







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Искусственный интеллект: алгоритмы поиска
Не все, кто блуждают, потеряны Дж. Р. Р. Толкин Поиск в пространстве состояний (англ. state space search) — группа математических методов, предназначенных для решения задач искусственного интеллекта. Википедия ⇡#Поиск в пространстве состояний: от формулировки задачи к решениюА давайте начнем с практики и попробуем решить классическую ИИ-задачку. Итак, три миссионера и три каннибала находятся на одной стороне реки, где также находится лодка, которая может выдержать не более двух человек. Найдите способ перевезти всех на другой берег реки, при этом нельзя нигде оставлять миссионеров меньше, чем каннибалов. Эта задача в свое время широко обсуждалась и была подробно проанализирована еще в 1968 году Амарелем. В 60-е годы алгоритмы поиска вызвали всплеск интереса, а стратегии их решения вошли в классическую проблематику ИИ. В конце статьи мы покажем вам дерево решения этой задачи, а сейчас разберем некоторые важные термины. Любой алгоритм поиска принимает в качестве входных данных некоторую задачу и возвращает решение в форме последовательности действий. Для начала разберемся, из каких элементов состоят понятия «цель», «задача» и ее «решение». Итак, представим себе, что мы отдыхаем на курорте, где перед нами стоит сложная и многокомпонентная задача – наилучшим образом провести свой долгожданный отпуск. Для ее выполнения надо учитывать множество факторов: если вы любите ночную жизнь, надо выбрать оживленную турзону; если хотите просто побродить по городу, надо посетить самые живописные парки, улочки и т. д. Отлично, вы отдыхаете, список дел еще далек от завершения, но... у вас билет в Москву на завтра, не подлежащий возврату. Вы же полетите, даже если еще не везде побывали и не перепробовали все местные деликатесы? Итак, в данном случае вы – агент принятия решений. В вашем случае надо стремиться к достижению цели — попасть на свой самолет. Все остальные действия вам будут только мешать. Первый шаг – сформулировать цель с учетом текущей ситуации и показателей вашей производительности в качестве агента принятия решений. Постановка цели позволяет организовывать поведение, ограничивая агента в выборе промежуточных этапов. Полагаю, что интуитивное понимание цели есть у всех, и мы знакомы с необходимостью жертвовать чем-то ради ее достижения. Таким образом, задача агента принятия решений – найти такую последовательность действий, которая в конечном итоге приведет его в целевое состояние. Эта последовательность и называется поиском. Прекрасно, цель есть, задача – как к ней прийти, а что же дальше? Дальше – формулировка задачи, очень важный этап для успешного достижения вашей цели. То есть вы наверняка постараетесь выяснить, как попасть в аэропорт, сколько времени занимает путь до него, – какие действия и состояния вам надо учитывать для достижения своей цели. Говоря формально, задача состоит из четырех частей: начальное состояние, множество действий, функция проверки цели и функция стоимости пути. Два последних определения нужно, вероятно, объяснить. Функция проверки цели: добрался ли я до пункта назначения? Функция стоимости пути: чего мне стоит каждый этап? В самом тривиальном случае стоимость последовательности действий равна количеству самих действий. На самом деле, конечно, каждый шаг неравнозначен и имеет свою цену. Теперь почему мы говорим именно о поиске в пространстве состояний: среда задачи представлена пространством состояний, а путь через него от начального до целевого состояния представляет собой решение. Алгоритмически скажем так: для решения задачи мы будем применять поиск на основе деревьев, а его разнообразные вариации воплощают различные возможные стратегии. ⇡#Неинформированный поискОбычно изучают пять стратегий неинформированного поиска – такого, при котором не используется никакая другая информация о состояниях, кроме той, что есть в условии задачи. Эти стратегии всего лишь могут вырабатывать преемников и отличать целевое состояние от нецелевого. Тем не менее они лежат в основе многих актуальных методов. Все стратегии поиска различаются тем, в каком порядке происходит развертывание узлов. Мы перечислим эти стратегии ниже для вашей информации и расскажем подробнее о двух основных:
Задача, с которой мы начали сегодняшний рассказ, решается с помощью поиска в ширину (breadth first search, BFS). Это один из классических методов обхода графа, при котором мы посещаем за один раз ближайших «соседей» нашей исходной точки, потом их «соседей», вычисляя при этом расстояние (минимальное количество ребер) от нашей исходной точки до каждой достижимой из нее вершины. Так мы движемся вширь, пока не найдем нашу искомую точку или пока очередь соседей не закончится. Почему-то мне приходит в голову образ поимки преступника, когда поиски идут одновременно в нескольких секторах города вокруг места преступления, обеспечивая наиболее полный охват территории. Давайте запишем этот алгоритм на Python: S = [None] * (n + 1) Что здесь происходит: у нас имеется граф с вершинами от 1 до n. Изначально расстояние S до всех вершин равно None, кроме исходной точки, до которой расстояние равно 0. В переменной begin сохраним номер исходной точки. Q – очередь (от слова queue), Qbegin – ее первый элемент. Чтобы добавить вершину в конец очереди, вызываем метод append для списка, а чтобы удалить вершину из начала списка, увеличиваем Qbegin на единицу (принцип first in, first out). Проверим, не опустела ли очередь: Qbegin < len(Q). Посмотрим внутрь цикла: первый элемент u из очереди убираем, а потом идем по его ближайшим соседям v. Если вершина v не была найдена ранее (проверим это при помощи условия S[v] is None), то расстояние до вершины v считаем равным расстоянию до вершины u+1 и потом добавляем вершину v в конец очереди. Теперь рассмотрим поиск в глубину. При поиске в глубину в памяти хранятся только те узлы, которые лежат на пути от корня до текущего узла. Проще говоря, из исходной точки мы делаем один шаг, от него еще один и так движемся, пока не дойдем до целевого состояния или до состояния, из которого дальше идти невозможно. Если такое произошло, алгоритм рекурсивно возвращается и от точки возврата снова идет вперед до тех пор, пока решение не будет обнаружено. Если вам случалось когда-то заблудиться, то вы представляете себе принцип работы этого алгоритма: телефон разрядился, вы понимаете, что идете не туда, возвращаетесь к знакомому памятнику и ищете дорогу от него в другом направлении. Так может выглядеть реализация на Python: visited = [False] * (n + 1) #проверка, посетили ли вершину? Возьмем снова граф с вершинами от 1 до n. Запустим алгоритм dfs (акроним depth first search): вершину назовем begin, узлы, в которые можно из нее попасть, попадут в список visited (формальным языком, вершины, лежащие в одной компоненте связности с begin). Из вершины посмотрим на все соседние узлы и посетим каждый. При посещении соседей посмотрим уже на их соседей. Список path нам нужен, чтобы построить пути из вершины begin до всех доступных вершин. Как видите, этот алгоритм основан на рекурсии. Чтобы он не зациклился, нам надо отмечать, в каких вершинах мы побывали раньше (в списке visited). А предшественников каждой вершины хранят для того, чтобы потом можно было построить дерево поиска. Выше рассказано о двух основных стратегиях неинформированного поиска. Если вы хотите узнать больше, рекомендуем почитать книгу «Искусственный интеллект: современный подход» (Стюарт Рассел, Питер Норвиг). Информированный поиск Считается, что стратегии информированного поиска в целом обеспечивают более эффективный поиск решения. Общий принцип здесь — поиск по первому наилучшему совпадению (Best-First-Search). Существует целое семейство алгоритмов такого рода с различными функциями оценки. Отличительной особенностью этих алгоритмов является эвристическая функция, обозначаемая как h(n): h(n) = оценка стоимости наименее дорогостоящего пути от узла n до целевого узла. В качестве примеров мы кратко рассмотрим так называемый жадный поиск и более подробно — алгоритм А*. Жадный поиск по первому наилучшему совпадению, или жадный поиск "лучший — первый", во многом похож на поиск в глубину, но он выбирает вершину, которая ближе не к исходной точке, а к цели, полагая, что так будет быстрее найдено решение. У этого алгоритма есть некая функция оценки (эвристика) того, как далеки вершины от достижения цели. Данный алгоритм, как и обход в глубину, не является оптимальным, к тому же он не полный (поскольку способен отправиться по бесконечному пути, да так и не вернуться, чтобы исследовать другие возможности). Поиск A*: минимизация суммарной оценки стоимости решения. Поиск A* – самый известный алгоритм поиска по наилучшему совпадению. Причина его успеха заключается в функции оценки – алгоритм принимает наиболее рациональное решение на каждом своем шаге. Удобнее всего формально описать ее: f(n) = оценка стоимости наименее дорогостоящего пути решения, проходящего через узел n. f(n) = g(n) + h(n), где g(n) — стоимость достижения данного узла, а h(n) — стоимость прохождения от данного узла до цели. Чтобы найти наименее дорогостоящее решение, лучше всего выбирать узел с наименьшим значением этой функции. Как оказалось, поиск А*, при соблюдении некоторых требований к его эвристике (а каких — ответим в следующей статье), может быть и полным, и оптимальным, так что эта стратегия себя вполне оправдывает. Интересно вам было написать программу для А* или кода уже многовато? Пока давайте решим с его применением небольшую задачу: 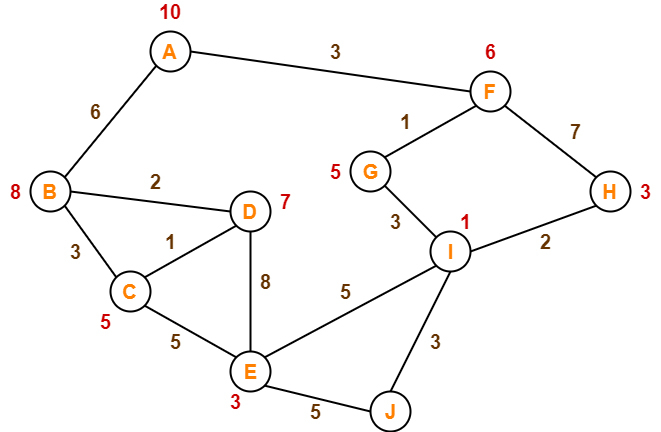 Рассмотрим данный граф. Каким образом его обойдет А*? Шаг 1:
Алгоритм A* просчитает f(B) и f(F).
Путь: A → F Шаг 2:Из узла F можно попасть в узел G и узел H. Алгоритм A* просчитает f(G) и f(H).
Поскольку f(G) < f(H), принимается решение отправиться в узел G. Путь: A → F → G Шаг 3: Из узла G можно попасть только в узел I. Алгоритм A*, тем не менее, просчитает f(I).
Принято решение отправиться в узел I. Путь: A → F → G → I Шаг 4:Из узла I можно попасть в узел E, H и J. Алгоритм A* просчитает f(E), f(H) и f(J).
Поскольку значение f(J) меньше, принято решение отправиться в узел J. Путь: A → F → G → I → J Рассказ об алгоритмах поиска не может быть полным без генетического алгоритма, но ему нужно будет посвятить отдельную статью. В рамках университетского курса ИИ также изучается поиск в условиях противодействия на примере минимаксного поиска и альфа-бета-отсечения – об этом тоже в другой раз. А теперь обещанное дерево к задачке из начала статьи. Обратите внимание, мы исключили ситуацию, когда в лодке находится только один человек, потому что второй должен пригнать ее обратно. Тогда вместе могут поплыть только два каннибала или один миссионер с одним каннибалом. Это и показано на двух единственно возможных узлах, исходящих из вершины. Еще возможен вариант, когда лодка отправится и вернется с теми же персонажами, это не показано на схеме. Однако если вы будете составлять алгоритм, придется эту ситуацию принять во внимание. Далее задача решается уже без проблем, так как достигнуты состояния, из которых переправу можно осуществить с соблюдением условий задачи.  Надеемся, что наш рассказ об алгоритмах поиска в ИИ вызвал у вас желание более глубоко в них разобраться и, возможно, попробовать свои силы в написании собственных программ. Источники:
Другие материалы цикла:
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()





