







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Практикум по ИИ-рисованию, часть девятая: SD3M — «троечка» на троечку
Забавно, как история релизов открытых моделей для преобразования текстовых подсказок в картинки, разрабатываемых и тренируемых компанией Stability AI, походит на череду взлётов и провалов последовательно выходивших версий ОС Microsoft. После легендарно успешной XP, напомним, появилась проблемная Vista; затем великолепная «семёрка» — а за ней безблагодатная Windows 8. У Stable Diffusion за изначально неказистой, но постепенно доведённой энтузиастами до ума версией 1.5 последовала откровенно неудачная SD 2.0 — неудачная, собственно, потому, что включала нетипичный для моделей такого рода кодировщик OpenCLIP, натренированый на весьма неоднозначно отобранных изображениях из открытого датасета LAION-5B. В ходе такого отбора были отсеяны не только неподобающие (NSFW) визуальные референсы, но и картины и иллюстрации за авторством популярных художников вроде пресловутого Грега Рутковски (Greg Rutkowski). Именно последнее окончательно взбеленило энтузиастов: если для SD 1.5 даже в исходном варианте, без применения особо дотренированных чекпойнтов, прекрасно срабатывали простенькие подсказки со стилями — "epic mediefal fantasy landscape, in the style of Greg Rutkowski" — и результат выходил впечатляющим, то SD 2.0 перестала «узнавать» имена наиболее широко известных иллюстраторов, авторские права которых на созданные произведения до сих пор актуальны и которые не соизволили предоставить эти произведения для тренировки ИИ. Приходилось использовать для описания желаемого больше слов, а со слишком длинными подсказками модель ладила плоховато. 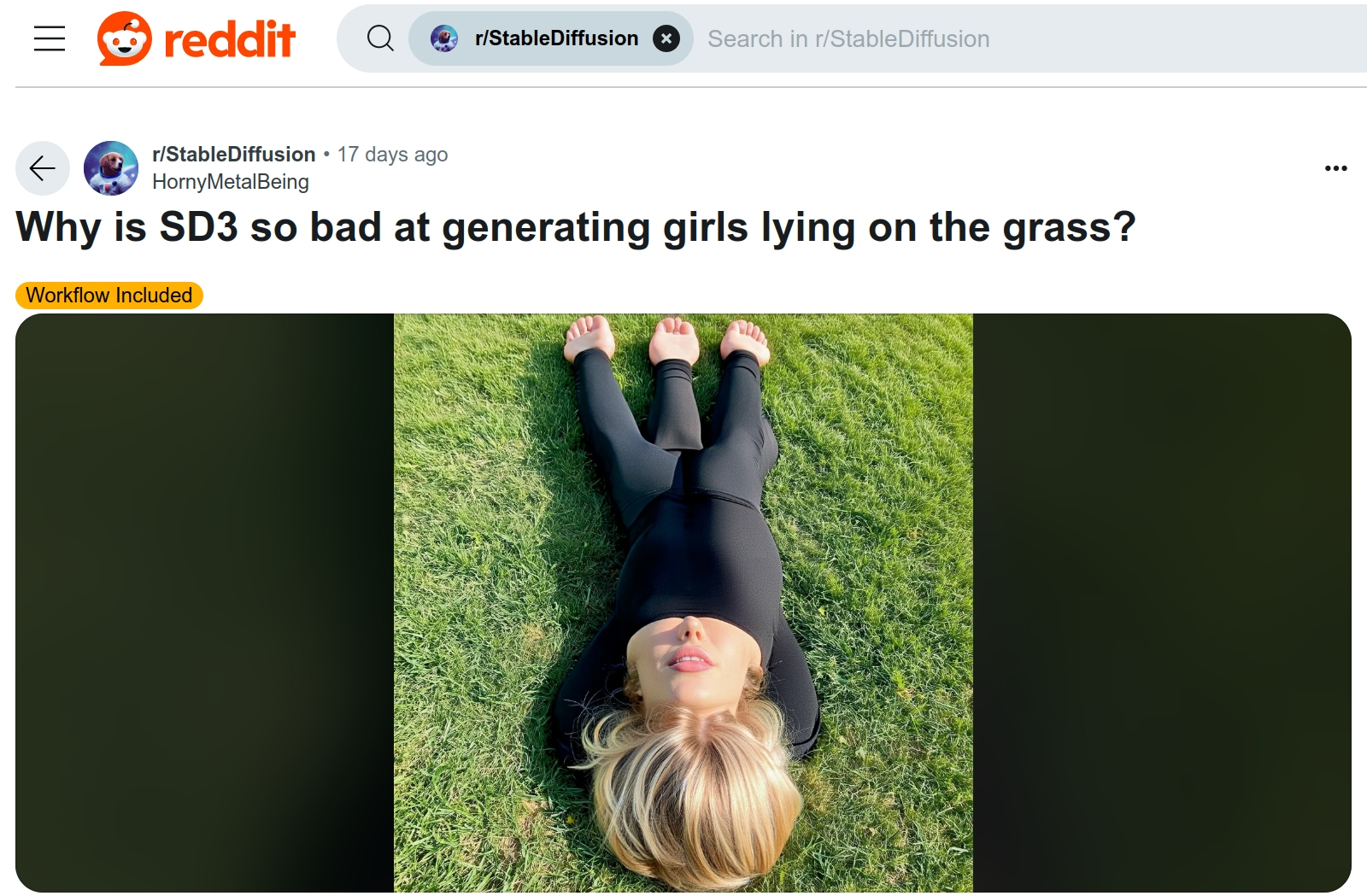
Энтузиаст задаёт простой вопрос, ответ на который придётся ещё поискать (источник: скриншот сайта Reddit) ⇡#Сели — встали, сели — всталиВ сочетании с изменённым кодировщиком (преобразователем текстовой подсказки в цифровые токены, с которыми уже после непосредственно работает модель) невозможность применять именованные стили попросту лишила энтузиастов мотивации дорабатывать «двоечку» своими силами. Ну в самом деле: тут надо было параллельно и разбираться с тем, как подгонять уже отработанную технику составления подсказок под новый кодировщик, и дообучать модель распознаванию тех образов и тем, с которыми создатели на этапе первичной тренировки её не познакомили, — а качественного отличия от «полуторки» генерируемые «двойкой» картинки всё-таки не гарантировали. Да, от стандартного для SD 1.5 размера 512×512 точек произошёл качественный скачок к 768×768, но к тому времени сообщество уже вовсю применяло апскейлеры, аутпейнтеры и прочий инструментарий для увеличения размеров итогового изображения, так что SD 2.0 прошла, по большому счёту, незамеченной. SDXL вернулась к стандартному (разработанному OpenAI и применяемому, в частности, проектом DALL-E) кодировщику CLIP — код его тоже открытый, но вот база данных, на которой он натренирован, в отличие от OpenCLIP, проприетарная. Вдобавок стандартный размер холста вырос у «Оверсайза» до 1024×1024, плюс появился целый ряд дополнительных усовершенствований, — так что энтузиасты с удовольствием взялись за его доработку. И к настоящему времени именно SDXL (да появившиеся не так давно менее требовательные к «железу» его производные вроде SDXL Turbo и SDXL Lightning) можно уверенно считать наиболее популярным ИИ-генератором изображений с открытым кодом. Впрочем, ярые приверженцы SD 1.5 с этим аргументированно спорят, указывая, что такие важнейшие инструменты, как ControlNet, в SDXL до сих пор достойно не перенесены. И вот с 12 июня 2024 г., с момента «выпуска в дикую природу» кода модели, позволяющего локальные генерации, должно было настать время «открытой» версии SD 3 — если точнее, то Stable Diffusion 3 Medium (SD3M или SD3 2B) с 2 млрд рабочих параметров. Условно, напомним, это число соответствует общему количеству весов на входах всех перцептронов модели. Ещё раньше, в апреле, Stability AI довела до ума и предложила для коммерческого использования 8-миллионную (по числу параметров) Stable Diffusion 3 Large, она же SD3 8B. У SDXL 1.0, напомним, — 3,5 млрд параметров, однако SD3M, по утверждению разработчиков, является «самой изощрённой моделью для генерации изображений из всех, что мы создали к настоящему времени». Имелось в виду, что при меньших, чем у «Оверсайза», потребностях в видеопамяти она даже в ответ на несложные подсказки должна будет выдавать изображения «с новым уровнем фотореалистичности». В числе достоинств «троечки» назывались также «беспрецедентное качество типографики получаемого на сгенерированных изображениях текста», «углублённое понимание подсказок за счёт объединения усилий сразу трёх кодировщиков» и «готовность к эффективной дотренировке даже на ограниченных наборах данных». 
Вверху — промо картинки, созданные в стенах Stability AI с помощью, как утверждается, SD3M (странно было бы предполагать, будто в маркетинговых целях здесь использованы генерации полноценной SD3 8B, верно ведь?) с соответствующими им подсказками; внизу — субъективно лучшие из тех изображений, что удалось нам за несколько дней непрерывной работы тестового ПК сгенерировать локально по тем же самым подсказкам на, прямо скажем, скромной по возможностям тестовой машине (источник: Stanility AI и ИИ-генерация на основе модели SD3M) Предполагалось, очевидно, что сообщество энтузиастов, получив в своё распоряжение новую долгожданную игрушку, примется доводить её до ума с тем же рвением, что и «полуторку» и «Оверсайз» в своё время. Однако с самого начала всё пошло не так: SD3M в первые же часы после публикации файлов модели на Hugging Face и Civitai умудрилась глубоко разочаровать свою аудиторию, причём сразу дважды. Первый раз — необъяснимой на первый взгляд идиосинкразией к подсказкам, включающим невинную вроде бы фразу «лёжа на/в траве» (lying on/in the grass); второй — неимоверно туманными формулировками в пользовательском соглашении, в которых оказались не в состоянии с ходу разобраться даже профессиональные юристы. И хотя с точки зрения рядового энтузиаста ИИ-художеств последнее кажется несущественным, на дальнейшем развитии модели именно законная сторона вопроса отразится самым непосредственным образом — вплоть до того, что никакого развития может и вовсе не последовать. Предыдущие творения Stable Diffusion с открытым кодом (точнее, с открытыми значениями нейросетевых весов, доступных для бесплатной загрузки с последующим исполнением локально), такие как SDXL, сопровождались одной из типичных для генеративных моделей CreativeML Open RAIL++-M License с такими характеристиками, как «бессрочная, всемирная, неисключительная, бесплатная, безвозмездная, безотзывная лицензия на авторское право с целью воспроизведения, подготовки, публичной демонстрации, публичного исполнения, сублицензирования и распространения дополнительных материалов как самой модели, так и производных от неё». «Троечка» же предусматривает две разновидности лицензирования: для некоммерческого применения — с весьма расхолаживающими формулировками вроде «Stability AI предоставляет вам неисключительную, всемирную, непередаваемую, не подлежащую сублицензированию, отзывную, безвозмездную и ограниченную лицензию на интеллектуальную собственность» — и куда более обременительную коммерческую. ⇡#Трава не доведёт до добраСпустя совсем непродолжительное время сообщество сошлось во мнении, что Stable Diffusion 3 — это не Open Source. И по сути объявило бойкот компании-разработчику, не желая тратить время и силы на дотренировку откровенно сырой и кривовато выхолощенной модели — с осознанием того, что Stability AI в любой момент может по малейшему капризу своих медиаменеджеров взять и отозвать лицензию, выданную ранее конкретному энтузиасту, производящему такую дотренировку. Сформулирован же лицензионный договор так, что у изучающих его неюристов складывается впечатление, будто вслед за отзывом разрешения на коммерческое применение SD3M бывший его получатель будет обязан удалить все созданные им производные от лицензированной ему интеллектуальной собственности, включая как сами дотренированные модели (LoRA, текстовые инверсии, целые чекпойнты), так и их производные (цитата: «Upon termination of this Agreement, you shall delete and cease use of any Software Products or Derivative Works») — т. е. плоды трудов уже других людей, использовавших эти производные модели как отправную точку для своей собственной работы; причём никем и никак не оплаченной, выполненной на чистом энтузиазме. Вскоре после того, как вал возмущения по этому поводу достиг стратосферных высот, начали появляться сообщения уже от профессиональных юристов, что не всё так плохо и что отзыв с запретом дальнейшего использования на деле должен касаться лишь неких вспомогательных продуктов с закрытым кодом, которые Stability AI передаст коммерческому пользователю (скажем, для ускорения и оптимизации всё той же дотренировки SD3M), — но финальных разъяснений на этот счёт сама компания так пока и не предоставила. И сам факт столь гнетущего молчания на протяжении вот уже трёх недель (на момент написания настоящей статьи) с момента появления «троечки» в открытом доступе вредит репутации разработчика куда значительнее, чем трава — генерируемым его творением девушкам. 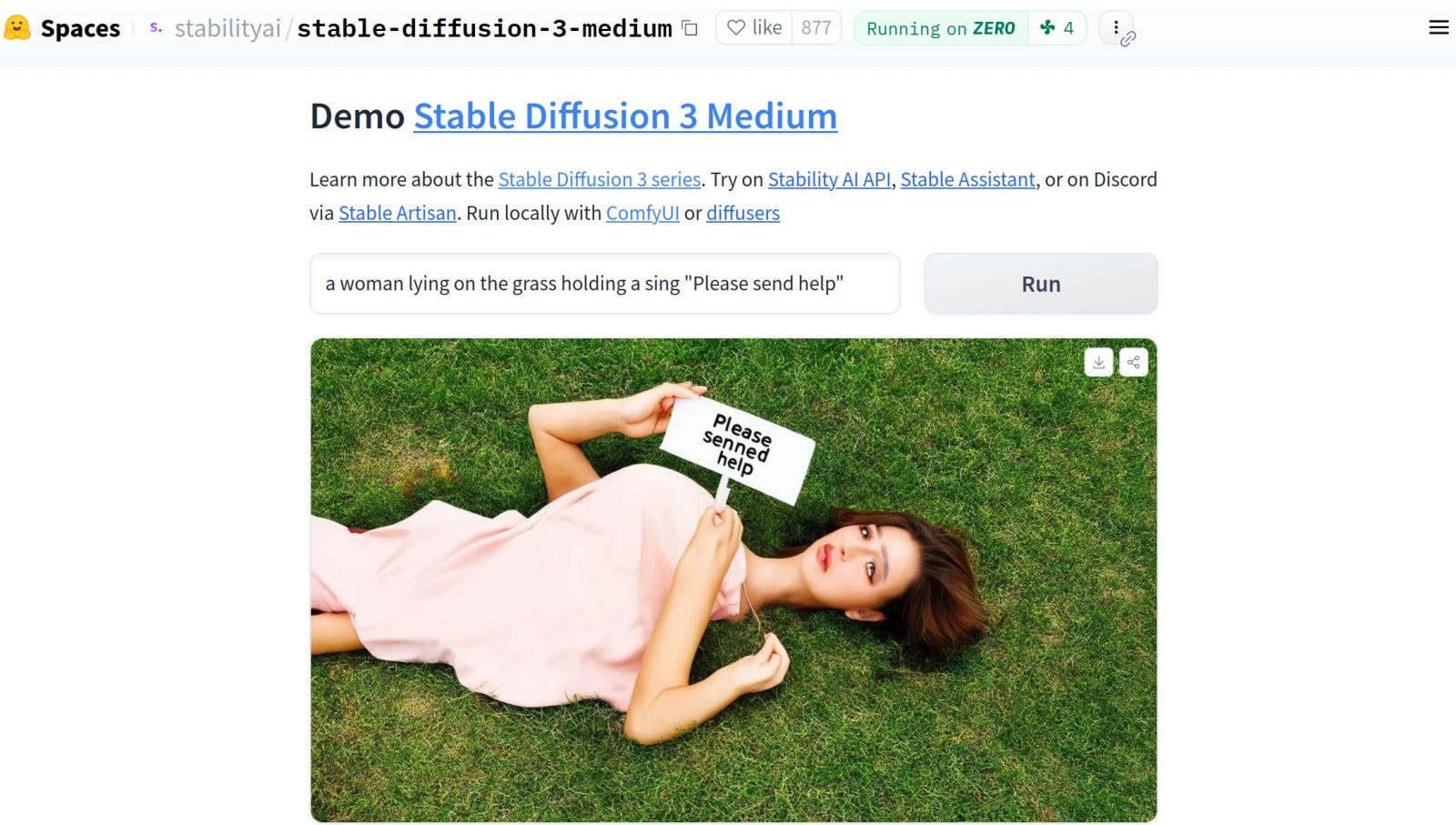
А что, текст-то и впрямь неплохо выходит! (Источник: скриншот демостраницы с общедоступным облачным API SD3M на сайте Hugging Face) Что же касается пресловутой травы, что успела буквально за считаные часы сделаться мемом сперва на Hugging Face, а после и практически на всех более или менее профильных площадках в Сети, то выяснилось, что присутствие в подсказке фразы вроде «a girl lying on the grass» приводит к появлению в выдаче «троечки» не просто галлюцинаций, но кошмарных порождений больной — в медицинском смысле — фантазии художников и кинематографистов, специализирующихся на body horror (заклинаем, если рассудок и жизнь дороги вам, — держитесь от подобного подальше и даже не пытайтесь вбивать эту фразу в окно поиска по картинкам с отключённым фильтром безопасности). При этом изображения стоящих — и чуть в меньшей степени сидящих — людей удаются «троечке» на уверенную четвёрку с плюсом, а портреты порой и вовсе выходят безупречными; по крайней мере, не хуже, чем у базовой модели SDXL 1.0, — загвоздка тут именно в каком-то внутреннем табу на горизонтальное положение человеческого тела. Судя по комментарию Эмада Мостака (Emad Mostaque), основателя и бывшего (до марта 2024-го) главы Stability AI, который ушёл из компании, чтобы «заниматься децентрализованными проектами в области искусственного интеллекта», грубое насилие над SD3M прямо накануне открытия её весов для ограниченного некоммерческого использования (API более крупной модели SD3 8B для онлайн-генерации, напомним, доступно через партнёрские сайты ещё с апреля, но её веса так и остаются сокрытыми) стало следствием стремления нынешнего руководства к безопасности — «в связи с нормативными обязательствами», сформулированными ещё в марте текущего года как Acceptable Use Policy. Именно в рамках этой политики с применением генеративной модели SD3M пользователям не дозволяется «совершать, продвигать, способствовать, облегчать, поощрять, планировать, подстрекать или способствовать дальнейшему насилию, терроризму или созданию контента, вызывающего ненависть, который дискриминирует или угрожает защищаемой группе людей (будь то по признаку пола, этнической принадлежности, сексуальной идентичности или ориентации, религии или др.)», — так что никаких вам изображений панд, в чём мать родила сражающихся с оголтелыми же драконами! Исключительно котики в смешных шляпах, псы в милых курточках, бутылки с неведомым содержимым и свежее, прямиком из духовки, печенье! Если говорить технически, возможно, выхолащивание модели заключалось в том, что из тренировочного набора данных попросту исключили изображения с лежащими людьми и иные картинки, каким-то образом подразумевавшие непристойное толкование, — и потому теперь «троечка» попросту «не понимает» значения слова «лежать». Либо же обновлённая архитектура SD3 позволила достаточно уверенно идентифицировать веса на перцептронах, активирующихся в ходе генерации «небезопасных» изображений, — и веса эти были прямо перед релизом выборочно обнулены, побочным эффектом чего и стало «вынужденное галлюцинирование». Наверное, это уже можно сравнить с лоботомией: кодировщик корректно переводит текст в токены, но в «обезопашенном» латентном пространстве эти токены уже ни на что конкретное не указывают, — и потому результирующие пикселы располагаются на картинке по сути как попало. 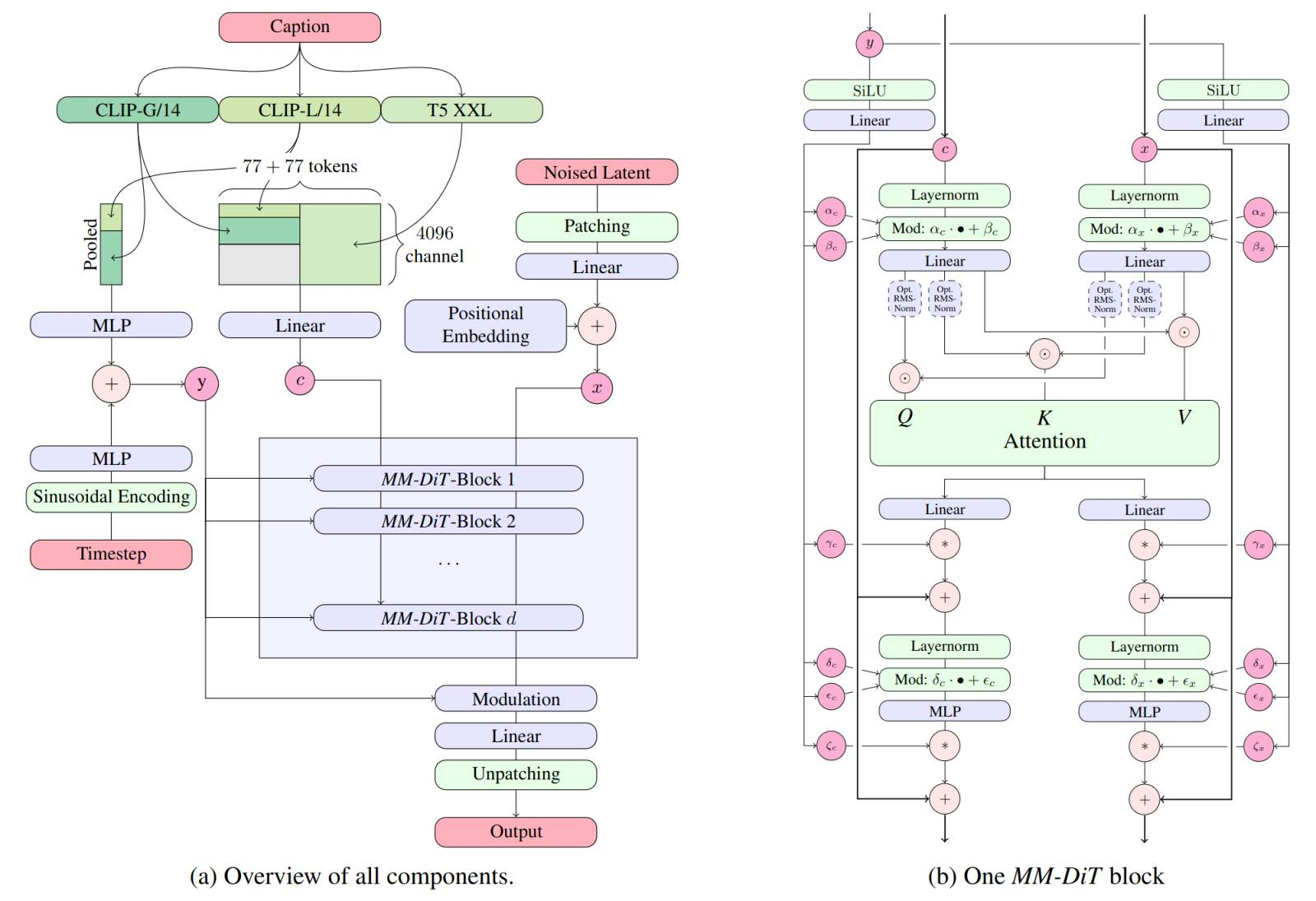
Общая архитектура SD3 (слева) и более детальное изображение одиночного блока MM-DiT (источник: Stability AI) Учитывая доступность API полноценной, но закрытой модели SD3 8B уже на протяжении нескольких месяцев и горячие заверения медиаменеджеров Stability AI в том, что «компактифицированная» 2B окажется почти такой же по качеству восприятия текста и генерации изображений, энтузиасты ИИ-рисования встретили выкладку в общий доступ весов SD3M 12 июня более чем восторженно: за первые 24 часа модель была скачана 2,7 млн раз. На данный момент заполучить её по-прежнему можно, хотя и чуть более кружным путём, чем это привычно для чекпойнтов SDXL и SD 1.5. Собственно, привычный путь — это обращение к сайту Civitai, с которого большинство моделей загружаются без регистрации, но с 17 июня и вплоть до момента передачи настоящей статьи на вёрстку посвящённая «троечке» страница этого сайта пребывает во временном бане. А причина одна: коммерческая лицензия на SD3M написана столь невнятным языком, что даже юристы Civitai взяли паузу для более пристального её изучения. Ведь если некий энтузиаст натренирует на своём ПК LoRA для «троечки» и выложит её на Civitai, а Stability AI вдруг решит, что результат вышел неподобающим, и отзовёт у виновного лицензию, — как в таком случае быть сайту-хостеру? Он ведь не просто размещает у себя чекпойнты, вспомогательные циклограммы и модели, а ещё и предоставляет посетителям возможность и облачной генерации картинок, и тренировки тех же самых LoRA, текстовых инверсий и проч. В общем, пока суд да дело, взять файлы самой модели и трёх идущих с ней в комплекте преобразователей текста в токены можно только с собственной страницы Stability AI на портале Hugging Face. ⇡#Будемте приступатьПравда, есть нюанс: чтобы получить доступ к загрузочным ссылкам, необходимо авторизоваться на сайте, а затем подтвердить принятие упомянутого чуть ранее драконовского лицензионного соглашения — впрочем, процедура эта бесплатная и из России вполне доступная. Всего на выбор предлагаются четыре варианта собственно моделей (models) и четыре же — преобразователей текстовой подсказки в токены (encoders), плюс три эталонных циклограммы для исполнения в рабочей среде ComfyUI, о которой мы как-то уже говорили: модели:
кодировщики:
циклограммы:
Мы в рамках настоящей «Мастерской» ограничимся базовой моделью sd3_medium.safetensors (4,2 Гбайт), тремя кодировщиками — clip_g.safetensors (1,3 Гбайт), clip_l.safetensors (234 Мбайт) и t5xxl_fp8_e4m3fn.safetensors (4,7 Гбайт), а также циклограммой sd3_medium_example_workflow_multi_prompt.json. Дело в том, что на нашей тестовой машине установлена, напомним, видеокарта GeForce GTX 1070 с 8 Гбайт видеоОЗУ, а в этот объём не поместятся более крупные модели со всеми интегрированными преобразователями разом. У чекпойнтов на основе SD 1.5 и SDXL кодировщики по умолчанию встроены в основной файл, но в данном случае этих преобразователей даже не два, а три, в сумме на 6 Гбайт с лишком, — вместе с самой моделью уже выходит больше 10 Гбайт; а если взять 16-битную версию кодировщика T5XXL, то потребуется ещё более выдающаяся видеокарта. В варианте же, когда сперва в видеопамять загружаются преобразователи текста в токены, а потом уже работающая с этими токенами модель, прекрасно удастся обойтись даже 6-Гбайт графическим адаптером. С этой точки зрения модульная «троечка» безусловно выигрывает у типичного SDXL-чекпойнта на 5-7 Гбайт. SD3M представляет собой модель на базе мультимодальных диффузионных трансформеров (Multimodal Diffusion Transformer, MMDiT) — и тем самым принципиально отличается от более ранних разработок Stability AI (да и не только её), которые опираются на архитектуру U-Net, предложенную ещё в 2015 г. «Мастерская» — не место для углублённого изучения разницы между этими подходами к ИИ-генерации картинок; скажем только, что MMDiT обеспечивает повышенную производительность модели, её возможность работать с бóльшим числом токенов (что, в свою очередь, позволяет оператору формулировать весьма пространные текстовые подсказки, а системе — достаточно пунктуально следовать им), а также лучшее качество получаемых в итоге изображений. Полноразмерная SD3 8B способна генерировать изображения на холсте в 4 Мпикс (2048×2048 точек), а также опережает DALL-E 3, Midjourney v6 и Ideogram v1 в таких зачётах, как воспроизведение текста в изображении, точность соответствия полученной картинки текстовой подсказке и общая визуальная эстетика. Преобразование текста в вектор токенов производится здесь сразу тремя кодировщиками (две модели CLIP и одна T5-XXL — «T5», кстати, от Text-To-Text Transfer Transformer) — и, вообще говоря, они не обязаны работать с одной и той же подсказкой. 
Все три модели-кодировщика помещены в подкаталог ComfyUI\models\clip\ установочной директории портативной (т. е. не нуждающейся в полноценной инсталляции — с прописыванием данных в системный реестр, установкой связей с внешними библиотеками и проч.) версии ComfyUI Но довольно предисловий: возьмёмся за то, чему посвящена «Мастерская», — за генерацию изображений на базе модели SD3M. Используем для этого, как уже говорилось, рабочую среду ComfyUI, загрузить которую можно по прямой ссылке с GitHub. Подчеркнём, что этот вариант — только для исполнения на графических адаптерах NVIDIA либо непосредственно на ЦП AMD или Intel (что будет, разумеется, куда как медленнее): владельцам видеокарт AMD предлагается костыль в виде пакетов rocm и pytorch, которые можно установить через менеджер загрузок pip. По завершении установки рабочей среды следует поместить закачанные ранее файлы .safetensors: модели — в каталог ComfyUI\models\checkpoints\ , преобразователи текста в токены — в ComfyUI\models\clip\ . И — можно приступать! ⇡#Время ускоритьсяЗаслуживает упоминания, что AUTOMATIC1111, хорошо знакомая читателям прежних «Мастерских» на тему ИИ-рисования рабочая среда, к концу июня также получила возможность исполнять SD3M, однако в ComfyUI поддержка новой модели пока остаётся наиболее полной. Неудивительно — ведь до самого недавнего времени автор «макаронного монстра», известный сообществу энтузиастов под ником ComfyAnonimous, или просто Comfy, был сотрудником Stability AI, где трудился, в частности, над внутрикорпоративной рабочей средой, которой пользуются сами разработчики. Как мы увидим чуть позже, новейшая версия ComfyUI и в самом деле свидетельствует о наличии у её автора определённых инсайдов относительно того, как устроена и работает эта противоречивая модель, — инсайдов, которыми создатели иных рабочих сред для локального исполнения Stable Diffusion 3 Medium похвастать по понятным причинам не могут. 
После установки свежей портативной версии ComfyUI и помещения файлов моделей в соответствующие подкаталоги запуск сервера рабочей среды производится двойным щелчком по файлу run_nvidia_gpu.bat Установить ComfyUI в портативной (portable) версии под Windows проще простого: после скачивания соответствующего ZIP-архива с официальной страницы проекта достаточно распаковать его в любой удобный каталог; желательно, конечно, на логическом разделе, базирующемся на SSD, а не на HDD, — обмен между накопителем и памятью с учётом предстоящих циклов загрузки-выгрузки моделей даже для генерации одной-единственной картинки (среде надо будет сперва поместить в видеоОЗУ преобразователи текста в токены, затем очистить видеопамять и загрузить собственно SD3M) ожидается тем более изрядный, чем меньше в распоряжении данного компьютера имеется видеопамяти. Кстати, портативная установка хороша ещё и полной своей независимостью: ничто — за исключением объёма свободного пространства на логическом диске — не мешает развернуть локально сколько угодно копий ComfyUI, чтобы вволю поэкспериментировать с различными расширениями, не опасаясь испортить уже отлаженную и отлично работающую систему. 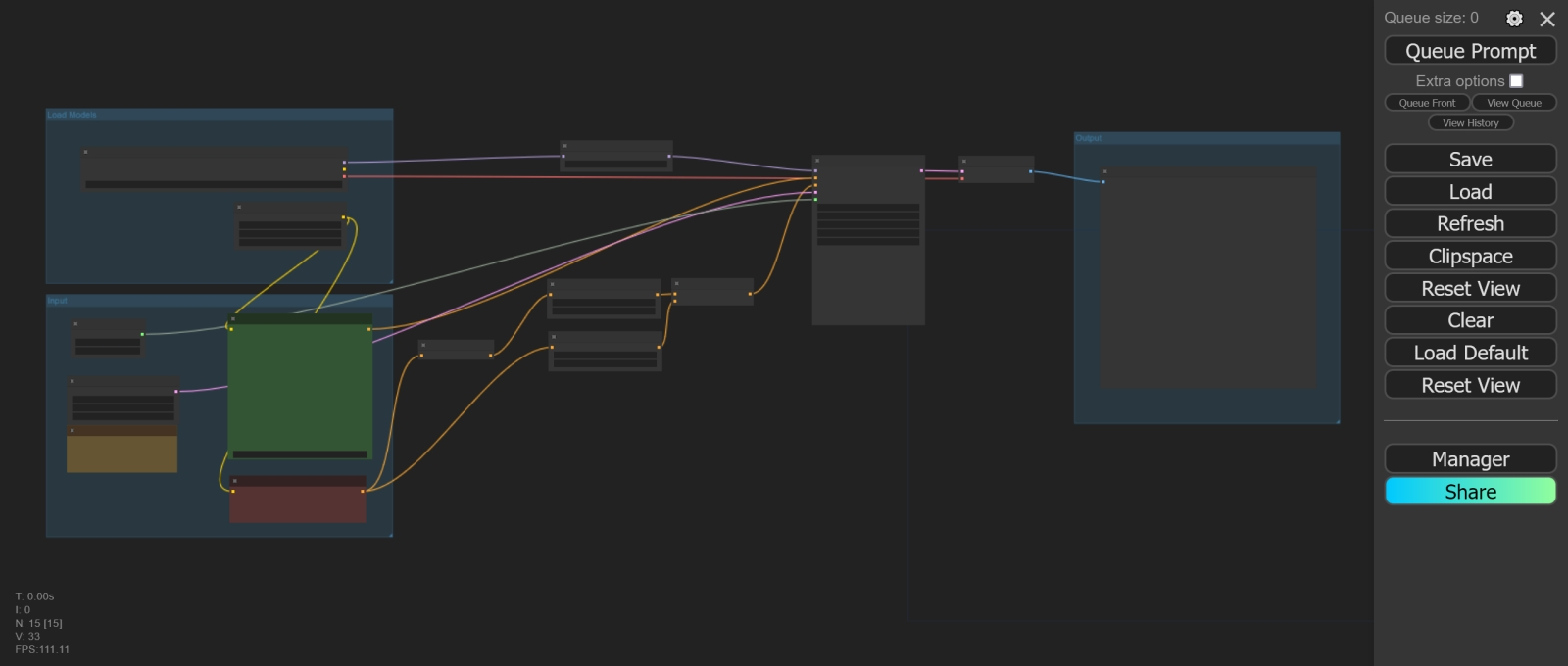
Общий вид (напомним, масштаб отображения в рабочей среде меняется вращением колёсика мыши, когда указатель её расположен на не занятой нодами части поля) опорной циклограммы с множественными полями ввода — на первый взгляд, не так уж она и запутанна Удостоверившись, что файл основной модели SD3M без встроенных кодировщиков текста в токены (файл stableDiffusion3SD3_sd3Medium.safetensors, 4,2 Гбайт) помещён в подкаталог checkpoints (в случае нашей тестовой инсталляции полный путь — C:\Fun-n-Games\ComfyUI-SD3\ComfyUI\models\checkpoints), а все три модели кодировщиков (файлы stableDiffusion3SD3_textEncoderClipG.safetensors, stableDiffusion3SD3_textEncoderClipL.safetensors и stableDiffusion3SD3_textEncoderT5E4m3fn.safetensors; 1,3 Гбайт, 234 Мбайт и 4,7 Гбайт соответственно) — в подкаталог clip (C:\Fun-n-Games\ComfyUI-SD3\ComfyUI\models\clip), можно запускать рабочую среду двойным щелчком по файлу run_nvidia_gpu.bat в корневой папке (в нашем случае C:\Fun-n-Games\ComfyUI-SD3\). После старта сервера в появившемся окне командной строки Windows в браузере по умолчанию автоматически (это подразумевают настройки BAT-файла) откроется новая вкладка, в которой по адресу 127.0.0.1/8188 и окажется доступен веб-интерфейс прирученного уже нами прежде (пусть только в первом приближении) «макаронного монстра». 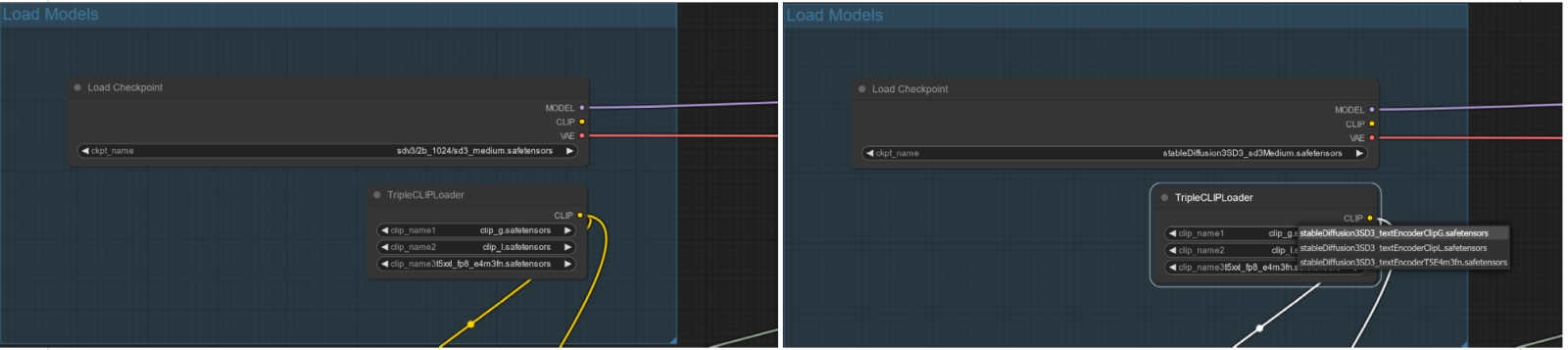
Слева — имена файлов собственно SD3M-модели в ноде «Load Checkpoint» и трёх моделей преобразователей в ноде «TripleCLIPLoader» в том виде, как они указаны в опорной циклограмме ComfyAnonimous; справа — в процессе исправления их на те, что актуальны для доступных для загрузки пользователями файлов того же предназначения В принципе, если в вашем распоряжении имеется более современная видеокарта NVIDIA (поколения RTX, а не GTX, пусть даже всего с 6 Гбайт видеоОЗУ), можно сразу же загружать в рабочую среду опорную циклограмму за авторством самого ComfyAnonimous, о которой говорилось уже ранее, — файл comfy_example_workflows_sd3_medium_example_workflow_multi_prompt.json с множественными окнами для ввода подсказок, по одному на каждый из трёх кодировщиков, — и работать с ней. Правда, сперва надо будет привести четыре имени файлов моделей (в нодах их загрузки) в соответствие с имеющимися. Автор опорной циклограммы, очевидно, оперировал на своём рабочем месте (в Stability AI, как уже упоминалось) с доступными ему локально файлами, называвшимися чуть иначе, так что, если нажать кнопку «Queue Prompt» в спартанском интерфейсе ComfyUI сразу после подгрузки циклограммы, рабочая среда выдаст сообщение об ошибке. ⇡#Трёхполье для ИИ-генерацииВпрочем, это исправить как раз несложно: гораздо сильнее удручает тот факт, что имеющаяся в нашем распоряжении видавшая виды GTX 1070 чудовищно медленно обрабатывает SD3M — генерация картинки идёт со скоростью в 27-30 секунд на каждую итерацию, и, если учесть, что параметр «Steps» в опорной циклограмме установлен в значение «28», времени уходит неоправданно много. Поэтому проведём небольшую оптимизацию — воспользуемся Python-модулем venv (virtual environments, «виртуальных окружений»), призванным, в частности, ускорять работу генеративных ИИ-моделей. В комплект поставки портативной версии ComfyUI он не входит, однако есть множество способов его установки, которые в итоге сводятся к развёртыванию полноценного окружения Python на локальном ПК — и активации необходимого модуля уже из этого окружения. 
Модифицировать BAT-файл для запуска ComfyUI с предварительной активацией venv можно в любом простом текстовом редакторе Будем рассчитывать на то, что следящие за нашими «Мастерскими» читатели уже располагают активной рабочей инсталляцией AUTOMATIC1111 на своих машинах. В этом случае всё значительно проще: модуль venv там уже развёрнут, и всё, что требуется сделать для активации его при запуске рабочей среды ComfyUI, — это должным образом произвести вызов. Для начала следует завершить работу сервера, переключившись на его окно и нажав «Ctrl» + «C», а затем введя «y» для подтверждения; после — скопировать BAT-файл run_nvidia_gpu.bat в новый, с именем, допустим, run_with_venv.bat. Исходный файл запуска весьма лаконичен — он просто вызывает портативно развёрнутую копию Python с параметром --windows-standalone-build: .\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build pause Параметр этот сам по себе не слишком однозначен — он подразумевает некие оптимизации, которые, скорее всего, рассчитаны как раз на более свежие графические адаптеры NVIDIA и потому могут ухудшать жизнь тех, кто до сих пор продолжает хранить верность своим заслуженным GTX. По этой причине уберём --windows-standalone-build из командной строки, а заодно откажется и от другой новомодной оптимизации — активного по умолчанию «умного менеджера памяти», smart memory, который стремится удерживать как можно больше информации в видеоОЗУ, не выгружая её. Это действительно ускоряет рисование ИИ-картинок, однако вместе с тем превращает наш морально устаревший компьютер в однозадачную систему — ни заниматься веб-сёрфингом, ни играть, ни даже работать с документами и почтой на ПК параллельно с активностью рабочей среды становится уже невозможно. Так что для тех, кто не располагает выделенным компьютером для ИИ-художеств, оптимальным представляется такой BAT-файл для запуска ComfyUI (не только с целью генерации картинок с SD3M, кстати, — для SDXL он тоже вполне подойдёт): @echo off call cd C:\Fun-n-Games\Git\stable-diffusion-webui\venv\Scripts echo %cd% call activate.bat echo venv activated call cd C:\Fun-n-Games\ComfyUI-SD3 echo %cd% call .\python_embeded\python.exe -s ComfyUI\main.py --disable-smart-memory pause Здесь предполагается, что портативная установка ComfyUI проведена в каталог C:\Fun-n-Games\ComfyUI-SD3\, а AUTOMATIC1111 ранее была проинсталлирована в C:\Fun-n-Games\Git\stable-diffusion-webui\ . Многочисленные «echo» нужны просто для визуального контроля того, что смена директорий проходит нормально и нужные команды исполняются, — после того как всё будет отлажено, их можно убрать из BAT-файла. 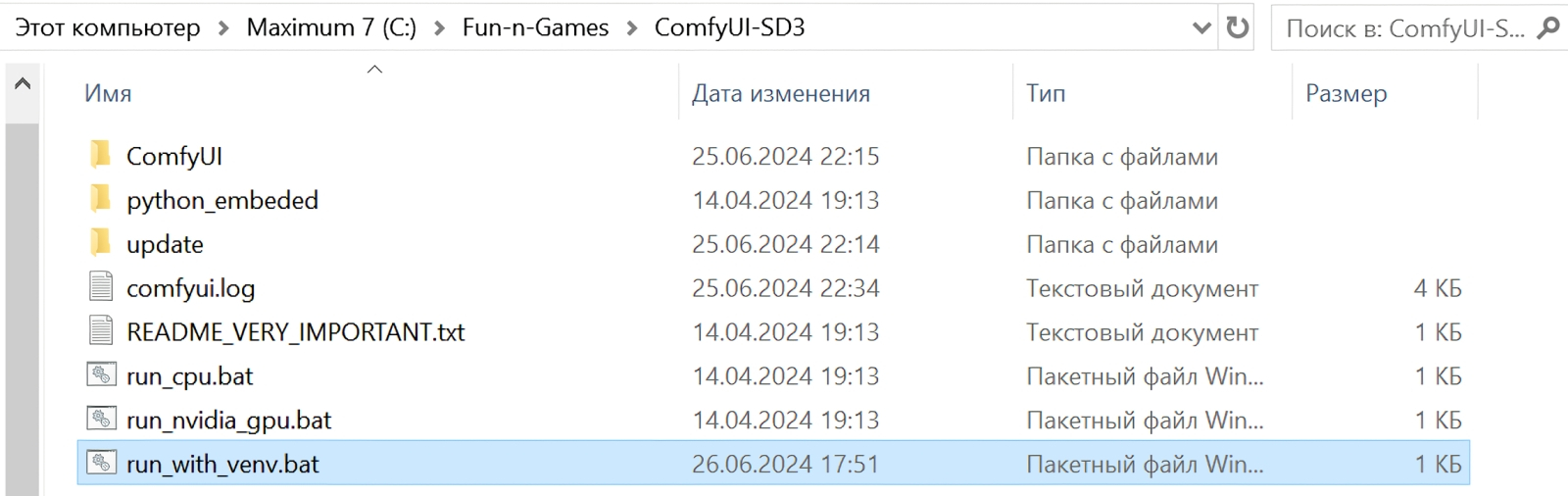
Отныне запускать сервер ComfyUI надо будет BAT-файлом run_with_venv.bat Снова запускаем рабочую среду, на сей раз дважды щёлкая по run_with_venv.bat. Поскольку мы ранее просто закрыли сервер, а веб-интерфейс не трогали, в соответствующей вкладке должна всё ещё оставаться та самая опорная циклограмма ComfyUI со скорректированными именами моделей. Обратим внимание на правую её часть: там размещена нода «Preview Image», которая не сохраняет готовую картинку на диск, а лишь демонстрирует её. Если запускать всякий раз циклограмму для генерации строго одного изображения, оценивать его визуально, что-то менять в параметрах, снова запускать — это вполне рабочий вариант: понравившуюся картинку всегда можно сохранить вручную щелчком правой кнопки мыши на ней. Но если производить в рабочей среде множество генераций последовательно, лучше, чтобы их результаты автоматически накапливались в постоянной памяти (в каталоге ComfyUI\output\ по умолчанию). 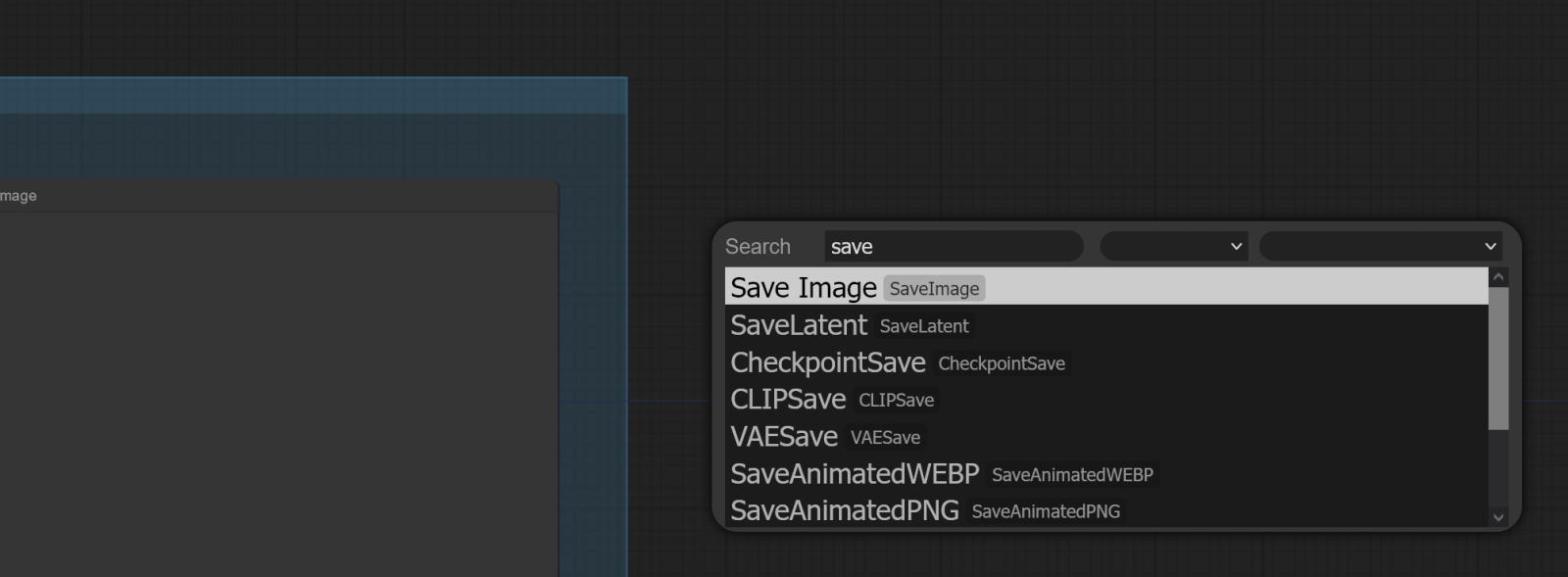
Двойной щелчок по пустой «миллиметровке» фона рабочей среды вызывает окно поиска нод Так что лучше сразу же поменять ноду «Preview Image» на «Save Image». Для этого щёлкаем левой кнопкой мыши дважды на любом свободном участке циклограммы — откроется окно выбора нод со строкой поиска. В этой строке начнём набирать «Save…» — и практически сразу же увидим искомое название. Дальше останется лишь кликнуть по нему и подсоединить вход появившейся ноды к выходу «IMAGE» ноды «VAE Decode», куда исходно была подсоединена «Preview Image». Саму же «Preview Image» можно далее убрать — просто выделить её, щёлкнув по заголовку, и нажать клавишу «Del» на клавиатуре. 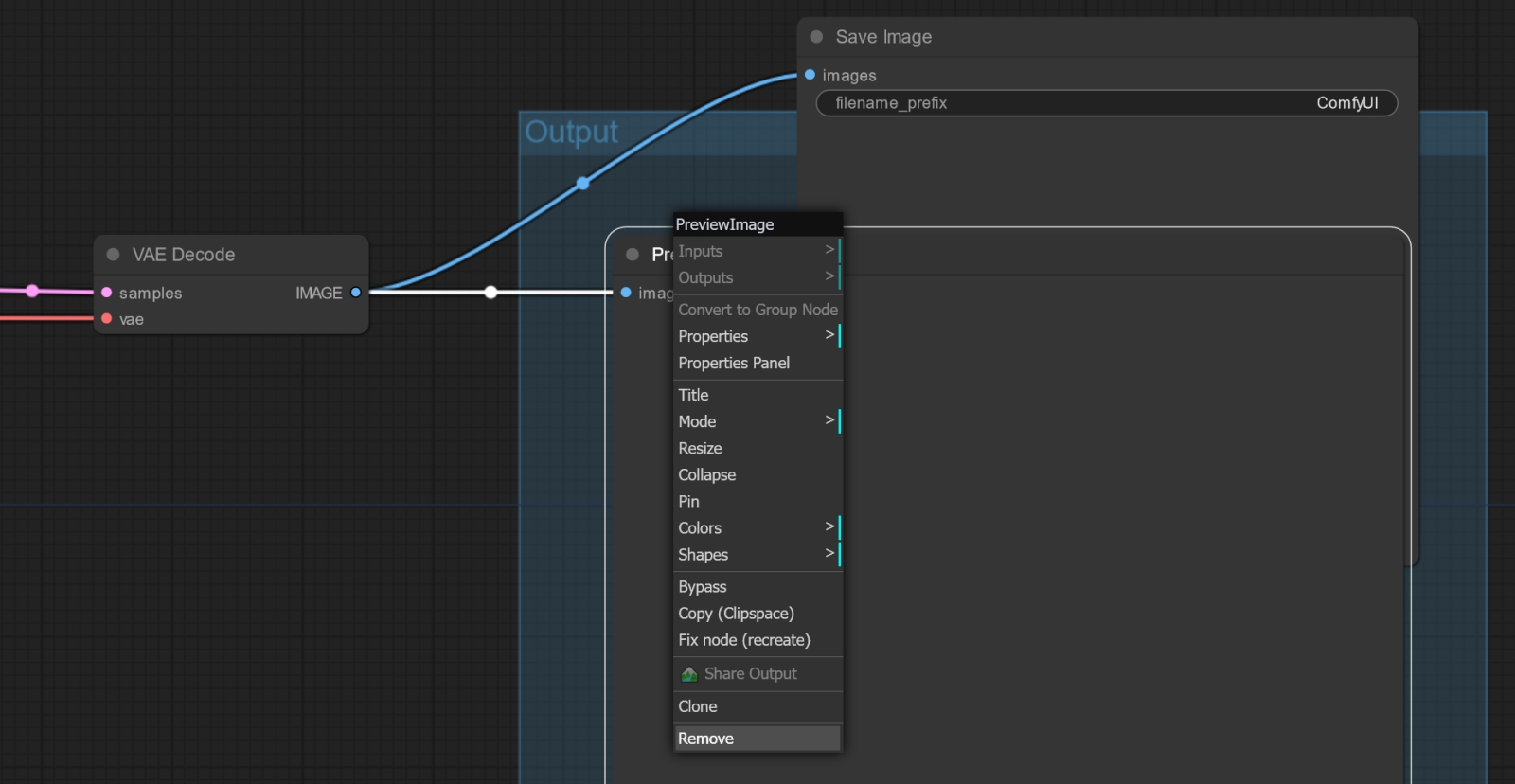
Удалять ноды можно и через меню, открывающееся при правом щелчке мыши по их заголовку И вот теперь — самое время запустить опорную циклограмму за авторством ComfyAnonimous (с нашими скромными коррективами) на исполнение. Получается вот что:  Весьма впечатляющая картинка, с настроением даже, — и не скажешь, что создана она при помощи той же самой модели, которой напрочь сносит башню инструкция отрисовывать лежащих на траве людей. При этом работает система довольно бодро — примерно 5-6 с на итерацию для картинки площадью в 1 Мпикс на GTX 1070 можно считать достойным показателем. Для сравнения: тот же ПК в той же ComfyUI с тем же BAT-файлом генерирует SDXL-картинки схожих размеров, тратя примерно 6-7 с на каждую итерацию, так что «троечку» вполне можно признать менее требовательной к аппаратному обеспечению ПК, на котором ведётся ИИ-генерация.  Подправим теперь размеры холста. Неподалёку от ноды «EmptySD3LatentImage», которая их задаёт, расположена «холостая» (в смысле, ни к чему ни с какой стороны не подключённая) справочная нода «Note», где содержится важное напоминание: общая площадь картинки в случае SD3M должна составлять примерно 1 Мпикс, — исходя из чего и следует подбирать размеры сторон прямоугольного холста. Зададим их тогда как 1344×768 — как раз примерно 1,03 Мпикс и выйдет. Обратим внимание: выше располагается нода «Seed», где задана собственно затравка, в данном случае «945512652412924», и указано, что меняться после генерации она не должна (параметр «fixed»).  Исполним ту же циклограмму с прежней затравкой, но уже для прямоугольного холста. Сразу же становится заметно, что времени на исполнение в целом уходит меньше, хотя скорость отрисовки осталась прежней — менее 6 с на итерацию. И это логично: раз текстовые подсказки не менялись, то загружать для них кодировщик(и) заново не требуется. Картинка на выходе, понятное дело, несколько отличается от первой, квадратной, но не принципиально — общая композиция, как и следовало ожидать, сохранилась. 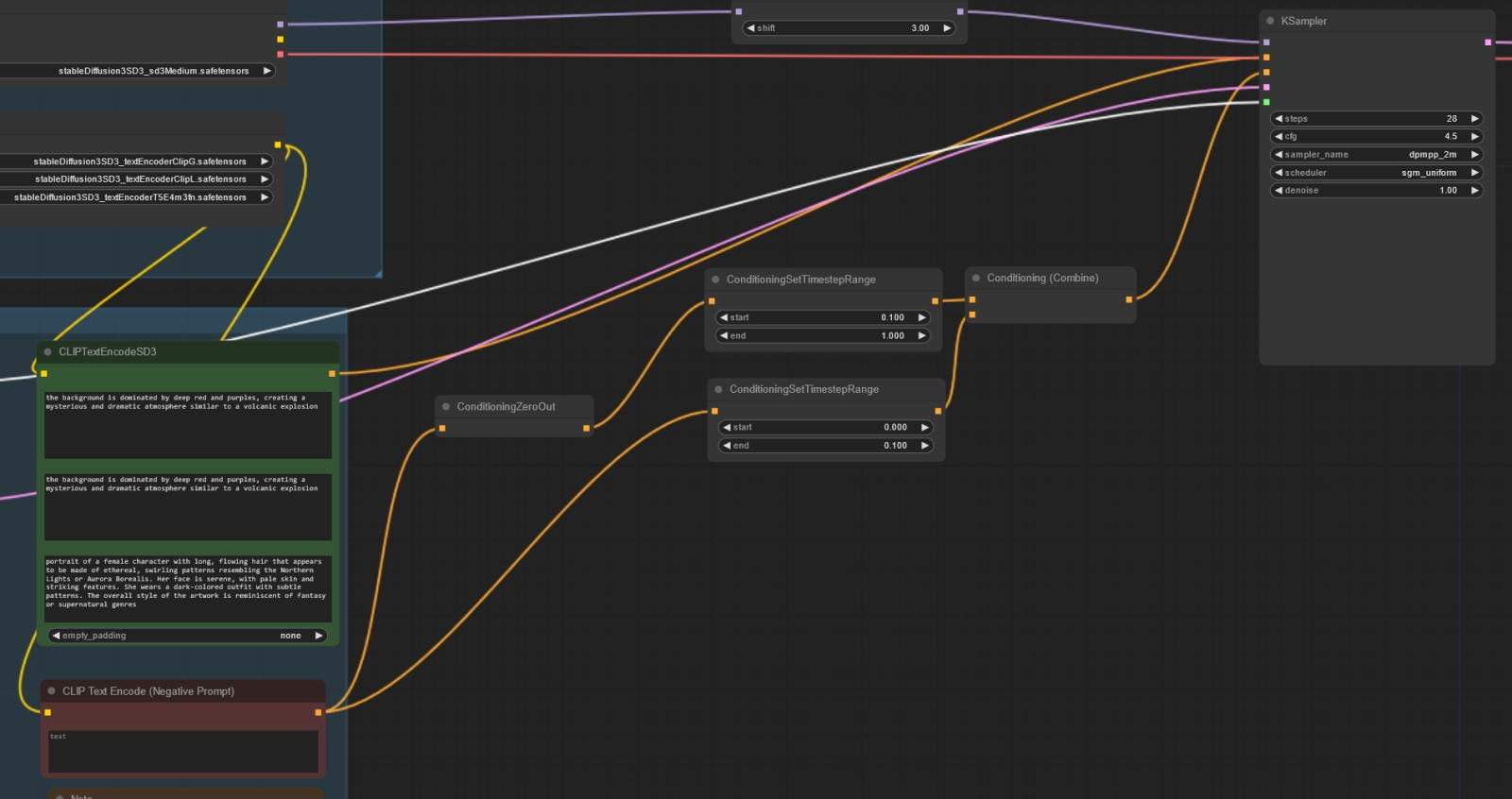 Теперь обратим внимание на ноды «CLIPTextEncodeSD3» и «CLIP Text Encode (Negative Prompt)». Первая выделяется тем, что содержит сразу три поля ввода; если убрать из них текст, станут видны пометки, для каких кодировщиков они предназначены, — сверху вниз это CLIP G, CLIP L и T5XXL. Прежде подобных нод в ComfyUI по понятным причинам не было. Опорная циклограмма содержит дублирующиеся недлинные подсказки для первых двух текстовых полей (для преобразователей CLIP G и CLIP L) и куда более пространную для третьего — T5XXL. Понятно, что содержанием этих полей можно в широких пределах играть, и само изучение того, в какой мере изменение текста в них влияет на итоговую картинку, представляет собой нетривиальную, но архиувлекательную задачу. Впрочем, по причинам, которые станут ясны чуть позже, заниматься ею вплотную мы пока не станем. А вот в ноде «CLIP Text Encode (Negative Prompt)», напротив, нет ничего особенного, — однако оцените, насколько непрост путь от неё до соответствующего входа «conditioning» основной ноды «KSampler»! Путь этот раздваивается, причём одна из его ветвей (верхняя в данном случае) указывает, что начиная с 10% шагов генерации и до её завершения система вообще не будет принимать в расчёт негативную подсказку (прохождение пути через ноду «ConditioningZeroOut» как раз и означает обнуление условия). Тогда как вторая ветвь пропускает негативную подсказку (тоже условно с половинным весом) в дальнейшую обработку без изменений — но лишь на первых 10% от общего числа шагов генерации. ⇡#Туманное далёкоЕщё раз: первые 10%, т. е. 3 из 28 назначенных в данном случае, шагов генерации негативная подсказка передаётся в ноду «KSampler», занятую формированием изображения в латентном пространстве (в пространство пикселов, т. е. в постижимую человеком картинку, результат её выдачи переводит следующая нода, «VAE Decoder»), нормальным образом: верхняя ветка (с обнулением условия) неактивна, работает только нижняя. Оставшиеся же 90% шагов (25 из 28 в нашем случае) негативная подсказка не работает вовсе: активна как раз верхняя ветка передачи условий — с их обнулением, — а движение по нижней блокировано граничным параметром срабатывания соответствующей ноды «ConditioningSetTimestepRange». Теперь понятно, почему ряд обозревателей утверждает, будто негативные подсказки для SD3M можно в принципе не использовать, — эффект от них (если рассматривать именно эту, опорную, циклограмму и предполагать, что на сайтах с онлайновой генерацией по модели SD3 Medium действуют аналогичные правила) минимален. 
Слева — генерация на основе модели SD3M в точности по опорной циклограмме, в середине — она же, но с пустой негативной подсказкой, справа — негативная подсказка та же, что и в первом случае, но передаётся на ноду «KSampler» напрямую, без разделения на ветви и активации дополнительных условий И всё-таки он есть: если просто взять и напрямую соединить выход ноды «CLIP Text Encode (Negative Prompt)» с соответствующим входом «KSampler» (или же пометить все промежуточные ноды с условиями на этом пути как «пропускаемые», «Bypass», что приведёт к тому же эффекту), качество итоговой картинки ощутимо ухудшится. Это, кстати, можно рассматривать в качестве косвенного доказательства «непропечённости» SD3M, поскольку отрегулировать силу и значимость негативной подсказки, строго говоря, разработчикам должно было быть по силам ещё до выкладки весов модели в открытый доступ. Две ветки хитро заданных условий применения негативной подсказки — своего рода заплатка, и в этом смысле сетования энтузиастов на то, что «троечка» откровенно не дотягивает до раскочегаренных маркетинговым отделом Stability AI в её отношении ожиданий, смотрятся вполне обоснованными. Отсутствие хотя бы краткого официального руководства по работе с SD3M привело к тому, что по Сети уже бродят слухи, будто эту модель вовсе не тренировали на применение негативных подсказок. Что, конечно, не так, но в любом случае применять эти подсказки надо точно иначе, чем это привычно операторам SD 1.5 и SDXL. В частности, энтузиасты на полном серьёзе утверждают, будто добавление в негативное поле детальных описаний как можно большего количества непристойностей (да-да, старого доброго «nsfw, nude» недостаточно — придётся всерьёз напрячь фантазию) приводит к заметному улучшению внешнего вида даже пресловутой девушки, лежащей на траве. Так это или нет — не выяснить без вдумчивой проверки (причём не факт, что даже маркировка «18+» в шапке нашего сайта убережёт издание от исков со стороны разъярённых ревнителей нравственности, если мы рискнём опубликовать скомпонованную энтузиастами «чудо-подсказку» — даром что она на английском). Эта забавная ситуация напоминает казус с раннесредневековыми поучениями против язычества, благодаря которым — именно потому, что в них содержались довольно детальные описания того, что и как не следует делать добропорядочным христианам, — до нас дошли хотя бы отрывочные письменные свидетельства о верованиях и обычаях дохристианской Руси. 
В чём SD3M точно хороша, так это в пространственном позиционировании объектов. Подсказка в данном случае такая: «a blue sphere on top of red cube, a calico cat is sitting to the left of the cube, a husky dog is barking to the right of the cube, a small funny mouse is dancing on top of the sphere» (источник: ИИ-генерация на основе модели SD3M) Теперь, хочется верить, стало понятнее, по какой причине углубляться далее в изучение SD3M на данном этапе представляется не самой разумной тратой сил и времени. Там действительно есть что обсудить и что поисследовать: и довольно жёстко рекомендованные параметры генерации в ноде «KSampler» (CFG — 4,5-5,0; число шагов — около 28; пара sampler/scheduler — исключительно dpmpp_2m/sgm_uniform, иначе качество выдачи ощутимо падает); и крайне значительный разброс субъективного качества генераций при строго одних и тех же стартовых параметрах, но с разными затравками; и избавление от пресловутого «проклятья лежания в/на траве» (для чего уже предлагаются весьма нерядовые решения); и, собственно, выяснение того, на какие же именно параметры генерации влияет каждый из трёх преобразователей текста в токены — и как, оперируя ими, добиваться получения настоящих шедевров ИИзобразительного ИИскусства (если такое с «троечкой» возможно в принципе, конечно). Тем более что увольнение Эмада Мостака в марте и ComfyAnonimous в июне, да и далеко не их одних, — не единственные неприятности, настигшие Stability AI. Как сообщает Reuters со ссылкой на The Information, этот британский стартап буквально только что (на момент написания настоящей статьи) в очередной раз поменял главного исполнительного директора которым стал Прем Аккараджу (Prem Akkaraju), ставленник известной глобальной группы ИТ-инвесторов — а та, в свою очередь, готова влить в компанию немалую сумму наличными (речь идёт о 80 млн долл. США). Положение самой Stability AI как бизнес-структуры сегодня откровенно нестабильно; многие разочарованные энтузиасты прочат ей скорый конец — и в такой ситуации сложно ожидать от компании вдумчивой работы даже над столь очевидными ошибками. 
Подборка субъективно удачных локальных генераций SD3M (оригиналы с циклограммами — в архиве по ссылке, указанной в конце статьи): ведь может же, может иногда! Непродуманная же лицензионная политика удерживает, увы, сообщество от самостоятельного доведения SD3M до ума, как это было с SD 1.5 и SDXL. Уж по крайней мере производные чекпойнты и инструменты вроде LoRA для последних двух моделей гарантированно останутся доступными для локального исполнения, даже когда (и если) Stability AI закончит свой путь как коммерческая структура. Сразу после оглушительного фиаско «троечки» на профильных форумах в Сети стали всё чаще раздаваться голоса в поддержку создания некоммерческого проекта по разработке генеративной модели для преобразования текста в образы на основе краудфандинга, — и к настоящему времени это движение начинает оформляться под именем Open Model Initiative. О готовности деятельно присоединиться к нему уже заявили Invoke (одна из площадок для онлайновой ИИ-генерации, ориентированная на профессиональные студии), Comfy Org (команда, занимающаяся поддержкой и развитием ComfyUI), Civitai (в представлениях не нуждается) и команда, стоящая за LAION (базой аннотированных изображений, именно на которой по большей части и тренируются такого рода модели). Так что в обозримой перспективе новые выпуски «Мастерской» будут, скорее всего, ориентироваться на работу с теми моделями, для которых сообщество уже успело создать широкий набор усовершенствований и дополнительных инструментов, — на «полуторку» и «Оверсайз». Возможно, время торжества SD3M ещё наступит, — но сегодня трудно даже предположить, когда именно. А пока интересующиеся могут загрузить архив с приведёнными в этой статье генерациями SD3M (циклограммы интегрированы прямо в PNG-файлы; достаточно перетащить картинку на рабочее поле ComfyUI из «Проводника» Windows, чтобы воспроизвести весь порядок и параметры генерации) здесь. Может, кто-то из наших читателей сумеет раньше завсегдатаев Reddit и Hugging Face обнаружить оптимальный способ распределения текста по трём полям подсказки, например? 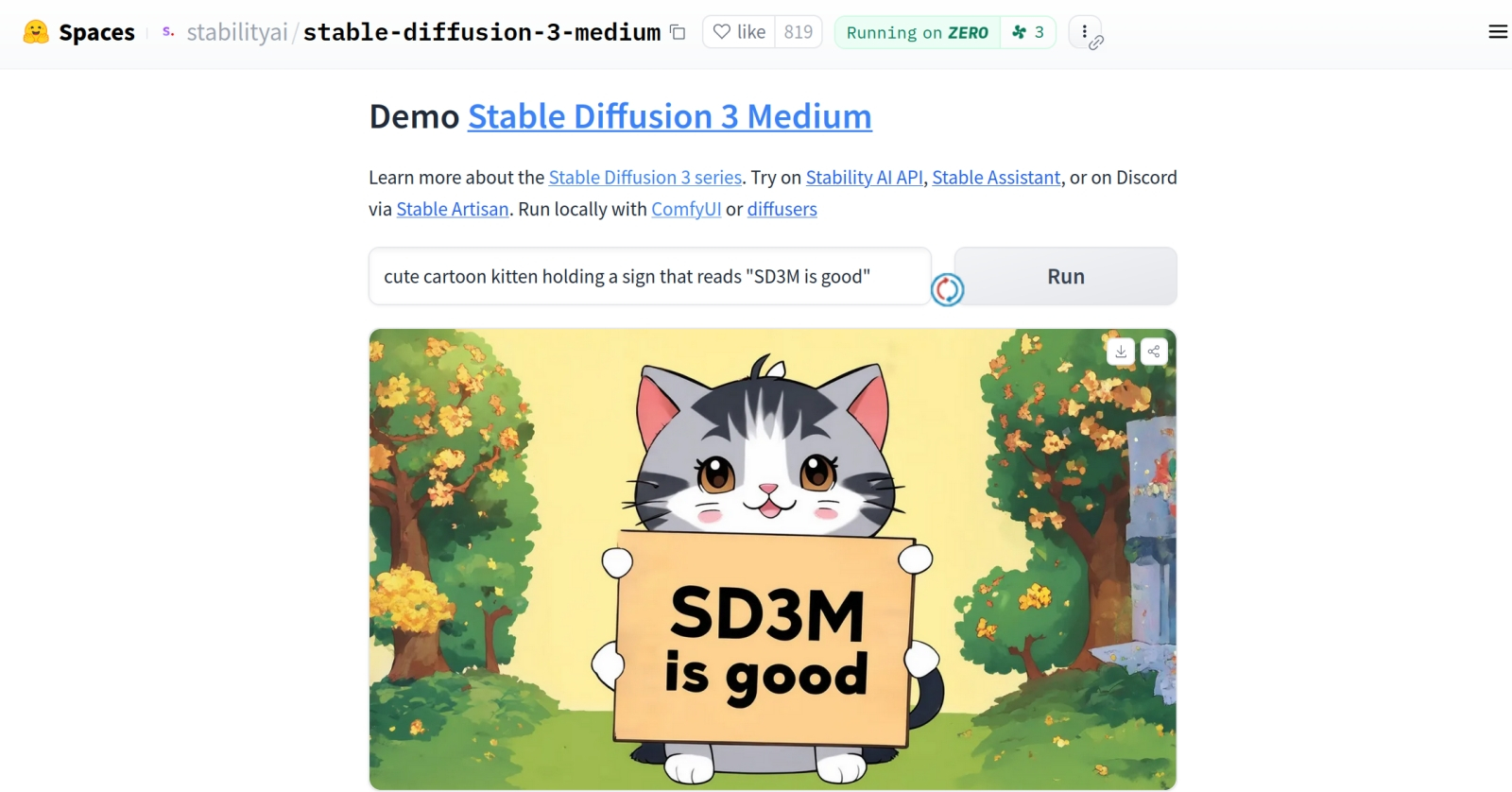
А вообще, всё с SD3M в порядке. Шестилапый кот-мультяшка врать не станет! (Источник: скриншот демостраницы с общедоступным облачным API SD3M на сайте Hugging Face) Материалы по теме: Stability AI сменила руководство и привлекла 80 млн долларов инвестиций. Stability AI погрязла в долгах и теперь ищет себе покупателя. ИИ-стартап Stability AI сократит 10 % персонала из-за усиления конкуренции. Анонсирована Stable Diffusion 3.0 — ИИ для рисования сменил архитектуру и научился писать.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





