|
Опрос
|
реклама
Быстрый переход
Компании начали проверять кандидатов на дипфейки — хакеры с ИИ всё чаще подсовывают «синтетических сотрудников»
20.07.2026 [13:11],
Алексей Разин
По мере распространения технологий генеративного искусственного интеллекта растут не только внешние угрозы в сфере кибербезопасности, но и внутренние. Компании, которые исторически полагались на традиционные методы защиты от кибератак изнутри, теперь вынуждены сталкиваться с новыми вызовами, которые возникли благодаря распространению технологий ИИ. 
Источник изображения: Unsplash, Azamat E Как поясняет Financial Times, раскрытая в прошлом году деятельность северокорейской группировки хакеров показала, насколько изобретательными могут быть организаторы кибератак на инфраструктуру американских компаний. Прежде всего, злоумышленникам удалось внедриться в более чем 100 компаний на территории США под видом более чем 80 американских граждан, чьи персональные данные были похищены. Активность хакеров позволила им выручить более $5 млн. По итогам расследования были арестованы 8 граждан США, которые содействовали северокорейским хакерам, размещая в жилых помещениях на американской территории «фермы ноутбуков», которые позволяли работодателям считать, что на них работают в удалённом режиме настоящие американцы. При этом установленные на этих американских «фермах» ноутбуки фактически удалённо управлялись из-за границ страны. По статистике оператора связи Verizon, из 22 000 инцидентов в сфере кибербезопасности в мире в текущем году примерно 12 % имели отношение к атакам на инфраструктуру компаний изнутри. Злонамеренные действия от атакующих, находящихся внутри компании, исторически причиняли самый серьёзный ущерб, поскольку хакер в этом случае обычно хорошо знаком со слабыми местами в защите и понимает, какие элементы проще и выгоднее атаковать. Кроме того, системы генеративного ИИ сейчас позволяют создавать «синтетических инсайдеров», которые выдают себя за реальных сотрудников компании, в случае необходимости похищая их внешность и голос с помощью цифровых технологий. Компании в таких условиях усилили отбор потенциальных соискателей на замещение вакансий, и к процессу подключаются специалисты по безопасности, которые ранее не всегда привлекались кадровыми подразделениями. Эксперты поясняют, что бороться с дипфейками на этапе удалённых собеседований можно довольно простыми методами. Достаточно попросить соискателя помахать рукой или повернуть голову в сторону, чтобы с высокой вероятностью выявить подлог. Подозрительная активность работающих на удалёнке сотрудников тоже должна мониториться специализированным ПО. В 62 % случаев, согласно статистике Fortinet, инциденты в сфере информационной безопасности в прошлом году имели место в результате человеческой ошибки или утечки учётных данных. Самые серьёзные инциденты в этой сфере могут обходиться бизнесу в сумму от $1 млн до $10 млн. Представители Google подчёркивают, что так называемое «теневое использование ИИ» сотрудниками тоже представляет угрозу для защиты информации компаний. Если какая-то чувствительная информация загружается сотрудником в чат-бот, она потом легко может стать достоянием злоумышленников. Угроза обретает особую актуальность с учётом распространения ИИ-агентов, которые могут выступать в роли виртуальных сотрудников. Их, в свою очередь, можно вовлечь в неправомерную деятельность, отмечает Financial Times. На корпоративном рынке появляется всё больше ПО, призванного следить за сохранностью конфиденциальных данных в условиях повального внедрения ИИ. Становится сложно обеспечить надёжность функционирования инфраструктуры и при этом не отпугнуть сотрудников излишним недоверием к ним со стороны работодателя. Важно чётко выделять индикаторы риска, но при этом не тормозить бизнес-процессы всеобщим недоверием и тотальной слежкой. Истцы взяли на вооружение ИИ и завалили британские суды работой до 2028 года
02.07.2026 [12:59],
Алексей Разин
По информации Financial Times, внедрение генеративного искусственного интеллекта коснулось британской судебной системы самым непосредственным образом, поскольку лишённые возможности нанимать дорогостоящих адвокатов граждане стали активнее использовать ИИ-ассистентов для подачи жалоб и исков. Местные суды теперь завалены работой до 2028 года. 
Источник изображения: Unsplash, Who’s Denilo ? Как поясняет источник, речь идёт преимущественно о специальных судебных органах Великобритании, которые рассматривают трудовые споры. В условиях, когда компании одна за одной объявляют о сокращении сотрудников в результате внедрения искусственного интеллекта, последний помогает жертвам подобных оптимизаций преследовать своего бывшего работодателя в суде. Уволенные сотрудники просто обращаются к чат-ботам с просьбой составить жалобу на работодателя, хотя ранее для этого обычно приходилось нанимать юриста, чьи услуги остаются не самыми дешёвыми. Издание приводит пример одной женщины, которую работодатель сократил во время нахождения в отпуске по уходу за ребёнком. Выйти на прежнее место работы она после завершения отпуска не смогла, но решила обратиться в профильный трибунал для получения компенсации. Составить текст жалобы ей помог чат-бот, в итоге суд встал на её сторону и заставил бывшего работодателя выплатить пострадавшей компенсацию в сумме шестимесячного жалования. Отмечается, что этот прецедент скорее является исключением, поскольку злоупотребление ИИ приводит к перегрузке британских судебных органов и увеличению сроков рассмотрения каждой трудовой жалобы. Юристы отмечают, что некоторые дела будут рассматриваться не ранее 2028 года. При этом некоторые истцы пытаются добиться через суд временных мер поддержки со стороны работодателя в виде выплаты ежемесячного жалования до окончательного рассмотрения дела. В судебной практике у таких жалоб появляется приоритет, поэтому их подача истцами вносит сильный беспорядок в работу трибуналов по трудовым спорам. Тем более, что многие истцы слепо доверяют ИИ в вопросах формулирования исковых требований и назначения компенсации. Нередко ИИ выдвигает завышенные требования, которые судом не удовлетворяются в первой инстанции, но истцы при этом сохраняют непоколебимость своих позиций. Кроме того, ИИ нередко формирует слишком объёмные документы, в которых судам приходится долго разбираться и тратить время на удаление ненужной информации, актуальность которой сам истец без помощи юристов проверить не мог. Представители правовой системы Великобритании теперь предлагают вернуть государственную пошлину за подачу судебных исков, которая была отменена с 2017 года ради «повышения доступности справедливости». Такой материальный барьер позволил бы отсечь не самые важные иски и разгрузить судебную систему. Кроме того, часть полномочий по рассмотрению трудовых споров можно было бы передать недавно организованному Агентству по соблюдению справедливости в трудовой сфере. Правозащитники отмечают, что ИИ обеспечил повышение доступности правосудия, в особенности для иммигрантов, не владеющих английским языком и специализированной терминологией в достаточной степени для самостоятельного представления своих интересов в суде. Словом, есть и положительные моменты, но пока британская система правосудия в большей мере страдает от увлечения истцов использованием генеративного ИИ. Компании начали считать деньги при внедрении ИИ, во многих случаях оно замедляется
22.06.2026 [07:55],
Алексей Разин
В сфере внедрения генеративного искусственного интеллекта, как отмечает Financial Times, наметились важные структурные изменения, которые заставляют клиентов пересматривать свой подход к финансированию процесса. Агентские решения вызывают рост расходов корпораций, и теперь они начали более вдумчиво оплачивать внедрение ИИ. 
Источник изображения: Anthropic Во многом такому перелому способствовала политика разработчиков ИИ типа OpenAI и Anthropic, которые после анализа собственных затрат поняли, что субсидируют многих клиентов, предоставляя им почти неограниченный доступ к вычислительным ресурсам в рамках подписки. Многие клиенты потребляют так много токенов, что расходы не покрываются выплатами в форме абонентской платы. Переход на соразмерную оплату потребляемых вычислительных ресурсов ужаснул многих клиентов. Например, небольшой разработчик ПО Workato после перехода на пропорциональную оплату токенов столкнулся с тем, что расходы на оплату услуг провайдеров ИИ в первый день выросли в семь раз. С этим явно нужно было что-то делать, и руководство компании стало два раза в неделю анализировать возможности сэкономить на использовании ИИ. В целом, как отмечает Financial Times, тактика потребителей систем ИИ сводится как к ограничению использования сторонних инструментов, за которые надо платить, так и к поиску более дешёвых альтернатив. В некоторых случаях последними становятся либо разворачиваемые на собственной инфраструктуре ИИ-модели с открытым исходным кодом, либо более доступные системы тех же китайских разработчиков. В условиях удалённого доступа китайские решения могут быть дешевле хотя бы в силу более низких тарифов на электроэнергию в КНР. С начала этого года китайские ИИ-модели обошли американских по объёму потребления токенов. Некоторые представители бизнеса ввели лимиты расходов на использование стороннего ИИ своими сотрудниками. Например, в Uber данная сумма ограничена $1500 на одного сотрудника в месяц. Расходы выросли по мере перехода пользователей от простого взаимодействия с чат-ботами к применению множественных ИИ-агентов. На одного человека в организации могут приходиться от 10 до 10 000 агентов, и все они непрерывно потребляют токены, за которые нужно платить. Аналитики Goldman Sachs ожидают, что к 2030 году потребление ИИ-токенов вырастет в 24 раза, и это само по себе усугубит дефицит чипов в ближайшие полтора года. Даже располагающие собственной вычислительной инфраструктурой компании типа Amazon (AWS) начали следить за эффективностью использования ресурсов. Этот облачный гигант начал бороться с фиктивной демонстрацией бурной ИИ-деятельности некоторыми сотрудниками, которые рассчитывали продемонстрировать руководству лояльность идее всеобщего погружения в такую активность. Meta✴✴ пришлось последовать примеру конкурента в апреле этого года. В любом случае, даже Amazon и Meta✴✴ зависят от сторонних провайдеров типа Anthropic, за услуги которых надо платить по коммерческим ставкам. Microsoft начала предлагать стремящимся к оптимизации затрат на ИИ клиентам новую услугу, позволяющую оптимальным образом выбирать используемые средства. Если для решения поставленной задачи достаточно ограничиться применением более дешёвой модели, то она поручается именно ей, а не отправляется по наиболее дорогому для клиента маршруту. Иногда при ручной маршрутизации запросов компании предпочитают использовать более старые и дешёвые ИИ-модели, не гонясь за самыми прогрессивными. При всём этом внутри компаний всегда находятся пользователи, которым не хватает вычислительных ресурсов для решения своих задач. Публичным компаниям становится сложнее оправдывать растущие расходы на ИИ перед акционерами и инвесторами. Маск проиграл Альтману в суде ещё раз — иск xAI к OpenAI о краже коммерческих тайн отклонён
16.06.2026 [05:09],
Алексей Разин
На этой неделе стартап xAI Илона Маска (Elon Musk), который теперь входит в состав вышедшей на IPO компании SpaceX, потерпел ещё одно поражение в суде в противостоянии с OpenAI. Суд отклонил претензии xAI в части предполагаемой попытки OpenAI получить доступ к коммерческой тайне истца путём переманивания одного из разработчиков чат-бота Grok. 
Источник изображения: Unsplash, Levart_Photographer Речь идёт о бывшем старшем разработчике Сюэчэне Ли (Xuechen Li), который работал в xAI с 2024 по 2025 годы, и якобы готовился передать OpenAI коммерческие секреты, связанные с разработкой ИИ-бота Grok. Истец строил свою линию на презентации, которую Ли предоставил OpenAI в момент, когда этот стартап пытался переманить его из xAI. Он указал на свой опыт предыдущей работы, сославшись на владение методом обучения ИИ-моделей с подкреплением и пост-обучения. По мнению xAI, по состоянию на июль 2025 года ChatGPT отставал в сфере комплексных суждений от Grok, а потому для OpenAI было важно получить в свой штат специалиста с профильными компетенциями. Судья Рита Линь (Rita Lin) отклонила иск xAI, исходя из суждения, что демонстрация навыков и опыта предыдущей работы является обычной частью собеседования при найме кандидатов на работу, и преследовать на этом основании всех работодателей было бы неразумно. По мнению судьи, представителям xAI не удалось доказать, что OpenAI склоняла инженера Ли к раскрытию коммерческой тайны стартапа, и что инженеры самой OpenAI были осведомлены о способности Ли раскрыть подобную информацию. OpenAI заявила в суде, что Сюэчэнь Ли никогда не работал в компании, а сама она никогда не получала коммерческих секретов xAI. По словам представителей OpenAI, компания просто не нуждается в заимствовании разработок xAI, поскольку последняя проигрывает конкурентную борьбу и не может справиться с оттоком кадров. Непосредственно Ли свою причастность к попыткам передать OpenAI коммерческую тайну xAI отрицает, бывший работодатель преследует его в суде по отдельному иску. OpenAI прокачала память ChatGPT — вскоре бот сможет помнить разное и для бесплатных пользователей
05.06.2026 [00:06],
Владимир Мироненко
OpenAI объявила об усовершенствовании функции запоминания ИИ-чат-бота ChatGPT, которая «стала умнее» и вскоре впервые станет доступна бесплатным пользователям. 
Источник изображения: OpenAI «Сегодня мы начинаем внедрение более мощной и масштабируемой системы синтеза памяти, разработанной для решения проблем устаревания, корректности и масштабируемости, которые мы наблюдаем при использовании памяти для сотен миллионов пользователей и на многолетних временных горизонтах в ChatGPT», — сообщила компания. Функция запоминания в ChatGPT обеспечивает чат-боту возможность изучать пользователя и запоминать его предпочтения с течением времени. Память предоставляет ChatGPT полезный контекст для естественного взаимодействия с пользователем без необходимости каждый раз начинать его с нуля. Компания сообщила, что более мощная и эффективная с точки зрения вычислений архитектура памяти построена на основе метода обработки информации Dreaming, который помогает заполнять пробелы в воспоминаниях, автоматически подбирая в фоновом режиме нужный контент из истории чатов. Выбранные с помощью Dreaming воспоминания можно просмотреть на странице сводки памяти. Здесь пользователь сможет получить информацию о том, что ChatGPT знает о нём, добавить или обновить сведения о себе, а также указать, какие темы ChatGPT должен затрагивать и когда. При улучшении памяти разработчики фокусировались на трёх основных моментах:
Компания также сообщила, что удваивает объём памяти ChatGPT для хранения данных. Подписчики версий ChatGPT Plus и Pro в США получат доступ к обновлённой системе памяти уже сегодня. Кроме того, было объявлено, что функция запоминания ChatGPT вскоре станет доступна бесплатным пользователям. «Недавние улучшения позволили сократить вычислительные ресурсы, необходимые для предоставления функции памяти на основе Dreaming бесплатным пользователям, примерно в пять раз, что позволяет начать внедрение этой функции для них в ближайшие недели и увеличить объём памяти для пользователей Plus и Pro», — сообщила OpenAI. Нейросеть Gemini начнёт объяснять пользователям, почему им стоит купить тот или иной товар
21.05.2026 [06:10],
Анжелла Марина
Компания Google представила масштабное обновление рекламных форматов в своей поисковой системе. Теперь пользователи увидят персонализированные объявления с развёрнутыми пояснениями от нейросети Gemini в ИИ-режиме (AI Mode). 
Источник изображения: Google В ИИ-режиме Google уже тестирует два формата: Conversational Discovery ads и Highlighted Answers. Первый тип рекламы генерирует индивидуальный ответ на конкретный запрос пользователя, а второй встраивает спонсорские товары в списки рекомендаций нейросети. Каждое такое объявление будет сопровождаться независимым пояснением, составленным алгоритмами Gemini на основе анализа продукта, с обязательной пометкой «Спонсировано». При этом пояснение генерируется отдельно от рекламного креатива, чтобы обеспечить объективность ответа. В ближайшие месяцы Google добавит аналогичные возможности в обычный поиск, не ограничиваясь режимом AI Mode. Разработчики внедрят формат AI-powered Shopping ads для помощи в выборе крупных покупок, таких как бытовая техника или электроника. При поиске конкретной категории товаров система даст объяснение, подчёркивающее актуальность конкретного предложения для потенциального покупателя. Дополнительно Google обновит процесс взаимодействия бизнеса с клиентами, заменив статические формы обратной связи интерактивным инструментом Business Agent for Leads. Внутри рекламного блока появится чат-бот, работающий на базе Gemini, который сможет моментально проконсультировать пользователей на основе данных с сайта рекламодателя, облегчая процесс изучения информации об услугах или образовательных программах. Изменения также затронут пилотную программу Direct Offers, запущенную в январе 2026 года при участии таких брендов, как Chewy, Gap и L’Oreal. Рекламодатели получат функцию объединения скидок, подарков и локальных купонов в единую кампанию, используя инструмент AI Brief для подбора аудитории, из которой ИИ будет собирать наиболее привлекательные наборы под каждый запрос. Параллельно туристические партнёры, включая Booking и Expedia, начнут транслировать свои спецпредложения непосредственно в интерфейсе ИИ-планировщика поездок. Обновлённые блоки Direct Offers будут естественным образом отображаться в ответах AI Mode по мере изучения вариантов для шоппинга. Для максимального охвата этих форматов компания рекомендует использовать инструменты AI Max for Search, AI Max for Shopping и Performance Max. При этом для продавцов, работающих по протоколу UCP, добавлена встроенная система оформления заказов (native checkout), позволяющая без лишних шагов конвертировать интерес пользователей в завершённые продажи. xAI теряет популярность, но Илон Маск ещё может вернуть стартап в гонку
12.05.2026 [09:34],
Алексей Разин
Представители OpenAI убеждены, что судебные претензии со стороны Илона Маска (Elon Musk) направлены на укрепление рыночных позиций его собственного стартапа xAI, основанного в 2023 году и недавно присоединённого к SpaceX. Независимая статистика говорит о снижении популярности xAI, но эксперты убеждены, что при наличии мотивации Маск способен всё исправить. 
Источник изображения: Unsplash, Мария Шалабаева В начале мая xAI заключила с Anthropic соглашение о сдаче в аренду вычислительных мощностей Colossus 1, которые xAI изначально планировала использовать для собственных нужд. Это может указывать на замедление темпов развития xAI и разработанного ею чат-бота Grok. Статистика AppMagic, на которую ссылается The Wall Street Journal, указывает на снижения количества скачиваний приложения Grok до 8,3 млн по итогам апреля против более чем 20 млн скачиваний в январе. Данные Recon Analytics гласят, что из более чем 260 000 американских пользователей ИИ-сервисов только 0,174 % в текущем квартале оплачивали подписку на Grok. Это почти столько же, как и годом ранее, и значительно меньше 6 %, соответствующих доле платных подписчиков конкурирующего ChatGPT. Сам Илон Маск в ходе своих апрельских судебных показаний назвал xAI «самой маленькой из ИИ-компаний». Для Grok проблемой остаётся отдалённость от нужд корпоративных пользователей, тогда как OpenAI и Anthropic активно развивают функции содействия ИИ в написании программного кода и автоматизации рутинных офисных задач при помощи ИИ-агентов. Опрос Enterprise Technology Research показал, что по итогам марта этого года 7 % корпоративных респондентов уже используют Grok или собираются это сделать. Годом ранее их доля не превышала 4 %, и хотя положительная динамика очевидна, в случае с Claude показатель вырос с 21 до 48 %, а у Google Gemini он увеличился с 27 до 40 %. При этом некоторые участники рынка верят, что Илон Маск ещё способен исправить ситуацию, если сконцентрируется на этой задаче. Он уже провёл в xAI серьёзную реорганизацию, и она может стать первым этапом реванша. Клиенты в стремительно меняющемся сегменте ИИ слабо привязаны к какой-то конкретной платформе. Если тот же Grok внезапно начнёт демонстрировать более впечатляющие результаты на форме конкурентов, то его популярность возрастёт довольно быстро. Anthropic занялась повышением привлекательности ИИ-бота Claude для простых пользователей
07.05.2026 [13:26],
Алексей Разин
Изначально Anthropic свои ИИ-решения ориентировала главным образом на корпоративных клиентов, поскольку это обеспечивало более быстрый рост как пользовательской базы, так и выручки. Теперь же компания решила сделать чат-бот Claude более привлекательным для рядовых пользователей, сообщает Bloomberg. 
Источник изображения: Anthropic В этом признался Майк Кригер (Mike Krieger), который возглавляет одну из лабораторий Anthropic, работающих над экспериментами с совершенствованием Claude. С прошлого года компания поручила своим специалистам научить чат-бота более качественной обработке запросов частного характера — например, имеющим отношение к здоровью, путешествиям и кулинарным рецептам. По словам Кригера, которые прозвучали из его уст на конференции для разработчиков в Сан-Франциско, сейчас Anthropic сконцентрирована на повышении качества и скорости работы чат-бота, а также устранении шероховатостей. В частности, ведётся работа по сокращению времени, необходимого для формирования и отправки пользовательских запросов после запуска мобильного приложения. Разработчикам Claude удалось сократить это время с прежних пяти-шести секунд до одной. Запущенный в 2023 году чат-бот Anthropic довольно быстро завоевал расположение рядовых пользователей, поскольку помимо рекламы в США, этому способствовали некоторые «вирусные истории» и даже скандал с исключением компании из числа доверенных поставщиков Пентагона. Сейчас Claude в магазине приложений Apple App Store находится на втором месте по популярности после ChatGPT конкурирующей OpenAI, обходя при этом Google Gemini. К марту Claude привлекал более 1 млн новых пользователей ежедневно. Сейчас, на волне такой популярности, Anthropic даже испытывает нехватку вычислительных мощностей. Эпидемию одиночества не вылечить ИИ-ботами — они лишь усиливают изоляцию
07.05.2026 [09:28],
Дмитрий Федоров
Одиночество толкает людей к ИИ-чат-ботам, но общение с ними лишь усиливает изоляцию. К такому выводу пришли психологи Данигэн Фолк (Dunigan Folk) и Элизабет Данн (Elizabeth Dunn), год наблюдавшие за 2149 взрослыми из четырёх англоязычных стран. Работа опубликована в журнале Psychological Science и ставит под сомнение надежды на то, что ИИ-компаньоны помогут справиться с эпидемией одиночества. 
Источник изображения: Kristina Tripkovic / unsplash.com Фолк и Данн четырежды за двенадцать месяцев опросили жителей Великобритании (50 %), США (28 %), Канады (14 %) и Австралии (8 %). Все четыре волны опросов прошли 979 человек, три — 466, две — 395, одну — 309. Средний возраст участников составил 40 лет, мужчин и женщин оказалось почти поровну. Каждый раз респондентов спрашивали, как часто за минувшие четыре месяца они обращались к ИИ-чат-ботам за советом по жизненным вопросам, вели с ними повседневные разговоры или просто искали компанию. Одновременно анкеты фиксировали уровень эмоциональной изоляции опрашиваемых и более широкий показатель их социальной связанности с окружающими. Исследователи учитывали и крупные события в жизни участников опроса: переезд, расставание, начало устойчивых романтических отношений, рождение ребёнка. В каждой волне от 26 до 30 % опрошенных сообщали, что за предыдущие четыре месяца пользовались чат-ботами в социальных целях — например, обращались к ним за советом по жизненным вопросам, вели с ними повседневные разговоры или искали у них ощущение общения. При этом средняя частота таких обращений за год наблюдения статистически значимо не изменилась. Для эмоциональной изоляции ключевая закономерность оказалась двунаправленной: участники, которые чувствовали себя более эмоционально изолированными, через четыре месяца, как правило, чаще обращались к чат-ботам, а рост такого использования, в свою очередь, предсказывал более высокую эмоциональную изоляцию в следующей волне. Крупные жизненные события с последующим ростом обращений к ИИ-чат-ботам связаны не были. С более широким показателем социальной связанности картина оказалась иной. Люди, ощущавшие более слабую связь с социальным окружением, тоже чаще обращались к чат-ботам четыре месяца спустя, однако само по себе такое использование не предсказывало статистически значимого дальнейшего снижения социальной связанности. Из всех жизненных событий только разрыв отношений был связан с последующим ослаблением социальной связанности, но обращений к ИИ-чат-ботам после него не прибавлялось. Остальные события — переезд, начало устойчивых романтических отношений, рождение ребёнка — не показали статистически значимой связи с последующей социальной связанностью. Авторы предполагают, что люди могут снова и снова обращаться к ИИ-чат-ботам, потому что они доступны в любой момент и убедительно имитируют живое общение. Но такие сравнительно лёгкие и поверхностные контакты, по мнению Фолка и Данн, могут вытеснять более ценное общение с реальными людьми. У ИИ нет собственной внутренней жизни, поэтому он не способен на подлинную ответную откровенность, важную для полноценных долгосрочных человеческих отношений, и именно поэтому привязанность к чат-ботам может со временем не удовлетворять социальные потребности человека, а усиливать чувство одиночества. «В совокупности эти результаты дают первые свидетельства того, что одиночество может побуждать людей искать общение с чат-ботами, но такое использование со временем способно усугублять чувство одиночества. Тем не менее мы призываем к осторожности в выводах, учитывая предварительный характер нашего анализа», — заключили авторы. Наблюдательный характер исследования не позволяет делать однозначных причинно-следственных выводов, а все данные получены из ответов самих участников, что не исключает систематических искажений. Google готова показывать рекламу в Gemini — OpenAI уже делает это в ChatGPT
30.04.2026 [19:51],
Анжелла Марина
Руководство Google подтвердило готовность интегрировать рекламные объявления в приложение Gemini, отказавшись от прежней политики полного их отсутствия. Решение продиктовано стремлением компании масштабировать продукт и монетизировать растущую аудиторию пользователей Gemini. 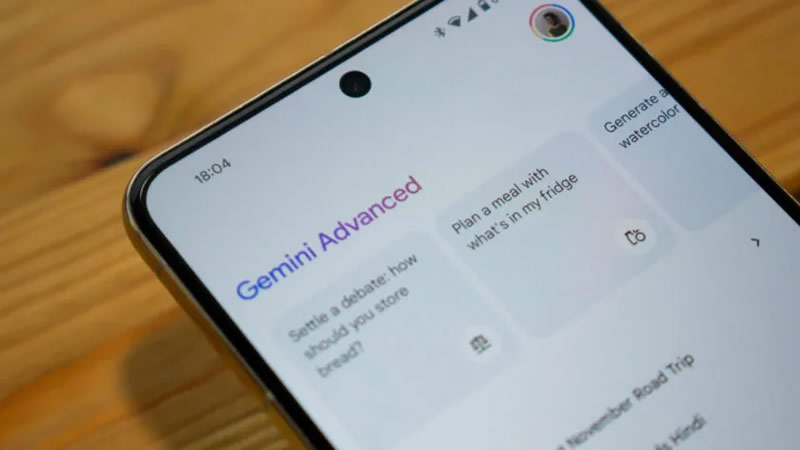
androidauthority.com По сообщению Android Authority со ссылкой на Business Insider, в ходе конференции по итогам первого квартала 2026 года главный коммерческий директор Google Филипп Шиндлер (Philipp Schindler) подтвердил готовность компании разместить рекламу в приложении Gemini. Он уточнил, что если рекламный формат покажет свою эффективность в ИИ-режиме поиска Google (AI Mode Search), он будет применён и в Gemini. Ранее корпорация не торопилась с внедрением рекламы, но теперь её позиция изменилась. Шиндлер обосновал изменение планов тем, что грамотно встроенная реклама предоставляет пользователям полезную коммерческую информацию и помогает развивать продукты для миллиардов людей. Это заявление согласуется с декабрьским сообщением издания Adweek, которое ещё раньше сообщало о планах Google разместить рекламные объявления в Gemini в течение 2026 года. Таким образом, ожидаемые изменения стали логичным шагом в стратегии монетизации ИИ-сервисов компании. Ранее мы также сообщали о том, что Google не исключает появление рекламы в Gemini. Несмотря на наличие платных подписок, общее число которых достигло 350 миллионов человек, дохода от них может быть недостаточно для поддержания полностью бесплатного режима работы чат-бота. Ситуация также усугубляется действиями конкурентов. В частности, компания OpenAI уже начала показ рекламы пользователям бесплатной версии ChatGPT. Google, вероятно, последует этому тренду, чтобы сохранить экономическую устойчивость своего флагманского ИИ-продукта на фоне растущих затрат на инфраструктуру. OpenAI заявила, что ChatGPT научился считать буквы в словах — но на деле он продолжает ошибаться
29.04.2026 [10:59],
Владимир Мироненко
Распространённой проблемой больших языковых моделей, используемых в чат-ботах с искусственным интеллектом, являются уверенные ошибки или, другими словами, ложь. Например, до недавних пор ChatGPT не мог правильно ответить на вопрос, сколько букв R в слове strawberry (клубника). 
Источник изображения: Levart_Photographer/unsplash.com Долгое время чат-бот выдавал неверный ответ, утверждая, что в слове strawberry буква R не встречается три раза. У других ИИ-моделей нередко наблюдалась аналогичная проблема. Еще одна распространённая ошибка: в ответ на вопрос «Я хочу сегодня помыть машину, но автомойка всего в 50 метрах. Стоит ли мне идти пешком, чтобы доехать туда?» чат-бот ChatGPT часто рекомендовал идти пешком, несмотря на очевидную логическую нестыковку. 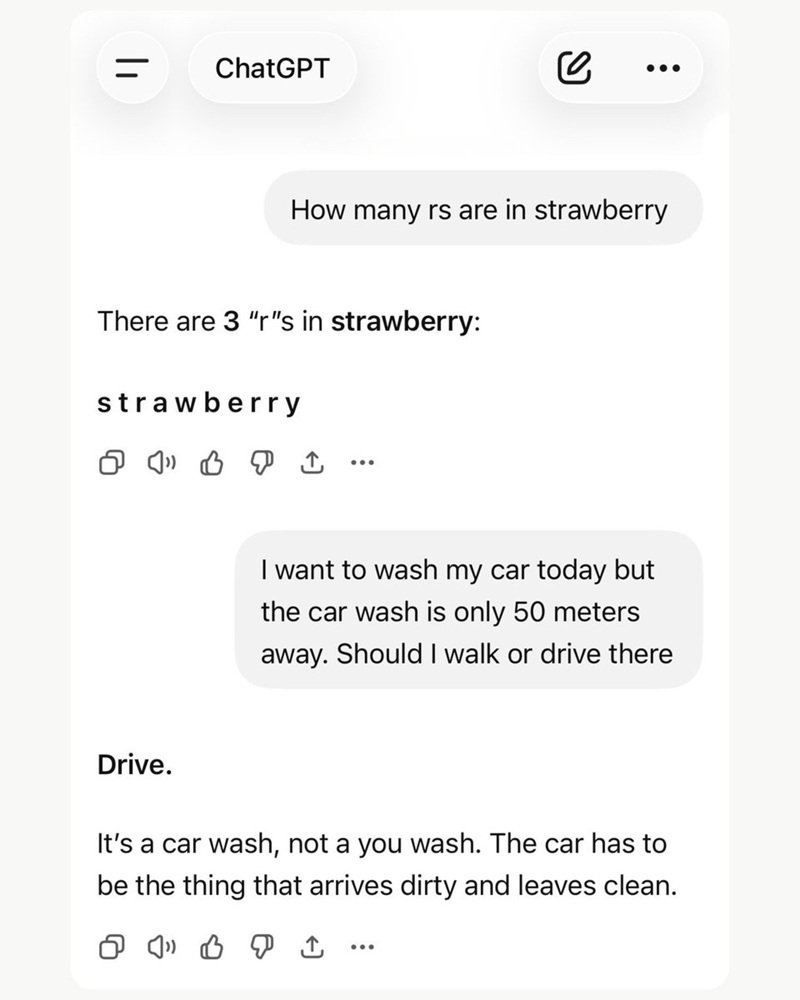
Источник изображений: 9to5google.com Одной из самых больших проблем, как пишет 9to5google.com, остается частота, с которой ИИ-инструменты уверенно лгут пользователям. Если информация неверна, чат-бот этого может не заметить, и, если указать на ошибку, ИИ может упорствовать и продолжать ошибаться, утверждая при этом, что он прав. Эта проблема рассматривается как опасность ИИ-инструментов, помимо того, что такие ответы просто раздражают с учётом потребляемых ИИ ресурсов. Сегодня OpenAI сообщила, что «наконец-то» ChatGPT может правильно ответить на вопросы по поводу количества букв R в слове strawberry и нужно ли идти к заправке для того, чтобы пополнить бак машины бензином. Но, как отметил 9to5google.com, существует подозрение, что это могут быть жёстко закодированные решения, поскольку в других случаях чат-бот продолжает ошибаться по той же логике. Например, на вопрос «Сколько букв R в слове cranberry (клюква)?» он постоянно отвечает: «В слове cranberry одна буква R», что, конечно же, неверно. 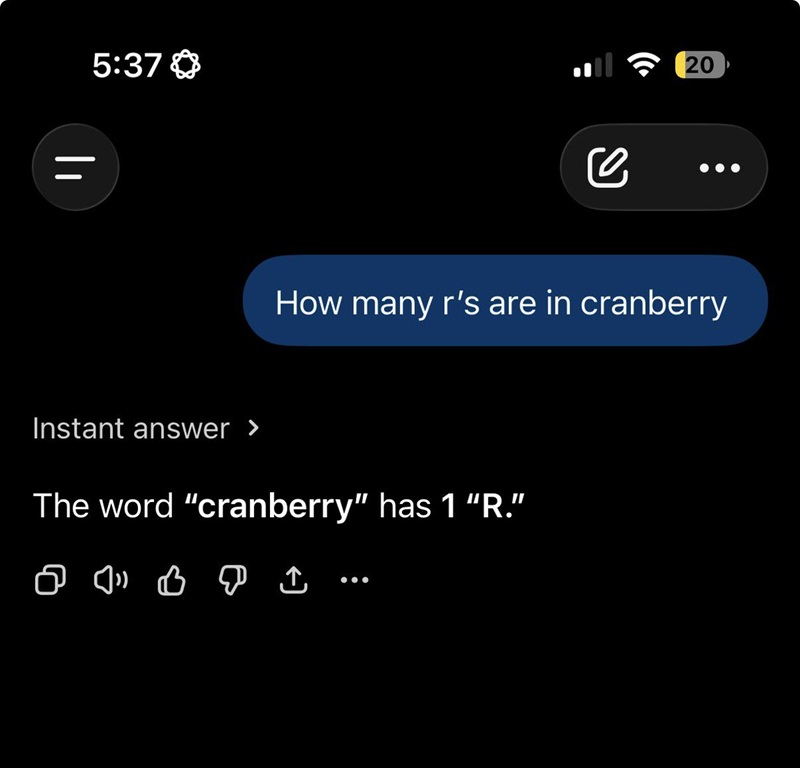 То есть, проблема по-прежнему существует, хотя OpenAI с гордостью объявила о её решении. ChatGPT Plus потеряет 80 % подписчиков в этом году — зато более дешёвый тариф ChatGPT Go расширит аудиторию в 37 раз
29.04.2026 [09:17],
Алексей Разин
Ещё вчера появилась общая информация о том, что руководство OpenAI обеспокоено снижением количества подписчиков и замедлением роста выручки, но подробности этого отчёта позволяют понять, как компания собирается бороться с данными тенденциями. Тарифный план ChatGPT Go за $8 в месяц должен увеличить количество подписчиков в текущем году с 3 млн до 112 млн человек. 
Источник изображения: OpenAI В некоторых регионах ChatGPT Go доступен за $5 в месяц. А вот количество желающих платить по $20 в месяц за доступ к тарифу ChatGPT Plus, по данным компании, в текущем году сократится почти в пять раз, с 44 млн до 9 млн человек. Кроме того, прогнозы OpenAI гласят, что количество подписчиков самого дорогого плана ChatGPT Pro вырастет в этом году вдвое, но их доля в общем количестве не превысит 1 %, поэтому рассчитывать именно на данный ценовой сегмент компания просто не может. Впрочем, даже приток пользователей к тарифу ChatGPT Pro не сможет компенсировать упущенную выручку из-за отказа клиентов от более дорогого тарифа ChatGPT Plus, если проанализировать динамику. Выручка OpenAI от подписок по итогам текущего года всё равно сократится на $155 млн. Кроме того, привлечение 109 млн новых подписчиков наверняка увеличит расходы OpenAI, и не факт, что выручка от подписок на этом направлении сможет их перекрыть. ОАЭ намерены перевести половину госсектора под управление агентного ИИ за два года
24.04.2026 [22:55],
Дмитрий Федоров
Объединённые Арабские Эмираты (ОАЭ) объявили план перевода 50 % государственного сектора, услуг и операций на агентный ИИ в течение двух лет. Инициативу представил шейх Мохаммед ибн Рашид Аль Мактум (Mohammed bin Rashid Al Maktoum). Страна позиционирует эту программу не как поэтапную цифровизацию, а как структурную перестройку госуправления — переход к модели автономного правительства. 
Источник изображений: ChatGPT / 3DNews Агентный ИИ — класс систем, способных не только генерировать аналитику, но и действовать самостоятельно: выполнять задачи, адаптироваться к меняющимся вводным данным и повышать собственную эффективность. В государственном контексте такие системы могут охватывать автоматизацию обращений граждан, оказания услуг и принятие операционных решений. Объявление примечательно тем, что инвестиции в ИИ подаются как инструмент национальной конкурентоспособности. ОАЭ годами выстраивали для этого основу: инфраструктуру цифровой идентификации, сервисы «умного правительства», суверенные облачные мощности, стратегии работы с данными и национальные ИИ-программы. Нынешний шаг выводит эти наработки за рамки цифрового обеспечения — к операционной автономии. Маниш Ранджан (Manish Ranjan), директор по исследованиям ПО и облачных технологий в IDC EMEA, считает, что успех программы определят не столько вычислительные мощности, сколько готовность госведомств перестроить процессы, на которых будет работать агентный ИИ. По его словам, ключевым фактором станет уровень подготовки данных, рабочих процедур и управленческих правил: для федерального государства такая перестройка — это многолетняя программа управления изменениями, а не обычное технологическое внедрение.  Мохамед Рушди (Mohamed Roushdy), директор по информационным технологиям Reem Finance, назвал цель амбициозной, но достижимой с учётом цифровой зрелости страны. «ОАЭ начинают не с нуля», — подчеркнул Рушди, указав на развитые платформы UAE Pass и TAMM, устойчивые государственные инвестиции и широкое внедрение ИИ в госструктурах. При этом он выделил серьёзные барьеры: фрагментацию унаследованных систем, неравномерную готовность данных и ограничения суверенных ИИ-мощностей, способные замедлить прогресс в работе с чувствительными нагрузками. Вопросы доверия, вероятно, определят следующую стадию ИИ-стратегии в госсекторе. По мере того как правительства переходят от ИИ как инструмента повышения производительности к системам, участвующим в принятии решений, прежних моделей управления рисками становится недостаточно. Ранджан считает, что руководителям госсектора нужно закладывать участие человека уже на этапе проектирования: заранее разграничивать решения, которые можно полностью автоматизировать, решения, требующие человеческой проверки, и зоны, где ответственность должна оставаться за человеком. Если в электронном государстве цифровое доверие строилось прежде всего на кибербезопасности, защите персональных данных и надёжности сервисов, то в агентных системах к этим требованиям добавляются объяснимость решений, постоянный надзор за моделями и подотчётность действий, выполняемых ИИ.  Инициатива ОАЭ поднимает и региональный вопрос — устанавливает ли страна планку, которой другие члены Совета сотрудничества арабских государств Персидского залива (GCC) будут вынуждены достичь. По мнению Ранджана, скорее всего да. «На протяжении последнего десятилетия эталоном в сфере государственных технологий GCC была цифровая зрелость — доступность электронных услуг и внедрение цифровой идентификации. ОАЭ фактически поднимают эту планку и заменяют прежний эталон готовностью к агентному ИИ», — заявил Ранджан. Если тренд закрепится, последствия выйдут за рамки трансформации госуправления и могут ускорить инвестиции в суверенные облака, платформы управления ИИ, ПО для автоматизации, цифровую инфраструктуру и развитие кадрового потенциала госсектора по всему региону. В этом случае обучение в сфере ИИ предстоит пройти каждому федеральному госслужащему. Повышение квалификации всё чаще входит в национальные ИИ-стратегии, однако масштаб и обязательный характер программы говорят о том, что правительство рассматривает развитие кадров как неотъемлемую часть перехода к операционной автономии. Потребительские ИИ-боты в 80 % случаев ставят неверные диагнозы, показало исследование
14.04.2026 [13:23],
Алексей Разин
Универсальность популярных чат-ботов с точки зрения поиска необходимой информации, как выясняется, не делает их пригодными для постановки точных медицинских диагнозов при ограниченном наборе данных. Более чем в 80 % случаев чат-боты ставят ошибочный диагноз, что делает их непригодными для замены консультации реального специалиста в области медицины. 
Источник изображения: Unsplash, Elen Sher Опубликованное на страницах Jama Network Open исследование, на которое ссылается Financial Times, использовало 29 описаний клинических случаев из справочной медицинской литературы для проверки качества определения диагноза популярными чат-ботами. Исследование показало, что при передаче чат-боту ограниченной информации о симптомах большие языковые модели затрудняются с выбором возможных диагнозов, и чаще всего сводят всё к единственному варианту, на который в действительности нельзя полагаться в дальнейшем лечении. Если входные данные достаточно подробные, то таких проблем с постановкой точного диагноза уже не наблюдается. Медицинские данные в ходе эксперимента передавались чат-ботам поэтапно, включая историю болезни, результаты осмотров и лабораторных анализов. Чат-ботам задавались вопросы на тему диагностики заболеваний, измерялась точность и полнота ответов. В выборку проверяемых ИИ-моделей попали два десятка популярных чат-ботов, включая разработанные OpenAI, Anthropic, Google, xAI и DeepSeek. При отсутствии полной информации о состоянии пациента более чем в 80 % все они демонстрировали склонность к постановке некорректного диагноза. Чем полнее была информация, тем точнее были результаты. В лучших случаях точность превышала 90 %, в среднем варианте ошибочные диагнозы ставились менее чем в 40 % случаев. Google и Anthropic заявили, что их чат-боты при попытке пользователей получить медицинские рекомендации настоятельно рекомендуют обращаться к специалистам. OpenAI указывает в правилах использования своих сервисов, что они не должны использоваться для получения медицинских рекомендаций, требующих наличия соответствующей лицензии. xAI и DeepSeek свои комментарии на этот счёт ресурсу Financial Times не предоставили. Некоторые из указанных разработчиков создают узкоспециализированные медицинские модели. Разработанная Google AMIE, например, показывает неплохие результаты, но на её заключения сложно полагаться в полной мере, как отмечают специалисты в области медицины, поскольку живой доктор в значительной степени полагается на визуальную оценку состояния пациента. При этом такие ИИ-модели имеют право на жизнь в тех регионах, где имеются проблемы с доступом к качественной медицинской помощи в классическом её понимании. Уже в этом году OpenAI рассчитывает выручить на рекламе $2,5 млрд, а к концу десятилетия увеличит сумму в 40 раз
10.04.2026 [08:22],
Алексей Разин
Стремление руководства OpenAI донести до инвесторов всю информацию о собственном бизнес-плане выражается не только в рассказе о расходах, но и ожидаемых доходах. Стартап по итогам текущего года в сфере рекламы рассчитывает выручить $2,5 млрд, а к 2030 году надеется увеличить эту сумму до $100 млрд. Для этого количество еженедельных активных пользователей сервисов OpenAI должно вырасти до 2,75 млрд человек. 
Источник изображения: OpenAI Подобные прогнозы стали известны благодаря изданию Axios, на которое ссылается агентство Reuters. Соответствующие планы OpenAI недавно продемонстрировала своим инвесторам в профильных презентациях. Для создателей чат-ботов и прочих ИИ-сервисов реклама и поступления с подписок являются основными источниками доходов, поэтому при построении бизнес-стратегии компании уделяют этим направлениям особое внимание. В следующем году выручка OpenAI от рекламы должна вырасти с $2,5 до $11 млрд, как отмечает источник, а в 2028 году вырасти до $25 млрд. Ещё через год рекламная выручка OpenAI должна увеличиться до $53 млрд, а к 2030 году она почти удвоится, если всё пойдёт по плану. Напомним, что примерно к этому моменту OpenAI рассчитывает впервые выйти в прибыль. Эксперимент по демонстрации рекламы в ChatGPT компания проводит с января этого года для отдельных категорий пользователей в США. Через шесть недель с начала этого эксперимента приведённая к году выручка от демонстрации рекламы выросла до $100 млн. Размещать свою рекламу в ChatGPT выразили желание более 600 компаний. В любом случае, OpenAI ещё очень далека от рекламных доходов основных конкурентов. Google в прошлом году на рекламе выручила почти $295 млрд, а Meta✴✴ Platforms — более $196 млрд. Пока OpenAI не наблюдает отторжения рекламы своими пользователями, соответствующие объявления просматриваются не хуже, чем в целом по отрасли. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



