







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Искусственный интеллект: аналоговые вычислители побеждают
⇡#Что не так с фон Нейманом?Традиционная на сегодня схема организации вычислительного полупроводникового устройства подразумевает физическое отделение процессора от памяти. Программы и данные, в соответствии с принципами фон Неймана, размещаются как раз в памяти (обычно это именно энергозависимое высокоскоростное ОЗУ), а процессор обращается к ней по сопрягающей эти два узла шине данных как за исходной информацией для расчётов, так и для выдачи результатов своих вычислений. Очевидно, что узким местом, которое иногда упоминают даже как «теснину фон Неймана», здесь оказывается пропускная способность внутрикомпьютерной шины данных. Ставший для ИТ-индустрии за десятилетия привычным путь преодоления этой теснины — за счёт неуклонного роста тактовой частоты работы процессора и распараллеливания выполняемых им операций, а также наращивания разрядности и скорости работы самой шины — прекрасно подходит для уверенного решения огромного круга задач. Но машинное обучение, на котором строится вся нынешняя концепция ИИ, в круг этот, к несчастью, целиком не вмещается. 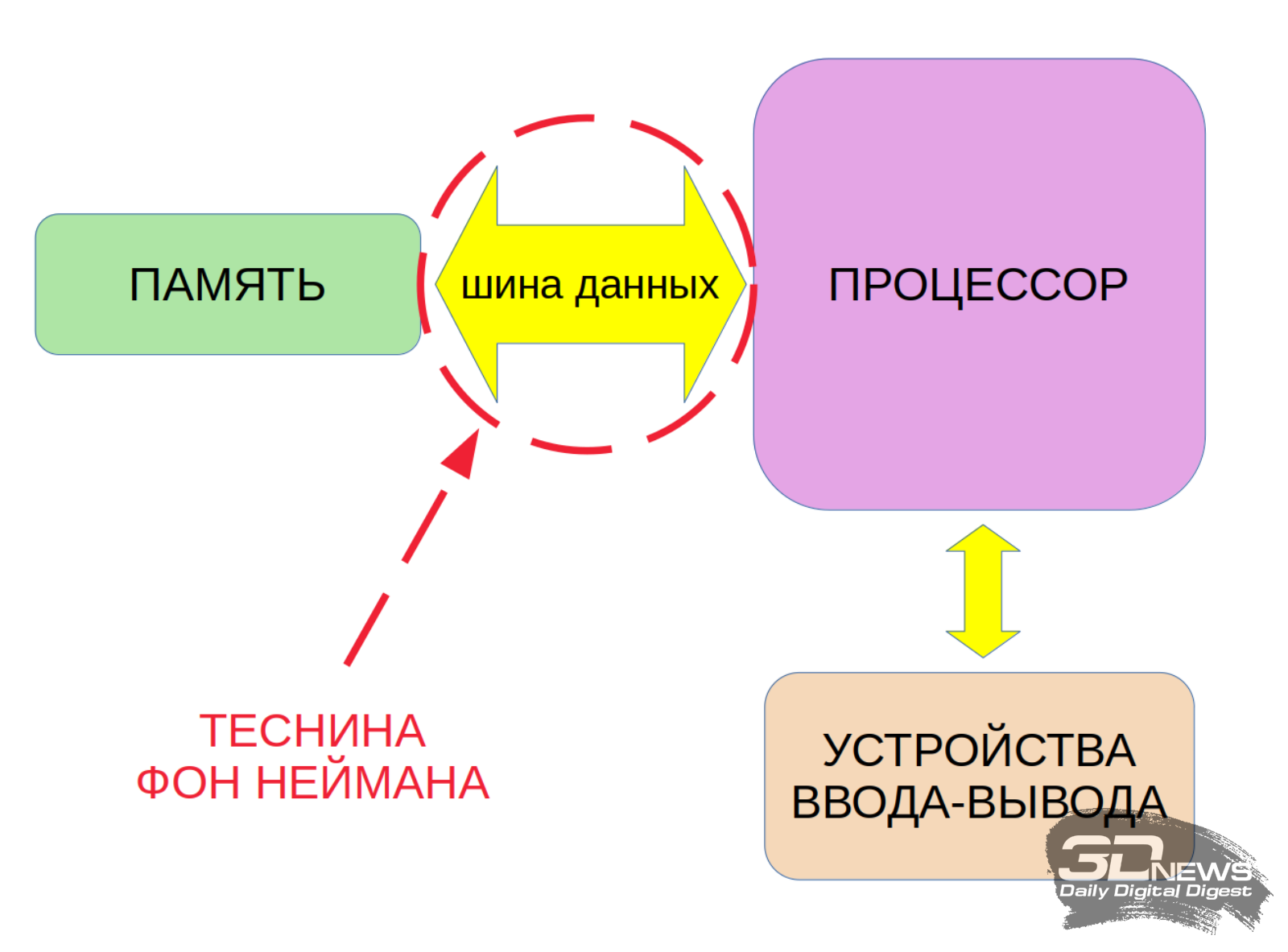
«Теснина фон Неймана» (von Neumann bottleneck) препятствует эффективному решению задач ИИ на компьютерах классической на сегодня архитектуры Суть в том, что основной принцип организации машинного обучения — это моделирование биологической нейросети, которое по сути своей сводится к взвешенному суммированию. В памяти компьютера формируются виртуальные нейроны со множеством входов. Входные сигналы поступают на каждый нейрон по различным входам с разными весами — т. е. с разной значимостью. Грубо говоря, если требуется определить, кошка ли изображена на картинке, веса признаков «есть хвост», «есть усы», «есть лапки с втяжными когтями» будут умеренно положительным, тогда как признак «есть рога», бесспорно, окажется обладающим огромным отрицательным весом. Рассмотрим процесс работы малого участка нейросети подробнее. В теории (и в цифровой модели) такой участок действует по аналогии с тем, как функционирует сеть нейронов в биологическом мозге. Здесь речь идёт именно о подобии, не о точном копировании (в частности, игнорируются химические коммуникации между нервными клетками, к рассмотрению принимаются только электрические), но по уровню развития даже нынешних лучших образцов ИИ уже очевидно, насколько этот путь продуктивен. Итак, грубо можно считать, что от рецепторов (органов чувств) электрические сигналы поступают в многослойную сеть нейронов, а после обработки последней выдаются на эффекторы — преобразователи сигналов в физические действия. То бишь зрительные рецепторы зафиксировали переключение светофора на красный — нейронная сеть сопоставила риски потери времени из-за минутной задержки и травмы в результате ДТП — эффекторы выдали двигательной системе команду притормозить у перехода. 
Биологически нейроны устроены довольно сложно, а структура связей между ними — ещё сложнее (источник: Pixabay) Нейронная сеть представлена в рассматриваемой модели структурой, состоящей из одномерных нейронных слоёв; каждый слой — набор независимых нейронов. У нейрона есть множество рецепторов (приёмников) сигнала, называемых дендритами, и единственный аксон — канал выдачи результирующего импульса. Участок контакта двух нейронов называется синапсом, причём проходящий через данный синапс сигнал определённым образом модулируется на основе обучения — усиливается или, наоборот, ослабевает. Описанная модель синаптических связей представляет, таким образом, каждый нейрон как вычислитель взвешенных сумм сигналов, поступающих к нему от других нейронов. Биологический мозг устроен заметно сложнее, но в математической модели эта сложность компенсируется важной модификацией базового нейрона: у того вместо строго одного аксона допускается несколько выходов. В результате открывается возможность комбинировать слой за слоем, в каждом из которых ряд сумматоров складывает взвешенные (с приписанными синаптическими весами) сигналы, полученные от каждого из нейронов предыдущего слоя, а затем передаёт результаты этого суммирования — тоже с весами, но уже другими — последующему слою. 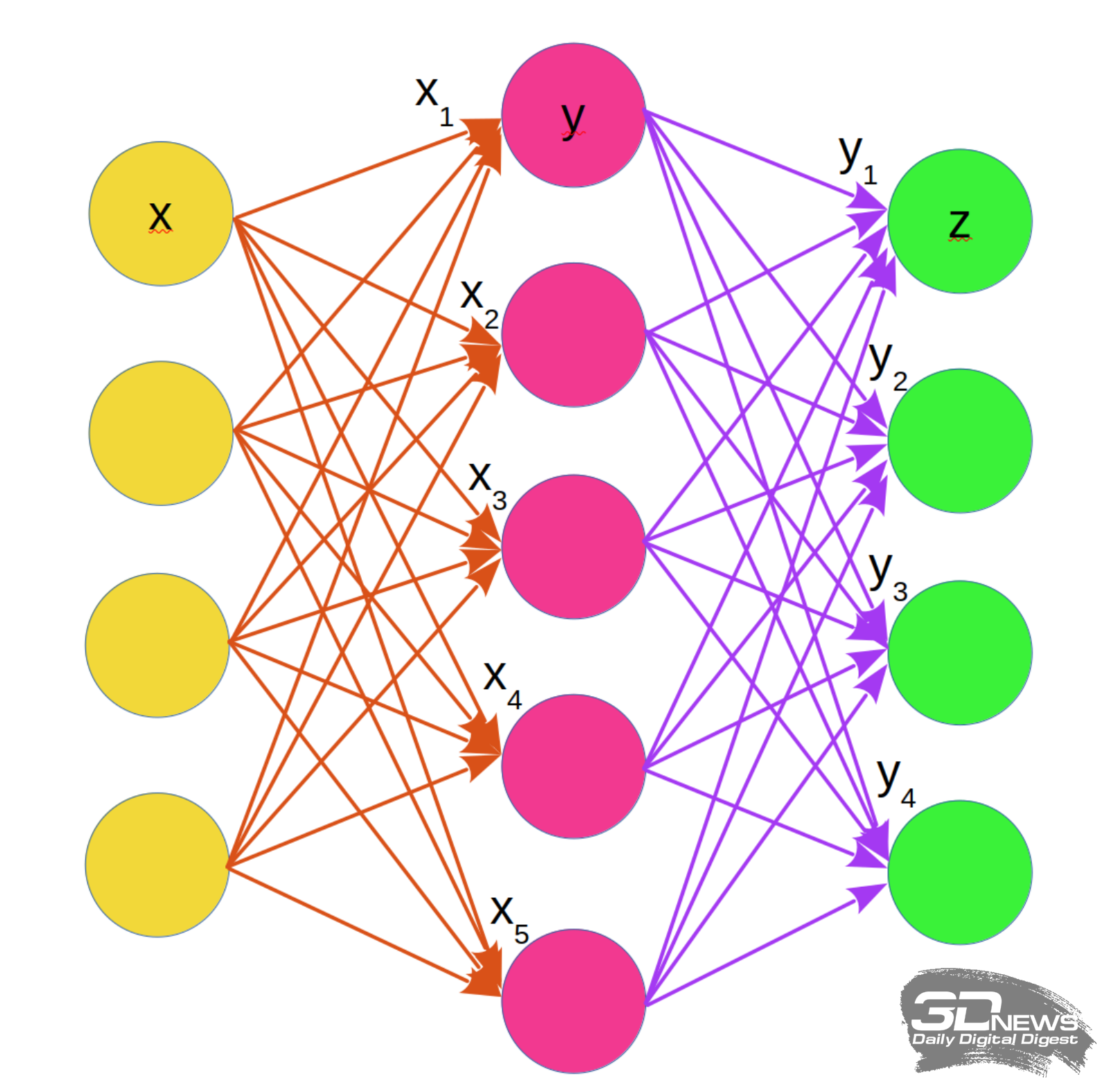
Упрощённая схема организации взвешенного суммирования в однослойной нейронной сети с синаптическими связями. Жёлтым указаны рецепторы, каждый из которых подаёт взвешенные сигналы (оранжевые стрелки) на нейроны (малиновые). Нейроны производят взвешенное суммирование, после чего, уже с новыми весами (фиолетовые стрелки), передают сигналы на эффекторы (зелёные). Буквами с нижними индексами отмечены веса синаптических связей, соответствующих отдельным (на данном рисунке — верхним) клеткам из слоёв рецепторов (x) и нейронов (y) Модель для обучения с одним слоем виртуальных нейронов — это фактически чек-лист со списком ключевых признаков. Просуммировав в столбик все указанные критерии, помноженные на соответствующие им веса, система получит в численном виде вероятность того, кошка изображена на рассматриваемом изображении или нет. Но на практике одним слоем дело не ограничивается: чем сложнее требуемый результат, тем больше необходимо промежуточных итераций. Обучение такой нейронной сети производится путём последовательного подбора синаптических весов для каждого слоя нейронов. Даже для базовой однослойной сети очевидно, насколько трудоёмка эта задача: изначально веса выставляются в некое стартовое значение, сигналы проходят по всей сети, она формирует на эффекторах некий результат — и тот сопоставляется с шаблоном. Если отличие есть (а оно изначально непременно будет), меняются значения весов и полный цикл взвешенных суммирований повторяется. По какому принципу менять веса в каждом слое для новой итерации — вопрос отдельный; главное, что каждый такой шаг требует проведения значительного числа операций умножения и сложения. 
Один из двух шкафов, составлявших шахматный компьютер IBM Deep Blue, в калифорнийском Музее компьютерной истории (источник: Wikimedia Commons) В итоге глубоко проработанная система ИИ оперирует сотнями взаимоувязанных слоёв, причём по каждой комбинации связей производит раз за разом взвешенное суммирование. И всё это — путём непрерывной перекачки гигантских потоков данных по внутренней шине: из ОЗУ в ЦП и обратно. Подлинно «умные» компьютеры вроде Deep Blue, впервые обыгравшего человека в шахматы, или AlphaGo, одержавшего победу над чемпионом мира по игре го, потребляют по 200-300 кВт, тогда как их оппоненты пользуются всё тем же старым добрым биологическим 20-Вт мозгом. Если человечество в самом деле планирует всё шире применять искусственный интеллект для решения своих повседневных задач, придётся изобрести значительно менее энергоёмкие методики взвешенного суммирования. ⇡#Лучше, чем кешСтрого говоря, современные (и даже не самые современные) процессоры уже располагают прямым, не задействующим внутреннюю шину данных доступом к ограниченным объёмам памяти. Речь идёт о процессорном кеше — на данный момент уже многоуровневом и довольно обширном. Кстати, графические адаптеры потому так хорошо подходят для решения задач ИИ, что в их составе и вычислительных ядер великое множество, и сопряжены они практически напрямую с внушительным объёмом оперативной памяти. Правда, на практике для машинного обучения с прицелом на действительно сложные задачи и этого оказывается недостаточно. 
Аналоговая микросхема разработки IBM (Analog AI Chip v1.0) — золотистый квадрат в центре платы; вокруг — управляющая обвязка для контроля состояния каждого из составляющих чип элементов с переменным сопротивлением на основе фазового перехода (источник: IBM) Сегодня наиболее адекватным способом преодолеть «теснину фон Неймана» целому ряду практикующих ИТ-инженеров представляется проведение вычислений непосредственно в памяти (compute in-memory, CIM), без необходимости гонять потоки данных между ЦП и ОЗУ через внутреннюю шину. Речь при этом идёт об энергонезависимой памяти (non-volatile memory, NVM), а не о различных разновидностях DRAM — в немалой мере как раз потому, что на хранение промежуточных данных в NVM не будет расходоваться энергия. То есть фактически CIM в этом случае реализуются на аппаратной базе специализированного процессора с гипертрофированным кешем первого уровня. Хорошо; но причём тут, собственно, аналоговые вычисления, если речь идёт всего лишь о перемещении обрабатываемых данных из DRAM в энергонезависимую память? Всё дело в том, что модуль NVM представляет собой в общем случае прямоугольную матрицу ячеек — хранилищ электрического заряда, позволяющую напрямую смоделировать узлы, соединения и, самое главное, веса для взвешенного суммирования. И операции, производимые над этой матрицей, на деле представляют собой подобие — аналог — работы биологической нейронной сети. Не виртуальное её моделирование на программном уровне, а прямую физическую аналогию — это чрезвычайно важно. 
PCIe-плата расширения Mythic MP10304 Quad-AMP с четырьмя аналоговыми матричными процессорами: потенциальная производительность на задачах ИИ — до 100 трлн операций в секунду, энергопотребление — до 25 Вт (источник: Mythic) Одна из уже сегодня реализующих подобный подходкомпаний, Mythic, использует модуль NVM, непосредственно объединённый с вычислительным ядром процессора, для хранения матрицы весов текущего слоя производимых в рамках машинного обучения операций — или нескольких слоёв, если доступная ёмкость это позволяет. IBM делает ставку на ячейки памяти с фазовым переходом (из кристаллического состояния в аморфное и обратно). Но в любом случае подсчёт взвешенной суммы для CIM с NVM производится прямым умножением вектора входных возмущений (набора данных по каждому из параметров) на матрицу весов. На предметном уровне CIM может реализовываться на различной элементной базе, включая магниторезистивную (MRAM) и резистивную (RRAM) память, память на основе эффекта фазового перехода (PCM) и даже флеш-память (NAND). Высокая производительность аналоговой структуры позволяет реализовывать сложные задачи ИИ, такие как распознавание образов, буквально в реальном масштабе времени и с минимальными (если сравнивать с фон неймановскими компьютерами) энергозатратами — что особенно важно для приложений активно развивающегося сегодня Интернета вещей. 
Принцип действия ячейки переменного сопротивления памяти PCM: при малых значениях входного напряжения вещество внутри ячейки кристаллизуется, при нарастании напряжения переходит в аморфное состояние — и в соответствии с этим меняется величина электрического сопротивления (источник: IBM) ⇡#Просуммируйте этоА теперь — самое главное: как именно реализуется это умножение. Если коротко, то вектор входных возмущений задаётся набором уровней напряжения по каждому из входных каналов. Матрица же весов представляет собой электротехническую микроструктуру с соответствующим распределением сопротивлений по узлам-ячейкам. И вот теперь-то совершенно естественным образом, как и свойственно аналоговому компьютеру, вычисление сводится к реализации объективных закономерностей — в данном случае закона Ома (сила тока = напряжение * сопротивление) для каждого из возмущений, проходящих через матричную структуру резисторов. Суммирование же взвешенных сигналов происходит в соответствии с правилами Кирхгофа для сложения токов в сложных цепях. 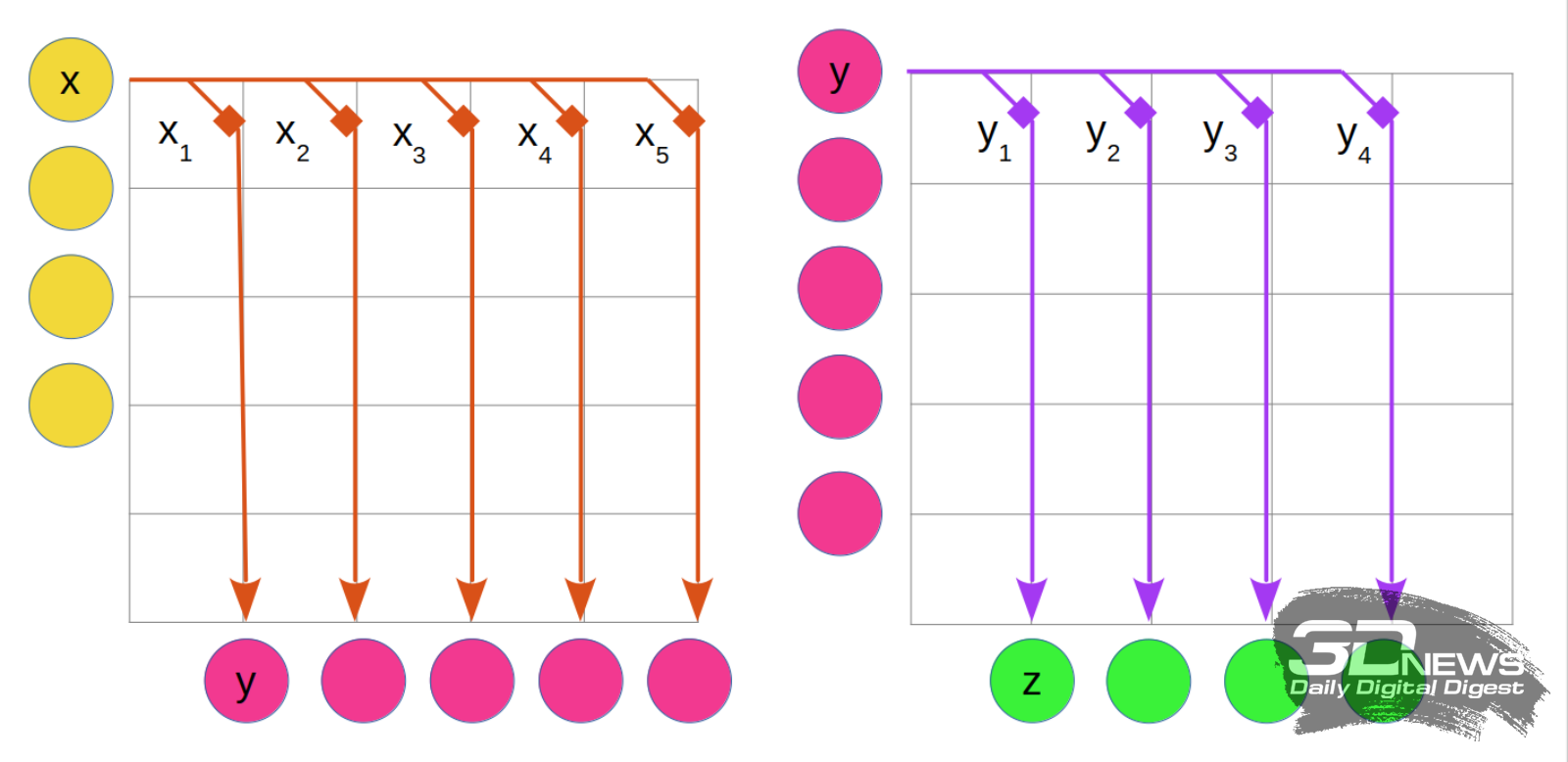
Вот как реализуется аналоговое взвешенное суммирование для однослойной нейросети на матрице с эффектом фазового перехода (phase-change memory, PCM). Цветовая кодировка соответствует иллюстрации «Упрощённая схема организации взвешенного суммирования» Слева на рисунке показан первый этап обработки: передача сигналов от каждого рецептора на нейроны представляется подачей напряжения на соответствующую горизонтальную шину модуля NVM. Веса x1, x2 и т. д. для каждого синапса кодируются величиной сопротивления отдельного PCM-элемента в составе матрицы (отмечены квадратами; такие же квадраты располагаются и в прочих ячейках матрицы — на рисунке они не показаны). Результирующие токи по вертикальным шинам приходят, складываясь в соответствии с правилами Кирхгофа, на приёмные ячейки — это соответствует взвешенному суммированию на нейронах. Величины полученных зарядов фиксируются на конденсаторах (на схеме не показаны), после чего соседняя или та же NVM-матрица может быть использована для второго этапа нейроморфных вычислений (правая часть рисунка). Теперь на входы слева подаются из упомянутых конденсаторов синаптические сигналы от нейронов, а PCM-элементам приписываются новые значения сопротивлений, соответствующие весам y1, y2 и т. д. В результате всё тем же методом взвешенного суммирования — опять-таки по полностью аналоговой схеме, без каких бы то ни было численных операций — получаются финальные величины зарядов для эффекторов. 
Аналоговый матричный процессор Mythic M1076 на плате расширения с интерфейсом М.2 (источник: Mythic) С технической точки зрения NVM-вычислитель представляет собой промежуточное по сложности устройство между модулем памяти и универсальным процессором. Так, аналоговый матричный процессор M1076 разработки Mythic, созданный по 40-нм производственным нормам, содержит 76 матриц на основе КМОП (комплементарной логики с транзисторами на металл-оксид-полупроводнике), что позволяет ему производить нейроморфные вычисления с использованием до 80 млн весов при типичном энергопотреблении на уровне 3 Вт, выполняя до 35 трлн операций в секунду (TOPS) — причём всё это великолепие умещается в формат карты расширения M.2. Применение такого чипа совместно с модулем NVIDIA Jetson Xavier NX, типичным выбором при построении современной цифровой неройсети, даёт возможность, по словам представителей компании-разработчика, поднять эффективную производительность вычислительного блока NVIDIAв 2-3 раза. Полноразмерная плата с разъёмом PCIe и 15 аналоговыми матричными процессорами на борту обещает производительность до 400 TOPS с возможностью назначать до 1,28 млрд синаптических весов и потребляет при этом не более 75 Вт. Схожим курсом движется IBM: она уже испытывает аналоговый NVM-вычислитель на основе элементов памяти с фазовым переходом, размеры рабочей матрицы которого составляют 784 × 250 элементов, — причём запустить свою ИИ-задачу на этом устройстве уже можно прямо онлайн. 
На смену таким раритетам, как этот польский аналоговый компьютер AKAT-1 1959 г., вскоре должны прийти значительно более мощные машины (источник: Britannica) Энергоэффективный ИИ на аналоговой аппаратной базе сумеет в прямом смысле слова оживить множество элементов Интернета вещей, индустриального и домашнего, которым остро необходима способность в реальном масштабе времени анализировать происходящее и формировать адекватную реакцию: от камер видеонаблюдения до автономного транспорта и дронов. По оценкам экспертов, доступные уже в ближайшее время аналоговые вычислители позволят десятикратно снизить потребление энергии в ходе нейроморфных расчётов. Особенно привлекательна в них с точки зрения нынешнего состояния ИТ-индустрии ориентация на зрелые (около 40 нм) технологические процессы, что даёт возможность не сворачивать ради них выпуск привычных микропроцессоров на булевой логике — и в итоге создавать выдающиеся по широкому спектру параметров цифроаналоговые вычислительные комплексы.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





