







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Почему современные полупроводники недостаточно хороши для ИИ?
Чем миниатюрнее производственные нормы, по которым выполняется микросхема, тем выше для неё плотность операций — количество вычислительных/логических действий, которые способна выполнить единица её площади (условный квадратный миллиметр). Собственно, для связанных с генеративными моделями искусственного интеллекта расчётов только того и надо: миниатюризируем техпроцесс, не считаясь с затратами, получаем повышенную производительность чипа, запускаем на нём очередную модель… и вдруг обнаруживаем, что скорость выполнения стандартных операций после очередного цикла смены производственных норм выросла хорошо если на 10-15%, тогда как объём рабочих параметров ИИ-модели увеличился более чем на десятичный порядок. Несоответствие налицо — надо с этим что-то делать. 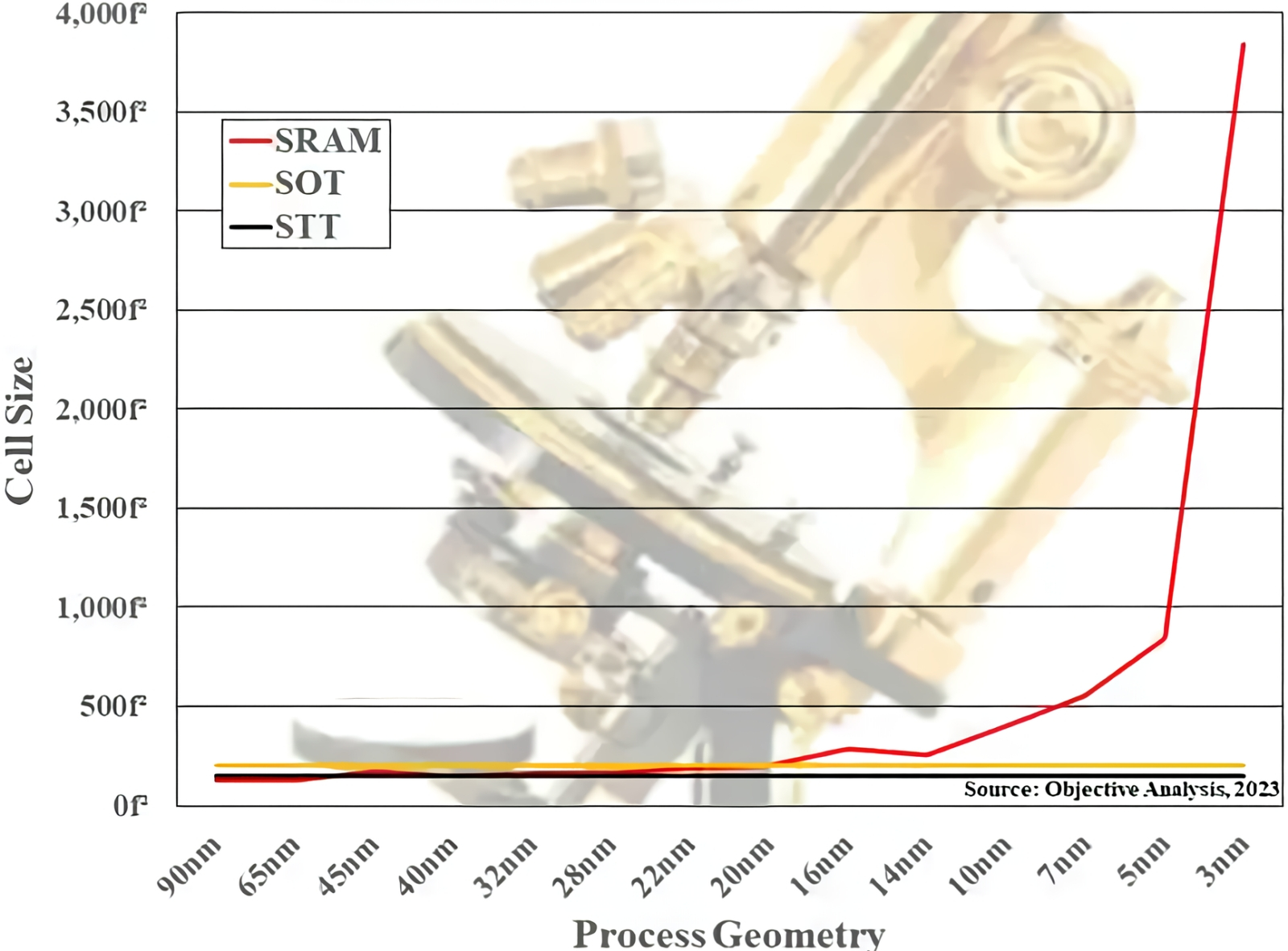
Зависимость характерной площади одиночной ячейки памяти в условных единицах f2 от размерности применяемого для её изготовления техпроцесса. Помимо SRAM, приведены данные для двух разновидностей магниторезистивной памяти: уже выпускаемой ныне STT-MRAM (spin-transfer torque MRAM, на основе эффекта переноса спинового момента) и перспективной SOT-MRAM (spin-orbit torque MRAM, на базе спин-орбитального вращательного момента) (источник: Objective Analysis) ⇡#Догонялки с памятьюНачнём с того, что сокращать геометрические размеры полупроводниковых ячеек памяти значительно сложнее, чем составленных из транзисторов логических схем, — мы об этом уже подробно рассказывали. Современные же микропроцессоры для ускорения своей работы в значительной мере полагаются на многоуровневые кеши данных, причём такие портативные хранилища наиболее часто востребованной информации в виде ячеек SRAM располагаются как можно ближе к логическим контурам; в идеале — прямо на одной с ними кремниевой подложке. В результате вместе с этими самыми контурами в ходе очередного цикла миниатюризации производственных норм уменьшаются и габариты ячеек памяти. Казалось бы, никаких проблем тут возникать не должно, поскольку память SRAM, в отличие от DRAM, не содержит конденсаторов, чьи физические размеры уменьшать неизмеримо сложнее, чем длину, ширину и даже толщину полупроводниковых элементов транзисторов, — мы уже как-то об этом писали. Но если бы в микроэлектронике всё было так просто! Напомним, что классическую элементарную ячейку динамической памяти с произвольным доступом — dynamic random access memory, DRAM — образует пара из конденсатора и транзистора (структурная схема one-transistor, one-capacitor — 1T1C), из-за чего она достаточно быстро способна как забирать, так и отдавать электрический заряд. В основе же статической памяти с произвольным доступом — static random access memory, SRAM — лежит транзисторная схема с положительной обратной связью. Благодаря тому, что заряд постоянно перемещается по контуру, состоящему из перекрёстно соединённых инверторов и двух ключевых транзисторов, скорости записи и считывания оказываются ещё выше, чем у DRAM. Правда, достигается это немалой ценой: типичная на сегодня ячейка SRAM — шеститранзисторная (структурная схема 6T), т. е. довольно-таки крупная; кроме того, прекращение подачи питания здесь тоже ведёт к мгновенной потере сохранявшегося в ячейке бита данных. 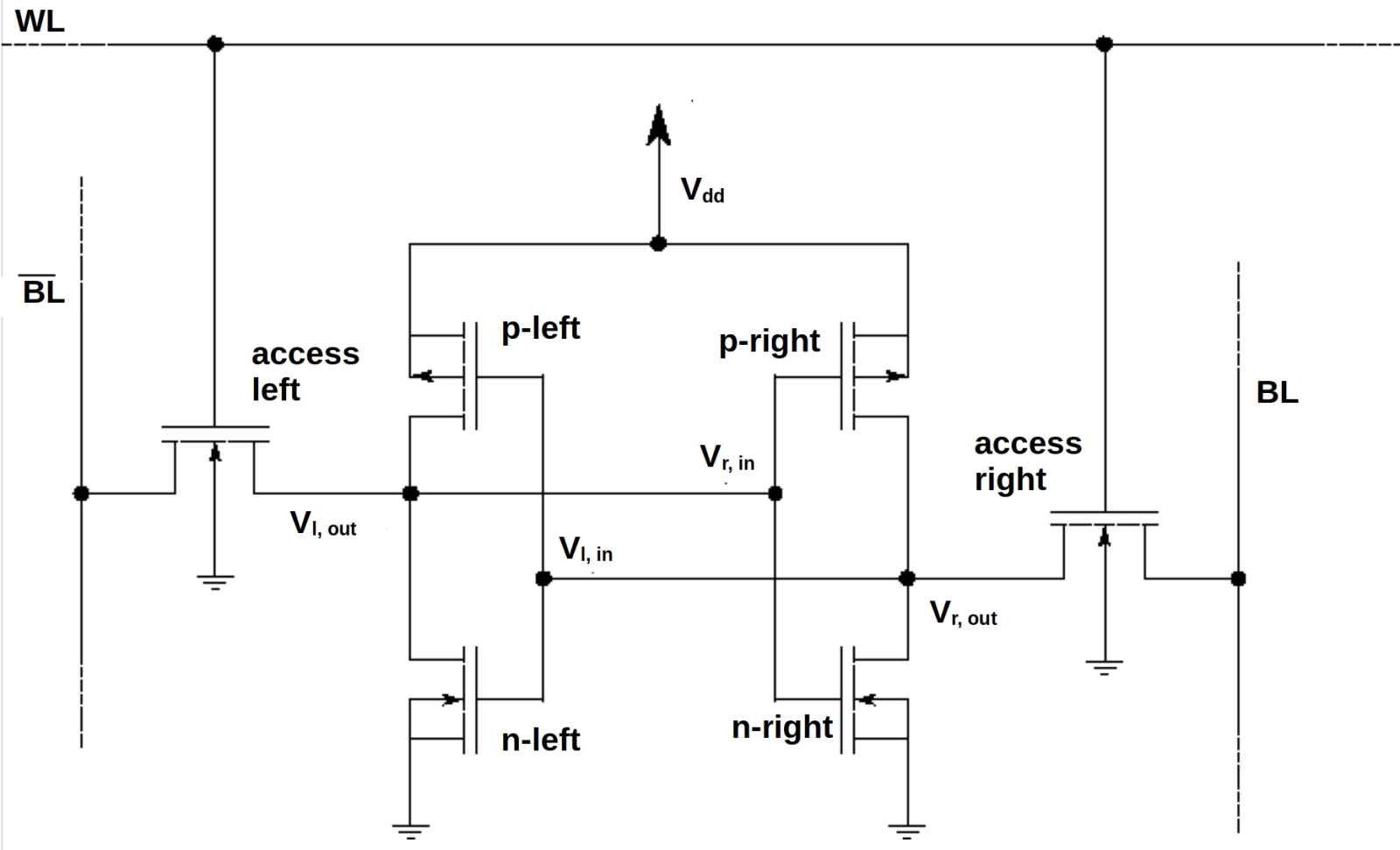
Схема типовой шеститранзисторной ячейки SRAM: битовые шины (BL и BL с чёрточкой) используют для записи и считывания данных; шина WL управляет транзисторами контроля доступа (access). Два образованных парами параллельно включённых КМОП-транзисторов инвертора образуют логическую схему «2ИЛИ», которая перенаправляет выходной потенциал Vout одной из этих пар на вход другой, Vin, и наоборот; таким образом, бит данных безостановочно «бегает по кругу» (точнее, по восьмёрке) внутри этой схемы — пока есть питание (источник: Wikimedia Commons) Можно сказать, что носителем информации в DRAM выступает заряд (точнее, его запасённая в конденсаторе конкретная величина, — помним о наиболее широко распространённых сегодня многоуровневых ячейках динамической памяти), а в SRAM — уровень циркулирующего по шестиячеечной схеме напряжения. Собственно, поскольку конкретное значение напряжения определяется параметрами подаваемого на схему тока, и пока этот ток идёт, напряжение неизменно, — почему такую память и называют статической. В случае же динамической памяти — DRAM — утекающий по естественным причинам заряд из ее конденсаторов требуется время от времени (именно в этом и заключается динамика) пополнять. Типичные времена доступа к ячейке SRAM не превышают 10 нс, к DRAM — составляют 60 нс и более. Неудивительно, что как раз от объёма SRAM, расположенной в непосредственной близости от вычислительных ядер серверных графических адаптеров (строго говоря, у самых логических контуров имеется ещё и регистровая память, но в ней хранят, если брать ЦП, и вовсе считанные десятки, максимум сотни байтов, а в случае ГП — сотни кбайт), производительность последних при решении ИИ-задач зависит едва ли не в большей степени, чем от количества видеопамяти, коммуникации ядер с которой происходят по заметно более узкой шине и отличаются большей латентностью. Так, обнародовав спецификации ускорителя H100, официальный сайт Nvidia с гордостью констатировал, что суммарный объём общей для всех его ядер локальной памяти и кеша L1 достиг в данном случае целых 256 Кбайт — что аж в 1,33 раза больше, чем было у его предшественника A100. Но почему, логично было бы осведомится, в таком случае речь идёт о сотнях килобайт на целый огромный серверный ускоритель, а не о десятках и сотнях мегабайт хотя бы? Всё дело в том, что при своих бесспорных достоинствах SRAM обладает парой крайне неприятных именно для ИИ-приложений недостатков. Первый — это чрезмерно высокая цена вопроса: отводить на каждый бит данных по шесть транзисторных ячеек — значит вычитать ровно то же самое количество из числа используемых для формирования логических контуров на том же самом микрокристалле. Вдобавок, поскольку записанная в такой контур условная логическая единичка непрерывно «бегает по кругу», потребляя энергию из цепи питания, тепловыделение занимаемого SRAM фрагмента полупроводникового кристалла выходит в целом выше, чем для прочей его поверхности, где располагаются логические контуры — активируемые пусть и достаточно часто, но всё-таки лишь время от времени. Неравномерность же нагрева и затрудняет организацию эффективного теплоотвода, и ведёт к более скорому износу ячеек статической памяти в сравнении с соседними логическими контурами. Во-вторых, миниатюризация полупроводниковых структур уже не первый десяток лет идёт в соответствии с уточнённым законом Деннарда, о котором мы уже рассказывали в подробностях: рабочее напряжение транзистора зафиксировано на уровне около 1 В, что, в свою очередь, препятствует сокращению геометрических размеров транзисторного канала. Ячейка SRAM вполне способна работать при сниженном напряжении и при уменьшенной толщине изолирующего слоя, который отделяет затвор от канала, и даже станет при этом эффективнее, но, поскольку компонуется она ровно из тех же элементов, что и логические схемы по соседству, приходится мириться с избыточным расходом энергии ею. Более того, в ходе миниатюризации технологических норм сокращается и толщина металлических межсоединений, которыми связаны на кремниевой подложке полупроводниковые элементы. Но и для них истончение выражается (по причине того, что длина свободного пробега электронов сперва сравнивается с полутолщиной канала, а затем и превосходит её) в росте сопротивления и увеличении тепловых потерь при прохождении по ним электрического тока. И чем интенсивнее обращается логика чипа к памяти SRAM — а в случае работы с ИИ-моделями, напомним, коммуникации между ними чрезвычайно плотные, — тем хуже будет проявлять себя на практике такой микропроцессор с быстрым (и крупным!) кешем как единое целое. 
Поверхность предсерийного экземпляра Intel 14th Gen Meteor Lake, на которой размечены основные узлы этого процессора; как видно, на SRAM-кеши различных уровней приходится ощутимая доля его площади (источник: Le Comptoir Du Hardware) ⇡#Связи имеют значение«Главная проблема машинного обучения — управление памятью, а вовсе не вычисления», — утверждает Стив Родди (Steve Roddy), главный маркетолог компании Quadric, и плотно работающие с ИИ эксперты с ним целиком и полностью согласны. Раз SRAM масштабируется на более миниатюрные техпроцессы хуже, чем логика, есть смысл выделить быструю память в некий промежуточный слой между оснащёнными скромным кешем вычислительными чипами и основным массивом DRAM, — но в таком случае потребуется шина, специализированная для скоростного обмена большими потоками данных. Как раз на эту роль прочат сравнительно новый открытый стандарт компьютерных межсоединений Compute Express Link (CXL), построенный как развитие PCIe и предназначенный для обмена информацией между центральными процессорами, графическими процессорами и оперативной памятью, в том числе и на уровне виртуальных машин. CXL в перспективе позволит кардинально изменить нынешнее положение дел, когда львиную долю площади процессорного чипа занимают ячейки SRAM — и всё равно этой памяти не хватает для перемножения огромных матриц (к которому, по сути, сводится весь генеративный ИИ) исключительно на месте — прямо в этой быстрой памяти, с минимальными задержками на информационный обмен с вычислительными ядрами. Увы, проектировщикам графических ускорителей всё равно приходится переправлять часть данных прямиком в гораздо более медленную DRAM. При наличии же эффективной шины CXL система может комплектоваться отдельно арифметически-логическими контурами (возможно, с минимальными SRAM-кешами первого уровня на тех же самых кристаллах), отдельно более ёмкими промежуточными модулями SRAM, отдельно DRAM-блоками памяти для расчётов, допускающих более длительные задержки, — и тогда обработка ИИ-вычислений пойдёт значительно быстрее. Свой подход к решению обозначенной проблемы предлагает AMD, применяя теперь уже и при создании ЦП потребительского уровня, а не только серверных чиплетную технологию 3D V-Cache — с монтажом отдельной микросхемы кеш-памяти над или под плоскостью кристалла самого процессора. Правда, удовольствие это затратное, да ещё и заметно увеличивает сроки изготовления процессоров, но, если уж задаваться целью заметно ускорить инференс (и тем более тренировку) ИИ-моделей, на такие жертвы разумно идти. 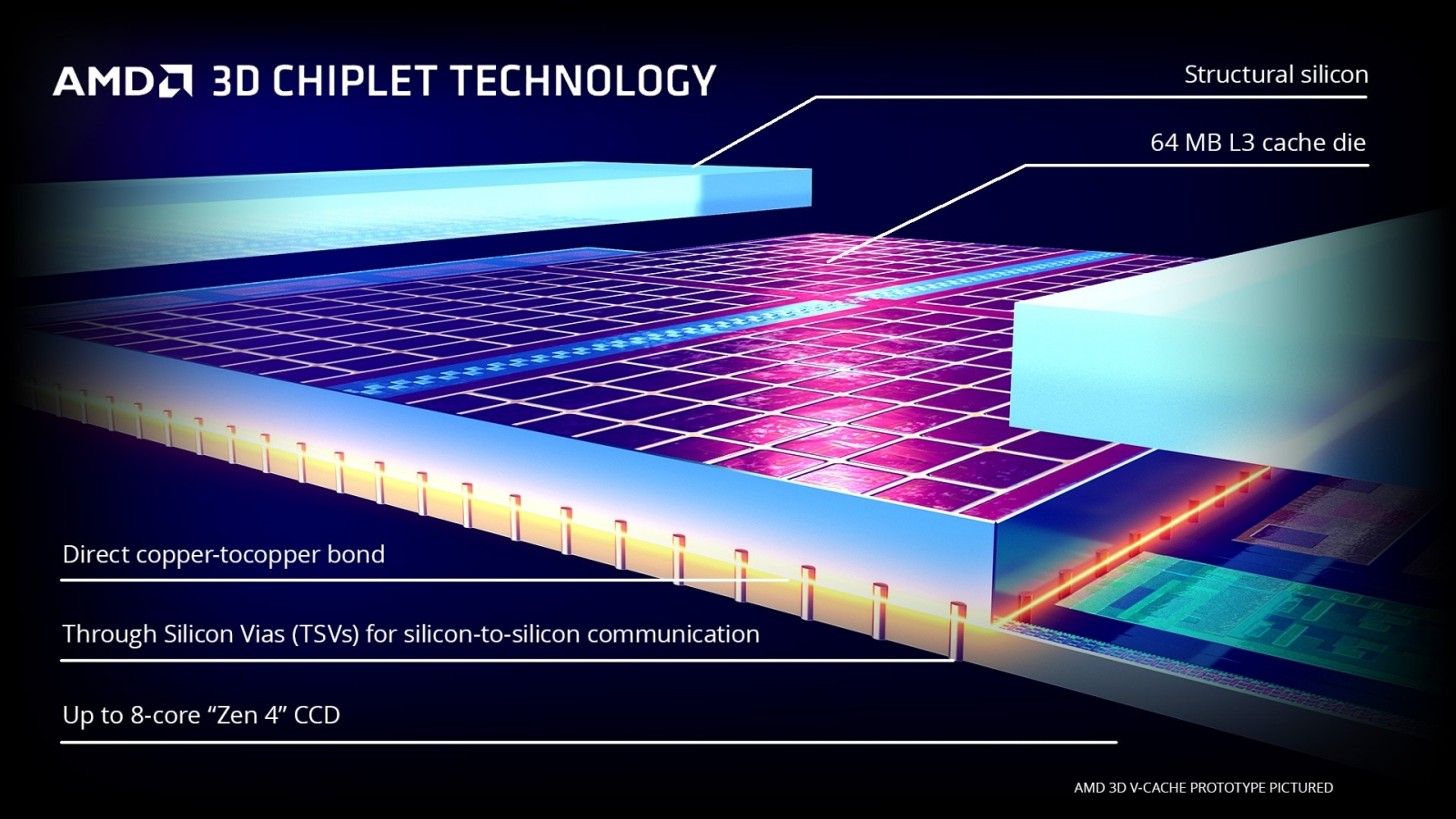
Применение 3D V-Cache подразумевает использование чиплетной технологии (источник: AMD) Дополнительные проблемы, с которыми сталкиваются инженеры в попытках миниатюризировать ячейки SRAM, порождаются ошибками одиночных событий — single-event upset (SEU). «Одиночным событием» по традиции называют взаимодействие микроэлектронного контура с высокоэнергичной заряженной частицей, чаще всего электроном из потока космических лучей, хотя порой SEU индуцируют и коротковолновые фотоны, и быстрые нейтроны. Энергия соударяющейся с полупроводником частицы передаётся материалу, и в случае ячейки памяти это может привести к изменению её логического состояния (bit flip) — переходу из изначального «1» в «0» или наоборот. Чем скромнее габариты формирующих SRAM элементов, чем меньше запасённая в шеститранзисторной ячейке энергия, тем с большей вероятностью очередное SEU (а космические лучи даже у самой поверхности Земли — явление отнюдь не редкое) приведёт к появлению сбойного бита в данной области кеш-памяти. Что крайне неприятно по той причине, что логические контуры для коррекции такого рода ошибок придётся размещать тут же, по соседству со статической памятью, опять-таки отбирая драгоценные транзисторы у основного «тела» вычислительного чипа. Кстати, если для компьютерных вычислений общего назначения SEU — всего лишь досадное неудобство, то с учётом курса на дальнейшую миниатюризацию служебных микросхем (применяемых в автомобиле и машиностроении, медицине и т. д.) от привычных ныне «40 нм»-«28 нм» по масштабной шкале вниз, самопроизвольный bit flip в процессорном кеше и тем более в регистровой памяти какого-нибудь промышленного контроллера, оставшийся незамеченным и неисправленным, грозит обернуться большой реальной бедой. Глава компании Flex Logix Джоффри Тейт (Geoffrey Tate) свидетельствует, что если в прежние десятилетия специальные микросхемы «с защитой от радиации» создавали лишь для аэрокосмических приложений (поскольку вероятность SEU тем больше, чем тоньше над полупроводниковым прибором слой земной атмосферы, весьма эффективно противодействующей космическим лучам), то начиная с производственной нормы TSMC N5 (маркетинговые «5 нм») воздействие заряженных частиц на ячейки SRAM оказалось уже слишком велико, чтобы оставлять его без внимания. При этом применять коррекцию ошибок, снижая тем самым полезную (уходящую на формирование главных логических контуров) площадь кристалла и добавляя определённые задержки в вычислительный процесс, выходит всё-таки экономически эффективнее, чем снабжать радиационной защитой стандартные ЦП и ГП для наземных применений, поскольку такая процедура разом прибавляет к их себестоимости от 25 до 50%. «Возможно, лет через десять нам всё-таки придётся экранировать чипы самого общего назначения от радиации, — сокрушался тем не менее мистер Тейт в 2024-м, — потому что безоглядно уменьшать размеры ячеек памяти дальше уже не удастся: от влияния заряженных частиц не избавиться никак». 
Устойчивые к радиации (точнее, к воздействию частиц космических лучей до определённых энергий) микросхемы внешне мало чем отличаются от предназначенных для массового рынка, а в будущем, возможно, эти небольшие отличия и вовсе сотрутся (источник: Intersil) Микроэлектронщики, разумеется, не сдаются — и даже в отсутствие острой необходимости защищать процессоры в ПК и серверах на поверхности Земли от космической радиации прямо сейчас продолжают изыскивать способы оптимизации работы SRAM. Ну например: раз ячейки статической памяти более чувствительны к понижению рабочего напряжения, чем построенные на точно таких же транзисторах логические схемы, представляется логичным подводить различные величины напряжений к процессорной логике и к интегрированной на тот же самый кристалл SRAM, — это подход «двойной подачи питания», dual power rail. Другой вариант — использовать высокоплотную память, high-density (HD) SRAM: вместо того, чтобы размещать на плоскости все шесть транзисторов ячейки 6T по соседству, их можно физически реализовать на едином «гребне» (fin), если речь идёт о FinFET, — в этом случае ячейка будет занимать на 30-45% меньшую площадь. Инженеры продолжают выдвигать всё новые идеи — просто потому, что технология интегрированной с логическими блоками на едином кристалле SRAM настолько хорошо отлажена и экономически эффективна, что едва ли не любые её усовершенствования, даже самые изощрённые, оказываются дешевле и быстрее в плане практической реализации, чем переход к иным типам памяти. ⇡#Есть такая память!Впрочем, и по направлению перспективной замены SRAM разработки тоже активно ведутся. Скажем, если выйдет поставить на место шеститранзисторной ячейки состоящую из одного-единственного элемента, это уже приведёт к многократному сокращению отводимой на один бит площади микросхемы, даже если такой элемент окажется крупнее стандартного для данной технологической нормы транзистора. Физической реализацией одноэлементной памяти с произвольным доступом может стать магниторезистивная её разновидность — magnetoresistive random access memory, MRAM, либо просто резистивная, resistive RAM — сокращённо ReRAM или RRAM; в последнем случае под воздействием приложенного напряжения меняются не магнитные свойства, а электрическое сопротивление материала. Увы, оба этих варианта, хотя в принципе и допускают создание соответствующих элементов на единой с логическими схемами подложке, пока что не позволяют получить память со сколько-нибудь сравнимыми с SRAM скоростными характеристиками. Таким образом, сложные многоуровневые конструкции (регистровые ячейки; кеши L1, L2, L3; затем уже DRAM с подключением через CXL, например) продолжают оставаться и экономически более выгодными, поскольку работают по-прежнему несопоставимо быстрее. 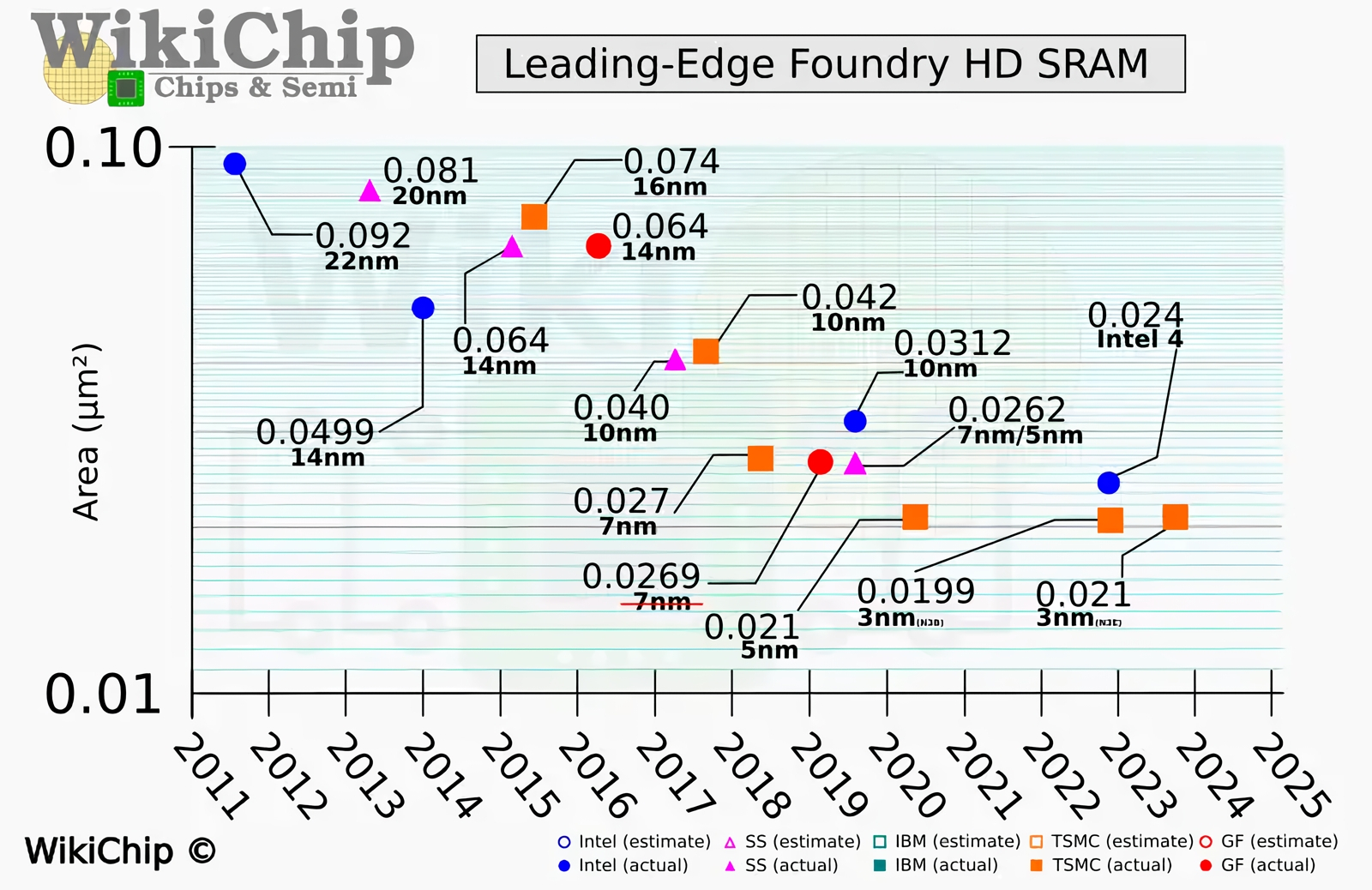
Наглядный график, отображающий замедление темпов, которыми сокращается площадь единичной ячейки (bitcell size) памяти SRAM, выраженная в миллионных долях квадратного миллиметра (по вертикали), с переходом на всё более миниатюрные производственные нормы (источник: WikiChip) Как же будут выкручиваться инженеры, если к моменту перехода на очередную технологическую норму выяснится, что формируемые с её применением ячейки SRAM попросту не годятся — занимают, к примеру, слишком большую площадь кристалла при пропорциональном его уменьшении (т. е. с сохранением прежнего числа транзисторов, идущих на формирование логических контуров, с одной стороны, и ячеек статической памяти — с другой)? Вопрос не праздный: для абстрактного чипа, 60% от общего числа транзисторов которого отведены под логику и 40% под SRAM, соотношение занимаемых теми и другими площадей для производственной нормы TSMC N16 (маркетинговые «16 нм») составляло примерно 82:18, для N5 — уже 78:22, а для N3 приблизилось к 71:29. Наиболее очевидным решением такой проблемы может стать уже упоминавшийся переход к чиплетной компоновке процессорного кристалла: логика (разумеется, с регистровыми ячейками памяти, от которых в рамках нынешних микроархитектур никуда не деться) на одном чиплете, кеши SRAM — на другом; при этом чиплет со статической памятью производится по более ранним производственным нормативам — чтобы избежать гнёта нарастающих в ходе миниатюризации проблем. Если учесть, кстати, что и сама логическая основа современного микропроцессора всё более укрупняется и что её тоже дробят на чиплеты как AMD, так и Intel, это представляется вполне разумным вариантом. Впрочем, списывать со счетов старые добрые ячейки 6T пока ещё рановато. В конце 2024-го, когда TSMC обнародовала более детальные спецификации своего перспективного технологического процесса N2, выяснилось, что площадь ячеек SRAM для него меньше, а плотность размещения сохраняемых в них данных, соответственно, выше, чем предполагали ранее независимые эксперты — на основе анализа прежнего перехода, от N3P к N3X. Дело, видимо, в том, что в случае N2 тайваньский чипмейкер впервые в своей практике сделал ставку на нанолистовые транзисторы с кольцевыми затворами (nanosheet GAA FET), что одновременно позволило и снизить потребляемую мощность, и увеличить производительность, и поднять плотность размещения этих элементарных полупроводниковых устройств до невиданных для FinFET значений. Для сравнения: если первый техпроцесс поколения N3 характеризовался плотностью SRAM в 33,55 Мбит/мм2, то переход к N2 поднял эту величину до 38,00 Мбит/мм2, — соответственно, площадь одиночной ячейки статической памяти на поверхности полупроводникового кристалла сократилась с 0,0199 до 0,0175 миллионной доли квадратного миллиметра (10-6 мм2). При этом важно отметить, что, когда техпроцесс N3 сменял собой предыдущий «5-нм» N5, площадь одиночной SRAM-ячейки практически не уменьшилась — между 0,0210 и 0,0199 10-6 мм2 всего-то около 5% разницы. 
Нанолистовой GAA-транзистор — спасение для классической SRAM? (Источник: TSMC) И разумеется, одними только проблемами со статической памятью дальнейшее развитие ИИ-вычислений не ограничивается. Достаточно упомянуть такое «бутылочное горлышко» на пути перемножения всё более многокомпонентных матриц, как неуклонный рост паразитной ёмкости и сопротивления межсоединений, которыми сопрягаются различные аппаратные компоненты полупроводниковых вычислителей. Помимо загрязнения полезных сигналов помехами (а их приходится убирать в том числе и логическим путём, добавляя новые уровни коррекции ошибок), эта напасть оборачивается повышенным расходом энергии и увеличением латентности — т. е. опять-таки ведёт к замедлению вычислений, которые и без того становятся чрезмерно громоздкими. Здесь всё упирается опять-таки в опережающие темпы масштабирования логических контуров — но отстают от них на сей раз не элементарные ячейки SRAM, а собственно металлические шины данных, что соединяют различные элементы полупроводниковых микросхем. Словом, ведущие эксперты микроэлектронной отрасли сегодня сомневаются, что экстенсивное наращивание плотности транзисторов на полупроводниковых микросхемах приведёт именно ИИ-вычисления — как раз по причине особой их требовательности к скорости обработки довольно простых операций — к желаемому для получения, скажем, AGI («сильного» ИИ) уровня. Если уже сегодня до двух третей потребляемых генеративными моделями в ходе инференса немалых объёмов энергии уходит на перемещение данных между процессорными ядрами и подсистемой памяти, то вполне вероятно, что качественный прорыв по направлению ИИ обеспечат всё-таки отличные от классических полупроводниковых фон-неймановских машин технологии — нейроморфные вычислители, аналоговые компьютеры, фотоника или что-то ещё. В любом случае, пока на исследования в области искусственного интеллекта человечество не скупится, рассматриваться параллельно будут все варианты — в том числе и расшивка «бутылочных горлышек» классического фон-неймановского подхода. Ведь уже столько сил и средств в него вложено — нельзя же просто взять и бросить!
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





