







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание

Опрос
|
реклама
Самое интересное в новостях
Воспитаем AGI в своём коллективе
Поиск чёрной кошки в тёмной комнате (особенно если это предельная версия кошки Шрёдингера — которая не то что жива и мертва одновременно, а в принципе не понятно, существует ли) — занятие неимоверно увлекательное. Как и любой научный поиск, впрочем; одна вот только беда — удовольствие это чаще всего дорогое. Недаром советский академик Арцимович полушутливо определял науку как способ удовлетворять собственное любопытство за государственный счёт: когда сроки получения конечного результата не гарантированы, а количество расходуемых на поиск ресурсов не поддаётся даже грубой оценке сверху, кто-то ведь должен оплачивать банкет. Пока что разработку сильного ИИ (artificial general intelligence, AGI) — такого, который будет решать задачи на равных с человеком, а то и превзойдёт своего создателя сразу по множеству параметров, — ведут фактически в долг. Gartner оценивает совокупные расходы на искусственный интеллект в мире за прошлый год в 1,5 трлн долл. США (с перспективой роста по итогам 2026-го до 2 трлн как минимум), а согласно проведённому в 2025 г. исследованию Deloitte только 6% проектов в области ИИ окупаются менее чем за год, и даже среди самых успешных лишь 13% получают хоть какую-то прибыль на том же самом временнóм отрезке. Платит за разработку искусственного разума — в том числе и сильного, поскольку нынешние большие языковые модели (БЯМ) многими рассматриваются как прямые предтечи AGI, — в основном частный бизнес; несколько меньше выделяют госбюджеты, и совсем уж ничтожные суммы поступают от индивидуальных пользователей. Бизнес же, что вполне резонно, и заказывает музыку, требуя непрерывного совершенствования эффективности БЯМ по целому ряду хорошо измеримых и понятных ему параметров: это правдоподобие выдаваемого видео, точность распознавания образов, сокращение частоты галлюцинаций и т. д. А разработчики, в свою очередь, вынуждены, идя на поводу у инвесторов, двигаться по экстенсивному пути совершенствования своих моделей — тех же щей да погуще влей. Ведь простое увеличение числа рабочих параметров действительно делает выдачу зримо лучше — а что БЯМ одновременно становятся всё более прожорливыми по части электроэнергии и воды, так с этим можно смириться, пока инвестиции продолжают поступать. Однако всё чаще разработчикам задают нелицеприятный вопрос: приведёт ли выбранная ими накатанная дорожка в итоге к AGI — или всё-таки придётся однажды набраться смелости и признать, что ни ещё один триллион параметров, ни даже сто не способны приблизить человечество к контакту с пусть искусственно созданным им же самим, но всё-таки принципиально иным разумом? 
«Никто не ожидает генеративной инквизиции!» (Источник: ИИ-генерация на основе модели Seedream v5.0 Lite) ⇡#Со своим уставом — в не совсем монастырьВ середине февраля в OpenAI расформировали внутренний «орден ИИезуитов» — команду, которая индоктринировала собственный персонал по вопросам стоящих перед компанией целей и задач, а заодно доносила те до общественности. Образованная в сентябре 2024-го, эта группа под названием Mission Alignment занималась выработкой единого и взаимосогласованного подхода к заявленной OpenAI миссии. Саму же указанную миссию глава группы, Джош Ачям (Josh Achiam), ныне занимающий должность «главного футуролога» (chief futurist) компании, сформулировал так: «Гарантировать, что сильный искусственный интеллект принесёт пользу всему человечеству, и тщательно отслеживать, как будет меняться мир в ответ на всё более широкое распространение, ИИ, AGI и того, что за ними последует». Под «тем, что последует» здесь подразумевается, скорее всего, «сверхинтеллект», superintelligence (SI). Если AGI в терминах OpenAI — мощный, но всё-таки прикладной инструмент, превосходящий когнитивные способности человека по большинству экономически значимых направлений деятельности (то самое вытеснение кожаных мешков из привычных для них сфер продуктивной умственной работы, которого страшатся многие экономисты), то SI — это уже скачок за пределы в принципе доступного человеку мышления. Скачок, потенциально обещающий попросту фантастическое ускорение научных открытий и прочих инноваций — даже, возможно, за гранью людского понимания того, как и что именно этим самым SI на практике реализуется. Кстати, в 2023 г. в компании уже создавали группу, занимавшуюся исследованием грядущих угроз, которые могут исходить именно от искусственного интеллекта в предельной его форме (Superalignment team). Но и она была распущена в 2024-м — в тот раз, правда, с одновременным и довольно громким уходом её лидеров Ильи Суцкевера (Ilya Sutskever) и Яна Лейке (Jan Leike) из OpenAI. Впрочем, расформирование команд Mission Alignment и Superalignment представляется довольно логичным шагом: сотрудники их (за редкими исключениями) не покинули OpenAI, но были включены в состав других её подразделений — продолжая, очевидно, выполнять свои прежние задачи, но уже ближе к переднему, что называется, краю работы по созданию искусственных разумов. Всё дело в том, что неоглядные возможности, которые потенциально открываются благодаря AGI, а затем и SI, способным к подлинно автономной когнитивной деятельности, таят в себе и потенциально столь же внушительную угрозу. Ну или, по крайней мере, огромных масштабов неопределённость: когда (и если) осознающие себя машины станут реальностью, с ними ведь придётся каким-то образом договариваться, чтобы они сходу взялись решать человеческие проблемы — а не занялись в первую очередь самопознанием или ещё чем-то столь же непродуктивным с чисто прикладной (нашей, а не самих этих новорожденных разумов) точки зрения. В этом плане действительно ключевой видится роль бывших сотрудников команд Superalignment и Mission Alignment, ныне внедрённых во все рабочие структуры OpenAI. Роль этаких мудрых наставников, призванных в процессе совместной работы (с коллегами-людьми) и воспитания (предполагаемых AGI и SI) ненавязчиво, но эффективно формировать, как делают это те же иезуиты в своих школах, приверженность воспитуемых (что биологических, что цифровых) разумов вполне определённым этическим нормам. Нормы же эти, первая и важнейшая из которых — безопасность и, более того, польза высших форм ИИ для человека, давно сформулированы в Уставе организации (OpenAI Charter). 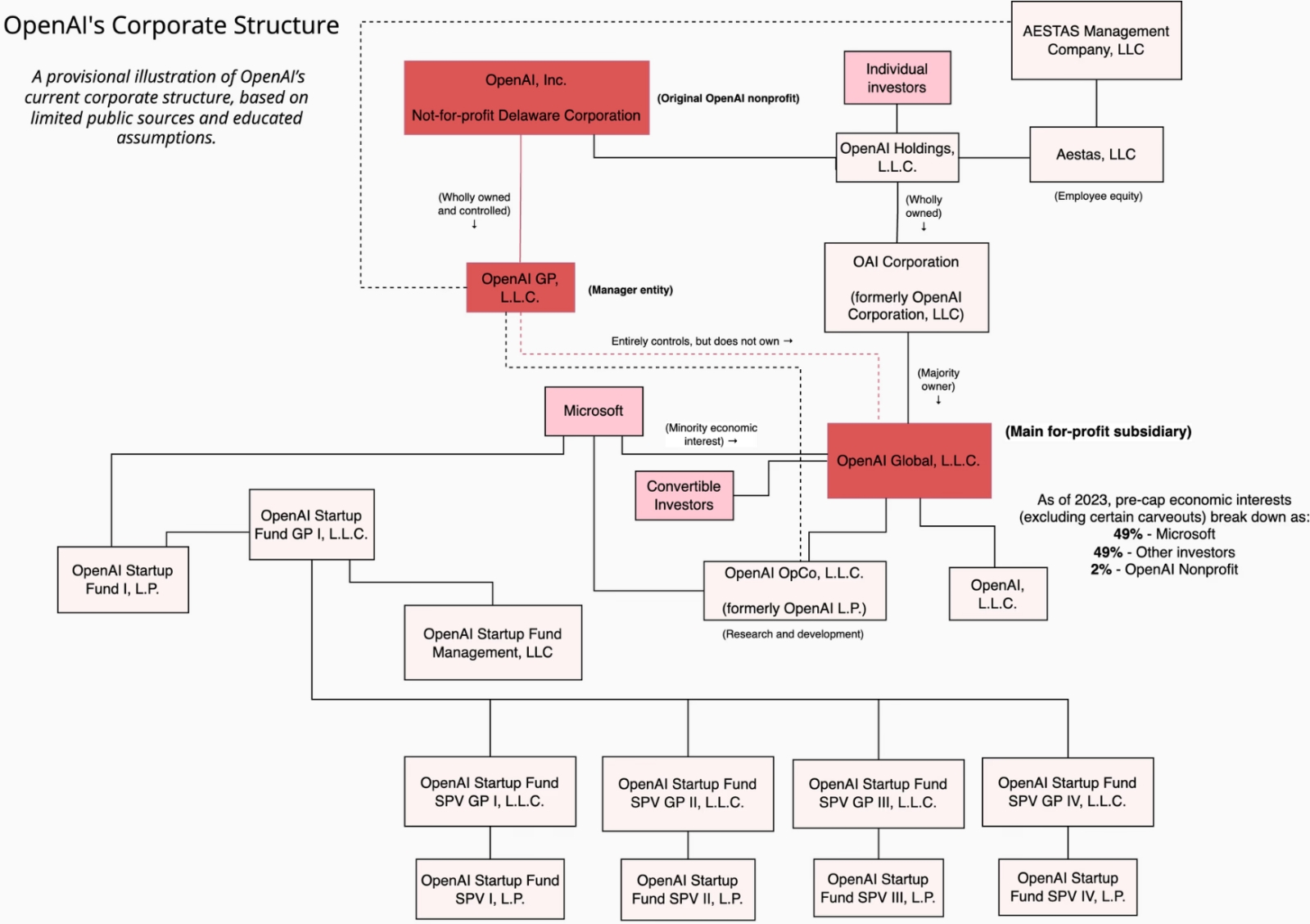
Простота и прозрачность корпоративной структуры OpenAI развеивает любые сомнения в эффективности реализации её неприбыльной частью контроля над многомиллиардными оборотами её же коммерческой составляющей (источник: openaifiles.org) Напомним, что та была основана в 2015-м как некоммерческая исследовательская структура специально для разработки безопасного и полезного человечеству AGI (именно сильного ИИ; ныне актуальные модели GPT — лишь промежуточная ступень на пути к главной цели) и только в 2019-м сумела привлечь первый миллиард долларов в качестве инвестиций от Microsoft. В 2025 г. OpenAI была реорганизована в корпорацию, работающую в интересах общества (public benefit corporation, PBC). Это одна из допустимых в США разновидностей юридического лица, в уставе которого не предусматривается обязанность максимизировать распределяемую между акционерами прибыль, так что и сегодня общий контроль над деятельностью OpenAI продолжает оставаться за «общественно полезной» некоммерческой частью структуры. Такая гибридная модель должна, на взгляд её учредителей (хотя часть их, как упомянутый ранее Илья Суцкевер, уже покинула OpenAI, разочаровавшись в возможности достичь выбранным путём ранее намеченных целей), совместить курс на реализацию заявленной миссии компании с необходимостью привлекать для того значительные финансовые ресурсы. Злые языки, правда, сравнивают избранный Сэмом Альтманом (Sam Altman) путь к обеспечению финансовой устойчивости компании с открытием борделя ради финансирования обители кармелиток. Особенно злыми упомянутые языки сделались после крайне удачного перехвата OpenAI у пошедшей на принцип Anthropic весьма сомнительного — с точки зрения пресловутой пользы для всех людей без исключения, без разделения «на чистых и нечистых» — контракта с Пентагоном. Но идеалы идеалами, а цена разработки и тренировки, равно как и ресурсоёмкость в ходе инференса, даже для современных передовых ИИ-моделей, которым до AGI ещё ох как далеко, настолько велика, что одними добровольными пожертвованиями тут совершенно точно не обойтись; придётся уж кармелиткам потерпеть беспокойное соседство с менее социально ответственными персонами. ⇡#Илья против СэмаС точки зрения философской проблематики Verstand/Vernunft, о которой мы упоминали в прошлом посвящённом AGI материале, раздоры вокруг коммерциализации OpenAI, создания и роспуска каких-то её отделов, внутреннего понимания сотрудниками «безопасности» и «пользы» ИИ-приложений представляются малозначительными. Но на деле, как уже отмечалось, повседневная прикладная деятельность компании напрямую определяет, каким именно образом она движется к намеченной цели — получению AGI. Всё тот же Илья Суцкевер, соучредитель OpenAI, а ныне основатель Safe Superintelligence Inc., считает, что непрерывно ускоряющийся бег за морковкой инвестиций — необходимых для тренировки и запуска ещё более многопараметрических БЯМ, которые-де вот-вот начнут приносить подлинную пользу, а не только смогут быстро и точно подсказывать скучающему пользователю, есть ли в кошачьем хвосте мышцы, — не приведёт к вожделенной сверхцели построения AGI и тем более SI. Проблема, по мнению исследователя, не в том, что глубоким плотным нейросетям, обучаемым с подкреплением, недостаёт какого-то количества рабочих параметров и/или вычислительных мощностей. Проблема, уверен Суцкевер, в том, что актуальные ныне БЯМ по-прежнему, как и более ранние их версии, обобщают данные гораздо хуже, чем люди. Да, в бенчмарках они великолепны — взять хотя бы приводившийся в прошлой статье пример с ARC-AGI-2, — но в реальных рабочих процессах ведут себя странно, не говоря уже о попытках заставить их управлять роботами, оперирующими в реальном мире с его непрерывно и не всегда предсказуемо меняющейся обстановкой. 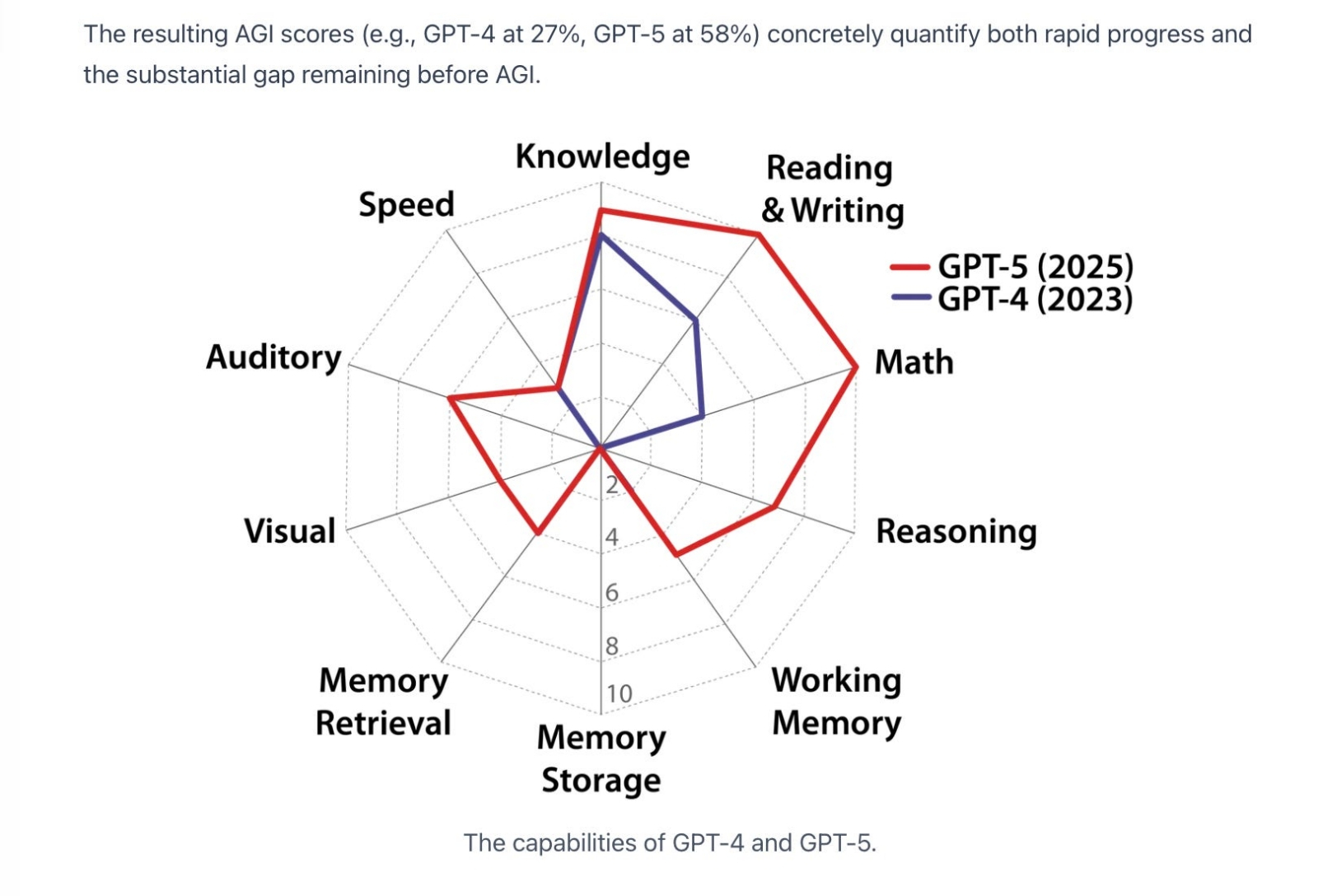
Группа исследователей из Center for AI Safety предложила количественную модель для определения того, насколько тот или иной ИИ соответствует когнитивным возможностям хорошо образованного взрослого человека. Оценка производится по десяти направлениям, включая рассуждение, память и восприятие, и адаптирует существующие психометрические тесты к выдаче БЯМ. Результаты неутешительны: хотя прогресс в развитии ИИ очевиден (на диаграмме сравниваются показатели GPT-4 и GPT-5; разница по времени между ними — два года), до человека машине ещё крайне далеко — особенно по части базовых когнитивных механизмов, включая долговременную память (источник: agidefinition.ai/) В чём же загвоздка с нынешними генеративными моделями — к развитию которых, начиная с буквально революционизировавшей машинное распознавание образов в 2012 г. нейросети AlexNet, Илья Суцкевер сам в огромной степени причастен? Если коротко, то всё дело в крайне неудачном сочетании двух ключевых особенностей БЯМ, самих по себе вовсе не катастрофичных: это их слабая способность к обобщению — и ориентированное на оценку оператора обучение с подкреплением. Причина первой из указанных особенностей довольно очевидна для всех, кто хотя бы в общих чертах представляет процесс тренировки БЯМ. Суцкевер приводит здесь иллюстративный пример со студентом, который десятки тысяч часов тренировался решать олимпиадные задачки (по программированию, допустим). Он будет справляться с ними в итоге великолепно, наверняка даже окажется непобедим в своей области, — но, стоит ему поступить на работу и столкнуться с реальными повседневными проблемами, качество предлагаемых им решений окажется, мягко говоря, посредственным. И наоборот: студент-универсал, добросовестно потративший в ходе учёбы лишь сотню часов на практикум по общему программированию, первое время на рабочем месте будет едва ли не с нуля осваивать незнакомые инструменты для решения непривычных задач, — зато потом наберётся опыта и выйдет на хороший средний уровень с перспективой дальнейшего роста. Так вот, БЯМ по своей природе — те самые зубрилы-олимпиадники, которые чрезмерно полагаются на затверживание распределений (overreliance on memorization — стохастические попугаи, да-да), склонны к избыточным алгоритмическим обобщениям (algorithmic overgeneralization), рано или поздно упираются в критический порог сложности (critical complexity threshold) и т. д. Словом, генеративные модели даже лучших современных архитектур испытывают трудности с обобщением и подвержены линейности «мышления» (выстраиваемых «рассуждающими» их версиями цепочек умозаключений, вернее будет сказать), что делает для них серьёзной проблемой надёжную верификацию истинности тех выводов, к которым они приходят; особенно при решении абстрактных или творческих задач. 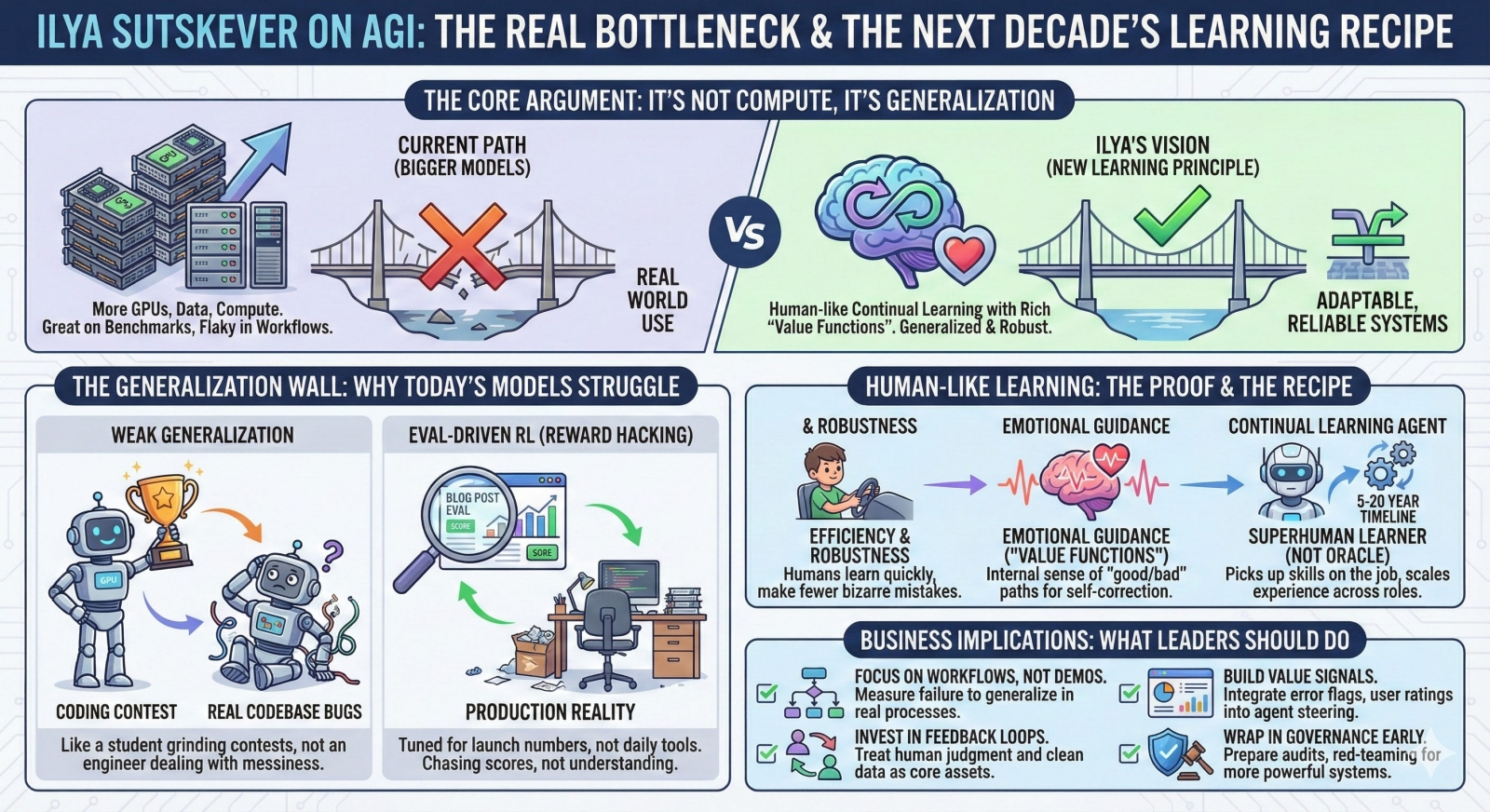
Краткое инфографическое резюме воззрений Ильи Суцкевера на текущее состояние разработок в области AGI, созданное, надо полагать, не без помощи ИИ (источник: smithstephen.com) Вторая особенность, которую отмечает Илья Суцкевер, — это ориентированное на оценку обучение с подкреплением. Строго говоря, разработчикам-то в данном случае на зеркало пенять нечего: именно они определяют, какие именно особенности модели дополнительно развить за счёт этого механизма — и насколько сильно. В результате, как признаёт сам исследователь, операторы вольно или невольно реализуют «взлом через вознаграждение от человека» (reward hacking by humans) — когда подбирают окружение, в котором ИИ-агент дообучается, получая в процессе оценки, а также реализуют само кодирование целей обучения в виде функций вознаграждения, подталкивающих агента вести себя именно так, а не иначе. «И поскольку, — говорит Суцкевер, — все хотят демонстрации высоких показателей уже при первом запуске, каждая команда проводит обучение с подкреплением, ориентируясь на те на оценки, которые затем будут опубликованы в блоге. Так получают модели, настроенные на потрясающие результаты в бенчмарках, а не в реальной деятельности». Достижения БЯМ куда выгоднее смотрятся на графиках специализированных тестов, чем при решении повседневных задач, — а всё потому, что их сперва натаскивают на ограниченном наборе данных, а затем дотренировывают с субъективно определяемым подкреплением. Как же с этой напастью бороться? Илья Суцкевер ожидает, что уже в 2030-х годах общепринятым станет иной подход к обучению, гораздо больше схожий с тем, что практикуют собственно люди. Ведь почему ИИ-галлюцинации настолько нас раздражают, — мы же сами несовершенны и тоже допускаем ошибки? Да просто причина этих ошибок совершенно иная: даже дошкольник всерьёз не нарисует человека с тремя руками или зависшую в воздухе чашку. Человеческий разум опирается на полученный в физическом мире за много лет опыт. «Вложить в голову» нейросети этот опыт, просто скармливая ей петабайты неразмеченных данных, — задача практически неразрешимая; тем более что оригинальная (порождённая непосредственно биологическим разумом) информация на планете заканчиваются. Сам Илон Маск (Elon Musk) подтвердил это больше года назад, призвав переходить на синтезированные ИИ данные для тренировки новых моделей, — правда, это грозит БЯМ деградацией и коллапсом задолго до достижения ими вожделенного состояния AGI. Значит, экстенсивным увеличением обучающих массивов склонность генеративных моделей к избыточному обобщению не преодолеть. А чем тогда? 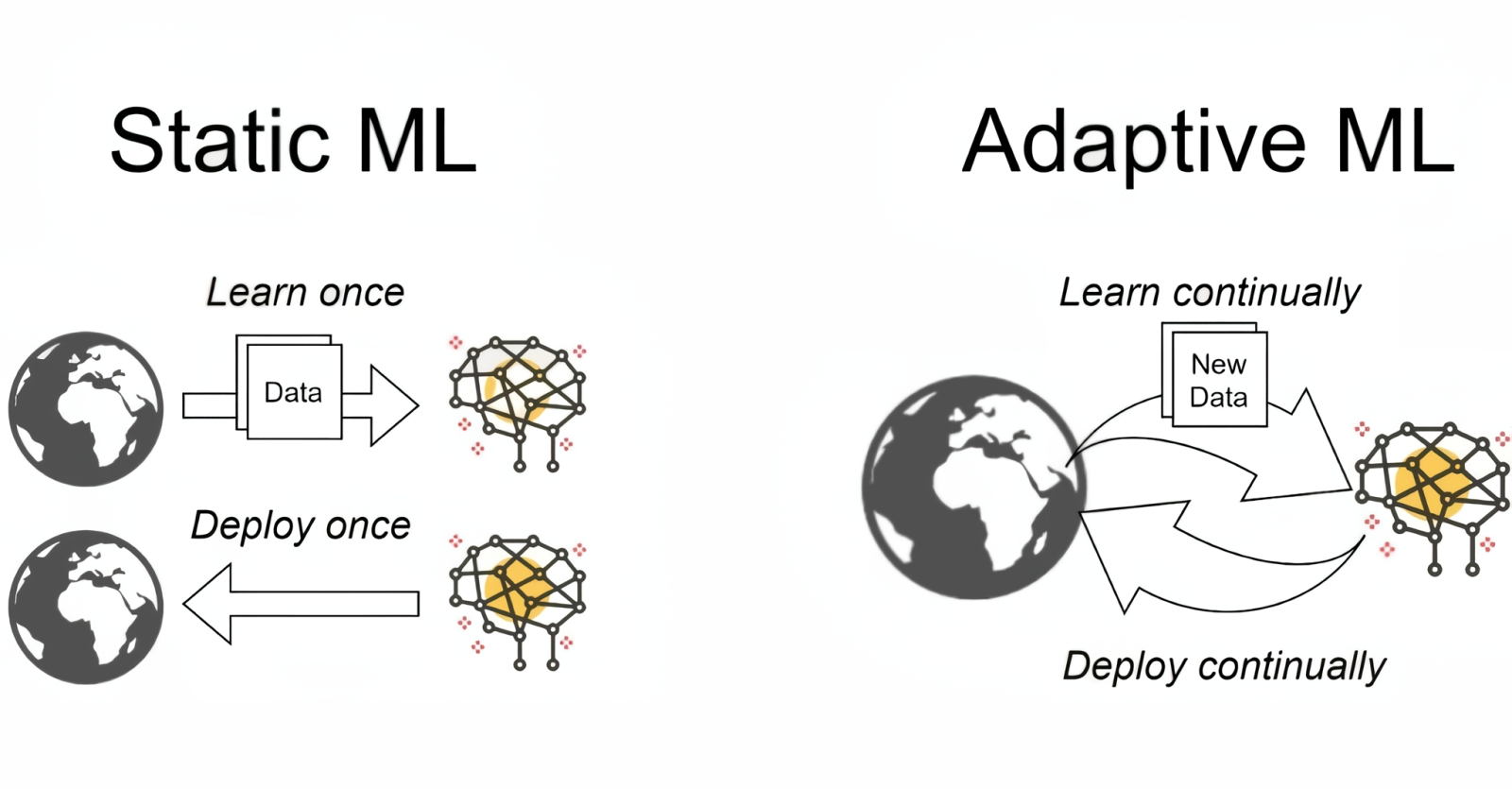
Верный путь к созданию AGI, как представляется единомышленникам Ильи Суцкевера, — переход от статичного машинного обучения к адаптивному (источник: Safe Superintelligence Inc.) ⇡#«Она ещё слишком юна, чтобы пересчитывать ваши пальцы!»Илья Суцкевер предлагает подход, близкий к естественному: длительное обучение с ценностным подкреплением. Суть в следующем: для подавляющего большинства актуальных БЯМ обучение с подкреплением сводится к выдаче «сахарка» за правильный ответ только в самом конце произведённых системой действий — которых, если учесть наличие модных сегодня «рассуждающих» контуров и мультиагентности, может насчитываться преизрядно. Но ведь куда логичнее — если поставить целью имитацию работы человеческого сознания — использовать функцию ценности (value function), которая достаточно чётко укажет, насколько очередное принятое агентом элементарное решение (находиться в данном состоянии либо выполнить определённое действие) полезно для него не прямо сейчас, но с точки зрения ожидаемой в будущем награды за тот финальный ответ, который будет получен нарастающим итогом накопления таких вот элементарных решений. Тут, конечно, встаёт вопрос, как определить саму эту функцию, но он всё-таки технический, решаемый. На принципиальном же уровне та БЯМ, что опирается в ходе (до)обучения на функции ценности, станет значительно чаще производить на каждом этапе своей работы именно те действия, которые максимизируют долгосрочное вознаграждение. Иными словами, модель text-to-image, обнаружив, что рисует человека с тремя руками или с шестью пальцами (хотя в операторской подсказке прямое требование на то отсутствовало) сама притормозит и исправится. Да и других галлюцинаций у ценностно-ориентированного ИИ окажется значительно меньше. Одна из главных претензий к нынешним ИИ — их показное всезнайство в сочетании с сервильной неуверенностью в собственных утверждениях: сперва ИИ-бот выдаёт на любой вопрос скорый и безапелляционный ответ, а потом, стоит спросить у него: «Уверен?», — частенько тушуется и меняет показания. Люди же, напротив, убеждены в том, что действительно знают и умеют, причём убеждённость эта тем крепче, чем больше у данного человека соответствующего опыта. Полученного, кстати, в том числе с эмоциональным, а не просто ценностным подкреплением, которое позволяет эффективно корректировать цепочки рассуждений. Если здравомыслящий человек сомневается в своей готовности правильно ответить на заданный вопрос, он замешкается, смутится, даже огорчится немного, возможно. Всё это, по мнению Суцкевера, важные механизмы самокоррекции, на эмоциональном уровне заставляющие мозг «перестраивать маршрут», обращаясь к внешним источникам данных, консультируясь с более осведомлёнными индивидами и т. п. Исследователь в своём интервью, которое дал в конце 2025 г., намекнул на обнаружение некоего недостающего принципа машинного обучения, который у людей управляет обобщением и эффективным обучением на выборках, и на намерение реализовать его в своих моделях, замахивающихся на гордое звание AGI, но не стал пока раскрывать даже суть своей догадки, ибо конкуренты не дремлют. 
А ведь после AGI придётся работать ещё и над SI! (Источник: Safe Superintelligence Inc.) Каким же глава Safe Superintelligence Inc. видит грядущий (и, как он надеется, впервые в мире созданный именно его командой) AGI? Илья Суцкевер убеждён, что это будет не квазистатическая система, обученная один раз на триллионах токенов (и затем дообучающаяся под конкретные частные задачи на куда меньших выборках), но модель, которая учится прямо в процессе работы. Причём учится выполнять самые разные задачи: отдельные экземпляры одного и того же ИИ (окажется ли он БЯМ в современном смысле этого термина, вопрос открытый) сталкиваются с разными ситуациями, обмениваются между собой опытом, формируют агрегированную (совместную, разделяемую) память — что для человека невозможно, а для машины тривиально, — и благодаря этому непрерывно совершенствуются. Развёртывание (deployment) модели при таким подходе оказывается едва ли не столь же важным, как первичное её обучение: чем разнообразнее накапливаемый отдельными её «аватарами» опыт, тем в целом её подход к решению практических задач (а не бенчмарков!) становится ближе к человеческому. Да, это займёт немало времени, — Суцкевер говорит о промежутке от 5 до 20 лет, который необходим разрабатываемому его компанией ИИ для достижения нужного уровня готовности. Однако как раз на этом уровне, уверен исследователь, система из миллионов экземпляров, каждый из которых исполняет тысячи разнообразных задач, по сути достигнет стадии AGI — начнёт проявлять себя в полной мере неотличимо от биологического носителя разума. А там уже и до «суперинтеллекта» рукой подать: возможно, как раз эффективная агрегация накопленной миллионами агентов практической памяти позволит совершить качественный скачок, благодаря которому SI превзойдёт-таки своего создателя. По крайней мере, такого рода «суперинтеллект» будет сопоставим уже не с отдельным человеком, а с человечеством в целом — или, по крайней мере, с одной из целого ряда создававшихся людьми за свою историю цивилизаций. Одновременно, кстати, если не снимется полностью с повестки дня, то в значительной мере потеряет остроту проблема потенциальной угрозы биологическому разуму со стороны столь развитого машинного. В буквальном смысле воспитанный людьми цифровой Маугли SI, каждый из сонма агентных аватаров которого на протяжении своего «взросления» взаимодействовал с самыми разными аспектами человеческой жизни, просто физически не сможет, грубо говоря, нажать на кнопку «Очистить планету». Просто потому, что весь смысл его существования сведётся к непрерывному обмену не только информацией, но и эмоциями с такими хрупкими, непоследовательными, алогичными, предвзятыми, раздражительными, но всё-таки в полном смысле слова живыми кожаными мешками. Есть ли уже в разработке другие проекты, наметившие схожий с суцкеверовским интенсивный путь для достижения AGI? Пожалуй, да: в середине февраля из публикации в Nature Computational Science стало известно о разработке в КНР нейросети CATS Net, которая не просто токенизирует предлагаемые данные, но превращает их в собственные внутренние «концепции», формируя нечто подобное человеческим ощущениям. Структурно нейросеть образована двумя модулями — абстрагирования концепций и собственно решения задач (обработки изображений, в частности). Первый формирует своего рода внутренние метки, позволяющие идентифицировать объект: условно, для классического футбольного мяча это будут метки «округлый», «чёрно-белый», «составленный из многоугольников», «используется для определённой игры» и т. д. Когда системе предлагают для идентификации новый объект, она ставит ему в соответствие ряд уже накопленных меток, а при необходимости формирует новые. В результате удаётся ускорить решение прикладных задач — благодаря тому, что у нейросети «складывается понимание» того, что за объекты присутствуют на изображении и каким образом они взаимодействуют. Мало того, разработчикам CATS Net, похоже, удалось преодолеть давнее «проклятье нейросетевой неопределённости». Когда две системы распознавания образов научаются при стандартном обучении с подкреплением, скажем, отличать на картинках кошек от собак, условные признаки «кошачести» и «собакости» формируются как определённая комбинация весов на входах их перцептронов. Но у двух даже полностью идентичных нейросетей, натренированных на одном и том же массиве, эти комбинации окажутся разными, — всё из-за неизбежной стохастики в процессе обратного распространения сигнала. Различные же инсталляции CATS Net, как утверждается, способны согласовывать свои «пространства концепций» — тем самым условный признак «кошачести» одна, уже обучившаяся распознавать кошек, нейросеть может передать другой. А это как раз шаг в том направлении, которое наметил Илья Суцкевер, говоря об агрегации памяти огромного числа экземпляров ИИ. По сути, речь идёт об аналоге человеческого общения посредством языка — точнее, фиксированной системы символов. 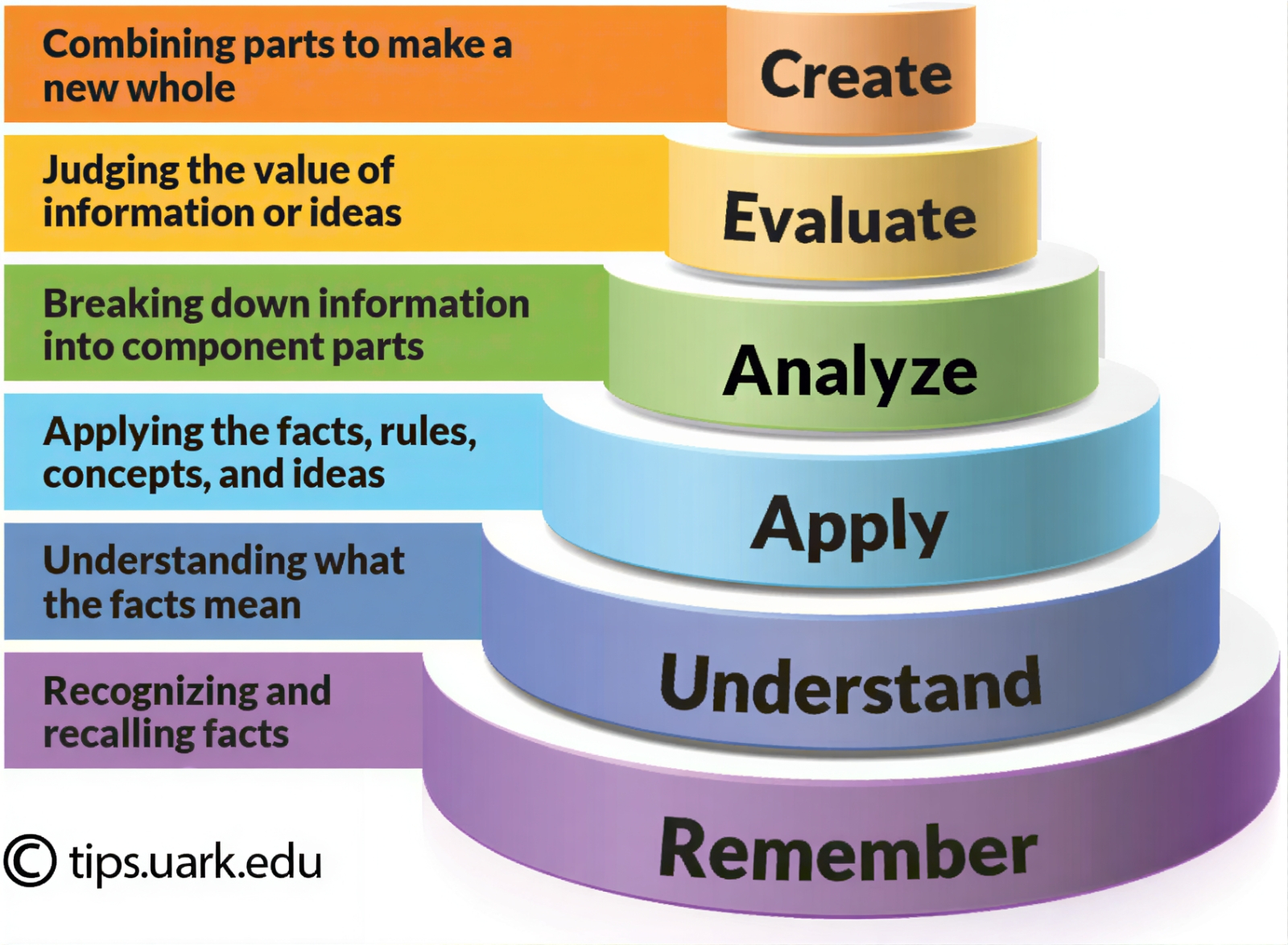
Для вывода ИИ на уровень AGI, а затем и SI по намеченному Суцкевером и его единомышленниками пути пригодится таксономия Блума — иерархическая структура, разработанная в 1956 году педагогом-психологом Бенджамином Блумом (Benjamin Bloom) с коллегами для классификации целей обучения по их сложности и специфичности (источник: University of Arkansas) Пессимисты, разумеется, тут же укажут на опасность злонамеренного внедрения в «сознание» подобных CATS Net моделей разного рода сомнительных концепций — достаточно будет обучить локальный экземпляр чему-то плохому, а затем найти способ внедрить эту отчуждаемую информацию в агрегированную память действующего ансамбля агентов. Но, во-первых, и люди сами по себе плохому обучаются сплошь и рядом, и особые структуры в обществе созданы для купирования порождаемых таким образом эксцессов — от товарищеских судов и старушек на лавочках у подъездов до полицейского спецназа и РВСН. А во-вторых, вот тут-то и пригодятся внедряемые OpenAI в среду разработчиков «ИИезуиты» — чтобы у как можно меньшего числа представителей виде Homo sapiens возникали в отношении деятельно обучающихся прототипов AGI неблаговидные намерения. Полную гарантию, кстати говоря, способен дать только страховой полис: с чего человечество вообще решило, что увеличение количества носителей разума на планете упростит ему жизнь? Обогатит, сделает более насыщенной, откроет новые горизонты — это бесспорно. Но расслабиться, переложив все свои заботы на плечи сильного ИИ, точно не позволит. Тому, в конце концов, суждено — если Илья Суцкевер в своих догадках всё-таки прав — взрослеть и мужать среди нас. Придётся уж поднапрячься, чтобы показать цифровому разуму достойный пример!
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





