







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Мастерская локальных ИИ: беседы с компьютером о прекрасном
Современные большие ИИ-модели — те, что базируются в облаке и доступны пользователям через веб-интерфейсы, смартфонные приложения либо API — по большей части мультимодальны (A2A, anything to anything — что включает и привычный для болтовни с ботами режим T2T, text to text, и преобразование словесной подсказки в изображение, T2I, text to image, и распознавание образов с детализированным их описанием — I2T, image to text, и многое иное). На входе они принимают и текстовые запросы, и картинки или даже видео, да и выдавать в ответ частенько способны тоже не один лишь текст — а и изображение, ролик, произнесённую синтезированным голосом фразу или мелодию. Возможно это благодаря крайне высокой мощности лежащих в основе таких моделей глубоких нейросетей, число параметров на входах искусственных нейронов в которых уже исчисляется триллионами (у GPT-4 их 1,76 трлн). Понятно, что для обеспечения сколько-нибудь адекватной скорости прохождения сигнала по таким нейросетям их цифровые образы необходимо целиком размещать в сверхбыстрой оперативной памяти — для чего той, в свою очередь, требуются сотни и тысячи Гбайт. Именно поэтому действительно интересные в плане живой коммуникации генеративные ИИ-модели невозможно запустить на домашнем ПК, — той же DeepSeek R1 в исходной (полнофункциональной) версии требуется по меньшей мере 1543 Гбайт видеопамяти. ![Пример плодотворного художественного сотрудничества оператора и локального ПК: слева — исходный натюрморт с сыром и мёдом из бесплатного фотобанка PXHere; в центре — его аналог, созданный моделью FLUX.1 [dev] по текстовой подсказке, сгенерированной другим ИИ-агентом, специализированным на распознавании образов, — Florence2; справа — результат ручного маскирования центрального объекта и дорисовки на его месте плюшевой пчёлки моделью FLUX.1 [fill]](https://cdn.3dnews.ru/assets/external/illustrations/2025/03/20/1120080/ailocal01-01.jpg)
Пример плодотворного художественного сотрудничества оператора и локального ПК: слева — исходный натюрморт с сыром и мёдом из бесплатного фотобанка PXHere; в центре — его аналог, созданный моделью FLUX.1 [dev] по текстовой подсказке, сгенерированной другим ИИ-агентом, специализированным на распознавании образов, — Florence2; справа — результат ручного маскирования центрального объекта и дорисовки на его месте плюшевой пчёлки моделью FLUX.1 [fill] Само собой, существуют «сжатые» (дистиллированные) варианты больших моделей, да ещё и особым образом «квантованные» (quantized; когда вместо 32- или 16-разрядных чисел с плавающей запятой весá на входах перцептронов представлены в более компактной форме, с 8 или 4 разрядами, — и даже это не предел), — так что какая-нибудь DeepSeek-R1-Distill-Qwen-7B с 7 млрд параметров будет занимать в видеопамяти уже 4,5 Гбайт, а DeepSeek-R1-Distill-Qwen-1.5B с полутора миллиардами параметров — и вовсе около 1 Гбайт. Корректно проведённая дистилляция моделей позволяет сохранить отличительные черты оригинала в заданной области: так, упомянутая DeepSeek-R1-Distill-Qwen-1.5B, которая представляет собой «сжатую» версию Qwen2.5-Math-1.5B (причём в процессе компактификации этой версии Qwen, исходно созданной разработчиками Alibaba Group, использовались ответы, сгенерированные DeepSeek R1, — именно поэтому в названии дистиллированного варианта присутствуют имена обеих исходных моделей), натренированной для решения математических и логических задач, в ряде соответствующих тестов превосходит полнофункциональные версии GPT-4o-0513 и Claude-3.5-Sonnet-1022. При этом «дистиллят» вполне может исполняться на локальном ПК, который соответствует, например, спецификациям Copilot+ PC — даже в отсутствие дискретной видеокарты. Но подлинной универсальности от таких компактифицированных и специализированных ИИ-агентов ожидать, конечно же, не приходится: упаси вас Тьюринг заводить с DeepSeek-R1-Distill-Qwen-1.5B беседы об отличных от математики материях! И всё-таки смысл запускать локально даже заведомо неуниверсальные ИИ-агенты есть — для решения разнообразных прикладных задач, которые по тем или иным причинам нерационально или же попросту неудобно выполнять в облаке. В рамках настоящей «Мастерской» мы рассмотрим одно из таких практических приложений малых генеративных моделей, а именно — посильную их помощь своим коллегам (тоже, по сути, малым языковым моделям с исходно узкой областью приложения — МЯМ), специализированным для создания картинок. Оказывается, привлекая к задаче преобразования художественного замысла в изображение не один ИИ, а два и более, но с различными специализациями, можно за сравнительно короткое время добиться более выдающихся результатов — чем если вручную в каком-нибудь графическом редакторе (особенно в отсутствие соответствующих навыков и опыта) доводить до кондиции не совсем устраивающее оператора изображение, сгенерированное всё той же FLUX.1. 
Процесс рассуждений и выдачу итогового ответа демонстрирует оптимизированная для исполнения на нейронном сопроцессоре (NPU в составе системы-на-кристалле; даже не дискретном GPU!) компактная ИИ-модель семейства Qwen 1.5B на Copilot+ PC с Windows Copilot Runtime (источник: Microsoft) ⇡#Под контролемВ серии «Практикумов по ИИ-рисованию», которую мы публиковали на протяжении почти двух лет, не раз упоминалась главная проблема машинной генерации изображений по текстовым подсказкам: чрезмерно высокая неопределённость получаемых результатов. Неопределённость буквально во всём: от качества картинки в целом (именно ради противодействия этой напасти подсказки для Stable Diffusion принято сопровождать непременными приговариваниями вроде «masterpiece, best quality, elaborate atmosphere») до её композиции и уровня исполнения отдельных деталей (смотрим на кисти человеческих рук в изображении оригинальной SD 1.5, без LoRA и текстовых инверсий, и плачем, — да и с ними в общем-то тоже, просто чуть реже). Да, сравнительно быстро сообществом энтузиастов ИИ-рисования были разработаны автоматизированные средства для генерации изображений по определённому шаблону — OpenPose для ControlNet, например: с их помощью можно взять работу живого художника или просто фотоснимок из реальной жизни — и сделать «примерно то же, но со вкусом ИИ». Однако воспроизводить напрямую либо с минимальными вариациями чужую картинку и не слишком интересно само по себе, и на практике требуется далеко не всегда. Куда чаще — скажем, для того, чтобы достойно проиллюстрировать очередной пост в соцсети либо публикацию в онлайновом издании, да даже попросту создать портрет собственного фэнтезийного персонажа для очередной настольной ролевой игры — нужно получить от машины изображение по мотивам некоего образца, а не более или менее рабскую его ИИ-копию. До появления модели FLUX.1 с её весьма развитым (благодаря опоре на «разъясняющую» ИИ-субмодель T5) «пониманием» естественной речи prompt engineering — то бишь составление такой текстовой подсказки, которая обеспечила бы генерирование изображения с высокой степенью соответствия задуманным оператором композиции и качеству — было едва ли не сродни чёрной магии. Требовалось особым (специфичным чуть ли не для каждого чекпойнта!) образом, часто совершенно по наитию, подбирать ключевые слова и располагать их в нужной последовательности. Инструменты семейства ConrolNet именно поэтому с таким восторгом и были приняты сообществом энтузиастов: они обеспечили куда более уверенный контроль над генерацией — хотя качество её самой и для SD 1.5, и для SDXL далеко не всегда соответствовало в итоге операторским ожиданиям. Приходилось после получения более-менее подходящей картинки либо неоднократно перерисовывать откровенно неудачные её участки с привлечением всё той же ИИ-модели (процедура inpainting), либо собственноручно править картинку в GIMP, Photoshop или ином графическом редакторе — если у оператора имелись соответствующие навыки, конечно. 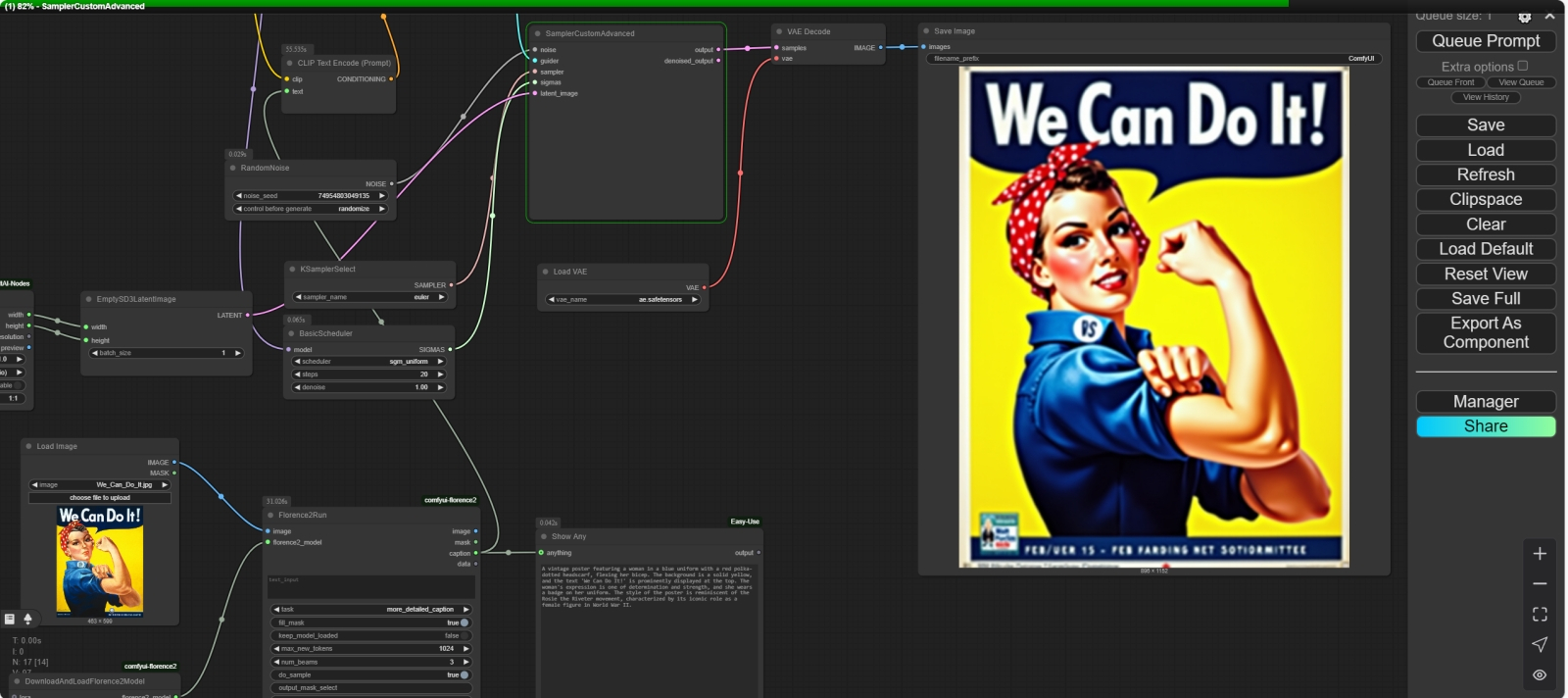
Комбинированную циклограмму, в которой последовательно работают ноды для автоматизированного текстового описания исходной картинки (слева внизу) и для преобразования полученной ИИ подсказки в изображение «по мотивам» оригинала (всё прочее), применять имеет смысл на быстрых ПК, — тогда не так обидно, если распознавание изображения в очередном конкретном случае выйдет не слишком удачным Теперь, когда FLUX.1 доступна уже более полугода и успела обзавестись изрядным вспомогательным инструментарием в виде различных моделей-дополнений LoRA, ситуация значительно проще. Некоторые разновидности ControlNet для FLUX.1 доступны тоже — правда, пока в менее широком ассортименте, чем для семейства Stable Diffusion, — однако если создавать новые картинки именно по мотивам имеющихся, можно обойтись и без них. Грубо говоря, поскольку новая модель разительно отличается от прежних повышенной дотошностью в плане следования подсказке, теперь от оператора требуется всего лишь детально и строго словами описать желаемую картинку (кстати, на этом этапе не так уж и важно, реальную или возникшую перед его мысленным взором) — и запустить FLUX.1 в свободный поиск (со случайным перебором затравки, seed) по этому описанию. Если сами слова подобраны корректно, желаемый результат не заставит себя долго ждать; взаимное же расположение этих слов (допуская, что они всё-таки формируют осмысленные фразы, а не просто перечислены через запятую) уже не столь важно, равно как и наличие добавочных, далеко не всегда очевидных модификаторов — вроде упоминавшихся уже «masterpiece, by Greg Rutkowsky, HDR, 8K UHD» и т. п.: вспомогательная нейросеть T5 разъяснит преобразователю текста в токены CLIP, как именно перекодировать полученное описание, чтобы получить соответствующий ему визуальный результат. Но вот вопрос: откуда взять детальное и строгое описание даже вполне реальной, а не воображаемой картинки — тем более, на английском; тем более, с пониманием, что далее этот текст будет использовать для создания нового изображения генеративная модель, т. е. какая-то специфика при подборе слов и построении фраз всё же должна присутствовать? Ответ напрашивается сам собой: логично будет перепоручить эту задачу другому ИИ, натренированному как раз на распознавание образов и на составление адекватных словесных портретов самых разнообразных объектов. Уж один-то современный ИИ другой («другого» тут не скажешь, — неодушевлённые они) точно поймёт; возможно даже лучше, чем среднего Homo sapiens. И, строго говоря, городить огород из узкопрофильных моделей на локальном ПК для этого вовсе не обязательно: онлайновые — облачные — инструменты для преобразования картинки в описывающий её текст имеются в изобилии, начиная со всем сегодня известных мультимодальных ChatGPT, Claude или DeepSeek и заканчивая более скромными, специализированными. Но вся прелесть как раз в том, что для формирования эффективной текстовой подсказки, которую входной контур FLUX.1 сумеет переработать в подходящий для генерации нужного изображения набор токенов, ИИ-боты с полумиллиардом и более рабочих параметров попросту не нужны, — равно как и доступ бесплатным онлайновым МЯМ (бесплатны они для досужего пользователя, а не для того, кто поддерживает их работу в облаке, — и потому имеют естественное ограничение на число запросов с одного IP-адреса за определённый период). Достаточно, к примеру, свободно распространяемых и пригодных для локального запуска моделей, созданных, чтобы решать задачи машинного зрения. В пример можно привести семейство Project Florence, разработанное в Microsoft. Скажем, вариант Florence-2, натренированный на 900 млн пар «изображение — текстовое описание», предлагает достаточно пространное контекстное окно и высокую производительность, чтобы и подробные длинные подсказки (которые так хорошо воспринимает FLUX.1) составлять, и даже на не самом мощном ПК отвечать на каждый запрос за время, исчисляемое максимум десятками секунд. 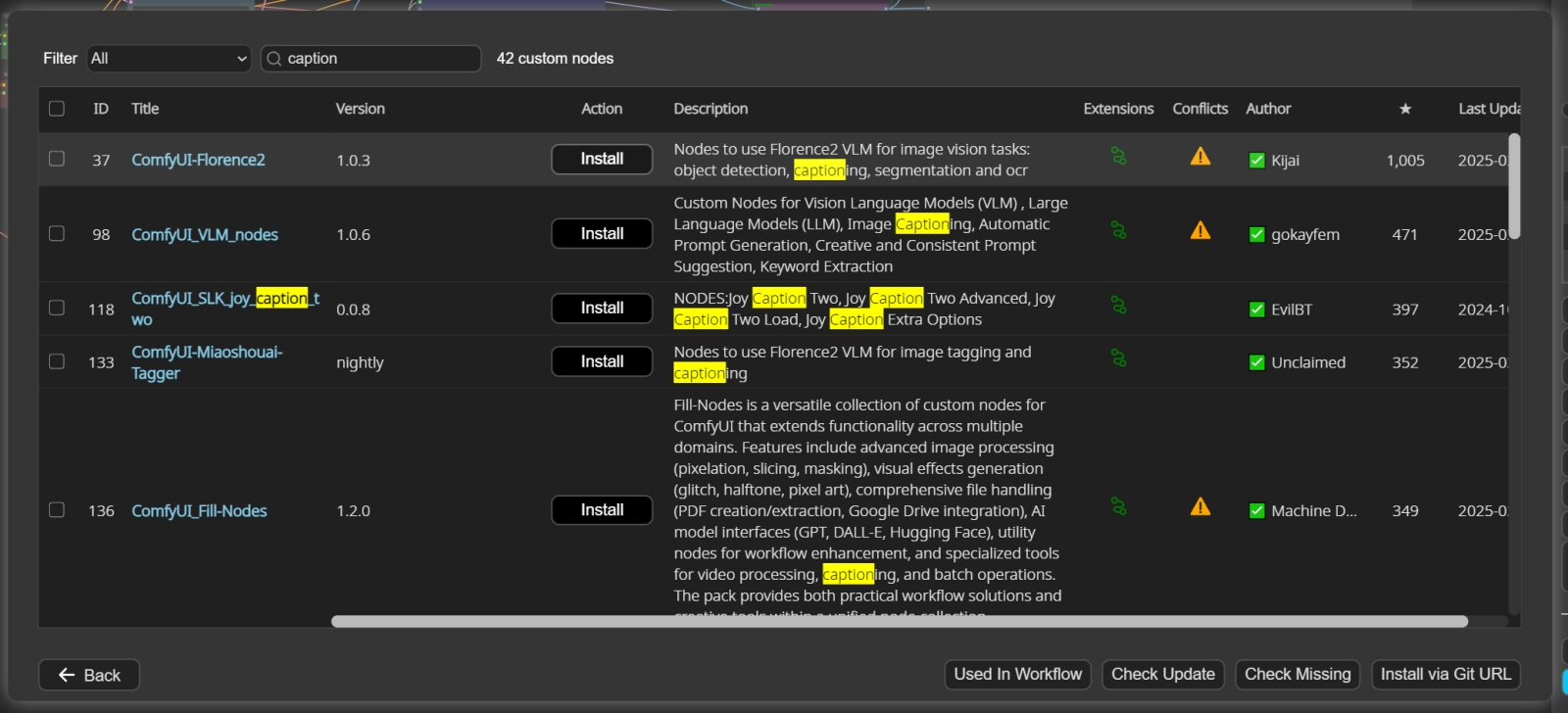
Поиск нужных расширений для ComfyUI по ключевым словам через Manager организован весьма удобно ⇡#Что вы видите на этой картинке?Знакомая уже читателям наших «Мастерских» рабочая среда ComfyUI предлагает все необходимые средства для интеграции таких вот локальных распознавателей картинок (облачных, кстати, тоже, через API с вводом идентификационного ключа, — но там есть своя специфика, и в настоящем материале мы их рассматривать не станем). В подробностях о том, как развёртывать и настраивать эту рабочую среду на локальном ПК под управлением Windows с дискретным графическим адаптером Nvidia именно для работы с моделями семейства FLUX.1, говорилось в 11-м и 12-м выпусках «Практикума по ИИ-рисованию». Подчеркнём только, что для обращения к Florence-2 нам потребуется актуализированная рабочая версия ComfyUI с активным расширением Manager. Интересующий нас в данном случае инструмент — нода «Florence2Run», возможность добавить которую в рабочую циклограмму появляется после установки соответствующего расширения. Сделать это в функциональной инсталляции ComfyUI тривиально, — достаточно из главного меню вызвать Manager, нажать на кнопку «Custom Nodes Manager» в его интерфейсе, а затем в строке поиска в открывшемся окне с перечнем доступных расширений начать вводить слово «caption» («описание»). Средств для преобразования картинки в текст энтузиасты применяемой нами рабочей среды предложили уже немало, но как раз расширение ComfyUI-Florence2 за авторством kijai — одно из наиболее популярных и, пожалуй, самое простое в применении. Ещё одно важное напоминание: после установки нового расширения (кнопка «Install» в соответствующей ему строке списка) система предложит перезагрузить сервер рабочей среды. Прежде чем это делать, имеет смысл вернуться в меню Manager и нажать там кнопку «Update all» — чтобы и сама ComfyUI, и все прочие ранее проинсталлированные расширения обновились до наиболее актуальных версий. Поскольку сейчас рабочая среда крайне активно развивается (из-за резкого всплеска интереса энтузиастов к локальному исполнению сразу нескольких появившихся почти одновременно очень неплохих моделей с открытыми весами для преобразования текста и картинок в видеоролики), обновления появляются заметно чаще, чем в конце 2024 года, скажем. 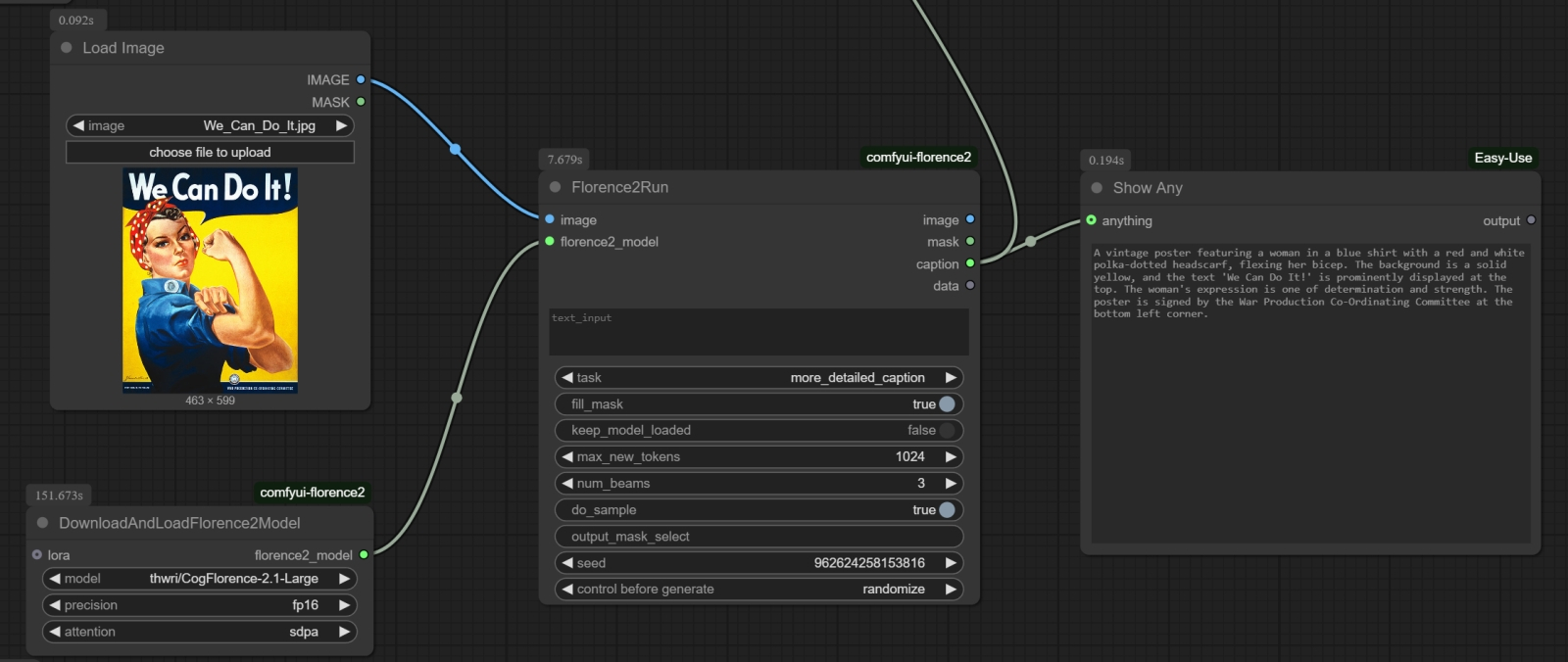
Фрагмент циклограммы, что порождает текстовое описание исходной картинки с использованием ноды «Florence2Run», а затем визуализирует этот текст для оператора посредством ноды «Show Any» По завершении перезагрузки — и сервера ComfyUI, и её веб-интерфейса — открываем новое окно для создания циклограммы, дважды щёлкаем мышью в пустом поле и в поисковой строке появившегося меню выбора нод начинаем вводить «Florence2Run». Выбираем нужную — и вот оно, главное окошко инструмента для распознавания картинок, т. е. для преобразования изображения (и, опционально, уточняющей процесс подсказки, — если ноду использовать в режиме маскирования) в текст (или в некое служебное изображение, туже самую маску). Теперь нужно дополнить ключевую ноду средством вызова модели: для этого от входа «florence2_model» на левой её стороне потянем мышкой связующую линию — и просто отпустим её где-то в пустом пространстве рабочего поля. Появится меню с вариантами нод, подходящих для организации такой связи; выберем среди них ту, что называется «DownloadAndLoadFlorence2Model». В названии этом нет тавтологии: после выбора в выпадающем меню уже этой ноды конкретной модели — например, Florence-2.1-Large — не нужно совершать никаких дополнительных действий вроде ручной загрузки соответствующего файла с размещением его в определённом каталоге. После того, как циклограмма будет достроена и впервые запущена на исполнение, система сама определит, что нужная модель отсутствует — и автоматически подтянет её из онлайн-репозитория в созданную ею же самой подпапку «LLM» папки «models» в корневом каталоге ComfyUI («download»), а затем и загрузит в видеопамять для исполнения («load»). А чтобы достроить циклограмму до полностью работоспособного состояния, не так уж много и остаётся: достаточно от входа «image» на левой стороне ноды «Florence2Run» протянуть мышкой новую связь, точно так же отпустить кнопку, и в открывшемся меню выбрать «Load Image». Результатом работы ИИ-распознавателя образов для начала пусть будет текст с описанием предложенной картинки: чтобы этот текст увидеть, воспользуемся нодой «ShowAny» из пакета расширений ComfyUI-Easy-Use (который уже наверняка установлен у тех, кто занимался с нами быстрым прототипированием с моделью FLUX.1, а если нет — то проинсталлировать и его через Manager несложно). Поскольку мы подведём к «ShowAny» соединение от выхода «caption» на правой стороне ноды «Florence2Run», отображаться там будет как раз текстовое описание. В самой же этой ноде из выпадающего меню «task» нужно выбрать задачу «more_detailed_caption», — результатом её исполнения как раз и будет достаточно пространное и подробное описание картинки на естественном языке, пригодное для передачи — в виде текстовой подсказки — на вход генеративной модели FLUX.1. 
Первое исполнение циклограммы с нодами «Florence2Run» и «DownloadAndLoadFlorence2Model» может занять несколько минут, — всё зависит от ширины Интернет-канала, которым располагает оператор ⇡#И мы сможем!Этим пока что и ограничимся: сохранением полученного результата мы здесь не озаботились, но на данном этапе оно и не нужно. В качестве картинки для распознавания возьмём для примера классический американский плакат времён Второй мировой с «Клепальщицей Роузи», Rosie the Riveter, — «We Can Do It», — и просто из «Проводника» Windows мышкой переместим выкачанное из Интернета его изображение на приёмное поле ноды «Load Image» (либо воспользуемся кнопкой «choose file to upload» непосредственно над ним). Всё; помимо этих четырёх нод, ничего пока больше не требуется, — нажимаем в главном меню ComfyUI «Queue Prompt» и запасаемся терпением. Модель Florence-2.1-Large занимает около 1,7 Гбайт, так что пока она загружается (полностью автоматически, напомним), придётся подождать, — зато потом на нашем тестовом ПК с древней видеокартой GeForce GTX 1070 с 8 Гбайт видеопамяти и с 24 Гбайт ОЗУ DDR3 распознавание образа займёт не более 22-25 с. Результатом же распознавания станет появившийся в окошке ноды текст, — такой, например: «A vintage poster featuring a woman in a blue uniform with a red polka-dotted headscarf, flexing her bicep. The background is a solid yellow, and the text 'We Can Do It!' is prominently displayed at the top. The woman's expression is one of determination and strength, and she wears a badge on her uniform. The style of the poster is reminiscent of the Rosie the Riveter movement, characterized by its iconic role as a female figure in World War II». Собственно, в первом приближении — всё: этот текст можно далее использовать как подсказку для генерации с моделью FLUX.1: скопировать и перенести в соседнее окно браузера, где открыта соответствующая циклограмма. Блок с нодой «Florence2Run» вполне допустимо интегрировать в процесс генерации,чтобы избавить себя от лишних движений «Ctrl+C»/«Ctrl+V», но дело в том, что порождающая описание картинки модель — тоже генеративная: её выдача всякий раз будет немного иной. И потому имеет смысл — учитывая, вдобавок, что исполняется эта мини-циклограмма очень быстро, — прогнать её несколько раз, копируя полученные результаты хотя бы в «Блокнот», чтобы потом составить из них более полное исчерпывающее описание. Впрочем, в данном случае — а мы проверили с десяток случайных затравок — изображения всякий раз выходят весьма и весьма схожими, вплоть до типографики и оформления текста, хотя параметры его подсказкой явно не задаются. Надо полагать, этот знаковый плакат входил в обучающий сет и для моделей семейства Florence, и для FLUX.1 — так что одна другую «понимает» даже по столь краткому описанию, что называется, с полуслова. ![Слева — изображение, сгенерированное FLUX.1 [dev] по порождённому Florence2 описанию плаката с «Клепальщицей Роузи» без каких бы то ни было дополнений; в центре — все параметры те же, включая затравку (seed), но добавлена LoRA Illustration V2 с силой воздействия 1,0; справа — то же самое, но с силой 0,5](https://cdn.3dnews.ru/assets/external/illustrations/2025/03/20/1120080/ailocal01-07.jpg)
Слева — изображение, сгенерированное FLUX.1 [dev] по порождённому Florence2 описанию плаката с «Клепальщицей Роузи» без каких бы то ни было дополнений; в центре — все параметры те же, включая затравку (seed), но добавлена LoRA Illustration V2 с силой воздействия 1,0; справа — то же самое, но с силой 0,5 Проверим это, слегка поменяв рабочие параметры генерирующей картинку модели — весá на входах её перцептронов — путём применения к ней LoRA. Поскольку плакат представляет собой рисунок, хотя и вполне реалистичный, воспользуемся вариантом Illustration V2, доступным на портале Civitai: вообще говоря, мини-моделей для акцентирования именно такого художественного стиля там предостаточно, и именно эта выбрана нами практически случайно. Циклограмму для генерации возьмём примерно ту же, что в прошлой «Мастерской», где использованы ноды «Unet Loader (GGUF)» для квантованной Q8.0-модели FLUX.1 [dev] и «Power Lora Loader (rgthree)» для загрузки, собственно, моделей LoRA. Параметры генерации установим такие: соотношение сторон холста — 3:4, величина изображения — 0,5 Мпикс, sampler — dpmpp_2m, scheduler — sgm_uniform, steps — 20, и с затравкой 574671788216636, выбрав «силу воздействия» (параметр «Strength») LoRA равной 1,00, получим уже как раз подобную исходной картинку, а не практически точную её копию. Это по-прежнему узнаваемый плакат с той же характерной надписью, но типографика её иная, и Роузи развёрнута в другую сторону, да и в целом стилистика картинки ближе к американскому же жанру pin-up, а не к агитационному рисунку. А вот если уменьшить силу воздействия мини-модели Illustration V2 до 0,5, получится интересный компромисс — изображение в целом станет привлекательнее, чем вовсе без LoRA (и это объяснимо; семейство FLUX.1 вообще лучше справляется с отображением фотореалистичных картинок, чем рисунков), особенно в части кистей рук и складок на ткани блузы, но и верности оригиналу станет больше. ⇡#Ближе к реальностиТеперь отвлечёмся от знакового плаката, который по причине своего бесспорного присутствия в тренировочных базах данных априори «близко знаком» всем имеющим дело с визуальными образами генеративным моделям, и посмотрим, насколько хороша Florence2 в описании изображений, для которых у FLUX.1 нет однозначного референса. Для этого с сайта PXHere, предлагающего бесплатные иллюстрации с открытыми правами для коммерческого и некоммерческого использования, загрузим изображение девушки в тренажёрном зале — и посмотрим, насколько точно удастся нашим работающим в паре ИИ его воспроизвести. Предварительно слегка модифицируем циклограмму с нодой «Florence2Run»: чтобы сохранять одновременно и аннотируемое изображение, и сгенерированное его описание, воспользуемся ещё одним расширением для ComfyUI с говорящими само за себя названием, — Save image with generation metadata. Устанавливается оно опять-таки через Manager, где отыскивается по названию (автор — giriss, на всякий случай). Нода «Save Image w/Metadata» из состава этого расширения включает исходно поля для ручного ввода позитивной и негативной частей подсказки. Следует преобразовать одно из этих окошек во входной «разъём» для получения данных — щёлкнув по самой ноде правой кнопкой мыши и выбрав в меню «Convert widget to input» — «Convert positive to input», после чего подсоединить к появившемуся с левой стороны входу «positive» выход «output» ноды «Show Any», в которой появляется сгенерированное моделью Florence2 описание предложенной её картинки. 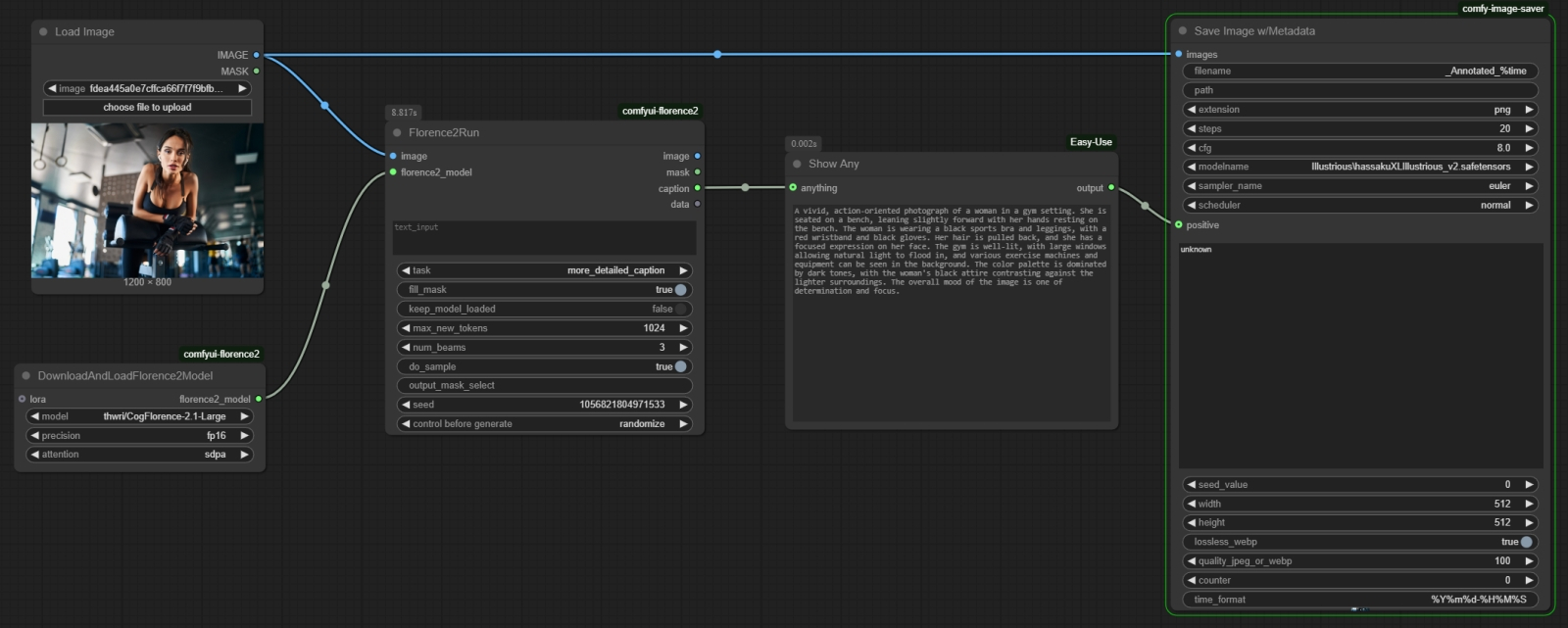
Дополнив уже знакомые нам четыре ноды ещё одной, «Save Image w/Metadata», получим возможность сохранять исходную картинку вместе с текстовым её описанием в едином PNG-файле, причём увидеть текстовый блок в самом начале этого файла удастся даже без запуска рабочей среды ComfyUI, — достаточно открыть его в любом просмотрщике содержимого (hex viewer/editor); вроде того, что в файловом менеджере FAR штатно вызывается по нажатию на «F3» Ко входу же «images» ноды «Save Image w/Metadata» нужно подключить выход «IMAGE» от «Load Image», — таким образом в выходном файле (префикс наименования которого задаётся в окошке «filename») будут сохранены и описываемое изображение, и предложенное для него ИИ описание. Вот что у нас получилось с первого раза: «A vivid, action-oriented photograph of a woman in a gym setting. She is seated on a bench, leaning forward with her hands resting on her knees. The woman is wearing a black sports bra and black leggings, accessorized with black gloves and a red wristband. Her hair is pulled back, and she has a focused expression on her face. The gym is well-lit, with natural light streaming in through large windows, and various exercise machines and equipment can be seen in the background. The color palette is dominated by dark tones, with the woman's skin and clothing contrasting against the lighter surroundings. The overall mood of the image is one of determination and focus». Как нетрудно заметить, действительности это описание соответствует далеко не полностью — руки девушки на исходном фото вовсе не покоятся на её коленях, — однако в целом представление о картинке создаёт. И действительно, генерация FLUX.1 [dev] с такой подсказкой и прежней затравкой порождает вполне адекватную описанию картинку — с которой далее уже можно работать. Напомним снова, что если нам по какой-то причине требуется по-настоящему точное, хотя и с вариациями, воспроизведение изначальной композиции, оптимальный для этого инструмент — ControlNet. Здесь же дополнительная ИИ-модель служит для порождения лишь в целом схожего с оригиналом цифрового образа, что с творческой точки зрения куда как продуктивнее. На что ещё способна нода «Florence2Run»? Поскольку генеративная модель, на которую она опирается, разрабатывалась для распознавания образов, с этой задачей локально запускаемая МЯМ тоже справляется неплохо. В меню «task» рассматриваемой ноды есть режимы «region_caption» и «dence_region_caption»: первая — для распознавания хорошо разнесённых в пространстве объектов, вторая — для плотно сгруппированных. Если к выходу «image» на правой стороне «Florence2Run» прикрепить стандартную ноду «Preview image», то после отработки одной из двух указанных опций в ней появится оригинальная картинка с наложенными на неё прямоугольниками, что ограничивают занимаемые распознанными объектами области. 
Слева — исходное фото девушки в спортзале из бесплатного фотобанка PXHere; справа — FLUX.1-визуализация (безо всяких LoRA) первой же попытки описать его с применением Florence2 Кроме того, «Florence2Run» способна распознавать на картинках тексты в режиме «ocr», создавать маски для указанных в текстовом поле объектов в режиме «referring_expression_segmentation» и проч. Но те же самые задачи несложно выполнять и в ручном режиме: онлайновые OCR-инструменты широко и бесплатно доступны (взять хотя бы интегрированный в поисковик «Яндекса», допускающий просто перетаскивание мышкой картинки со сканом документа из «Проводника» в окно браузера), а маскировать нечто на сгенерированной картинке для его ИИ-перерисовывания проще всё-таки непосредственно оператору. Дело в том, что очень редко объект на порождённом генеративной моделью изображении требуется преобразовать строго внутри его исходных границ: к примеру, поменять лежащее на столе яблоко на точно такой же круглый апельсин. В этом случае, действительно, можно задать в текстовом поле ноды «Florence2Run» слово «apple», и на выходе «mask» получится изображение, собственно, маски, — белый «след» выделенного ИИ-яблока на чёрном фоне. Используя затем эту маску на том же самом исходном изображении и запустив генерацию со словом «orange», а ещё лучше «orange \(fruit\)» (обратные косые черты в данном случае показывают системе, что скобки надо воспринимать не как значимую часть подсказки — в синтаксисе «(orange:1.2)», — а как указание на уточняющий характер заключённого в них слова), получим прежнюю картинку, только с апельсином вместо яблока. Вот только сработает этот метод как следует исключительно для не слишком реалистичных изображений. Реальное яблоко, к примеру, неизбежно будет создавать рефлексы на окружающих его объектах: пусть слабые, но достойная генеративная модель вроде FLUX.1, обученная на огромном массиве фотоснимков, «представление» о них имеет, — так что лежащий на белой скатерти апельсин, что отбрасывает на эту скатерть чуть зеленоватый отсвет (потому что прежде там лежало яблоко), будет смотреться ненатуралистично. По этой причине работа с масками предполагает обычно удаление с картинки не только подлежащего замене объекта, но и его ближайшего окружения — с тем, чтобы затем генеративная модель дорисовала на его место что-то иное наиболее естественным образом, на который способна. Укрупнённая маска позволяет также перерисовывать объект с изменением формы и размера: скажем, «переодеть» нарисованную девушку из юбки в брюки сгенерированная по подсказке «skirt» ИИ-маска не позволит — не все нужные области окажутся ею захвачены; а вот созданная вручную — вполне. 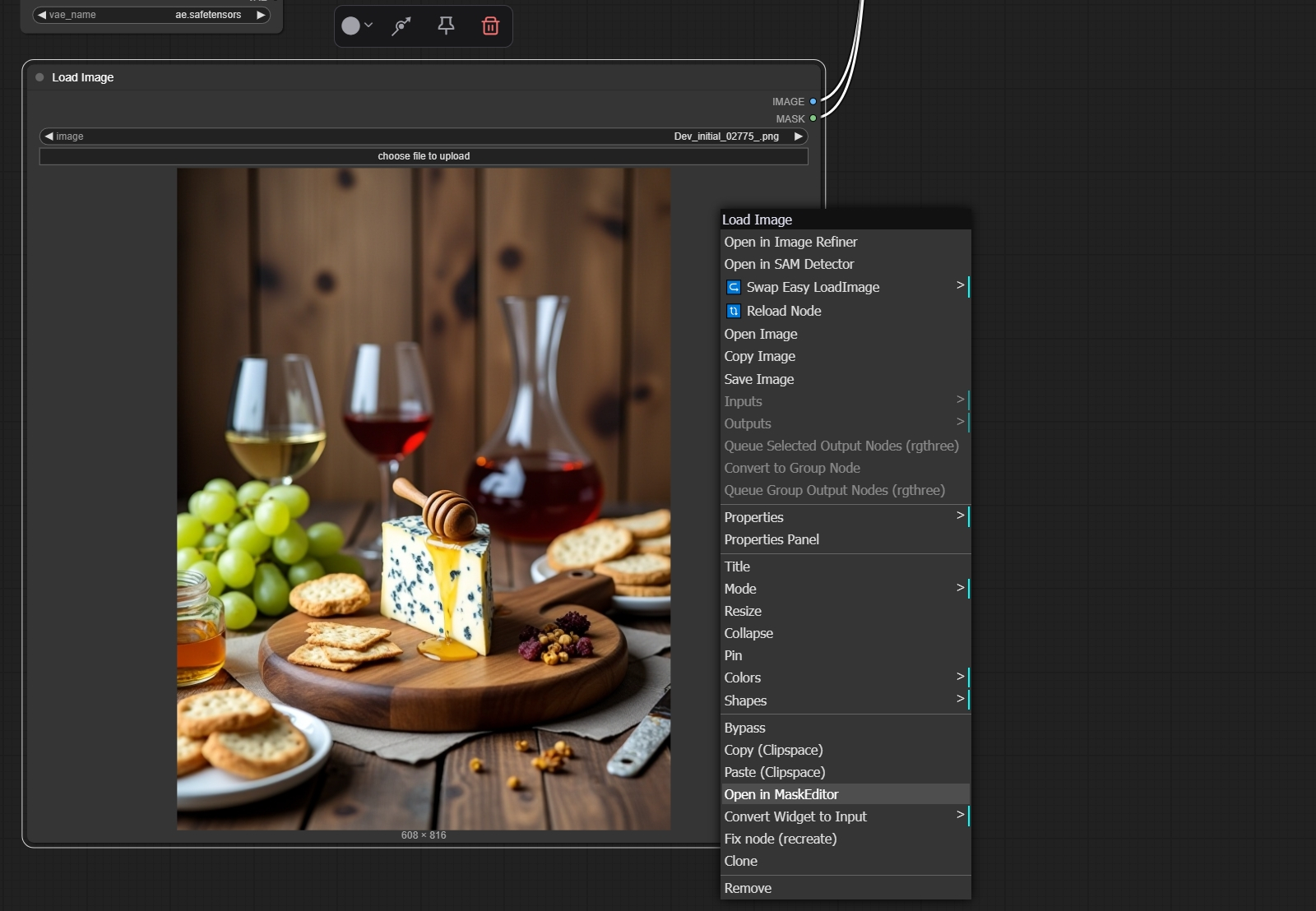
Непритязательная базовая нода «Load Image» в актуальной версии ComfyUI предлагает интегрированную функциональность создания масок, — доступ к соответствующему редактору открывается через меню правой кнопки мыши ⇡#Ручное управлениеПродемонстрируем на примере, как это делается в случае FLUX.1 — тем более, что для интеллектуальной пере- и дорисовки (функциональность inpainting и outpainting соответственно) сама же компания Black Forest Labs уже предложила специализированную модель FLUX.1-Fill-dev. Модель эта занимает, правда, в исходном виде почти 24 Гбайт, — но для неё энтузиастами созданы GGUF-квантованные версии; в частности, flux1-dev-Q8_0.gguf; более щадящего размера (около 13 Гбайт) и практически не отличимая от оригинала по качеству создаваемых изображений. Скачанный по приведённой чуть выше ссылке файл нужно поместить в каталог models/unet в структуре рабочей директории ComfyUI, в компанию к прочим GGUF-моделям, а дальше вместо нашей стандартной циклограммы для FLUX.1 [dev] использовать файл flux-fill-inpaint-example.json из официального руководства по реализации ИИ-перерисовки в среде ComfyUI. Ничего архисложного там нет; более того, вместо привычной ключевой ноды «SamplerCustomAdvanced» для собственно генерации применяется памятная по моделям Stable Diffusion классическая нода «KSampler», у которой имеются раздельные входы для позитивной и негативной частей подсказки, — на негативную в случае FLUX.1, разумеется, придётся завести пустую строку. Важно также отметить непривычную комбинацию параметров: для «перерисовочной» версии этой модели предлагают выставлять параметр guidance в 30.0 (вместо стандартных для Flux.1 [dev] 3,5), sampler — «euler», scheduler — «normal», steps — в значение 20, а «cfg» в ноде «KSampler» — в 1,0. Собственно маскирование производится посредством встроенного в скромную на вид ноду «Load Image» инструментария. После загрузки в неё подвергаемого перерисовке изображения нужно щёлкнуть на ней правой кнопкой мыши и в появившемся меню выбрать опцию «Open in MaskEditor». Картинка откроется в лаконичном, но эффективном редакторе масок, где следует, подобрав нужный размер кисти, замазать ею намеченный к перерисовке объект (плюс его ближайшее окружение), а затем нажать на «Save». В результате на исходной картинке появится серое пятно, — в нём и будет происходить новая генерация. А вот чего именно, определит текстовое поле позитивной части подсказки: там нужно кратко и ёмко описать, что именно оператор желает видеть на месте только что появившегося пятна. Используемая для до- и перерисовки fill-модель FLUX.1 натренирована так, чтобы перенимать стилистику и композицию изменяемого изображения от не закрытой маской его части, и потому то, что появляется в результате вместо изначально удалённого объекта, чаще всего гармонично и естественно вписывается в итоговую картинку. Кстати, все примеры, которые мы здесь приводили, традицилонно доступны для закачке в виде архива с PNG-картинками, содержащими нужные циклограммы, по этой вот ссылке. ![Фрагмент опорной циклограммы flux-fill-inpaint-example.json, на котором заметны нетипичные для модели FLUX.1 [dev]/[schnell], но вполне оправданные в случае FLUX.1 [fill] ноды и параметры](https://cdn.3dnews.ru/assets/external/illustrations/2025/03/20/1120080/ailocal01-11.jpg)
Фрагмент опорной циклограммы flux-fill-inpaint-example.json, на котором заметны нетипичные для модели FLUX.1 [dev]/[schnell], но вполне оправданные в случае FLUX.1 [fill] ноды и параметры Так что же выходит, локально исполняемые МЯМ в случае генерации картинок имеют весьма ограниченное применение — для описания сторонних изображений, сегментации, детектирования объектов и, кажется, всё? Пожалуй, так и есть, — уж слишком несопоставимы мощности (выраженные в числе активных параметров многослойной нейросети) генеративных моделей, пригодных для запуска на игровом ПК — и на гиперскейлерском облачном сервере. И всё-таки энтузиасты продолжают развивать локальные T2T-боты, причём особенно активно с появлением дистиллированных моделей-агентов, специализированных на решении достаточно узких задач. Каких и для чего именно — постараемся выяснить в следующих выпусках нашей «Мастерской»! ⇡#Материалы по теме
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





