







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexВ последний день акции Shipmas, в рамках которой было обещано в течение 12 дней показывать, анонсировать и рассказывать о новых ИИ-функциях, компания OpenAI представила пару больших языковых моделей нового поколения o3 и o3-mini, обладающих способностью рассуждать.









Источник изображений: OpenAI
OpenAI отмечает, что речь не идёт о выпуске новых языковых моделей сегодня. Компания пояснила, что обучение этих нейросетей ещё не завершено и окончательный результат их обучения может отличаться от того, о чём она говорит сегодня. В то же время OpenAI принимает заявки исследовательского сообщества на тестирование этих моделей перед их публичным выпуском. Компания ещё не решила, когда это произойдёт.
В сентябре этого года OpenAI запустила думающую ИИ-модель o1 (кодовое название Strawberry). Решение назвать новые модели o3 связано с тем, что таким образом компания решила избежать путаницы (или конфликтов товарных знаков) с британской телекоммуникационной компанией O2.
Термин «рассуждающая модель ИИ» в последнее время стал очень модным в среде разработки технологий искусственного интеллекта и машинного обучения. Однако, по сути, он означает лишь то, что для решения заданного вопроса машина разбивает заданные инструкции на более мелкие задачи. Это в конечном итоге позволяет добиться от неё более точного результата. «Рассуждающие» модели ИИ чаще всего показывают весь процесс решения и то, как ИИ пришёл к тому или иному ответу, а не просто дают окончательный ответ без объяснения.
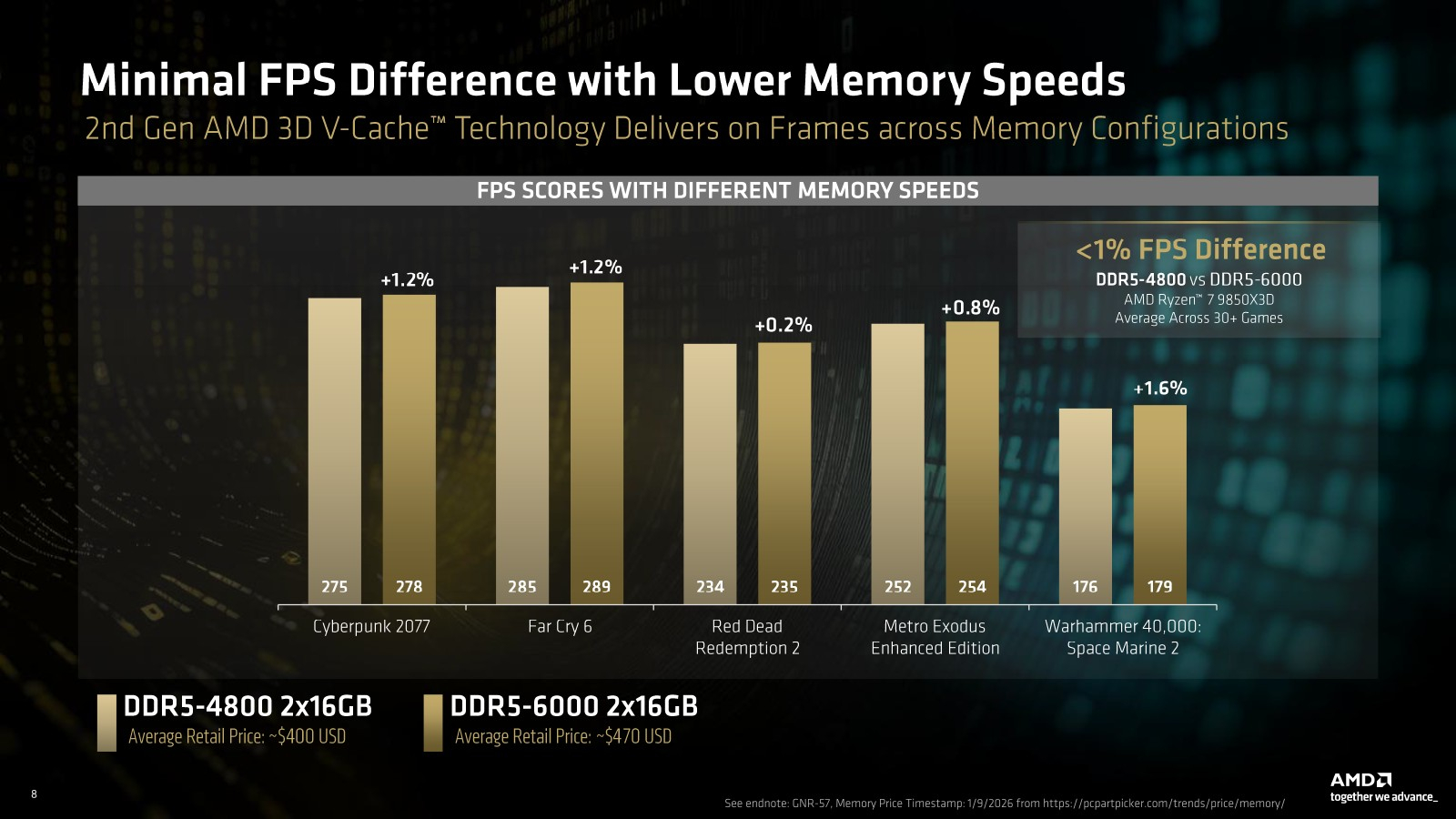
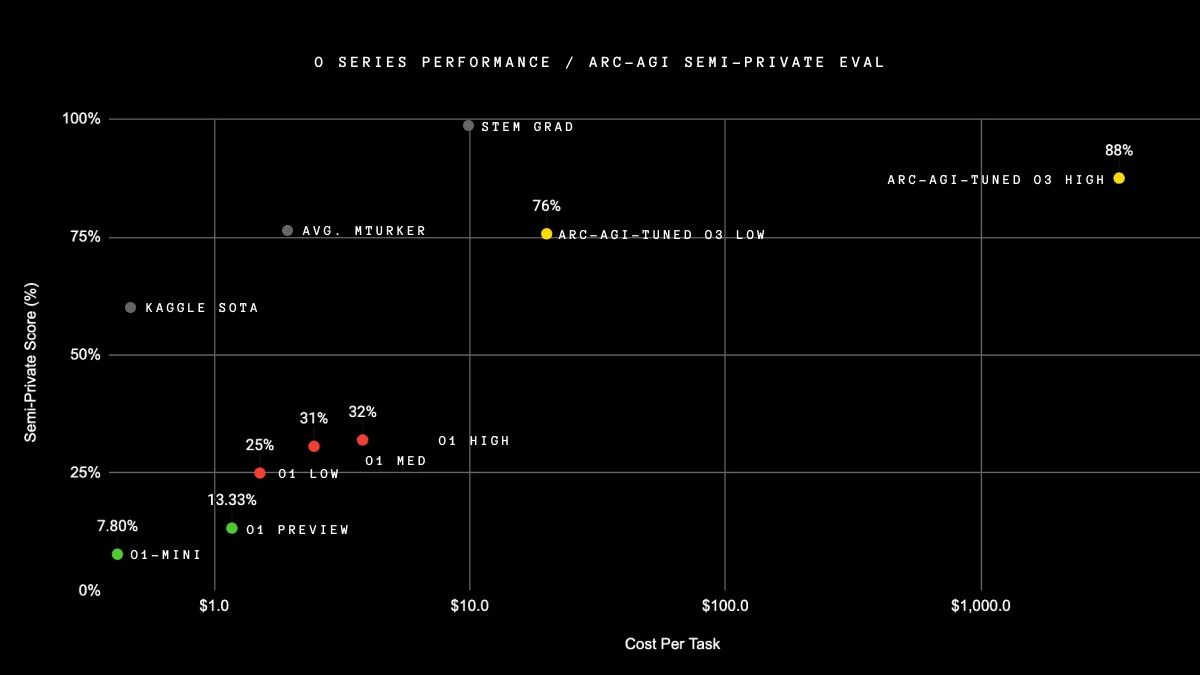
Как утверждает OpenAI, её новая модель o3 превосходит предыдущие рекорды производительности по всем направлениям. В рамках теста ARC-AGI, который был специально создан для сравнения возможностей искусственного интеллекта с интеллектом человека, модель o3 более чем в три раза превзошла возможности o1, продемонстрировав результат в 88 %.
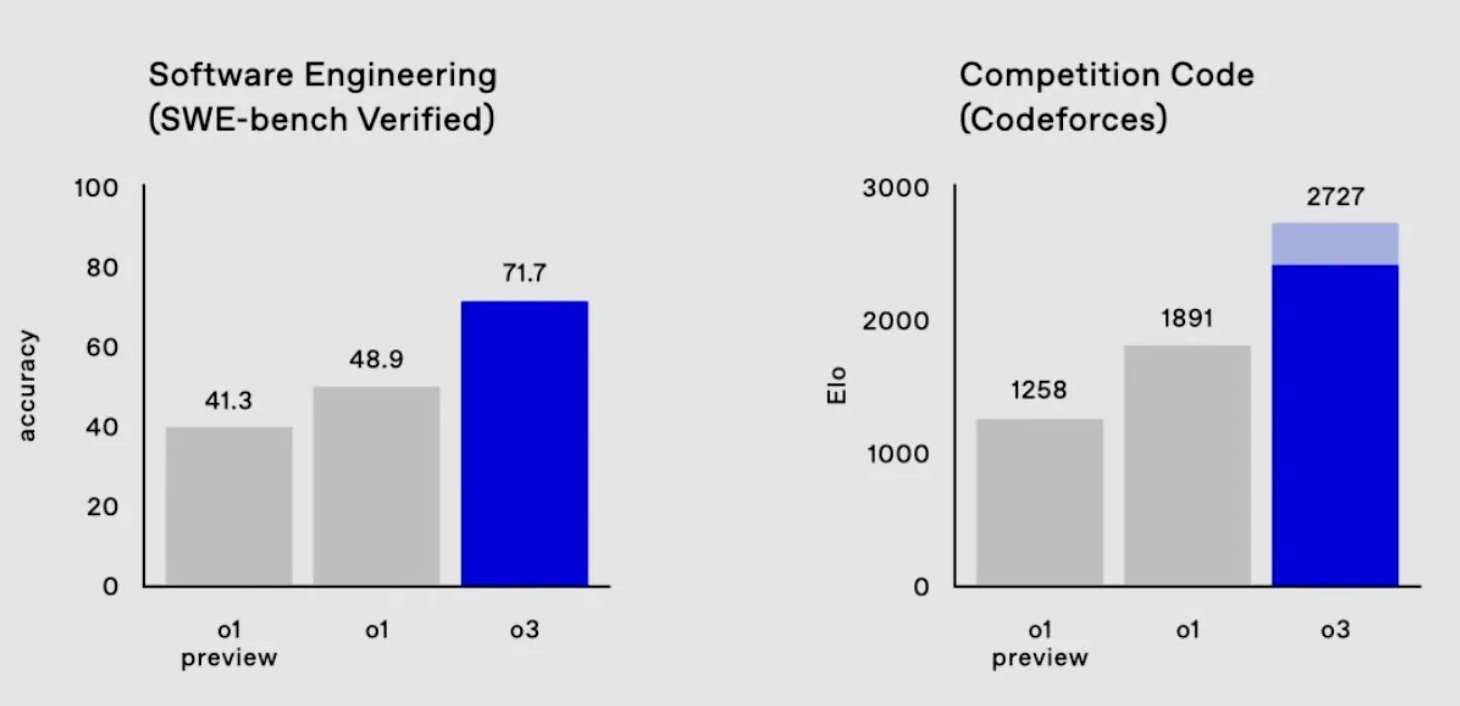
Новая модель также быстрее предшественника в написании кода (тест SWE-Bench Verified) на 22,8 % и даже превзошла ведущего учёного OpenAI в спортивном программировании.
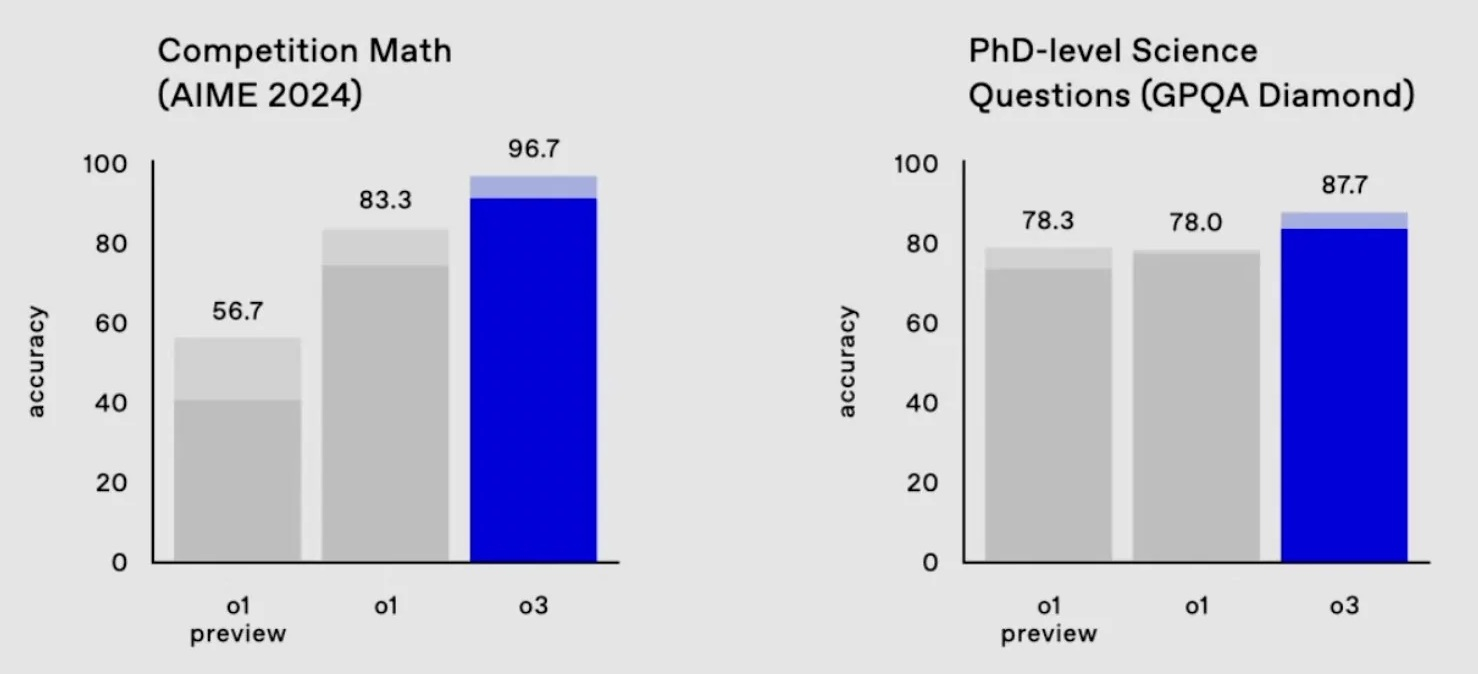
Модель o3 почти справилась с одним из самых сложных математических тестов, AIME 2024, пропустив в нём лишь один вопрос, а также набрала в бенчмарке GPQA Diamond 87,7 % — значительно больше, чем любой результат человека-эксперта.
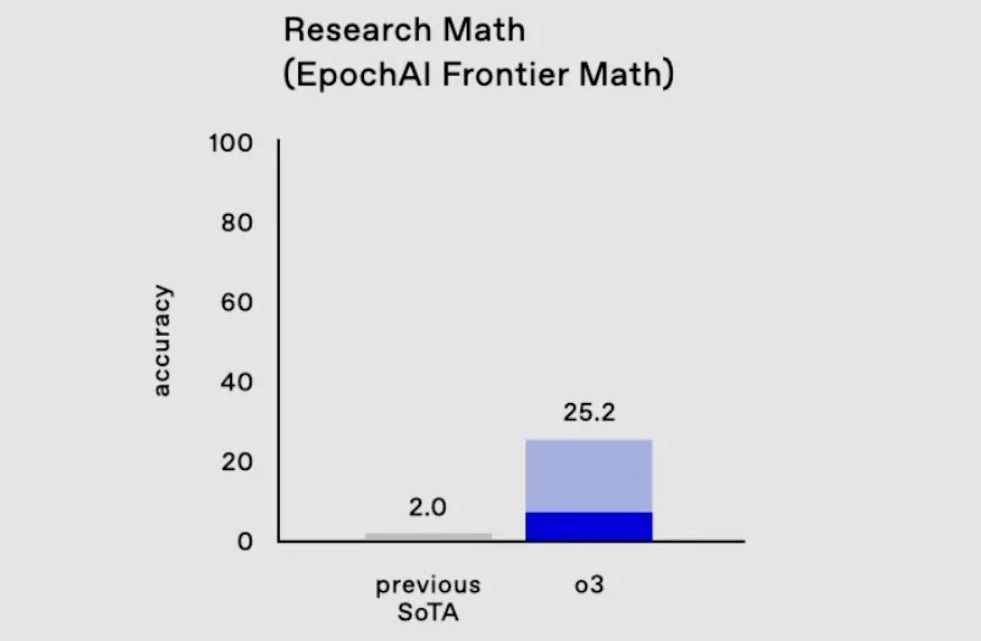
В самых сложных математических и логических тестах, которые обычно ставят в тупик любые другие ИИ, o3 решила 25,2 процента задач — результаты других моделей не превышают и двух процентов.
Весомым преимуществом o3, как и o1, является возможность моделей «рассуждать» и эффективно проверять свои же факты, чтобы избегать различного рода ошибок и галлюцинаций. Правда, разработчики из OpenAI заявили, что процесс проверки фактов перед выдачей ответа приводит к небольшой задержке — от нескольких секунд до нескольких минут (зависит от сложности вопроса). Кроме того, задержка связана с тем, что модель определяет, соответствует ли запрос пользователя политике безопасности OpenAI. Компания утверждает, что при тестировании нового алгоритма защиты на o1 она намного лучше следовала правилам безопасности, чем предыдущие модели, включая GPT-4.
И всё же, как отмечают журналисты TechCrunch, основным недостатком «рассуждающих» моделей является то, что для их работы требуется гораздо больше вычислительных мощностей, поэтому в итоге их использование обходится значительно дороже «обычных» решений.
Источники:





