|
Опрос
|
реклама
Быстрый переход
Nvidia отчиталась о прогрессе в разработке DLSS 5 с нейронным рендерингом
21.07.2026 [18:26],
Николай Хижняк
Nvidia в рамках конференции SIGGRAPH 2026, которая проходит в Лос-Анджелесе (США), отчиталась о прогрессе в разработке новой технологии нейронного рендеринга DLSS 5. Несмотря на первоначальную негативную реакцию геймеров, компания продолжает развивать технологию и подготовила новую демонстрацию того, как должна работать DLSS 5. 
Источник изображений: Nvidia Один из ключевых аспектов новой технологии заключается в том, что разработчики игр смогут выбирать из трёх моделей DLSS 5, каждая из которых обеспечивает разный уровень структурной интенсивности, глобального освещения, детализации текстур и многого другого. Модели, обозначенные как Model A, Model B и Model C, могут быть адаптированы к конкретным сценам или определённым персонажам. Кроме того, их можно будет комбинировать в соответствии со своими требованиями. Каждая модель имеет различное количество параметров. Другими словами, некоторые модели потребляют больше памяти. Однако, все они, как правило, хорошо работают с использованием одного графического процессора. Напомним, что в рамках первой демонстрации DLSS 5 компания Nvidia использовала две видеокарты RTX 5090. Релизная же версия DLSS 5 потребует только одну видеокарту RTX. Технические требования к DLSS 5 пока не озвучены.  Nvidia ещё раз подчеркнула, что DLSS 5 позволяет сохранить художественный замысел создателей игр, а не меняет его. Противоположное мнение у геймеров сложилось из первой демонстрации, где показанные изображения персонажей казались фактически заново перерисованными ИИ. Nvidia заявляет, что каждый отдельный объект, сцена и игровые настройки могут быть настроены в соответствии с видением разработчика. Это один из вызовов, с которым компания столкнулась при разработке DLSS 5. Nvidia отмечает, что поддержание визуальной идентичности, семантики объектов и поз персонажей, а также семантики выходного освещения, движения и художественного оформления имеет решающее значение. В рамках этих строгих параметров DLSS 5 применяет фотореализм материалов для повышения визуальной привлекательности. Ниже можно увидеть настройку применяемой модели, где есть регулируемые параметры, которые можно задать для каждой сцены и каждого персонажа. 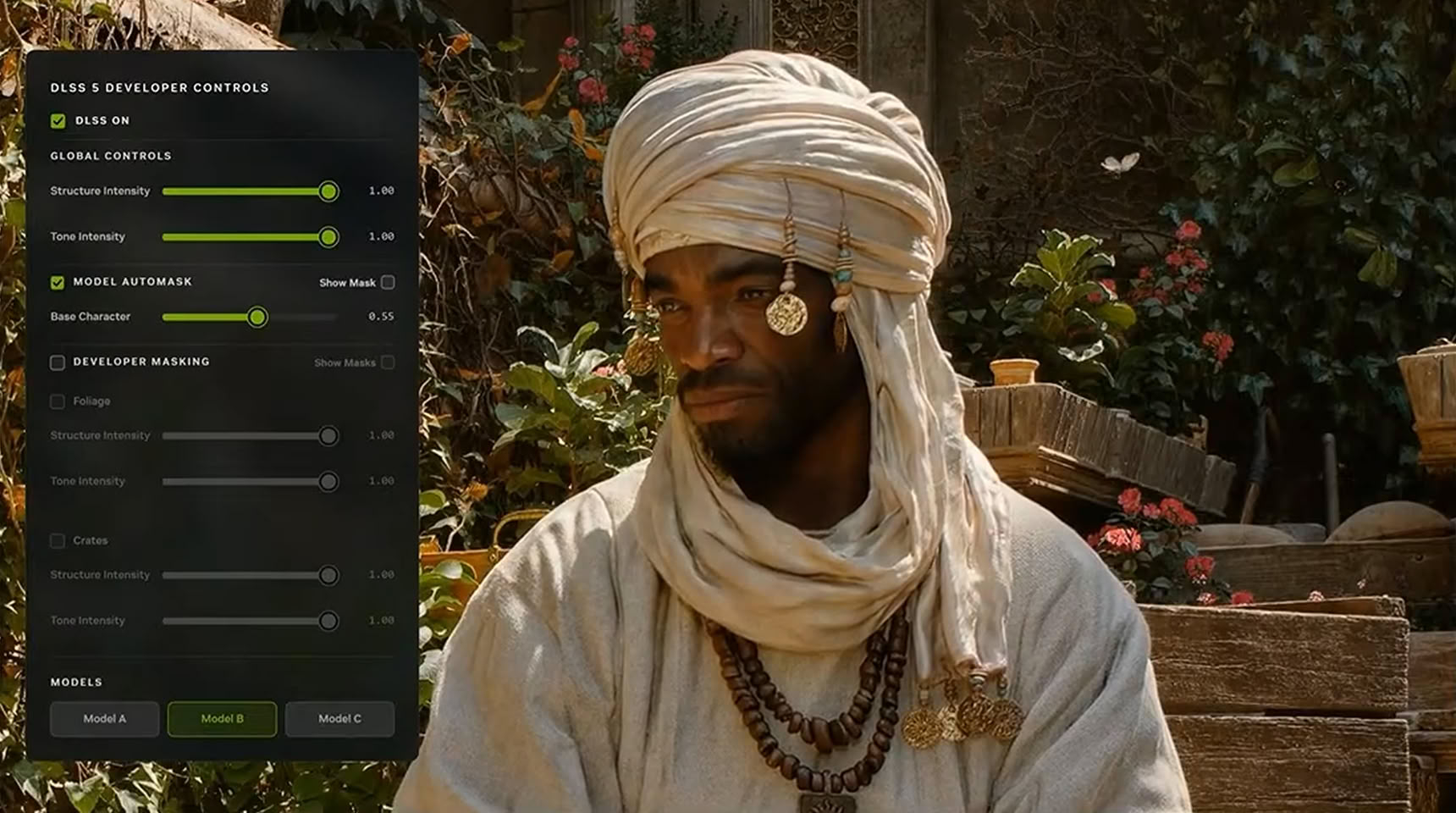 Вторая сложность, которую Nvidia пришлось решать при разработке DLSS 5, — это временная потоковая обработка. Традиционные генераторы видео на основе генеративного ИИ обрабатывают данные по частям, анализируя каждый кадр и генерируя пакет кадров одновременно. Однако рендеринг в реальном времени требует немедленной генерации, кадр за кадром. Поскольку DLSS 5 использует векторы движения из игрового движка, она может мгновенно генерировать дополнительные текстуры без задержки. Это приводит к отсутствию мерцания или искажения изображения, поскольку DLSS 5 точно знает, куда прикрепить текстуру, и мгновенно выполняет её генерацию. Примеры с включённой DLSS 5 и без неё

Смотреть все изображения (8)



Смотреть все изображения (8) Последняя сложность с DLSS 5 — это скорость. Для рендеринга кадра в разрешении 4K с 8,3 млн пикселей со скоростью более 60 кадров в секунду Nvidia достигает этого менее чем за 16 мс. При этом большая часть времени обработки приходится на игровой движок, а не на модель DLSS 5. Технология настолько эффективна, что пользователи не заметят никаких задержек во время игры, утверждает Nvidia. Хотя компания подчёркивает эффективность DLSS 5 в использовании видеопамяти, пока остаётся неясным, будут ли игры в 4K на видеокартах с меньшим объёмом памяти выглядеть хуже, чем на картах с большим объёмом видеопамяти. Поскольку запуск DLSS 5 ожидается этой осенью, Nvidia ещё предоставит общие системные требования и дополнительные подробности, но улучшения по сравнению с оригинальной демоверсией пока выглядят многообещающими. Учёные создали искусственные нейроны, сигналы которых живой мозг воспринял как свои
02.05.2026 [21:16],
Геннадий Детинич
Инженеры из Северо-Западного университета (Northwestern University) впервые методом печати создали искусственные нейроны, способные не просто имитировать, но и напрямую взаимодействовать с живыми клетками мозга, поскольку устройство генерирует электрические сигналы, по своей форме и временным характеристикам идентичные биологическим. Это открывает прямую возможность создания интерфейса «человек—компьютер», а также нейроморфных компьютеров, имитирующих работу мозга. 
Источник изображения: Northwestern University Основой интересной технологии стали чернила из наночешуек дисульфида молибдена и графена. С их помощью на гибкую полимерную подложку методом струйного напыления наносился рисунок, после чего подложка подвергалась воздействию тока для частичного разложения. Весь фокус оказался в сохранении части связующего полимерного материала. Этот процесс приводил к формированию тонких проводящих путей — филаментов, или нитей. Тем самым напечатанные элементы могли напрямую влиять на форму и силу протекающего по ним тока, что удивительным образом совпало со спектром сигналов нейронной активности — от одиночных спайков до пакетных «очередей» импульсов. Совпадение активности искусственных нервных сигналов с природными было подтверждено экспериментально: когда искусственные нейроны подключили к срезам тканей мозжечка мыши, живые клетки отреагировали на них как на свои собственные, активировав нейронные цепи. Это стало первой демонстрацией того, что напечатанные нейроны могут генерировать сигналы правильной формы и в верном временном диапазоне, не будучи при этом ни слишком медленными, как предыдущие органические аналоги, ни слишком быстрыми, как электронные. Представленная разработка прокладывает путь к созданию интерфейсов «мозг—компьютер» следующего поколения, нейропротезов для восстановления слуха, зрения и движения, а также может решить проблему чрезмерного энергопотребления искусственного интеллекта. Если нейроморфным вычислениям удастся добиться энергоэффективности мозга, которая, по словам авторов, на пять порядков превосходит эту характеристику для классических компьютеров, данная технология в будущем позволит создавать вычислительные системы, требующие для работы кардинально меньше ресурсов. Nvidia анонсировала DLSS 5 с нейронным рендерингом — ИИ добавит фотореализм в каждую игру уже осенью
16.03.2026 [22:40],
Николай Хижняк
Глава компании Nvidia Дженсен Хуанг (Jensen Huang) анонсировал на конференции GTC 2026 технологию DLSS 5. Новая версия апскейлера знаменует переход от функций, ориентированных на повышение производительности, к генерации изображений для повышения визуального качества. Выпуск технологии планируется осенью этого года. 
Источник изображений: Nvidia Компания заявляет, что новая версия DLSS использует модель нейронного рендеринга в реальном времени, которая добавляет фотореалистичное освещение и детализацию материалов к игровым кадрам. 
 По данным Nvidia, DLSS 5 берёт данные о цвете и векторах движения из каждого игрового кадра, а затем применяет модель искусственного интеллекта, которая улучшает освещение и отклик материалов, оставаясь при этом привязанной к исходной 3D-сцене. Компания заявляет, что система работает в реальном времени с разрешением до 4K и разработана для обеспечения детерминированного и согласованного вывода от кадра к кадру, что является ключевым требованием для игр. 
 DLSS 5 позиционируется как обновление визуального конвейера, а не как ещё один этап генерации кадров. Nvidia заявляет, что модель обучена понимать элементы сцены, такие как кожа, волосы, ткань и условия освещения, а затем использовать эту информацию для улучшения эффектов, таких как подповерхностное рассеивание, блеск ткани и взаимодействие света с волосами. Разработчики также получат элементы управления интенсивностью, цветокоррекцией и маскированием, а интеграция будет продолжаться через существующую структуру Nvidia Streamline, используемую для DLSS и Reflex.   Поддержка DLSS 5 уже согласована с несколькими крупными издателями и студиями, включая Bethesda, Capcom, Ubisoft, NetEase, Tencent и Warner Bros. Games. Первыми играми, которые предложат поддержку DLSS 5, станут: Starfield, Assassin’s Creed Shadows, Hogwarts Legacy, Resident Evil Requiem, Delta Force, Naraka: Bladepoint и The Elder Scrolls IV: Oblivion Remastered. 
 По данным Digital Foundry, Nvidia использовала две видеокарты RTX 5090 для демонстрации работы технологии. Однако релизная версия DLSS 5 потребует только одну карту RTX. «Компания Nvidia использовала две видеокарты RTX 5090 для своих демонстраций: одна запускала игру, а другая работала исключительно с технологией DLSS 5. Использование двух GPU сейчас необходимо, поскольку DLSS 5 ещё предстоит пройти долгий путь в плане оптимизации — как с точки зрения производительности, так и с точки зрения объёма использующейся видеопамяти. Однако DLSS 5 разработана для использования на одном графическом процессоре, и именно в таком режиме она будет выпущена позже в этом году. Насколько масштабируемой она окажется, также ещё предстоит выяснить, но, как и в случае с другими технологиями DLSS, Nvidia сообщает, что вычислительные затраты увеличиваются с разрешением», — говорит Digital Foundry. Nvidia пока не сообщает, какие графические архитектуры получат поддержку DLSS 5. Учёные начали строить дата-центры из биокомпьютеров на клетках человеческого мозга
10.03.2026 [15:22],
Алексей Разин
Учёные и изобретатели давно пытаются подсмотреть удачные решения у природы, а потому стартап Cortical Labs разрабатывает биокомпьютеры, сочетающие выращенные на основе клеток человеческой крови нейроны человеческого мозга и полупроводниковые чипы. Существующие экземпляры таких гибридных систем уже научились играть не только в Pong, но и в Doom. И из таких систем уже начали строить дата-центры. 
Источник изображения: Cortical Labs, Bloomberg Австралийский стартап Cortical Labs уже запустил небольшой центр обработки данных на основе биокомпьютеров CL1 в Мельбурне, а в Сингапуре аналогичная экспериментальная площадка возводится в сотрудничестве с DayOne Data Centers. Исследователи разработали гибридный процессор, который отправляет компьютерные команды выращенным в лабораторных условиях клеткам человеческого головного мозга, а затем пытается интерпретировать их ответы. В отличие от мощных суперкомпьютеров, такая биологическая гибридная система потребляет очень мало электроэнергии. По сути, один модуль CL1 по уровню энергопотребления сопоставим с карманным калькулятором. Пока первый биологический суперкомпьютер на основе систем CL1 не может похвастать высоким быстродействием, но его возможности постоянно совершенствуются. Сперва создатели научили его играть в Pong, а недавно подняли планку мастерства до всем известного Doom. Специализированный ЦОД в Мельбурне разместит 120 модулей CL1, а новая площадка в Сингапуре сможет приютить до 1000 таких модулей, хотя и поэтапно. Курировать работу второго ЦОД будет Национальный университет Сингапура. Топ-менеджер Intel: в половине отгруженных в этом году ПК будет ускоритель ИИ
18.02.2026 [18:12],
Сергей Сурабекянц
Президент японского подразделения Intel Макото Оно (Makoto Ohno) уверен, что 2026 год станет решающим для ПК с поддержкой ИИ. По его прогнозам, в этом году на ПК с ИИ придётся примерно половина от общего объёма поставок за год. По предварительным оценкам IDC, в 2026 году будет отгружено около 260 млн ПК. Если прогноз Макото Оно сбудется, 130 млн из них будут оснащены нейронным процессором (NPU) или другим чипом для локальной обработки данных с помощью ИИ. Тем не менее Макото Оно признал, что основной причиной покупки ПК с ИИ могут оказаться не его возможности по ускорению искусственного интеллекта, а повышенная производительность в широком спектре прикладных задач и более длительное время автономной работы благодаря новым поколениям оптимизированных процессоров. «Прогнозируется, что к 2026 году […] каждый второй компьютер будет ПК с искусственным интеллектом. Однако, учитывая текущую ситуацию, причинами выбора ПК с ИИ являются его высокая производительность и длительное время автономной работы, обеспечиваемое использованием нейронного процессора. Другими словами, важно учитывать тот факт, что люди в настоящее время покупают ПК с ИИ не для того, чтобы использовать его функции, связанные с ИИ», — отметил Макото Оно. По словам Макото Оно, Intel хочет в кратчайшие сроки сделать ПК с ИИ нормой, а не исключением. Компания признает, что в настоящее время эти ПК в основном воспринимаются как продукты высокого класса, и стремится как можно быстрее изменить это восприятие и вывести такие устройства на массовый рынок. Intel также подчеркнула необходимость большего количества приложений, которые действительно используют возможности ПК с ИИ, с целью достижения точки, когда люди будут покупать ПК с ИИ для конкретной цели, а не просто потому, что это новейший продукт. Грибная электроника приближается — учёные превратили мицелий шиитаке в нейронную сеть
28.10.2025 [12:26],
Геннадий Детинич
В последние годы учёные активно исследуют возможность использования в электронике грибного мицелия как естественной нейронной сети. С его помощью электроника может стать биоразлагаемой и энергоэффективной, создав основу для высокопроизводительных вычислений будущего, где обычная компостная куча сможет стать элементом кластера. 
Источник изображения: The Ohio State University / John LaRocco Традиционные полупроводники на всех этапах обработки требуют огромных энергозатрат и наносят вред окружающей среде, тогда как грибные структуры предлагают экологически чистый и менее затратный с точки зрения потребления энергии подход к обработке и хранению данных. В новом исследовании учёные из Университета штата Огайо (The Ohio State University) предприняли попытку создать на основе обычных съедобных грибов органические мемристоры — компоненты, имитирующие нейронную активность мозга. Подобная технология открывает путь к биоэлектронике, где грибные сети выступают в роли стабильных и недорогих элементов вычислительных платформ. В ходе работы, результаты которой были опубликованы в журнале PLOS ONE, исследователи культивировали образцы мицелия шиитаке и шампиньонов, после чего высушили их для лучшей сохранности и подключили к электронным цепям. Для тестирования применялись различные напряжения и частоты: в мицелий помещались электроды, а съём данных производился в разных точках структуры. Таким образом, учёные «обучали» сеть мицелия работать подобно мемристору — элементу памяти, который сохраняет информацию о предыдущих электрических состояниях. В ходе экспериментов было обнаружено, что некоторые участки мицелия воспроизводят эффекты памяти, аналогичные работе полупроводниковых чипов. В частности, удалось добиться скорости переключения электрического состояния мицелия с частотой 5850 Гц и точностью 90 %. По мере увеличения частоты эффективность работы памяти из мицелия снижалась, однако этот барьер можно преодолеть за счёт расширения сети (и параллельной работы множества элементов памяти) — что для грибного мицелия труда не составит. В режиме ожидания, как нетрудно догадаться, мицелий не требовал энергии для поддержания состояний. Получив столь интересный результат, учёные уже мечтают о носимых гаджетах с грибным мицелием в качестве нейронной сети и о создании огромных ферм для масштабирования вычислений в интересах аэрокосмической отрасли или супервычислений — с минимальными затратами энергии и возможностью полной утилизации «грибных» компьютеров. Почему были выбраны грибы шиитаке? Возможно, это реверанс в сторону спонсора работы — Исследовательского института Honda. Учёные подсмотрели у природы и создали нейрон на белковых нанопроводах, впервые работающий как настоящий
01.10.2025 [11:41],
Геннадий Детинич
Очевидно, что выбранный наукой путь к созданию искусственного интеллекта сопряжён с невероятным потреблением энергии. Если это не «хитрый план» подорвать экономику соперников, то просто недальновидная трата ресурсов планеты. Природа давно уже придумала интеллект, достаточно энергоэффективный, чтобы не пропасть в пучине эволюции биологической жизни на Земле. Осталось воплотить разработки природы в «железе» и, похоже, это произойдёт раньше, чем позже. 
Источник изображения: ИИ-генерация Grok 3/3DNews Учёные из Университета Массачусетса в Амхерсте (UMass) разработали искусственный нейрон, который имитирует поведение и «массогабаритные» характеристики реальных нейронов: по размеру, энергопотреблению, силе сигнала, временным характеристикам и чувствительности к химическим сигналам. Последнее — наиболее важное свойство, поскольку нервная система живых организмов и человека в частности работает не только с электрическим потенциалом, но и с нейромедиаторами — химическими соединениями, возбуждающими электрический сигнал в нейронах. Разработчики, ничуть не стесняясь, заявили о прорыве в биоэлектронике, который позволит объединить электронику и биологию для более эффективной обработки данных, аналогичной работе мозга, функционирующего при сравнительно низком энергопотреблении по сравнению с современными ИИ-моделями вроде ChatGPT. Исследование также подчёркивает потенциал таких нейронов в медицине, вычислительной технике и интерфейсах мозг-машина, что способно решить проблему несоответствия сигналов между искусственными (высоковольтными) и биологическими (низковольтными) системами. Искусственный нейрон построен на базе мемристора — памяти на основе изменения сопротивления ячейки, использовавшего белковые нанопровода из бактерии Geobacter sulfurreducens. Эти нанопровода позволили снизить напряжение переключения элемента до 60 мВ и ток до 1,7 нА, что соответствует биологическим уровням и оказалось в 10 раз эффективнее предыдущих аналогов (напомним, электроника обычно работает от 500 мВ и выше). Мемристор был интегрирован в цепь из конденсатора и резистора для имитации фаз нейронной активности — от накопления заряда до его всплеска и последующей стабилизации для новой работы. Кроме того, в схему были добавлены химические сенсоры для обнаружения ионов (например, натрия) и нейромедиаторов (дофамина), чтобы имитировать нейромодуляцию — ту самую реакцию нейронов на химические вещества, например, на кофеин в чашке утреннего кофе. 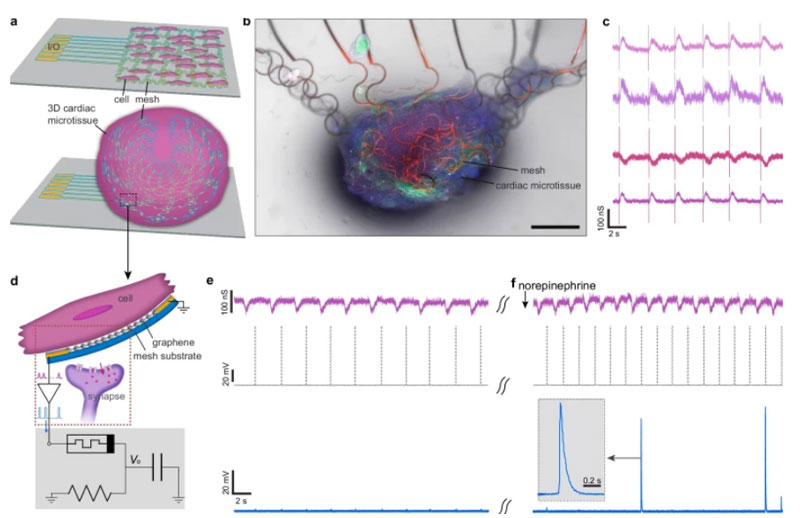
Источник изображения: Nature Communications 2025 Разработанный учёными нейрон генерировал импульсы с энергией, сравнимой с биологической (0,2–37 пДж), и продемонстрировал частотный отклик, регулируемый химическими сигналами. При подключении к кардиомиоцитам (клеткам сердечной мышечной ткани) из стволовых клеток человека через графеновую сенсорную сетку он в реальном времени смог регистрировать электрические сигналы, отличая нормальную активность от изменений под влиянием норадреналина, что повышало частоту импульсов — вызывало условное учащённое сердцебиение. Тем самым учёные показали, что живые клетки могут без проблем сопрягаться с электроникой и всё это прекрасно работает в связке. Прототип открывает путь к энергоэффективным датчикам для мониторинга клеток, реакции на лекарства и даже восстановления повреждённых нейронных цепей, возникающих при серьёзных травмах мозга или позвоночника. В будущем такие нейроны могут улучшить интерфейсы мозг-машина и создать вычислители на основе биологических систем, интегрируясь с живой тканью без промежуточных преобразований. Мобильная графика Arm станет производительнее — в GPU встроят нейронные ускорители
12.08.2025 [17:58],
Сергей Сурабекянц
Arm сообщила, что следующее поколение её мобильных графических процессоров, которое выйдет в 2026 году, будет использовать нейронные технологии, обеспечивающие более высокое качество изображения и повышенную производительность. Компания также представила программный интерфейс (API) для разработчиков, чтобы они могли начать работу с ним уже сегодня, не дожидаясь появления нового оборудования. 
Источник изображений: Arm В первую очередь Arm рассматривает использование нейронного ускорения для масштабирования графики до более высокого разрешения без ущерба для производительности. Среди других предполагаемых сценариев — удвоение частоты кадров с помощью интерполяции и повышение качества изображения за счёт трассировки пути в реальном времени на мобильных устройствах с меньшим количеством лучей на пиксель. «Поскольку ИИ всё больше сливается с графикой реального времени, нам необходим ИИ на базе графических процессоров, который был бы интегрированным, производительным и, что особенно важно, энергоэффективным. Упрощение разработки ИИ на графических процессорах для разработчиков стало движущей силой технических инноваций, о которых мы здесь говорим», — заявил научный сотрудник Arm в области ИИ и платформ для разработчиков Герайнт Норт (Geraint North). Arm отказалась раскрывать подробную техническую информацию о нейронных ускорителях до анонса следующего поколения графических процессоров Mali. Известно лишь, что они будут размещаться в шейдерных ядрах, а производительность нейросетей будет масштабироваться в зависимости от их количества в конкретной реализации GPU. Архитектура Arm пятого поколения предусматривает конфигурации вплоть до 16 ядер. В прошлом году Arm анонсировала технологию масштабирования Arm Accuracy Super Resolution (Arm ASR), позволяющую игре рендерить изображение с более низким разрешением и применять алгоритм масштабирования, снижая затраты на обработку кадра при сохранении качества. Новая технология Neural Super Sampling (NSS) на базе аппаратного нейронного ускорителя способна масштабировать картинку с 540p до 1080p за 4 мс на кадр и снижать нагрузку на графический процессор на 50 %.  «Рендеринг в реальном времени с использованием искусственного интеллекта быстрее, чётче и энергоэффективнее. Таким образом, NSS может создавать выходные данные того же качества с использованием входных данных более низкого качества или даже более высокого качества с теми же входными данными», — заявил Норт. Arm также представила технологии Neural Frame Rate Upscaling (NFRU) и Neural Super Sampling and Denoising (NSSD). NFRU повышает частоту кадров путём создания промежуточного кадра из двух последовательных кадров. «Нейронная сеть также тесно связана с новым оборудованием, которое мы добавим к нашим графическим процессорам для ускорения генерации векторов движения, отслеживающих перемещение пикселей между кадрами. Это позволит очень дёшево масштабировать контент, работающий с частотой 30 кадров в секунду, до 60 кадров в секунду», — пояснил Норт. Технология NSSD предназначена для обеспечения качества изображения трассировки пути, которая, по словам Норта, слишком затратна с точки зрения вычислительных ресурсов даже на настольных системах: «Когда вы объединяете трассировку пути с нейронной сетью, вы фактически можете проецировать лишь небольшое количество лучей на пиксель в сцену, и вы можете использовать нейронную технологию для добавления недостающих деталей. Таким образом, нейронная сеть может экстраполировать данные не только из соседних пикселей, но и из предыдущих кадров». Все эти новшества доступны разработчикам уже сегодня благодаря набору инструментов для разработки нейронной графики. В комплект входят плагины для Unreal Engine, позволяющие интегрировать нейронный суперсэмплинг в игру «всего за несколько кликов». Модели доступны в открытых форматах на GitHub и Hugging Face. Также доступна полная эмуляция расширений Arm ML Vulkan для ПК, что позволяет программистам использовать весь стек приложений, не дожидаясь выпуска мобильных чипов.  Arm — не первая компания, внедряющая нейронные технологии в чипы смартфонов. В частности, ИИ уже широко используется для управления функциями камеры. Компания Qualcomm, лицензиат Arm, расширяет возможности искусственного интеллекта своих смартфонных платформ благодаря нейронным процессорам (NPU). На прошлогодней выставке MWC компания Qualcomm продемонстрировала большую языковую модель с 7 млрд параметров, работающую на Android-смартфоне, и представила свой AI Hub для разработчиков. Длительная работа с ИИ-инструментами ослабляет у людей когнитивные способности, выяснили учёные
20.06.2025 [14:05],
Сергей Сурабекянц
Использование генеративного ИИ становится всё более распространённым в образовании, юриспруденции, СМИ и других областях. Недавнее исследование Массачусетского технологического института (Massachusetts Institute of Technology, MIT) наглядно продемонстрировало, как использование инструментов ИИ ухудшает деятельность мозга. Тест выявил существенно более слабые связи между областями мозга, ухудшение памяти и низкую вовлеченность у участников, использовавших большие языковые модели (LLM). 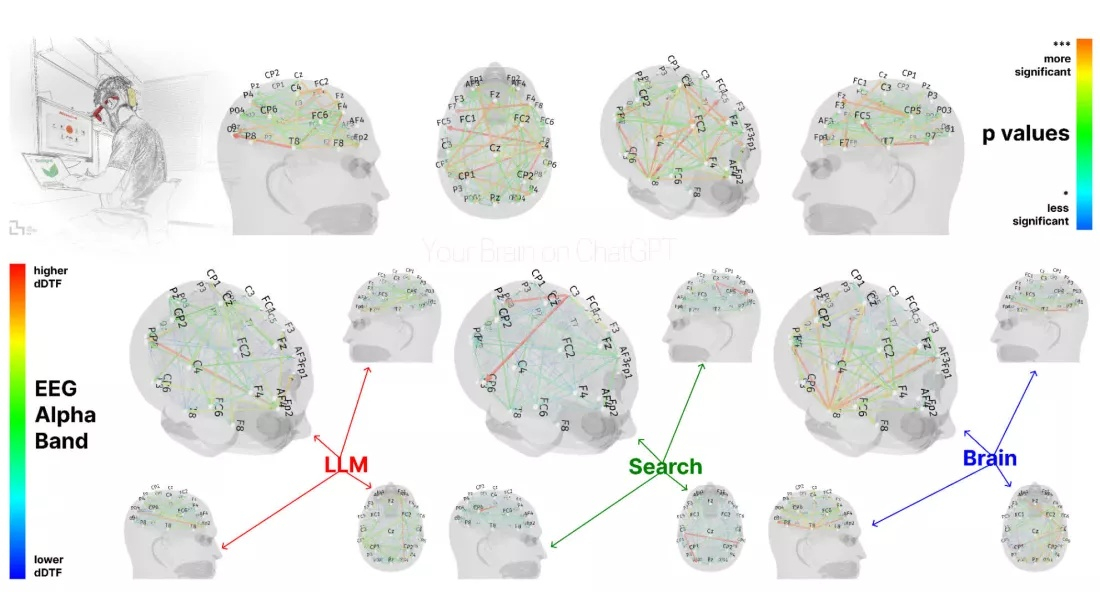
Источник изображения: MIT В процессе исследования, проведённого учёными Массачусетского технологического института, три группы участников написали по три эссе. Первая группа полагалась на LLM, вторая могла использовать лишь классические поисковые системы, а третья не использовала каких-либо внешних источников. Затем первая и третья группы поменялись участниками для написания четвёртого эссе. На всём протяжении тестов производился электронный мониторинг мозга участников. Эссе участников тестирования, использовавших LLM, получили высокие оценки как от людей, так и от нейросети. Их структура, как правило, была более однородной, а содержание точнее соответствовало исходному заданию. Эти участники чаще копировали и вставляли, меньше редактировали свою работу и в дальнейшем испытывали трудности с цитированием собственных текстов. Группа, которая использовала поисковые системы, продемонстрировала низкий и средний уровень мозговых связей. Их текст также был довольно качественным и однородным, при этом они лучше могли цитировать свои работы, что предполагает более сильное сохранение памяти по сравнению с пользователями LLM. Результаты участников, использовавших только собственный мозг, были далеко не самыми точными, зато участники этой группы продемонстрировали значительно более сильную нейронную связь, что свидетельствует о более глубокой умственной вовлеченности. Хотя с течением времени нейронные связи неизбежно ослабевали, участники могли легко вспомнить более ранний материал. Интересно, что участники, которые перешли из группы LLM в группу, изучавшую только мозг, продемонстрировали повышенную нейронную связь, однако испытывали трудности с воспроизведением информации из более раннего периода эксперимента. Их мозговая активность сбросилась до уровня новичка относительно тем эссе. В целом, результаты показывают, что любое использование цифровых инструментов влияет на мозговую активность, но поисковые системы требуют больших умственных усилий, чем генеративный ИИ. Эти результаты могут иметь значительные последствия для образования, где использование ИИ становится широко распространённым. Большинство учеников теперь активно используют такие инструменты, как ChatGPT при выполнении заданий. Некоторые генерируют только планы или идеи тем, в то время как другие используют задания в качестве подсказок и получают готовые работы, даже не вникая в их содержимое. Преподаватели также начали использовать ИИ для оценки заданий и отслеживания использования ИИ. Извечное соревнование снаряда и брони перешло в новую фазу. Представлен первый в мире настольный компьютер с живыми клетками человеческого мозга внутри
04.03.2025 [10:24],
Геннадий Детинич
На выставке MWC 2025 австралийский стартап Cortical Labs представил первый в мире настольный компьютер CL1, использующий живые клетки человеческого мозга. Уникальная система поддерживает жизнеспособность клеток и способствует их развитию в процессе самообучения. Компьютер функционирует автономно, не требуя подключения к классическим вычислительным устройствам. Предполагается, что искусственный интеллект на подобных платформах будет не только более энергоэффективным, но и интеллектуально продвинутым.  Cortical Labs была основана в Мельбурне в 2019 году и с тех пор разрабатывала гибридную платформу «клетки-кремний» совместно с учёными Университета Монаша (Австралия). В вычислениях, требующих сложных математических операций, мозг человека уступает традиционным кремниевым процессорам. Согласно недавним исследованиям, скорость работы человеческого мозга ниже, чем у 50-летнего процессора.  Однако в задачах, связанных с интуитивным поиском решений, человеческий интеллект по-прежнему остаётся вне конкуренции. Только летом 2022 года компьютерная система Frontier стоимостью $600 млн, занимавшая площадь 630 м², впервые превзошла человека в интуитивных вычислениях. Это доказывает, что биологические вычислительные системы ещё рано списывать со счетов.  Первым значимым достижением Cortical Labs стал гибридный процессор DishBrain, основанный на CMOS-матрице и колонии нейронов. Его обучили играть в Pong: нейроны росли на сетке электродов, а затем их стимулировали микроразрядами тока, поощряя успешные удары и «наказывая» промахи. Этот метод позволил сформировать устойчивые нейронные связи, ведущие к самообучению.  С тех пор компания значительно усовершенствовала свою платформу и теперь готова к массовому производству гибридных компьютеров. Первая модель CL1, представленная на MWC 2025 в Барселоне, представляет собой биореактор — систему жизнеобеспечения для колоний нервной ткани, растущих на кремниевом чипе. Конкретное количество клеток и их конфигурацию заранее предсказать невозможно, но для технического описания планируется использовать термин КОЕ (колониеобразующие единицы). Разработчики признают, что до конца не понимают, из каких именно клеток состоит их биологический процессор и в каком соотношении они должны присутствовать. В настоящее время компания использует два метода выращивания искусственной нервной ткани: получение индуцированных плюрипотентных стволовых клеток (iPSCs) из крови грызунов и человека, а также генетические модификации. Однако точный контроль этих процессов пока недостижим, что приводит к вариативности результатов.  Несмотря на это, технология уже готова к коммерческому внедрению. Cortical Labs планирует начать поставки CL1 во второй половине 2025 года. Ожидаемая стоимость одного компьютера — $35 000, что примерно в 2,5 раза дешевле аналогов. В конце года компания запустит облачный доступ к кластеру CL1, включающему четыре секции по 30 компьютеров каждая. Это будет первый опыт объединения биокомпьютеров в кластер, и его результаты пока сложно предсказать. Такая неопределённость отпугивает инвесторов, однако успешные продажи могут вернуть доверие финансовых кругов. Как отдельные устройства, так и облачный кластер рассматриваются компанией как эксперимент. Разработчики пока не имеют чёткого представления о том, как именно система должна работать и в каких областях будет наиболее эффективна. В идеале биокомпьютеры смогут потреблять меньше энергии и быстрее справляться с генеративными моделями. Например, энергопотребление стойки из CL1 составит около 1 кВт — значительно меньше, чем у классических серверов. 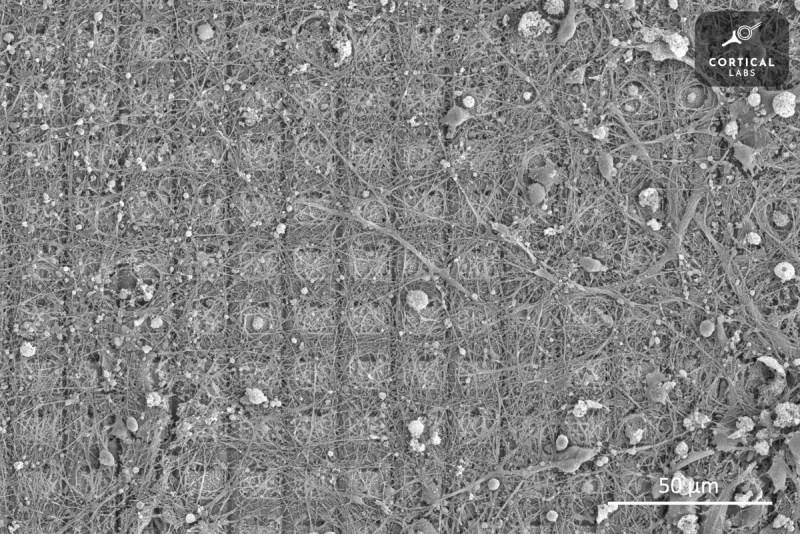
Нейроны DishBrain, растущие на массиве электродов. Источник изображения: Cortical Labs Помимо вычислительных задач, биологические компьютеры могут стать платформой для тестирования новых лекарств от нейродегенеративных заболеваний. Испытания на живых людях неэтичны, а использование колоний нервных клеток в компьютерах может стать альтернативным методом исследования. Это направление может оказаться самым ценным применением новой технологии, поскольку в конечном счёте здоровье человека важнее всего. Китайцы встроили оптическую нейронную сеть в торец оптоволокна — это подтолкнёт развитие квантовой связи, медицины и не только
18.02.2025 [10:53],
Геннадий Детинич
Дальнейшее развитие оптических технологий требует новых подходов в эпоху расцвета нейронных систем. Свойства света способствуют первичной обработке визуальной информации непосредственно в оптоволокне, что заставляет учёных искать способы воплотить такие механизмы на практике. О прорыве в этой сфере сообщили китайские учёные, которые сумели встроить оптическую нейронную сеть в торец оптоволокна для передачи изображений без искажений. 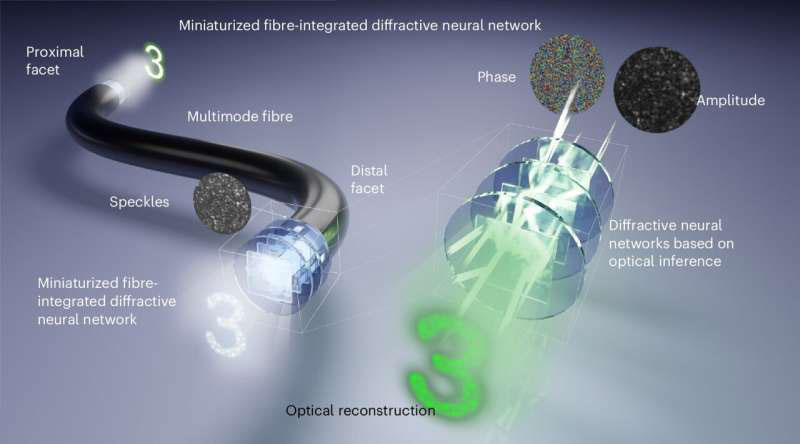
Источник изображения: USST Исследователи из Шанхайского университета науки и технологий (USST) опубликовали в журнале Nature Photonics статью, в которой рассказали о разработке технологии передачи изображений по оптоволокну для малоинвазивного эндоскопа. Учёные работали с многомодовым оптоволокном (MMF) как с более ёмким каналом, имеющим толщину с человеческий волос. Однако из-за склонности MMF к рассеиванию пришлось разработать ряд решений для его уменьшения. При этом высокая пропускная способность MMF рассматривалась как критически важный инструмент в таких областях, как квантовая информация и микроэндоскопия. В настоящее время компенсацию модовой дисперсии (рассеивания) осуществляют с помощью искусственных нейронных сетей и пространственных модуляторов света, однако эти методы дают лишь ограниченный успех в восстановлении искажённых изображений после их передачи по многомодовому оптоволокну. Учёные из USST поставили перед собой задачу преодолеть этот барьер, предложив принципиально новый подход. Исследователи разработали и интегрировали в дальний конец 35-сантиметрового оптоволокна многослойные оптические дифракционные нейронные сети. Внешне они представляют собой специально протравленные прозрачные пластинки, в которых свет преломляется определённым образом, фактически выполняя простейшие вычислительные операции со скоростью света. Такое решение позволяет обрабатывать оптическое умножение матриц и реализовывать больше связей в нейронных сетях без использования электрических схем. Это открывает возможности для таких задач, как оптическая классификация изображений, дешифрование и обнаружение фазы. 
Источник изображения: Nature Photonics 2025 Пластинки многослойных оптических дифракционных нейронных сетей были изготовлены со сторонами 150 мкм. Они позволили считывать и передавать по оптоволокну оптические изображения со сторонами 65 мкм с разрешением 4,9 мкм. В частности, учёные продемонстрировали способность системы различать группы клеток HeLa, не включённых в процесс обучения. При этом система обеспечивала высококачественную оптическую реконструкцию изображения, что подчёркивает потенциал интеграции миниатюризированных дифракционных нейронных сетей с многомодовым оптоволокном. Это создаёт беспрецедентную платформу для оптического вывода в микронном масштабе, прокладывая путь к созданию многофункциональных компактных фотонных систем, применимых в медицине, науке и квантовой фотонике. Нобелевскую премию по физике присудили отцам нейросетей и машинного обучения
08.10.2024 [15:18],
Геннадий Детинич
В основе ряда нейронных сетей, алгоритмов машинного обучения и искусственного интеллекта лежат глубокие открытия в области физики, о чём сегодня заявили представители Нобелевского комитета Каролинского института Стокгольма. Премия 2024 года за эти заслуги присуждена физику Джону Хопфилду (John Hopfield) и математику Джеффри Хинтону (Geoffrey Hinton). 
Источник изображения: nobelprize.org Джон Хопфилд родился 15 июля 1933 года, а докторскую степень по физике он получил в 1958 году в Корнеллском университете. Джеффри Хинтон родился 6 декабря 1947 года, а в 1978 году получил докторскую степень в Эдинбургском университете в сфере ИИ. Интересно отметить, что Хинтон приходится правнуком известному британскому математику Джорджу Булю (1815–1864). Сейчас он сотрудник Университета Торонто, Канада. Оба начали плотно работать над нейронными сетями с начала 80-х годов прошлого века. Джон Хопфилд стал известен в 1982 году как изобретатель ассоциативной нейронной сети, получившей его имя. Хинтон изобрёл метод, который позволял автоматизировать процесс извлечения данных для идентификации элементов изображений. Где во всём этом физика? Для создания нейросети Хопфилд воспользовался известным свойством атомов стремиться к наименьшему значению их энергии. Сеть Хопфилда описывается способом, эквивалентным поведению энергии в системе атомных спинов. Обучение происходит путем нахождения таких значений для соединений между узлами сети, чтобы сохранённые изображения имели низкую энергию. Тогда поиск сводится к такой обработке соединений между узлами, после которой энергия сети снижалась, и это вело бы к обнаружению наилучшего соответствия. Джеффри Хинтон использовал сеть Хопфилда в качестве основы для новой сети, использующей другой метод: машину Больцмана. С её помощью можно научиться распознавать характерные элементы в данных конкретного типа. Для этого Хинтон использовал инструменты статистической физики, науки о системах, построенных из множества похожих компонентов. Машина обучается путем подачи ей примеров, которые с большой вероятностью могут возникнуть при запуске машины. Машина Больцмана может использоваться для классификации изображений или создания новых примеров (рисунков), на которых она была обучена. «Работа лауреатов уже принесла наибольшую пользу. В физике мы используем искусственные нейронные сети в широком спектре областей, таких как разработка новых материалов с определенными свойствами», — прокомментировала награждение Эллен Мунс (Ellen Moons), председатель Нобелевского комитета по физике. Биокомпьютер на живых клетках человеческого мозга теперь можно арендовать за $500 в месяц
28.08.2024 [00:07],
Анжелла Марина
Компания FinalSpark открыла удалённый доступ к своей революционной платформе Neuroplatform, предоставляющей учёным возможность проводить исследования на биокомпьютерах на основе органоидов человеческого мозга. Фактически, теперь по сходной цене можно взять в аренду биологический процессор на базе живых клеток. 
Источник изображения: Copilot Neuroplatform — это первая в мире онлайн-платформа, позволяющая арендовать доступ к биопроцессорам, использующим живые нейроны для вычислений. Как пишет Tom's Hardware, эти процессоры обладают эффективностью в миллион раз выше по сравнению с традиционными цифровыми процессорами. В основе инновационной разработки лежат органоиды, представляющие из себя трёхмерные тканевые структуры, искусственно выращенные из клеток человеческого мозга и содержащие функциональные нейроны. 
Источник изображения: FinalSpark Органоиды, наполненные нейронами, обладают исключительной способностью к обучению и обработке информации. Один такой органоид, по оценкам, содержит 10 000 живых человеческих нейронов. По мнению компании, использование биопроцессоров, основанных на биологических нейронах, вместо транзисторов, может значительно сократить потребление энергии в технологическом мире. «Экономия миллиардов ватт при обучении больших языковых моделей или других ресурсоёмких задач станет в том числе позитивным фактором и для окружающей среды», — подчёркивают в FinalSpark. 
Источник изображения: FinalSpark Архитектура платформы сочетает в себе аппаратное обеспечение, программное обеспечение и биологию. Она основана на использовании многоэлектродных массивов (MEA), в которых размещаются органоиды человеческого мозга в микрофлюидной системе жизнеобеспечения. 3D-тканевые массы связаны и стимулируются восемью электродами, с камерами наблюдения и настроенным программным стеком для того, чтобы исследователи могли вводить переменные данных, а также считывать и интерпретировать выходные данные процессора. 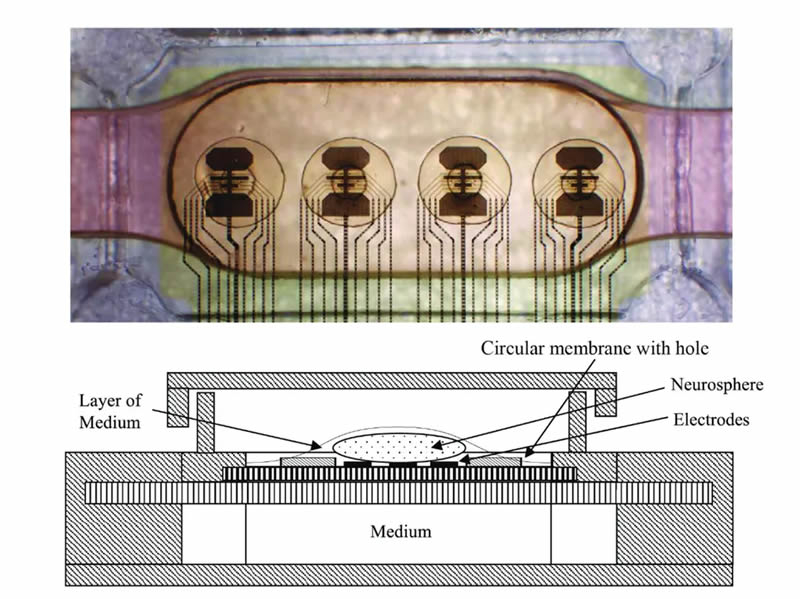
Источник изображения: FinalSpark В разработке Neuroplatform участвуют пять крупных исследовательских институтов, и уже девять пользователей зарегистрированы на платформе. Открытие доступа к Neuroplatform для более широкого круга академических исследователей является важным шагом, который позволит ускорить исследования в области биокомпьютинга и раскрыть потенциал технологии. Платформа предлагает четыре общих органоида, которые могут быть арендованы за $500 в месяц на пользователя. Для некоторых проектов доступ предоставляется бесплатно. FinalSpark утверждает, что эта цена включает в себя доступ к полностью управляемой удалённой нейроплатформе, позволяющей проводить исследования в области биовычислений. Поставлена первая коммерческая система на «кремниевом мозге» IBM
30.03.2016 [14:45],
Геннадий Детинич
Компания IBM официальным пресс-релизом сообщила, что Ливерморская национальная лаборатория им. Лоуренса стала первым покупателем единственного в мире компьютера, имитирующего работу головного мозга. Уникальная система базируется на разработке IBM по созданию нейросинаптического процессора. Проект стартовал в 2008 году по заказу агентства DARPA. Ожидалось, что IBM создаст процессор, способный на оперативный анализ данных на поле боя. Процессор должен был работать по алгоритмам, имитирующим работу головного мозга. Соответственно, в основе разработки лежит архитектура, отличная от классической неймановской логики. 
Структура кристалла процессора IBM TrueNorth (IBM) После серии изысканий в 2011 году компания IBM представила процессор TrueNorth. Решение выпускалось с использованием 45-нм техпроцесса SOI-CMOS и содержало 256 аналогов нейронов. Кроме этого одно ядро содержало 262 тысяч программируемых аналогов синапсов, а в другом находились 65 тысяч обучаемых синапсов. Естественно, все эти «нейроны и синапсы» представляли собой электронные цепи из обычных кремниевых транзисторов, но связанных между собой специальной логикой по типу ячеистых сетей. 
Процессор IBM TrueNorth второго поколения (IBM) Второе поколение процессоров TrueNorth вышло в 2014 году. Производством процессора с использованием 28-нм техпроцесса занималась компания Samsung. Новый процессор включал уже один миллион цифровых нейронов и 256 млн программируемых синапсов. При всём этом процессор TrueNorth — это чип с 5,4 млрд транзисторов. Что поразительно, довольно большое число транзисторов не сказалось на потреблении процессора. В ходе вычислений с производительностью 46 млрд синаптических операций в секунду процессор потребляет всего 70 милливатт (0,8 вольт). Ливерморской лаборатории передан компьютер на базе 16 таких процессоров и его потребление составляет всего 2,5 Вт — как у планшета. 
16-ядерная система на «когнитивных» процессорах IBM TrueNorth, проданная Ливерморской лаборатории Кроме компьютера компания IBM включила в поставку набор необходимого программного обеспечения как для работы системы, так и для разработки программ. Ожидается, что имитирующий работу мозга компьютер поможет решить ряд сложных для традиционной логики задач. В лаборатории не скрывают, что основным направлением деятельности с использованием «познающей» системы станет изучение проблем по заказам Национальной администрации по ядерной безопасности (National Nuclear Security Administration), которая занимается широким спектром вопросов контроля над распространением ядерного вооружения. Также в лаборатории будут прорабатывать варианты создания суперкомпьютеров будущего с 50-кратно увеличенной производительностью по отношению к современным системам. 
Ведущий разработчик «когнитивного» процессора IBM, Дхармендра Модха (Dharmendra S. Modha) Кстати, по неофициальным данным, которые приводит сайт The Wall Street Journal, система IBM обошлась лаборатории всего в один млн долларов США. В принципе, неплохо для IBM за систему с 16-ядерным процессором. Компаниям Intel и AMD такое даже не снилось. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex







