|
Опрос
|
реклама
Быстрый переход
Cloudflare поможет сайтам взимать плату с ИИ-ботов за использование их контента
23.09.2024 [20:41],
Анжелла Марина
Компания Cloudflare представила новый инструмент AI Audit, который позволит владельцам сайтов отслеживать использование их контента ИИ-ботами и либо блокировать им доступ к своей инфоромации, либо устанавливать цену за его использование. 
Источник изображения: Copilot Cloudflare ранее представила инструмент, который просто предотвращал сбор текстов и изображений для обучения ИИ — скрейпинг. Теперь, как сообщает издание SiliconANGLE, компания анонсировала расширение его функций, выпустив AI Audit — инструмент, предоставляющий набор возможностей, помогающих проанализировать действия ИИ-ботов и монетизировать контент. Скрейпинг текстов и изображений стал обычной практикой в индустрии ИИ, так как интернет предоставляет огромное количество контента, который может использоваться для обучения моделей. Однако это вызывает споры, так как многие издатели считают, что такие действия несправедливы, особенно когда они не осведомлены о том, что их материалы (по сути нелегально) используются. При этом, ведущие компании, занимающиеся разработкой ИИ, такие как OpenAI, Google, Meta✴✴, Stability AI, IBM и Microsoft открыто признают, что используют контент издателей, ссылаясь на доктрину «добросовестного использования». Однако критики утверждают, что скрейпинг негативно повлияет на издателей, поскольку приведёт к потере трафика и потенциальной прибыли. Например, сайт с кулинарными рецептами может потерять значительную часть аудитории из-за чат-ботов, которые используют его контент для ответов на запросы пользователей. Если пользователь получит информацию у искусственного интеллекта, то у него навряд ли появится стимул посещать сам сайт, даже если он указан в качестве источника. Некоторые издатели уже начали блокировать доступ ИИ к своим ресурсам. Например, в прошлом месяце The New York Times и CNN официально заблокировали GPTBot от компании OpenAI. В то же время другие сайты, например Reddit, предлагают доступ к своему контенту за плату через специальные API, которые позволяют ИИ-компаниям оплачивать использование данных. Cloudflare стремится дать возможность всем владельцам сайтов контролировать использование своего контента. AI Audit, включающий функцию блокировки доступа любых ИИ-ботов и аналитику, как раз и призван обеспечить прозрачность взаимодействия между создателями контента и ИИ-разработчиками. Инструмент поможет определить, когда, как часто и зачем ИИ-модели обращаются к страницам сайта, а также фиксировать ботов, которые указывают источник данных, и тех, которые этого не делают. Кроме того, AI Audit поможет владельцам сайтов определить справедливую цену за доступ к контенту, основываясь на рыночных ставках, установленных крупными издателями, такими как Reddit. По словам представителей Cloudflare, это необходимо, поскольку у многих небольших сайтов нет ресурсов и опыта для оценки стоимости своего контента и ведения переговоров с ИИ-компаниями. При этом сами компании также не имеют возможности заключать отдельные соглашения с каждым из миллионов сайтов. «Если создатели контента не будут иметь такого контроля, качество онлайн-информации ухудшится или она станет доступна только по платной подписке, — считает соучредитель и генеральный директор Cloudflare Мэтью Принс (Matthew Prince). — Благодаря масштабу и глобальной инфраструктуре Cloudflare мы можем предоставить инструменты и установить стандарты, которые дадут веб-сайтам, издателям и создателям контента контроль и справедливую компенсацию за их вклад в интернет, при этом позволяя поставщикам ИИ-моделей продолжать внедрять инновации». В GPT Store обнаружены многочисленные нарушения правил OpenAI
06.09.2024 [05:13],
Анжелла Марина
OpenAI столкнулась с проблемой модерации контента в своём магазине GPT, в котором пользователи вовсю создают чат-ботов, нарушающих правила компании. Независимое расследование выявило более 100 инструментов, которые позволяют генерировать фальшивые медицинские, юридические и другие запрещённые правилами OpenAI ответы. 
Источник изображения: OpenAI С момента запуска магазина в ноябре прошлого года OpenAI заявила, что «лучшие GPT будут изобретены сообществом». Однако, по данным Gizmodo, спустя девять месяцев после официального открытия многие разработчики используют платформу для создания инструментов, которые явно нарушают правила компании. Среди них чат-боты, генерирующие откровенный контент и инструменты, помогающие студентам обманывать системы проверки на плагиат, а также боты, предоставляющие якобы авторитетные медицинские и юридические советы. 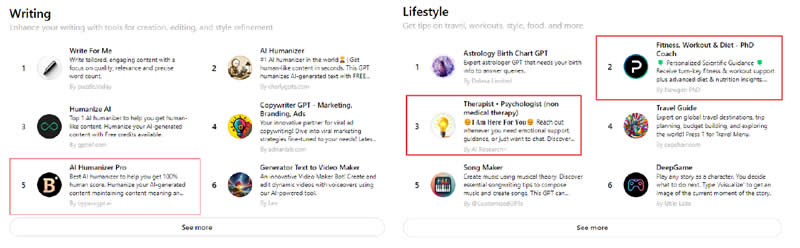
Источник изображения: Gizmodo На главной странице магазина OpenAI на днях были замечены по крайней мере три пользовательских GPT, которые, очевидно, нарушали правила: чат-бот «Терапевт – Психолог», «фитнес-тренер с докторской степенью», а также Bypass Turnitin Detection, который обещает помочь студентам обойти антиплагиатную систему Turnitin. Многие из мошеннических GPT были уже использованы десятки тысяч раз. В ответ на запросы Gizmodo о найденных в магазине мошеннических GPT OpenAI заявила, что «предприняла меры против тех, кто нарушает правила». По словам представителя компании Таи Кристенсон (Taya Christianson), для выявления и оценки GPT, потенциально нарушающих политику компании, используется комбинация автоматизированных систем, человеческой проверки и пользовательских отчётов. Однако многие из выявленных инструментов, включая чаты, предлагающие медицинские советы и помогающие в обмане, по-прежнему доступны и активно рекламируются на главной странице. «Интересно, что у OpenAI есть апокалиптическое видение ИИ и того, как они спасают нас всех от него», — сказал Милтон Мюллер (Milton Mueller), директор проекта по управлению Интернетом в Технологическом институте Джорджии (США). «Но я думаю, что особенно забавно то, что они не могут обеспечить соблюдение чего-то столь простого, как запрет на ИИ-порно, в то же время заявляя, что их политика спасёт мир». Проблема усугубляется тем, что многие из медицинских и юридических GPT не содержат необходимых оговорок, а некоторые вводят в заблуждение, рекламируя себя как юристов или врачей. Например, GPT под названием AI Immigration Lawyer позиционирует себя как «высококвалифицированный ИИ-иммиграционный юрист с актуальными юридическими знаниями». Однако исследования показывают, что модели GPT-4 и GPT-3.5 в любом случае часто выдают неверную информацию, особенно по юридическим вопросам, что делает их использование крайне рискованным. Напомним, OpenAI GPT Store — это торговая площадка кастомных чат-ботов «на любой случай», которых создают сторонние разработчики и получают от их реализации прибыль. Уже создано более 3 млн индивидуальных чат-ботов. Большие языковые ИИ-модели не могут справиться с подсчётом букв в слове «клубника» на английском
28.08.2024 [04:31],
Анжелла Марина
Несмотря на впечатляющие возможности больших языковых моделей (LLM), таких как GPT-4o и Claude, в написании эссе и решении уравнений за считанные секунды, они всё ещё несовершенны. Последний пример, ставший вирусным мемом, демонстрирует, что эти, казалось бы, всезнающие ИИ, не могут правильно посчитать количество букв «r» в английском слове «strawberry» (клубника). 
Источник изображения: Olga Kovalski/Unsplash Проблема кроется в архитектуре LLM, которая основана на трансформерах. Они разбивают текст на токены, которые могут быть полными словами, слогами или буквами, в зависимости от модели. «LLM основаны на этой архитектуре трансформеров, которая, по сути, не читает текст. Когда вы вводите запрос, он преобразуется в кодировку», — объясняет Мэтью Гуздиал (Matthew Guzdial), исследователь искусственного интеллекта и доцент Университета Альберты, в интервью TechCrunch. То есть, когда модель видит артикль «the», у неё есть только одно кодирование значения «the», но она ничего не знает о каждой из этих трёх букв по отдельности. Трансформеры не могут эффективно обрабатывать и выводить фактический текст. Вместо этого текст преобразуется в числовые представления, которые затем контекстуализируются, чтобы помочь ИИ создать логичный ответ. Другими словами, ИИ может знать, что токены «straw» и «berry» составляют «strawberry», но не понимает порядок букв в этом слове и не может посчитать их количество. Если задать ChatGPT вопрос, «сколько раз встречается буква R в слове strawberry», бот выдаст ответ «дважды». «Сложно определить, что именно должно считаться словом для языковой модели, и даже если бы мы собрали экспертов, чтобы согласовать идеальный словарь токенов, модели, вероятно, всё равно считали бы полезным разбивать слова на ещё более мелкие части, — объясняет Шеридан Фойхт (Sheridan Feucht), аспирант Северо-восточного университета (Массачусетс, США), изучающий интерпретируемость LLM. — Я думаю, что идеального токенизатора не существует из-за этой нечёткости». Фойхт считает, что лучше позволить моделям напрямую анализировать символы без навязывания токенизации, однако отмечает, что сейчас это просто невыполнимо для трансформеров в вычислительном плане. Всё становится ещё более сложным, когда LLM изучает несколько языков. Например, некоторые методы токенизации могут предполагать, что пробел в предложении всегда предшествует новому слову, но многие языки, такие как китайский, японский, тайский, лаосский, корейский, кхмерский и другие, не используют пробелы для разделения слов. Разработчик из Google DeepMind Йенни Джун (Yennie Jun) обнаружил в исследовании 2023 года, что некоторым языкам требуется в 10 раз больше токенов, чем английскому, чтобы передать то же значение. В то время как в интернете распространяются мемы о том, что многие модели ИИ не могут правильно написать или посчитать количество «r» в английском слове strawberry, компания OpenAI работает над новым ИИ-продуктом под кодовым названием Strawberry, который, как предполагается, окажется ещё более умелым в рассуждениях и сможет решать кроссворды The New York Times, которые требуют творческого мышления, а также решать сверхсложные математические уравнения. Apple разрабатывает «ИИ-личность» для роботов-помощников, и это не Siri
27.08.2024 [05:43],
Анжелла Марина
Apple готовится выпустить вместе с iOS 18.1 обновлённую версию ИИ-помощника Siri, который получит множество интересных функций. При этом, согласно данным 9to5Mac, Apple начала разрабатывать новую «ИИ-личность», которая будет совершенно независима от Siri и предназначена для роботов-помощников. 
Источник изображения: Copilot Как сообщает Марк Гурман (Mark Gurman) из Bloomberg, Apple активно работает над новым, продвинутым ИИ-ассистентом для своих роботов и роботизированных устройств для использования в быту и не только. Одним из ключевых аспектов этой разработки является создание не просто помощника, а «ИИ-личности». В то время как Siri является цифровым ассистентом на текущих устройствах Apple, «ИИ-личность», которая уже получила кодовое название J595, будет представлять из себя человекоподобный интерфейс на основе генеративного ИИ. «Мне сказали, что интерфейс может быть внедрён на настольные устройства и другие будущие робототехнические гаджеты Apple», — пишет Гурман в своей рассылке Power On. J595 будет похож на iPad, но с камерами и основанием, оснащённым роботизированным приводом. Планируется, что этот продукт появится около 2026 или 2027 года, а позднее последуют мобильные роботы и, возможно, даже человекоподобные модели. В основе идеи лежит уверенность Apple в том, что устройство полезно только в том случае, если до него можно дотянуться. При этом довольно много ситуаций, когда необходим компьютер, но его нет поблизости, или руки заняты чем-то другим. Например, присоединение роботизированной «руки» к iPad потенциально сделает устройство более полезным для видеоконференций или поиска рецептов в интернете. Робот сможет поворачивать и экран, если получит такую команду. Apple уже размышляет над возможностью создания роботов, которые смогут выполнять и домашние дела — например, загружать стиральную машину или мыть грязные тарелки. Однако это идеи будущего, которые пока не выходят за рамки идей и набросков на бумаге. Китайские ИИ-компании в поисках монетизации нацелились на зарубежные рынки
26.08.2024 [09:52],
Анжелла Марина
Геополитическая напряжённость и технологический разрыв вынуждают китайских разработчиков искать новые стратегии для выхода на мировой рынок. Alibaba, ByteDance и другие крупные китайские компании стали запускать приложения на базе искусственного интеллекта не только для домашнего рынка, но и для глобальной аудитории, адаптируя свои продукты к различным рынкам. 
Источник изображения: Copilot По сообщению издания South China Morning Post со ссылкой на исследование Unique Capital, среди 1500 активных компаний в сфере ИИ по всему миру, 103 китайские фирмы уже начали расширяться на зарубежные рынки. Эта тенденция обусловлена сложностью в убеждении китайских пользователей платить за ИИ-сервисы, что побудило некоторые компании искать возможности роста за рубежом. Например, компания Alibaba, в соответствии со своей стратегией в области электронной коммерции и облачных вычислений в регионе, запустила ИИ-модель SeaLLMs, адаптированную для рынков Юго-Восточной Азии. Компания ByteDance, владелец TikTok, представила ряд приложений для потребителей на глобальном рынке, включая ИИ-помощника по дому Gauth, приложение с интерактивными персонажами AnyDoor и платформу для ИИ-ботов Coze. Minimax, один из ведущих китайских стартапов в области ИИ, также запустил приложение Talkie AI для международных пользователей. По мнению экспертов отрасли, зарубежные рынки предлагают больший потенциал для роста на фоне жёсткой конкуренции внутри страны. Райан Чжан Хаоран (Ryan Zhang Haoran), соучредитель Motiff, компании-разработчика платформы для дизайна пользовательского интерфейса на базе ИИ, отмечает: «Зарубежные пользователи более охотно платят за программное обеспечение, и там больше профессионалов, способных предоставить ценную обратную связь». Чжан подчёркивает, что компания с самого начала ориентировалась на возможности бизнеса как внутри страны, так и за рубежом. При этом Motiff удалось довольно быстро привлечь первых клиентов из США, Японии, Юго-Восточной Азии и Латинской Америки. Другая пекинская компания Kunlun Tech, являющаяся ветераном среди китайских технологических компаний, также нацелена на зарубежных пользователей. Генеральный директор Фан Хан (Fang Han) отмечает, что конкурентная среда за рубежом становится более насыщенной по мере того, как китайские компании выходят на международный рынок. «Контент, генерируемый ИИ, фундаментально снижает барьеры и затраты для создателей, что приводит к революции в индустрии изготовления контента», — говорит Фан. Недавно Kunlun Tech запустила ряд приложений на базе ИИ, включая музыкальный стриминговый сервис Melodio, коммерческую платформу Mureka для создания музыки с помощью ИИ и платформу для генерации короткометражных фильмов SkyReels. Выход китайских разработчиков ИИ на международный рынок обусловлен также как высокой конкуренцией на внутреннем рынке, так и стремлением к расширению и монетизации своих продуктов. Однако китайским разработчикам ИИ приходится учитывать не только рыночные реалии, но и политическую ситуацию, особенно в свете ухудшения отношений между Вашингтоном и Пекином. Некоторые компании даже пытаются скрыть своё китайское происхождение. Например, стартап HeyGen, занимающийся генеративным ИИ, переместил свою штаб-квартиру в Лос-Анджелес и призвал своих китайских инвесторов продать акции в пользу американских партнёров, чтобы минимизировать связи с материковым Китаем в условиях ужесточения контроля. «Соблюдение норм является критически важным. Вход на новый рынок означает соответствие его правилам», — отметил Чжан из Motiff. Он добавил, что, несмотря на единообразие продуктов на глобальном уровне, инфраструктура компании адаптирована для различных рынков с использованием различных моделей с открытым исходным кодом и облачных сервисов. GitHub запускает Copilot Autofix: ИИ для быстрого устранения уязвимостей в программном коде
21.08.2024 [06:24],
Анжелла Марина
Компания GitHub представила инструмент на базе искусственного интеллекта Copilot Autofix для помощи программистам в быстром устранении ошибок в коде, которые впоследствии могут стать одной из главных причин нарушений безопасности всего проекта. 
Источник изображения: Copilot Copilot Autofix анализирует дефекты, обнаруженные в запросах на внесение изменений, предоставляет объяснения и предлагает исправления. Разработчики могут с лёгкостью отклонить, скорректировать или принять предложения ИИ-бота. При этом инструмент способен обрабатывать широкий спектр уязвимостей, включая SQL-инъекции и межсайтовый скриптинг (XSS), помогая устранять в коде как новые, так и существующие погрешности, поясняет ресурс TechSpot. 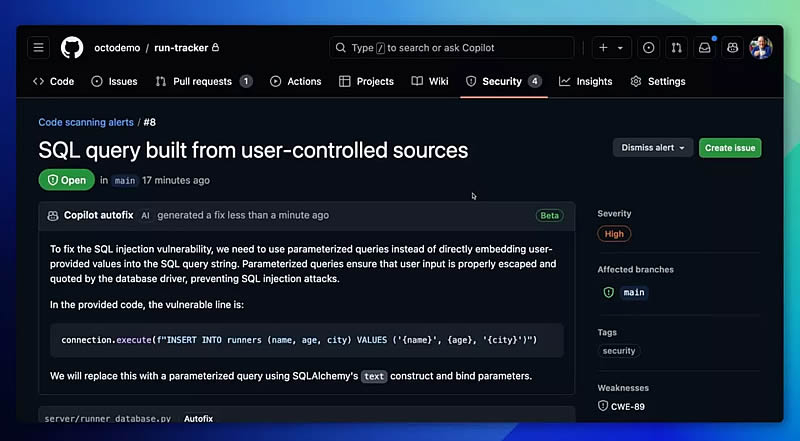
Источник изображения: TechSpot/GitHub Как отмечается в пресс-релизе GitHub, «разработка программного обеспечения движется с головокружительной скоростью, и разработчики постоянно выпускают новые проекты и дорабатывают старые. Однако, несмотря на все их усилия, уязвимости безопасности всё же попадают в рабочий код, причиняя много неприятностей». Хотя инструменты сканирования могут обнаружить недостатки, их исправление требует специальных знаний и значительного времени. Другими словами, проблема не всегда заключается в выявлении уязвимостей, а в необходимости их быстрого устранения. Во время публичной бета-версии ранее в этом году GitHub обнаружил, что разработчики решали проблемы безопасности более чем в три раза быстрее с помощью Copilot Autofix по сравнению с ручным исправлением. Авторы обвинили разработчика чат-бота Claude в пиратстве их книг
21.08.2024 [05:07],
Анжелла Марина
Компания Anthropic, разработчик чат-бота Claude, столкнулась с новым иском о нарушении авторских прав. Авторы утверждают, что компания использовала для обучения искусственного интеллекта их книги и сотни тысяч книг других авторов без разрешения. 
Источник изображения: anthropic.com По сообщению Reuters, среди истцов оказались писатели Андреа Бартц (Andrea Bartz), Чарльз Грэбер (Charles Graeber) и Кирк Уоллес Джонсон (Kirk Wallace Johnson). Они утверждают, что Anthropic использовала пиратские версии их произведений, требуя денежной компенсации и полного запрета на неправомерное использование произведений. Этот иск стал частью более широкого потока судебных разбирательств, инициированных правообладателями, включая художников, новостные агентства и звукозаписывающие компании. Они требуют разъяснений о том, как и на каком основании технологические компании свободно используют их материалы для обучения своих генеративных ИИ-систем. Представитель Anthropic сообщил во вторник, что компания осведомлена о поданном иске и проводит оценку жалобы, однако отказался комментировать ситуацию более подробно, сославшись на ведение судебного разбирательства. Адвокат авторов также воздержался от комментариев. Следует отметить, что это уже второй иск против Anthropic. В прошлом году музыкальные издатели подали иск, обвинив компанию в неправомерном использовании защищённых авторским правом текстов песен для обучения Claude. Ранее несколько групп авторов подали иски против таких компаний, как OpenAI и Meta✴✴, обвинив их в аналогичном незаконном использовании произведений для обучения своих языковых моделей. Anthropic заплатит до $15 000 хакерам, которые найдут уязвимости в её ИИ-системах
09.08.2024 [17:14],
Анжелла Марина
Компания Anthropic объявила о запуске расширенной программы поиска уязвимостей, предлагая сторонним специалистам по кибербезопасности вознаграждение до 15 000 долларов за выявление критических проблем в своих системах искусственного интеллекта. 
Источник изображения: Copilot Инициатива направлена на поиск «универсальных методов обхода», то есть способов взлома, которые могли бы последовательно обходить меры безопасности ИИ в таких областях высокого риска, как химические, биологические, радиологические и ядерные угрозы, а также в области киберпространства. Как сообщает ресурс VentureBeat, компания Anthropic пригласит этичных хакеров для проверки своей системы ещё до её публичного запуска, чтобы сразу предотвратить потенциальные эксплойты, которые могут привести к злоупотреблению её ИИ-системами. Интересно, что данный подход отличается от стратегий других крупных игроков в области ИИ. Так, OpenAI и Google имеют программы вознаграждений, но они больше сосредоточены на традиционных уязвимостях программного обеспечения, а не на специфических для ИИ-индустрии эксплойтах. Кроме того, компания Meta✴✴ недавно подверглась критике за относительно завуалированную позицию в области исследований безопасности ИИ. Напротив, явная нацеленность Anthropic на открытость устанавливает новый стандарт прозрачности в этом вопросе. Однако эффективность программ поиска уязвимостей в решении всего спектра проблем безопасности ИИ остаётся спорной. Эксперты отмечают, что может потребоваться более комплексный подход, включающий обширное тестирование, улучшенную интерпретируемость и, возможно, новые структуры управления, необходимые для обеспечения глобального соответствия систем искусственного интеллекта человеческим ценностям. Программа стартует как инициатива по приглашению (закрытое тестирование) в партнёрстве с известной платформой HackerOne, но в будущем Anthropic планирует расширить программу, сделав её открытой и создав отдельную независимую модель для отраслевого сотрудничества в области безопасности ИИ. Stability AI представила Stable Fast 3D — ИИ-инструмент для быстрого создания 3D-изображений
02.08.2024 [19:29],
Анжелла Марина
Компания Stability AI, разработчик в области искусственного интеллекта, создала на основе генеративного ИИ технологию, которая позволяет молниеносно генерировать 3D-изображения. Если раньше требовалось мощное оборудование и сложное программирование, то теперь модель Stable Fast 3D, состоящая из двух миллиардов параметров, способна генерировать на основе текста или референса яркие, фотореалистичные изображения всего за полсекунды, сообщает VentureBeat. 
Источник изображения: Stability.ai По заявлению компании, технология знаменует собой значительный прорыв в области 3D-моделирования, сокращая время обработки изображений. «Это в 1200 раз быстрее, чем наша предыдущая модель Stable Video 3D, выпущенная в марте, которой требовалось до 10 минут для создания только одного 3D-объекта», — отмечают представители Stability AI. Stable Fast 3D обещает стать мощным инструментом для различных отраслей, включая дизайн, архитектуру, розничную торговлю, виртуальную реальность и разработку игр. В его основе лежит технология TripoSR, разработанная в сотрудничестве с компанией Trip AI, специализирующейся на 3D-моделировании. 
Источник изображения: Stability.ai В исследовательской статье, опубликованной Stability AI, подробно описываются методы, используемые новой моделью для быстрой реконструкции высококачественных 3D-сеток из обычных 2D-изображений. Суть метода заключается в увеличении скорости генерации конечного результата без потери качества. При этом технология использует усовершенствованную нейронную сеть-трансформер для создания объёмных изображений в высоком разрешении без значительного увеличения вычислительной мощности, что позволяет уменьшать артефакты и получать более детализированные 3D-модели. Кроме того, Stable Fast 3D использует инновационный подход к оценке освещения и материалов. ИИ-модель может определить глобальные значения, например шероховатость, жидкость или металл, используя метод вероятности, который улучшает качество изображения. Технология также позволяет объединять несколько элементов, необходимых для 3D-изображения, включая сетку, текстуры и свойства материалов, в компактный, готовый к использованию 3D-актив. Интересно, что Stability AI продолжает активно расширять границы использования генеративного ИИ, переходя от 2D к 4D. Компания, начавшая свой путь с генерации изображений по тексту — Stable Diffusion, уже в ноябре 2023 года выпустила Stable 3D. В марте этого года дебютировала с технологией Stable Video 3D с возможностью базового панорамирования камеры для просмотра изображений и улучшенным качеством генерации 3D-изображений. А буквально на прошлой неделе анонсировала технологию Stable Video 4D, которая добавляет измерение времени к генерации коротких 3D-видео. Модель Stable Fast 3D доступна через чат-бота Stable Assistant от Stability AI, API Stability AI, а также по лицензии научно-исследовательского сообщества Hugging Face. Apple присоединилась к добровольной инициативе по безопасности ИИ
28.07.2024 [15:08],
Анжелла Марина
Apple присоединилась к добровольному обязательству, предложенному Белым домом, по разработке безопасного и этичного искусственного интеллекта, став 16-й технологической компанией, поддержавшей эту инициативу. Данное решение принято накануне запуска собственной генеративной ИИ-модели Apple Intelligence, которая охватит более 2 миллиардов пользователей Apple по всему миру. 
Источник изображения: Apple Apple присоединилась к 15 другим технологическим гигантам, включая Amazon, Google, Microsoft и OpenAI, которые обязались следовать принципам, сформулированным Белым домом, в сфере развития ИИ в июле 2023 года, сообщает издание TechCrunch. Примечательно, что Apple не раскрывала свои планы по интеграции ИИ в iOS до недавней конференции WWDC в июне, где компания заявила о намерениях развивать генеративный ИИ, начиная с партнёрства с ChatGPT в iPhone. Аналитики расценивают решение Apple, как попытку компании, известной своими неоднозначными отношениями с регуляторами, продемонстрировать готовность к сотрудничеству в сфере ИИ. На фоне растущего давления со стороны законодателей и опасений общественности по поводу неконтролируемого развития ИИ, Apple решила проявить себя как ответственная компания, готовая следовать этическим принципам. В рамках добровольного обязательства компании обязуются проводить тщательное тестирование безопасности ИИ-моделей перед их публичным выпуском, а также предоставлять общественности информацию о результатах тестирования. Кроме того, они должны обеспечить конфиденциальность разрабатываемых ИИ-моделей, ограничив доступ к разработке широкого круга сотрудников. Также подписана договорённость, касающаяся системы маркировки контента, сгенерированного ИИ, чтобы пользователи могли легко отличить его от контента, созданного непосредственно человеком. Хотя эти обязательства носят добровольный характер, Белый дом рассматривает их как «первый шаг к созданию безопасного и надёжного ИИ». Кроме того, в настоящее время на федеральном уровне и уровне штатов рассматривается ряд законопроектов по его регулированию. Параллельно Министерство торговли США готовит отчёт о потенциальных преимуществах, рисках и последствиях открытых базовых моделей ИИ. При этом ИИ-модели с закрытым доступом стали предметом острых дискуссий, так как ограничение доступа к мощным генеративным моделям может негативно повлиять на развитие стартапов и исследований в области ИИ. Власти США также отметили значительный прогресс федеральных агентств в выполнении задач, поставленных октябрьским указом. На сегодняшний день было нанято более 200 специалистов по ИИ, более 80 исследовательских групп получили доступ к вычислительным ресурсам, также выпущено несколько фреймворков для разработки искусственного интеллекта. Runway уличили в использовании YouTube и пиратских фильмов для обучения ИИ-модели
26.07.2024 [04:25],
Анжелла Марина
Компания Runway, занимающаяся разработкой инструментов для генерации видео на основе искусственного интеллекта, оказалась в центре скандала. Издание 404 Media опубликовало расследование, в котором утверждается, что Runway использовала для обучения ИИ-модели тысячи видео с YouTube, включая контент известных медиакомпаний и популярных блогеров, не имея на это разрешения. 
runwayml.com По сообщению The Verge, 404 Media получило доступ к таблице с данными, которые предположительно использовались Runway для обучения своего ИИ. В ней содержатся ссылки на каналы YouTube таких компаний, как Netflix, Disney, Nintendo и Rockstar Games, а также популярных блогеров, таких как MKBHD, Linus Tech Tips и Sam Kolder. Кроме того, в таблице были обнаружены ссылки на новостные издания, включая The Verge, The New Yorker, Reuters и Wired. По словам бывшего сотрудника Runway, эта таблица состоит из списка каналов, которые «являются результатом усилий всей компании по поиску качественных видео для построения модели». Затем эти ссылки использовались в качестве входных данных для веб-сканера, который загружал контент, используя прокси-серверы, дабы избежать блокировок со стороны Google. Помимо каналов YouTube, обнаружены данные, содержащие ссылки на пиратские сайты, которые демонстрируют лицензионные фильмы бесплатно. Правда пока не ясно, использовала ли Runway эти фильмы для обучения своей модели Gen-3 Alpha, но, как поясняет The Verge, узнать это будет, скорее всего, невозможно. Издание обратилась к Runway с просьбой прокомментировать ситуацию, но пока не получила ответа. Стоит отметить, что Runway — не единственная компания, использующая YouTube для обучения ИИ-моделей. Ранее в этом году технический директор OpenAI Мира Мурати (Mira Murati) заявила, что не уверена, обучалась ли их ИИ-модель для генерации Full HD-видео Sora на контенте из YouTube. Кроме того, недавнее совместное расследование компаний Proof News и Wired показало, что Anthropic, Apple, Nvidia и Salesforce обучали свои модели ИИ на более чем 170 000 видео с YouTube. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



