







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Мастерская локальных ИИ: победа не числом, а умением
Ближе к завершению 2025 г. арсенал приверженцев генерации изображений по текстовым подсказкам (text-to-image, T2I, — ограничимся именно специализированными моделями такого рода, потому что и ряд T2V-моделей, предназначенных исходно для создания видео, тоже способны выдавать неплохие статичные кадры) расширился неимоверно. Вдобавок к давно и хорошо известным DALL·E 3, Midjourney v7 и GPT-4o, которые не прекращали эволюционировать, к услугам тех, кто не прочь мириться с ограничениями онлайновых сервисов — от весьма волюнтаристских порой входных и выходных контент-фильтров до необходимости платить за каждую получаемую из облака картинку, — оказались Google Imagen 4, Nano Banana (она же Gemini 2.5 Flash Image), Seedream 4.0 и несколько других. Но и поклонники локальных ИИ-рисовалок заполучили в своё распоряжение ряд новинок: это и китайские Qwen-Image и Hunyuan Image 3.0, и долгожданная FLUX.2 от германской Black Forest Labs (основанной, напомним, в 2024-м выходцами из Stability AI — которой мы, в свою очередь, обязаны семейством T2I-моделей Stable Diffusion). ⇡#А ты не лопнешь?И всё было бы просто замечательно, если бы не размеры. Предназначенная для исполнения исключительно на облачных серверах Nano Banana, к примеру, — в её основу положена архитектура мультимодальных диффузионных трансформеров (MMDiT), — представляет собой плотную нейросеть с 80 млрд параметров, из которых в каждый момент времени задействуется около 13 млрд. У облачной (просто её создатели из ByteDance не желают выкладывать её веса в открытый доступ, — мало ли что всякие там пользователи без присмотра генерировать примутся!) Seedream 4.0 — 12 млрд параметров, у локальной FLUX.2 [dev] — 32 млрд; ядро Hunyuan Image 3.0 и вовсе образовано ансамблем экспертов, задействующим трансфузию (Mixture of Experts with the Transfusion method), что позволяет и ей из 80 млрд в принципе доступных параметров выбирать и активировать в каждом конкретном случае около 13 млрд. 
Все приведённые изображения выполнены разными моделями по одной и той же недлинной подсказке (см. её далее в тексте): верхний ряд, слева направо, — ZIT, GPT-image-1, FLUX.2 Pro; нижний ряд — Seedream 4.0, Nano Banana Pro, FLUX.1 Pro 1.1. Сразу бросается в глаза избыточная вольность последней модели, что относится к предыдущему поколению (использует CLIP и T5 для прямолинейного преобразования подсказки в токены), при обращении с китайскими иероглифами Но если для сторонников онлайн-генерации число параметров и архитектурные особенности той или иной модели в прикладном плане не слишком важны, то тех, кто желает, чтобы ИИ рисовал для них картинки исключительно локально, наметившаяся тенденция откровенно удручала. Чем лучше очередная новинка справлялась с «пониманием» текстовой подсказки и претворением той в графический образ, тем выше в среднем оказывались её системные требования. Более того, ряд свежих моделей начали опираться на самые актуальные программно-аппаратные решения (Nvidia CUDA 13.0, скажем), что делает их исполнение на формально архаичном, но всё ещё исправно действующем «железе» вроде GeGorce GTX 10-й и 20-й серий едва ли не невозможным. Словом, уже казалось — особенно после выхода FLUX.2 под конец ноября 2025 г., когда энтузиасты хором охнули, взглянув на размеры предлагаемых им к закачке файлов (53 Гбайт в сумме — и это ещё в «экономном» представлении весов, FP8 вместо FP16), — что дальше будет только хуже. Как вдруг! В последних числах ноября жаркие споры вокруг FLUX.2 в тематических сообществах Reddit и на иных площадках практически разом утихли: всеобщее внимание обратилось на скромную на первый взгляд — всего-то 6 млрд параметров, да ещё и на однопоточной архитектуре диффузионных трансформеров, — модель Z-Image Turbo (далее — ZIT), созданную в Tongyi Lab, что входит в состав Alibaba Group. Точнее даже, 6 млрд — это характеристика базовой модели, которая именуется просто Z-Image, на момент написания настоящей «Мастерской» ещё пока в свет не вышедшей. И это ещё одно смелое нововведение китайских товарищей: вместо того, чтобы сперва предлагать сообществу полнофункциональную, но более тяжеловесную версию, они сразу же выкатили дистиллированный (обученный с учителем, где в роли последнего — базовая модель) Turbo-вариант — с CFG = 1, требующий всего девяти шагов (steps) для генерации хоть фотореалистичных, хоть стилизованных изображений, да ещё и отменно справляющийся с воспроизведением на картинке предложенного в подсказке текста — причём как английского, так и китайского. В итоге энтузиасты буквально за несколько дней едва ли не позабыли о FLUX.2 и прочих локальных T2I-тяжеловесах, тем более что вскоре появилось расширение Z-Image-Turbo-Fun-Controlnet-Union, добавившее ещё и базовые возможности I2I (image-to-image generation). Легковесная, быстрая, отменно следующая подсказкам, очень достойная по качеству картинки, допускающая простую и эффективную тренировку LoRA пользователями, ZiV стала настоящим предрождественским подарком энтузиастам ИИ-рисования: «Я с самого момента выхода в свет Stable Diffusion 1.5 такого восторга от попавшей в мои руки генеративной игрушки не испытывал!» — это ещё одна из самых сдержанных реакций на новинку. Разберёмся же вчерне, как именно с ней работать локально. 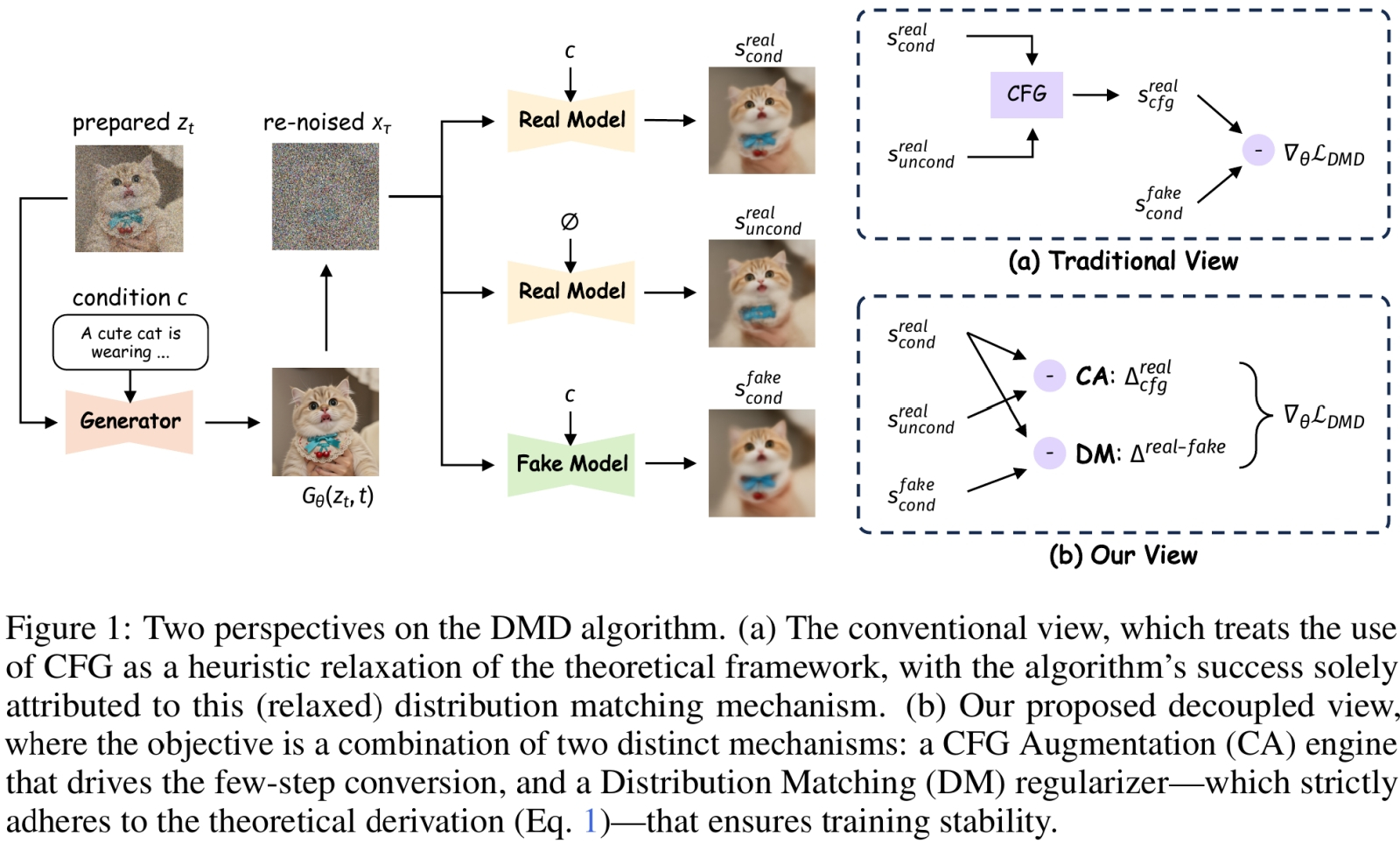
Диаграмма из препринта, опубликованного группой исследователей из Tongyi Lab 27 ноября 2025 г., где поясняется, как именно они применили вообще-то давно известный алгоритм DMD (Distribution Matching Distillation — дистилляция с учётом совпадающих распределений) для получения столь скоростной, компактной и выдающейся по характеристикам модели (источник: arxiv.org/pdf/2511.22677) Мы не станем в рамках «Мастерской» расписывать архитектурные достоинства ZIT — пусть полученные изображения говорят сами за себя. Тем более что благодаря высокой скорости работы и скромным системным требованиям — на нашем тестовом одре (Intel Core i7-2600K, 24 Гбайт DDR3-1333, GeForce GTX 1070 8Gb) изображение в 1 Мпикс (1024×1024 точки) эта модель выпекает в ComfyUI за 240-330 секунд, т. е. 20-25 с на одну итерацию, — поэкспериментировать с различными вариантами текстового ввода, стилями, персонажами и проч. каждый сможет сам без особенных затруднений. Главное — начать. ⇡#Взять и поставитьМы по-прежнему, как и в прошлых нескольких «Мастерских», пользуемся для локальной генерации рабочей средой ComfyUI: её поддержка сообществом более чем адекватна и практически все нововведения реализуются там буквально с колёс. Да, «макаронный» интерфейс может с непривычки показаться чрезмерно громоздким, но на деле — если аккуратно расставлять блоки и не допускать визуального перепутывания соединяющих их линий — разобраться в логике работы той или иной циклограммы оказывается вовсе не трудно. О том, как развёртывать ComfyUI — из практических соображений предпочтительнее portable-версия с предварительно настроенным Python в комплекте, не регистрирующая никакие ключи и пути в системном реестре, — на ПК под управлением Windows, мы не раз прежде рассказывали. Напомним лишь, что, если у вас на компьютере эта рабочая среда уже функционирует, её не помешает на всякий случай обновить, чтобы там точно появилась поддержка ZIT (а она имеется начиная с версии 0.3.75). Сперва в установочном каталоге надо будет заглянуть в папку update и запустить скрипт update_comfyui.bat; затем уже, подняв сервер (запуском скрипта run_nvidia_gpu.bat в основном каталоге), нажать в меню веб-интерфейса на кнопку «Manager» (соответствующее расширение уже должно быть установлено), а в открывшемся после этого окошке — на «Update all». После ещё одного перезапуска всё окончательно будет готово к дальнейшей работе. 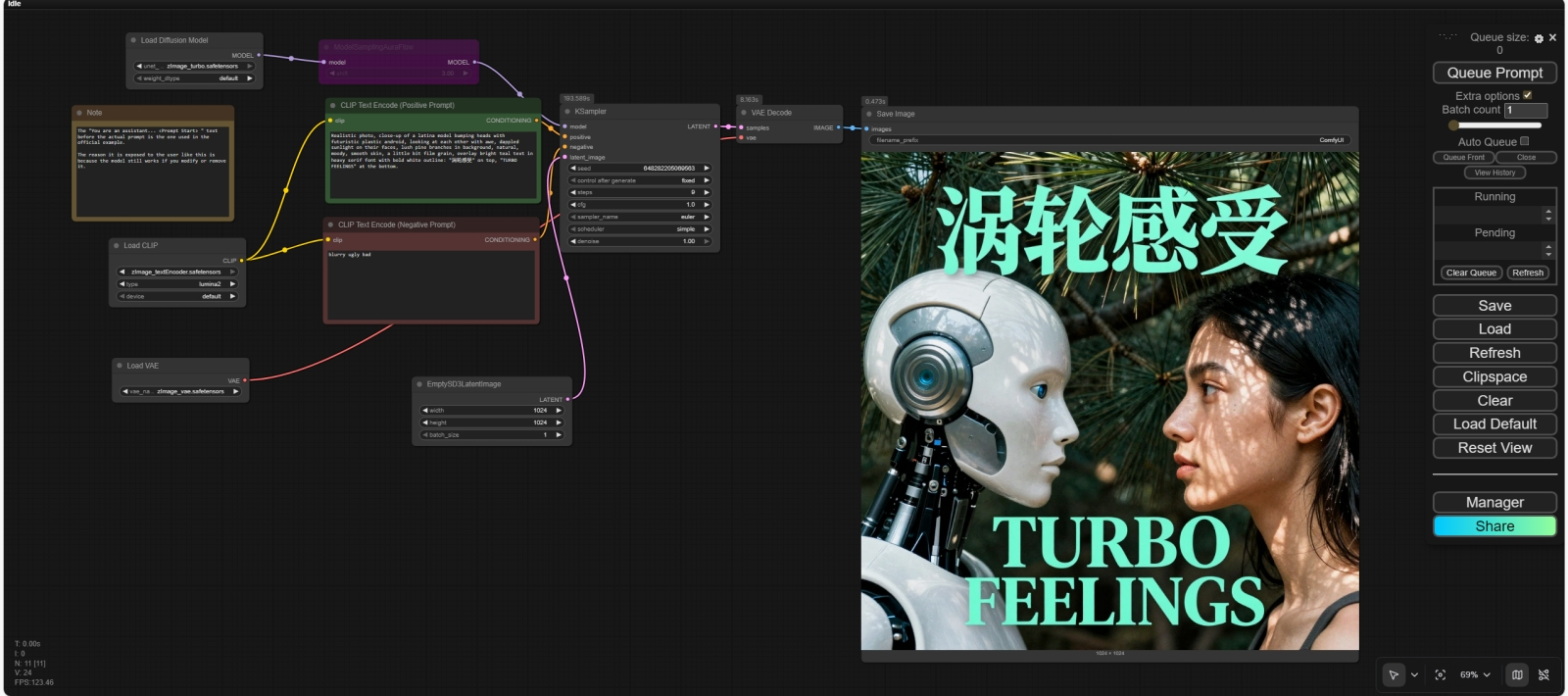
Скриншот модельной циклограммы с сайта Comfy Anonimous, только вместо его исходной подсказки здесь введена (и сработала) та, с которой мы будем разбираться чуть ниже. Обратите внимание на старую панель управления справа и на кнопку «Manager», свидетельствующую, что расширение это — оптимальное для управления прочими расширениями — уже установлено Сама же эта работа привычно начнётся с загрузки файлов необходимых моделей. На сайте автора используемой нами рабочей среды, Comfy Anonimous, размещены пример циклограммы и все необходимые ссылки на соответствующие репозитории портала Hugging Face. Скачать нужно будет:
Оговоримся, впрочем, что предлагаемая уважаемым Comfy Anonimous модельная циклограмма, на наш взгляд, не совсем оптимальна. Во-первых, там присутствует нода для отрицательной подсказки, которая именно в случае ZIV смысла не имеет (возможно, для пока — на момент написания этого текста — не выложенной Z-Image Base она и пригодится; сказать пока трудно), поскольку дистиллированная эта модель запускается с фиксированным значением бесклассификаторного указателя, classifier-free guidance, — CFG = 1. Что, в свою очередь, обессмысливает применение негативной подсказки вовсе, поскольку в ComfyUI та, если CFG равен единице, попросту игнорируется. Это сделано ради дополнительного ускорения именно турбомоделей, поскольку как раз в их случае из формулы, что указывает, какую именно долю «шума» убрать на очередном шаге из исходного изображения (чтобы получить заявленную в текстовой подсказке картинку), негативная часть подсказки входит с нулевым множителем. По этой причине в принципе незачем тратить вычислительные ресурсы на предварительную обработку этой части. 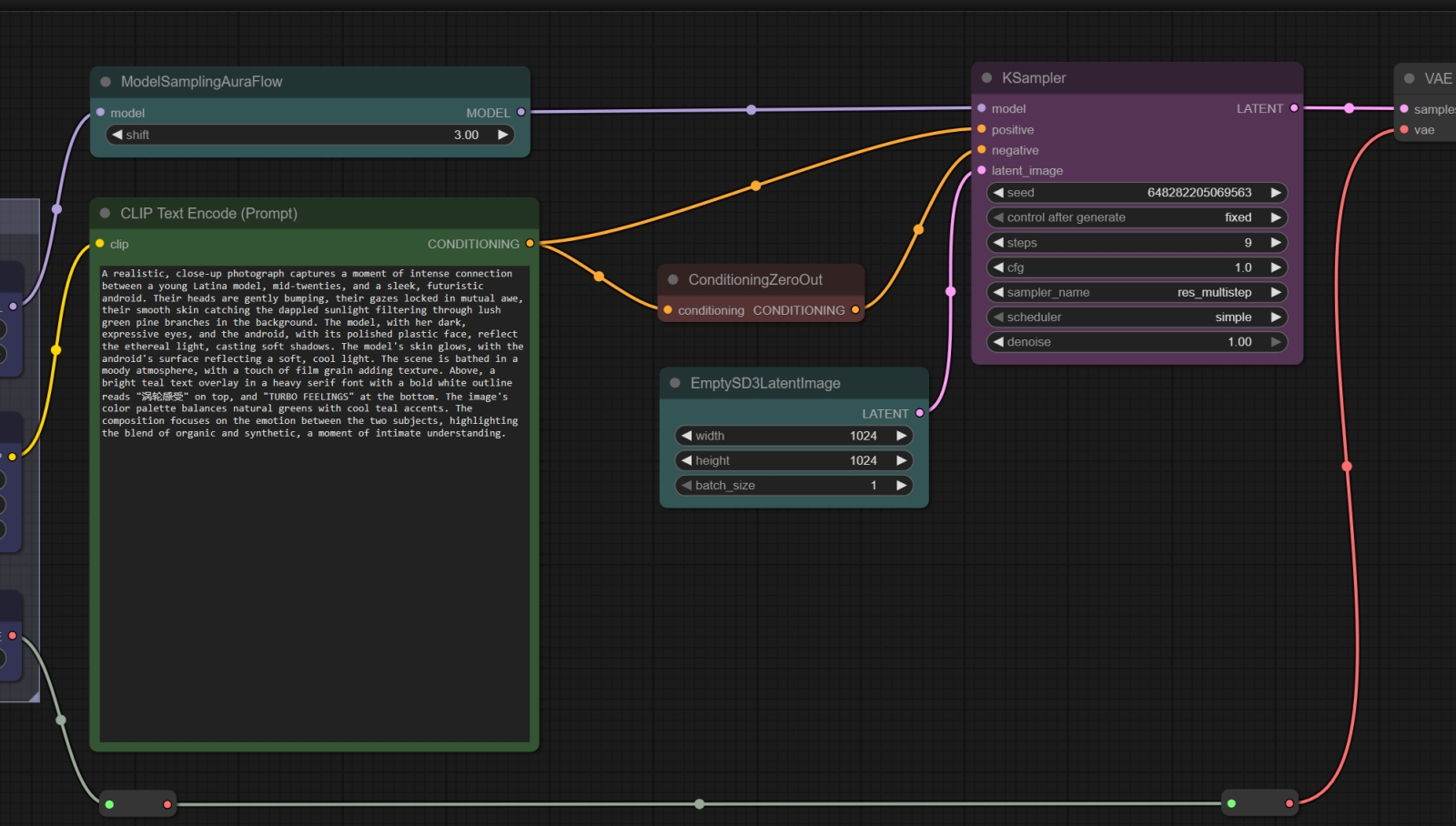
Особая нода «ConditioningZeroOut» (скромный кирпично-красный прямоугольничек в центре) получает на входе преобразованную узлом «CLIP Text Encode» текстовую подсказку, а выдаёт, как и следует из названия, нулевой результат. Эту ноду и нужно использовать, чтобы «подать ноль» на соответствующий вход «negative» ноды «KSampler» По этой причине вместо ноды текстового ввода для негативной подсказки мы ставим обнуляющую заглушку «ConditioningZeroOut». Кроме того, вместо канонического алгоритма выборки (sampler) Euler возьмём на вооружение оптимизированный как раз для ZIT алгоритм RES (Restart), в новых версиях ComfyUI доступный в выпадающем меню ноды сэмплера под названием res_multistep. Это как раз не обязательно; более того, хотя RES ускоряет работу циклограммы, обеспечивая весьма достойные результаты при более скромном использовании видеопамяти, другие алгоритмы — и, кстати, в комбинациях с другими планировщиками (scheduler), а не только с применённым здесь simple, — могут порождать более визуально привлекательные картинки. Правда, ценой более длительного времени исполнения, но в данном случае модель сама по себе настолько быстрая, что позволить себе поэкспериментировать можно. Ещё один момент: нода «ModelSamplingAuraFlow», которая в модельной циклограмме деактивирована (т. е. пропускает поток данных через себя, никак его не обрабатывая; чтобы её задействовать, нужно щёлкнуть по ней левой кнопкой мыши, тем самым выделив, и нажать на клавиатуре Ctrl+B), на деле всё-таки работает. Просто то значение, что она задаёт по умолчанию — 3,0, — как раз и используется при её деактивации. Нода эта появилась в рабочей среде вместе с поддержкой крайне амбициозной T2I-модели AuraFlow, которую энтузиасты, разочарованные провалом Stable Diffusion 3, принялись делать сами, но, поскольку работа эта кропотливая и дорогостоящая, проект пока остаётся на стадии беты. Однако сам алгоритм выборки (сэмплинга), предложенный этими разработчиками, оказался настолько удачным, что соответствующую ноду нередко применяют в ComfyUI-циклограммах, использующих быстрые («турбо») модели. Так вот; величину «3.0», заданную в «ModelSamplingAuraFlow» можно, а с экспериментаторской точки зрения — и нужно менять; она влияет на баланс между следованием букве текстовой подсказки и качеством итоговой картинки, служа своего рода заменой параметру CFG для турбомоделей, у которых сам этот параметр жёстко зафиксирован на уровне единицы. В общем, упомянутую ноду можно активировать — и пока не трогать, обеспечив себе на будущее дополнительный задел для экспериментаторства. 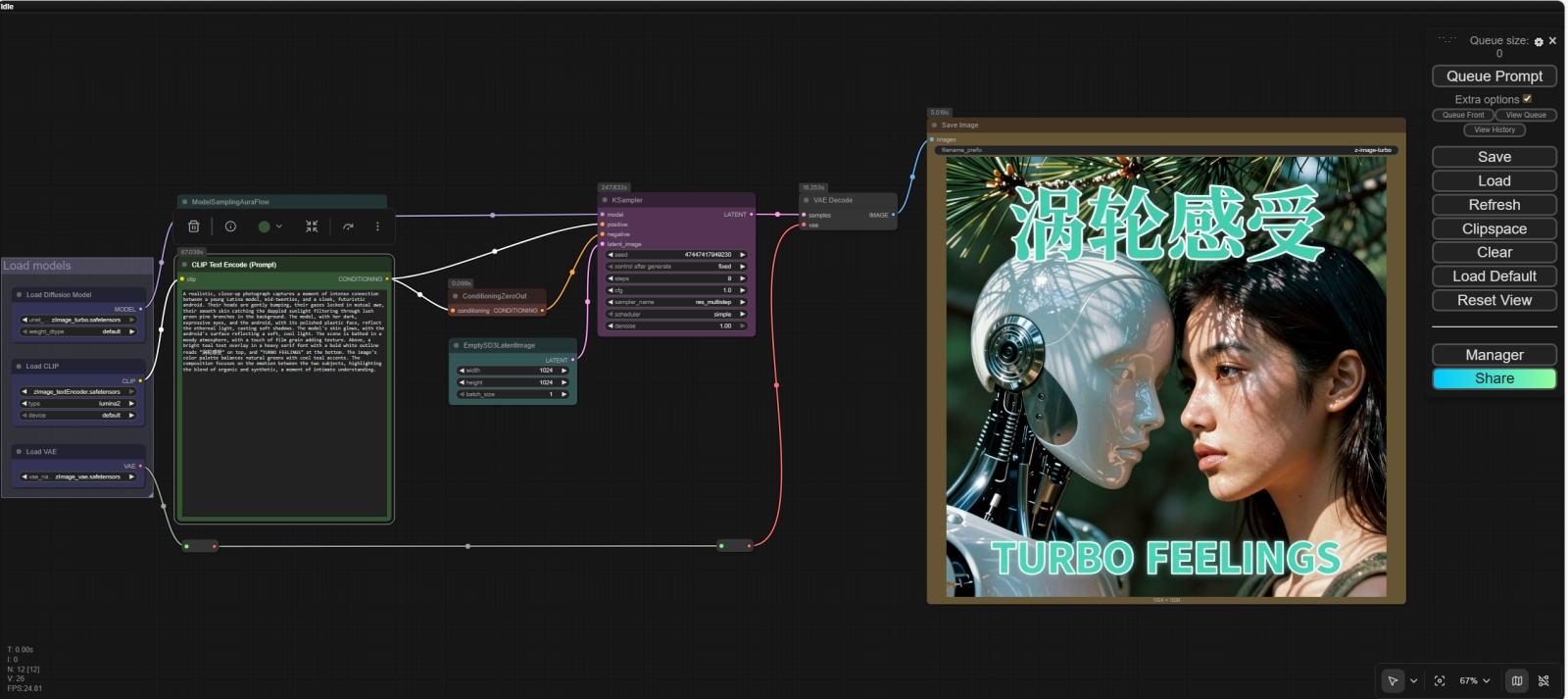
Скриншот общего вида исходной циклограммы, с которой мы будем далее экспериментировать, в рабочем поле ComfyUI. Обратите внимание снова: здесь используется старый интерфейс, в котором, на наш взгляд, все часто используемые органы управления расположены логичнее и удобнее, чем в новом. По умолчанию свежая версия ComfyUI установится с новым, куда более минималистичным интерфейсом; чтобы его отключить и вернуть прежний, надо перейти в главное меню, нажав на приметный значок шестерёнки («Settings»), и в первом же открывшемся окне деактивировать ползунок «Use new menu» ⇡#Человек и роботВ числе достоинств ZIT и сами разработчики, и многочисленные уже её пользователи указывают достойную фотореалистичность (особенно в части передачи фактуры человеческой кожи — с этим у многих даже более тяжеловесных моделей до сих пор не всё в порядке), адекватное воспроизведение англо- и китаеязычных текстов, уверенное следование операторским подсказкам. Проверим все эти утверждения разом, предложив системе, раз за разом перебирая случайные затравки, изобразить следующее: Realistic photo, close-up of a latina model bumping heads with futuristic plastic android, looking at each other with awe, dappled sunlight on their faces, lush pine branches in background, natural, moody, smooth skin, a little bit film grain, overlay bright teal text in heavy serif font with bold white outline: "涡轮感受" on top, "TURBO FEELINGS" at the bottom. 
Результат исполнения заданной подсказки с затравкой 47447417949230: слева — с алгоритмом выборки Euler, справа — RES Сразу отметим, что мелкие огрехи в воспроизведении заданного тут налицо: то лбами персонажи толком не сталкиваются, то белой обводки (white outline) вокруг литер не видно, то шрифт без засечек, хотя явно указан serif. Зато всё остальное — очень даже хорошо: и сам андроид, и сосновые ветки, и игра света и тени; даже латиноамериканские черты у девушки бросаются в глаза — в отличие от картинок, нарисованных по той же подсказке, например FLUX.2 Pro или Nano Banana Pro. И с балансом белого здесь по умолчанию полный порядок — в отличие от некоторых безбожно желтящих онлайновых моделей. Значит ли это, что первое испытание ZIV прошла успешно и дальше можно спокойно экспериментировать с параметром ModelSamplingAuraFlow, с алгоритмами выборки и планировщиками? Не совсем: внимательный читатель наверняка отметил ещё в самом начале необычно внушительный размер файла модели перекодировщика текста в токены, qwen_3_4b.safetensors, — это явно не те сравнительно простенькие CLIP и T5, на которые полагались Stable Diffusion 3 и FLUX.1. Тут переработкой текстового ввода занимается полноценная (мультимодальная!) малая языковая модель Qwen3-4b — та самая, что использовалась при исходном обучении Z-Image. МЯМ играет в данном случае роль высокоуровневого трансформера — и, кстати, новенькая FLUX.2 тоже полагается на солидный ИИ-перекодировщик, Mistral Small 3.2 в версии 24 млрд параметров. Так вот; как раз по той причине, что ZIT построена на однопотоковых диффузионных трансформерах (Single-Stream Diffusion Transformer, S3-DiT), она обрабатывает текст и визуальные образы совместно. А значит, не полагается на вылавливание из подсказки «знакомых» ей по этапу тренировки слов и понятий (цепочек токенов, точнее), а с ходу корректно интерпретирует семантику фраз и устанавливает адекватные взаимосвязи между объектами в извлекаемом из латентного пространства кадре. 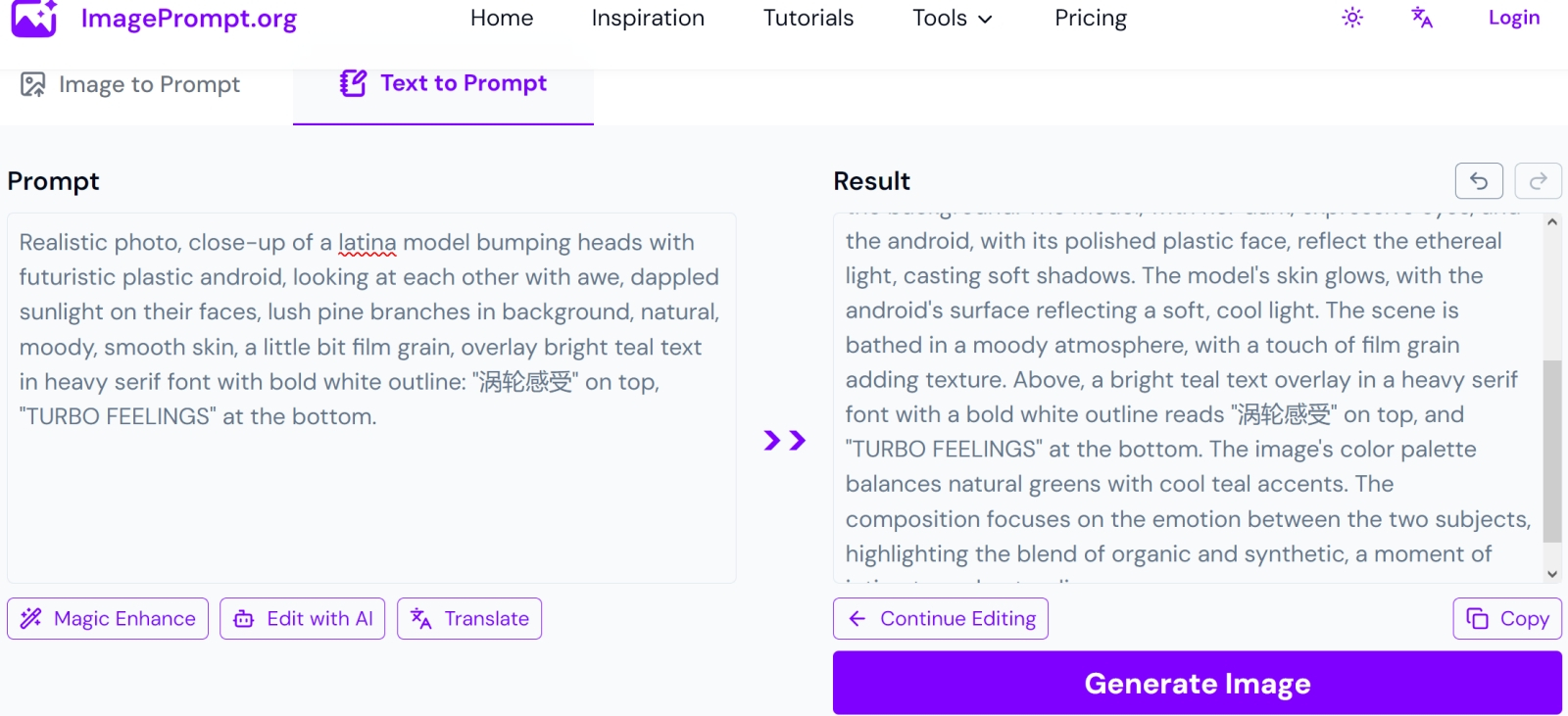
Мощный ИИ, практически любой современный облачный, здорово помогает с обогащением подсказок (prompt enhancement): можно попросить ChatGPT, Grok, Mistral и проч. расширить и дополнить предложенную фразу, а можно обратиться к специализированным онлайновым ресурсам (скриншот сайта ImagePrompt.org) Практическое следствие отсюда, даже два:

Два варианта обработки ZIT подсказки с одной и той же затравкой: слева — с коротким исходным текстом, справа — с креативно распространённым сторонней ИИ-моделью; оцените, насколько ожила картинка! ⇡#Больше хороших картинокЕсли воспользоваться онлайновыми средствами обогащения подсказок (мы здесь задействовали сайт ImagePrompt.org, раздел «Text to Prompt»), из приведённого ранее текста на 63 слова про девушку и андроида выйдет, к примеру, вот что (понятно, что, поскольку там тоже работает авторегрессионная генеративная модель, при каждом запуске результат будет выходить несколько иным): A realistic, close-up photograph captures a moment of intense connection between a young Latina model, mid-twenties, and a sleek, futuristic android. Their heads are gently bumping, their gazes locked in mutual awe, their smooth skin catching the dappled sunlight filtering through lush green pine branches in the background. The model, with her dark, expressive eyes, and the android, with its polished plastic face, reflect the ethereal light, casting soft shadows. The model's skin glows, with the android's surface reflecting a soft, cool light. The scene is bathed in a moody atmosphere, with a touch of film grain adding texture. Above, a bright teal text overlay in a heavy serif font with a bold white outline reads "涡轮感受" on top, and "TURBO FEELINGS" at the bottom. The image's color palette balances natural greens with cool teal accents. The composition focuses on the emotion between the two subjects, highlighting the blend of organic and synthetic, a moment of intimate understanding. Овчинка явно стоит выделки: время на обработку расширенной подсказки если и увеличивается, то практически неощутимо, зато результат выходит заметно приятнее — и в целом более соответствует исходной (короткой) подсказке, как ни парадоксально. 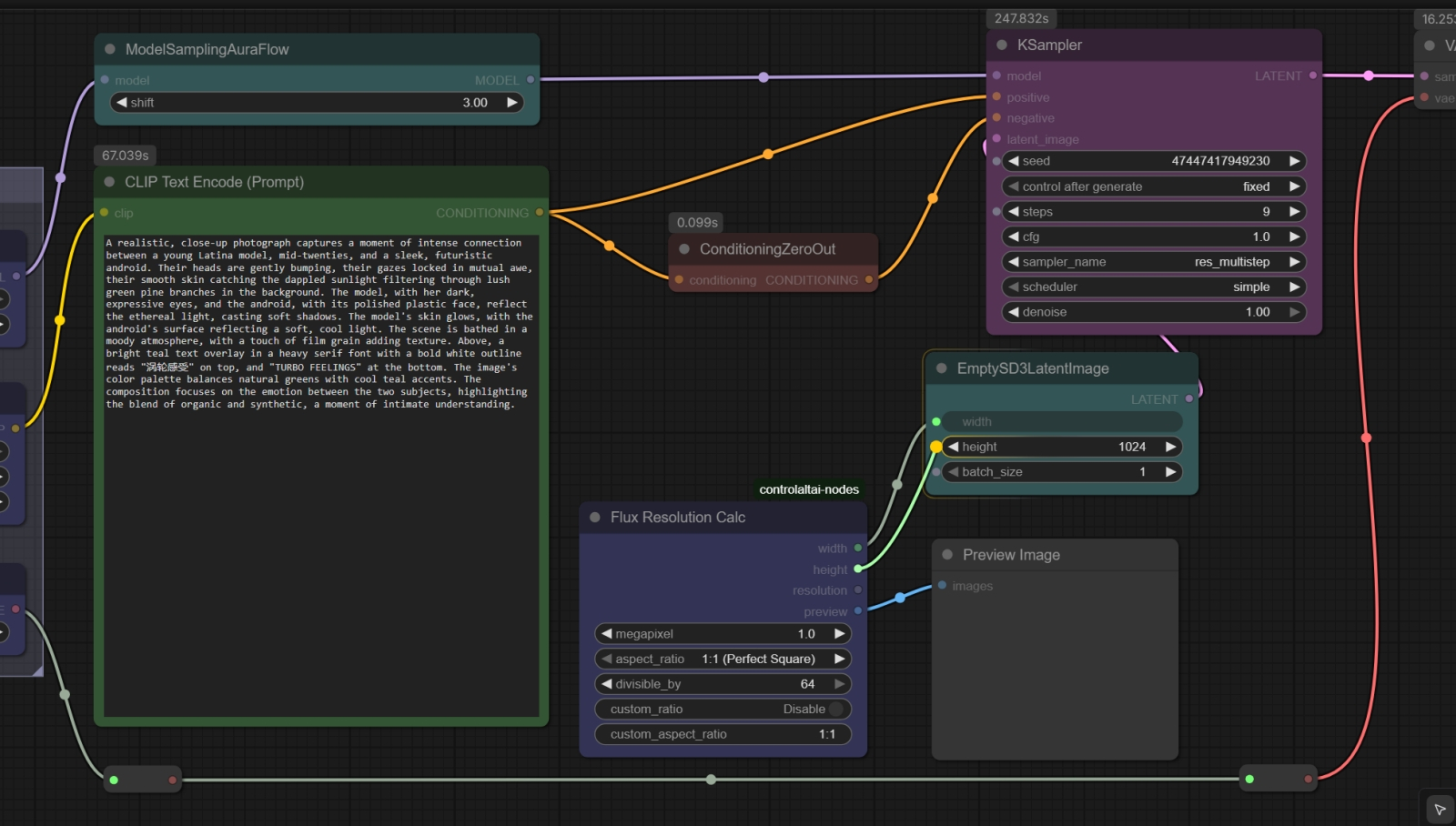
Чтобы соединить выход ноды «Flux Resolution Calc» со входами для ширины и высоты на ноде «EmptySD3LatentImage», достаточно мышкой потащить линию от выходной точки и подвести её к нужному полю ввода — то автоматически преобразуется в точку входа. Удобно! Теперь, освоив технику обогащения подсказок, добавим ZIT-генерациям вариативности: скорость исполнения этих моделей настолько велика, что их прямо-таки подмывает запускать в режиме бесконечной генерации с вылавливанием особенно удачных изображений (хотя они и в среднем весьма хороши). И для начала автоматизируем выбор разрешения картинки: нода «EmptySD3LatentImage» предусматривает только ручной ввод ширины и высоты в пикселах — нельзя ли как-то поудобнее? Можно! В составе дополнения ControlAltAI, о котором мы упоминали в прошлой «Мастерской», есть нода «Flux Resolution Calc» с удобнейшим выпадающим меню соотношений сторон изображения (1:1, 2:3, 16:9 и проч.), а также его полного разрешения в мегапикселах (от 0,1 до 2,5). Дополнение это, если его в рабочей среде ещё нет, просто устанавливается через «Manager» — находится по названию, дальше кнопка «Install», — и, как обычно, после перезапуска сервера и перезагрузки веб-страницы в браузере всё готово к работе. 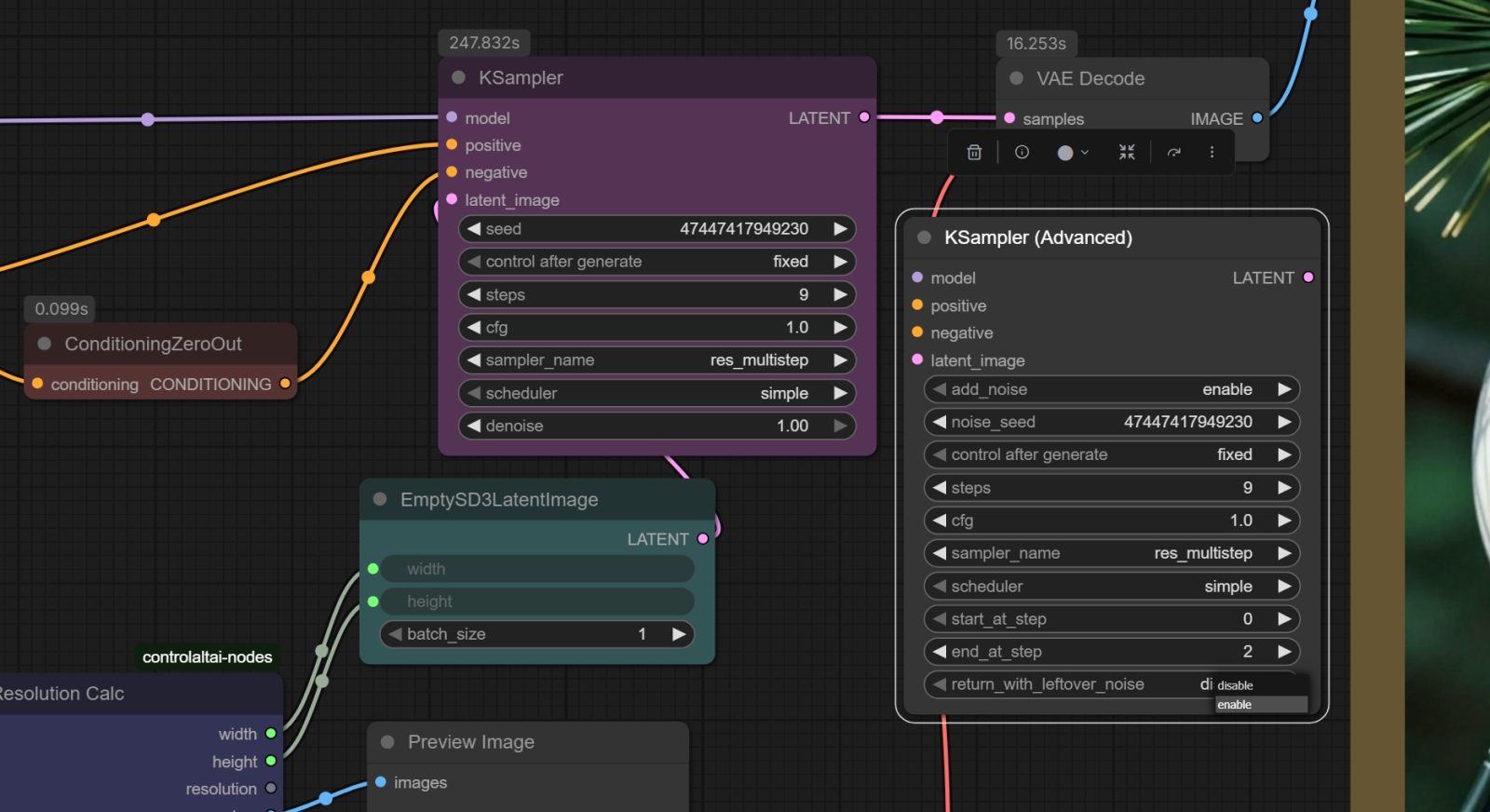
Для начала рядом с рабочей нодой «KSampler» открываем «KSampler (Advanced)» и переносим те значения, что указаны в первой. Обязательно нужно выставить параметр «end at step» в значение «2», а в самом низу указать «enable», чтобы на следующую ноду недогенерированная (2 шага из 9) картинка передавалась с остаточным шумом Следующий этап — замена ноды «KSampler» сразу двумя «KSampler (Advanced)», и вот для чего. Как мы уже говорили, вариативность изображений, выдаваемых ZIT, не слишком велика именно по причине уверенного выявления семантических связей в подсказке: когда всё чётко определено вплоть до мелких деталей, простора для творческого поиска остаётся мало («художник-мечтатель в логической западне» — как раз про это). Однако можно сделать хитрый ход, впервые, насколько мы можем судить, предложенный пользователем Reddit под ником SnareEmu: из 9 шагов генерации первые 1-2 должны идти абсолютно вслепую, с нулевой положительной (а не только отрицательной) подсказкой. И только за оставшиеся 7-8 шагов на той основе, что совершенно случайным, получается, образом выужена из латентного пространства, модель будет стараться дорисовать семантически связную картинку в меру своего разумения. 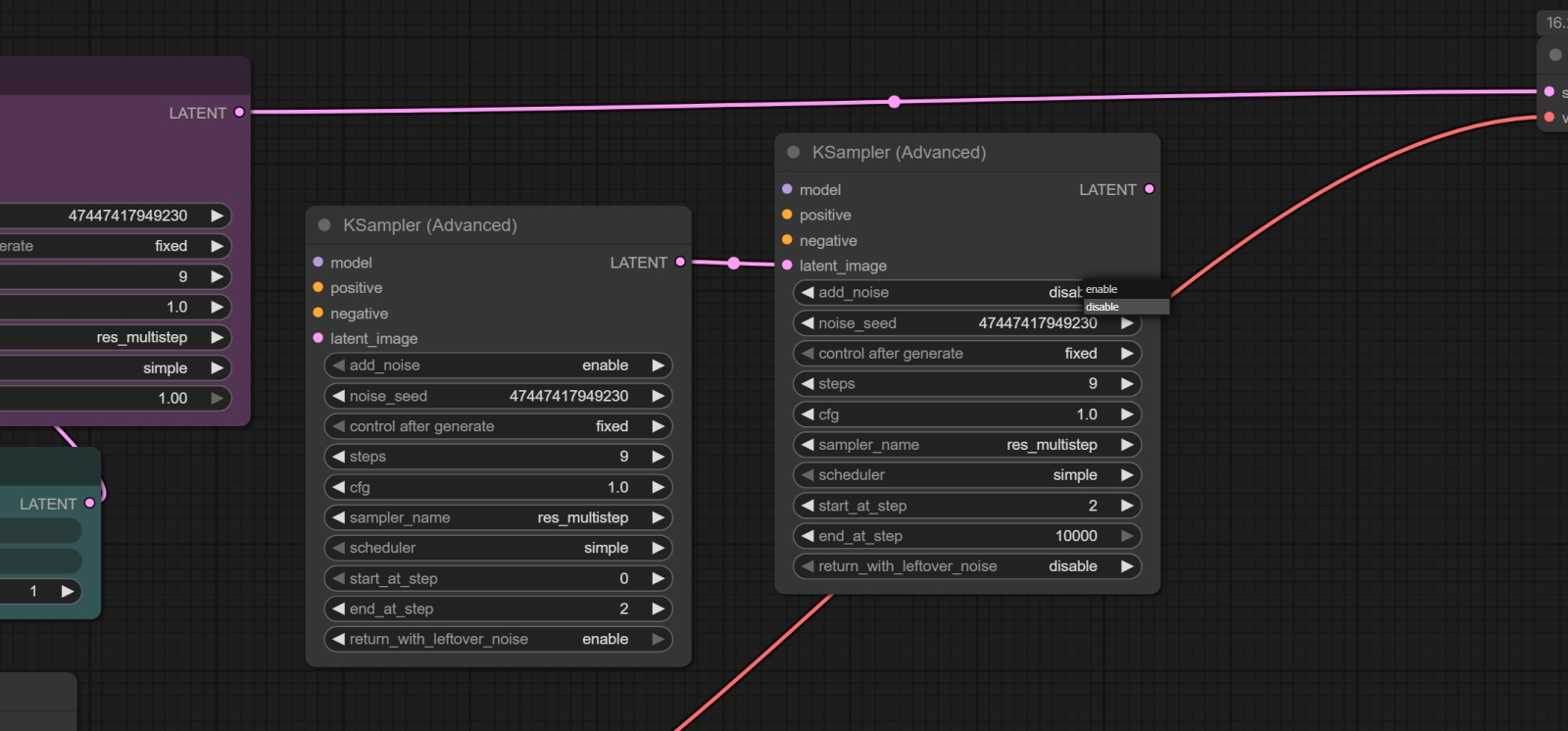
Вторая нода «KSampler (Advanced)» завершает начатое первой, и от неё выход идёт уже на стандартную ноду «VAE Decode» для преобразования готового латентного изображения в пиксельное. Здесь параметру «start at step» следует придать значение «2», а «add noise» (самый верхний) — «disable» Для этого как раз и пригодится нода «KSampler (Advanced)», которая умеет останавливать генерацию на заданном шаге и передавать дальше латентное изображение — не готовую картинку! — с остаточными шумами, чтобы уже следующая нода их использовала по своему разумению. Таким образом, первая из нод «KSampler (Advanced)» встанет на место прежней «KSampler», начнёт генерацию с теми же самыми параметрами, а на втором шаге передаст непропечённую картинку второй — которая уже доведёт дело до конца. Дальше нужно корректно всё пересоединить: выход «MODEL» ноды «ModelSamplingAuraFlow» приходит теперь на входы обеих «KSampler (Advanced)», выход «CONDITIONING» от ноды с позитивной подсказкой — на соответствующий вход второй «KSampler (Advanced)», а вот от «ConditioningZeroOut» потоки «нулевых» данных приходят на три входа: на оба подходящих у первой «KSampler (Advanced)» и на вход «negative» второй. 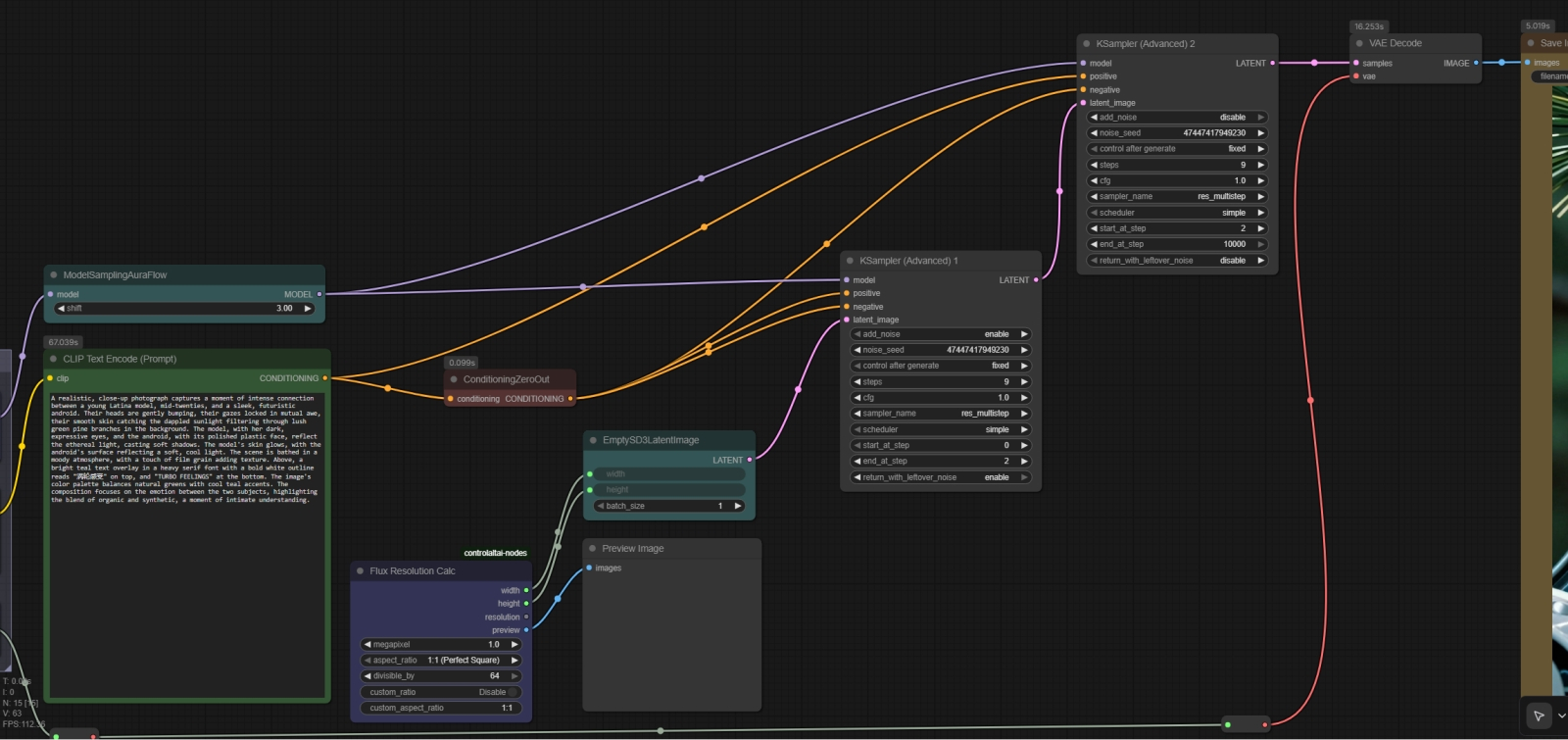
Общий вид связей в узле генерации изображения усложнённой циклограммы. Обратите внимание: на вход ноды «VAE Decode» параметр «vae» подаётся с выхода загружающей эту модель ноды «Load VAE» (она осталась за левым обрезом картинки) через две служебные мини-ноды перенаправления, «Reroute». Сделано это исключительно ради пущей наглядности: так соединительные линии не пересекаются, и циклограмма читается без особого труда Далее логично будет задать значение «random» для полей «control after generate» в обеих нодах «KSampler (Advanced)» — и запускать уже генерацию в бесконечном цикле, наслаждаясь явно расширившимся разнообразием. Кстати, сам SnareEmu рекомендует в своём посте увеличивать значение «ModelSamplingAuraFlow» от исходных 3 — это помогает дополнительно усиливать вариативность; разумной величиной в сообществе энтузиастов ZIT признана 6 или 7. И, как обычно, сгенерированные в рамках этой «Мастерской» изображения — PNG-файлы со встроенными циклограммами, которые открываются в рабочей среде ComfyUI, — можно скачать из облака. 
Разнообразие! Теперь при соотношении сторон 2:3; прочие параметры, включая распространённую подсказку, прежние, — соседние картинки различаются только затравками, seeds Отметим, кстати, что не всегда разнообразие, добавляемое прямиком из бездны латентного пространства, — это хорошо. Если визуализировать (используя ноды «VAE Decode» и «Preview Image») те россыпи разноцветных точек, которые представляет собой картинка после двух шагов генерации, на них частенько будут видны периодические артефакты, — чаще горизонтальные, а порой и вертикальные группы пикселов схожей расцветки, из которых на следующем этапе, за оставшиеся шаги, формируются не заданные исходной подсказкой структуры: скорее всего, это особенность ZIT как дистиллированной модели. Однако и такие структуры могут внезапно оказаться эстетически привлекательными — по крайней мере, скучно с таким вариантом рабочей циклограммы для Z-Image Turbo экспериментатору-энтузиасту уж точно не будет. Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





