|
Опрос
|
реклама
Быстрый переход
Asus представила настольный ПК на суперчипе Nvidia Grace Blackwell Ultra GB300
20.07.2025 [22:32],
Владимир Фетисов
Не так давно Nvidia представила платформу Grace Blackwell Ultra GB300. Важной особенностью анонса стало то, что этот суперчип ляжет в основу не только линейки рабочих станций Nvidia DGX, но также будет доступен OEM-производителям, стремящимся вывести на рынок ПК-решения для задач искусственного интеллекта. Одним из таких партнёров Nvidia стала компания Asus, которая анонсировала ПК ExpertCenter Pro ET900N G3 на базе платформы Grace Blackwell Ultra GB300. 
Источник изображений: Asus Платформа GB300 объединяет Arm-процессор Grace с 72 ядрами Neoverse V2 и пару чипов Blackwell Ultra, оснащённых 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Для соединения компонентов используется высокоскоростной интерфейс NVLink-C2C. Компьютер ET900N G3 поддерживает установку до 784 Гбайт памяти и обеспечивает производительность на уровне 20 Пфлопс. Материнская плата формата ATX оснащена стандартными разъёмами EPS12V для питания процессора и других системных компонентов. Также предусмотрены три разъёма 12V-2x6, которые теоретически могут использоваться для подачи до 1800 Вт мощности на графический ускоритель. Кроме того, в наличии три слота PCIe x16 для подключения плат расширения, три слота M.2, несколько интерфейсов USB, а также сетевой адаптер ConnectX-8 SuperNIC. В качестве программной платформы используется Nvidia DGX OS.  Отметим, что ET900N G3 был анонсирован вместе с мини-ПК Ascent GX-10, в основе которого лежит платформа GB10. Похоже, что Asus наладила прочные партнёрские отношения с Nvidia. Не исключено, что это сотрудничество в будущем распространится и на потребительские платформы Nvidia, которые, по слухам, могут появиться уже в следующем году. Нестабильность, перегрев и протечки заставили Nvidia упростить дизайн современных ИИ-серверов
28.05.2025 [14:16],
Алексей Разин
Технические проблемы преследовали семейство ускорителей Nvidia Blackwell с конца прошлого года, в результате чего партнёры компании не могли обеспечить довольно быструю рыночную экспансию решений серии GB200, но теперь все трудности позади. Nvidia сделала выводы из этого опыта, упростив конструкцию GB300 с целью предотвращения возможных проблем с наращиванием объёмов производства. 
Источник изображения: Nvidia Издание Financial Times напоминает, что стоечные системы на основе ускорителей Blackwell первого поколения страдали от целого ряда технических проблем. Во-первых, содержались дефекты в компоненте, отвечающем за скоростной обмен данными между отдельными чипами. Во-вторых, сообщалось о перегреве компонентов в плотно скомпонованных системах. В-третьих, жидкостная система охлаждения в некоторых случаях давала течь. По словам опрошенных Financial Times источников, наблюдавшиеся ещё два или три месяца назад технические проблемы с выпуском стоечных систем на базе Blackwell удалось решить при активном содействии партнёров Nvidia. Теперь объёмы их выпуска наращиваются без особых затруднений. В третьем квартале Nvidia собирается наладить выпуск систем следующего поколения, относящихся к серии GB300. От некоторых изначальных технических решений компания предпочла отказаться ради более высокой надёжности. В частности, перспективный дизайн печатных плат Cordelia предусматривал возможность простой замены отдельных графических процессоров при обслуживании системы. Тем не менее, сопутствующие риски вынудили Nvidia отказаться от него в пользу существующего дизайна печатных плат — Bianca, который уже применяется при производстве GB200 и проверен временем. В целом, Nvidia полна решимости когда-нибудь внедрить дизайн Cordelia, но пока этот шаг отложен до момента выхода на рынок ИИ-ускорителей следующего поколения. За счёт нынешних уступок в дизайне Nvidia рассчитывает быстрее нарастить объёмы выпуска GB300, и это позволит ей быстрее компенсировать потери на китайском рынке, вызванные запретом со стороны США на поставки ускорителей семейства H20. Аналитики Bank of America предположили, что квартальная норма прибыли Nvidia в результате санкций против Китая снизится с 71 до 58 %. Отчёт за первый квартал текущего фискального года компания опубликует на этой неделе. Micron и SK hynix представили компактные модули памяти SOCAMM для ИИ-систем Nvidia GB300
19.03.2025 [19:54],
Анжелла Марина
Компании Micron, Samsung и SK hynix анонсировали новые модули памяти SOCAMM на основе уложенных в стеки чипов LPDDR5X, ёмкость которых достигает 128 Гбайт. Технология ориентирована на серверы с низким энергопотреблением и на системы, использующие искусственный интеллект. Первые SOCAMM появятся в системах с Nvidia Grace Blackwell Ultra GB300 Superchip. 
Источник изображения: Micron Micron первой выпустит SOCAMM объёмом 128 Гбайт, используя свою технологию производства DRAM 1β (1-бета, пятое поколение 10-нм класса). Хотя компания не раскрывает точную скорость передачи данных, она заявляет поддержку скорости до 9,6 ГТ/с. В то же время представленный на конференции Nvidia GTC 2025 модуль SOCAMM от SK hynix работает на скорости до 7,5 ГТ/с. Дополнительно Tom's Hardware сообщает, что размер одного модуля SOCAMM составляет 14 × 90 мм, что примерно в три раза меньше стандартного модуля RDIMM, а внутри размещены до четырёх стеков по 16 микросхем памяти LPDDR5X. 
Источник изображения: Tom's Hardware Энергопотребление памяти является одним из ключевых факторов, влияющих на общую энергоэффективность серверов. В системах с терабайтами памяти DDR5 на сокет энергопотребление DRAM может превышать энергопотребление центрального процессора. Nvidia учла этот аспект при разработке своих процессоров Grace, ориентированных на использование энергоэффективной памяти LPDDR5X. Однако в машинах на базе GB200 Grace Blackwell компании пришлось использовать припаянные модули LPDDR5X, так как стандартные модули не могли обеспечить необходимую ёмкость. 
Источник изображения: Tom's Hardware SOCAMM от Micron решает эту проблему, предлагая стандартное модульное решение, способное вместить четыре 16-слойных стека LPDDR5X и обеспечивая тем самым высокую ёмкость. По словам представителей компании, их модули SOCAMM ёмкостью 128 Гбайт потребляют на треть меньше энергии, чем модули DDR5 R-DIMM такой же ёмкости. При этом пока неясно, станет ли SOCAMM отраслевым стандартом, поддерживаемым JEDEC, или останется проприетарным решением, разработанным Micron, Samsung, SK hynix и Nvidia для серверов на базе процессоров Grace и Vera. В настоящее время Micron уже запустила массовое производство SOCAMM. Они появятся в системах на базе Nvidia GB300 Grace Blackwell Ultra Superchip во второй половине текущего года. Отметим, что модульная конструкция упрощает производство и обслуживание серверов, что, вероятно, положительно скажется на ценах на системы, в первую очередь, для нужд искусственного интеллекта. Nvidia представила Blackwell Ultra с 288 Гбайт HBM3e — ИИ-ускоритель «для эпохи рассуждений»
19.03.2025 [11:20],
Андрей Созинов
Компания Nvidia в рамках открытия конференции GTC 2025 официально анонсировала ускоритель вычислений для центров обработки данных Blackwell Ultra B300, суперчип Grace Blackwell Ultra GB300, а также различные системы на его основе. Новинка «создана для эпохи рассуждений», то есть для новейших, более сложных и требовательных к ресурсам ИИ-моделей (LLM), способных размышлять над задачами. 
Источник изображений: Nvidia Nvidia уже традиционно не стала раскрывать всех деталей о новинке. В компании лишь отметили, что графические процессоры Blackwell Ultra (в составе GB300 и B300) физически отличаются от чипов Blackwell (в GB200 и B200). Отметим, что Blackwell Ultra B300 представляет собой классический ускоритель на GPU, тогда как Grace Blackwell Ultra GB300 — это связка из Arm-процессора Grace с 72 ядрами Neoverse V2 и двух графических процессоров Blackwell Ultra. 
Плата с парой CPU Grace и четырьмя Blackwell Ultra Nvidia отмечает увеличенный на 50 % объём набортной памяти. Blackwell Ultra получил 288 Гбайт HBM3e, что будет как раз кстати при работе с особенно крупными LLM. Объём памяти вырос благодаря использованию новых 12-ярусных стеков HBM3e — в Blackwell B200 применяются восьмиярусные стеки HBM3e, обеспечивающие 192 Гбайт памяти. По словам Nvidia, производительность Blackwell Ultra должна в 1,5 раза превышать производительность Blackwell в запуске уже обученных моделей (FP4 inference). Компания заявляет о производительности в 15 Пфлопс для вычислений FP4, а также о 30 Пфлопс для разреженных FP4. Для оригинального ускорителя Blackwell B200 эти показатели составляли 10 и 20 Пфлопс соответственно. 
GB300 NVL72 Nvidia предложит несколько готовых систем на базе новых ускорителей вычислений, которые начнут поступать в продажу во второй половине 2025 года. GB300 NVL72 — фактически это готовая серверная стойка, объединяющая 72 графических процессора Blackwell Ultra и 36 центральных процессоров Grace. Новинка, как и её предшественница GB200 NVL72, оснащена системой жидкостного охлаждения, использует NVLink пятого поколения, модули Nvidia ConnectX-8 SuperNIC и предлагает 18 Тбайт оперативной памяти LPDDR5X. Производительность достигает 1100 Пфлопс в FP4-вычислениях и до 1400 Пфлопс в разреженных вычислениях. 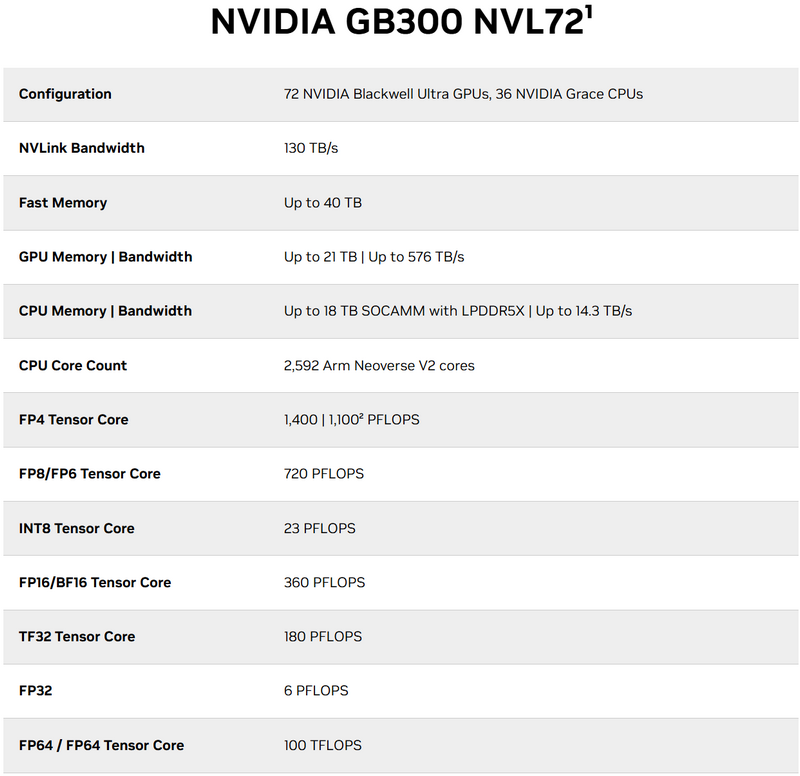 Nvidia особенно отмечает применение интерконнекта NVLink 5-го поколения, который соединяет отдельные чипы для создания «одного большого GPU». Он обладает пропускной способностью 1,8 Тбайт/с на GPU, а общая пропускная способность достигает 130 Тбайт/с. Начиная с Blackwell, NVLink также может использоваться в качестве интерфейса для соединения нескольких стоек, что ранее осуществлялось через InfiniBand со скоростью 100 Гбайт/с. Поэтому Nvidia заявляет о 18-кратном увеличении скорости для этого конкретного сценария. 
Blackwell Ultra DGX SuperPOD В домен NVLink можно подключить до 576 графических процессоров. Собственно, такую систему Nvidia тоже предложит — Blackwell Ultra DGX SuperPOD. Это кластер из восьми стоек NVL72, который включает 288 процессоров Grace, 576 чипов Blackwell Ultra, 300 Тбайт памяти HBM3e и FP4-производительность в 11,5 Экзафлопс. Наконец, Nvidia представила систему HGX B300 NVL16 — решение для тех, кому вместо Arm-процессора Grace нужен чип на x86-совместимой архитектуре. В системе имеется 16 графических процессоров B300A, соединённые через NVLink, и центральные x86-процессоры. Nvidia не уточняет, какие именно CPU применены, но в прошлом использовались чипы как от AMD, так и от Intel.  Ускорители вычислений и системы на базе Blackwell Ultra появятся на рынке во второй половине текущего года. Их предложат все крупные производители серверов, а также новинки будут доступны у основных облачных провайдеров. Ускорители Nvidia B300 прибавят в быстродействии 50 %, но ограничатся ростом TDP на 200 Вт
28.12.2024 [07:57],
Алексей Разин
Второе поколение ускорителей Nvidia с архитектурой Blackwell в лице B300, как сообщает Tom’s Hardware со ссылкой на SemiAnalysis, предложит рост быстродействия на 50 % по сравнению с GB200, но уровень TDP при этом увеличится только с 1200 до 1400 Вт. Чипы семейства B300, по оценкам аналитиков, появятся примерно через полгода после B200, поставки которых уже должны были начаться в этом квартале. 
Источник изображения: Nvidia Выпускать чипы B300 по прежней технологии 4NP будет компания TSMC, но это не помешает добиться роста производительности в вычислениях на 50 %. Ещё одним важным изменением станет использование чипами серии B300 двенадцатиярусных стеков памяти типа HBM3E. Оно обеспечит объём памяти в 288 Гбайт на один ускоритель и пропускную способность на уровне 8 Тбайт/с. Подобные изменения в совокупности позволят снизить затраты на обучение нейронных сетей до трёх раз по сравнению с предшественниками. Появление сетевого контроллера ConnectX-8 класса 800G позволит удвоить пропускную способность сетевого интерфейса относительно текущего ConnectX-7, а увеличение количества линий PCI Express с 32 до 48 штук расширит возможности интеграции данных ускорителей в серверных системах. Важным изменением при производстве ускорителей B300 станет и отказ Nvidia от поставок материнских плат или серверных систем строго в эталонном дизайне. Расширив доступ партнёров к производству таких ускорителей и систем, Nvidia увеличит объёмы поставок продукции. В целом, устройство систем на базе B300 и GB300 будет формироваться на принципах большей свободы, и клиенты от этого только выиграют. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


