|
Опрос
|
реклама
Быстрый переход
Meta✴ убрала алгоритм распознавания лиц из программного кода для умных очков
09.06.2026 [17:29],
Павел Котов
Алгоритм распознавания лиц в умных очках Meta✴✴ проработал всего один день. После того, как о новой скрытой функции сообщили СМИ, компания оперативно выпустила ещё одно обновление, в котором соответствующего фрагмента кода уже не стало. 
Источник изображения: Meta✴✴ Журналисты Wired обнаружили функцию Name Tag в приложении Meta✴✴ AI при выходе обновления от 4 июня. Речь идёт о приложении для подключения умных очков к смартфону — и с данной функцией умные очки запускали механизм распознавания лиц для всех, кто оказывается в кадре их камер, преобразовывая изображения лиц в идентификаторы и сверяя их с каждым новым сканированием лица. Ещё в феврале об этой функции под названием Name Tag сообщила New York Times; учитывая, что названия совпали, обнаруженный Wired код выполнял эту же задачу. И 5 июня данная функция с выходом очередного обновления исчезла. По официальной версии, лицевая идентификация предназначалась для того, чтобы владелец очков мог быстрее узнавать людей, с которыми когда-либо встречался. Для забывчивых людей функция, пожалуй, удобная, а вот для тех, кто, не давая согласия, оказываться под камерой устройства, — не самая приятная. Умные очки Meta✴✴ выпускаются совместно с компанией Luxottica под её брендами Ray-Ban и Oakley. Эти гаджеты уже вызвали недовольство общественности из-за злоупотреблений. Они навлекли на себя коллективный иск в отношении Meta✴✴ и гнев европейских чиновников. В самой компании заявили, что функция была лишь пилотным проектом, и пока не было «окончательного решения о том, что делать, и делать ли что-нибудь вообще». В Meta✴ AI может появится распознавание лиц людей через камеру очков
05.06.2026 [06:34],
Анжелла Марина
Вопрос конфиденциальности в умных очках Ray-Ban Meta✴✴ опять всплыл на поверхность. В приложении Meta✴✴ AI обнаружен код ещё не анонсированной системы распознавания лиц под названием NameTag. Ранее появились сообщения о том, что независимые моддеры физически отключают светодиод записи для скрытой съёмки. 
Источник изображения: Joanna Stern/YouTube Компоненты технологии уже попали на смартфоны пользователей вопреки заверениям компании об отсутствии окончательного решения о внедрении NameTag. Журналисты Wired, по сообщению Android Authority, изучили код приложения для очков Ray-Ban и Oakley, которое было загружено уже более 50 миллионов раз, выяснив, что код появился ещё в январе и включает три модели искусственного интеллекта. Одна модель распознаёт лица, другая корректирует их размер, а третья преобразует в локальные данные для сверки с сохранёнными на телефоне эталонными шаблонами. При активации система должна уведомлять владельцев очков о распознавании конкретного человека, оказавшегося в поле зрения камеры. В майской версии приложения эта функция, предположительно, была переименована в Connections. Представитель компании Райан Дэниелс (Ryan Daniels) в ответ на публикацию Wired заявил, что найденные фрагменты кода являются «лишь свидетельством» изучения компанией подобных возможностей, подчеркнув, что «ничего не было отправлено потребителям и никакого окончательного решения не принято». В Meta✴✴ также добавили, что если функция когда-либо будет развёрнута, то это произойдёт с полной прозрачностью и без «создания базы лиц». Одновременно Android Authority отмечает, что, несмотря на то, что Meta✴✴ продолжает отрицать принятие окончательного решения, стоит признать потенциальную пользу технологии, так как распознавание гаджетом знакомых людей может оказаться удобным инструментом. Шпионам и не снилось: умные очки Meta✴ смогут распознавать людей и показывать информацию о них
13.02.2026 [19:01],
Сергей Сурабекянц
Компания Meta✴✴ планирует добавить функцию распознавания лиц в свои популярные умные очки уже в этом году. Эта функция, известная внутри компании как Name Tag, позволит владельцам умных очков идентифицировать людей и получать информацию о них с помощью ИИ-помощника Meta✴✴. Но окончательное решение ещё не принято и планы Meta✴✴ могут измениться. Компания уже год обдумывает выпуск этой функции, которая несёт в себе «риски для безопасности и конфиденциальности». 
Источник изображения: Meta✴✴ Согласно опубликованной внутренней служебной переписке, Meta✴✴ первоначально планировала выпустить Name Tag на конференции людей с нарушениями зрения, прежде чем предложить их широкой публике, но в итоге отказалась от этого замысла. Сообщается, что Meta✴✴ посчитала нынешние политические потрясения в Соединённых Штатах подходящим временем для выпуска этой функции. «Мы запустим её в динамичной политической обстановке, когда многие группы гражданского общества, которые, как мы ожидали, могли бы ополчиться на нас, сосредоточили свои ресурсы на других проблемах», — говорится в документе компании. В 2021 году компания Meta✴✴ рассматривала возможность добавления технологии распознавания лиц в первую версию своих умных очков Ray-Ban, но отказалась от этих планов из-за технических трудностей и этических проблем. Теперь компания на фоне успеха умных очков вернулась к своим планам в связи со сближением администрации США с крупными технологическими компаниями. «Т-Банк» выпустил ИИ-модель распознавания речи с открытым исходным кодом — T-one
22.07.2025 [11:32],
Антон Чивчалов
Российская группа компаний «Т-Технологии», владеющая «Т-Банком», опубликовала собственную ИИ-модель распознавания речи с открытым исходным кодом. Речевая модель под названием T-one обещает новый уровень качества распознавания, по словам её разработчиков. Также обещаются прорывные решения, такие как распознавание речи в реальном времени, передаёт Forbes. 
Источник изображения: «Т-Технологии» Более подробно о T-one представители «Т-Технологий» рассказали 19 июля в Москве на Второй конференции по машинному обучению Turbo ML. А на официальном ресурсе компании на платформе GitHub объясняется, что T-one — это высокопроизводительная система автоматического распознавания речи (ASR) с акцентом на распознавание русского языка в телефонии. Кстати, на GitHub она уже доступна для скачивания. Также её можно загрузить с Hugging Face. Для разработчиков приведены инструкции по развёртыванию системы. T-one — модель относительно небольшая, около 70 млн параметров. Для сравнения, речевая модель компании GigaAM от «Сбера» состоит из 240 млн параметров, а модель Whisper large-v3 от OpenAI — из 1,55 млрд. Однако, по утверждениям разработчиков T-One, это не мешает последней обгонять именитых конкурентов именно в распознавании русской речи в телефонных разговорах, под что она «заточена». «Т-Технологии» позиционируют свою разработку как для бизнеса, так и для научного сообщества. Второму она будет интересна низкой стоимостью: эксплуатация на собственном сервере должна быть в десятки раз дешевле конкурирующих решений от облачных провайдеров. T-one хорошо адаптируется под нужды конкретной компании и разработку собственных решений. «Это могут быть компании, разрабатывающие голосовых роботов и ассистентов, занимающиеся автоматизацией кол-центров, — пояснили представители «Т-Технологий» на конференции Turbo ML. — Они могут взять за основу эту модель и адаптировать её под свои решения. Это позволит сократить ресурсы на разработку с нуля». Холодильники Samsung научились узнавать членов семьи по голосу
11.06.2025 [19:27],
Сергей Сурабекянц
Новейшие умные холодильники Samsung теперь поддерживают распознавание голосов членов семьи с помощью фирменного ИИ-помощника Bixby. Он может использоваться для вывода персонализированной информации на встроенные умные дисплеи в зависимости от того, кто из членов семьи говорит. В условиях отсутствия у Samsung собственной линейки умных колонок, бытовые приборы остаются единственным реальным путём для применения такого рода персонализации. 
Источник изображений: Samsung Маркетологи Samsung уверяют, что главное преимущество такого холодильника заключается в возможности отображения календаря или личной фотогалереи каждого члена семьи на основе распознанных голосовых команд. Холодильник можно будет попросить включить будильник на смартфоне или просто отыскать утерянный гаджет (особенно актуально, если он оказался внутри холодильника). Распознавание голоса может оказаться полезным для людей с ослабленным зрением, например умный холодильник может автоматически изменить режим отображения своего экрана в соответствии с настройками смартфона, такими как инверсия цвета или оттенки серого. Samsung добавила новый способ активации ИИ-помощника Bixby на своих холодильниках. Помимо нажатия на значок Bixby или использования голосовых команд, теперь можно просто дважды нажать на выключенный дисплей холодильника.  Функция распознавания голоса и новый способ вызова Bixby появятся в обновлении для холодильников Samsung Bespoke AI с Family Hub, начиная с моделей 2025 года, а позже будут развёрнуты на устройствах с меньшими дисплеями AI Home. Конечно, прогресс не стоит на месте. Но буквально десять лет назад человека, разговаривающего с холодильником, могли запросто (и вполне обоснованно!) отправить в психиатрическую клинику. Figure похвалилась успехами человекоподобного робота Helix на работе, но посылки продолжают летать по складу
09.06.2025 [19:26],
Сергей Сурабекянц
Три месяца назад робототехнический стартап Figure «устроил на работу» в почтовое отделение своего передового гуманоидного робота Helix. Сегодня представители компании подробно рассказали о накопленном за это время опыте и успехах робота в сортировке посылок. Однако при просмотре опубликованного компанией почти часового видеоролика мы заметили множество ошибок, совершаемых Helix. Пожалуй, свои посылки мы ему пока доверить не готовы. 
Источник изображений: Figure «Теперь Helix может обрабатывать более широкий спектр упаковок и приближается к ловкости и скорости человеческого уровня, приближая нас к полностью автономной сортировке посылок. Этот быстрый прогресс подчёркивает масштабируемость основанного на обучении подхода Helix к робототехнике, который быстро переносится в реальное применение», — так оценил успехи робота представитель Figure. По его словам, за счёт масштабирования данных и усовершенствования архитектуры возможности Helix существенно повысились:
Помимо стандартных жёстких коробок система теперь обрабатывает полиэтиленовые пакеты, мягкие конверты и другие деформируемые или тонкие посылки. Эти предметы могут складываться, мяться или изгибаться, что затрудняет захват и распознавание этикеток. Helix решает эту задачу, корректируя стратегию захвата на лету — например, отбрасывая мягкий пакет для его динамического переворота или используя специальные захваты для плоских почтовых отправлений. 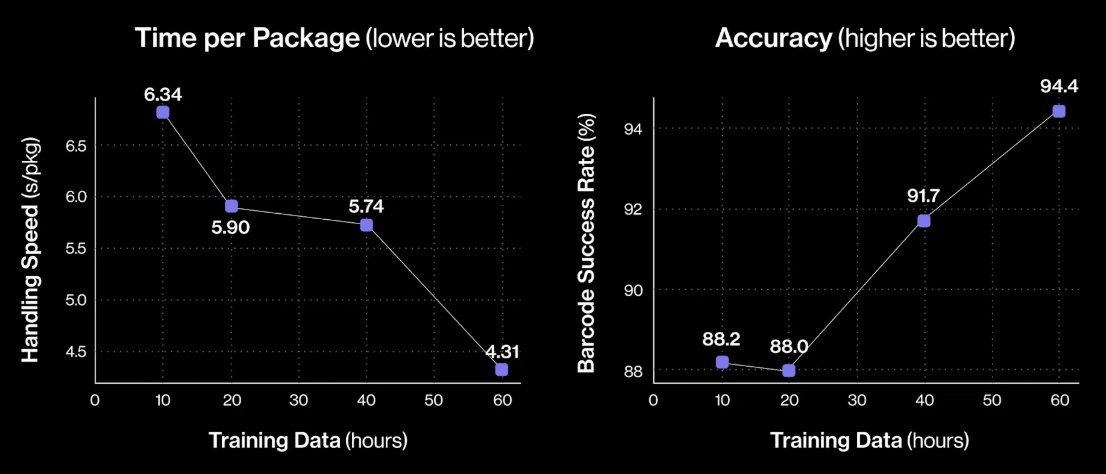 Робот должен поворачивать упаковку штрих-кодом вниз для сканирования. Helix старается расправить пластиковую упаковку, чтобы сканер смог успешно считать штрих-код. Такое адаптивное поведение подчёркивает преимущества сквозного обучения — робот выполняет действия, которые не были жёстко запрограммированы, чтобы компенсировать несовершенства упаковки. Многие достижения стали возможны благодаря целенаправленным улучшениям визуально-моторной политики робота. Он получил новые модули памяти и машинного зрения, что позволило ему лучше воспринимать состояние окружающей среды и быстро адаптироваться к изменениям ситуации. 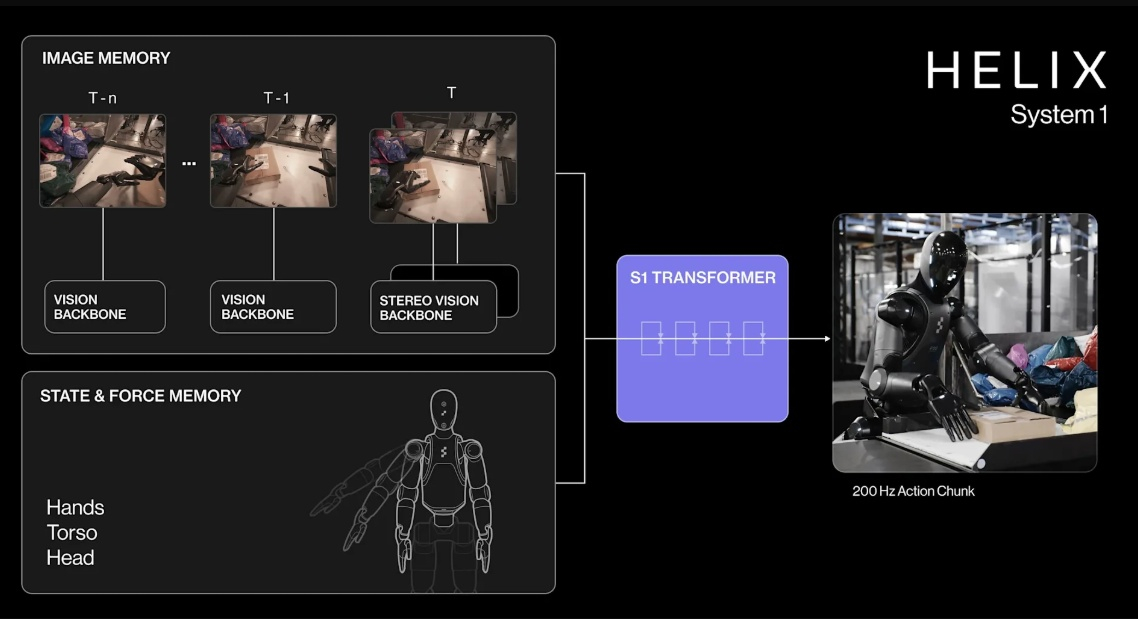 Helix оснащён модулем неявной визуальной памяти, который обеспечивает поведение с учётом текущего состояния — робот запоминает, какие стороны упаковки он уже осмотрел, либо какие зоны конвейера свободны. Модуль памяти помогает устранять избыточные движения, давая Helix ощущение временного контекста и позволяя ему действовать более стратегически при выполнении многошаговых манипуляций. Отслеживание истории недавних состояний позволяет роботу осуществлять более быстрое и реактивное управление. В результате ускоряется реакция на неожиданности и помехи: если пакет смещается или попытка захвата оказывается неудачной, Helix корректирует движение «на лету». Это значительно сократило время обработки каждого пакета. 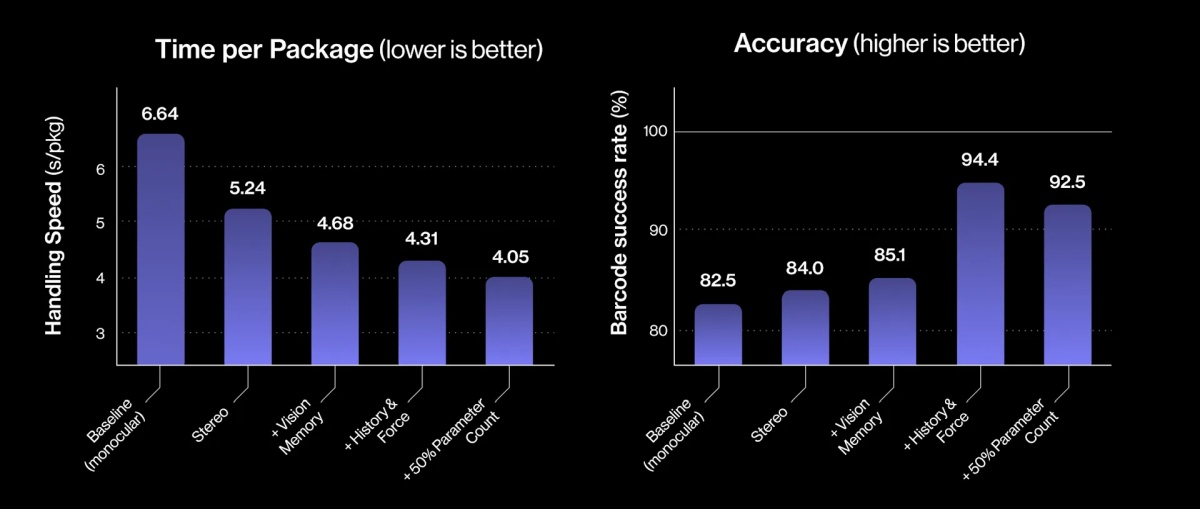 Helix использует аналог человеческого осязания благодаря интегрированной обратной связи по усилию. Робот способен определить момент соприкосновения с объектом и использовать это для модуляции движения, например, приостанавливая опускание при контакте с конвейерной лентой. Хотя основной задачей Helix в логистическом сценарии является автономная сортировка, он легко адаптируется к новым взаимодействиям. Например, протянутая к нему рука человека интерпретируется как сигнал к передаче предмета: робот отдаёт посылку, а не размещает её на конвейере — подобное поведение заранее явно не программировалось, система самостоятельно обучилась ему.  «Helix неуклонно масштабируется в плане ловкости и надёжности, сокращая разрыв между освоенными роботизированными манипуляциями и требованиями реальных задач. Мы продолжим расширять набор навыков и обеспечивать стабильность на ещё больших скоростях и рабочих нагрузках», — заявил представитель Figure. В реальности всё далеко не так радужно, как описывают маркетологи Figure — по следующим ссылкам можно увидеть, что робот совершает много ошибок, путается, роняет посылки и порой откровенно зависает. Так что какое-то время «кожаные мешки» на этой работе ещё будут востребованы. Но, учитывая нынешние темпы развития робототехники и бум искусственного интеллекта, почтовым служащим пора подумать о смене профессии. Meta✴ наделит следующие умные очки Ray-Ban «супервосприятием» — функцией распознавания лиц окружающих
08.05.2025 [19:27],
Владимир Мироненко
Meta✴✴ изучает возможность добавления технологии распознавания лиц в будущие версии своих умных очков Ray-Ban Meta✴✴, сообщил ресурс The Information. Новая функция «супервосприятия» позволит пользователям идентифицировать людей поблизости, сканируя их лица, хотя это может вызвать проблемы с конфиденциальностью, поскольку не всем окружающим такое поведение придётся по душе. 
Источник изображения: Ray-Ban В связи с этим в Meta✴✴ обсуждают, следует ли отключать светодиодный индикатор камеры, сигнализирующий о запуске процесса распознавания лиц. Нынешние модели умных очков Ray-Ban Meta✴✴ AI оснащены светодиодным индикатором, который начинает мигать, оповещая окружающих о включении камеры. По данным источников, новые модели умных очков под названиями Aperol и Bellini с функцией «супервосприятия» выйдут в 2026 году. Ожидается, что они получат более мощные аккумуляторы, поскольку при использовании новой функции значительно возрастает потребление энергии. При тестировании технологии на существующих моделях очков Ray-Ban Meta✴✴ AI продолжительность автономной работы сокращалась всего до 30 минут. Разработанное Meta✴✴ программное обеспечение на базе ИИ, активируемое командой «Эй, Meta✴✴, запусти живой ИИ», позволит не только распознавать лица, но и напоминать владельцу умных очков, например, взять ключи, если ИИ заметит, что он этого не сделал, или забрать продукты по пути домой. Поскольку в режиме «супервосприятия» камера и датчики очков работают постоянно, ИИ сможет отслеживать действия пользователя и напоминать ему, если он что-то упустил из виду. Приложение «Фотографии» в Windows 11 получит большое обновление, основанное на ИИ
25.03.2025 [18:18],
Сергей Сурабекянц
Приложение «Фотографии» в Windows 11 скоро пополнится новыми инструментами на базе ИИ. Microsoft в настоящее время тестирует обновление, которое добавляет кнопку Copilot и ярлыки для инструментов ИИ в контекстное меню «Проводника» и возможность поиска в интернете по распознанному тексту. Также появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. 
Источник изображений: Microsoft Участники программы Windows Insider в канале Release Preview получили возможность протестировать несколько новых функций на основе ИИ. Многие из этих функций уже некоторое время находятся в разработке, но их появление в канале Release Preview говорит о скором появлении в общедоступной стабильной версии системы. Microsoft запланировала мероприятие, посвящённое ИИ, на 4 апреля 2025 года, приурочив его к 50-летию компании. Ожидается презентация новых функций ИИ для Windows 11 и приложений Microsoft. В конце января для участников программы Windows Insiders в Windows 11 и Windows 10 в приложении «Фотографии» появилась функция оптического распознавания символов (OCR), поддерживающая более 160 языков. Для распознавания текста достаточно нажать кнопку «Сканировать текст» в приложении. Теперь стало возможным использовать функцию «Поиск в интернете», чтобы найти распознанный текст прямо из приложения. Такой подход упрощает извлечение и поиск онлайн-результатов текста из документов, заметок, снимков экрана и других изображений. Microsoft добавила новые ярлыки для инструментов ИИ в «Проводник». Они обеспечивают быстрый доступ к редактированию при помощи ИИ и визуальному поиску без необходимости открывать приложение «Фотографии». Теперь достаточно щёлкнуть правой кнопкой мыши изображение в «Проводнике», чтобы добавить форматированный текст, настроить композицию с помощью выбора объекта или улучшить цветопередачу. Ярлык «Стереть объект» позволяет быстро удалить нежелательные элементы. А «Визуальный поиск с помощью Bing» быстро находит похожие изображения и связанные продукты. В галерее приложения «Фотографии» появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. Функция «Показать вложенные папки» показывает в галерее все изображения и видео из вложенных папок, что может в некоторых случаях упростить навигацию. В верхней части приложения «Фотографии» добавлена выделенная красным кнопка Copilot, которая при помощи ИИ позволяет:
 Из других изменений стоит упомянуть добавленную в приложение поддержку файлов формата JXL. Приложение «Фотографии» вряд ли сможет составить конкуренцию таким программным монстрам для редактирования изображений, как Photoshop или CorelDraw, но будет весьма полезным для быстрого внесения незначительных изменений без дополнительных затрат и подписок. Meta✴ в партнёрстве с ЮНЕСКО запускает новую программу сбора данных для улучшения речи и перевода ИИ
07.02.2025 [18:49],
Сергей Сурабекянц
LTPP (Language Technology Partner Program — партнёрская программа по языковым технологиям) — совместная инициатива ЮНЕСКО и Meta✴✴ по поиску авторов, которые могут предоставить более 10 часов записей речи с транскрипциями, большие объёмы письменного текста и наборы переведённых текстов на разных языках. В дальнейшем эти данные будут интегрированы в ИИ-модели с открытым исходным кодом для распознавания речи и перевода. Усилия LTPP будут сосредоточены на недостаточно обслуживаемых языках для поддержки работы, уже проводимой в этом направлении ЮНЕСКО. «В конечном итоге наша цель — создать интеллектуальные системы, которые могут понимать и реагировать на сложные потребности человека, независимо от языка или культурного происхождения», — заявил представитель Meta✴✴. В дополнение к новой инициативе Meta✴✴ опубликовала открытый исходный код программы для оценки производительности моделей языкового перевода. Тест, состоящий из предложений, созданных лингвистами, поддерживает семь языков, и доступен на платформе разработки ИИ Hugging Face. Meta✴✴ продолжает расширять количество языков, поддерживаемых её ИИ-моделями и развивать функции автоматического перевода для создателей контента. В сентябре прошлого года компания начала тестирование инструмента для перевода голосов в Instagram✴✴ Reels, который дублирует речь создателя на другом языке с автоматическим липсинком. На сегодняшний день обработка на платформах Meta✴✴ контента на языках, отличных от английского, далека от совершенства. По некоторым данным, в соцсети Facebook✴✴ 79 % дезинформации о COVID на итальянском и испанском языках не были распознаны и отмечены системой, по сравнению с 29 % на английском языке. А сообщения на арабском языке, наоборот, часто ошибочно помечаются как разжигающие ненависть. Meta✴✴ заявила, что принимает меры по улучшению своих технологий перевода и модерации. И, хотя компания позиционирует обе свои языковые инициативы как филантропические, нет никаких сомнений, что главным бенефициаром этих программ станет именно Meta✴✴, которая сможет существенно улучшить качество распознавания речи и перевода. Российские специалисты из Smart Engines расшифровали рукописи Пушкина при помощи ИИ
06.02.2025 [17:59],
Сергей Сурабекянц
Специалисты российской компании Smart Engines расшифровали зачёркнутые фрагменты черновых рукописей Александра Пушкина с помощью разработанной ими системы искусственного интеллекта «Да Винчи». Нейросетевая архитектура «Да Винчи» широко используется для распознавания документов, в частности российских паспортов, вне зависимости от угла и условий съёмки. 
Источник изображения: Wikipedia, «Литературные места России» В процессе обучения ИИ запомнил, какие движения пера в незачёркнутых словах характерны для почерка великого русского поэта, а затем восстановил утраченные места, пользуясь созданной моделью движений его руки. Таким способом удалось идентифицировать несколько неопределяемых ранее слов из черновых рукописей Пушкина. Эти находки внесли существенный вклад в понимание творческого процесса поэта. Узнать, какие слова пришлись Пушкину не по душе, удалось с помощью нейросетевой архитектуры «Да Винчи», разработанной специалистами Smart Engines для удаления линий разграфки, затрудняющих распознавание рукописных данных в официальных документах. Эта технология позволяет автоматически определять геометрию документа и распознавать данные вне зависимости от его расположения в кадре, наличия помех и искажений. Технология одинаково успешно справляется как со сканами, так и с фотографиями документов, в том числе в зеркальном отражении. Алгоритмы Smart Engines уже интегрированы в решения для мгновенного распознавания данных паспорта и других документов. Распознавание паспорта РФ при помощи камеры смартфона требует всего 0,15 секунды. Серверные решения позволяют распознавать до 55 паспортов в секунду на процессор без использования GPU. 
Источник изображения: Smart Engines «Проведённый нами эксперимент по расшифровке ранее нечитаемых слов в рукописях Александра Пушкина подтвердил колоссальный потенциал нейросетей в самых разных областях науки. Мы видим, что искусственный интеллект может стать надёжным инструментом для исследователя […] Предложенный метод снятия зачёркиваний при помощи ИИ может быть применён не только к рукописям Пушкина, но и к архивным записям других известных авторов, а также историческим документам. Это открывает новые возможности для изучения творческого процесса написания знаменитых литературных произведений», — уверен генеральный директор Smart Engines Владимир Арлазаров. Остаётся неясным лишь одно: если великий русский поэт какие-то слова зачёркивал, возможно, он не хотел, чтобы кто-нибудь их прочитал, в том числе и искусственный интеллект? Российский электромобиль «Атом» будет узнавать водителя по лицу с помощью ИИ
19.09.2024 [18:19],
Сергей Сурабекянц
Telegram-канал «Ростеха» сообщил, что перспективный российский электромобиль «Атом» получит систему распознавания лиц на основе искусственного интеллекта. Такое решение позволит «Атому» «узнавать» конкретного водителя и мгновенно адаптироваться под него. Внедрением функций распознавания лиц при помощи ИИ займётся компания NtechLab. 
Источник изображений: «Атом» В «Ростехе» утверждают, что эта разработка станет первым в России внедрением функций ИИ в автотранспорт. Аутентификация водителя будет производиться при помощи мобильного приложения. Разработчики гарантируют уверенное распознавание людей в очках и головном уборе. Обман системы исключён — она обучена отличать живого человека от силиконовой маски или фотографии. В будущем система распознавания лиц «Ростеха» может быть использована в каршеринге и такси.  Серийное производство основанного на отечественной модульной платформе компактного электромобиля «Атом» должно начаться в 2025 году на столичном заводе «Москвич». Электрокар разработан российским стартапом «Кама», ключевой инвестор проекта — дочерняя структура «Росатома» «Рэнера» – отраслевой интегратор в области систем накопления энергии. В настоящий момент ведутся испытания функциональных прототипов. Будущие объёмы производства электрокаров представитель «Камы» не раскрывает. Компания «Кама» — производитель «Атома» — была основана в августе 2021 года. Основными инвесторами проекта стали гендиректор предприятия «Камаз» Сергей Когогин и основатель и бывший владелец инвестиционной компании «Тройка Диалог» Рубен Варданян. Swarovski Optik представила умный бинокль — он умеет распознавать птиц и животных, снимать фото и видео
11.01.2024 [17:43],
Сергей Сурабекянц
На выставке CES 2024 компания Swarovski Optik представила первый в мире умный бинокль AX Visio, который может идентифицировать объекты при помощи искусственного интеллекта, снимать фотографии и видео, а также вести прямую трансляцию изображения. Объектив бинокля диаметром 32 мм обладает 10-кратным увеличением и обеспечивает поле зрения 112 метров на расстоянии 1000 метров. 
Источник изображений: Swarovski Optik Разрешение датчика изображения AX Visio составляет 4208 × 3120 пикселей, то есть 13 Мп, однако запись видео возможна лишь в разрешении Full HD. Благодаря мобильному приложению видео и фотографии легко загружаются на смартфон для дальнейшей классификации и обработки. Функция Live View обеспечивает возможность делиться наблюдениями в реальном времени. Эксперты особо отмечают возможности нового бинокля AX Visio по распознаванию объектов в сфере наблюдений за животным миром. AX Visio оснащён нейропроцессором (NPU), который, как утверждается, способен быстро и надёжно идентифицировать самые разнообразные виды животных и птиц, что очень поможет учёным, экоактивистам и просто любителям природы.  По информации производителя, время автономной работы AX Visio составляет «до 15 часов при нормальной работе и 2 часа при интенсивном использовании». Бинокль имеет встроенный компас и функцию отображения угла наклона гаджета относительно горизонта. Весит устройство чуть менее 1100 граммов. AX Visio уже доступен для заказа по цене $4799. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




