|
Опрос
|
реклама
Быстрый переход
AMD и Cerebras объединились для противостояния Nvidia Groq
24.07.2026 [13:03],
Павел Котов
Графические процессоры хорошо подходят для обучения искусственного интеллекта, но для инференса, то есть развёртывания уже обученных моделей требуется большой объём быстрой памяти. AMD объединилась с Cerebras Systems для разработки вычислительной платформы, объединяющей системы Instinct с ускорителями на базе памяти SRAM, чтобы обеспечить инференс со сверхнизкой задержкой для работы ИИ-агентов. 
Источник изображения: cerebras.ai Совместный проект восполняет пробел в портфеле AMD, образовавшийся после того, как Nvidia в декабре поглотила за $20 млрд стартап Groq. Гендиректор и соучредитель Cerebras Эндрю Фельдман (Andrew Feldman) не в восторге от деятельности Nvidia, которую он сравнивал с торговцами оружием. В отличие от графических процессоров, чипы Cerebras Wefer Scale Engine (WSE) используют не HBM4, а встроенную в чипы память SRAM, которая на порядки быстрее. Благодаря этому оборудование Cerebras является одним из быстрейших в мире в задачах инференса — скорость генерации часто превышает 2000 токенов в секунду. Комплексные системы обрабатывают сложные запросы на ускорителях AMD Instinct, а генерация токенов, требующая больших объёмов памяти, делегируется Cerebras WSE — в результате достигается высокая производительность без ущерба для пропускной способности или стоимости. Конкретные показатели пока не приводятся, кроме одного: количество генерируемых токенов в секунду на ватт потребляемой энергии возрастает пятикратно. Подобная схема есть у конкурента. Вместе с системами Nvidia Vera Rubin работают LPU (Language Processing Units) Groq 3 — разница в том, что если для обслуживания модели с 1 трлн параметров Kimi K2.5 требуются две тысяч чипов Groq, то в системах AMD и Cerebras хватит и нескольких десятков. Объединённое решение будет доступно в Cerebras Cloud уже в этом году, и это не последняя сделка AMD со стартапом. Cerebras провела крупнейшее IPO в этом году — акции конкурента Nvidia взлетели на 68 % в первый же день
15.05.2026 [11:44],
Павел Котов
Акции компании Cerebras Systems, которые начали торговаться накануне на бирже Nasdaq, закрылись на отметке $311,07 при стартовой цене $185. Оценка производителя чипов выросла примерно до $95 млрд; компания продала 30 млн акций и привлекла $5,55 млрд. 
Источник изображения: cerebras.ai Это крупнейшее первичное размещение акций (IPO) американской технологической компании с момента выхода Uber на биржу в 2019 году. Если андеррайтеры — банки Morgan Stanley, Citigroup, Barclays и UBS — воспользуются опционами на покупку ещё 4,5 млн акций, общая сумма поступлений может достичь $6,38 млрд. Cerebras со штаб-квартирой в Кремниевой долине, работает в отрасли искусственного интеллекта, которая в последние месяцы способствовала росту компаний по полупроводниковому направлению: только в этом году трёхзначный рост продемонстрировали AMD, Intel и Micron. Последний тренд — ИИ-агенты, позволяющие автоматически выполнять задачи. Он спровоцировал дополнительный рост спроса на ускорители Nvidia и традиционные центральные процессоры. В прошлом году выручка Cerebras увеличилась на 76 % до $510 млн при чистой прибыли $88 млн — предшествующий год она завершила с убытком $481,6 млн. Самым серьёзным конкурентом Cerebras выступает Nvidia — самая дорогая компания в мире; при этом Cerebras настаивает на преимуществах своих решений по скорости и цене в сравнении с ускорителями Nvidia. Выход на биржу был для Cerebras долгим и сложным. Первую заявку компания подала в сентябре 2024 года, но спустя немногим более года была вынуждена отозвать её из-за сильной зависимости от одного клиента в ОАЭ — компании G42. В апреле этого года она подала повторную заявку, отметив, что в минувшем году на G42 пришлись 24 % выручки, а не 85 %, как годом ранее. При этом 62 % выручки в 2025 году пришлись на долю Университета искусственного интеллекта им. Мохаммеда бен Зайеда в ОАЭ. Соучредителю и гендиректору Cerebras Эндрю Фельдману (Andrew Feldman) принадлежат 5 % голосующих акций компании и доля, стоимость которой на момент выхода на биржу составляла около $2 млрд. Fidelity контролирует около 11 %, венчурная фирма Benchmark — 9 %. Сейчас Cerebras переориентируется с продажи своих ускорителей на предоставление облачных услуг на основе собственных чипов, конкурируя с Google, Microsoft, Oracle и CoreWeave. Компания заключила сделку с OpenAI на $20 млрд, срок которой истекает в 2028 году; её ускорители решила установить в своих центрах обработки данных компания Amazon. У OpenAI и Amazon также есть долгосрочные опционы на покупку акций Cerebras. OpenAI получит долю в конкуренте Nvidia в сфере ИИ-чипов
17.04.2026 [17:25],
Владимир Фетисов
OpenAI выплатит разработчику чипов Cerebras более $20 млрд за использование серверов на базе продуктов стартапа в течение трёх лет. Это вдвое больше, чем предполагалось ранее: в начале года OpenAI договорилась о покупке у Cerebras до 750 мегаватт вычислительных мощностей. 
Источник изображений: Cerebras В сообщении сказано, что в рамках достигнутых договорённостей OpenAI получит варранты на миноритарную долю в Cerebras, которая в дальнейшем может быть увеличена. В дополнение к этому OpenAI предоставит Cerebras около $1 млрд для финансирования строительства центров обработки данных, которые будут использоваться для обслуживания ИИ-продуктов компании. По данным источника, Cerebras раскроет детали сделки уже на этой неделе. На данный момент официальные представители OpenAI и Cerebras воздерживаются от комментариев по данному вопросу. Напомним, Cerebras позиционирует себя в качестве конкурента Nvidia — крупнейшего производителя ИИ-чипов. Стартап планировал провести IPO в США, но отложил его из-за проверки комитета по иностранным инвестициям США на предмет соответствия требованиям национальной безопасности. Внимание ведомства привлекли вложения со стороны компания G42 из ОАЭ, связанной с облачными вычислениями и искусственным интеллектом, а также являющейся крупнейшим клиентом Cerebras. По данным источника, американские власти подозревают G42 в связях с Китаем. Amazon начнёт запускать ИИ-модели на гигантских чипах Cerebras
14.03.2026 [10:32],
Владимир Фетисов
Amazon планирует использовать чипы стартапа Cerebras Systems Inc. наряду с собственными процессорами Trainium, что, по словам компании, создаст оптимальные условия для запуска больших языковых моделей. Платформа Amazon Web Services, являющаяся одним из крупнейших поставщиков облачных вычислительных мощностей, начнёт предлагать новый сервис на основе договорённостей с Cerebras во второй половине 2026 года. Финансовые условия сделки не разглашаются. 
Источник изображения: Cerebras Партнёрство Amazon и Cerebras является очередной попыткой удовлетворить огромный спрос на инфраструктуру для вычислений в сфере искусственного интеллекта. По словам вице-президента Amazon Web Services Нафии Бшары (Nafea Bshara), обе компании готовились к этому сотрудничеству в течение нескольких лет. Он также добавил, что платформа AWS намерена задействовать столько чипов для увеличения вычислительных мощностей, сколько будет востребовано. Для Cerebras, которая планирует первичное публичное размещение акций (IPO), наличие среди клиентов Amazon поможет повысить узнаваемость компании на потенциально огромном рынке. Платформа AWS стала первой из числа крупнейших операторов центров обработки данных, кто обязался задействовать в своей инфраструктуре чипы Cerebras. Согласно имеющимся данным, чипы Amazon и Cerebras будут работать в связке для обеспечения инференс-вычислений, т.е. запуска больших языковых моделей и генерации ответов на входящие запросы. Чипы Amazon Trainium 3 используют для осмысления пользовательских запросов, после чего чипы Cerebras Wafer Scale Engine обеспечат генерацию ответов. Обычно такой подход имеет существенный недостаток: взаимодействие между разными компонентами замедляет процесс. Однако в данном случае компании стремятся получить преимущество, используя специализированные чипы, которые способны быстрее обрабатывать задачи инференса. Улучшение производительности будет особенно заметно в областях, требующих взаимодействия с пользователем, например, при поэтапном написании программного кода. «Хотя сервис только на базе чипов Trainium, вероятно, будет дешевле, новое комбинированное предложение станет привлекательным там, где время — деньги», — считает Бшара. Amazon продолжает оставаться крупным клиентом Nvidia, а также ведёт разработку собственных ИИ-чипов. Эти усилия направлены на улучшение экономических показателей центров обработки данных компании и достижение возможности предлагать клиентам уникальные услуги. OpenAI выпустила GPT-5.3-Codex-Spark — свою первую ИИ-модель, работающую без чипов Nvidia
12.02.2026 [23:26],
Николай Хижняк
Компания OpenAI выпустила свою первую модель искусственного интеллекта, работающую на гигантских чипах-ускорителях Wafer Scale Engine 3 от стартапа Cerebras Systems. Данный шаг является частью усилий создателя ChatGPT по диверсификации поставщиков аппаратного обеспечения для обучения своих моделей. 
Источник изображения: OpenAI Модель GPT-5.3-Codex-Spark является менее мощной, но более быстрой версией продвинутой модели GPT-5.3-Codex, ориентированной на помощь в написании программного кода. Версия Spark позволит инженерам-программистам быстро выполнять такие задачи, как редактирование отдельных фрагментов кода и запуск тестов. Пользователи также могут легко прервать работу модели или дать ей указание выполнить что-то другое, связанное с вайб-кодингом, не дожидаясь завершения длительного вычислительного процесса. 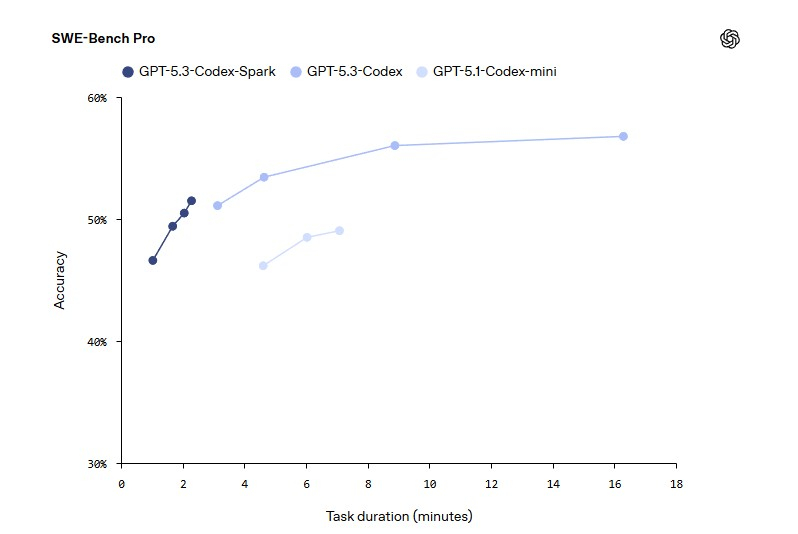
Источник изображения: OpenAI В прошлом месяце OpenAI заключила сделку на сумму более $10 млрд на использование оборудования Cerebras для ускорения обучения своих моделей ИИ. Для Cerebras это партнёрство представляет собой значительный шаг в её стремлении конкурировать на рынке аппаратных средств для ИИ, где долгое время доминирует компания Nvidia. Для OpenAI — это способ расширить сотрудничество с разными поставщиками оборудования для удовлетворения растущих вычислительных потребностей. 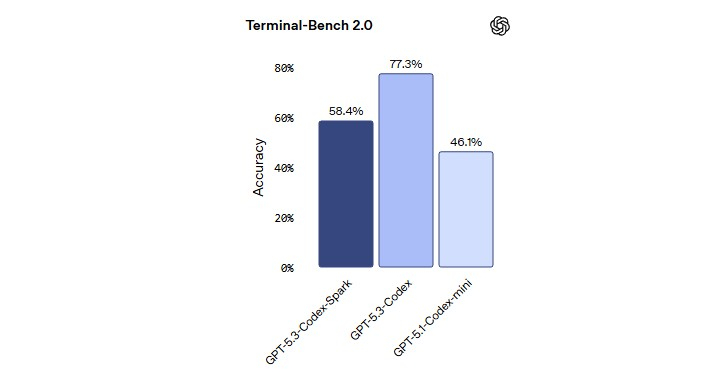
Источник изображения: OpenAI В октябре OpenAI заявила о заключении многолетнего соглашения о стратегическом партнёрстве, в рамках которого будет построена ИИ-инфраструктура на базе сотен тысяч ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт. Позже в том же месяце OpenAI согласилась приобрести специализированные чипы и сетевые компоненты у Broadcom. Как пишет Bloomberg, в последнее время отношения OpenAI с Nvidia оказались под пристальным вниманием на фоне сообщений о напряженности между двумя компаниями. Однако руководители обеих компаний публично заявили, что по-прежнему привержены сотрудничеству. В заявлении, опубликованном в четверг, представитель OpenAI заявил, что партнёрство компании с Nvidia является «основополагающим» и что самые мощные модели ИИ OpenAI являются результатом «многолетней совместной работы над аппаратным и программным обеспечением» двух компаний. «Именно поэтому мы делаем упор на Nvidia как на основу нашей системы обучения и вывода, целенаправленно расширяя экосистему вокруг неё за счёт партнёрств с Cerebras, AMD и Broadcom», — заявил представитель компании. Первоначально GPT-5.3-Codex-Spark будет доступна подписчикам ChatGPT Pro в качестве предварительной версии для исследований. OpenAI собирается предоставить доступ к новой ИИ-модели для более широкого числа пользователей в ближайшие недели. Компания также отмечает, что Codex имеет более 1 млн активных еженедельных пользователей. OpenAI усомнилась в эффективности ускорителей Nvidia для инференса и всё активнее ищет им альтернативу
03.02.2026 [08:40],
Алексей Разин
Принято считать, что OpenAI и Nvidia являются главными выгодоприобретателями бума искусственного интеллекта, и они поддерживают прочные партнёрские отношения, которые должны быть подкреплены сделкой на сумму $100 млрд. Источники при этом отмечают, что эффективность ускорителей Nvidia в инференсе может не устраивать OpenAI, поэтому она стремится найти им подходящую альтернативу. 
Источник изображения: Nvidia Об этом по своим каналам удалось выяснить Reuters, хотя публично OpenAI и Nvidia продолжают выражать крайнюю степень взаимной лояльности. Если верить данным источника, OpenAI хотела бы до 10 % ускорителей в своей вычислительной инфраструктуре заменить на решения сторонних поставщиков, которые лучше проявляли бы себя в задачах инференса — то есть, эффективнее бы работали с уже обученными большими языковыми моделями. OpenAI даже хотела договориться с Cerebras и Groq о поставках разрабатываемых этими стартапами чипов, но Nvidia решила сработать на опережение, купив в прошлом году последний за $20 млрд. До этого Groq вела переговоры с другими инвесторами о вложении в свой капитал до $14 млрд, но Nvidia предложила больше, обеспечив при этом весьма специфическую структуру сделки. По её условиям, Groq сохранила возможность лицензирования своих разработок другим компаниям, но фактически Nvidia перевела в свой штат основных разработчиков ускорителей из Groq. Фактически, остальным компаниям Groq теперь может предложить только программное обеспечение для облачных систем. Одновременно возникают вопросы по целесообразности сделки, в рамках которой Nvidia предложила направить в капитал OpenAI до $100 млрд. Пока стороны отрицают наличие проблем в этой сфере, хотя Nvidia и подчёркивает, что её обязательства не носят строгого характера. Сделку с Cerebras компании OpenAI заключить удалось, теперь вторая будет покупать у первой так называемые «царь-ускорители», которые неплохо проявляют себя в задачах инференса. Проблема OpenAI до сих пор заключалась в том, что она сильно зависит от ускорителей Nvidia и AMD, которые используют внешнюю, пусть и очень быструю память HBM, а в инференсе себя лучше проявляют чипы с большим объёмом интегрированной памяти. Таковые как раз предлагают Groq и Cerebras, а также конкурирующая Google. С последней, кстати, смогла договориться Anthropic, поэтому OpenAI пришлось искать альтернативы. По некоторым данным, OpenAI столкнулась с неэффективностью ускорителей Nvidia при создании ИИ-агента Codex, который помогает разработчикам создавать программный код. Обычные пользователи того же ChatGPT подобных проблем не испытывают, но для программистов OpenAI постарается предложить другие аппаратные решения типа изделий Cerebras, чтобы повысить производительность соответствующих программных инструментов. OpenAI договорилась о покупке царь-ускорителей Cerebras на $10 млрд — чтобы снизить зависимость от Nvidia
15.01.2026 [07:54],
Владимир Фетисов
Компания OpenAI подписала соглашение с разработчиком царь-ускорителей Cerebras. В рамках достигнутых договорённостей Cerebras поставит OpenAI 750 МВт вычислительных мощностей до 2028 года для достижения цели по удержанию лидирующих позиций в сфере ИИ и удовлетворения растущего спроса со стороны потребителей. По данным источника, сумма сделки составит $10 млрд. 
Источник изображения: OpenAI Гендиректор Cerebras Эндрю Фельдман (Andrew Feldman) сообщил, что переговоры между двумя компаниями начались в августе прошлого года. Поводом стала демонстрация Cerebras того, что ИИ-модели OpenAI способны работать на ускорителях компании более эффективно, чем на традиционных GPU. После нескольких месяцев переговоров стороны достигли соглашения, в рамках которого Cerebras будет продавать OpenAI сервисы инференса на базе собственных ускорителей. В рамках сделки Cerebras построит или арендует центры обработки данных, полностью оснащённые своими ускорителями, а OpenAI будет оплачивать использование облачных сервисов и задействует их для собственных нужд. Вычислительные мощности будут вводиться в эксплуатацию в несколько этапов вплоть до 2028 года. «Вычислительная стратегия OpenAI заключается в создании отказоустойчивого портфеля, в рамках которого для разных рабочих нагрузок используются подходящие системы. Cerebras добавит нашей платформе выделенное решение для инференса с низкой задержкой. Это означает более быстрые ответы, более естественное взаимодействие и более прочную основу для масштабирования использования ИИ в реальном времени для гораздо большего числа людей», — говорится в заявлении OpenAI. «Мы в восторге от партнёрства с OpenAI, которое объединяет ведущие мировые ИИ-модели с самым быстрым в мире процессором для ИИ. Подобно тому, как широкополосный доступ преобразил интернет, инференс в реальном времени преобразит ИИ, открыв совершенно новые способы создания и взаимодействия с ИИ-моделями», — уверен Эндрю Фельдман. Производитель гигантских ИИ-чипов Cerebras оказался втянут в скандал с криптомошенничеством
19.06.2025 [18:31],
Сергей Сурабекянц
Cerebras, занимающаяся разработкой чипов для систем машинного обучения и других ресурсоёмких задач, сообщила, что её аккаунт в соцсети X был взломан и использован для продвижения выпущенной киберпреступниками фальшивой криптовалюты. Монета Cerebras, стартовавшая 15 июня с токеном $CEREBRAS, сразу же вызвала подозрения у отраслевых аналитиков. Руководители компании опровергли выпуск каких-бы то ни было криптотокенов, подтвердив взлом аккаунта Cerebras. 
Источник изображения: unsplash.com «Официальный аккаунт Cerebras Systems в соцсети X был захвачен злоумышленниками для продвижения мошеннической криптовалютной схемы, — сообщила компания. — Обратите внимание: Cerebras не запускает и никогда не будет запускать или поддерживать какую-либо криптовалюту или токен. Мы работаем над тем, чтобы вернуть себе контроль над аккаунтом. Будьте бдительны и защитите себя от мошенничества». На данный момент Cerebras, похоже, восстановила контроль над своим аккаунтом X, не зафиксировав никаких подозрительных действий за последние 24 часа. 
Источник изображения: Cerebras Cerebras является ведущим производителем крупнейших чипов ИИ и утверждает, что является единственной компанией в мире, создающей аппаратное обеспечение ИИ в масштабе полупроводниковых пластин. Она удерживает мировой рекорд по скорости инференса большой языковой модели Llama 4 Maverick с 400 млрд параметров — более 2500 транзакций/с, что в два с лишним раза превышает производительность флагманского решения Nvidia. Cerebras также может похвастаться такими поразительными аппаратными средствами, как процессор ИИ с 900 тыс. ядер, эквивалентный 62 графическим процессорам Nvidia H100. Разработчик ИИ-ускорителей Cerebras Systems готовится к выходу на IPO
01.10.2024 [07:56],
Алексей Разин
Основанная в 2016 году в Калифорнии компания Cerebras Systems разрабатывает непривычно крупные чипы для ускорения работы систем искусственного интеллекта, а их выпуском на квадратных подложках занимается TSMC. Американский стартап остаётся убыточным, но уже начал готовиться к выходу на IPO, опубликовав проспект для инвесторов. 
Источник изображения: Cerebras Прежде всего, из опубликованных данных становится понятно, что по итогам первого полугодия компания получила чистые убытки составили $66,6 млн при выручке $136,4 млн. За год до этого выручка не превышала $8,7 млн при чистых убытках в размере $77,8 млн. По итогам всего прошлого года выручка Cerebras достигла $78,7 млн при убытках в размере $127,2 млн. Во втором квартале прошлого года компания выручила $69,8 млн и получила убытки в размере $50,9 млн. За год до этого выручка не превышала $5,7 млн, а чистые убытки составили $26,2 млн. В текущем году операционные расходы Cerebras выросли из-за необходимости найма дополнительного персонала в связи с расширением бизнеса. В прошлом году компания G42 из ОАЭ формировала 83 % выручки Cerebras. Помимо продажи собственно чипов ускорителей, компания занимается предоставлением доступа к собственным облачным мощностям на их основе. Получив в 2021 году $250 млн финансирования, Cerebras оценивала свою капитализацию в $4 млрд. На какую сумму она претендует по итогам IPO, пока не уточняется. Арабская G42 сейчас владеет примерно 5 % акций Cerebras, примерно столько же сосредоточено в руках основателя Эндрю Фельдмана (Andrew Feldman). Компания G42 обязуется до марта 2025 года потратить около $1,43 млрд на покупку ускорителей Cerebras. По мере увеличения объёмов закупок G42 получит право купить большее количество акций американской компании. Пакетами акций Cerebras не менее 5 % владеют около шести институциональных инвесторов. Основатель и глава OpenAI Сэм Альтман (Sam Altman) также является акционером Cerebras, как и сооснователь Sun Microsystems Энди Бехтольсхайм (Andy Bechtolsheim). Молодые компании серьёзно настроены потягаться с Nvidia на рынке систем для запуска ИИ-моделей
28.08.2024 [16:52],
Павел Котов
В попытке ослабить мёртвую хватку Nvidia на рынке чипов для систем искусственного интеллекта сейчас мобилизуется множество конкурентов компании — они привлекают сотни миллионов долларов инвестиций, стремясь воспользоваться волной бума ИИ. Среди наиболее перспективных конкурентов значатся такие компании, как Cerebras, d-Matrix и Groq. 
Источник изображения: Mariia Shalabaieva / unsplash.com Мелкие компании решили воспользоваться тем, что спрос на оборудование для инференса ИИ будет расти экспоненциальными темпами. Эти системы необходимы для запуска уже обученных систем вроде OpenAI ChatGPT и Google Gemini — популярность подобных приложений продолжает расти. Сейчас самыми популярными в этом сегменте являются графические процессоры Nvidia, принадлежащие к семейству Hopper. Компании Cerebras, d-Matrix и Groq заняты разработкой более дешёвых, но и более узконаправленных чипов, которые предназначаются для запуска моделей ИИ. Cerebras накануне представила платформу Cerebras Inference, которая работает на чипе CS-3, который занимает целую 300-мм кремниевую пластину. Этот чип, утверждает производитель, в 20 раз быстрее в задачах вывода ИИ, чем ускорители Nvidia Hopper, но стоит дешевле — это подтверждают тесты Artificial Analysis. Чип Cerebras CS-3 отличает другая архитектура, предусматривающая интеграцию компонентов памяти непосредственно в кремниевую пластину процессора. Ограничения, которые налагает пропускная способность памяти, значительно снижают производительность ИИ-ускорителей, утверждают в Cerebras — объединение логики и памяти на одном большом чипе даёт результаты «на порядки быстрее». В конце этого года ещё одна компания, d-Matrix, намеревается выпустить собственную аппаратную платформу Corsair, предназначенную для работы с Triton — открытой программной средой, которая выступает альтернативой Nvidia Cuda. В прошлом году компания привлекла $110 млн вложений, и в этом также проводит раунд финансирования, на котором намеревается привлечь от инвесторов ещё $200 млн или более. Бывший основатель команды, выступающей разработчиком тензорных процессоров Google, теперь возглавляет ещё одну компанию — Groq, которая в этом месяце привлекла $640 млн при оценке $2,8 млрд. Стартапам в области полупроводников, даже несмотря на шумиху в сегменте ИИ-оборудования, непросто выйти на рынок, предупреждают аналитики. Японский финансовый конгломерат SoftBank в июле поглотил чипмейкера Graphcore, заплатив $600 млн — при том, что с момента своего основания в 2016 году компания привлекла у около $700 млн. Но инвесторы не отчаиваются найти и поддержать «новую Nvidia», и этот процесс способствует развитию многих стартапов. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



