|
Опрос
|
реклама
Быстрый переход
Amazon раскрыла планы по NVLink Fusion в Trainium4 и представила ИИ-модели Nova 2 и Sonic
03.12.2025 [05:04],
Алексей Разин
Поскольку сама Arm недавно заявила о поддержке интерфейса NVLink Fusion в своих процессорных архитектурах, её клиентам сделать это рано или поздно тоже бы пришлось. Облачный гигант Amazon (AWS) начал декабрь заявления о намерениях реализовать поддержку интерфейса Nvidia в своих будущих ускорителях семейства Trainium4. 
Источник изображения: AWS Сроки выхода этих ускорителей при этом названы не были, как отмечает Reuters. Анонс был сделан на недельной конференции по облачным вычислениям в Лас-Вегасе, которая собрала около 60 000 посетителей. Непосредственно среди разработчиков чипов поддержку NVLink Fusion ранее анонсировали компании Intel, Samsung и Qualcomm, теперь к ним присоединилась и AWS. По замыслу последней, технология Nvidia поможет компании создавать более эффективные вычислительные кластеры, в которых серверы быстрее обмениваются информацией друг с другом. Прежде чем появятся ускорители Trainium4, компания AWS наполнит рынок серверами на основе ускорителей Trainium3, распространение которых уже начала. Данные системы содержат 144 чипов и в четыре раза превосходят по быстродействию своих предшественников, при этом потребляя на 40 % меньше электроэнергии. Представители AWS рассчитывают конкурировать с другими участниками рынка, включая Nvidia, благодаря более выгодному сочетанию цены и быстродействия своих решений. В программной сфере AWS представила ИИ-модель Nova 2, которая получила возможность комбинировать в ответах на запросы текстовую и визуальную информацию, а также генерировать речевые сообщения. Модель Sonic специализируется на речевом обмене информации, причём делает это вполне естественно, по словам разработчиков. AWS помогает клиентам создавать собственные ИИ-модели, для этого был представлен сервис Nova Forge, который предоставляет инструменты для обучения более специализированных моделей. Arm объявила о поддержке интерфейса NVLink Fusion компании Nvidia
18.11.2025 [07:37],
Алексей Разин
В мае этого года Nvidia разрешила сторонним разработчиков чипов использовать её интерфейс NVLink для интеграции собственных компонентов, количество участников инициативы стремительно растёт. На этой неделе к ним примкнул британский холдинг Arm, который предлагает процессорные архитектуры. Поддержка NVLink будет реализована в рамках платформы Neoverse. 
Источник изображения: Nvidia Использование данного интерфейса позволит разработчикам процессоров сочетать архитектуру Arm с готовыми компонентами Nvidia, повышая скорость обмена данными в серверных системах. Intel и Samsung уже заявили о своих намерениях использовать NVLink, теперь их примеру могут последовать клиенты Arm, в число которых входят Amazon (AWS) и Microsoft, а также Google. В свою очередь, Arm рассчитывает довести долю своих решений в сегменте компонентов для гиперскейлеров до 50 %. Поддержка NVLink позволит процессорам с архитектурой Arm Neoverse эффективнее обмениваться данными с ускорителями вычислений Nvidia, которые доминируют в серверном сегменте. В одном ИИ-сервере на единственный многоядерный процессор может приходиться до восьми ускорителей вычислений. Сотрудничество Arm и Nvidia продолжается в конструктивном русле, даже с учётом провала сделки 2020 года, по условиям которой последняя хотела купить этого разработчика процессорных архитектур. Nvidia продолжает оставаться акционером Arm, но основная часть акций холдинга принадлежит японской корпорации SoftBank. В этом месяце последняя продала свои акции Nvidia, чтобы направить средства на финансирование инициатив, связанных с OpenAI и проектом Stargate в США. Samsung стала партнёром Nvidia по интеграции чипов через NVLink
14.10.2025 [08:07],
Алексей Разин
Южнокорейская компания Samsung Electronics как разрабатывает процессоры для собственных нужд, так и выпускает полупроводниковые компоненты по заказу прочих разработчиков. По этой причине для Nvidia она стала очевидным партнёром в сфере интеграции компонентов с использованием фирменного интерфейса NVLink, встав в один ряд с Intel. 
Источник изображения: Nvidia Если профильная сделка с Intel широко освещалась в прессе, то появление Samsung в рядах партнёров Nvidia на этом направлении удостоилось лишь записи в корпоративном блоге на отвлечённые темы. Как отмечается в материале Nvidia, контрактное подразделение Samsung Foundry становится партнёром компании по разработке и производству заказных полупроводниковых компонентов. По словам представителей Nvidia, это сотрудничество призвано удовлетворить растущий спрос на заказные CPU и XPU, спроектированные с учётом пожеланий конкретных клиентов. В эти дни в Калифорнии проходит саммит OCP — участников инициативы Open Compute Project, которая подразумевает формирование инфраструктуры серверных систем с открытой архитектурой, позволяющей гибко расширять возможности аппаратного обеспечения за счёт компонентов разных поставщиков. Nvidia уже сотрудничает с Intel, Fujitsu и Qualcomm в сфере взаимной интеграции своих компонентов в рамках инициативы NVLink Fusion, а Samsung присоединится к тем партнёрам, которые помогают Nvidia создавать заказные компоненты. Marvell и MediaTek входят в их число, помимо прочих. Как отмечает TechPowerUp, при создании заказных компонентов с поддержкой интерфейса NVLink компания Nvidia диктует партнёрам довольно жёсткие условия, которые не предусматривают создание ими полностью независимых решений. Nvidia не только сохраняет контроль над интеллектуальной собственностью в сфере аппаратного обеспечения, но и строго следит за применением программного. Для обращения к коммутаторам NVLink, например, от партнёров Nvidia требуется специальная лицензия. Fujitsu внедрит технологии Nvidia в суперкомпьютеры на собственных процессорах
03.10.2025 [11:34],
Алексей Разин
Некоторое время назад Nvidia представила инициативу NVLink Fusion, которая позволит сторонним разработчикам полупроводниковых компонентов добиваться более эффективной интеграции чипов Nvidia в свои системы. Очередным партнёром по внедрению NVLink в этом смысле для Nvidia станет японская компания Fujitsu. 
Источник изображений: Fujitsu Строго говоря, содержательный пресс-релиз на страницах сайта Fujitsu перечисляет многие сферы сотрудничества с Nvidia, включая и область квантовых вычислений, но решение о соединении процессоров Monaka компании Fujitsu и GPU компании Nvidia при помощи NVLink Fusion стоит особняком. Первые плоды сотрудничества двух компаний появятся к 2030 году. Для совместных заявлений на эту тему основатель Nvidia Дженсен Хуанг (Jensen Huang) даже отправился в японскую столицу, где разделил сцену с главой Fujitsu Такахито Токитой (Takahito Tokita). Финансовые условия сотрудничества Nvidia и Fujitsu остались за рамками заявлений. По словам главы первой из компаний, Fujitsu буквально создаст аппаратное решение, позволяющие «объединить» свои центральные процессоры с технологиями Nvidia. К 2030 году Fujitsu при поддержке партнёров, в число которых вошла и Nvidia, намеревается построить суперкомпьютер Fugaku NEXT, производительность которого превысит предшественника в пять или десять раз. 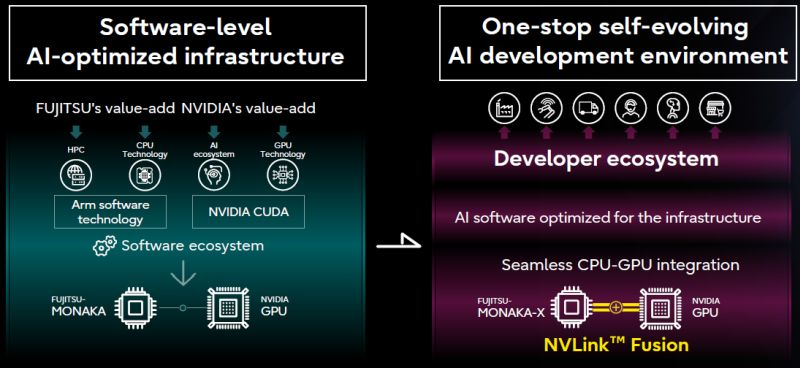 Как признался Хуанг, создание Fugaku NEXT будет только первым шагом на пути реализации множества совместных инициатив Fujitsu и Nvidia. Интеграция с технологиями Nvidia позволит Fujitsu увеличить рыночный охват для своих решений. Японская компания также продвигает идею «ИИ-суверенитета» нации и готова прилагать к её реализации максимум усилий со своей стороны. Кроме того, у Fujitsu за счёт интеграции с частью экосистемы Nvidia откроются перспективы на европейском рынке ИИ. По словам главы компании, её японскую штаб-квартиру регулярно посещают делегации из Европы, интерес к решениям Fujitsu на этом рынке очень высок. Fujitsu и Nvidia при участии разнообразных партнёров также собираются разрабатывать большие языковые модели для робототехники, промышленной автоматизации, торговли, автономного транспорта и здравоохранения. Nvidia открыла доступ к использованию интерфейса NVLink сторонними разработчиками чипов
19.05.2025 [08:28],
Алексей Разин
До недавних пор Nvidia использовала скоростной интерфейс NVLink для передачи данных исключительно в собственной продукции, но необходимость более широкой интеграции разнородных компонентов в современных условиях подтолкнула её к созданию «открытой» версии интерфейса NVLink Fusion, доступ к которому на платной основе она будет предоставлять сторонним разработчикам чипов. 
Источник изображения: Nvidia Прежде всего, данный шаг направлен на появление более сложных серверных систем для работы с искусственным интеллектом, которые будут сочетать компоненты Nvidia с аппаратными решениями других разработчиков, и при этом использовать высокую пропускную способность NVLink. Воспользоваться соответствующим предложением уже готовы компании MediaTek, Marvell, Alchip Technologies, Astera Labs, Synopsys и Cadence. Компании Fujitsu и Qualcomm уже заявили о намерениях использовать NVLink Fusion для интеграции своих центральных процессоров с графическими процессорами Nvidia в сфере ускорения вычислений для ИИ. В случае с Fujitsu речь идёт о 2-нм процессоре Fujitsu-Monaka, который будет использовать Arm-совместимую архитектуру. Стоечные решения Nvidia семейств GB200 NVL72 и GB300 NVL72 за счёт использования интерфейса NVLink пятого поколения, как отмечает сама компания, обеспечивают скорость передачи данных до 1,8 Тбайт/с на один графический процессор, что в 14 раз превышает возможности стандартного интерфейса PCI Express Gen5. Для управления серверными системами, использующими интерфейс NVLink Fusion, компания создала программное обеспечение NVIDIA Mission Control. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



