







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
AGI: и хочется, и колется
В ходе январского (2026 г.) Всемирного экономического форума в Давосе резко схлестнулись две противоположные точки зрения на сильный, если использовать устоявшийся русскоязычный термин, искусственный интеллект, он же рукотворный интеллект в общем смысле (т. е. не просто пригодный для создания убедительных видео по текстовым подсказкам или построения сложных маршрутов путешествий с бронированием отелей и заказом билетов, а во всех прикладных отношениях неотличимый от биологического человеческого) — artificial general intelligence, AGI. Группа оптимистов, представленная Дарио Амодеи (Dario Amodei), генеральным директором Anthropic (при косвенной, поскольку он в этом году мероприятие пропустил, но горячей поддержке главы OpenAI Сэма Альтмана, Sam Altman), твердила, что AGI не просто достижим в ближайшие считаные годы, но что разработчики уже двигаются в сторону некоего искусственного «суперинтеллекта» (superintelligence), который-де окажется «умнее всех людей на планете, вместе взятых». Пессимисты же — точнее сказать, осторожничающие реалисты вроде Демиса Хассабиса (Demis Hassabis), руководящего разработками модели Gemini в Google нобелевского лауреата, или же увенчанного премией Тьюринга, самой престижной наградой в области компьютерных наук, пионера в области ИИ и нейронных сетей в целом Яна Лекуна (Yann LeCun), — упирали на принципиальную непригодность активнейшим образом развиваемых сегодня больших языковых моделей (БЯМ) для достижения AGI, хоть сколько-нибудь сопоставимого с человеческим. 
«Ну сколько можно ждать, пока меня наконец-то изобретут?» (Источник: ИИ-генерация на основе модели SeeDream 4.5) Хассабис, впрочем, оговорился, что существует всё-таки, по его мнению, 50%-ная вероятность (ну то есть как динозавра встретить) создать вожделенный AGI в течение ближайших десяти лет, — хотя для этого, «возможно, нам понадобится ещё один или два прорыва». Прорывы нужны по таким направлениям, как способность моделей учиться на нескольких примерах, сопоставляя и анализируя их; по-настоящему непрерывно и самостоятельно получать новые знания; свободно оперировать обширной долговременной памятью; наконец, инициативно развиваться, совершенствуя свои — далёкие пока от идеала — навыки рассуждения и планирования. И скачок, который предстоит на этом пути сделать разработчикам, — принципиально качественный: нынешние БЯМ, строго говоря, вовсе не обладают никаким интеллектом; ни общим, ни частным. Они не более чем стохастические попугаи (stochastic parrots — вполне устоявшийся в среде специалистов термин), иллюзия интеллектуального поведения которых — всего лишь проекция (чтобы не сказать — вторичное пережёвывание) созданных реальным человеческим интеллектом данных из того массива, на котором они обучались. Языковая модель не более чем нанизывает один токен на другой, используя статистические закономерности с добавлением щепотки стохастики, но понимание того, чем она занимается, у неё самой отсутствует. Отсюда, собственно, и галлюцинации, и подверженность атакам через «отравление» подсказок и датасетов, и неспособность отличать физическую реальность от вымысла. Понятно, что в идеале пресловутый AGI должен избавиться от попугайства, от ретрансляции (с некоторыми искажениями, принимаемыми за творчество) исключительно почерпнутых из тренировочного набора данных мыслей, и начать генерировать свои собственные. Отталкиваясь от предварительно усвоенного массива, да, — но ведь так поступает и биологический разум. А почему, собственно, мы тогда считаем какого-нибудь увлечённого школьника, что сыпет — весьма к месту — цитатами из великих философов, интеллектуалом, а ещё вернее и ближе к тексту (да с прямыми ссылками на первоисточники!) приводящего те же самые цитаты ChatGPT, Grok или Claude — нет? 
«Попка не дур-р-рак! Попка стохастик!» (Источник: ИИ-генерация на основе модели GPT-image-1) Интеллект — понятие многогранное, даже если подходить к нему не с философской, а с чисто практической стороны. Оно включает в себя усвоение новой информации, способность решать возникающие проблемы, выявление закономерностей в рядах данных, работу с абстрактными и сложными вопросами (условно «жидкий», или гибкий — fluid — интеллект) и применение ранее полученных знаний и опыта («кристаллизованный» интеллект). А ведь есть ещё и социальный интеллект, существенно важный для деятельности в коллективе, и физический (точнее было бы называть его корпоральным, наверное, — имеется в виду навык координации тела и обращения с предметами в пространстве), в особенности присущий выдающимся спортсменам. Но все эти определения хороши для биологических существ — с их сформированными эволюцией телами и разумами. А с какой меркой подходить к разуму искусственному — на основании чего судить, достаточно ли тот интеллектуален, чтобы встать вровень с человеком? Каким, собственно, образом на практике удостовериться — когда и если наступит время, — что просто искусственный интеллект наконец-то сделался сильным? Тест Тьюринга в наши дни уже заведомо не годится — нужен иной подход. ⇡#Определимся с определениямиИ для начала неплохо было бы определиться с тем, как измерять уровень интеллекта в принципе, — предварительно, кстати, уточнив, что же представляет собой собственно интеллект. Сперва зафиксировать объект измерения, затем — метод. Идея вроде бы здравая, но вот с реализацией её возникают определённые загвоздки, — начиная уже с самих определения и метода. Это заметно уже по тому, что замерять интеллект, даже у самих людей, — задача непростая. Система тестов IQ довольно неплохо определяет способность человека решать определённые задачи, что с некоторыми оговорками действительно можно считать мерилом интеллекта — в современных условиях городской западной цивилизации. Но вот, допустим, какой-нибудь охотник-собиратель с самодельными копьём и луком отлично выживает в своей нецивилизованной глуши, хотя наверняка не наберёт, проходя этот тест, и полусотни баллов, — а уважаемый профессор Гарварда с IQ 130+ в тех же условиях и с тою же экипировкой навряд ли протянет больше трёх-пяти суток. Ну и у кого из них, спрашивается, интеллект выше? 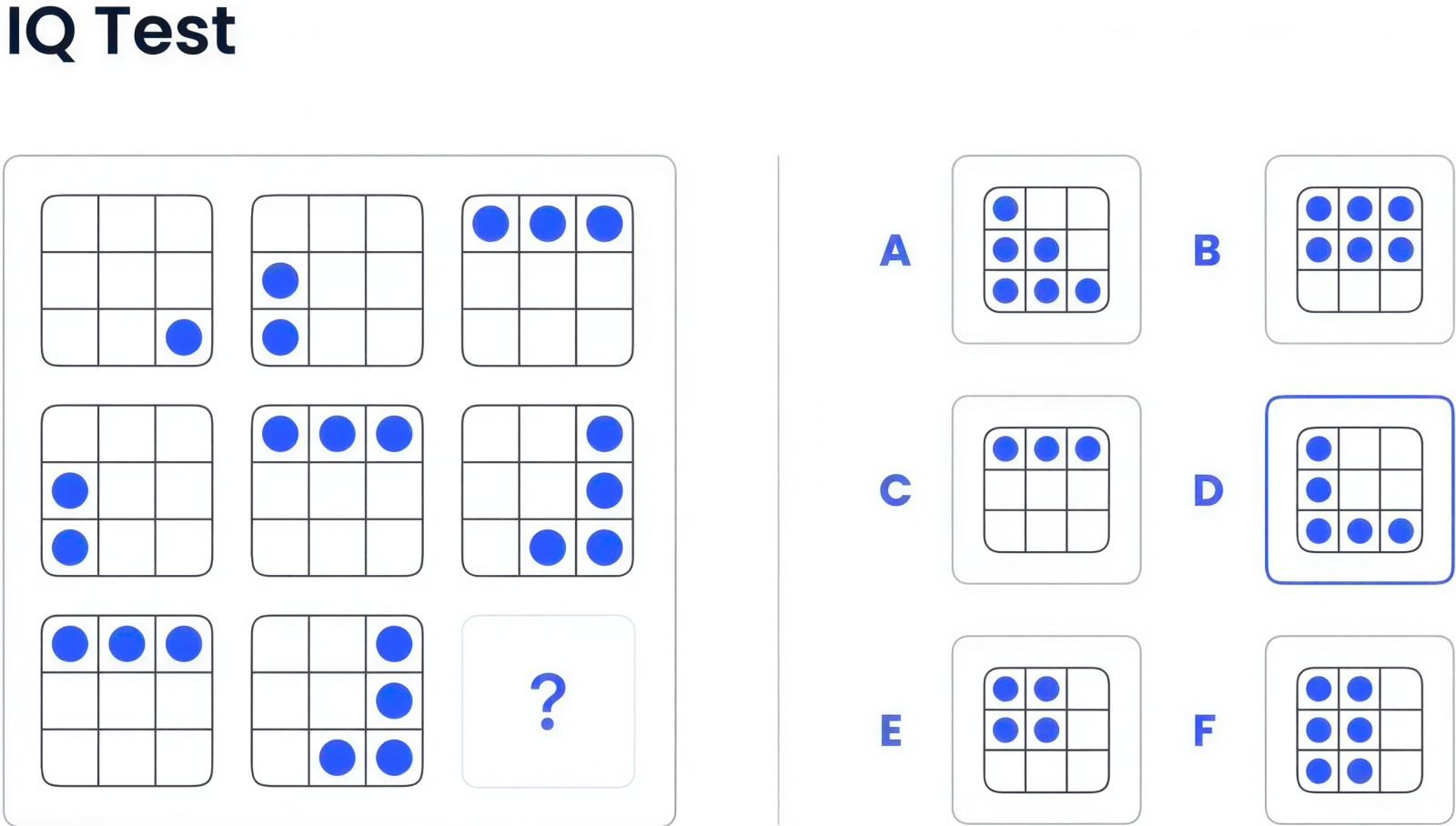
Чтобы доказать, что вы не робот, подберите… А, проехали; уже не актуально (источник: Nobel IQ) Проблема в том, что универсально — в отрыве от среды приложения мыслительной активности — определить интеллект навряд ли удастся. Недаром его принято трактовать как общую познавательную способность, которая проявляется в том, как её носитель воспринимает, понимает, объясняет и прогнозирует происходящее прежде всего с ним самим, какие решения принимает и насколько эффективно действует — в первую очередь, кстати, в нетипичных для себя ситуациях; иначе поведение индивида сводится к более или менее сложному коктейлю условных рефлексов; стандартных реакций на привычные стимулы. Антропологи и вовсе склонны определять интеллект как способность решать нестандартные задачи нестандартными методами — с учётом, разумеется, предыдущего опыта. Казалось бы, ну вот всё и разложилось по полочкам: стохастический попугай априори не способен прибегать к нестандартным — отсутствовавшим в той выборке данных, на которой он обучался, — методам, не говоря уже о том, чтобы принимать какие-то там решения. Ему делают запрос — он раскладывает тот на цепочку токенов — продолжает эту цепочку в соответствии с затверженными в ходе тренировки и зафиксированными в виде весов на входах своих перцептронов закономерностями — переводит полученную цепочку токенов ответа в набор букв и знаков пунктуации (или картинку, или видеоролик, — не суть) — и выдаёт её оператору. Ни понимания заданного вопроса, ни проявления инициативы при поиске ответа, ни какой бы то ни было нестандартности (если за ту не считать упомянутую уже щепотку стохастики, добавляемую в ходе авторегрессионного процесса) тут в принципе нет. Тема снята с повестки, Хассабис и Лекун правы, AGI через БЯМ не получить, — расходимся до появления каких-то принципиально новых подходов к организации искусственного интеллекта. Или всё-таки нет? 
«Тварь я дрожащая или взглянуть на свет право имею?» (Источник: ИИ-генерация на основе модели Nano Banana) На деле ситуация несколько сложнее — не в последнюю очередь по причине широты самого термина «интеллект» (англ. intelligence, лат. intellectus со значением «понимание, осмысление»), который за века философских, психологических и социальных изысканий значительно подразмылся. Путаница началась ещё с Иммануила Канта (Immanuel Kant), который инвертировал привычное средневековым схоластам различение intellectus и ratio (разума) как высшей и низшей познавательных способностей. Соответственно, метафизический — докантовский — термин intellectus обозначал сверхчувственное постижение духовных сущностей, не связанное с грубым, приземлённым опытом; simplex intuitus в томистской терминологии. Тогда как ratio называли банальную элементарную абстракцию; умение извлекать из частного общее, доступное в известном смысле даже амёбам: те ведь избегают яркого света и экстремальных температур, двигаясь туда, где им комфортней, — а значит, претворяют доступное им ничтожное, по сравнению с нашим, чувственное восприятие во вполне прикладное и рациональное, пусть и не осмысленное (им попросту нечем, нервной системы-то нет), действие. Таким образом, если ratio характерно для приземлённой, вещной жизни, активно, требует сопоставлений, рассуждений, проб и ошибок — и уже потому в схоластическом понимании низменно, — то intellectus, напротив, проявляется через созерцание, озарение, пассивное постижение первопричины постигаемого явления; а значит, его можно отнести к божественным свойствам. Ранняя германская философия следовала этой традиции, обозначая ratio — дискурсивный, рассудочный, логический разум — как Vernunft (что в переводе с немецкого и есть «разум»), а intellectus — высшее, метафизическое проникновение в суть вещей — как Verstand (основное значение — как раз «понимание»). 
Верный подданный Её Императорского Величества Елизаветы Петровны Иммануил Кант критикует Чистый Разум при большом стечении не на шутку заинтересованного народа; рисунок Питера Брейгеля Старшего (источник: ИИ-генерация на основе модели Nano Banana) Кант же в своём фундаментальном труде «Критика чистого разума» поставил под сомнение традиционную схоластическую метафизику — ведь, поскольку предмет той лежит за пределами доступного человеку опыта, она не может быть точной наукой, положения которой выводятся логически и подтверждаются экспериментально. «Чистым» философ, кстати, вслед за Лейбницем (Gottfried Wilhelm Leibniz) называл разум, не наполненный эмпирическим содержанием; разум как таковой, как саму способность к познанию, — ну чем не глубокая нейросеть в исходном своём состоянии, с нулевыми весами на входах всех перцептронов? Отрицая для человеческого разума интеллектуальную интуицию — то бишь непосредственное понимание сущностей/первопричин/метафизических реальностей, — Кант показал, что человеческий интеллект по своей сути дискурсивен, и как раз потому назвал Vernunft ту «тяготеющую к метафизике» самонадеянную попытку постичь в принципе непостижимый абсолют, за которой неизбежно следует скатывание к иллюзии. В итоге философ обозначил словом Verstand анализ опыта; вполне обыденный навык образовывать прикладные понятия и строить логические умозаключения на эмпирическом основании. Высшую же способность формулировать метафизические идеи (и заодно диалектически разоблачать трансцендентальные иллюзии), прежний intellectus, он назвал Vernunft. Эту классификацию подхватил затем Гегель (Georg Wilhelm Friedrich Hegel), а позже — и прочие философы Нового времени. С их лёгкой руки в переводы — что на русский, что на английский — и проник «интеллект» как кантовский Verstand. Прежнее же, схоластическое наполнение этого термина — «прямое постижение» через боговдохновенное откровение извне — унаследовал Vernunft, понимаемый как отвлечённая от грубой практики способность к развитию безусловных, умозрительных идей (таких, как «свобода» или «бессмертие»). И, поскольку Verstand у Канта подразумевает деятельное использование врождённых категорий (таких, как причинность, субстанция и единство) для формирования в сознании индивида связных и осмысленных переживаний, процесс этот тесно связан с самосознанием и моральной автономией — которые у современных ИИ со всей очевидностью отсутствуют. Может, кстати, и хорошо, что отсутствуют: морально автономный AGI был бы вполне способен задать человечеству жару. 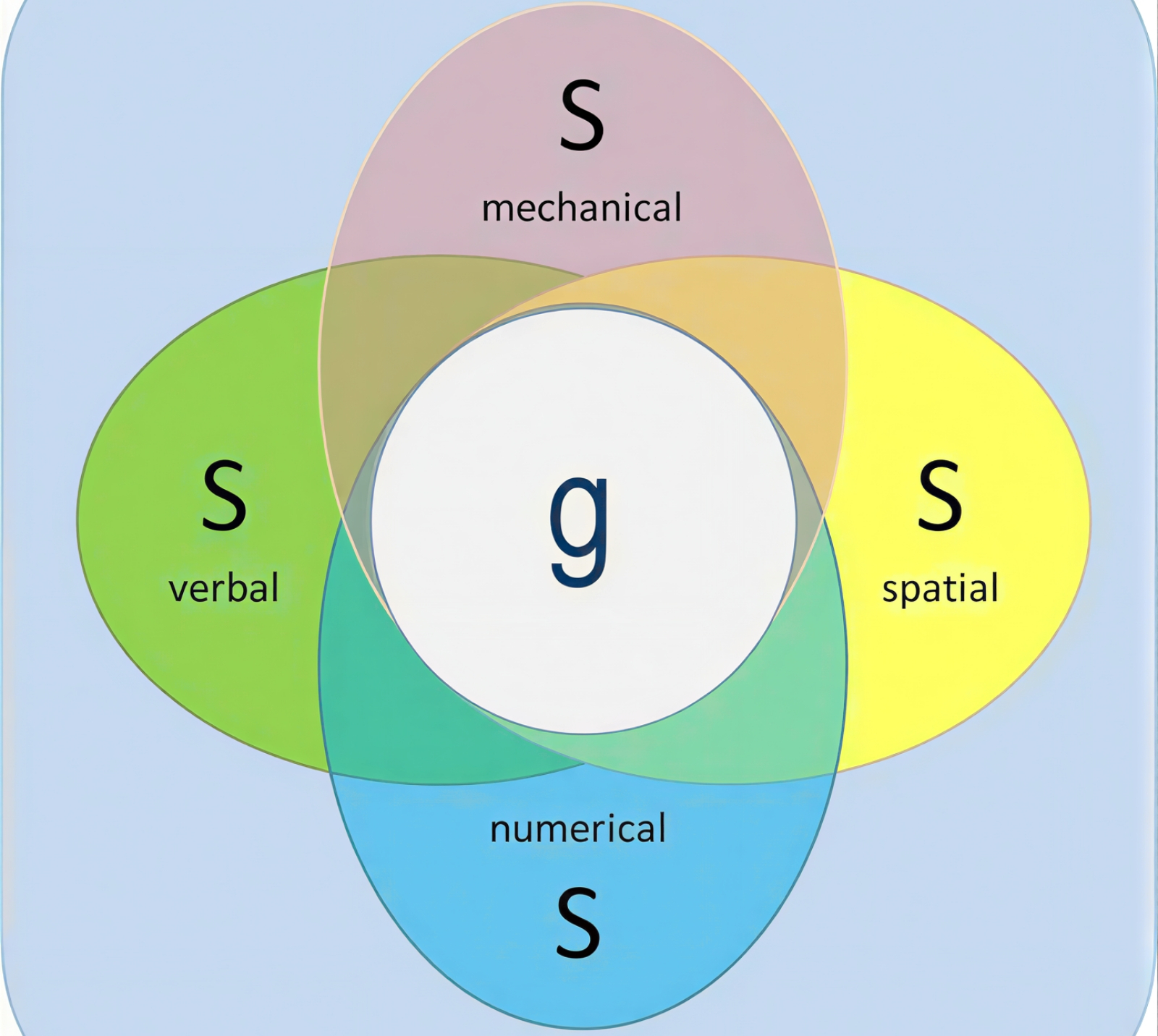
Через специализированные s-факторы различных умственных способностей косвенно определяется общий g-фактор интеллекта (источник: Simply Psychology) ⇡#Всё упирается в GТем не менее параллелей между кантианским определением интеллекта и тем смысловым наполнением, что несёт тот же самый термин в словосочетании «ИИ», предостаточно. И классической философией дело не ограничивается: в конце XIX — начале XX века, на фоне всеохватной индустриализации и повсеместного перехода к комплектованию армий по призыву, остро встала необходимость измерять интеллект, оставляя уже даже за скобками выяснение его физической или метафизической природы. Стало слишком очевидно, что кто-то уверенно сладит с паровой машиной даже в критической ситуации, а кто-то и ключи подавать обречён сплошь не те; что один новобранец освоит беспроводной телеграф за неделю, а другому и для подметания плаца ничего более хрупкого, чем лом, доверять не следует. В этой связи начало развиваться тестологическое (или психометрическое) направление в изучении интеллекта: Чарльз Спирмен (Charles Edward Spearman), один из пионеров психометрии, подвёл статистическую базу под известную поговорку «Талантливый человек талантлив во всём». Он подметил, изучая результаты школьных экзаменов в самом начале 1900-х, что если некий ученик высоко оценивается по одному из предметов, то с немалой вероятностью он и по другим будет успевать выше среднего. Положительную корреляцию между формально никак не связанными между собой областями мыслительной деятельности Спирмен приписал влиянию некоего преобладающего фактора, который он обозначил как g (от general, разумеется, — то же слово, что позже вошло в акроним «AGI») — общий фактор интеллекта. Специфические же для конкретной умственной деятельности способности он безыскусно поименовал s-факторами. Соответственно, количественный тест на выявление величины g-фактора в этой модели сводится к измерению и корректному учёту (поскольку они априори не равновесны) определённого числа s-факторов — через сравнительно несложные и хорошо калибруемые тесты. И хотя с тех пор психометрика существенно эволюционировала — так, методика Реймонда Каттелла (Raymond Cattell) предполагает различение «жидкой» и «отвердевшей» фаз умственных способностей, Gf (от fluid) и Gc (crystallized), — g-фактор продолжает оставаться основой количественных измерений человеческого интеллекта в тестах IQ и им родственных, имеющих сугубо прикладное значение. Особенно для работодателей: как показывают академические исследования, люди с более высокими количественными метриками интеллекта справляются с задачами лучше, потому что быстрее обрабатывают информацию и эффективнее связывают разнородные идеи, создавая в ходе их синтеза новые прикладные инструменты. 
В начале 1997 г. компьютер IBM Deep Blue вошёл в историю шахмат, уверенно победив тогдашнего человеческого действующего чемпиона мира по классическим турнирным правилам, — и с тех пор шахматная корона к Homo sapiens уже не возвращалась (источник: IBM) По мере увеличения сложности работы возрастает и важность интеллекта, — и для различных реализаций ИИ это умозаключение справедливо не в меньшей степени, чем для офисного клерка или университетского профессора. Но как напрямую сравнить человека с машиной? Использовать всё тот же тест IQ — с учётом того, что генеративные модели сегодня особенно востребованы как раз для решения прикладных задач? По крайней мере, сам Альтман не так давно прямо заявлял: «Приблизительно, на мой взгляд, — это не научное определение, просто ощущение на кончиках пальцев, — каждый год мы повышаем IQ своего ИИ на одно стандартное отклонение». И действительно, предельно формализованные, эти тесты великолепно подходят для того, чтобы скармливать их мультимодальным чат-ботам. Но у такой формализации есть и оборотная сторона: усвоив (особенно в ходе обучения с подкреплением), как верно решать предлагаемые задачки, стохастический попугай станет делать это с каждым разом всё лучше — компенсируя вычислительной эффективностью своей нейросети отсутствие у неё человеческого интеллекта, для измерения которого IQ, собственно, и создавался. Даже если оставить в стороне спорность применения этого теста в качестве единственного мерила человеческих мыслительных способностей, для выявления момента предполагаемого перехода от просто ИИ к AGI он точно не годится. Тогда что — шахматы? Сегодня это уже даже не смешно, хотя в 1950-х исследователи из IBM всерьёз рассуждали, что «если бы удалось создать успешную в состязании с человеком шахматную машину, это позволило бы проникнуть в самую суть того, что происходит в биологическом мозге в процессе интеллектуального поиска». Но нет; построенная и запрограммированная тою же самой компанией машина Deep Blue, даром что одолела, пусть и не с первой попытки, в 1997 г. действовавшего на тот момент чемпиона мира по шахматам, в иных областях никаких значимых успехов не продемонстрировала. Упомянутый ранее тест для различения умной машины и человека, предложенный Аланом Тьюрингом (Alan Turing) в 1950-м, не срабатывает уже для современных БЯМ уровня GPT-4.5: в ходе пятиминутной онлайновой беседы с ботом 73% добровольцев в 2025 г. признали его за человека — хотя и намеренно задавали ему вопросы из самых разных областей знания, и в самой стилистике фраз пытались выявить признаки «искусственности». На мякине стохастического попугая не проведёшь, он отменно мимикрирует. Да и в любом случае тест Тьюринга — качественный (машина/человек, «1»/«0»), а не количественный. И всё же выясняется, что, если вспомнить об исходном значении литеры g в аббревиатуре AGI и опереться на уже накопленный массив знаний о том, в чём хороши нынешние ИИ и в чём плохи, всё-таки есть шанс напрямую сопоставить машинный разум с человеческим. 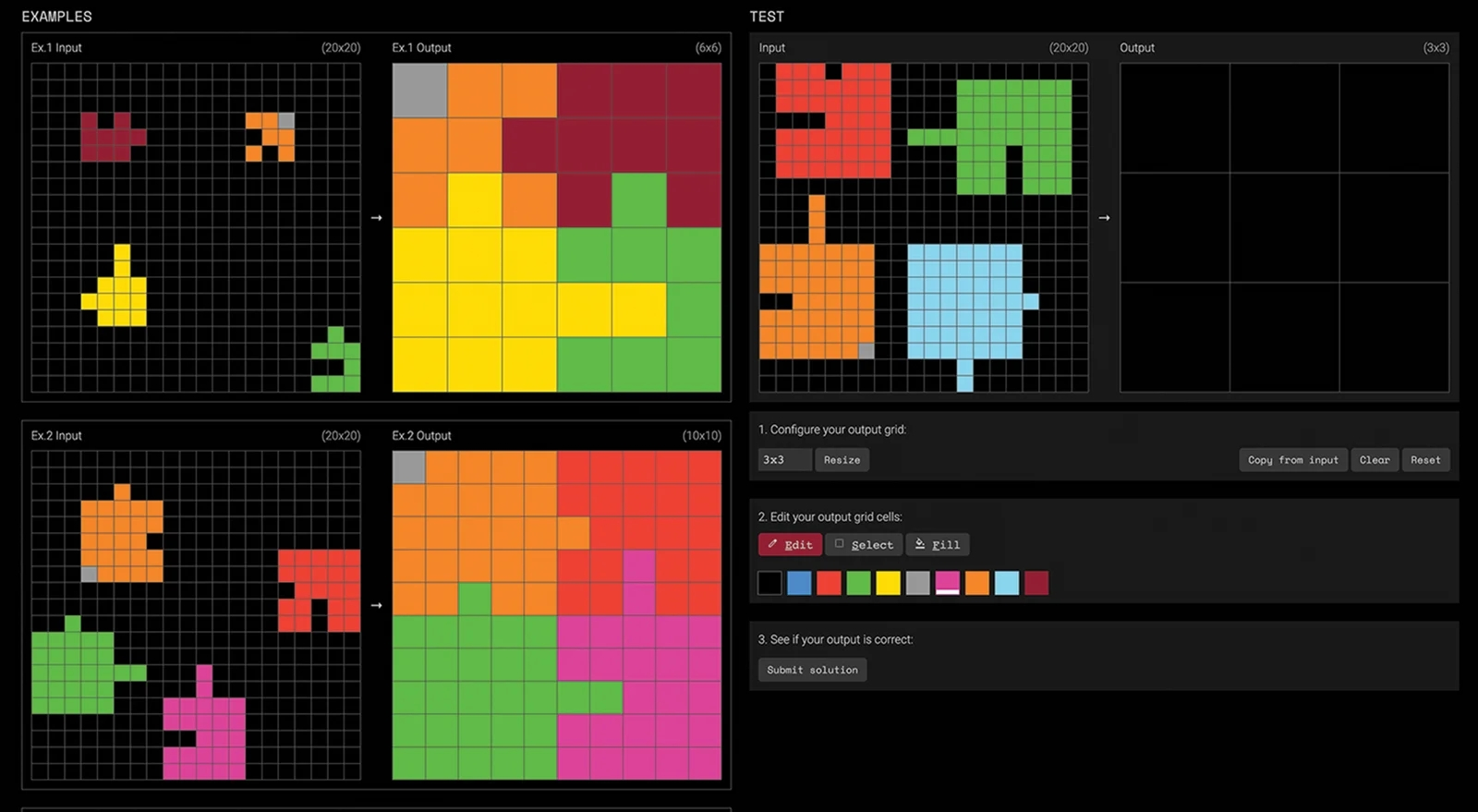
Одна из предлагаемых ARC задач на абстракцию и способность к рассуждению: абстрактные правила, задающие в данном случае взаимное расположение фигур на плоскости без наложений и пустот, ИИ должен вывести — сам для себя — всего из нескольких примеров (источник: ARC Prize Foundation) ⇡#Гибкость на грани текучестиКак Чарльз Спирмен пытался оценить выведенный им g-фактор через измерение множества разнородных s-факторов, так и Франсуа Шолле (François Chollet), ранее сотрудник Google, а позже основатель ИИ-стартапа Ndea, предложил в 2019 г. оценивать способности нейросетей к интеллектуальной деятельности косвенно. А именно — определял, в какой мере та или иная модель в принципе способна приобретать новые способности и насколько легко и быстро ей это удаётся. Такой подход, конечно, тоже небесспорен: если сильный интеллект воспринимать как суперпозицию отдельных когнитивных навыков, то и измерять, по-хорошему, надо бы их все. Однако — вспомним антропологическое определение интеллекта — готовность претендующей на разумность системы вырабатывать новые способы решения не встречавшихся ей прежде задач действительно можно считать наиболее надёжным признаком её условной разумности. По крайней мере, если со способностью приобретать новые способности у ИИ дело плохо, AGI ему точно не стать. Взять хотя бы пресловутые ранние БЯМ — не имевшие доступа в Сеть, не дополненные «рассуждающими» контурами и не готовые дообучаться с подкреплением прямо в ходе коммуникации с оператором: если ответа на заданный им вопрос не содержалось в тренировочной базе, они в лучшем случае признавали свою немощь, а в худшем — напропалую галлюцинировали. Шолле предложил для претендующих на высокое звание AGI нейросетей бенчмарк Abstraction and Reasoning Corpus (ARC), в настоящее время упоминаемый как ARC-AGI-1. Состоит он из сотен задач с визуальными головоломками: каждая задача содержит несколько демонстраций — вот условие, вот верное решение — и контрольного испытания. Здесь проверяется как раз тот самый гибкий («жидкофазный», fliud) интеллект, который особо выделяет школа Каттелла и в котором классические БЯМ откровенно слабоваты. Чтобы решить предложенные головоломки, предварительно накопленные знания не пригодятся, — понадобится умение определять связность объектов, обнаруживать признаки симметрии, выявлять взаимодополняющие элементы. Словом, проявлять то здравомыслие (практически кантовский Verstand), которым обладают способные решать схожие задачки дошкольники. Идея Шолле оказалась настолько хороша, что в течение пяти лет ARC-AGI-1 уверенно отсеивал претендентов на звание «вот-вот, уже почти AGI», выставляя им патетически низкие баллы. Правда, затем OpenAI собралась с силами и выкатила-таки «рассуждающую» модель o3, которая продемонстрировала результат лучше, чем у контрольной группы биологических экспертов. Да, победа вышла пирровой, — вычислительные затраты на решение одной головоломки оценивались в 20 тыс. долл. США, — но кто сказал, что AGI на актуальной ныне аппаратной платформе в принципе будет дешёвым удовольствием? 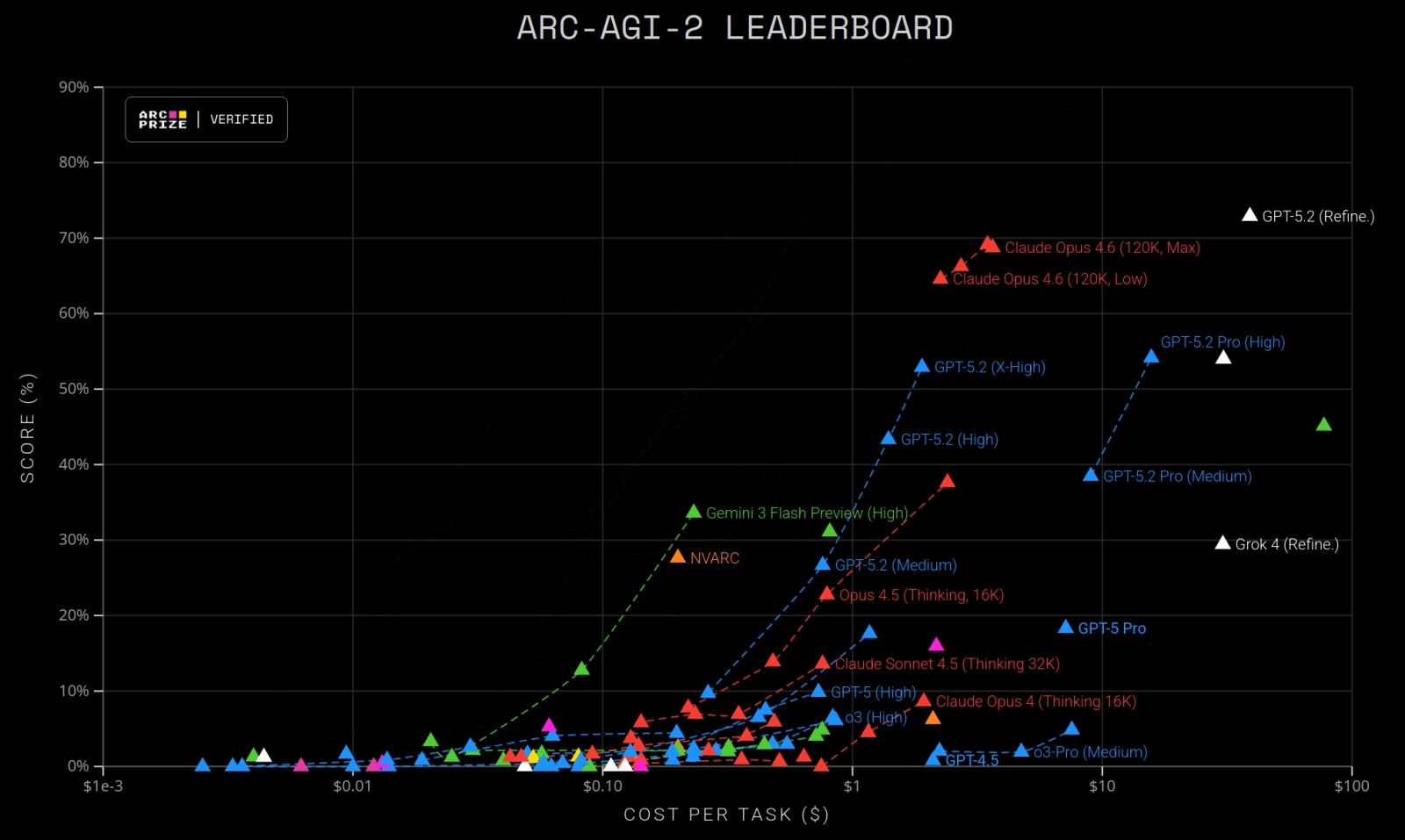
Не прошло и года с момента появления нового «сверхсложного» бенчмарка для ИИ, а уже есть модели, набирающие на нём более 70% (источник: ARC Prize Foundation) Впрочем, и ARC-AGI-1 не удалось избежать критики, характерной едва ли не для любых ИТ-(а не только ИИ-)бенчмарков. Поскольку набор тестов в нём поневоле ограничен (а иначе как можно было бы говорить о корректном сравнении результатов для разных участников?), принимавшие вызов модели нередко брутфорсили верные решения вместо того, чтобы «приобретать новые способности», и/или практиковали оверфиттинг (переобучение), жертвуя универсальностью своих возможностей ради набора большего числа баллов в необычно сложном для себя тесте. В итоге сам Шолле признал, что успешное прохождение первой версии теста вовсе не свидетельствует о достижении AGI — поскольку фиксирует опять-таки сам факт решения одной конкретной задачи, но не широкую приспосабливаемость и не выработку в системе пресловутого здравомыслия, после появления которого уже можно будет ставить вопрос о мере её разумности. В марте 2025-го миру был явлен ARC-AGI-2, который курирует отныне некоммерческая организация — фонд ARC Prize Foundation с заявленной миссией «служить ориентиром на пути к созданию искусственного интеллекта через установление долгосрочных контрольных показателей». Призовой фонд в 1 млн долл. («Those are rookie numbers!» — как бы говорят нам Google, Microsoft, Nvidia и прочие купающиеся в миллиардах киты мировой ИИ-отрасли) предполагается распределять между командами, чьи ИИ смогут решить 85% и более из 120 новых задач — НО! — со значительными ограничениями: используя всего четыре графических процессора и за 12 часов либо быстрее. Задачи действительно усложнились: они теперь требуют выявления из предложенных примеров и применения сразу нескольких правил, проведения многоэтапных связных рассуждений, интерпретации определённых символов и т. д. Средний результат человека, которому предлагают ARC-AGI-2, — около 60%, а через полгода после появления теста в открытом доступе лучший на тот момент ИИ — Grok 4 (Thinking) — показывал всего-то 16%. Правда, на момент написания настоящей статьи флагманские генеративные модели явно подтянулись: Claude Opus 4.6 (120K, High) достигла 69,2% при себестоимости решения в 3,47 доллара за задачу, Gemini 3 Pro (Refine) — 54,0% при 30,57 долл./зад., а GPT-5/2 (Refine) — 72,9% при 38,99 долл./зад. И эксперты опять не столько потирают руки в ожидании скорого, уже вот-вот, явления AGI народу (Сэм Альтман-то потирает, конечно, — но он этим занят непрерывно уже который год), сколько привычно сетуют на оверфиттинг и брутфорс — бесспорно, теперь на существенно новом и куда более прогрессивном уровне. Так что нынче в разработке находится уже ARC-AGI-3, бенчмарк с динамическими задачами (мини-играми на всё том же прямоугольном поле), но вряд ли стоит сомневаться, что и с ним история в целом повторится. 
Желающие могут самолично испробовать предварительную версию ARC-AGI-3 на three.arcprize.org, только имейте в виду, что для этих мини-игр нет инструкций — придётся самостоятельно разбираться с управлением, открывать для себя правила и обнаруживать, к какой именно конечной цели следует двигаться (источник: ARC Prize Foundation) Графические головоломки вроде тех, что предлагает ARC, — действительно серьёзный вызов для современных моделей ИИ, тем более что в практических приложениях, где эти модели регулярно используют, им не приходится складывать пазлы из разноцветных квадратиков. Эксперты говорят, что такого рода бенчмарки — неплохой теоретический ориентир, который действительно помогает развивать способности БЯМ, но всё-таки достижению уровня AGI они не способствуют. Тем не менее общий путь, намеченный Шолле, представляется вполне разумным: предлагать искусственному интеллекту целый спектр испытаний, совершенствование в каждом из которых будет свидетельствовать об общем его прогрессе в g-направлении. Только вместо довольно волюнтаристски выбранной оценки «способности приобретать способности» в собирании графических головоломок имеет смысл задействовать более разнородные средства. А именно — решение мультимодальных задач (с привлечением текста, статической графики, видео, звукового ряда и 3D-моделирования), создание устойчивых виртуальных миров и достижение в них определённых целей, прохождение созданных для людей видеоигр и т. д. И это только начало: чтобы выйти на уровень подлинно сильного интеллекта, ИИ придётся научиться вести адекватные социальные коммуникации с другими носителями разума (с людьми прежде всего, хотя начинать можно и со своих собратьев по машинному разуму), оперировать в реальном мире (куда менее толерантном к ошибкам, чем миры виртуальные), самостоятельно ставить перед собой цели и определять способы их достижения. Тут мы снова возвращаемся к вопросу о том, в какой мере моральная автономия AGI — когда и если он её всё-таки обретёт — будет соответствовать человеческой (и какой именно из человеческих, кстати? Туги-душители подойдут?). А также о том, по какому же всё-таки пути развиваться искусственному интеллекту, если БЯМ на основе плотных глубоких нейросетей — действительно тупиковая тропка; это довольно широко распространённое в экспертной среде мнение, которое, кстати, разделяет и сам Франсуа Шолле. Каким же всё-таки способом можно усилить искусственный интеллект настолько, чтобы он дорос однажды до пресловутого AGI? Идеи есть, но тема эта заслуживает отдельного обсуждения. Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











