наносит меньший урон по производительности. В соответствии с данными ATi, производительность R300 не будет падать вообще при включении билинейной и 16X анизотропной фильтрации, и лишь небольшое падение производительности будет наблюдаться при включении трилинейной фильтрации. Отметим, что раньше nVidia жаловалась на то, что при включении анизотропной фильтрации ATi берет билинейные семплы, а nVidia - трилинейные, съедающие в два раза большую пропускную способность памяти. Сейчас же у Radeon 9700 Pro появилась возможность включить либо "производительную" анизотропную фильтрацию (с билинейной), либо "качественную" (с трилинейной). Так что nVidia будет довольна. HyperZ IIIATi стала первой компанией, внедрившей технологию отсечения невидимых полигонов, которую они назвали HyperZ. В R300 используется третье поколение HyperZ, которая отличается от HyperZ II ускоренными версиями всех трех компонент.ATi не слишком подробно указывает улучшения HyperZ III, поэтому, как нам кажется, HyperZ III работает быстрее по причине более высокой тактовой частоты R300, внедрением "ранней Z" (объяснено чуть ниже) и, возможно, увеличением числа пикселей, которые компонента "иерархия-Z" может отбрасывать в один момент времени. Вкратце напомним состав и функциональность HyperZ III: Технология ATi HyperZ состоит из трех функциональных компонент, работающих совместно друг с другом для оптимизации использования пропускной способности памяти. Три компоненты - это Иерархия-Z (Hierarchical-Z), Z-сжатие (Z-Compression) и быстрая Z-очистка (Fast Z-Clear). Ниже мы рассмотрим каждую из этих компонент, равно как и их влияние на производительность. Следует также напомнить, что HyperZ разделяет кадровый буфер и Z-буфер на блоки 8x8 пикселей, с которыми намного более удобно работать. Сейчас давайте вспомним некоторые основы традиционного 3D рендеринга. Z-буфер - это часть памяти, которая отводится под хранение значений координаты Z выводимых пикселей. Значения Z определяют, какой пиксель, и какой полигон будут выведены перед другими на экране. Традиционный 3D ускоритель обрабатывает каждый принятый полигон, без учета его положения относительно сцены. Следовательно, каждый выводимый полигон будет освещен и текстурирован. Z-буфер, как мы уже упоминали, используется для хранения значения глубины каждого пикселя в "заднем" буфере. Каждый пиксель каждого полигона должен быть проверен через Z буфер на предмет того, находится ли он ближе к наблюдателю, чем другой пиксель, уже хранящийся в буфере. Проверка Z-буфера должна быть проведена уже после того, как пиксель будет освещен и текстурирован. Если пиксель должен выводиться перед существующим пикселем, то новый пиксель замещает (или смешивается, при условии прозрачности) текущий пиксель в "заднем" буфере, а глубина Z-буфера для данного пикселя изменяется. Если новый пиксель выводится позади текущего пикселя, то новый пиксель отбрасывается и никаких изменений "заднего" буфера не происходит (или опять же происходит смешение двух пикселей). Если подобные бесполезные пиксели все же будут выводиться на экран, то такой дефект называется "перерисовкой" (overdraw). Скажем, в некоторых ситуациях типичной является перерисовка трех пикселей. Как только сцена заполнится, "задний" буфер переносится в "передний" буфер для вывода на монитор. Только что мы описали способ, известный как "прямое отображение" (immediate mode rendering), подобный способ используется со времен 60-х годов для рендеринга в системах CAD, архитектурных программах, приложениях по созданию спецэффектов и сегодня - в большинстве видеоускорителей. К сожалению, такой метод приводит к большому проценту перерисовки, когда обрабатываются даже невидимые объекты.
И хотя R300 не использует мозаичный рендеринг, он все же применяет некоторые методы отложенного рендеринга для увеличения использования пропускной способности памяти. Из приведенного выше примера вы можете легко догадаться о том количестве обращений к Z-буферу, которые требуются для вывода одной сцены. ATi HyperZ увеличивает эффективность этих обращений, так что вместо предотвращения корня проблемы (перерисовки), ATi уменьшает негативные последствия - частые обращения к Z-буферу. Первой компонентой HyperZ является Иерархия-Z, которая позволяет ускорителю проверять Z-буфер для данного пикселя еще до того, как пиксель попадает на конвейер рендеринга. В результате ненужные пиксели отбрасываются на ранней стадии, перед тем, как R300 начнет их обрабатывать. В R300 добавлена технология "ранняя-Z" (Early-Z), которая подразделяет Z-буфер на уровне пикселей, так что карта достигает близкой к 100% эффективности при отбрасывании перекрытых пикселей. Иерархия-Z использует флаг для каждого из 8x8 блоков Z-буфера. Флаг содержит минимальное значение Z, из всех значений Z данного блока. Затем значение Z пикселя, поступившего из движка настройки треугольников, сравнивается со значением флага данного блока. Если значение Z поступившего пикселя меньше значения флага, то пиксель отбрасывается, и блок не читается из Z-буфера в кэш. Если же значение Z у пикселя больше значения блока, то блок считывается из Z-буфера в кэш, по пути проходя через Z-декомпрессию.
Затем следует Z-сжатие. Как говорит название, потери данных при этом не происходит. Z-сжатие компрессирует значение Z у пикселей блока с коэффициентом от 2:1 до 4:1 перед передачей блоков в Z-буфер, что заметно экономит пропускную способность памяти.
Последняя компонента HyperZ - быстрая Z-очистка, которая позволяет быстро очищать Z-буфер после полного отображения сцены. Кстати, метод очистки Z-буфера у ATi значительно быстрее методов конкурентов. Быстрая Z-очистка изменяет только лишь флаг для каждого блока, ускоряя процесс очистки.
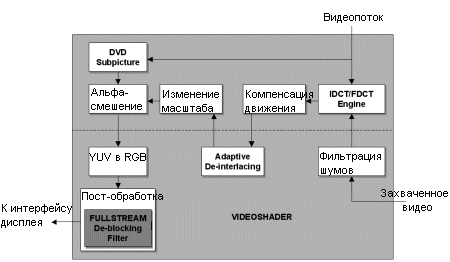
Как мы уже упоминали выше, технология ATi HyperZ III как нельзя более полезна при улучшении производительности сглаживания по причине Z-сжатия. В случае 6X сглаживания сжатие Z (равно как и сжатие цвета) может достигать значения 1:24. Обработка видео через 3D конвейерЕще одной впечатляющей возможностью R300 является обработка видеопотока через 3D конвейер вместо стандартного пропускания через DAC. Благодаря такой способности не только отпадает необходимость проигрывать видео через оверлей, но появляется возможность выводить на экран несколько видеопотоков.Как и в RV250, R300 поддерживает технологию FULLSTREAM.
Возможность запускать пиксельные программы при выводе видеопотока (Videoshader) открывает новые возможности, и ATi FULLSTREAM является одной из реализаций данной технологии. При должной программной поддержке (на сегодня это только RealPlayer), FULLSTREAM поможет устранить артефакты высоких степеней сжатия на потоках с низким битрейтом. Как видим, после обработки получается несколько размытая картинка, зато блоков уже почти не заметно.
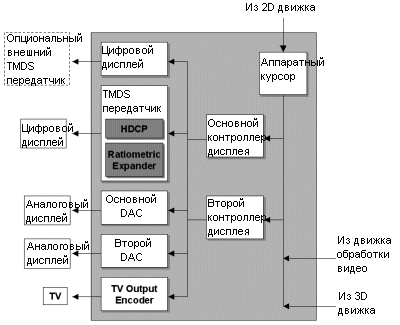
Как видим, использование пиксельных программ позволяет карте выполнять великое множество функций без специального видеочипа. Мы еще более подробно остановимся на функциях R300 и нового чипа ATi Rage Theater осенью, когда ATi выпустит R300 версию All-in-Wonder Radeon. Выход на дисплеиВ Parhelia Matrox уже реализовала цветовую точность 10/10/10 бит, которая позволит получить более качественные цвета на выходе. Обычный 32-битный цвет использует только 24 бита для цветовой информации, в то время как оставшиеся 8 бит не используются для вывода на ЭЛТ или ЖК монитор. Radeon 9700 Pro также может использовать 10 бит точности на каждый цветовой канал, что дает 1024 различных уровня красного, зеленого и синего вместо 256 уровней. От этого выиграют, прежде всего, аналоговые устройства вывода, а вот как к дополнительным двум битам отнесутся ЖК мониторы пока что предположить трудно.Итак, Radeon 9700 Pro оснащен двумя встроенными 400 МГц RAMDAC с 10-ю битами на канал для вывода на ЭЛТ и одним встроенным 165 МГц TMDS передатчиком для ЖК мониторов. Встроенный ТВ-выход поддерживает форматы NTSC/PAL/SECAM с разрешением вплоть до 1024x768.
Карта - Radeon 9700 ProКогда ATi сообщила, что первые платы с R300 будут называться Radeon 9700 Pro, мы сразу же поинтересовались - а выйдет ли обычный Radeon 9700? И хотя сама ATi не будет производить эту плату, партнеры компании выпустят варианты с более низкими тактовыми частотами, которые и будут называться Radeon 9700. Мы точно не знаем, но предполагаем что-то типа 300/300 МГц.Давайте теперь перейдем от чипа R300 к карте Radeon 9700.
К сожалению, Radeon 9700 несет только один DVI порт и один VGA порт. Поддержка двух мониторов реализуется через технологию Hydravision, включенную в ядро. Если вам нужно два DVI выхода, то вам придется подождать FireGL версии карты (FireGL X1). ATi выполнила свои обещания насчет тактовой частоты в 325 МГц и $399 - именно такими характеристиками обладает Radeon 9700 Pro. Частота памяти составит 310 МГц (эффективное значение - 620 МГц).
Карта изготовлена ATi на плате с красным текстолитом. Сзади вы можете заметить небольшой распределитель тепла.
Схема питания R300 разбита на две части. Справа вы видите разъем питания как у флоппи-дисководов для подачи дополнительного питания. На плате есть специальный разъем для подключения питания, поскольку карта потребляет больше мощности, чем позволяет спецификация AGP 3.0. ATi будет поставлять в комплекте переходник для использования больших вилок питания.
Унифицированная архитектура драйверовКогда ATi представила Radeon 8500, компания обещала произвести переход к унифицированной архитектуре драйверов (UDA) точно так же, как nVidia. Но после разговоров с одним из инженеров ATi мы узнали, что DirectX драйверы R300 являются абсолютно новыми.То есть они не основаны на DX драйверах Radeon 8500, что означает отсутствие унифицированной архитектуры драйверов, поскольку ускоритель следующего поколения не использует код от драйверов ускорителя предыдущего поколения. Преимущество такого подхода заключается в исправлении ряда проблем, имевшихся у ATi в прошлом. Но существует и ряд недостатков. Скажем, все те ошибки, что были исправлены в старых драйверах, могут вновь выплыть в новых. ATi убедила нас, что DirectX драйверы R300 станут основой для унифицированной архитектуры драйверов чипов следующего поколения. Посмотрим, получится ли у ATi на этот раз. У драйверов ATi всегда существовали какие-либо недостатки, и, к сожалению, с выходом R300 ситуация сильно не изменилась. С одной стороны, мы не встретили каких-либо проблем с производительностью, совместимостью или качеством картинки с текущей версией драйверов. Карта и драйверы прекрасно прошли через все тесты. С другой стороны, очевидно, что огромные усилия программистов были затрачены на переработку драйверов R300, так что мы надеемся, что в играх не возникнет проблем, хотя в это достаточно трудно поверить. В любом случае, ставки ATi с R300 слишком велики, чтобы позволять драйверам сдерживать продвижение чипа. С Radeon 9700 Pro поставляются WHQL сертифицированные драйверы на основе платформы CATALYST 2.2. Драйверы внешне похожи на другие версии CATALYST, однако здесь есть два явных отличия, специфичных для R300. Во-первых, были убраны настройки сглаживания по отношению качество/производительность, поскольку R300 стал поддерживать сглаживание по методу мультисемплинга. Вы можете выбрать 2X, 4X или 6X сглаживание. Во-вторых, была добавлена возможность указания качества или производительности для анизотропной фильтрации. Режим производительности, по всей видимости, идентичен подобному режиму на Radeon 8500 (исключая поддержку трилинейной фильтрации), в то время как режим качества правильно обрабатывает ситуации с поворотом вдоль оси Z.
Тестирование AnandtechКак уже было сказано выше, Radeon 9700 Pro ощутимо быстрее всех карт, поэтому мы ограничим сравнительное тестирование только одной GeForce4 Ti 4600.Из-за близкой цены Parhelia-512 мы хотели и ее включить в тестирование, однако с последним билдом UT2003 и последней версией драйверов Parhelia мы не смогли завершить тестирование. Поскольку большинство тестов Anandtech завязаны именно на UT2003, Parhelia была опущена.
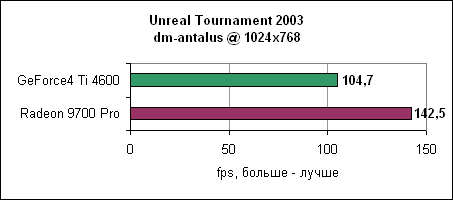
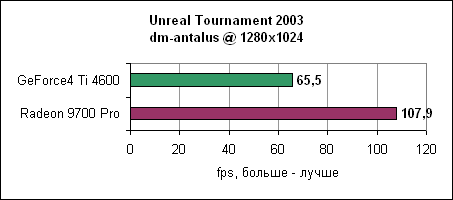
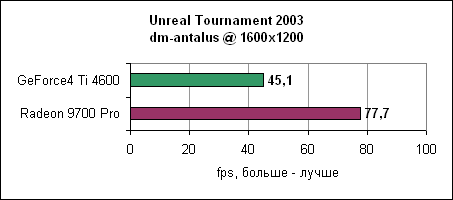
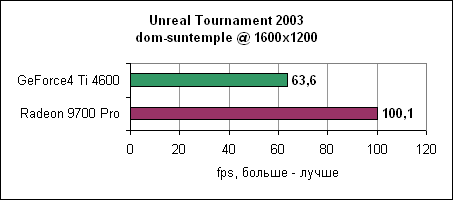
Unreal Tournament 2003Epic поставила нам новый билд движка UT2003, на котором были добавлены несколько уровней. В этом тесте мы посмотрим на большее количество уровней, один из которых даже более интенсивен, чем предыдущий рекордсмен - antalus.
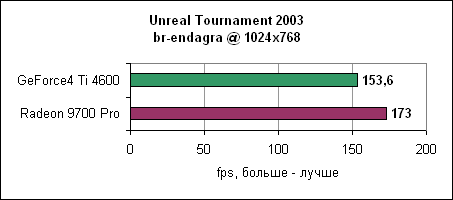
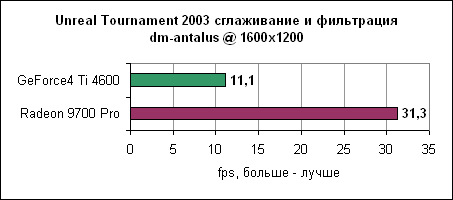
9700 опережает GeForce4 Ti 4600 на 30-70% в зависимости от разрешения.
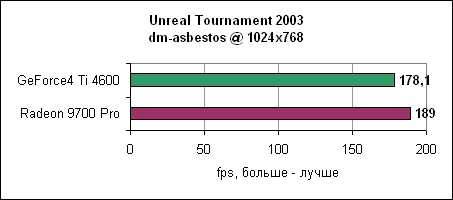
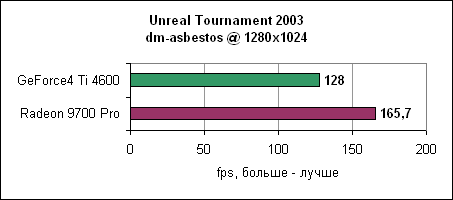
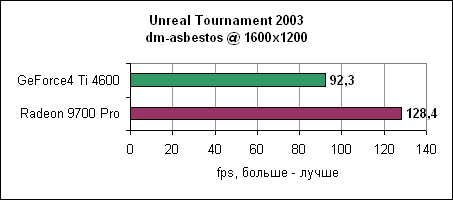
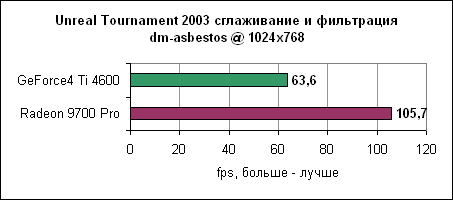
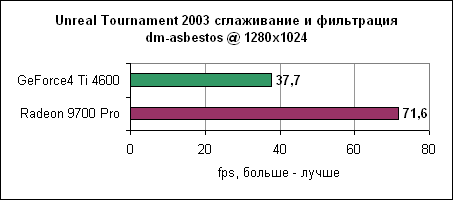
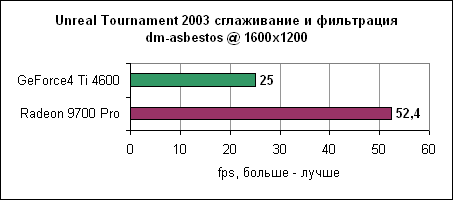
Уровень asbestos сильнее привязан к процессору, поэтому здесь Ti 4600 подобралась в пределах 6% к Radeon 9700 на 1024x768. Наибольшая разница в производительности наблюдается в 1600x1200 - менее 40%. Мы продолжаем тестировать UT2003 в режимах "захват флага" и bombing run.
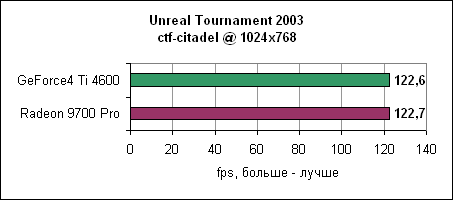
Две карты показывают практически одинаковую скорость в 1024x768, что показывает хорошую отлаженность драйверов nVidia. В 1600x1200 Radeon 9700 Pro смог оторваться на 33%.
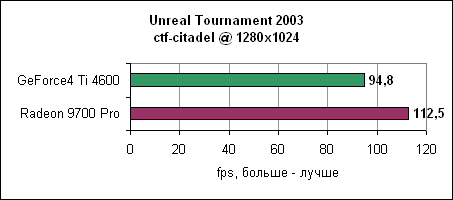
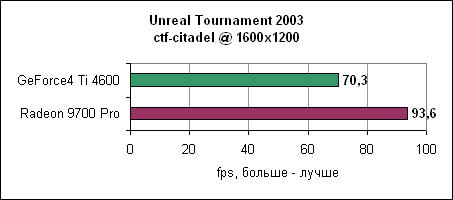
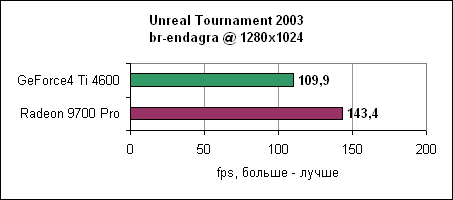
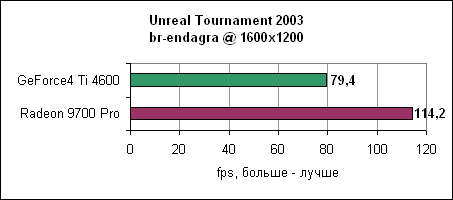
В 1024x768 мы наблюдаем 173 fps у Radeon, и даже в 1600x1200 карта показывает 110 fps, на 43% быстрее Ti 4600. Давайте посмотрим еще на один deathmatch уровень и на уровень double domination.
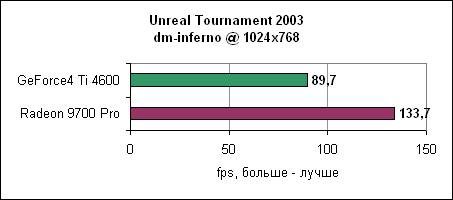
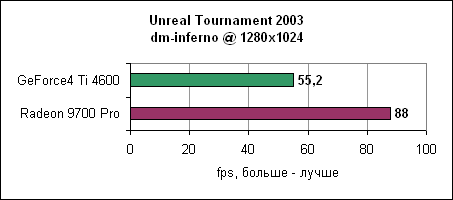
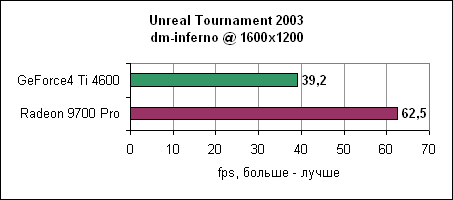
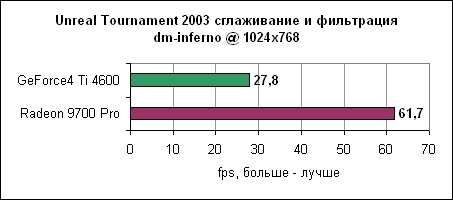
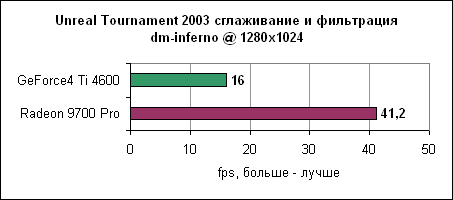
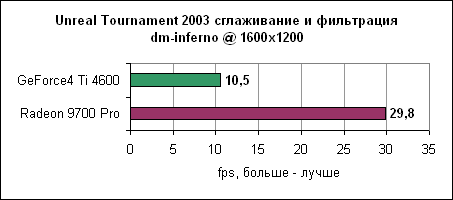
Inferno, как видим, еще более нагружает карту, чем antalus. Radeon 9700 нас вновь не разочаровывает и показывает 50-60% отрыв от Ti 4600.
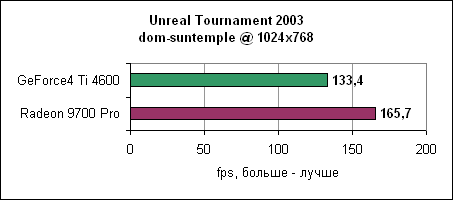
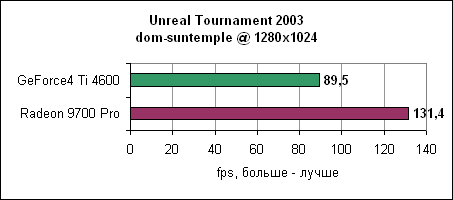
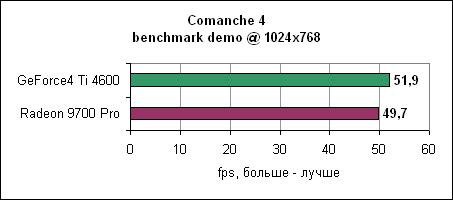
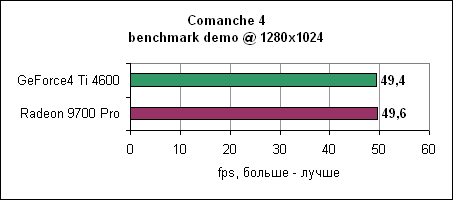
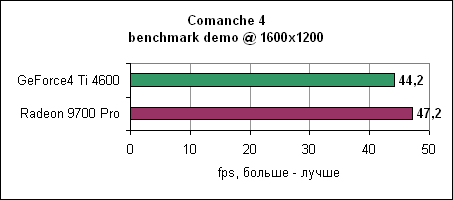
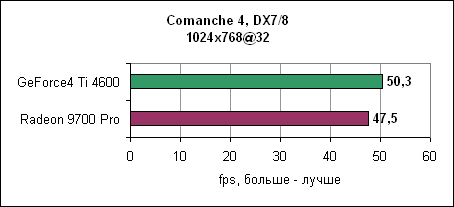
В последнем тесте UT200 тенденция продолжается - Radeon 9700 Pro отрывается на 24-59% в зависимости от разрешения. Comanche 4Летные симуляторы обычно редко используются в тестировании, поскольку они больше привязаны к процессору и платформе, но для полноты мы решили включить и Comanche 4. Мы использовали публично доступную демо игры.
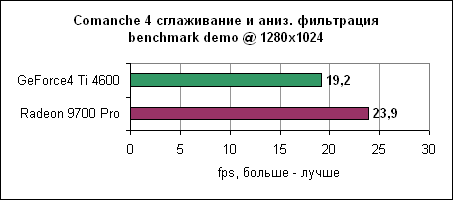
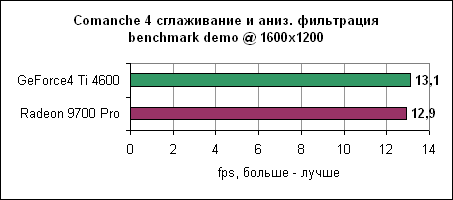
Довольно удивительно, но здесь Radeon 9700 Pro оказался чуть медленнее Ti 4600. Объяснение очевидно - Comanche 4 сильно привязан к процессору, поэтому менее мощная GeForce4 смогла выйти на дюйм вперед.
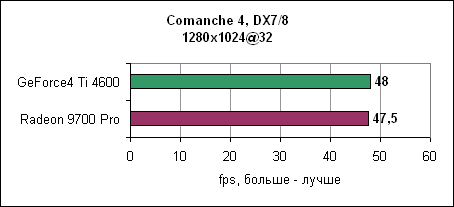
Практически равные результаты на 1280x1024.
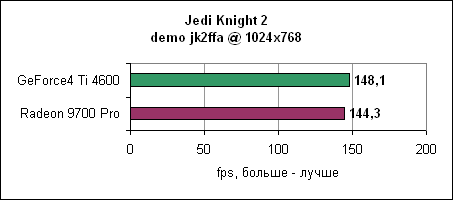
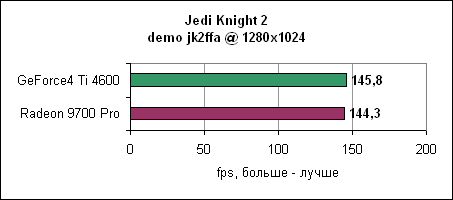
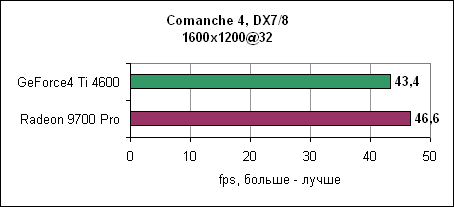
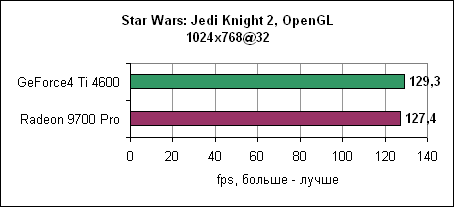
Ну и, наконец, в 1600x1200 Radeon 9700 Pro выходит вперед, но ненамного. Впрочем, обеих карт будет вполне достаточно для нормальной игры в Comanche 4. Jedi Knight 2Игра основывается на движке Quake III, причем она также сильно привязана к процессору. После результатов Comanche 4 вы знаете, чего здесь следует ожидать.
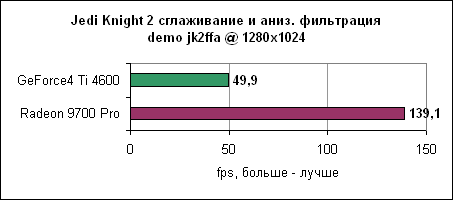
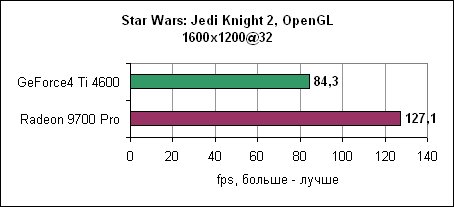
И вновь Radeon 9700 Pro чуть медленнее GeForce4 Ti 4600.
ATI пока не может изменить картину...
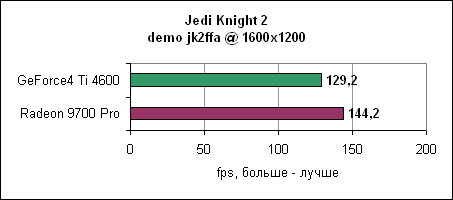
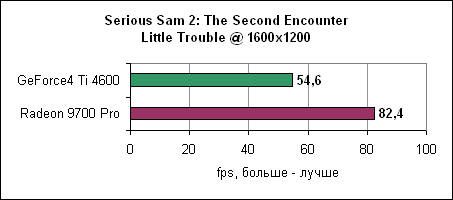
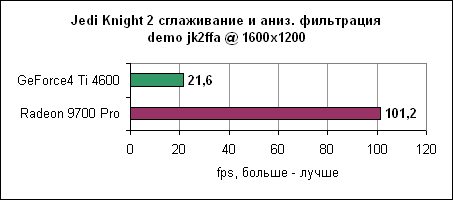
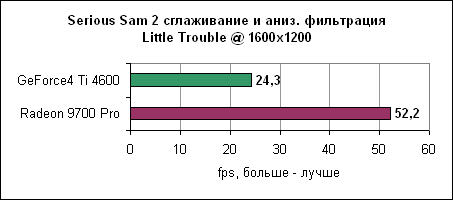
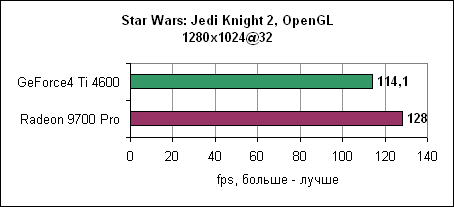
И, наконец, в 1600x1200 увеличенная пропускная способность памяти дает себя знать - Radeon 9700 Pro отрывается на 12%. Serious Sam 2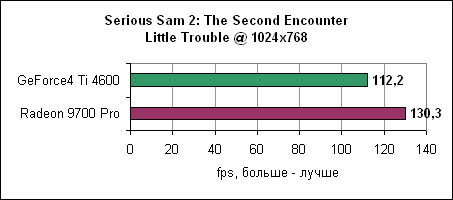
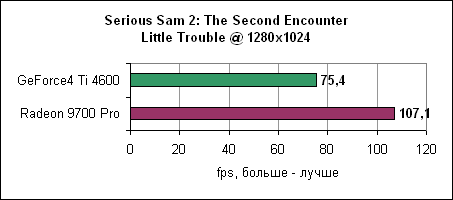
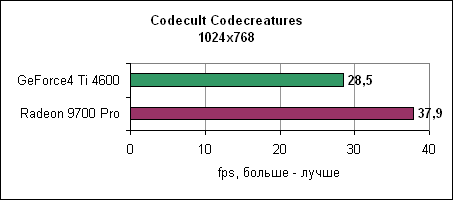
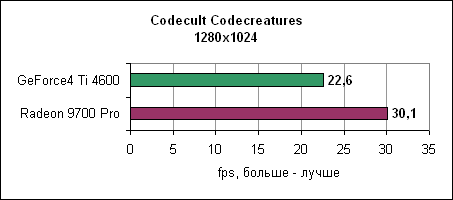
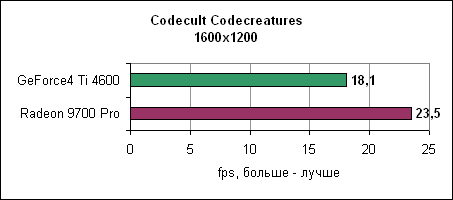
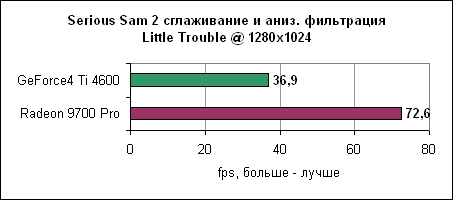
Тест Codecreatures DirectX 8.1Движок Codecult Codecreatures представляет собой довольно интересный DirectX 8.1 тест. Поскольку движок не слишком широко используется, тест находится ближе к синтетическому, однако все же интересно взглянуть на его результаты. Они показывают, как карты себя ведут под интенсивным DirectX 8.1 приложением.
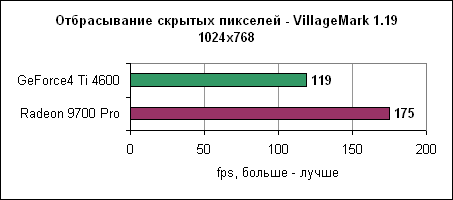
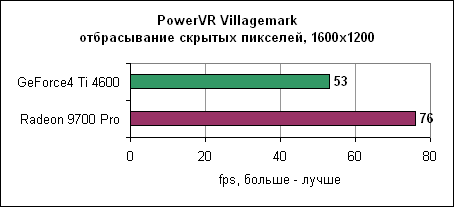
Radeon 9700 Pro на 30% обгоняет Ti 4600. Контроллер памяти и синтетические тестыATi стала первой компанией, которая ввела технологию отбрасывания перекрытых пикселей на ранних ступенях конвейера. Для проверки мы использовали Villagemark, где крайне велика избыточная прорисовка объектов.
По ряду причин Radeon 9700 Pro показывает здесь 47% отрыв, но немалую долю сюда вносит HyperZ III. nVidia сможет достойно на это ответить лишь с NV30 в конце года. Поскольку Radeon 9700 Pro имеет только один текстурный блок на конвейер, скорость заполнения при мультитекстурировании практически идентична GeForce4 Ti 4600. Что более важно, здесь заметны преимущества Radeon 9700 Pro в пропускной способности полигонов и в тесте пиксельных программ. Качество анизотропной фильтрацииКак мы объясняли выше, ядро R300 имеет несколько отличный от Radeon 8500 движок анизотропной фильтрации, с исправленными ошибками. Давайте посмотрим на качество.
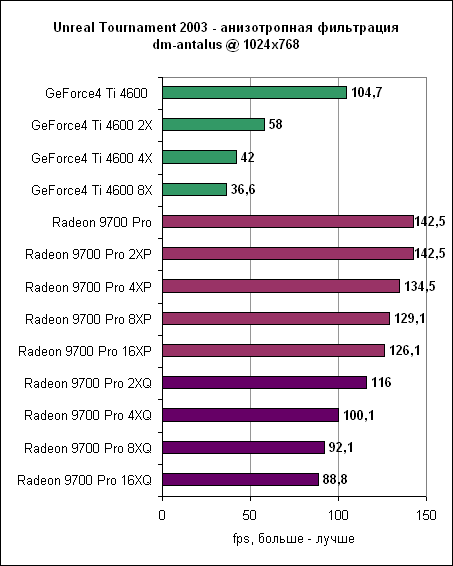
Важно заметить, что в большинстве случаев (равно как и в показанном здесь) вы вряд ли сможете выделить какие-либо отличия между установками анизотропной фильтрации ATi на качество и производительность. Как видим, ATi 16X обеспечивает качество, сравнимое с nVidia 8X. Помните, что ATi использует адаптивный алгоритм фильтрации, который не всегда использует максимальное количество семплов, что позволяет Radeon 9700 Pro обеспечивать схожее качество картинки с меньшим ущербом производительности. Давайте обратимся к цифрам. Производительность анизотропной фильтрацииДля измерения производительности анизотропной фильтрации был вновь использован UT2003 на уровне antalus.
Здесь сразу же видны преимущества алгоритма адаптивной фильтрации ATi. Конечно, он не безупречен, однако его плюсы явно перевешивают минусы. Качество сглаживанияВ R300 ATi, наконец-то, ввела сглаживание по алгоритму мультисемплинга. Давайте сравним его с алгоритмом мультисемплинга GeForce4.
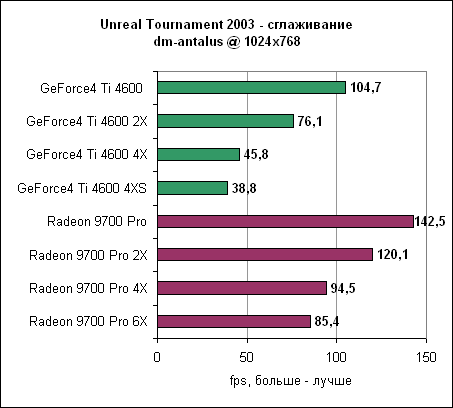
Вряд ли вы сможете найти различия между двумя картами по качеству сглаживания. И там и там картинка прекрасна, особенно при сравнимой установке 4X. Производительность сглаживанияИспользовался тот же самый тест, что и при измерении скорости анизотропной фильтрации.
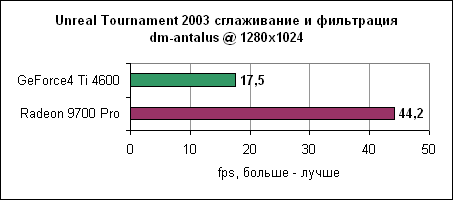
Как видим, переход к мультисемплингу заметно помог ATi - в большинстве игры вы сможете нормально использовать даже 6X режим. Сглаживание и анизотропная фильтрация - Unreal Tournament 2003Так ли хорош Radeon 9700 Pro, если он заметно преуспевает только в 1600x1200? Если ваши мониторы пока не готовы к такому разрешению, то Radeon 9700 Pro обеспечивает иной вариант - вместо повышения разрешения, установите его в 1024x768, но включите дополнительные функции. Не правда ли, от карты за $399 можно ожидать нормальных скоростей в 4X сглаживании с 16X анизотропной фильтрацией? Давайте посмотрим.Мы запускали несколько тестов со следующими настройками Radeon 9700 Pro:
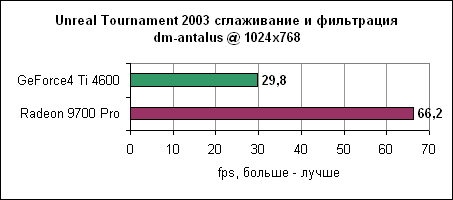
Если на высоких разрешениях вы вряд ли сможете играть, в 1024x768 при сглаживании и анизотропной фильтрации частота кадров хороша. Даже в этом, достаточно тяжелом тесте.
Как вы помните, на уровне dm-asbestos Ti 4600 показывала сравнимые с Radeon 9700 Pro результаты, однако все изменилось. Ti 4600 ощутимо тормозит.
Та же тенденция. Сглаживание и анизотропная фильтрация - Comanche 4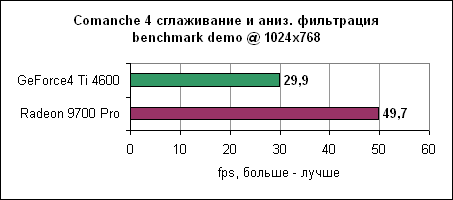
Данный тест очень сильно привязан к процессору, однако посмотрите на отрыв Radeon 9700 Pro в 1024x768. На высоких разрешениях играют роль другие узкие места. Сглаживание и анизотропная фильтрация - Jedi Knight 2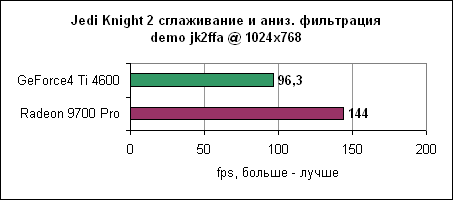
Еще один привязанный к процессору тест. Radeon 9700 Pro вновь демонстрирует свою силу. Сглаживание и анизотропная фильтрация - Serious Sam 2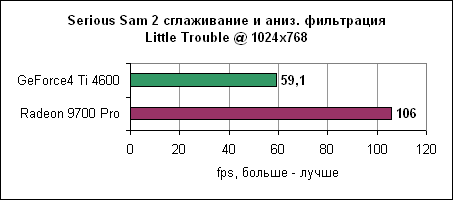
То же самое. Масштабирование процессоровКак обычно, мы завершаем тестирование ATi Radeon 9700 Pro привычным сравнением по масштабируемости.Целью в данном тестировании было выявить скорость карт только лишь от тактовой частоты процессоров, не учитывая размер кэша, архитектуру или частоту FSB. Для этого мы взяли Athlon XP 2100+ и изменяли у него коэффициент умножения. Частота шины по-прежнему составляла 133 МГц, множитель же изменялся от 6X (800 МГц) до 13X. И хотя данный метод приводил к необычным комбинациями частот, он прекрасно подошел. Конечно, 800 МГц Athlon XP на 133 МГц FSB не следует соотносить с обычным 800 МГц Athlon XP, однако представление о производительности вы получите.
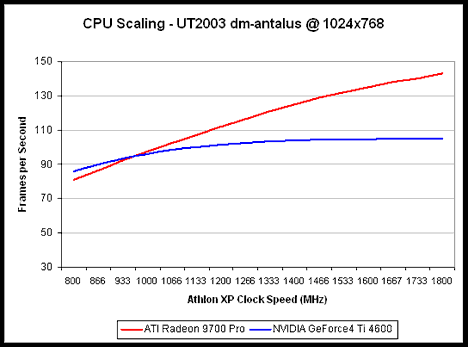
До отметки 933 МГц Ti 4600 оказывается быстрее Radeon 9700 Pro, так что не стоит оснащать медленные процессор Radeon 9700 Pro. Однако при достижении отметки 1,33-1,4 ГГц 9700 Pro явно выходит вперед.
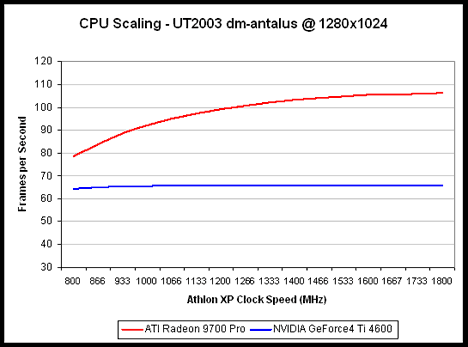
На высоких разрешениях ATi Radeon 9700 оказывается быстрее при любом процессоре. Тестирование Tom’s Hardware GuideВ качестве тестовой мы выбрали платформу на базе Pentium 4 2,53 ГГц, поскольку пользователи, у которых найдется лишних $300 на видеокарту, наверняка обладают и самой быстрой платформой и памятью.Впрочем, мы также провели тесты по масштабируемости процессора, в которых участвовали платформы на базе Pentium 4 1,6 ГГц и Pentium III 800 МГц.
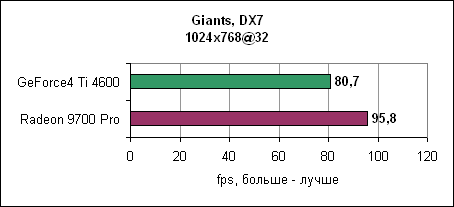
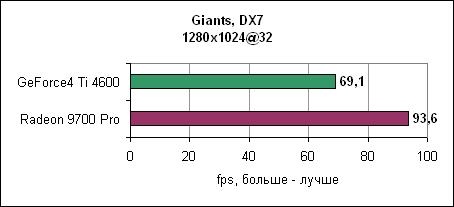
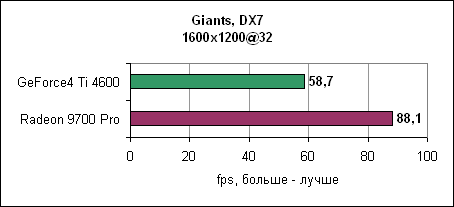
Тесты можно подразделить на несколько групп. Во-первых, можно выделить типичные игровые тесты. Затем следуют синтетические тесты, которые измеряют игровую производительность (3DMark2001 SE), потом - теоретические тесты, которые измеряют специфические параметры типа пропускной способности треугольников и скорость заполнения. Наконец, мы проверим качество картинки при использовании анизотропной фильтрации и сглаживания. GiantsGiants - это DirectX 7 игра, использующая текстуры среднего размера. Игровой движок поддерживает аппаратный T&L и достаточно сильно использует мощь акселератора, даже по сравнению с современными играми.
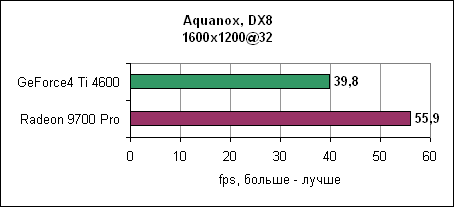
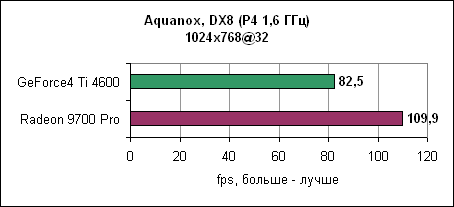
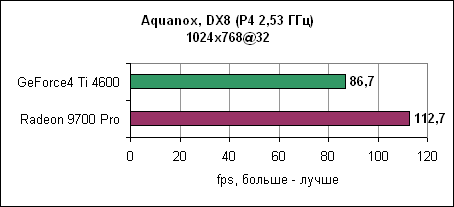
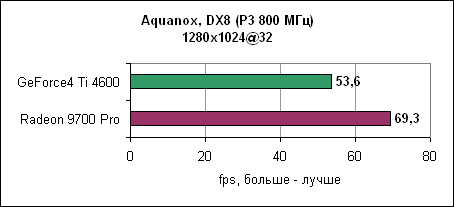
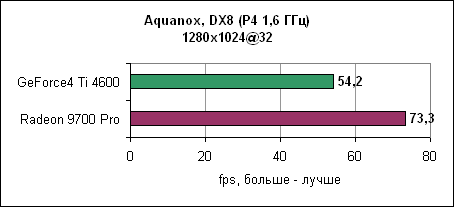
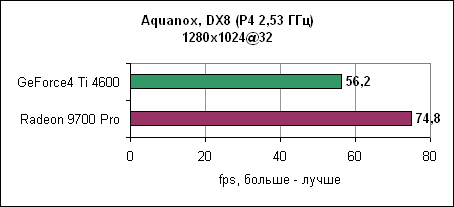
Radeon 9700 Pro оставляет GeForce4 Ti позади. Разница растет при повышении разрешения. AquanoxAquanox использует технологии DirectX 8. Производительность здесь определяется силой блоков вершинных программ.
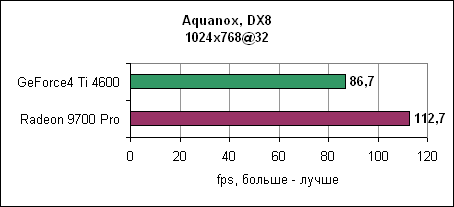
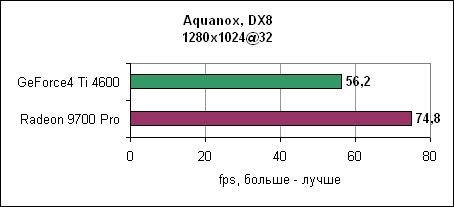
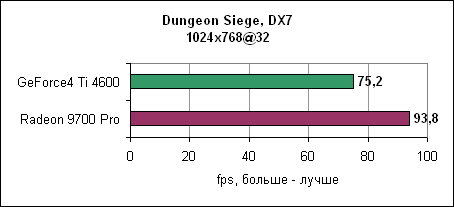
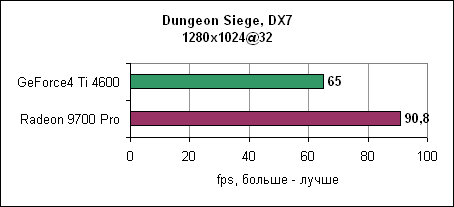
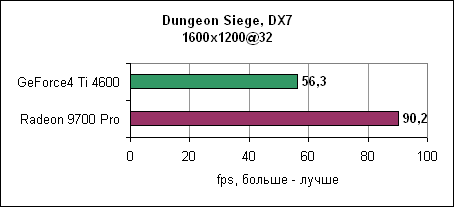
И снова nVidia повержена Radeon 9700 Pro. В 1280x1024 GeForce4 уходит за магическую границу в 60 fps, в то время как Radeon 9700 Pro держится до разрешения 1600x1200. Dungeon SiegeDungeon Siege - это ролевая игра, основанная на DirectX 7 движке. В игре используется процедура, автоматически определяющая видеокарту и соответственно устанавливающая уровень детализации. Если карта не распознана, то движок выставляет самые низкокачественные установки. ATi послала нам обновленный файл конфигурации игры, который вносит Radeon 9000 и Radeon 9700 в список поддерживаемых карт. nVidia GeForce4 уже там содержится. Каждая карта работает с настройками по умолчанию.
Результат потрясающ. Если производительность GeForce4 падает при увеличении разрешения, то Radeon 9700 уверенно держится на всех разрешениях. Comanche 4Comanche 4 построена на технологии DirectX 8, игра активно использует пиксельные и вершинные программы. Однако она слишком привязана к процессору, так что даже на быстрых процессорах различия между картами нивелируются. Игра является больше тестом общей производительности системы, нежели только одной видеокарты. Так что покупка новой видеокарты при тормозной системе вам ничего не даст.
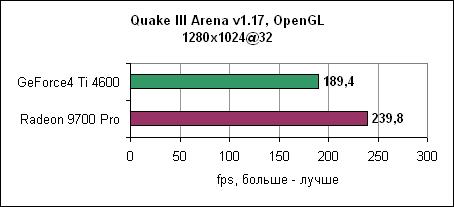
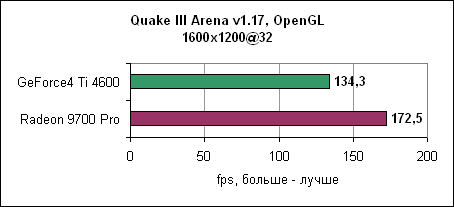
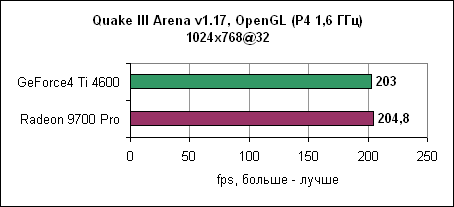
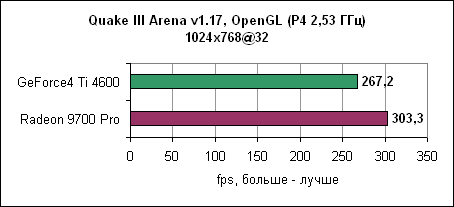
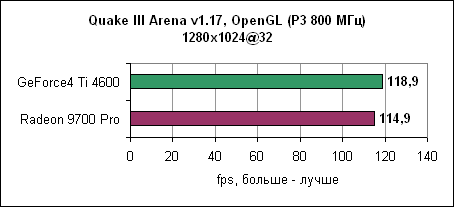
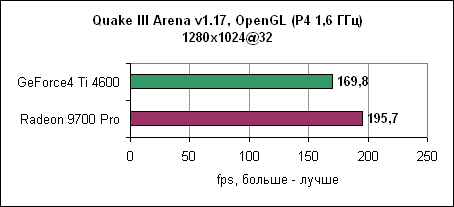
При низком разрешении GeForce4 Ti смогла немножко выйти вперед. Quake IIIДвижок Quake III уже устарел, однако игра до сих пор очень популярна. Обновленная версия движка используется в некоторых современных играх. В любом случае, данная OpenGL игра до сих пор является стандартом в тестах по определению чистой OpenGL производительности.
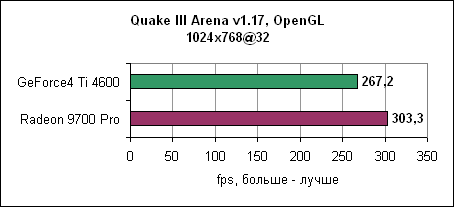
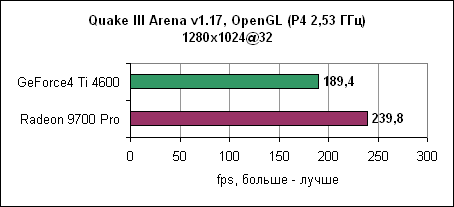
Radeon 9700 Pro смог преодолеть барьер в 300 fps при разрешении 1024x768 при максимальном качестве. Лидерство ATi сохранилось и на других разрешениях. Jedi Knight IIJedi Knight II основан на обновленном движке Quake III. Игра использует текстуры с высоким разрешением и более сложные 3D модели.
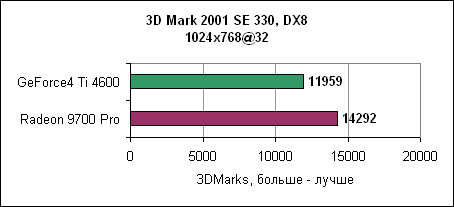
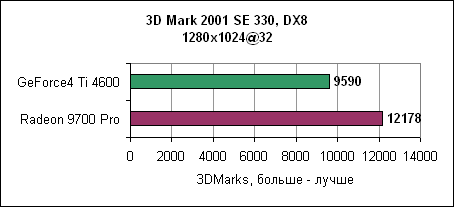
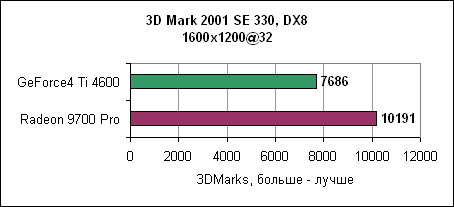
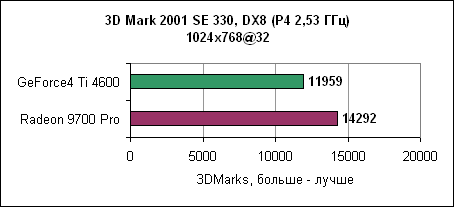
В 1024x768 обе карты показывают примерно равный результат. Игра очень сильно привязана к процессору. При увеличении разрешения мы наблюдаем все больший отрыв карт ATi. Падение производительности при переходе к 1600x1200 ничтожно. 3DMark 2001 SEНесмотря на синтетический характер теста, его результаты хорошо показывают производительность 3D карт.
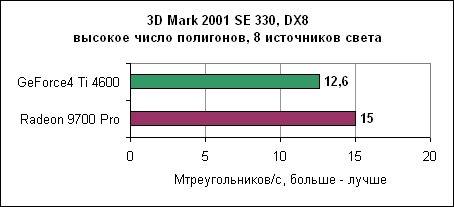
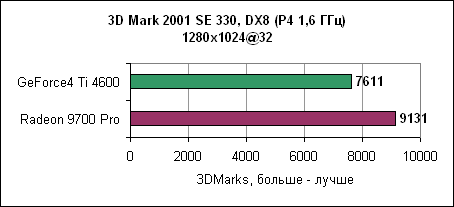
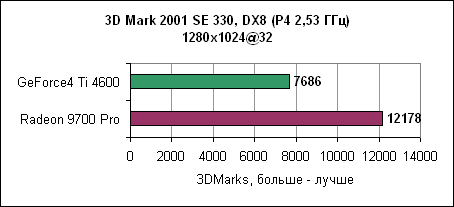
Отрыв Radeon 9700 Pro впечатляет. 3D производительность в деталяхНа производительность карты в играх влияет множество факторов. Если игра использует большие текстуры, то основное значение здесь имеет скорость заполнения. Если сложные 3D модели - то критичным является пропускная способность треугольников. И, наконец, немаловажна производительность пиксельных и вершинных программ. Детализованные тесты позволяют достаточно аккуратно сравнить производительность Radeon 9700 Pro и GeForce4 Ti4600.Пропускная способность треугольниковВ современных играх число треугольников, из которых состоит 3D модель, постоянно увеличивается. Примерами могут служить гонки с тщательно прорисованными моделями или внешние уровни со множеством растений и т.д.3DMark 2001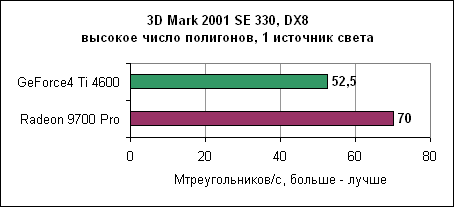
В данном тесте Radeon 9700 явно обгоняет GeForce4 Ti, как с дополнительными источниками света (восемь источников), так и в простом варианте. BenMark 5Данный тест был разработан nVidia для демонстрации T&L производительности карты.
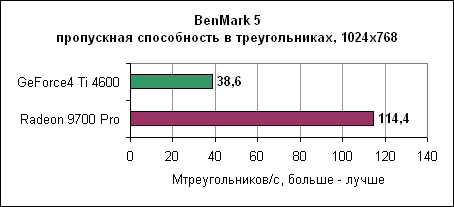
Здесь Radeon 9700 Pro в три раза обгоняет GeForce4 Ti - несмотря на то, что он обладает "всего" в два раза большим числом блоков вершинных программ. Похоже, блоки Radeon более эффективны.
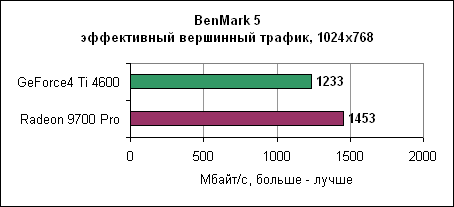
Тест измеряет данные, передающиеся по шине. И вновь Radeon 9700 здесь выходит немного вперед. Radeon 9700 Pro - явный победитель в категории максимальной пропускной способности треугольников. GeForce4 Ti и рядом не находится. Скорость заполненияСкорость заполнения показывает, насколько быстро пиксельные конвейеры могут обрабатывать текстуры. Ниже приведены детализованные результаты 3DMark2001 SE.
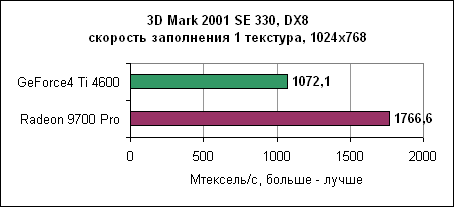
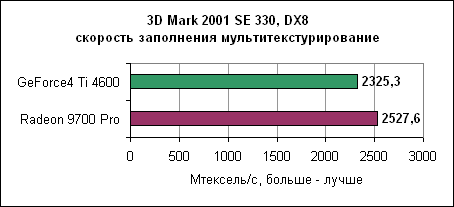
Здесь показана производительность при использовании только одной текстуры. Мы сразу видим преимущество восьми пиксельных конвейеров Radeon 9700 Pro. nVidia GeForce4 обладает только лишь четырьмя конвейерами, поэтому она находится позади.
В тесте мультитекстурирования (две текстуры на объект, к примеру, накладываются при использовании карт освещения) мы видим, что восемь пиксельных конвейеров ATi не всегда хороши, поскольку каждый конвейер может обработать только одну текстуру за такт. Конвейеры GeForce4 могут обрабатывать по две текстуры, поэтому производительность карт почти одинакова. К сожалению для ATi, большинство современных игр активно используют мультитекстурирование. По результатам скорости заполнения получаются спорные выводы. Восемь пиксельных конвейеров ATi не всегда так уж и эффективны, особенно при мультитекстурировании. Однако, как покажет следующий тест пиксельных программ, восемь конвейеров - вещь все же полезная. Пиксельные программыСейчас давайте сравним производительность пиксельных программ у обеих карт.
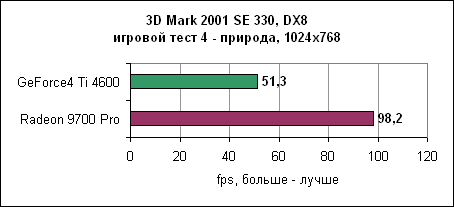
Сцена природы - один из игровых тестов. Здесь Radeon 9700 почти в два раза быстрее Ti4600.
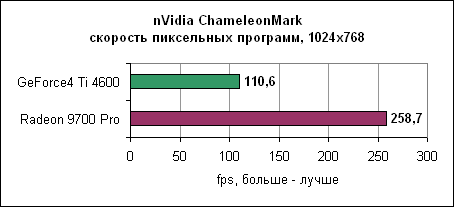
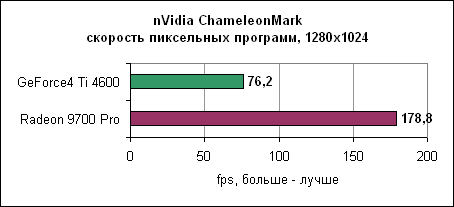
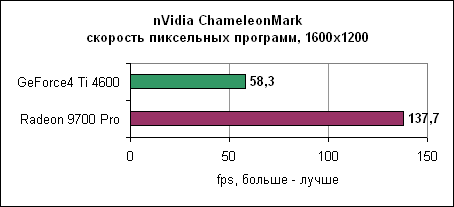
Radeon доминирует во всех тестах пиксельных программ. nVidia ChameleonMarkПоследний тест пиксельных программ в нашем репертуаре от nVidia. ChameleonMark создан для демонстрации производительности пиксельных программ линейки GeForce3.
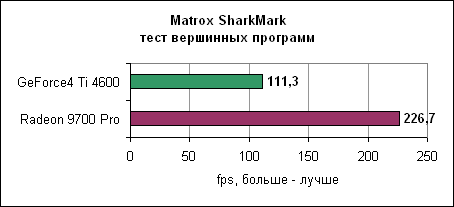
Результаты вновь потрясающи. Radeon 9700 Pro работает в три раза быстрее GeForce4. Архитектура ATi с восемью пиксельными конвейерами здесь показывает свои мускулы во всей красе. Производительность пиксельных программ Radeon практически в два раза выше GeForce4, что неудивительно, ведь Radeon имеет в два раза больше пиксельных конвейеров. Тесты вершинных программВершинные программы отвечают за расчет геометрии сцены. Radeon 9700 Pro использует четыре блока вершинных программ, в два раза больше, чем у nVidia GeForce4.3DMark 2001 SE 330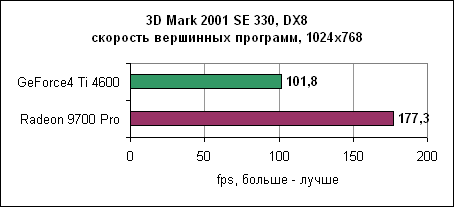 Как и предполагалось, здесь лидирует Radeon. Matrox SharkMarkSharkMark разработана Matrox и выпущена во время анонса новых карт Parhelia. Тест работает в окне в определенном разрешении.
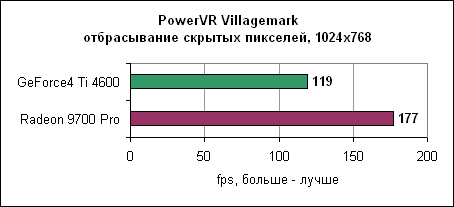
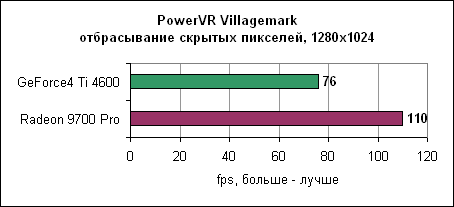
И вновь здесь лидирует Radeon 9700 Pro. Radeon явно доминирует в тестах вершинных программ. Однако сами по себе блоки вершинных программ у Radeon 9700 не быстрее блоков nVidia. Отбрасывание скрытых пикселейКак вы помните, технологии отбрасывания скрытых пикселей позволяют ускорить вывод 3D сцен. Если какой-либо объект на сцене перекрыт другим объектом, то ускорителю вряд ли необходимо отрисовывать первый объект (конечно же, если объект переднего плана не полупрозрачен). Как nVidia, так и ATi выработали свои технологии отбрасывания невидимых пикселей.PowerVR VillagemarkВ Villagemark PowerVR попыталась создать тест по проверке алгоритмов отбрасывания невидимых пикселей. По идее тест должен был демонстрировать преимущество мозаичной архитектуры рендеринга линейки Kyro.
Результат говорит сам за себя. Если даже Radeon 9700 обладает более высокой пропускной способностью треугольников, технология Hyper-Z тоже себя неплохо показывает. Производительность сглаживанияСледуя за nVidia, ATi реализовала более быстрый алгоритм сглаживания мультисемплинга. Давайте посмотрим, какую производительность нам следует ожидать в OpenGL и DirectX играх.3DMark 2001 SE 300 - сглаживание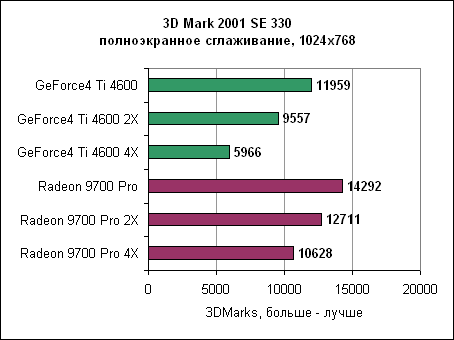
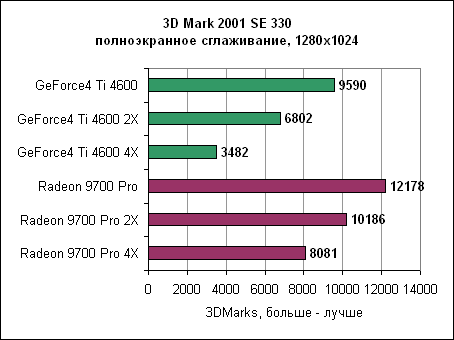
Radeon явно получает преимущество от своей пропускной способности памяти. Даже при 2X FSAA он быстрее GeForce4 вообще без сглаживания. При включении 2X или 4X сглаживания он обеспечивает почти в два раза большую производительность по сравнению с GeForce4. 3DMark 2001 SE 300 - сглаживание, Dragothic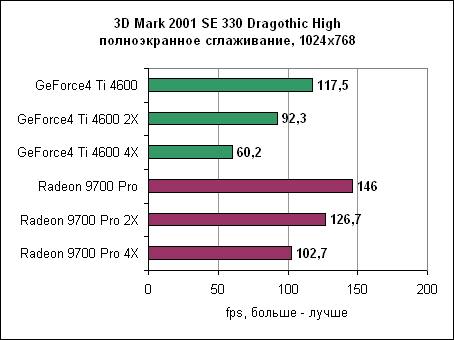
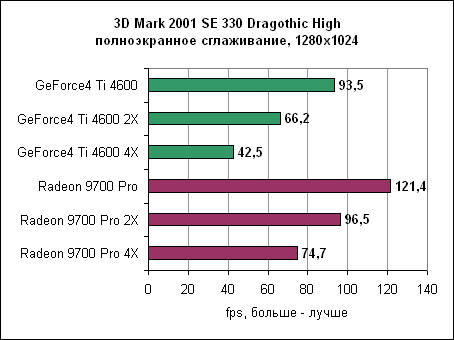
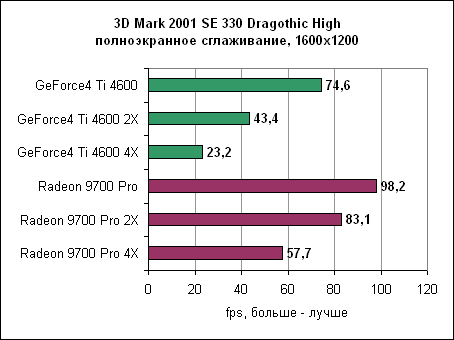
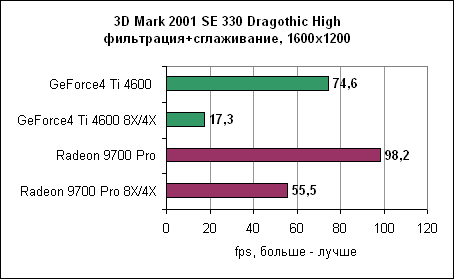
В Dragothic Radeon вновь показывает свое превосходство. Quake 3 - сглаживание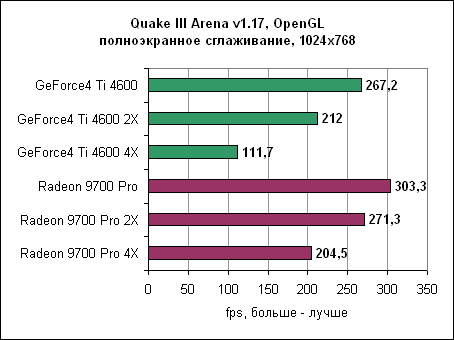
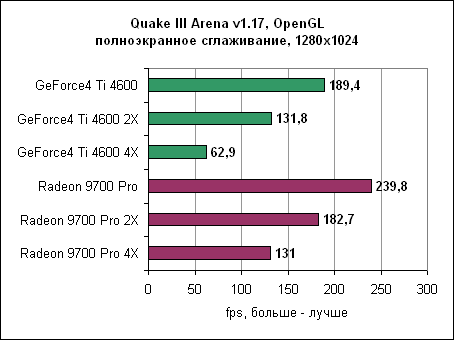
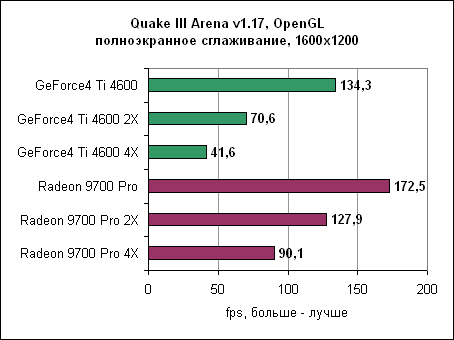
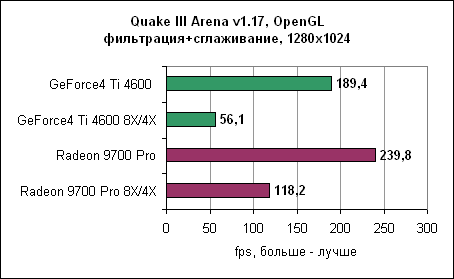
И вновь с включенным сглаживанием Radeon достигает производительности GeForce4 без сглаживания вообще. Если обе карты перевести в режим сглаживания 4XFSAA, то ATi оказывается почти в два раза быстрее карты от nVidia. Так что при включении сглаживания ATi Radeon 9700 Pro явно дает понять, кто в доме хозяин. Производительность карты при включении сглаживания оказывается практически в два раза выше GeForce4 Ti 4600. И даже при включении сглаживания 2X ATi Radeon 9700 Pro обычно быстрее nVidia Ti 4600 без сглаживания. Анизотропная фильтрацияАнизотропная фильтрация - это технология, позволяющая текстурам выглядеть намного четче и рельефнее при отображении их под небольшим углом. Radeon 9700 позволяет использовать анизотропную фильтрацию с билинейным или трилинейным фильтрами. nVidia, с другой стороны, позволяет включать только трилинейный фильтр, который обеспечивает лучшее качество в ущерб производительности. Обе карты будут выставлены в уровень фильтрации 8X.Реализация анизотропной фильтрации от ATi имеет несколько хитростей, уменьшающих нагрузку на процессор и увеличивающих производительность. К примеру, карта изменяет уровень фильтрации в зависимости от угла, под которым просматривается плоскость. Это, в принципе, неплохая идея, поскольку меньшие (следовательно, быстрые) уровни фильтрации обычно бывают достаточны при небольших углах. Конечно, nVidia пошла своим путем, и сейчас идут оживленные споры - чей же способ лучше. Сейчас мы можем найти разницу между двумя методами, только лишь сняв скриншоты и пройдясь по ним с увеличительным стеклом. В играх пользователи вряд ли заметят какую-либо разницу. И вновь хорошие результаты Radeon в тестах объясняются наличием восьми пиксельных конвейеров. 3DMark 2001 SE 330 - анизотропная фильтрация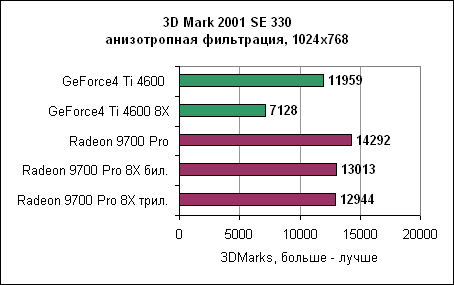
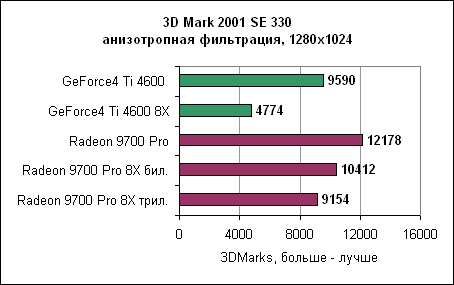
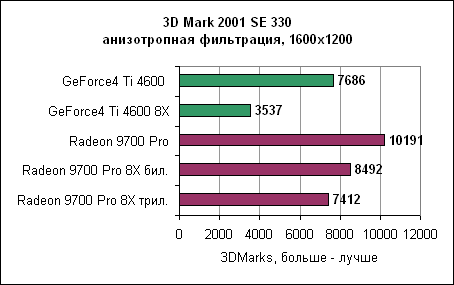
Анизотропная фильтрация ATi оказывается эффективнее. Конечно же, немалую роль в этом играют восемь пиксельных конвейеров. 3DMark 2001 SE 330, Dragothic - анизотропная фильтрация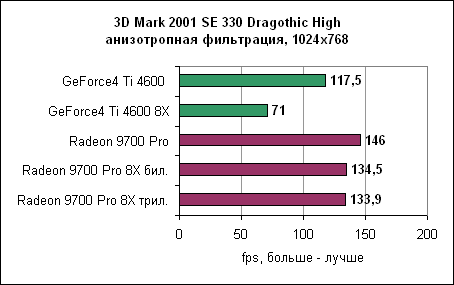
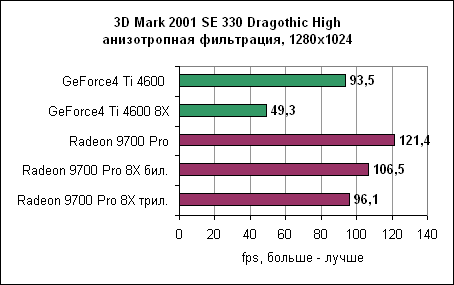
Детализованные результаты Dragothic показывают, как сильно падает производительность GeForce4 при включении анизотропной фильтрации. Для сравнения, включение анизотропной фильтрации на Radeon очень слабо влияет на производительность. Quake III - анизотропная фильтрация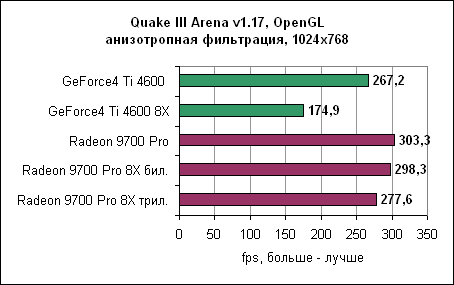
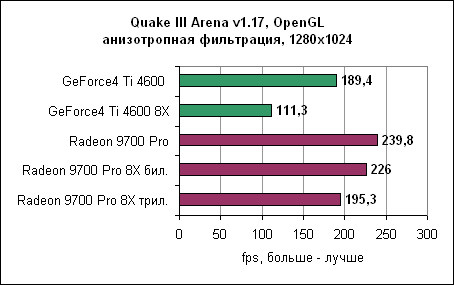
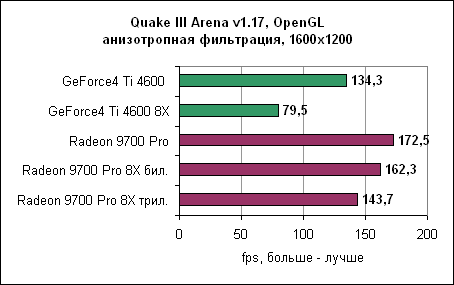
Radeon превосходен в OpenGL. Однако в текущих драйверах Catalyst есть ошибка. Изменение качества фильтрации с билинейной на трилинейную (или наоборот) в меню драйверов ни на что не влияет. Во время тестирования мы устанавливали фильтрацию вручную, изменяя соответствующий ключ реестра. Анизотропная фильтрация ATi явно эффективнее по производительности. Несмотря на то, что nVidia фильтрует всю сцену, используя самый "честный" метод, по качеству очень трудно отличить картинку от ATi и nVidia. Следует признать, что в одном-двух случаях алгоритм ATi ошибался в выборе уровня фильтрации из-за ужасного угла просмотра, но лучшая производительность легко перевешивает редко возникающие ошибки. Ведь вы можете выкрутить настройки фильтрации в 16X и по-прежнему получать большую частоту кадров, чем у nVidia. Возможно, ATi следовало бы включить в драйвер опциональную возможность наложения полной анизотропной фильтрации на всю сцену, тогда все бы были довольны. Максимальное качество - анизотропная фильтрация и полноэкранное сглаживаниеНаконец, мы переходим к самому "тяжелому" тесту, с которым не всегда справляются даже самые крутые карты. Наша цель - получить максимально возможное качество, включив как анизотропную фильтрацию, так и сглаживание.3DMark 2001 SE - сглаживание и анизотропная фильтрация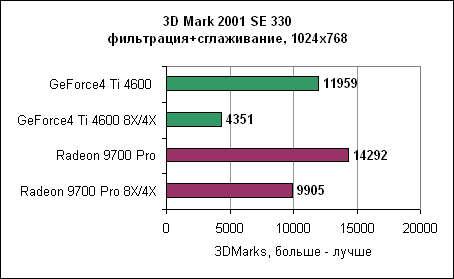
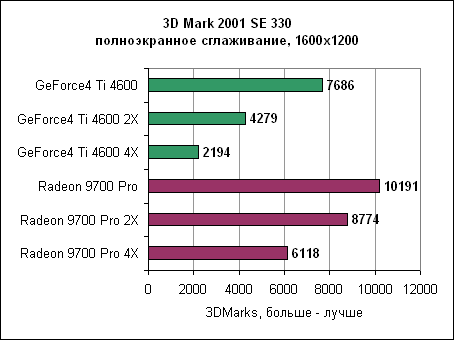
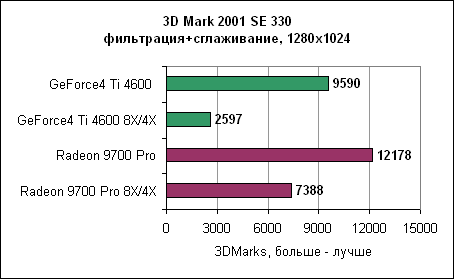
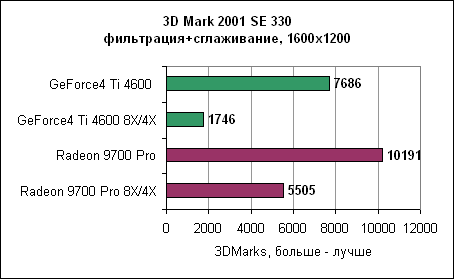
Как показывают результаты, GeForce4 находится далеко позади. В разрешении 1600x1200 Radeon 9700 почти в три раза быстрее. 3DMark 2001 SE Dragothic High - сглаживание и анизотропная фильтрация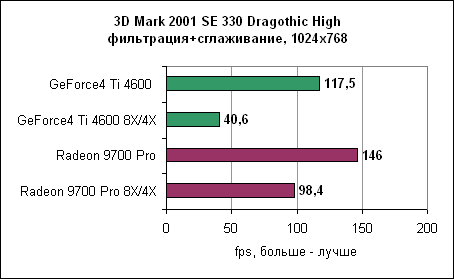
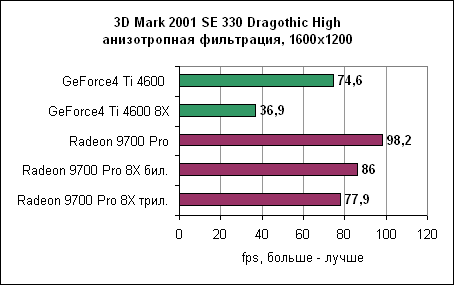
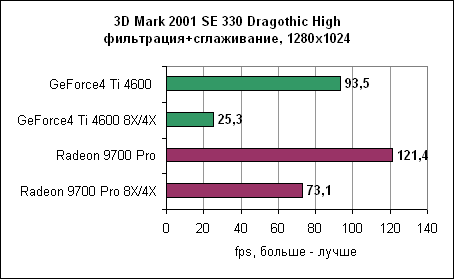
В Dragothic отношение производительностей не меняется. Quake III - сглаживание и анизотропная фильтрация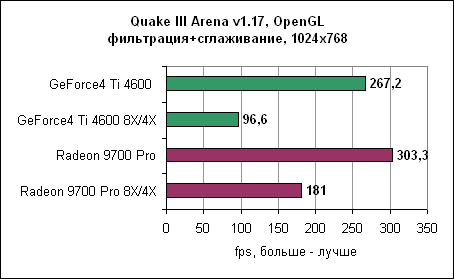
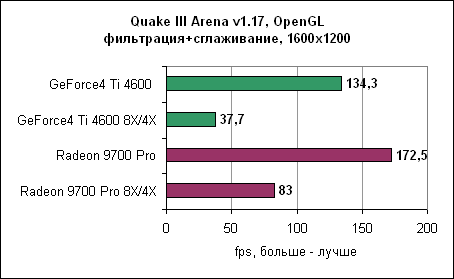
В Quake III Radeon 9700 "всего" в два раза быстрее GeForce4 Ti. В этом режиме тестирования GeForce4 Ti значительно проигрывает Radeon 9700. Интересно заметить, что разница в производительности между двумя картами в Direct3D больше, чем в OpenGL. В свете полученных результатов существует вероятность, что nVidia пересмотрит свой подход к анизотропной фильтрации. Масштабирование процессораМногие тесты выглядят замечательно, но они могут легко ввести в заблуждение неискушенного пользователя. Новые графические карты необходимо использовать вместе с современными платформами для достижения их полного потенциала. Однако у многих пользователей дома еще нет столь скоростного оборудования, как на тестовых стендах. Поэтому перед ними стоит выбор - что обновлять? Процессор? Материнскую плату? Видеокарту?Для того, чтобы вам помочь в этом нелегком деле, мы провели несколько тестов на более медленных машинах - Pentium 4 1600 МГц и Pentium 3 800 МГц. Помните, что мы можем делать лишь общие выводы. Если игра больше всего зависит от процессора, то даже самые быстрые видеокарты не смогут ускорить вашу систему. И наоборот, если игра привязана к скорости видеокарты, то даже на слабых системах вы получите ощутимый прирост, особенно если вы пожелаете использовать сглаживание и/или анизотропную фильтрацию. Aquanox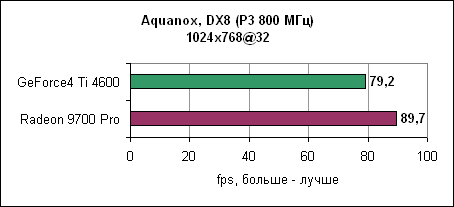
Графический движок Aquanox не слишком сильно зависит от процессора. Он больше привязан к видеокарте. В разрешении 1280x1024 система на P3 показала практически такие же результаты, как Pentium 4 2,53 ГГц. Подобный феномен наблюдается как на GeForce4 Ti, так и на Radeon 9700 Pro. Quake III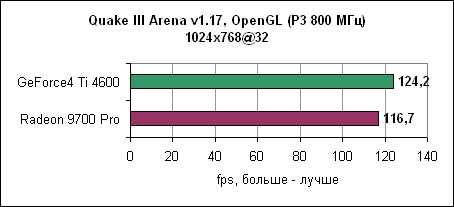
Quake 3 в этом отношении совершенно отличается. Игра просто любит мощь процессора. И если Radeon и GeForce4 показывают почти одинаковые результаты на Pentium 4 1600 МГц, то переход к Pentium 4 2,53 ГГц раскрывает полный потенциал Radeon. 3DMark 2001 SE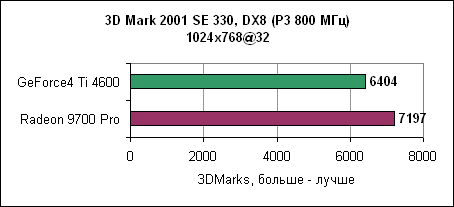
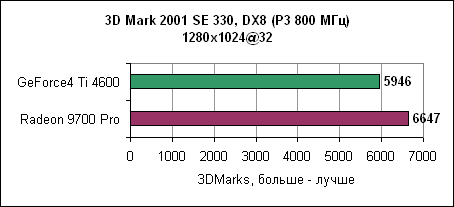
На результат 3DMark влияет как процессор, так и видеокарта. Так что быстрый процессор не всегда приводит к лучшему результату. И наоборот, быстрая видеокарта не всегда дает лучшие частоты кадров. По крайней мере, в низких разрешениях. В общем, если вы покупаете Radeon 9700, то не забудьте обновить и свою систему. Заключение
На основе существующих спецификаций NV30, верите вы в это или нет, следующий чип nVidia будет быстрее Radeon 9700 Pro. Поскольку и ATi, и nVidia должны поддерживать DirectX 9, то вы уже можете отгадать большинство спецификаций NV30. Чип будет поддерживать пиксельные и вершинные программы 2.0, нам следует ожидать 8 конвейеров, и поскольку ATi и Matrox перешли на 256-битную DDR шину памяти, от nVidia можно ожидать такого же шага. Кстати, у nVidia будет весомое преимущество - NV30 будет производиться по 0,13 мкм техпроцессу, что означает не только меньшие размеры по сравнению с R300, но и более высокие тактовые частоты. ATi знает о подобных возможностях, и единственное что спасает сейчас канадскую компанию - сроки выхода NV30. 0,13 мкм чип немного задерживается, и ожидаемый выход перенесен на ноябрь. Впрочем, как считают инженеры ATi, NV30 реально может перенестись вообще на 2003 год, так что Radeon 9700 Pro пройдет до конца года победным шествием. Если вам нужна самая быстрая карта, то вы без сомнения можете брать Radeon 9700 Pro, который будет лучше любой модели GeForce4 или Parhelia. Такая ситуация сохранится как минимум еще несколько месяцев. Вложение денег в Radeon 9700 Pro нельзя назвать пустым - карта имеет немалую перспективу. ATi запускала Doom3 на Radeon 9700 Pro, а Джон Кармак публично выразил свою поддержку карте от ATi. Не забывайте, что еще не так давно Кармак даже в руки не брал Radeon 8500 по причине сырых драйверов. Ну а если вы сомневаетесь в необходимости 128 Мб на борту, то, скажем, тот же самый Doom3 будет использовать 80 Мб текстур. Показанные выше тесты Unreal Tournament 2003 говорят сами за себя. Radeon 9700 Pro наконец-то сделал разрешение 1600x1200 действительно игровым, а 4X сглаживание вы можете включать в любой из сегодняшних игр. Наиболее всего от Radeon 9700 выиграют будущие игры с использованием пиксельных и вершинных программ. Как предполагает ATi, к рождеству 2002 года выйдут порядка 100 игр с поддержкой DirectX 8. К тому времени наконец-то выйдет DirectX 9, и страсти на арене 3D графики еще больше накалятся. Мы не предполагаем, что DX9 повлияет на что-либо в этом году, поскольку все знают, сколько времени требуется, чтобы разработчики реализовали какую-либо новую возможность. И вновь скажем: ATi наконец-то сделала это. Чип R300 является не только лидером в области производительности, но он также несет множество технологических инноваций, причем все сделано на несколько месяцев раньше nVidia. Сейчас усиленно муссируются слухи о выходе 0,13 мкм R300 к концу года, но вероятность такого события все же слишком мала. ATi наверняка обновит R300, вероятнее всего переведет на 0,13 мкм техпроцесс, но явно не раньше 2003 года. 0,13 мкм R300, оснащенный памятью DDR-II станет неплохим конкурентом для NV35 весной 2003 года. А учитывая технологическое лидерство ATi мы можем увидеть обновленный вариант R300 даже раньше NV35. Впрочем, до конца года отдыхать ATi не придется. Компания выпустит несколько новых продуктов. Среди них будет All-in-Wonder Radeon на основе R300, который наконец-то добавит аппаратное MPEG-2 кодирование в карту All-in-Wonder. Упомянем и Radeon 9500, призванный закрыть дыру в линейке продуктов ATi. Radeon 8500 и 8500LE сойдут со сцены, Radeon 9000 займет нишу около $100, а вот на диапазон между $150 и $300 как раз и будет рассчитан Radeon 9500. 9500 представляет собой обрезанную версию Radeon 9700, цена его будет составлять ориентировочно от $200 до $300. Как мы предполагаем, спецификации Radeon 9500 будут аналогичны Radeon 9700, однако число конвейеров рендеринга будет уменьшено с 8 до 4, а тактовые частоты - понижены. Впрочем, ATi пока что не делится информацией о 9500. Если у вас стоит проблема выбора - Radeon 9700 Pro или GeForce4 Ti 4600, то мы однозначно рекомендуем первый вариант, даже учитывая разницу в цене в $100 между ними. Что мы можем точно сказать - на рынке 3D графики сейчас явно выступают два лидера. Обе компании доказали, что они умеют делать вещи так, как нужно, и работают не покладая рук над разработкой самых быстрых и функциональных ускорителей. Дополнительные материалы:
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.