|
Опрос
|
реклама
Быстрый переход
ИИ заполоняет интернет: 35 % появившихся за последние годы сайтов были созданы нейросетями
28.04.2026 [19:39],
Сергей Сурабекянц
Группа исследователей, в которую входят учёные и энтузиасты проекта «Архив интернета», опубликовала свои выводы в статье под названием «Влияние текста, сгенерированного ИИ, на интернет». По их данным, начиная с 2022 года более трети всех сайтов создано с помощью ИИ. Исследование также показало, что контент, сгенерированный ИИ, делает интернет более позитивным и менее разнообразным. 
Источник изображений: unsplash.com Вдохновлённые теорией «мёртвого интернета» — идеей о том, что большая часть интернета теперь состоит из ботов, обменивающихся сообщениями, — команда исследователей обратилась в «Архив интернета», чтобы получить образцы сайтов за 33 месяца с августа 2022 года по май 2025 года. Проект «Архив интернета» (Internet Archive) — это некоммерческая организация, которая, как и следует из названия, занимается сохранением цифрового контента Сети для будущих поколений. «Для каждого выбранного URL-адреса мы получаем самый старый доступный архивный снимок через API сервера CDX Wayback Machine, — говорится в исследовании. — Исходный HTML-код каждого снимка загружается и сохраняется локально для последующей обработки». Исследователи использовали программное обеспечение для обнаружения ИИ Pangram v3, которое, по их данным, оказалось самым точным инструментом для определения контента, созданного нейросетью. «Опасения вызывают распространение в интернете текста, сгенерированного и обработанного с помощью ИИ, что может привести к ухудшению семантического и стилистического разнообразия, фактической точности и другим негативным последствиям, — пишут исследователи. — Мы обнаружили, что к середине 2025 года примерно 35 % вновь опубликованных сайтов были классифицированы как сгенерированные или обработанные с помощью ИИ, по сравнению с нулевым показателем до запуска ChatGPT в конце 2022 года».  «Я считаю невероятную скорость захвата интернета искусственным интеллектом просто поразительной, — заявил соавтор статьи Йонаш Долежал (Jonáš Doležal). — После десятилетий, в течение которых люди формировали интернет, значительная его часть всего за три года стала определяться искусственным интеллектом. На мой взгляд, мы являемся свидетелями масштабной трансформации цифрового ландшафта за гораздо меньшее время, чем потребовалось для его создания изначально». Исследователи проверили шесть распространённых критических замечаний в адрес текста, сгенерированного ИИ:
«Для каждой гипотезы мы определяем измеримый сигнал, вычисляем его для каждой ежемесячной выборки сайтов и проверяем, коррелирует ли он с совокупным показателем вероятности ИИ за месяцы», — пояснили учёные. Например, чтобы проверить, заполняет ли ИИ интернет ложной информацией, команда извлекла основанные на фактах утверждения с выбранных ими сайтов, а затем проверила их достоверность. Чтобы выяснить, ссылается ли ИИ на источники, команда вычисляла плотность исходящих ссылок в тексте, сгенерированном ИИ.  К удивлению исследователей, только две из шести проверенных ими теорий о влиянии текста, сгенерированного ИИ, оказались верными. ИИ делал интернет менее семантически разнообразным и в целом более позитивным, но он не вызывал распространения лжи и не устранял её источники. «Самым удивительным результатом стало то, что наша гипотеза о распаде истины не подтвердилась, — отметил Долежал. — Мы целенаправленно искали увеличение количества заведомо ложных утверждений, но не обнаружили. Но всё же возможно, что ИИ незаметно увеличивает объём утверждений, которые нельзя проверить с помощью существующих инструментов и инфраструктуры проверки фактов. Или же интернет изначально не был особенно склонен к соблюдению истины». Исследователи заявили, что продолжат изучать влияние ИИ-контента на интернет. В настоящее время они создают «непрерывный инструмент», который будет непрерывно анализировать ситуацию, а не создавать статичный «снимок» ресурсов Сети. Учёные планируют выяснить, какие типы сайтов сильнее всего наполнены нейросетевым контентом, с разбивкой по категориям и языкам, а также оценить, где наиболее ярко проявляются последствия применения ИИ.  Для Долежала подобные исследования имеют решающее значение для обеспечения полезного и продуктивного интернета. «По мере распространения контента, созданного с помощью ИИ, задача состоит в том, чтобы найти применение этим моделям, которое не приведёт просто к созданию очищенного, повторяющегося контента, — считает он. — Скорее, вместо того чтобы заставлять модели быть идеально покладистыми и уступчивыми, стоит предоставить им больше индивидуальности или конфликтности, что может помочь им выступать в качестве творческого партнёра, а не замены человеческого голоса». Приложение «Фотографии» в Windows 11 получит большое обновление, основанное на ИИ
25.03.2025 [18:18],
Сергей Сурабекянц
Приложение «Фотографии» в Windows 11 скоро пополнится новыми инструментами на базе ИИ. Microsoft в настоящее время тестирует обновление, которое добавляет кнопку Copilot и ярлыки для инструментов ИИ в контекстное меню «Проводника» и возможность поиска в интернете по распознанному тексту. Также появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. 
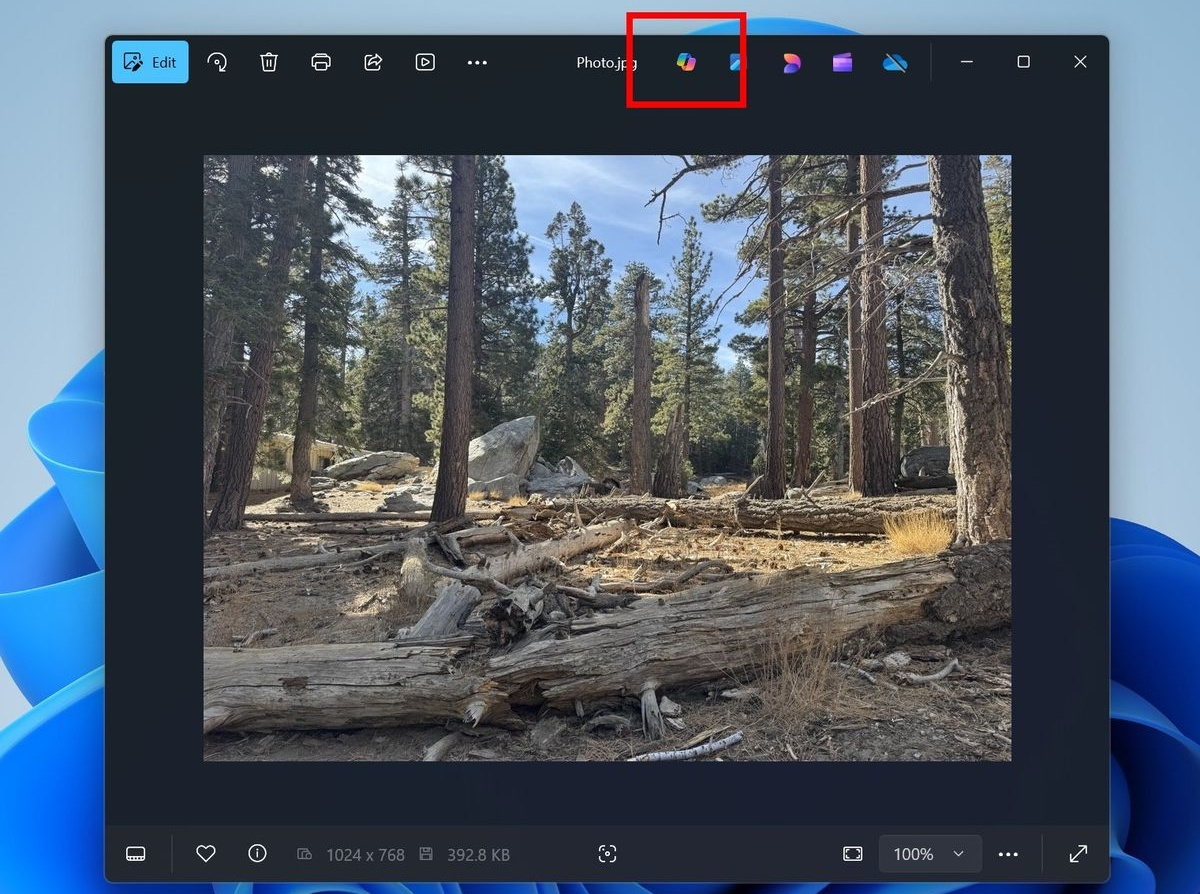
Источник изображений: Microsoft Участники программы Windows Insider в канале Release Preview получили возможность протестировать несколько новых функций на основе ИИ. Многие из этих функций уже некоторое время находятся в разработке, но их появление в канале Release Preview говорит о скором появлении в общедоступной стабильной версии системы. Microsoft запланировала мероприятие, посвящённое ИИ, на 4 апреля 2025 года, приурочив его к 50-летию компании. Ожидается презентация новых функций ИИ для Windows 11 и приложений Microsoft. В конце января для участников программы Windows Insiders в Windows 11 и Windows 10 в приложении «Фотографии» появилась функция оптического распознавания символов (OCR), поддерживающая более 160 языков. Для распознавания текста достаточно нажать кнопку «Сканировать текст» в приложении. Теперь стало возможным использовать функцию «Поиск в интернете», чтобы найти распознанный текст прямо из приложения. Такой подход упрощает извлечение и поиск онлайн-результатов текста из документов, заметок, снимков экрана и других изображений. Microsoft добавила новые ярлыки для инструментов ИИ в «Проводник». Они обеспечивают быстрый доступ к редактированию при помощи ИИ и визуальному поиску без необходимости открывать приложение «Фотографии». Теперь достаточно щёлкнуть правой кнопкой мыши изображение в «Проводнике», чтобы добавить форматированный текст, настроить композицию с помощью выбора объекта или улучшить цветопередачу. Ярлык «Стереть объект» позволяет быстро удалить нежелательные элементы. А «Визуальный поиск с помощью Bing» быстро находит похожие изображения и связанные продукты. В галерее приложения «Фотографии» появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. Функция «Показать вложенные папки» показывает в галерее все изображения и видео из вложенных папок, что может в некоторых случаях упростить навигацию. В верхней части приложения «Фотографии» добавлена выделенная красным кнопка Copilot, которая при помощи ИИ позволяет:
 Из других изменений стоит упомянуть добавленную в приложение поддержку файлов формата JXL. Приложение «Фотографии» вряд ли сможет составить конкуренцию таким программным монстрам для редактирования изображений, как Photoshop или CorelDraw, но будет весьма полезным для быстрого внесения незначительных изменений без дополнительных затрат и подписок. Российские специалисты из Smart Engines расшифровали рукописи Пушкина при помощи ИИ
06.02.2025 [17:59],
Сергей Сурабекянц
Специалисты российской компании Smart Engines расшифровали зачёркнутые фрагменты черновых рукописей Александра Пушкина с помощью разработанной ими системы искусственного интеллекта «Да Винчи». Нейросетевая архитектура «Да Винчи» широко используется для распознавания документов, в частности российских паспортов, вне зависимости от угла и условий съёмки. 
Источник изображения: Wikipedia, «Литературные места России» В процессе обучения ИИ запомнил, какие движения пера в незачёркнутых словах характерны для почерка великого русского поэта, а затем восстановил утраченные места, пользуясь созданной моделью движений его руки. Таким способом удалось идентифицировать несколько неопределяемых ранее слов из черновых рукописей Пушкина. Эти находки внесли существенный вклад в понимание творческого процесса поэта. Узнать, какие слова пришлись Пушкину не по душе, удалось с помощью нейросетевой архитектуры «Да Винчи», разработанной специалистами Smart Engines для удаления линий разграфки, затрудняющих распознавание рукописных данных в официальных документах. Эта технология позволяет автоматически определять геометрию документа и распознавать данные вне зависимости от его расположения в кадре, наличия помех и искажений. Технология одинаково успешно справляется как со сканами, так и с фотографиями документов, в том числе в зеркальном отражении. Алгоритмы Smart Engines уже интегрированы в решения для мгновенного распознавания данных паспорта и других документов. Распознавание паспорта РФ при помощи камеры смартфона требует всего 0,15 секунды. Серверные решения позволяют распознавать до 55 паспортов в секунду на процессор без использования GPU. 
Источник изображения: Smart Engines «Проведённый нами эксперимент по расшифровке ранее нечитаемых слов в рукописях Александра Пушкина подтвердил колоссальный потенциал нейросетей в самых разных областях науки. Мы видим, что искусственный интеллект может стать надёжным инструментом для исследователя […] Предложенный метод снятия зачёркиваний при помощи ИИ может быть применён не только к рукописям Пушкина, но и к архивным записям других известных авторов, а также историческим документам. Это открывает новые возможности для изучения творческого процесса написания знаменитых литературных произведений», — уверен генеральный директор Smart Engines Владимир Арлазаров. Остаётся неясным лишь одно: если великий русский поэт какие-то слова зачёркивал, возможно, он не хотел, чтобы кто-нибудь их прочитал, в том числе и искусственный интеллект? Nvidia представила ИИ-модель Fugatto, которая «понимает и генерирует звук, как это делают люди»
25.11.2024 [18:33],
Сергей Сурабекянц
Nvidia представила новую экспериментальную генеративную модель ИИ, которую компания описывает как «швейцарский армейский нож для звука». Модель Fugatto (Foundational Generative Audio Transformer Opus 1) использует текстовые подсказки для генерации новых или изменения существующих музыкальных, голосовых и звуковых файлов. В создании модели принимали участие разработчики со всего мира, что усилило «многоакцентные и многоязычные возможности модели». 
Источник изображения: Nvidia «Мы хотели создать модель, которая понимает и генерирует звук, как это делают люди», — рассказал участник проекта и менеджер по прикладным исследованиям звука в Nvidia Рафаэль Валле (Rafael Valle). Компания предложила несколько сценариев, в которых модель Fugatto может оказаться востребованной:
Исследователи утверждают, что модель при некоторой дополнительной тонкой настройке также может выполнять задачи, не входившие в её предварительное обучение. Модель может объединять отдельные инструкции, например, генерировать речь с определёнными интонациями и акцентом или звук пения птиц во время грозы. Модель также умеет генерировать изменяющиеся со временем звуки, например, шум приближающегося ливня или удаляющегося поезда. Fugatto не является первой технологией генеративного ИИ, которая может создавать звуки из текстовых подсказок. Ранее Meta✴✴ выпустила аналогичную модель ИИ с открытым исходным кодом. Google предлагает ИИ-инструмент собственной разработки для преобразования текста в музыку MusicLM, доступ к которому можно получить через сайт компании AI Test Kitchen. Nvidia пока не предоставила публичный доступ к Fugatto и воздержалась от комментариев на этот счёт. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


