|
Опрос
|
реклама
Быстрый переход
В YouTube появился ИИ-генератор полноценных роликов по текстовому описанию — их можно будет публиковать в Shorts
13.02.2025 [22:57],
Владимир Фетисов
На платформе YouTube появилась новая функция на основе искусственного интеллекта. Она предназначена для генерации небольших роликов, которые пользователи могут публиковать в Shorts. Речь идёт об инструменте YouTube Dream Screen, который построен на базе Google Veo 2. Эта функция и раньше позволяла генерировать ролики на основе текстового описания, но прежде пользователи могли лишь задействовать их в качестве фона. 
Источник изображения: Copilot Теперь же созданные с помощью Dream Screen видео можно публиковать в своём аккаунте в Shorts. Чтобы опробовать новые возможности пользователю нужно активировать камеру в Shorts, запустить функцию Dream Screen, открыть панель выбора медиафайлов и нажать на кнопку «Создать». После этого можно ввести текстовое описание будущего ролика, а также выбрать один из доступных стилей, объективов, кинематографических эффектов и указать продолжительность видео. По словам представителей YouTube, возможность публиковать сгенерированные ИИ ролики в Shorts на этой неделе появится у пользователей платформы из США, Канады, Австралии и Новой Зеландии. Позднее она также станет доступна в других странах, но более точные сроки озвучены не были. Это обновление стало несколько неожиданным, учитывая, что последняя версия нейросети Google Veo всё ещё находится в раннем доступе. По данным YouTube, интеграция нейросети с функцией Dream Screen позволит быстрее генерировать более «детальные и реалистичные» видео с учётом физики реального мира и естественных движений людей. При этом созданные с помощью ИИ видео будут помечаться, как видимыми визуальными метками, так и невидимыми водяными знаками Google SynthID, указывающими на то, что ролик создан или изменён с помощью нейросети. YouTube добавил в Shorts функцию Dream Screen — ИИ-генератор фонов для роликов
22.11.2024 [16:25],
Павел Котов
Администрация YouTube объявила, что в разделе коротких вертикальных роликов Shorts теперь доступна обновлённая функция Dream Screen — генерация динамических фоновых изображений с использованием искусственного интеллекта. Ранее функция Dream Screen позволяла генерировать в качестве фонов не видео, а неподвижные картинки. 
Источник изображения: YouTube Новая возможность появилась благодаря интеграции модели для генерации видео Google DeepMind Veo — она позволяет создавать ролики с разрешением 1080p в разных кинематографических стилях. Чтобы запустить новую функцию, необходимо перейти в камеру Shorts, выбрать значок «Зелёный экран» и опцию Dream Screen — здесь можно ввести текстовый запрос, например, «пейзаж из конфет» или «волшебный лес и ручей»; после чего останется выбрать стиль анимации и нажать кнопку «Создать». Dream Screen создаст несколько видеофонов, из которых нужно выбрать один, после чего можно записывать видео с этим изображением позади себя. Новая функция пригодится, например, чтобы погрузить зрителя в атмосферу любимой книги или подготовить анимированное вступление к основному ролику. В перспективе YouTube планирует предоставить авторам возможность создавать 6-секундные видеоролики, полностью сгенерированные Dream Screen. Крупнейшая в мире платформа коротких видео TikTok также поддерживает создание фоновых изображений с помощью ИИ, но эти картинки пока статические. Воспользоваться обновлённым вариантом Dream Screen могут пользователи YouTube из США, Канады, Австралии и Новой Зеландии. Adobe интегрировала ИИ-генератор видео Firefly Video Model в редактор Premiere Pro
15.10.2024 [00:37],
Владимир Фетисов
Компания Adobe официально представила новую генеративную нейросеть Firefly Video Model, которая предназначена для работы с видео и стала частью приложения Premiere Pro. С помощью этого инструмента пользователи смогут дополнять отснятый материал, а также создавать ролики на основе статичных изображений и текстовых подсказок. 
Источник изображений: Adobe Функция Generative Extend на базе упомянутой нейросети в рамках бета-тестирования становится доступной пользователям Premiere Pro. Она позволит продлить видео на несколько секунд в начале, конце или каком-то другом отрезке ролика. Это может оказаться полезным, если в процессе монтажа нужно скорректировать мелкие недочёты, такие как смещение взгляда человека в кадре или лишние движения.  С помощью Generative Extend можно продлить ролик лишь на две секунды, поэтому он подходит только для внесения небольших изменений. Данный инструмент работает с разрешением 720p или 1080p с частотой 24 кадра в секунду. Функция также подходит для увеличения продолжительности аудио, но есть ограничения. Например, пользователь может продлить какой-либо звуковой эффект или окружающий шум до 10 секунд, но сделать это же с записями разговором или музыкальными композициями не удастся. 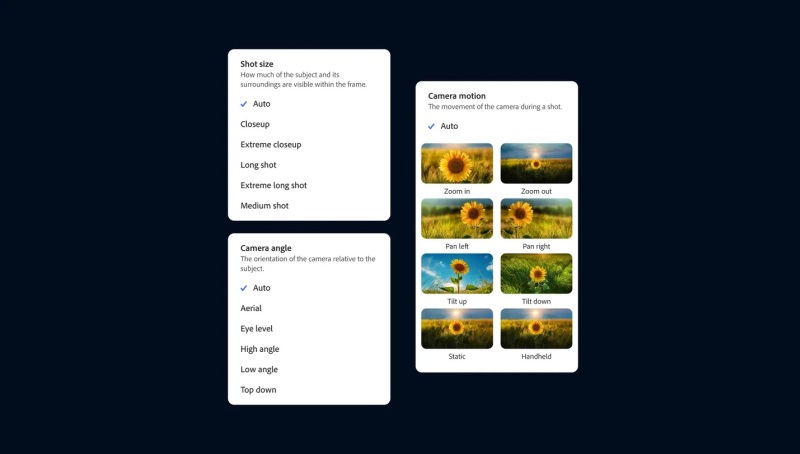 В веб-версии Firefly появились два новых инструмента генерации видео. Речь идёт о функциях Text-to-Video и Image-to-Video, которые, как можно понять из названия, позволяют создавать видео на основе текстовых подсказок и статических изображений. На данном этапе обе функции находятся на этапе ограниченного бета-тестирования, поэтому могут быть доступны не всем пользователям веб-версии Firefly. Text-to-Video работает аналогично другим ИИ-генераторам видео, таким как Sora от OpenAI. Пользователю нужно ввести текстовое описание желаемого результата и запустить процесс генерации ролика. Поддерживается имитация разных стилей, а сгенерированные ролики можно доработать с помощью набора «элементов управления камерой», которые позволяют имитировать такие вещи, как угол наклона камеры, движение и менять расстояние съёмки. Image-to-Video позволяет добавить к текстовому описанию статическое изображение, чтобы генерируемые ролики более точно соответствовали требованиям пользователя. Adobe предлагает использовать этот инструмент, в том числе, для пересъёмки отдельных фрагментов, генерируя новые видео на основе отдельных кадров из существующих роликов. Однако опубликованные примеры дают понять, что этот инструмент, по крайней мере на данном этапе, не позволит отказаться от пересъёмки, поскольку он не совсем точно воспроизводит все имеющиеся на изображении объекты. Ниже пример оригинального видео и ролика, сгенерированного на основе кадра из оригинала. Снимать длинные ролики с помощью этих инструментов не получится, по крайней мере на данном этапе. Функции Text-to-Video и Image-to-Video позволяют создавать видео продолжительностью 5 секунд в качестве 720p с частотой 24 кадра в секунду. Для сравнения, OpenAI утверждает, что её ИИ-генератор Sora может создавать видео длиной до минуты «при сохранении визуального качества и соблюдении подсказок пользователя». Однако этот алгоритм всё ещё недоступен широкому кругу пользователей, несмотря на то, что с момента его анонса прошло несколько месяцев. Для создания видео с помощью Text-to-Video, Image-to-Video и Generative Extend требуется около 90 секунд, но в Adobe сообщили о работе над «турборежимом» для сокращения времени генерации. В компании отметили, что созданные на основе Firefly Video Model инструменты «коммерчески безопасны», поскольку нейросеть обучается на контенте, который Adobe разрешено использовать. MiniMax представила бесплатный ИИ-генератор video-1, который превращает текст в видео за 2 минуты
02.09.2024 [19:03],
Владимир Фетисов
Китайский стартап MiniMax, работающий в сфере искусственного интеллекта, представил алгоритм video-1, который генерирует небольшие видеоклипы на основе текстовых подсказок. Генератор video-1 был представлен широкой публике на прошедшей несколько дней назад в Шанхае первой конференции разработчиков компании, а позднее стал доступен всем желающим на веб-сайте MiniMax. 
Источник изображения: scmp.com С помощью video-1 пользователь может на основе текстового описания создавать видеоролики продолжительностью до 6 секунд. Процесс создания такого ролика занимает около 2 минут. Основатель MiniMax Ян Цзюньцзе (Yan Junjie) рассказал на презентации, что video-1 является первой версией алгоритма генерации видео по текстовым подсказкам, отметив, что в будущем нейросеть сможет создавать ролики на основе статических изображений, а также позволит редактировать уже созданные клипы. Появление video-1 отражает стремление китайских технологических компаний продвинуться в зарождающемся сегменте рынка ИИ. Генератор видео был представлен всего через несколько месяцев после анонса нейросети Sora компании OpenAI, которая также позволяет создавать видео по текстовым подсказкам. Что касается MiniMax, то компания была основана в декабре 2021 года и с тех пор она проделала немалую работу. Новый инструмент video-1 предлагается в рамках платформы MiniMax под названием Hailuo AI, которая ориентирована на потребительский рынок и уже предоставляет доступ к функциям генерации текстов и музыки с помощью нейросетей. Помимо MiniMax, разработкой ИИ-алгоритмов для генерации видео из текста занимаются и другие китайские компании. Пекинский стартап Shengshu AI в июле запустил собственный генератор видео из текста на китайском или английском языках под названием Vidu. Стартап Zhipu AI стоимостью более $1 млрд в том же месяце представил свой аналог Sora, который может создавать небольшие видео на основе текстовых подсказок или статических изображений. Владелец TikTok и Douyin, компания ByteDance, в прошлом месяце опубликовала в китайском App Store приложение Jimeng text-to-video для генерации видео из текста, а ещё ранее оно появилось в местных магазинах Android-приложений. Jimeng позволяет создать бесплатно 80 изображений или 26 видео, а для более активного взаимодействия с нейросетью предлагается оформить подписку за 69 юаней (около $10). В прошлом месяце компания Alibaba Group Holding объявила о разработке алгоритма для генерации видео под названием Tora, основанного на модели OpenSora. Отметим, что среди инвесторов MiniMax есть крупные IT-компании, такие как Alibaba, Tencent Holdings и miHoYo (создатель Genshin Impact). Очередной раунд финансирования прошёл весной и после его завершения рыночная стоимость MiniMax оценивалась более чем в $2 млрд. Stability AI представила генератор 4D-видео Stable Video 4D
25.07.2024 [01:21],
Владимир Фетисов
На фоне популярности генеративных нейросетей уже доступно множество ИИ-алгоритмов для создания видео, таких как Sora, Haiper и Luma AI. Разработчики из Stability AI представили нечто совершенно новое. Речь идёт о нейросети Stable Video 4D, которая опирается на существующую модель Stable Video Diffusion, позволяющую преобразовывать изображения в видео. Новый инструмент развивает эту концепцию, создавая из получаемых видеоданных несколько роликов с 8 разными перспективами. 
Stable Diffusion 3 «Мы считаем, что Stable Video 4D будет использоваться в кинопроизводстве, играх, AR/VR и других сферах, где присутствует необходимость просмотра динамически движущихся 3D-объектов с произвольных ракурсов», — считает глава подразделения по 3D-исследованиям в Stability AI Варун Джампани (Varun Jampani). Это не первый случай, когда Stability AI выходит за пределы генерации двумерного видео. В марте компания анонсировала алгоритм Stable Video 3D, с помощью которого пользователи могут создавать короткие 3D-ролики на основе изображения или текстового описания. С запуском Stable Video 4D компания делает значительный шаг вперёд. Если понятие 3D или три измерения обычно понимается как тип изображения или видео с глубиной, то 4D, не добавляет ещё одно измерение. На самом деле 4D включает в себя ширину (x), высоту (y), глубину (z) и время (t). Это означает, что Stable Video 4D позволяет смотреть на движущиеся 3D-объекты с разных точек обзора и в разные моменты времени. «Ключевые аспекты, которые позволили создать Stable Video 4D, заключаются в том, что мы объединили сильные стороны наших ранее выпущенных моделей Stable Video Diffusion и Stable Video 3D, а также доработали их с помощью тщательно подобранного набора данных динамически движущихся 3D-объектов», — пояснил Джампани. Он также добавил, что Stable Video 4D является первым в своём роде алгоритмом, в котором одна нейросеть выполняет синтез изображения и генерацию видео. В уже существующих аналогах для решения этих задач используются отдельные нейросети. «Stable Video 4D полностью синтезирует восемь новых видео с нуля, используя для этого входное видео в качестве руководства. Нет никакой явной передачи информации о пикселях с входа на выход, вся эта передача информации осуществляется нейросетью неявно», — добавил Джампани. Он добавил, что на данный момент Stable Video 4D может обрабатывать видео с одним объектом длительностью несколько секунд с простым фоном. В дальнейшем разработчики планируют улучшить алгоритм, чтобы он мог использоваться для обработки более сложных видео. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




